MySQL搭建主从复制集群,实现读写分离_创建mysql集群,主从复制,读写分离,实现一主两从-程序员宅基地
技术标签: Java java mysql 编程环境安装 数据库
目录
一、准备
准备两台服务器,为每台都安装好mysql。
此时的两台服务器它们的mysql之间没有半毛钱关系,各自是独立的。
如果不会安装,后续我也会出一篇安装教程。请关注我的【编程环境安装】专栏。
二、配置
2.1 配置主库
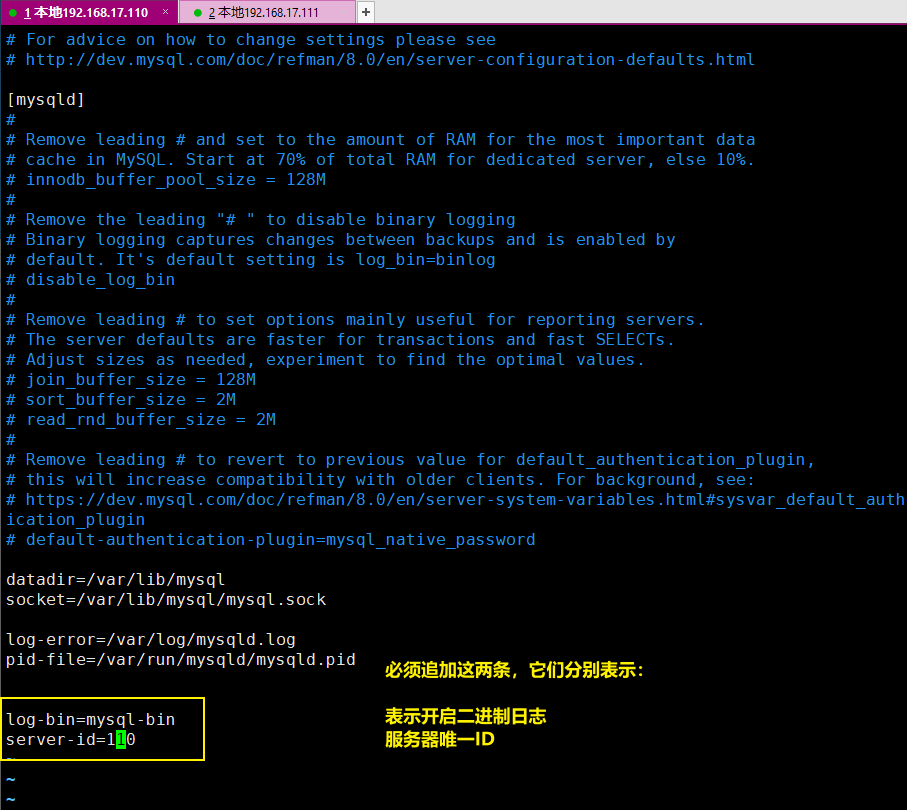
修改配置文件/etc/my.cnf
追加如下:
[mysqld]
log-bin=mysql-bin
server-id=110以后在进行增删改操作的时候,它都会进行记录日志。
重启服务
systemctl restart mysqld
为主库再创建一个账户并授权
CREATE USER '主库用户名'@'%' IDENTIFIED BY '主库用户名密码';
GRANT REPLICATION SLAVE ON *.* TO '主库名称'@'%';
ALTER USER '主库用户名'@'%' IDENDIFIED WITH mysql_native_password BY '主库用户名密码';
