数据挖掘实验-主成分分析与类特征化_主成分分析的目的和作用-程序员宅基地
技术标签: 数据挖掘
数据集&代码![]() https://www.aliyundrive.com/s/Jtcuion5iNC
https://www.aliyundrive.com/s/Jtcuion5iNC
一.主成分分析
1.实验目的
-
了解主成分分析的目的,内容以及流程。
-
掌握主成分分析,能够进行编程实现。
2.实验原理
主成分分析的目的
主成分分析就是把原有的多个指标转化成少数几个代表性较好的综合指标,这少数几个指标能够反映原来指标大部分的信息(85%以上),并且各个指标之间保持独立,避免出现重叠信息。主成分分析主要起着降维和简化数据结构的作用。
主成分分析的数学模型
假设所讨论的实际问题中,有p个指标,把这p个指标看作p个随机变量,记为X1,X2,…,Xp,主成分分析就是要把这p个指标的问题,转变为讨论 m 个新的指标F1,F2,…,Fm(m<p),按照保留主要信息量的原则充分反映原指标的信息,并且相互独立。
![]()
主成分分析的做法是寻求原指标的线性组合Fi。
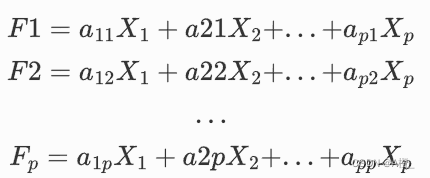
满足如下条件:
-
主成分的系数平方和为1:
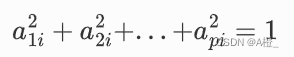
-
主成分之间相互独立,无重叠的信息:
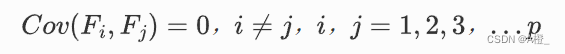
-
主成分之间的方差依次递减:

求解主成分的过程
-
求样本均值\overline{X}和样本协方差矩阵S;
-
求S的特征根\lambda
-
求特征根所对应的单位特征向量
-
写出主成分的表达式
![]()
其中主成分选取时,根据累积贡献率的大小取前面m个主成分。
选取原则:
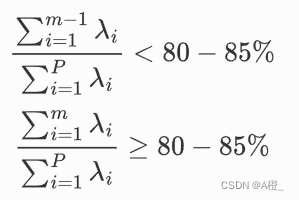
3.实验过程
R语言内置了主成分分析的计算函数,也有其他的包可以进行主成分分析,实验中使用R语言,采用内置的PCA主成分分析函数进行主成分分析。以下以对癌症数据集BLCA的数据进行主成分分析为例,说明完成主成分分析的过程,其他数据集的方法是相同的。
(1)环境准备
安装并导入用于多元统计分析可视化的factoextra包。
options(repos=structure(c(CRAN="https://mirrors.tuna.tsinghua.edu.cn/CRAN/")))
install.packages("factoextra",dependencies = TRUE)
library(factoextra)将数据导入。
data <- read.csv('D:\\Files\\文档\\HNU5\\数据挖掘\\数据集\\BLCA\\rna.csv') 进行转置,将样本放在行,属性(gene_id)放在列上。
data <- t(data)(2)进行主成分分析
使用R语言内置的prcomp函数进行主成分分析:
cancer.pr <- prcomp(data)R语言中的prcomp函数可以有另外两个参数:
-
SCALE:设置为true,则在进行主成分分析之前将数据进行标准化。
-
RANK:主成分个数。
当各变量之间存在不同量纲时,就需要使用标准化。在对本书聚集进行分析时,考虑到数据都是样本的基因表达值,假设量纲是相同的,不进行标准化。
使用summary函数查看主成分贡献率:
summary(cancer.pr)部分结果如下:
其中Standard deviation表示标准差,Proportion of Variance表示单主成分贡献率,Cumulative Proportion表示累积贡献率。根据主成分的选取原则,选取的m个主成分的累积贡献率应该大于80%,因此可以看出,需要选择前116个主成分,此时主成分的累计贡献率为80.15%,可以反映原来指标大部分的信息。

进行主成分选取时,还可以生成碎石图,查看最大到最小排列的贡献值:
