决策树Python头歌-程序员宅基地
基于头歌,头歌真的是太多有趣的故事。
任务描述
本关任务:编写一个使用决策树算法进行信息增益计算及结点划分的程序。
决策树模型
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。 决策树由结点和有向边组成。结点有两种类型:内部结点和叶结点,其中内部结点表示一个特征或属性,叶结点表示一个类。一般的,一棵决策树包含一个根结点、若干个内部结点和若干个叶结点。叶结点对应于决策结果,其他每个结点则对应于一个属性测试。每个结点包含的样本集合根据属性测试的结果被划分到子结点中,根结点包含样本全集,从根结点到每个叶结点的路径对应了一个判定测试序列。在下图中,圆和方框分别表示内部结点和叶结点。决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树。下图为决策树的示意图:
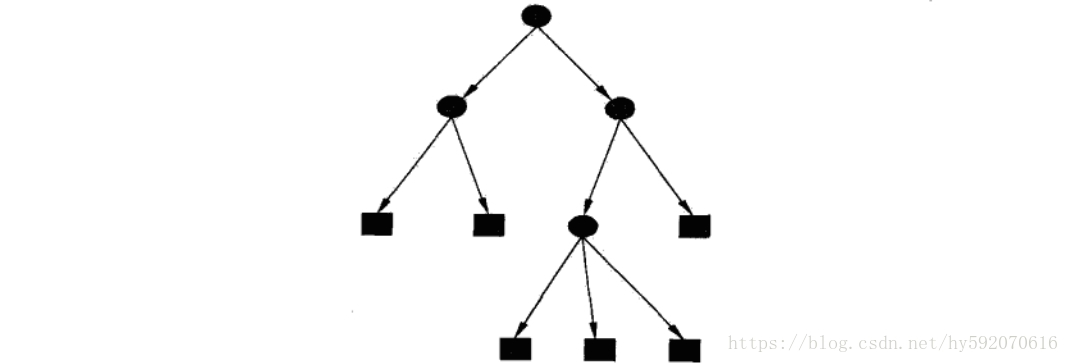
决策树根据任务的不同可以分为回归树和分类树,在本次课程中,我们主要实现分类树的构建。
决策树分类器
决策树算法分类和人类在进行决策时的处理机制类似,依据对一系列属性取值的判定得出最终决策。决策树是一棵树结构,其每个非叶子节点表示一个特征属性上的测试,每个分支表示这个特征属性在某个值域上的输出,而每个叶子节点对应于最终决策结果。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点对应的类别作为决策结果。
决策树学习的目的是产生一棵泛化性能强,即处理未见示例能力强的决策树。其基本流程遵循“分而治之”的策略,算法伪代码如下图所示:
输入:训练集D={(x_1,y_1),(x_2,y_2),⋯,(x_m,y_m)};
属性集A={a_1,a_2,⋯,a_d}.
过程:函数TreeGenerate(D,A)
1: 生成节点node
2: if D中样本全属于同一类别C then
3: 将node标记为C类叶节点;return
4: end if
5: if A=∅ or D中样本在A上取值相同 then
6: 将node标记为叶节点,其类别标记为D中样本数最多的类;return
7: end if
8: 从A中选择最优 划分属性a_*;
9: for a_*的每一个取值a_*^v do
10: 为node生成一个分支;令D_v表示D中在a_*上取值为a_*^v的样本子集;
11: if D_v=∅ then
12: 将分支节点标记为叶节点,其类别标记为D中样本最多的类;return
13: else
14: 以TreeGenerate(D_v,A\{a_*})为分支节点
15: end if
16: end for
输出:以node为根节点的一棵决策树编程要求
根据提示,在右侧编辑器补充代码,实现决策树信息熵构建,包括:
- 划分的函数
- 信息熵计算的函数
- 最优划分属性和最优值计算的函数
- 进行划分,并打印划分后的信息熵值
import numpy as np
from sklearn import datasets
#######Begin#######
# 划分函数
def split(x,y,d,value):
#######End#########
index_a=(x[:,d]<=value)
index_b=(x[:,d]>value)
return x[index_a],x[index_b],y[index_a],y[index_b]
#######Begin#######
# 信息熵的计算
from collections import Counter
def entropy(y):
counter=Counter(y)
res=0.0
for i in counter.values():
p=i/len(y)
res+=-p*np.log(p)
return res
#######End#########
#######Begin#######
# 计算最优划分属性和值的函数
def try_spit(x,y):
best_entropy=float("inf")
best_d,best_v=-1,-1
for d in range(x.shape[1]):
sorted_index=np.argsort(x[:,d])
for i in range(1,len(x)):
if x[sorted_index[i-1],d] != x[sorted_index[i],d]:
v=(x[sorted_index[i-1],d]+x[sorted_index[i],d])/2
x_l,x_r,y_l,y_r=split(x,y,d,v)
e=entropy(y_l)+entropy(y_r)
if e<best_entropy:
best_entropy,best_d,best_v=e,d,v