flush privileges;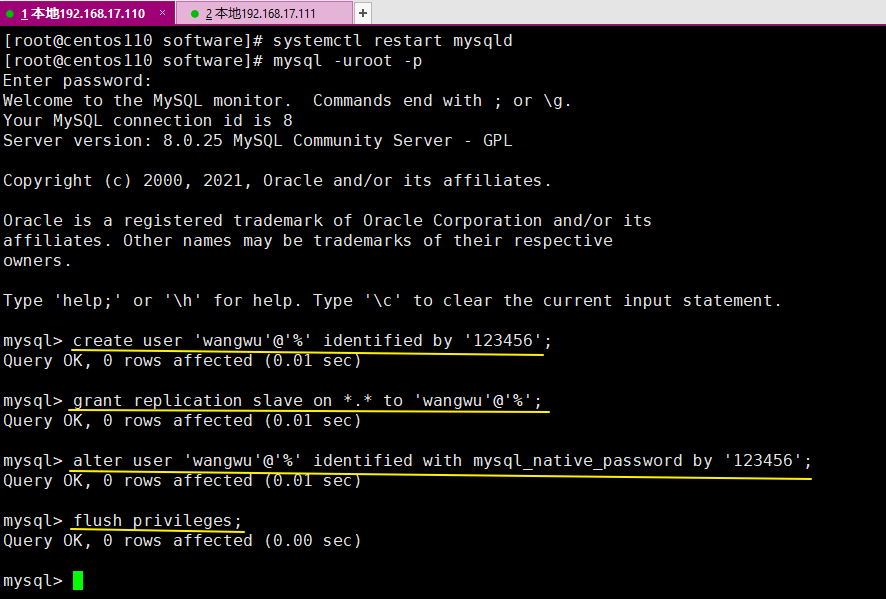
这一步是为主库创建一个用户,并为这个用户授予复制从库的权限。
查看状态
我们先记住这个File和Position的值

记得现在就不要再在主库操作了,否则这个位置就会发生变化。
2.2 配置从库
修改配置文件/etc/my.cnf
增加配置:服务器的唯一标识
server-id=111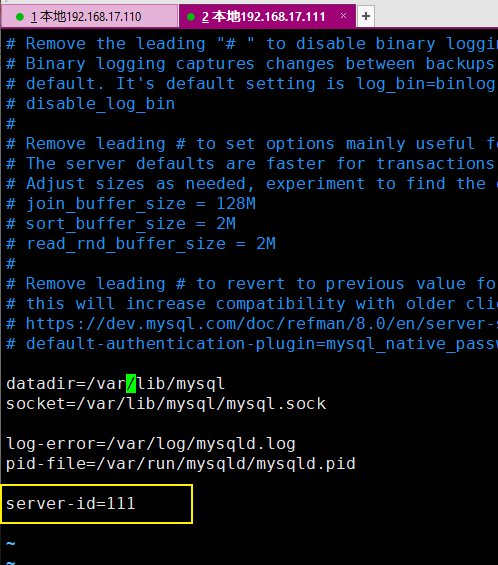
重启mysql服务
systemctl restart mysqld
配置需要同步的主机
CHANGE MASTER TO
MASTER_HOST='主机的ip地址',
MASTER_USER='主机刚才创建的用户名',
MASTER_PASSWORD='主机用户名的密码',
MASTER_LOG_FILE='主机上记录的File值',
MASTER_LOG_POS=主机上记录的Position值;
启动salve同步
start slave; 查看是否同步
查看是否同步
show slave status;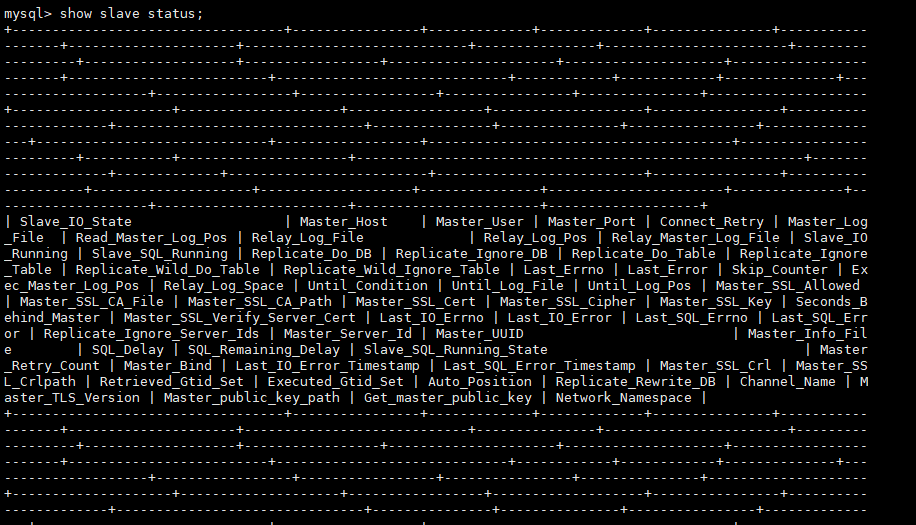 很乱啊,我们把它复制到文本编辑器上来看看
很乱啊,我们把它复制到文本编辑器上来看看

至此,主从复制集群就搭建完成了!