fviz_eig(cancer.pr, addlabels = TRUE, ylim = c(0, 100)) 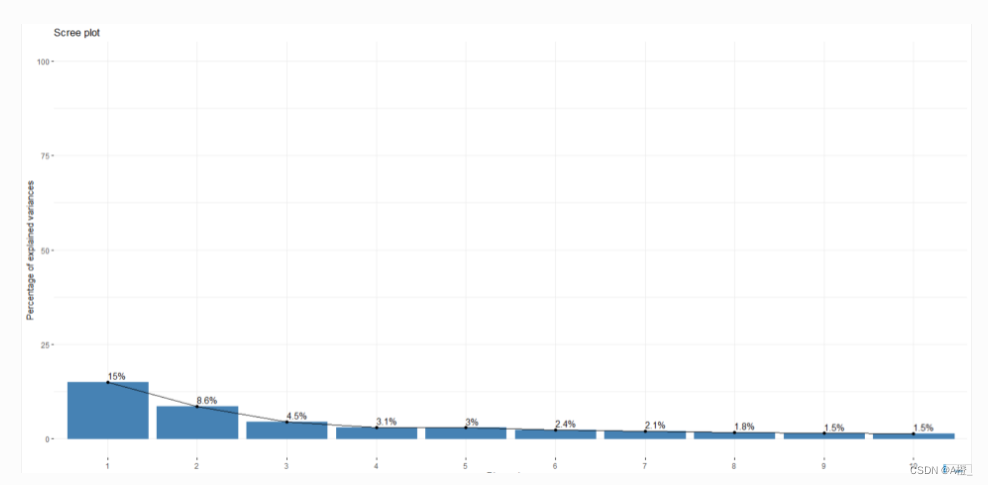
这里可以看出,最大的主成分贡献值有15%,大部分主成分贡献值都比较小,因此才需要前116个主成分才能使累积贡献率达到80%,这也说明原数据无法降维到很小的维度。
还可以绘制一个变量相关性可视化图,相关图中越远离原点,主成分PC对变量的代表性越高(相关性强),靠近的变量为正相关。
fviz_pca_var(cancer.pr)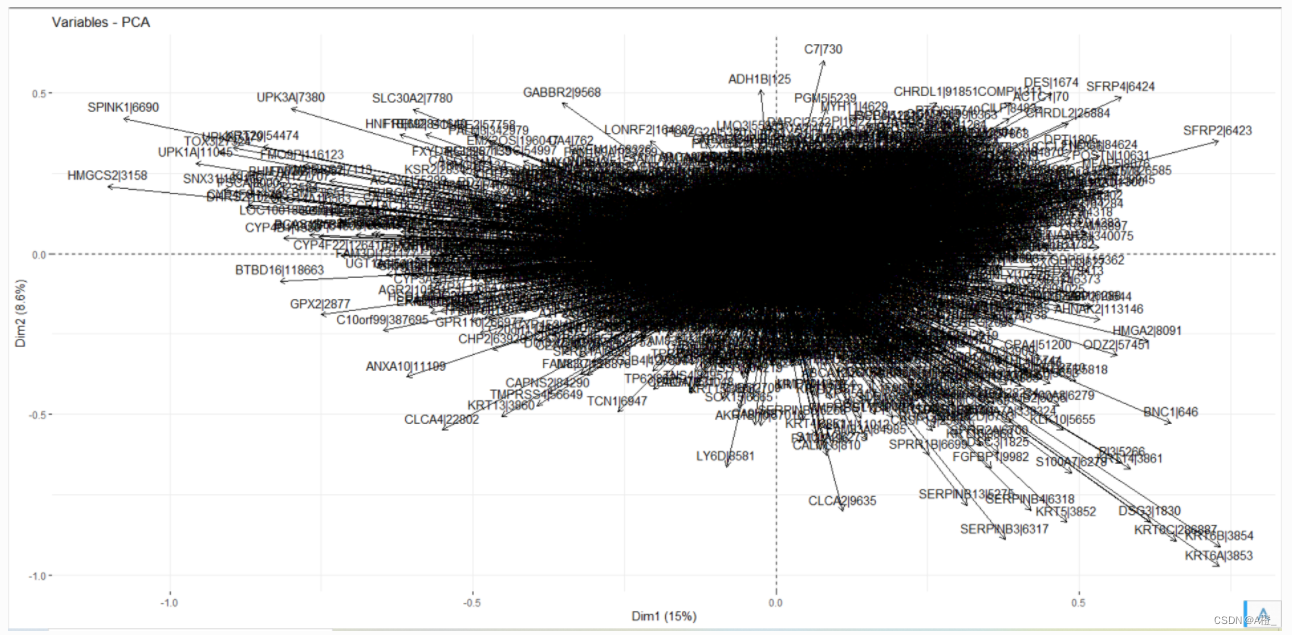
还有一些其他的绘图函数和主成分分析结果的信息,表示主成分对变量的代表性强弱,每个变量对特定主成分的贡献等,这里由于主成分分析后数据维度仍然很高,不做相关的分析。
(4)计算主成分数据
主成分分析主要起着降维和简化数据结构的作用。经过以上对主成分的求解,已经确定可以保留前20个主成分,只需要计算各个样本的主成分值,此后对数据的分析只需要基于主成分数据,不需要使用原始数据了。最后将结果导出,就完成了数据的主成分分析。
cancer.pca <- predict(cancer.pr)[,1:116]
write.table (cancer.pca, file ="D:\\Files\\文档\\HNU5\\数据挖掘\\数据集\\BLCA\\pca.csv", sep =",", row.names =TRUE, col.names =TRUE, quote =TRUE)对于主成分分析后的样本,可以进行坐标可视化:
fviz_pca_ind(cancer.pr)#score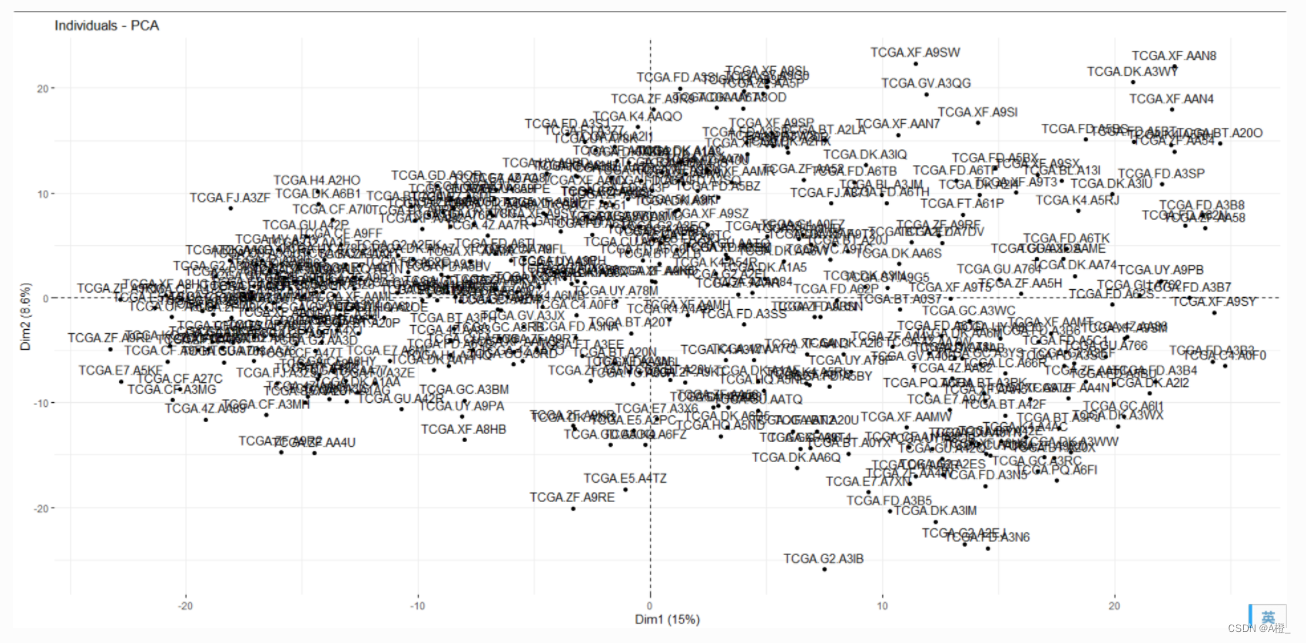
对于不同癌症类型的数据集,进行主成分分析后:
| 类型 | 主成分数 | 累积贡献率 |
|---|---|---|
| BLCA | 116 | 80.15% |
| BRCA | 212 | 80.072% |
| KIRC | 114 | 80.125% |
| LUAD | 140 | 80.099% |
| PAAD | 45 | 80.15% |
4.实验结果分析
对不同的数据集进行主成分分析后,数据维度明显降低了,体现了主成分分析进行数据降维的作用。但仍需保留很多主成分才能满足累积贡献率达到80%的要求,这体现了数据的复杂程度。主成分分析后的各个数据集没有相同的属性,不清楚如何对不同癌症类型的主成分分析后的数据进行比较,因此没有完成。
二.类概念描述及特征化分析
1.实验目的
-
了解类特征化和类对比分析目的,内容以及流程。
-
掌握类特征化和类对比分析,能够编程实现。
-
掌握属性相关分析,实现基于信息增益的属性相关分析。
2.实验原理
类特征化和类对比分析
概念(类)描述是描述性数据挖掘的最基本形式。类描述由类特征和比较组成。
-
类特征化:汇总并描述称作目标类的数据集。
-
类(比较)对比:汇总并将一个称作目标类数据集与称作对比类的其他数据集相区别。
属性相关分析
-
通过识别不相关或者是弱相关的属性,将他们排除在概念描述过程之外,从而确定哪些属性应当包含在类特征化和类比较中。
-
属性相关分析的基本思想是计算某种度量,用于量化属性与给定类或概念的相关性。可采用的度量包括信息增益、不确定性和相关系数。
信息增益
信息增益通过计算一个样本分类的期望信息和属性的熵来获得一个属性的信息增益,判定该属性与当前的特征化任务的相关性。
信息增益的计算方法如下:
S是一个训练样本的集合,该样本中每个集合的类编号已知。每个样本为一个元组。有个属性来判定某个训练样本的类编号。
假设S中有m个类,共S个训练样本,每个类Ci有Si个样本,那么任意一个样本属于类Ci的概率是Si/S,那么用来分类一个给定样本的期望信息是:
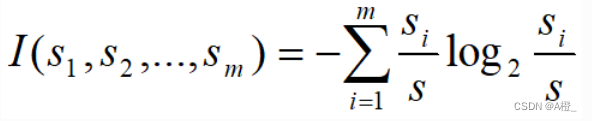
一个有v个值的属性A{a1,a2,...,av}可以将S分成v个子集{S1,S2,...,Sv},其中Sj包含S中属性A上的值为aj的样本。假设Sj包含类Ci的sij个样本。根据A的这种划分的期望信息称为A的熵。
