Apache Solr7.4 入门教程(二)_solr omit term frequencies & positions-程序员宅基地
四、创建core实例
1. core简介
简单说core就是solr的一个实例,一个solr服务下可以有多个core,每个core下都有自己的索引库和与之相应的配置文件,所以在操作solr创建索引之前要创建一个core,因为索引都存在core下面。
2. core创建
core的创建方式,我列出两种比较方便的。
(1). 以管理进入cmd, 在$SOLR_HOME/bin目录下执行solr create –c <name>,创建一个core执行完后,会在$SOLR_HOME/server/solr 下创建一个 eden_core文件夹。

(2).在AdminUI页面创建一个core。
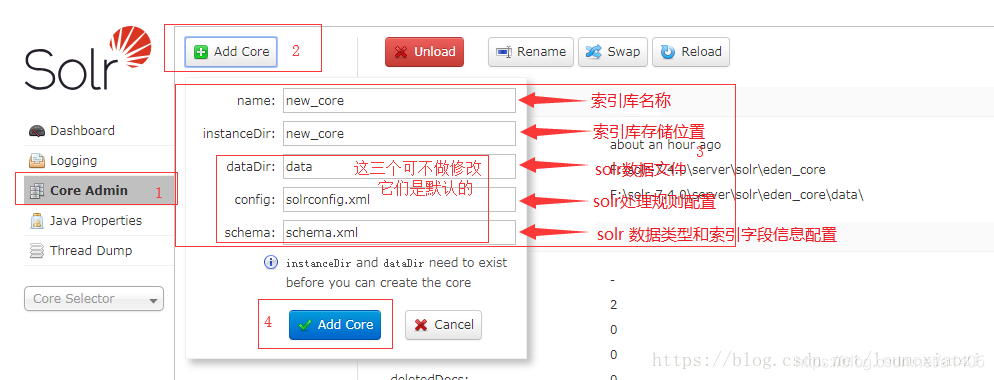
这种需要你提前,准备好 $索引库名/conf/solrconfig.xml,$索引库名/conf/lang/下的一些文件,不然会报如下一系列错误, 所以,我们需要从$SOLR_HOME/solr/configsets/sample_techproducts_configs/conf/ 下拷贝以下文件:
lang/ 下所有文件
managed-schema
solrconfig.xml
synonyms.txt
stopwords.txt
protwords.txt
params.json五、managed-schema(schema.xml)
1. schema简介:
schema是用来告诉solr如何建立索引的,他的配置围绕着一个schema配置文件,这个配置文件决定着solr如何建立索引,每个字段的数据类型,分词方式等,老版本的schema配置文件的名字叫做schema.xml他的配置方式就是手工编辑,但是现在新版本的schema配置文件的名字叫做managed-schema,他的配置方式不再是用手工编辑而是使用schemaAPI来配置,官方给出的解释是使用schemaAPI修改managed-schema内容后不需要重新加载core或者重启solr更适合在生产环境下维护,如果使用手工编辑的方式更改配置不进行重加载core有可能会造成配置丢失,配置文件所在的路径如下:$SOLR_HOME/server/solr/eden_core/conf/managed-schema
2. schema 主要成员
<schema>
<field/>
<dynamicField/>
<uniqueKey/>
<fieldType>
<analyzer>
<tokenizer/>
<filter/>
</analyzer>
</fieldType/>
<copyField/>
<dynamicField>
</schema>2.1 field
属性 默认值 说明
name 必须,不能取名score,前后辍为下划线的名字(如:_VERSION_)为保留名字
type 必须,值为定义的<fieldType>
indexed true 是否进行索引。 true的时候进行索引
stored true 是否存储。如果此字段的值需要显示在搜索结果中,则需要进行存储。
docValues false 是否需要存储docValues。true为设置。docValues用于提升sorting, faceting, grouping, function queries等性能,现在仅支持StrField, UUIDFiel和所有的Trie*Field,此值为true的字段要求此字段multiValued=false,并且 (required=true或设置了default的值).
multiValued false 是否有多个值
omitNorms 如果你的大部分的document的长度大小都差不多,则设置成true。如果此字段在索引时需要boost,则设置为false.