三、测试主从复制是否生效
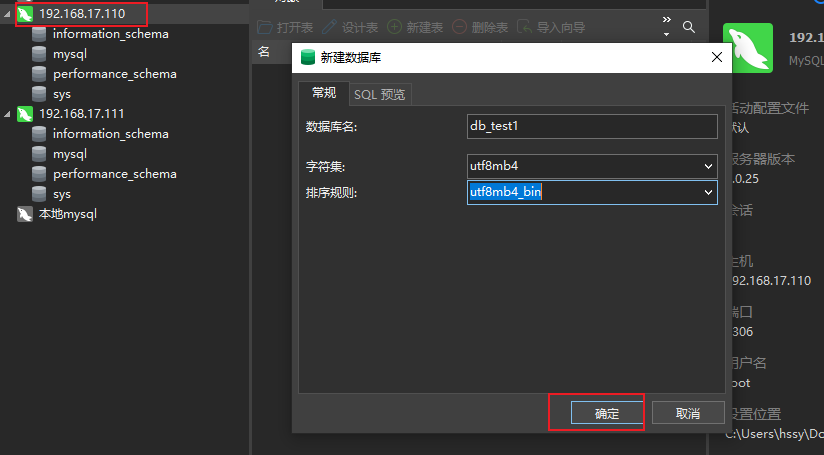
我们通过navicat连接上这两个数据库,通过操作看看,它们的变化。
在主库创建一个数据库。

四、读写分离案例
4.1 背景
如果系统的访问量增大,既要查询又要写入,单台数据库已经不能满足访问压力了。
这个时候就可以考虑主从复制。将数据库拆分成主库和从库。主库主要负责处理事务性的增删改操作,从库负责处理查询操作。
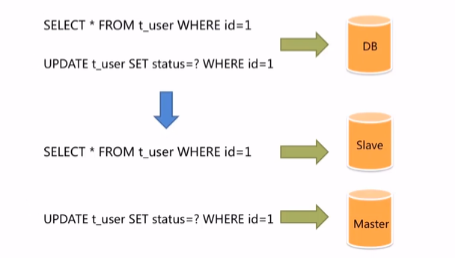
但是我们的系统怎么知道,我们的操作是查询操作,还是增删改操作?又怎么根据操作的类型选择主库还是从库呢?
这个时候就用到了Sharding-JDBC!
4.2 Sharding-JDBC介绍
Sharding-JDBC定位为轻量级的Java框架,在Java的jdbc层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可以理解为增强版的jdbc驱动,完全兼容jdbc和各种orm框架。
-
适用于任何基于JDBC的ORM框架,如:JPA,Hibernate,Mybatis,Spring JDBC Template或直接使用JDBC。
-
支持任何第三方的数据库连接池,如:DBCP,C3P0,Druid,HikariCP等。
-
支持任意实现JDBC规范的数据库。目前支持Mysql,Oracle,SQL server,PostgreSQL以及任何遵顼SQL92标准的数据库。
4.3 项目测试前期准备
在使用分库分表之前,先要搭建好主从复制的数据库。
然后我们先创建一个web项目:
数据库准备
CREATE TABLE `user` (
`id` int unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '姓名',
`age` tinyint DEFAULT NULL COMMENT '年龄',
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '住址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='用户'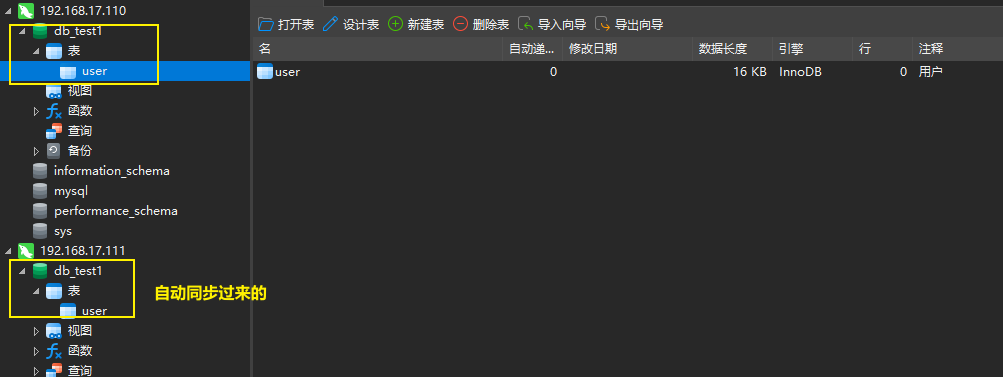
导入依赖
作为web项目基本的一些依赖,没什么好讲的。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.12</version>
</dependency>配置文件
目前只配置了端口号和mybatisplus的相关配置
连数据源连接我们都没有配置,这是因为后面要使用sharding-jdbc
server.port=8080
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
mybatis-plus.global-config.db-config.logic-delete-value=1
mybatis-plus.global-config.db-config.logic-not-delete-value=0
mybatis-plus.configuration.map-underscore-to-camel-case=true
mybatis-plus.global-config.db-config.id-type=assign_id代码生成器
使用代码生成器,快速生成刚才创建的表的controller、entity、service、mapper等文件。
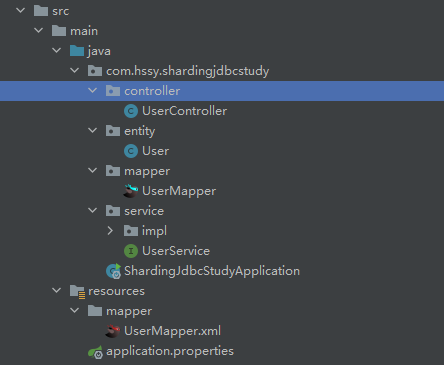
这些做好以后,下面开始使用到sharding-jdbc!