return best_entropy,best_d,best_v
#######End#########
# 加载数据
d=datasets.load_iris()
x=d.data[:,2:]
y=d.target
# 计算出最优划分属性和最优值
best_entropy=try_spit(x,y)[0]
best_d=try_spit(x,y)[1]
best_v=try_spit(x,y)[2]
# 使用最优划分属性和值进行划分
x_l,x_r,y_l,y_r=split(x,y,best_d,best_v)
# 打印结果
print("叶子结点的熵值:")
print(entropy(y_l))
print("分支结点的熵值:")
print(entropy(y_r))
这个耗时很久,大多是信息熵entropy(y)函数的内部编写出现了问题。
第一次:
#定义二分类问题的信息熵计算函数np.sum(-p*np.log(p))
def entropy(p):
return -p*np.log(p)-(1-p)*np.log(1-p)Error:
RuntimeWarning: divide by zero encountered in log
return -p*np.log(p)-(1-p)*np.log(1-p)
这里log标错是因为p应该不为0和1
RuntimeWarning: invalid value encountered in multiply
return -p*np.log(p)-(1-p)*np.log(1-p)
这里multiply标错是p等于1时乘法无效
RuntimeWarning: invalid value encountered in log
return -p*np.log(p)-(1-p)*np.log(1-p)
这里log标错同上。
第二次:
课本例题:
第三次:
第四次:找找Counter函数的功能。
智能推荐
数据结构——图论基础篇_图论中有同权-程序员宅基地
文章浏览阅读525次。基本概念:图论〔Graph Theory〕是数学的一个分支。它以图为研究对象。图论中的图是由若干给定的点及连接两点的线所构成的图形,这种图形通常用来描述某些事物之间的某种特定关系,用点代表事物,用连接两点的线表示相应两个事物间具有这种关系。图论是一种表示 "多对多" 的关系图是由顶点和边组成的:(可以无边,但至少包含一个顶点)一组顶点:通常用 V(vertex) 表示顶点集合..._图论中有同权
Vue中 Vue.extend() 详解及使用-程序员宅基地
文章浏览阅读3w次,点赞13次,收藏45次。Vue中 Vue.extend() 详解及使用_vue.extend
解决springboot,单元测试启动ApplicationRunner问题_applicationrunner解决-程序员宅基地
文章浏览阅读1.6k次。在执行单元测试时,ApplicationRunner被意外启动,导致了Netty服务器被初始化,单元测试无法执行的问题。解决方案:通过设置ApplicationRunner对应Bean的Profile解决对应组件添加注解:@Profile("!test")单元测试添加注解:@ActiveProfiles("test")..._applicationrunner解决
Java前景如何,容易找工作嘛_java 岗位找工作容易-程序员宅基地
文章浏览阅读748次。/*文章很长,能看完的少走一个月弯路,绝不抖机灵*/这篇文章是为了介绍自己自学用过的Java视频资料。本套整合教程总共180+G,共450+小时。考虑到绝大部分视频至少要看两遍,而且视频总时长并不代表学习时长,所以零基础初学者总学习时间大约为:600小时视频时长 + 100小时理解 + 100小时练习,至少需要800小时。你可能觉得自己能一天学习8小时,实际上平均下来每天能学4小时都算厉害了。总会有各种原因,比如当天内容太难,公司聚会,要出差等等。如果周末你也是坚持学习,那么最理想状况下,6_java 岗位找工作容易
【顺序表和链表】_什么是顺序表?什么是链表?-程序员宅基地
文章浏览阅读1.5k次,点赞27次,收藏14次。文章目录一:线性表1.1 顺序表1.1.1 接口实现1.2 链表1.2.1 链表与数组的区别1.2.2 结构体的自引用1.2.3 链表的分类一:线性表线性表是n个具有相同特性的数据元素的有限序列。线性表是一种在实际中广泛使用的数据结构,常见的线性表有:顺序表,链表,栈,队列,字符串等。线性表在逻辑上是线性结构,也就是说是一条连续的实线,但其实在物理结构上不一定连续,其中线性表在储存的时候,通常以数组和链式结构的形式存储。1.1 顺序表顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性_什么是顺序表?什么是链表?