termVectors false 设置为true,使More Like This特性生效,会极大的增加索引文件的大小
termPositions false 通常用于提高高亮搜索结果这一功能的性能。设置为true,会增加索引文件的大小
termOffsets fasle 通常用于提高高亮搜索结果这一功能的性能。设置为true,会增加索引文件的大小
termPayloads fasle 通常用于提高高亮搜索结果这一功能的性能。设置为true,会增加索引文件的大小
required fasle 如果设置为true,则索引时,如果此字段值为null,则会报错
default 此字段是默认字段
sortMissingFirst
sortMissingLast false 需要对搜索结果根据某个字段排序时,如果某条记录的此字段值为空,则该记录是排在搜索结果的最前/最后
omitTermFreqAndPositions 对所有不是文本类型的字段,默认为TRUE
omitPositions 与omitTermFreqAndPositions相似,只是仅忽略位置信息
useDocValuesAsStored 当docValues=true时,设置此值为TRUE,则如果返回的字段列表使用了通配符,即使此字段设置了stored=false,此字段还是会出现在返回的结果里,
large false 设置为TRUE时,需要设置stored=true和multiValued=false, 表示此字段是大字段,会被懒加载。通常用于此字段的内容可能比较大,不需要载入内存
说明:
omitNorms:
norm是基于document length norm,document boost和field boost计算出的浮点(float)值。这里的boost可以理解为权重。document length norm用于为较小的document增加权重(权重较大的话,计算搜索结果的score值会更高一点)。也就是说如果有一个比较小的document和一个比较长的document都符合搜索条件,Lucene会认为那个较小的document相对于较长的document更新符合搜索条件。omitNorms是指忽略norm,所以设为false时,较小的document和较长的document有相同的权重。因此如果我们需要为某个字段在索引时进行加权(boost),则应该设置为false。当字段类型为基本类型(比如:int, float,date,bool. string)时此默认值是true。
termVectors, termPositions, termOffsets 和 termPayloads:
此四个属性通常用于 hl.useFastVectorHighlighter为true时的情况,会较大地增加索引大小。
omitTermFreqAndPositions:
如果为TRUE,索引时将忽略频率、位置、负载等信息,这有助于提升不需要这些信息的字段的性能,也会减少索引大小。但是查询如果依赖于字段的位置信息,则会导致查询不到相关document。
2.2 dynamicField
为满足前辍或后辍的一些字段提供统一的定义。如<dynamicField name="*_s" index="true" stored="true" type="string" /> 表示所有以“_s”为后辍的field都具有index="true" stored="true" type="string"这些属性。dynamicField通常用于以下情形:
2.2.1 document模型具有较多的字段
举个粟子:想要索引pdf文件,Solr提供了一个简单的requestHandler – /update/extract,最终会调用apache的另外一个开源项目Tika去解析pdf文件,Solr返回的解析后的document里包含了很多field,我们只想要其中的某些field,如果我们在<field>里只配置了我们想要的field,那么进行索引的时候会报错,错误消息大体为没有定义什么什么field,这时,我们可以配置一个<dynamicField name="ignore_*" type="ignored" multiValued="true">,然后在solrconfig.xml里相应的requestHandler里配置<str name="uprefix">ignore_</str>,这样对于在managed-schema里没定义的field都会被忽略掉。
2.2.2 支持来自不同来源的文档
比如索引的时候想要增加标注其来源的field,可以进行如下的配置:
<field name="source1_field1" type="string" index="true" stored="true" />
<field name="source1_field2" type="string" index="true" stored="true" />
<field name="source1_field3" type="string" index="true" stored="true" />
<field name="source2_field1" type="string" index="true" stored="true" />
<field name="source2_field2" type="string" index="true" stored="true" />
<field name="source2_field3" type="string" index="true" stored="true" />但是如果有很多来源的话,这种配置就太多了。我们只须配置<dynamicField name="*_s" index="true" stored="true" type="string" />,然后索引的时候改成:
<doc>
<field name="id">hello</field>
<field name="source1_field1_s">hello</field>
</doc>这样,索引时的field名既可以保留来源的信息,又不需要在配置文件里配置很多的field定义。
2.2.3 增加新的文档来源