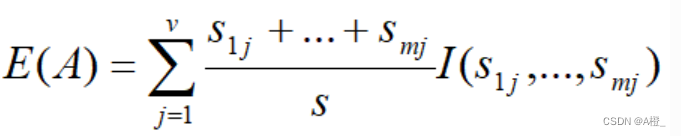
A上该划分的获得的信息增益定义为:

具有高信息增益的属性,是给定集合中具有高区分度的属性。所以可以通过计算S中样本的每个属性的信息增益,来得到一个属性的相关性的排序。就可以识别不相关或者是弱相关的属性,将其排除在概念描述过程外。
包含属性相关分析的类特征化的过程
-
数据收集
-
通过查询处理收集数据库中相关的数据,并将其划分为一个目标类和一个或多个对比类。
-
-
预相关分析
-
识别属性和维的集合
-
对有大量不同值的属性进行删除或概化
-
产生候选关系
-
-
使用选定的相关分析度量删除不相关弱相关的属性
-
使用相关分析度量(信息增益),评估候选关系中的每个属性
-
根据所计算的相关性对属性进行排序
-
低于临界值的不相关和弱相关的属性被删除
-
产生初始目标类工作关系
-
-
产生概念描述
包含属性相关分析的类对比分析的过程
类对比分析的过程如下:
-
数据收集:
通过查询处理收集数据库中相关的数据,并将其划分为一个目标类和一个或多个对比类。
-
维相关分析:
使用属性相关分析方法,使我们的任务中仅包含强相关的维。
-
同步概化
同步的在目标类和对比类上进行概化,得到主目标类关系/方体和主对比类关系/方体。
-
导出比较的表示
用可视化技术表达类比较描述,通常会包含“对比”度量,反映目标类与对比类间的比较。
3.实验过程
使用属性相关分析进行类特征化和类对比分析,使用Python语言完成编程实现。
(1)数据收集
使用给定的数据集进行类特征化和类对比分析,选定三类癌症BLCA,BRCA,KIRC进行分析。其中选定BLCA为目标类,BRCA,KIRC为对比类。这里直接使用原有的三个数据集,不做处理,待进行属性相关分析时再对数据进行需要的处理。
(2)预相关分析
这一步需要对有大量不同值的属性进行删除或概化,而且应尽量保守,保留更多属性用于后续的分析。对于癌症基因数据集,每个属性都是一个基因,要决定哪一个属性可以删除是困难的,一些属性或许可以根据概念分层向上攀升,但是需要对于基因信息具有专业知识才可以完成。例如:观察到一些基因id有相同的前缀,比如CXCL11|6373,CXCL14|9547,经查询资料,CXC是编码趋化因子蛋白质的基序,因此属性或许可以根据概念分层向上攀升(首先要将原数据的值进行一步概化,才能进行向上攀升的概化)。
考虑到数据集中的属性过多,难以删除或合并相等的概化的广义元组,这里不删除或以合并的方式概化任何属性。而是做最基本的概化,即将原数据集中各个基因的值概化为一个等级,划分原数据的范围区分不同等级,这类似于挖掘研究生的一般特征时,对GPA进行概化,根据GPA的分级作为概念分层。
对于数据集中数值的概化使用区间划分的方式进行概化,应该有一个标准,类似于成绩可以是低于60分划分为不及格,大于85分划分为优秀,这个标准应该是根据数据含义进行设置的。在癌症数据集中,这个值应该由了解数据的专业人员进行制定,这里仅为了练习与熟悉类特征化与类对比分析,因此简单的将数据进行等距划分,求出三个数据集中数据的最大值和最小值,划分为等距的区间。这一步比较简单,直接在EXCEL表格中完成,三个癌症类的数据集中最大的数据为4.62,最小为-1.85,划分为6个区间,每个区间长度为1.08。使用python程序完成概化,并保存到文件中。
核心代码如下:
step = 1.08
base_value = -1.86
base_path = "./属性概化结果"
# 对数据进行基本概化,将值概化为不同分级
def generalize(file_path:str):
file_name = os.path.basename(file_path) #文件名
output_path = os.path.join(base_path,file_name) #保存结果
df = pd.read_csv(file_path,index_col="gene_id")