添加依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>添加配置文件规则
# 定义数据源的名字,有几个填写几个,通过.隔开,名字随便取,但是后面配置主从数据源需要根据此名字进行设置
spring.shardingsphere.datasource.names=master-haha,slave-haha
# 数据源1
spring.shardingsphere.datasource.master-haha.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master-haha.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.master-haha.url=jdbc:mysql://192.168.17.110:3306/db_test1?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.master-haha.username=root
spring.shardingsphere.datasource.master-haha.password=123456
# 数据源2
spring.shardingsphere.datasource.slave-haha.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.slave-haha.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave-haha.url=jdbc:mysql://192.168.17.111:3306/db_test1?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.slave-haha.username=root
spring.shardingsphere.datasource.slave-haha.password=123456
# 配置从库负载均衡策略:轮询。就是说从库实际不一定只有一台,当每次查询操作进来的时候,轮询去查每台从库。
spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin
# 设置最终数据源的名称 其实就是spring中bean对象的名称
spring.shardingsphere.masterslave.name=dataSource
# 指定主库数据源名称
spring.shardingsphere.masterslave.master-data-source-name=master-haha
# 指定从库数据源名称 从库如果有多个,通过逗号隔开
spring.shardingsphere.masterslave.slave-data-source-names=slave-haha
# 开启控制台的sql显示,默认是false
spring.shardingsphere.props.sql.show=true以上规则定义好了,它查询就会去从库(每台从库轮询查),增删改去主库。
但是,最后还需要修改一下spring的bean覆盖策略,默认是不允许同名bean的。