还是上面的例子,如果将来有新的文档来源,我们可以不必在配置文件里增加诸如 <field name="source5_field1" type="string" index="true" stored="true" />这样的配置,就可以直接在索引的时候添加“source5_field1_s”这样的字段。
2.3 uniqueKey
一般情况下需要配置<uniqueKey>id</uniqueKey>,虽然目录不是必须的,但是强烈建议设置此值。就好像数据库设计时,虽然不强制每个表有主键,但是一般情况下还是会设置一个主键的。
2.4 copyField
用百度或google搜索时,我们可能想要搜索一个人名,或者书名,或者网站的名字,其后台索引文件里分别由不同的field去保存那些值,那它是如何用一个输入框去搜索不同的field的内容的呢?答案就是<copyField> (不知道百度或google用的是什么搜索技术,但是原理应该差不多)
<field name="text" type="string" index="true" stored="true" multiValues="true" />
<copyField source="man_name" dest="text" />
<copyField source="book_name" dest="text" />
<copyField source="web_address" dest="text" />这样我们就只需要搜索text里的内容就可以了。
2.5 fieldType
fieldType主要定义了一些字段类型,其name属性值用于前面中的type属性的值。e.g. <fieldType name="string" class="solr.StrField" sortMissingLast="true" /> 其中class属性中solr是org.apache.solr.schema这个包名的缩写。
fieldType的属性:
1)name 由字母、数字和下划线组成。不能以数字开头。此值用于前面中的type属性的值。
2)class 此值表明索引并存储此fieldType的数据的类型(e.g char,int,date…)。如果此类不是solr提供的(自定义的或第三方的类),则不能用”solr.”,需要写类的全路径名。
3)positionIncrementGap 值为整数,用于multiValued=”true”的字段,指定多个值之间的距离,以防出现假的短语匹配。
比如描述书本作者的字段是有多个值的,假设有两个作者:John Smith 和 Mike Jackson,我们搜索”Smith Mike”这个作者,如果positionIncrementGap值设成0,则此记录就会被认为是匹配搜索条件的,实际上是不匹配的。对于这种情况,我们应该把此值设置成一个较大的值,比如100。
4) autoGeneratePhaseQueries 值为布尔类型。默认值为false。对于文本字段,如果设置为TRUE的话,Solr自动为相邻的terms生成短语查询。如果为FALSE,包含在双引号内的terms才会被认为是短语。
举个粟子:索引中的文本内容为: * 日图三餐,夜图一宿 。 我们在搜索的输入框里输入日图,如果autoGeneratePhaseQueries 为true,我们加上highlight的话,返回的匹配结果为: 日图三餐,夜图一宿 *。 如果值为false,则返回结果为 日图三餐,夜图一宿。如果值为false,我们还是想要进行短语查询,可在输入框里输入”春花”(注意需要加上两个双引号)。
5)docValuesFormat 自定义docValues的格式。设置此值的话,必须在solrconfig.xml里配置schema-aware codec。如:<codecFactory class="solr.SchemaCodecFactory" /> 在网上搜了一下,只看到有两个值 Memory 和 Disk。猜想这个属性的作用应该是定义docValues值是存在硬盘上还是存在内存中吧。
6)postingsFormat 自定义PostingsFormat。设置此值的话,必须在solrconfig.xml里配置schema-aware codec。不太清楚具体有什么用。
注:尽量不要使用docValuesFormat和postingFormat。Solr的guideline上有一段话,翻译如下:
仅当使用默认的codec 时,Lucene索引才支持向后兼容。因此,如果使用了这两个属性,那么将来想要升级到更高版本的Solr 时,需要你切换回默认的codec,然后优化现有的索引或者重新建立整个索引。
以下的属性也同时存在于<field>里,如果<field>里的值会覆盖<fieldType>里的值。
7)indexed 布尔值。true表示进行索引。
8)stored 布尔值。true表示进行存储。
9)docValues 布尔值。true表示field的值将会被存储于面向列的数据结构中。
10)sortMissingFirst 布尔值。true表示排序的时候,此field值为空的记录排在此field值不为空的记录的前面。
11)sortMissingLast 布尔值 。意思和sortMissingFirst相反。
12)multiValues 布尔值。
13)omitNorms 布尔值。
14)omitTermFreqAndPositions 布尔值。忽略term frequency, positions 和 payloads。所有非文本类型字段,此默认值是true。
15)omitPositions 布尔值。布尔值。忽略positions。
16)termVectors, termPositions, termOffsets 和 termPayloads 布尔值。
17)required 布尔值。
18)useDocValuesAsStored 布尔值。
19)large 布尔值。默认FALSE
fieldType里class属性的一些值:
1)BinaryField 二进制数据
2)BoolField 布尔值数据。以”1”、”T”和”t”开头的字符都被认为是true,其它都是false