df = pd.DataFrame(df.values.T,index=df.columns,columns=df.index) #进行转置
labels = list(df.columns.values) #gene_id
for index,row in df.iterrows():
for gene_id in labels:
for i in range(0,6):
if row[gene_id]>base_value+i*step and row[gene_id]<base_value+(i+1)*step:
row[gene_id] = i
break
df.to_csv(output_path)得到的结果形式如下:
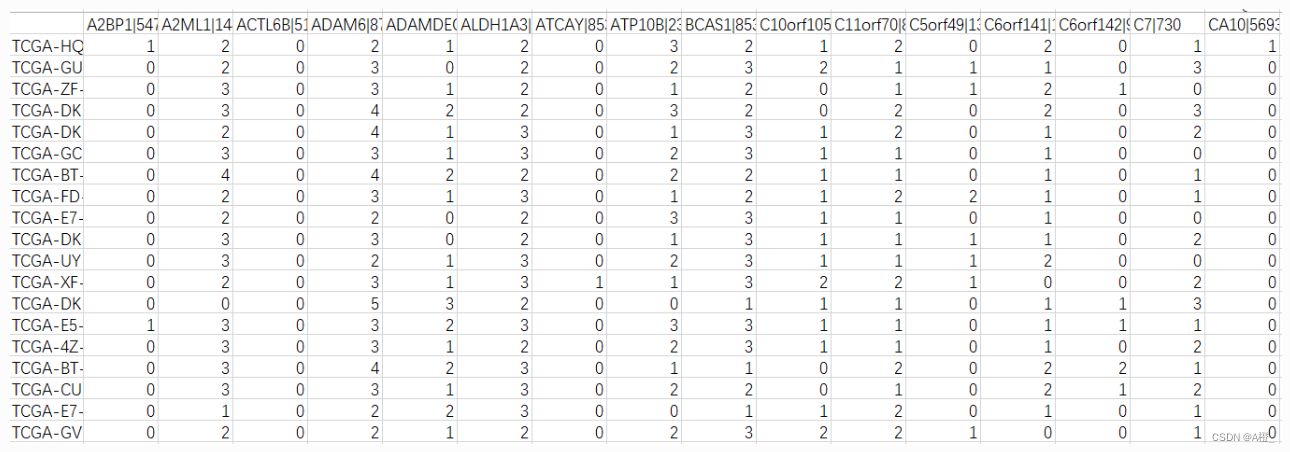
(3)基于信息增益的属性相关分析
完成了以上的属性概化后,计算每个属性的信息增益,去掉不相关或若相关的属性。
为了方便计算信息增益,先对概化后的数据进行统计,对每个基因不同的划分值的样本个数进行统计:
base_path = "./类特征化与对比分析数据"
def pre(file_path):
file_name = os.path.basename(file_path)
output_path = os.path.join(base_path,file_name)
df = pd.read_csv(file_path,index_col=0)
labels = list(df.columns.values)
data = {}
for gene_id in labels:
data[gene_id] = [0,0,0,0,0,0]
for index,row in df.iterrows():
for gene_id in labels:
data[gene_id][int(row[gene_id])] +=1
newdf = pd.DataFrame(data)
newdf.to_csv(output_path)
def main():
# 数据统计
pre("./属性概化数据/BLCArna.csv")
pre("./属性概化数据/BRCArna.csv")
pre("./属性概化数据/KIRCrna.csv")进行以上的统计后,统计数据形式如下:

分类一个给定样本的期望信息计算如下:
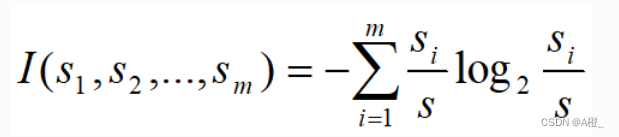
假设计算基因A进行分类的期望信息,一共有三个类,则s1,s2,s3为三个类在基因A上的样本数。计算如下:
# 计算分类一个给定样本的期望信息
def I(s:list)->float:
sum_s = 0
res_I = 0.0
for si in s:
sum_s += s
for si in s:
if si>0:
res_I += -(si/sum_s * math.log(si/sum_s,2))
return res_I如果样本根据基因A划分为v个子集,则计算给定的样本进行分类所需的期望信息(A的熵):
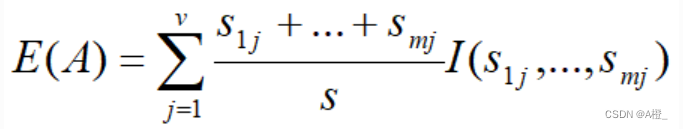
A上该划分的获得的信息增益为:
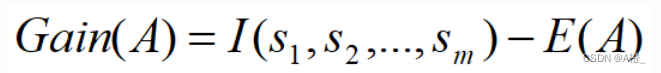
为方便数据处理,将E(A)的计算包含在Gain(A)的计算当中,完整的计算实现如下:
def main():
# 数据统计
pre("./属性概化数据/BLCArna.csv")
pre("./属性概化数据/BRCArna.csv")
pre("./属性概化数据/KIRCrna.csv")
df1 = pd.read_csv("./类特征化与对比分析数据/BLCArna.csv",index_col=0)
df2 = pd.read_csv("./类特征化与对比分析数据/BRCArna.csv",index_col=0)
df3 = pd.read_csv("./类特征化与对比分析数据/KIRCrna.csv",index_col=0)
result_path = "./类特征化与对比分析数据/Gain.csv"