为什么要修改呢?因为我们定义的bean的名称和druid中定义的bean的名字重复了。
而spring中默认不允许同名的bean的。
所以需要在配置文件中再加上一段配置
# 允许bean定义覆盖,后创建的bean会覆盖前面的同名bean对象
spring.main.allow-bean-definition-overriding=true否则启动项目会报错
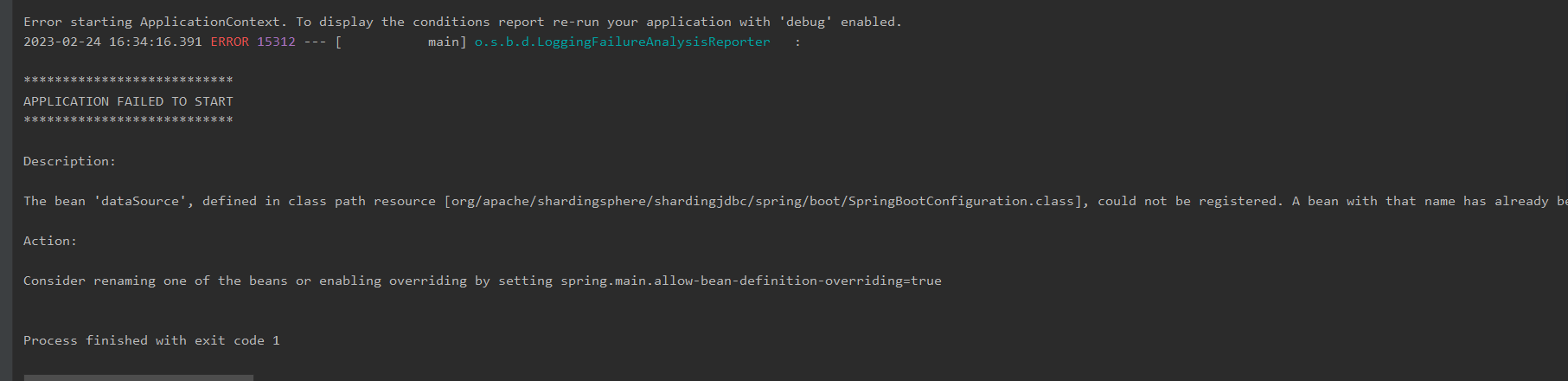 ok,下面我们创建一些测试方法来验证一下。
ok,下面我们创建一些测试方法来验证一下。
4.4 验证
创建测试方法,包含增删改查
注意这里引入了一个DataSource对象,虽然实际业务代码并没有使用到,但是我们只是想看看它到底是谁。
@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {
@Autowired
private DataSource dataSource;
@Autowired
private UserService userService;
@PostMapping
public User save(User user){
userService.save(user);
return user;
}
@DeleteMapping("/{id}")
public void delete(@PathVariable Long id){
userService.removeById(id);
}
@PutMapping
public User update(User user){
userService.updateById(user);
return user;
}
@GetMapping("/{id}")
public User getById(@PathVariable Long id){
User user = userService.getById(id);
return user;
}
@GetMapping("/list")
public List<User> list(User user){
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(user.getId() != null,User::getId,user.getId());
queryWrapper.eq(user.getName() != null,User::getName,user.getName());
List<User> list = userService.list(queryWrapper);
return list;
}
}打上断点,以DEBUG的方式启动
断点的位置我们如图
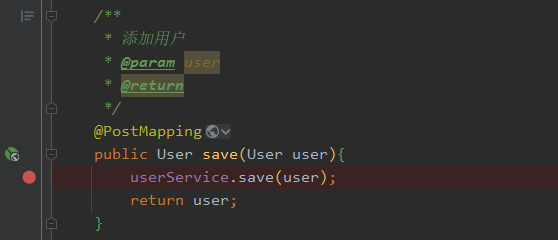
发送请求测试
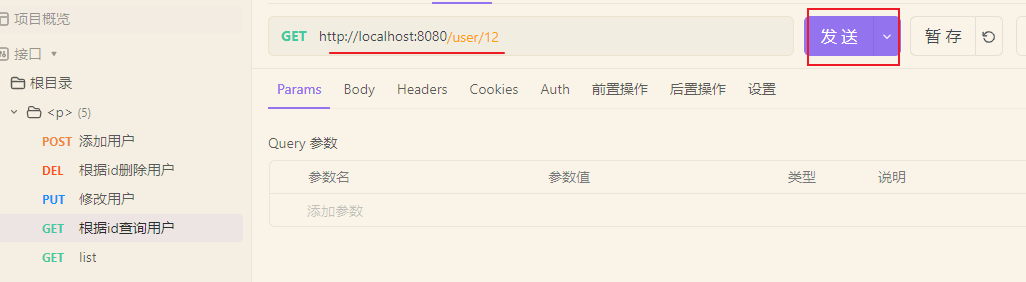
我们可以通过postman来发送请求试试,我这里使用apifox来测试。
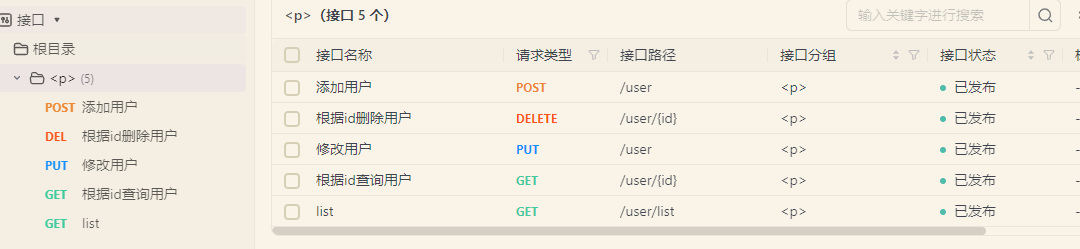
先来查询一下
我们发现这个datasource是shardingjdbc提供的

接着放行该请求
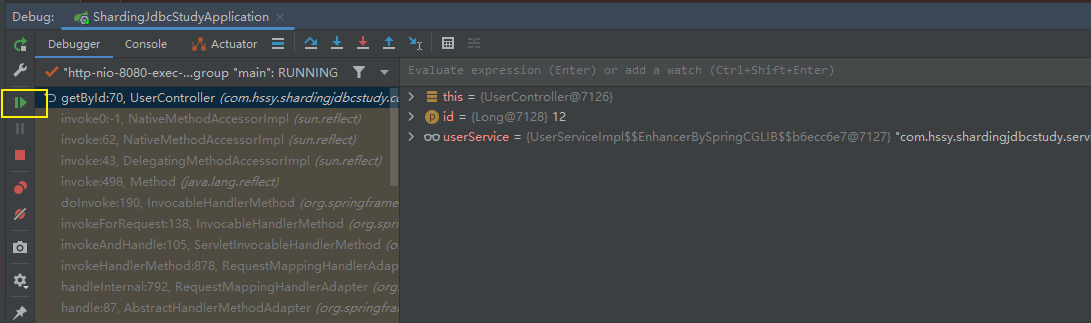
我们通过控制台看到,这条sql是从库去查询的!