3)CollationField 参见 CollationField
4)CurrencyField 支持货币及汇率。
5)DateRangeField 日期
6)ExternalFileField 从硬盘上的某个文件获取值
7)EnumField 允许定义一组枚举值,用于对不能根据字母或数值排序的字段进行排序。
<fieldType name="priorityLevel" class="solr.EnumField" enumsConfig="enumsConfig.xml" enumName="priority" /> enumsConfig的值是枚举值的配置文件。enumsConfig.xml 示例:
<?xml version="1.0" ?>
<enumsConfig>
<enum name="priority"><!-- 上面<fieldType> 里的enumName的值 -->
<value>Low</value>
<value>Medium</value>
<value>High</value>
</enum>
<enum name="risk"> ... 其它一些枚举名及其值列表 ...</enum>
</enumsConfig>8)ICUCollationField 参见 ICUCollationField
9)LatLonPointSpatialField 经纬度。用于空间搜索。通常表示为”lat,lon”
10)PointType 单值多维度点值。个人理解是指坐标值,比如二维或二维坐标。
11)PreAnalyzedField 参见 PreAnalyzedField
12)RandomSortField 不包含值。在此类型的字段上排序,将会返回随机的排序结果。
13)SpatialRecursivePrefixTreeFieldType 接受”latitue,logitude”格式的字符串或WKT格式。完全不明白是啥。
14)StrField UTF-8或Unicode的字符串。用于较小的字段,并且不被切分或分析(个人理解:此字段的值不会被拆分,被做为一个整体进行索引)。限制小于32K
15)TextField
16)TrieDateField, TrieDoubleField, TrieFloatField, TrieIntField, TrieLongField 见下面的说明
17)DatePointField, DoublePointField, FloatPointField, IntPointField, LongPointField 见下面的说明
18)UUIDField 定义一个document的唯一值。官方文档提到在SolrCloud环境下,不能保证唯一性,不建议使用,推荐使用UUIDUpdateProcessorFactory去生成UUID。
另外,在solr给的sample文件里,对于数值类型,定义了如下三个fieldType(以int为例):
a). <fieldType name="pint" class="solr.IntPointField" docValues="true" />
b). <fieldType name="int" class="solr.TrieIntField" docValues="true" precisionStep="0" positionIncrementGap="0"/>
c). <fieldType name="tint" class="solr.TrieIntField" docValues="true" precisionStep="8" positionIncrementGap="0"/>
对于a),对于数值类型的field,索引时使用KD-trees。 sample文件里提到要比 Trie*Field更快更高效,但是不支持某些特性。并未说明不支持哪些特性,所以并不推荐使用
对于b),通常用于确定性搜索,比如要搜索年龄是18的人。
对于c),用于范围搜索,比如要搜索某个年龄段的人。
也就是说,我们如果要对某项数据(比如人的信息,其中包含年龄字段)进行索引,一个人有唯一的年龄值,但是我们搜索的时候,可能需要进行确定年龄的搜索和年龄段的搜索,那么我们就需要定义两个年龄相关的field,其中一个field的fieldType为int,另一个field的fieldType为tint。
对 precisionStep 的一些说明:
比如 单个车的价格是不一样的,我们通常会查询某个价格范围内的车子信息。假设所有车辆价格范围是1万~1000万,为了加快查询速度,会把这个价格区间划分为几个区间进行索引。precisionStep的值差不就是划分为多少个区间的意思。
2.5.1Analyzer
有些时候,我们需要自定义 fieldType。下面的例子就是自定义的 fieldType,<analyzer type="index"> 表示索引时怎么处理,<analyzer type="query">表示查询时怎么处理。
复制代码
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- 本例中,我们只在查询时应用同义词
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>tokenizer: 对输入流进行分词。这里的“solr.” 代表:org.apache.solr.analysis. 这个包
filter: 对tokenizer输出的每一个分词,进行处理。
2.5.2 Tokenizer
2.5.2.1. solr.StandardTokenizerFactory
把文本用空格和标点符号分割。对于小数点(.),如果后面不是空格的话,将会被保留。如网址。连字符(-)的两边会被分割成两个分词(token)。
参数:maxTokenLength 分词的最大长度,超出部分将被忽略。
example:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory" maxTokenLength="100"/>
</analyzer>输入: Please email [email protected] by 03-09, re: m37-xq.