# 计算每个属性的信息增益
labels = list(df1.columns.values) # 取出gene_id,接下来计算每个gene_id的信息增益
result = {}
for gene_id in labels:
gain = 0
# 先计算I(s1,s2,s3)
s = [0,0,0]
for i in range(6):
s[0] += df1[gene_id][i]
s[1] += df2[gene_id][i]
s[2] += df3[gene_id][i]
I_s = I(s) # 该基因整体对样本分类的期望信息
sum_s = s[0]+s[1]+s[2] # 该基因样本总数
# 计算E(gene_id)
E = 0
for i in range(6):
s1i = df1[gene_id][i]
s2i = df2[gene_id][i]
s3i = df3[gene_id][i]
silist = [s1i,s2i,s3i]
E += I(silist) * ((s1i+s2i+s3i)/sum_s) # 基因不同子集对样本分类的期望信息加权和即为属性的熵
gain = I_s - E # 该基因的信息增益
result[gene_id] = gain
resultdf = pd.DataFrame(result,index=["gain"])
# 转置,行为基因,列为信息增益
resultdf = pd.DataFrame(resultdf.values.T,index=resultdf.columns,columns=resultdf.index)
# 按信息增益从小到大排序
resultdf=resultdf.sort_values(by='gain',axis=0,ascending=True)
resultdf.to_csv(result_path)计算完成后的信息增益如下:
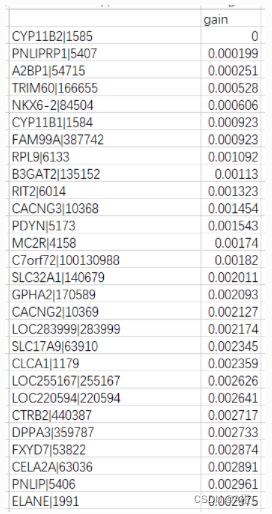
得到了各个属性的信息增益,就可以根据信息增益删除不相关和弱相关的属性了。对于不相关和弱相关的临界值的设定,如果属性总数较少,可以将这个临界值取小一些,保留较多的属性;如果像本数据集中,属性非常多,可能就需要将临界值取大一些,将大量弱相关的属性删除,尽可能保留强相关的属性。
绘制一个简单的密度图观察属性的信息增益情况:
df = pd.read_csv("./类特征化与对比分析数据./gain.csv",index_col=0)
df.plot.kde()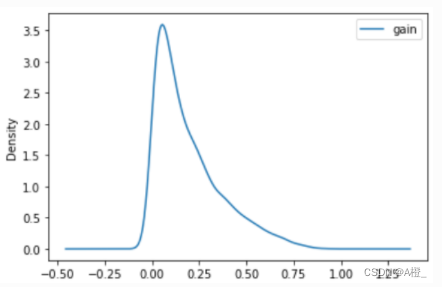
可以观察到绝大多数属性的信息增益都很小,小于0.25,因此实际上临界值取0.25就可以去掉大部分的弱相关和无关属性。由于该数据集本身的维度非常大,属性非常多,去掉弱相关和无关属性后仍有许多属性,在下面进行对比分析时,仅对强相关的属性进行比较分析,因此这里就不取具体的临界值进行属性删除了。
(4)特征化和对比分析
完成上述的属性概化和属性相关分析之后,就可以进行最后的特征化和对比分析了。可以采用量化规则,使用t_weight表示主概化关系中元组的典型性。
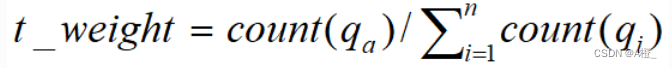
仅使用在属性相关分析中,信息增益最大的3个属性导出概化的表示和导出比较的表示。
result_path = "./类特征化与对比分析数据/characterize_discriminate.csv"
def main():
df = pd.read_csv("./类特征化与对比分析数据./gain.csv",index_col=0)
# 取信息增益最高的3个属性
gene_id = list(df.index[-3:-1])
gene_id.append(df.index[-1])
# 导出概化和比较的表示
data_count("./属性概化数据/BLCArna.csv",gene_id)
data_count("./属性概化数据/BRCArna.csv",gene_id)