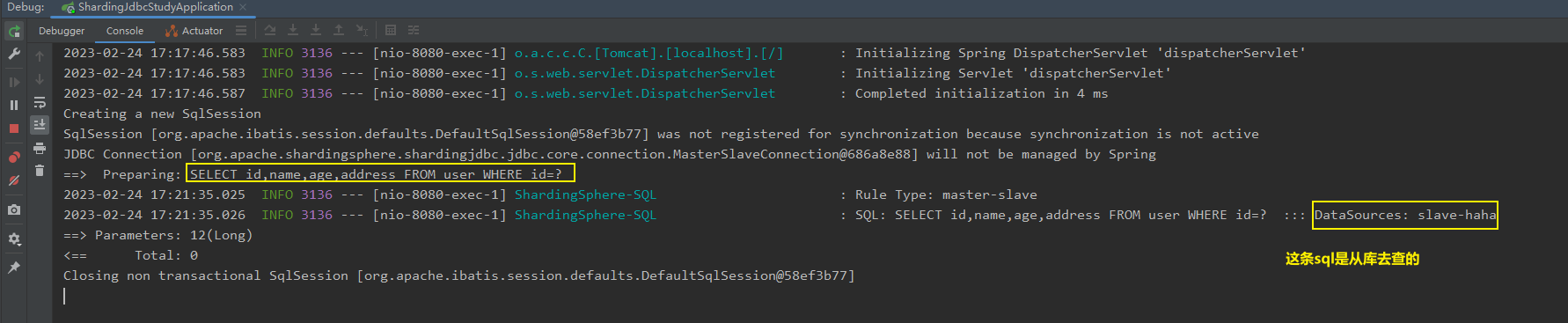
ok,再发送添加请求试试。
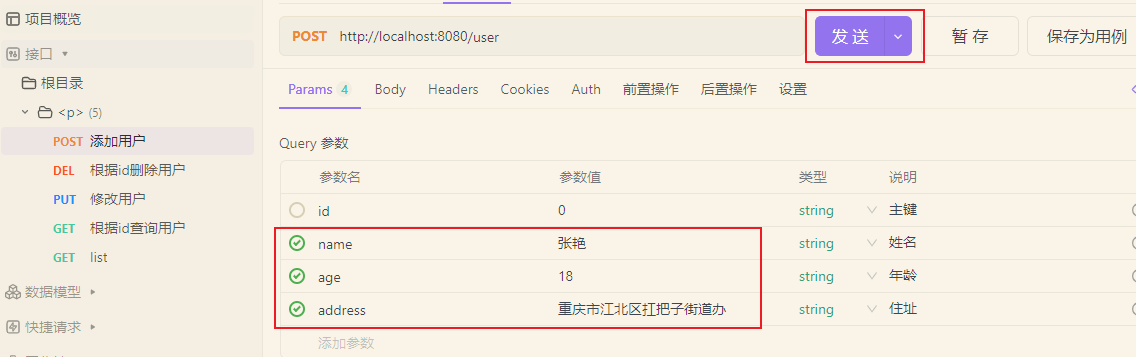
我们直接放行,发现添加操作是主库执行的。
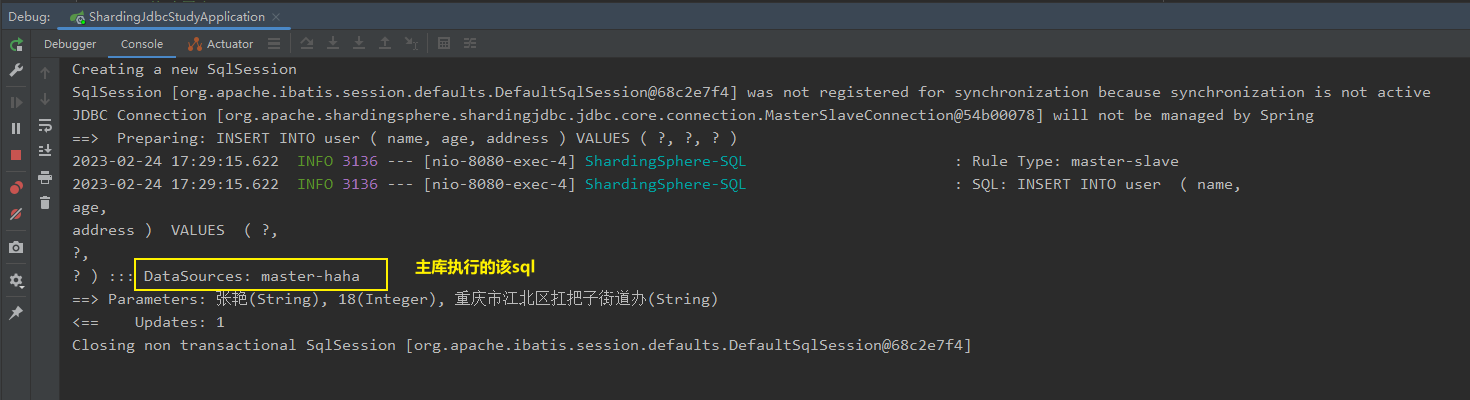
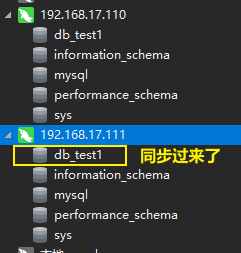
ok,下面我们再检查一下数据库

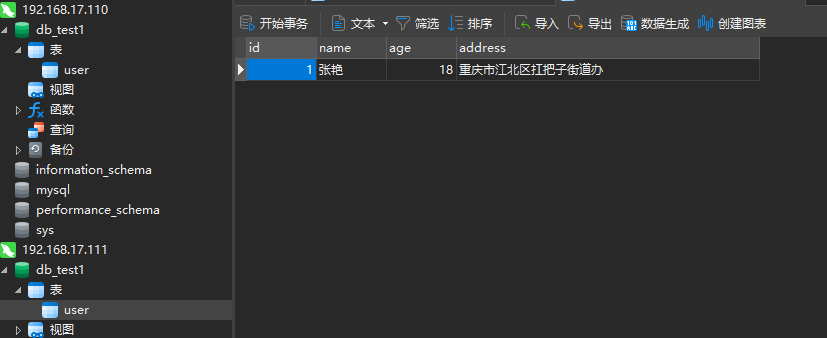
ok,主库也同步到了从库了。
五、主从复制数据不同步的问题
案例:误操作向从库添加了数据。
我通过navicat向从库的user表中生成假数据1w条,这肯定不会同步到主库的。
因为是主库写,从库读。不能乱来。
这就导致从库出现问题。我们通过show slave status;命令查看从库是否同步,发现sql转储线程停掉了。那肯定就不能继续同步数据了。
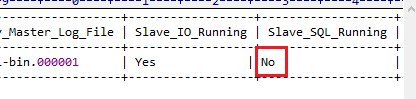
这个时候解决办法就是重新同步。具体方法时间关系就不再赘述了。附上思维导图:
MySQL主从复制那些事儿| ProcessOn免费在线作图,在线流程图,在线思维导图
文章花费了我大量心血和时间,
吃水不忘挖井人,如果对你有帮助,别忘了三连,点赞收藏评论 ~
智能推荐
Yolov1 + Yolov2 + Yolov3 发展史、论文、代码最全资源分享合集 ! ! !_yolov用什么语言-程序员宅基地
文章浏览阅读1.8k次,点赞4次,收藏36次。点击上方“码农的后花园”,选择“星标”公众号 精选文章,第一时间送达YOLO之父Jeseph Redmon毕业于美国米德尔伯里学院计算机科学专业,辅修数学,他主要研究范围是..._yolov用什么语言
离散 Hopfield 神经网络的分类与matlab实现_离散hopfield神经网络 科研能力分类 例子 matlab-程序员宅基地
文章浏览阅读738次。科研能力是高校的核心能力,其高低已成为衡量一所高校综合实力的重要指标。科研能力的高低不仅影响高校自身的发展,对高校所在地区的经济发展也有很大的影响。如何准确评价高校的科研能力已成为摆在政府、企业和高校面前的一个十分重要的问题。影响科研能力的因素众多,且互相交叉,互相渗透和互相影响,无法用确定的数学模型进行描述。目前,高校科研能力评价的方法很多,但普遍存在工作繁琐、时间滞后等缺点,且人为主观因素对评价结果有很大的影响。如何快速,准确地对众多高校的科研能力进行客观、公正地评价?这是一个目前亟待解决的问题。_离散hopfield神经网络 科研能力分类 例子 matlab
VUE移动到指定位置(scrollIntoView)----亲测避坑_scrollintoview的坑-程序员宅基地
文章浏览阅读1.6w次,点赞6次,收藏20次。用(scrollIntoView)来实现移动到指定位置建议不要放在(mt-loadmore)里使用,不然头部会被挤上去----亲测html<div id="pronbit" ref="pronbit">需要移动到的位置</div>js//选中iddocument.getElementById(e).scrollIntoView({ behavior: "sm..._scrollintoview的坑