输出: “Please”, “email”, “john.doe”, “foo.com”, “by”, “03”, “09”, “re”, “m37”, “xq”
2.5.2.2. solr.ClassicTokenizerFactory
跟StardardTokenizerFactory差不多,不同点如下:
(1)连字符(-)两边如果有数字的话,将不会被拆分。
(2)能识别邮件地址
参数:maxTokenLength 分词的最大长度,超出部分将被忽略。
示例:
输入: Please email [email protected] by 03-09, re: m37-xq.
输出: “Please”, “email”, “[email protected]“, “by”, “03-09”, “re”, “m37-xq”
2.5.2.3. solr.KeywordTokenizerFactory
整个文本做为一个分词。
示例:
输入: Please email [email protected] by 03-09, re: m37-xq.
输出: “Please email [email protected] by 03-09, re: m37-xq”
2.5.2.4. solr.LetterTokenizerFactory
连续的字母做为一个分词。
示例:
输入: I can’t.
输出: “I”, “can”, “t”
2.5.2.5. solr.LowerCaseTokenizerFactory
按非字母进行分词,并转化成小写。
示例:
输入: I LOVE my iPhone.
输出: “I”, “love”, “my”, “iphone”
2.5.2.6. solr.NGramTokenizerFactory
对文本按照 n-Gram 进行分词。
参数:minGramSize (default 1) – 必须 > 0
maxGramSize (default 2) – 必须 >= minGramSize
示例:
输入: hey man
输出: “h”, “e”, “y”, ” “, “m”, “a”, “n”, “he”, “ey”, “y “, ” m”, “ma”, “an”
2.5.2.7. solr.EdgeNGramTokenizerFactory
对文本按照 n-Gram 进行分词。
参数:minGramSize (default 1) – 必须 > 0
maxGramSize (default 1) – 必须 >= minGramSize
side (default “front”) – “front” or “back”
示例:
输入: babaloo
输出(default): “b”
输出(minGramSize=2, maxGramSize=5):”ba”, “bab”, “baba”, “babal”
2.5.2.8. solr.ICUTokenizerFactory
对多语言文本,基于其语言特性,进行恰当地分词。
参数:rulefile– 此值的格式: 四个字母的语言代码+“:”+文件路径
<analyzer>
<tokenizer class="solr.ICUTokenizerFactory" rulefile="Latn:my.Latin.rule.rbbi,Cyrl:my.Cyrillic.rules.rbbi"/>
</analyzer>注意:需要添加额外的jar包到Solr 的 classpath下。
2.5.2.9. solr.PathHierarchyTokenizerFactory
用replace指定的字符代替delimiter指定的字符,并进行分词
参数:delimiter (no default)
replace (no default)
示例:
<analyzer>
<tokenizer class="solr.PathHierarchyTokenizerFactory" delimiter="\" replace="/"/>
</analyzer>输入: d:\usr\local\apache
输出: “d:”, “d:/usr”, “d:/usr/local”, “d:/usr/local/apache”
2.5.2.10. solr.PatternTokenizerFactory
利用Java的正则表达式进行分词。
参数:pattern – 必填
group – 可选。默认 -1 。
-1 表示正则表达式作为分割符。0 表示符合正则表达式的才会被认为是一个分词而保留。大于0的值(比如2)表示只保留符合正则表达式的部分中的第2个部分。
示例:
<analyzer>
<tokenizer class="solr.PatternTokenizerFactory" pattern="\s*\s*" />
</analyzer>输入: fee,fie, foe , fun, foo
输出: “fee”, “fie”, “foe”, “fun”, “foo”
示例:
<analyzer>
<tokenizer class="solr.PatternTokenizerFactory" pattern="[A-Z][A-Za-z]*" group="0"/>
</analyzer>输入: Hello, My name is Rose.