data_count("./属性概化数据/KIRCrna.csv",gene_id)
def data_count(file_name,gene_id):
# 导出概化的表示
df = pd.read_csv(file_name,index_col=0)
# 原数据只保留指定的属性,然后进行count,这里只保留3个强相关属性
df = df[gene_id]
count = {}
total = len(df)
cols = gene_id.copy()
cols.append('count') # 保存count列
newdf = pd.DataFrame(columns=cols) # 结果
for row in df.iterrows():
item = tuple(row[1][gene_id]) # item即为这三个属性的一种取值组合
if item not in count:
count[item] = 1
else:
count[item] += 1
for key,value in count.items(): # 保存结果到文件
n_row = list(key)
n_row.append("%.2f%%" % (round(value/total,4)*100))
newdf.loc[len(newdf)] = n_row
newdf.to_csv(result_path,index = False, mode = 'a')导出结果如下,从上到下为BLCA,BRCA,KIRC的概化表示结果:
目标类BLCA的主概化结果:
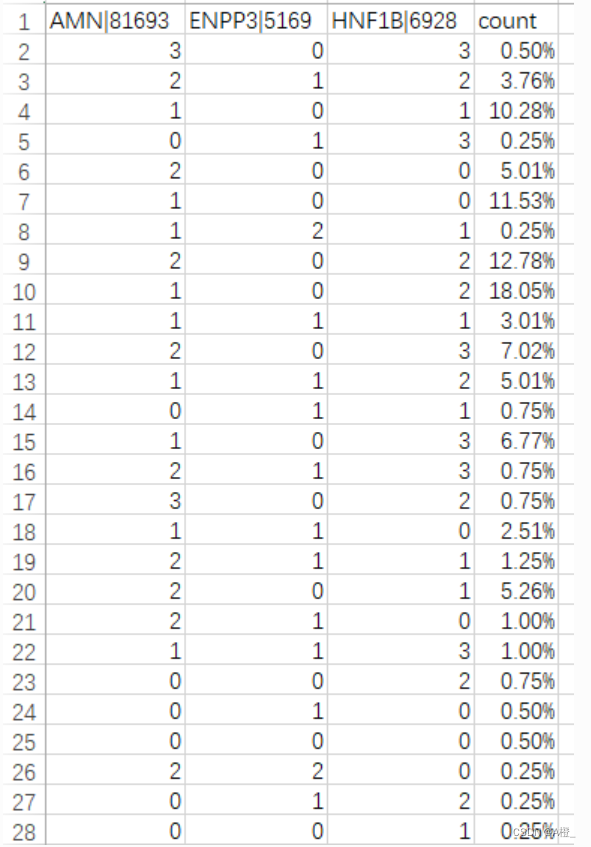
类比较描述中的目标类和对比类的区分特性也可以用量化规则来表示,即量化区分规则:
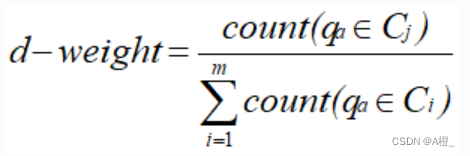
这和类特征化中计算t_weight的方式类似,只是计算初始目标类工作关系中的一种元组和目标类和对比类工作关系中这种元组的总元组数的比。实现如下:
def d_weight(gene_id):
# 计算d_weight,需要用到三个数据集中的数据
df1 = pd.read_csv("./属性概化数据/BLCArna.csv",index_col=0)
df2 = pd.read_csv("./属性概化数据/BRCArna.csv",index_col=0)
df3 = pd.read_csv("./属性概化数据/KIRCrna.csv",index_col=0)
# 保留指定属性
df1 = df1[gene_id]
df2 = df2[gene_id]
df3 = df3[gene_id]
count = {}
# 这里和特征化的过程是类似的,但是需要注意count的含义不同了,计算的是d_weight,此外结果还有一列为类型
cols = gene_id.copy()
cols.append('count') # count列
cols.insert(0,'type') # 增加一个类型列
newdf = pd.DataFrame(columns=cols)
# 计算d_weight,先各个类的概化元组数
for row in df1.iterrows():
item = tuple(row[1][gene_id])
if item not in count:
count[item] = [1,0,0] # 三个值表示目标类,两个对比类的该种元组数
else:
count[item][1] += 1
for row in df2.iterrows():
item = tuple(row[1][gene_id])
if item not in count:
count[item] = [0,1,0] # 对比类的概化元组
else:
count[item][1] += 1
for row in df3.iterrows():
item = tuple(row[1][gene_id])
if item not in count:
count[item] = [0,0,1]
else:
count[item][2] += 1
# 计算d_weight
for key,value in count.items(): # 保存结果到文件
n_row = list(key)
sum_num = value[0]+value[1]+value[2] # 总元组数
n_row1 = n_row.copy()
n_row2 = n_row.copy()
n_row3 = n_row.copy()
n_row1.append("%.2f%%" % (round(value[0]/sum_num,4)*100))
n_row2.append("%.2f%%" % (round(value[1]/sum_num,4)*100))
n_row3.append("%.2f%%" % (round(value[2]/sum_num,4)*100))
n_row1.insert(0,"BLCA")
n_row2.insert(0,"BRCA")
n_row3.insert(0,"KIRC")
newdf.loc[len(newdf)] = n_row1
newdf.loc[len(newdf)] = n_row2
newdf.loc[len(newdf)] = n_row3
newdf.to_csv("./类特征化与对比分析数据/d_weight.csv",index = False)结果形式如下:
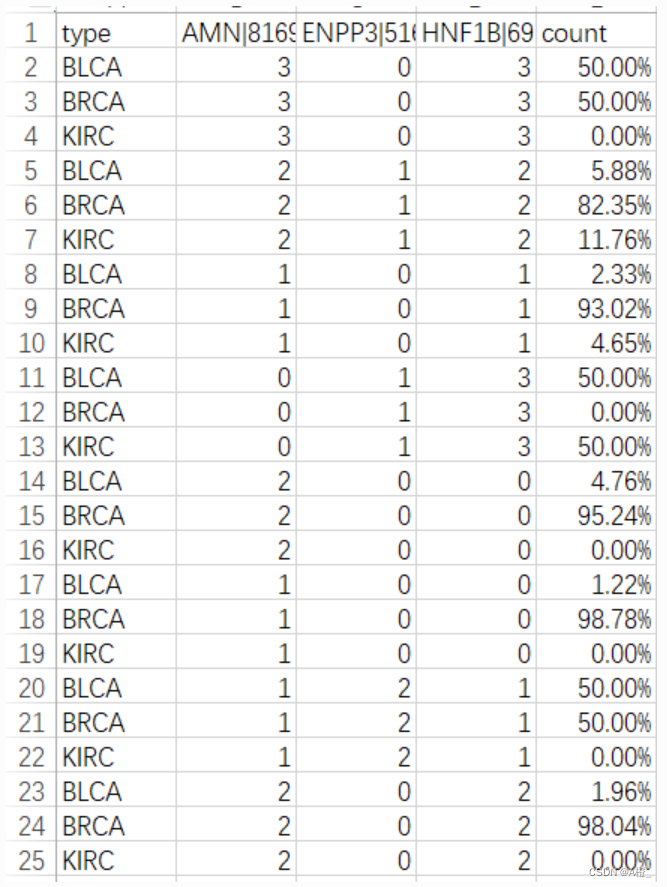
较高的count(即d_weight)值表示概化元组代表的概念主要来自于目标类。但最终的结果集中,目标类BLCA的d_weight值没有很高,反而是对比类BRCA和KIRC在很多概化元组上的d_weight接近100%,这可能意味着对比类的特征更加明显。
4.实验结果分析
对于特征化分析中的结果,目标类BLCA的特征似乎并不明显,概化元组的t_weight普遍比较低。而对比类BRCA和KIRC两类中,有一些t_weight值很高,例如BRCA在这三个属性上的等级为0,1,0(0对应原数据-1.85~-0.77,1对应原数据-0.77~0.31)的样本占了总样本的60%,可以认为是该类的重要特征。最后使用量化区分规则进行类对比分析时与类特征化时类似,目标类的d_weight不大,而对比类在一些概化元组上有显著的d_weight,这些概化元组可以明显的将目标类与对比类区分开。
处理过程中的一些简化对结果可能存在影响,例如属性概化时对值进行了区间划分,这个划分直接对最大值最小值之间进行等值划分,实际上可能刚好将体现特征的范围划分为了两部分,导致了结果不准确。
三.实验总结
通过本次实验,加深了对主成分分析,概念描述的类特征化和类对比分析的理解,并且进行了实现。第一题的主要问题为基因个数过多,远大于样本量,主成分分析的结果仍然很大,不确定如果样本充足,是否主成分分析的结果更好。主成分分析后对于结果该如何进行处理或分析还不了解。第二题主要是实现类特征化和类对比分析,最重要的部分是属性相关分析。在实现过程中主要是学习和尝试分析的方法和步骤,许多处理都简化且存在不合理,例如预处理进行属性概化时对值的区间划分,最后也只使用了根据计算信息增益得到的三个强相关的属性进行类特征化和类对比分析。尽管仍然存在许多问题(过程本身的问题,缺少对数据可视化展示的技巧等),但通过实验较为完整的完成了分析过程,理解了主成分分析,类特征化与类对比分析的目的和步骤。
智能推荐
稀疏编码的数学基础与理论分析-程序员宅基地
文章浏览阅读290次,点赞8次,收藏10次。1.背景介绍稀疏编码是一种用于处理稀疏数据的编码技术,其主要应用于信息传输、存储和处理等领域。稀疏数据是指数据中大部分元素为零或近似于零的数据,例如文本、图像、音频、视频等。稀疏编码的核心思想是将稀疏数据表示为非零元素和它们对应的位置信息,从而减少存储空间和计算复杂度。稀疏编码的研究起源于1990年代,随着大数据时代的到来,稀疏编码技术的应用范围和影响力不断扩大。目前,稀疏编码已经成为计算...