valine评论系统不能使用_code 403: 访问被api域名白名单拒绝,请检查你的安全域名设置-程序员宅基地
文章浏览阅读2.1k次。一.今天发现 Valine 评论系统不见了,没法使用啦,发现原来是valine里的av -min.js检查不到的原因。官方也给了说法,是因为 leancloud.cn 以及 …lncld.net 域名不能解析了。那我的解决方法是什么呢??首先,我找到了av -min.js和valine.min.js的源码。源码链接如下: av -min.js valine.min.js接下来我们在我们的github.io上/js下新建两个js文件,分别是av -min.js和valine.min.js然_code 403: 访问被api域名白名单拒绝,请检查你的安全域名设置
随便推点
DM368开发 -- 文件烧写_dm368 不能下载 yaffs 程序-程序员宅基地
文章浏览阅读5.6k次,点赞2次,收藏5次。参看:DM36x的UBL分析以及串口启动UBL 是 RBL 引导启动的一段小程序,主要负责初始化时钟,串口,NAND,DDR2 等,然后把 uboot, kernel, rootfs 复制到 DDR2 上并引导 uboot。为什么 UBL 跟串口启动一起讲,那是因为这两个关系很密切,很多代码是共用的,而且代码都放在同一个目录下,所以就合起来一起讲了。一、UBLubl 的代码放在 dvsdk 目录下_dm368 不能下载 yaffs 程序
什么是分库分表?为什么需要分表?什么时候分库分表-程序员宅基地
文章浏览阅读1.4k次,点赞4次,收藏14次。分库分表是在海量数据下,由于单库、表数据量过大,导致数据库性能持续下降的问题,演变出的技术方案。分库分表是由分库和分表这两个独立概念组成的,只不过通常分库与分表的操作会同时进行,以至于我们习惯性的将它们合在一起叫做分库分表。通过一定的规则,将原本数据量大的数据库拆分成多个单独的数据库,将原本数据量大的表拆分成若干个数据表,使得单一的库、表性能达到最优的效果(响应速度快),以此提升整体数据库性能。预定义算法是事先已经明确知道分库和分表的数量,可以直接将某类数据路由到指定库或表中,查询的时候亦是如此。_分库分表
多行业万能预约门店小程序源码系统 带完整的搭建教程以及安装代码包-程序员宅基地
文章浏览阅读472次。小编给大家分享一款多行业万能预约门店小程序源码系统。该系统不仅具备高度的可定制性,还提供了丰富的功能模块,能够轻松应对不同行业的预约需求。:该系统支持多行业预约需求,无论是美容美发、餐饮娱乐还是医疗健身等行业,都能找到适合的预约模板和功能模块。:该系统提供了完整的搭建教程和安装代码包,用户只需按照教程操作,即可轻松完成小程序的搭建和部署。:系统提供了丰富的数据分析和统计功能,可以帮助商家了解预约情况、客户分布等信息,为门店运营提供有力支持。同时,还支持预约提醒功能,确保客户能够按时到店,提高预约的准确率。
解决antd的select下拉框因为数据量太大造成卡顿的问题_select 数据量太大-程序员宅基地
文章浏览阅读2.1w次,点赞23次,收藏42次。相信用过antd的同学基本都用过select下拉框了,这个组件数据量少的时候很好用,但是当数据量大的时候,比如大几百条上千条甚至是几千条的时候就感觉一点都不好用了,卡的我怀疑人生,一点用户体验都没有了。当然这不是我想去优化它的动力,主要是公司业务人员和后端的同事也无法忍受,于是我只能屈从于他们的淫威。。。。想要优化肯定要知道为什么会卡,初步判断就是数据量过大导致渲染option组件的时间过长导致卡..._select 数据量太大
使用MQTT.fx与百度天工物接入平台实现嵌入式设备的对接_百度天工mqtt还能用嘛-程序员宅基地
文章浏览阅读120次。通过本文的介绍,我们了解了如何使用MQTT.fx与百度天工物接入平台对接嵌入式设备。首先,我们注册了百度天工账号并创建了物接入应用;最后,我们通过订阅和发布消息的方式实现了与百度天工物接入平台的数据交互。在这个背景下,百度推出了天工物接入平台,为开发者提供了简单、高效的物联网设备连接方案。MQTT.fx是一款开源的MQTT客户端工具,它支持多种操作系统,并提供了直观的用户界面,方便开发者进行MQTT消息的订阅和发布操作。百度天工物接入平台是百度基于物联网技术推出的一款用于连接和管理物联网设备的平台。_百度天工mqtt还能用嘛
【深度学习】Normalizing flow原理推导+Pytorch实现-程序员宅基地
文章浏览阅读1.4k次,点赞33次,收藏31次。1、前言Normalizingflow\boxed{Normalizing \hspace{0.1cm} flow}Normalizingflow,流模型,一种能够与目前流行的生成模型——GAN、VAE\boxed{\mathbf{GAN、VAE}}GAN、VAE相媲美的模型。其也是一个生成模型,可是它的思路和另外两个的迂回策略却很大不同。本文我们就简单来介绍一个这个模型吧2、引入在生成模型中,我们的目的就是计算出数据x的概率分布。然而,数据的分布总是千奇百怪的。其无法被定义,无法被观测,无法被_normalizing flow