输出: “Hello”, “My”, “Rose”
2.5.2.11. solr.UAX29URLEmailTokenizerFactory
空格和标点符号做为分割符。小数点如果后面不是空格,则被保留。连接符(“-”)连起来的各个部分将被划分为独立的分词,除非其中包含数字。网址、Email、IP地址将会被认为一个整体。
参数:maxTokenLength – 长度超过此值的分词将会被截断。
2.5.2.12. solr.WhitespaceTokenizerFactory
仅将空格做为分割符。
参数:rule – “java”: 默认值,利用Character.isWhitespace(int)确定是否是whitespace。 “unicode”: 利用Unicode的whitespace做为分割符。
2.5.3 filter
自定义fieldType时,通常还会用到filter。filter必须跟在tokenizer或其它filter之后。如:
<fieldType>
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>Solr 提供了很多的filter,具体如下:
1. ASCII Folding Filter
2. Beider-Morse Filter
3. Classic Filter
4. Common Grams Filter
5. Collation Key Filter
6. Daitch-Mokotoff Soundex Filter
7. Double Metaphone Filter
8. Edge N-Gram Filter
9. English Minimal Stem Filter
10. English Possessive Filter
11. Fingerprint Filter
12. Flatten Graph Filter
13. Hunspell Stem Filter
14. Hyphenated Words Filter
15. ICU Folding Filter
16. ICU Normalizer 2 Filter
17. ICU Transform Filter
18. Keep Word Filter
19. KStem Filter
20. Length Filter
21. Limit Token Count Filter
22. Limit Token Offset Filter
23. Limit Token Position Filter
24. Lower Case Filter
25. Managed Stop Filter
26. Managed Synonym Filter
27. N-Gram Filter
28. Numeric Payload Token Filter
29. Pattern Replace Filter
30. Phonetic Filter
31. Porter Stem Filter
32. Remove Duplicated Token Filter
33. Reversed Wildcard Filter
34. Shingle Filter
35. Snowball Porter Stemmer Filter
36. Standard Filter
37. Stop Filter
38. Suggest Stop Filter
39. Synonym Filter
40. Synonym Graph Filter
41. Token Offset Payload Filter
42. Trim Filter
43. Type As Payload Filter
44. Type Token Filter
45. Word Delimiter Filter
46. Word Delimiter Graph Filter
2.6. defaultSearchField
defaultSearchField指定搜索的时候默认搜索字段的值。
2.7. solrQueryParser
solrQueryParser指定搜索时多个词之间的关系,可以是or,and两种。
2.8. 性能优化
1、 将所有只用于搜索的,而不需要作为结果的field(特别是一些比较大的field)的stored设置为false;
2、 将不需要被用于搜索的,而只是作为结果返回的field的indexed设置为false;
3、 删除所有不必要的copyField声明为了索引字段的最小化和搜索的效率;
4、 将所有的 text fields的index都设置成false,然后使用copyField将他们都复制到一个总的 text field上,然后进行搜索。
六、solrconfig.xml
solrconfig.xml配置文件主要定义了Solr的一些处理规则,包括索引数据的存放位置,更新,删除,查询的一些规则配置。
1、 solrconfig 成员
1.1 luceneMatchVersion
表示Solr底层依赖的lucene版本
1.2 lib
lib 定义了Solr需要额外引用的jar包位置。它告诉 Solr 如何去加载 solr plugins(Solr 插件 ) 依赖的 jar 包,在 solrconfig.xml 配置文件的注释中有配置示例,例如:
<lib dir="./lib" regex=”lucene-\w+\.jar”/>
这里的 dir 表示一个 jar 包目录路径,该目录路径是相对于你当前 core 根目录的; regex 表示一个正则表达式,用来过滤文件名的,符合正则表达式的 jar 文件将会被加载,如果对应的文件不存在,会自动忽略这一配置,一般建议将其注释掉,只添加需要使用的jar包。
1.3 dataDir
用来指定一个 solr 的索引数据目录, solr 创建的索引会存放在 data\index 目录下,默认 dataDir 是相对于当前 core 目录 ( 如果 solr_home 下存在 core 的话 ) ,如果 solr_home 下不存在 core 的话,那 dataDir 默认就是相对于 solr_home 啦,不过一般 dataDir 都在 core.properties 下配置。
1.4 directoryFactory
规定了索引存储方案
1. solr.StandardDirectoryFactory,这是一个基于文件系统存储目录的工厂,它会试图选择最好的实现基于你当前的操作系统和Java虚拟机版本
2. solr.SimpleFSDirectoryFactory,适用于小型应用程序,不支持大数据和多线程