SyntaxErrorException系列日记一:FUNCTION xxxxxx.xxxxxx does not exist_function test.collection_set does not exist-程序员宅基地
文章浏览阅读4.2k次。错误记录:FUNCTION mytest.CONCATE does not exist 如下:CONCATE是错误的一般应该检查函数是否拼写错误SELECT city_id ,city_name,airport_name,city_code,city_pinyin,city_abbreviation FROM city_airport WHERE 1=1 AND city_function test.collection_set does not exist
设计模式精讲:单例模式-程序员宅基地
文章浏览阅读75次。一个类的静态内部类,在外面的类被加载的时候,它里面的静态的类是不会被加载的,只有当我们调用getInstance方法的时候才会被加载。实际上要加载一个类我们也可以这么来写:Class.forName("类的名字"),只把class放到内存里而不进行实例化,如果我们用这种方式把Mgr01加到内存之后,这个static的INSTANCE是实例化的,因为他是一个静态变量,load到内存就会初始化。这两种方法的缺点就是,实例在类加载时就被创建了,如果应用程序不需要使用该实例,那么就会浪费一定的内存空间。
“OSGeo.GDAL.GdalPINVOKE”的类型初始值设定项引发异常和OSGeo.OGR.Ogr”的类型初始值设定项引发异常-程序员宅基地
文章浏览阅读3.3k次。出现这个的原因大概是:1、32位和64位用错,32位程序用的64位的dll,64位程序使用32位的dll。2、缺少依赖库。3、环境变量配置错误。缺少依赖库首先找到缺少哪些关联库,也可以直接把bin目录下的所有dll拷贝过去查询gdal***.dll的关联动态库:1、找到vs的命令提示符,如图2、输入:dumpbin /dependents c:\…\…\…\gdal***.dll即可看到该dll所关联的dll3、将gadl中能查到的属于上图中关联的dll,和gda_osgeo.gdal.gdalpinvoke”的类型初始值设定项引发异常
随便推点
LaTeX 索引_\usepackage[t1]{fontenc}什么意思-程序员宅基地
文章浏览阅读6.5k次。在大型的文档中,例如书籍等,通常会有一个按字母顺序排列的列表来列出文档中的主要术语。通过 LaTeX 和 imakeidx 包,你可以轻松地在文档中创建索引表。_\usepackage[t1]{fontenc}什么意思
【git】阿里云上传代码到github附SSH-KEY免密码上传&更新github代码到本地-程序员宅基地