EasyGBS国标流媒体服务器GB28181国标方案安装使用文档-程序员宅基地
文章浏览阅读217次。EasyGBS - GB28181 国标方案安装使用文档下载安装包下载,正式使用需商业授权, 功能一致在线演示在线API架构图EasySIPCMSSIP 中心信令服务, 单节点, 自带一个 Redis Server, 随 EasySIPCMS 自启动, 不需要手动运行EasySIPSMSSIP 流媒体服务, 根..._easygbs-windows-2.6.0-23042316使用文档
【Web】记录巅峰极客2023 BabyURL题目复现——Jackson原生链_原生jackson 反序列化链子-程序员宅基地
文章浏览阅读1.2k次,点赞27次,收藏7次。2023巅峰极客 BabyURL之前AliyunCTF Bypassit I这题考查了这样一条链子:其实就是Jackson的原生反序列化利用今天复现的这题也是大同小异,一起来整一下。_原生jackson 反序列化链子
一文搞懂SpringCloud,详解干货,做好笔记_spring cloud-程序员宅基地
文章浏览阅读734次,点赞9次,收藏7次。微服务架构简单的说就是将单体应用进一步拆分,拆分成更小的服务,每个服务都是一个可以独立运行的项目。这么多小服务,如何管理他们?(服务治理 注册中心[服务注册 发现 剔除])这么多小服务,他们之间如何通讯?这么多小服务,客户端怎么访问他们?(网关)这么多小服务,一旦出现问题了,应该如何自处理?(容错)这么多小服务,一旦出现问题了,应该如何排错?(链路追踪)对于上面的问题,是任何一个微服务设计者都不能绕过去的,因此大部分的微服务产品都针对每一个问题提供了相应的组件来解决它们。_spring cloud
Js实现图片点击切换与轮播-程序员宅基地
文章浏览阅读5.9k次,点赞6次,收藏20次。Js实现图片点击切换与轮播图片点击切换<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title></title> <script type="text/ja..._点击图片进行轮播图切换
tensorflow-gpu版本安装教程(过程详细)_tensorflow gpu版本安装-程序员宅基地
文章浏览阅读10w+次,点赞245次,收藏1.5k次。在开始安装前,如果你的电脑装过tensorflow,请先把他们卸载干净,包括依赖的包(tensorflow-estimator、tensorboard、tensorflow、keras-applications、keras-preprocessing),不然后续安装了tensorflow-gpu可能会出现找不到cuda的问题。cuda、cudnn。..._tensorflow gpu版本安装
随便推点
物联网时代 权限滥用漏洞的攻击及防御-程序员宅基地
文章浏览阅读243次。0x00 简介权限滥用漏洞一般归类于逻辑问题,是指服务端功能开放过多或权限限制不严格,导致攻击者可以通过直接或间接调用的方式达到攻击效果。随着物联网时代的到来,这种漏洞已经屡见不鲜,各种漏洞组合利用也是千奇百怪、五花八门,这里总结漏洞是为了更好地应对和预防,如有不妥之处还请业内人士多多指教。0x01 背景2014年4月,在比特币飞涨的时代某网站曾经..._使用物联网漏洞的使用者
Visual Odometry and Depth Calculation--Epipolar Geometry--Direct Method--PnP_normalized plane coordinates-程序员宅基地
文章浏览阅读786次。A. Epipolar geometry and triangulationThe epipolar geometry mainly adopts the feature point method, such as SIFT, SURF and ORB, etc. to obtain the feature points corresponding to two frames of images. As shown in Figure 1, let the first image be and th_normalized plane coordinates
开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先抽取关系)_语义角色增强的关系抽取-程序员宅基地
文章浏览阅读708次,点赞2次,收藏3次。开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先关系再实体)一.第二代开放信息抽取系统背景 第一代开放信息抽取系统(Open Information Extraction, OIE, learning-based, 自学习, 先抽取实体)通常抽取大量冗余信息,为了消除这些冗余信息,诞生了第二代开放信息抽取系统。二.第二代开放信息抽取系统历史第二代开放信息抽取系统着眼于解决第一代系统的三大问题: 大量非信息性提取(即省略关键信息的提取)、_语义角色增强的关系抽取
10个顶尖响应式HTML5网页_html欢迎页面-程序员宅基地
文章浏览阅读1.1w次,点赞6次,收藏51次。快速完成网页设计,10个顶尖响应式HTML5网页模板助你一臂之力为了寻找一个优质的网页模板,网页设计师和开发者往往可能会花上大半天的时间。不过幸运的是,现在的网页设计师和开发人员已经开始共享HTML5,Bootstrap和CSS3中的免费网页模板资源。鉴于网站模板的灵活性和强大的功能,现在广大设计师和开发者对html5网站的实际需求日益增长。为了造福大众,Mockplus的小伙伴整理了2018年最..._html欢迎页面
计算机二级 考试科目,2018全国计算机等级考试调整,一、二级都增加了考试科目...-程序员宅基地
文章浏览阅读282次。原标题:2018全国计算机等级考试调整,一、二级都增加了考试科目全国计算机等级考试将于9月15-17日举行。在备考的最后冲刺阶段,小编为大家整理了今年新公布的全国计算机等级考试调整方案,希望对备考的小伙伴有所帮助,快随小编往下看吧!从2018年3月开始,全国计算机等级考试实施2018版考试大纲,并按新体系开考各个考试级别。具体调整内容如下:一、考试级别及科目1.一级新增“网络安全素质教育”科目(代..._计算机二级增报科目什么意思
conan简单使用_apt install conan-程序员宅基地
文章浏览阅读240次。conan简单使用。_apt install conan