文章浏览阅读1k次,点赞25次,收藏20次。由于细节内容实在太多了,为了不影响文章的观赏性,只截出了一部分知识点大致的介绍一下,每个小节点里面都有更细化的内容!小编准备了一份Java进阶学习路线图(Xmind)以及来年金三银四必备的一份《Java面试必备指南》《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》点击传送门即可获取!路线图(Xmind)以及来年金三银四必备的一份《Java面试必备指南》**[外链图片转存中…(img-pLeNWyeQ-1712070767763)]
linux非root用户打开80,Linux非root用户如何使用80端口启动程序-程序员宅基地
文章浏览阅读2.3k次。默认情况下Linux的1024以下端口是只有root用户才有权限占用,我们的tomcat,apache,nginx等等程序如果想要用普通用户来占用80端口的话就会抛出java.net.BindException: Permission denied:80的异常。bind时perror提示错误信息:permission denied解决办法有两种:1.使用非80端口启动程序,然后再用iptables..._80端口必须用root
leetcode有效的括号_(*)扩号leetcode-程序员宅基地
文章浏览阅读184次。package leetcode.有效的括号;import java.util.Stack;/** * 给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。 * <p> * 有效字符串需满足: * <p> * 左括号必须用相同类型的右括号闭合。 * 左括号必须以正确的顺序闭合。 * 注意空字符串可被认为是有效字..._(*)扩号leetcode
SPSS实现单因素方差分析_单因素方差分析的数据格式是怎样的-程序员宅基地
文章浏览阅读4k次,点赞7次,收藏44次。总目录:SPSS学习整理SPSS实现单因素方差分析目的适用情景数据处理SPSS操作SPSS输出结果分析知识点目的检验单因素水平下的一个或多个独立因变量均值是否存在显著性差异,即检验单因素各个水平的均值是否来自同一个总体。(因变量为连续变量)适用情景方差分析前提:各个总体服从正态分布各个总体方差相等观测值独立数据处理SPSS操作SPSS输出结果分析基本信息基于平均值显著性为0.729,大于0.05,认为各组总体方差相等F=8.744,显著性为0.007,小于0._单因素方差分析的数据格式是怎样的
window xp IIS 安装遇到的错误并安装不成功_win xp 0x1009956b-程序员宅基地
文章浏览阅读667次。IIS安装时,安装程序无法复制一个或多个文件。特定错误码是0x4b8 故障现象安装IIS的时候一直提示如下错误,IIS无法正常安装。提示:安装程序无法复制一个或多个文件。特定错误码是 0x4b8。按“确定”以继续;或者按“取消”,停止安装并且再试一次。如果继续,组件可能无法正常运行。解决方案(1) 开始 > 运行 > 输入 CMD >再输入以下命令:esentutl /p %windir_win xp 0x1009956b