3. solr.NIOFSDirectoryFactory,适用于多线程环境,但是不适用在windows平台(很慢),是因为JVM还存在bug
4. solr.MMapDirectoryFactory,这个是solr3.1到4.0版本在linux64位系统下默认的实现。它是通过使用虚拟内存和内核特性调用 mmap 去访问存储在磁盘中的索引文件。它允许 lucene 或 solr 直接访问I/O缓存。如果不需要近实时搜索功能,使用此工厂是个不错的方案。
5. solr.NRTCachingDirectoryFactory,此工厂设计目的是存储部分索引在内存中,从而加快了近实时搜索的速度
6. solr.RAMDirectoryFactory,这是一个内存存储方案,不能持久化存储,在系统重启或服务器crash时数据会丢失。且不支持索引复制
1.5 codecFactory
编解码工厂允许使用自定义的编解码器。例如:如果想启动per-field DocValues格式, 可以在solrconfig.xml里面设置SchemaCodecFactory:
docValuesFormat=”Lucene42”: 这是默认设置,所有数据会被加载到堆内存中。
docValuesFormat=”Disk”: 这是另外一个实现,将部分数据存储在磁盘上。
docValuesFormat=”SimpleText”: 文本格式,非常慢,用于学习。
<codecFactory class="solr.SchemaCodecFactory"/>
<schemaFactory class="ClassicIndexSchemaFactory"/>
1.6 indexConfig
用于设置索引的低级别的属性
<filter class="solr.LimitTokenCountFilterFactory" maxTokenCount="10000"/>//限制token最大长度
<writeLockTimeout>1000</writeLockTimeout>//IndexWriter等待解锁的最长时间(毫秒)。
<maxIndexingThreads>8</maxIndexingThreads>//
<useCompoundFile>false</useCompoundFile>//solr默认为false。如果为true,索引文件减少,检索性能降低,追求平衡。
<ramBufferSizeMB>100</ramBufferSizeMB>//缓存
<maxBufferedDocs>1000</maxBufferedDocs>//同上。两个同时定义时命中较低的那个。
<mergePolicy class="org.apache.lucene.index.TieredMergePolicy">
<int name="maxMergeAtOnce">10</int>
<int name="segmentsPerTier">10</int>
</mergePolicy>//合并策略
<mergeFactor>10</mergeFactor>//合并因子,每次合并多少个segments。
<mergeScheduler class="org.apache.lucene.index.ConcurrentMergeScheduler"/>//合并调度器。
<lockType>${solr.lock.type:native}</lockType>//锁工厂。
<unlockOnStartup>false</unlockOnStartup>//是否启动时先解锁。
<termIndexInterval>128</termIndexInterval>//Lucene loads terms into memory 间隔
<reopenReaders>true</reopenReaders>//重新打开,替代先关闭-再打开。
<deletionPolicy class="solr.SolrDeletionPolicy">//提交删除策略,必须实现org.apache.lucene.index.IndexDeletionPolicy
<str name="maxCommitsToKeep">1</str>
<str name="maxOptimizedCommitsToKeep">0</str>
<str name="maxCommitAge">30MINUTES</str>// OR <str name="maxCommitAge">1DAY</str>
<infoStream file="INFOSTREAM.txt">false</infoStream>//相当于把创建索引时的日志输出。注:<lockType>${solr.lock.type:native}</lockType>
设置索引库的锁方式,主要有三种:
1.single:适用于只读的索引库,即索引库是定死的,不会再更改
2.native:使用本地操作系统的文件锁方式,不能用于多个solr服务共用同一个索引库。Solr3.6 及后期版本使用的默认锁机制。
3.simple:使用简单的文件锁机制
4. hdfs: 使用HdfsLockFactory来支持读取和写入索引和事务日志文件到HDFS文件系统
1.7 updateHandler
<!--updateHandler: 这个更新处理器主要涉及底层的关于如何更新处理内部的信息。 -->
<updateHandler class="solr.DirectUpdateHandler2">
<updateLog>
<str name="dir">${solr.ulog.dir:}</str>
</updateLog>
<autoCommit>
<maxDocs>10000</maxDocs> <!-- 触发自动提交前最多可以等待提交的文档数量 -->
<maxTime>86000</maxTime> <!-- 在添加了一个文档之后,触发自动提交之前所最大的等待时间-->
</autoCommit>
<!--一个postCommit的事件被触发当每一个提交之后 -->
<listener event="postCommit" class="solr.RunExecutableListener">
<str name="exe">snapshooter</str> <!-- exe--可执行的文件类型 -->
<str name="dir">solr/bin</str> <!--dir--可以用该目录做为当前的工作目录。默认为"." -->
<bool name="wait">true</bool> <!-- wait--调用线程要等到可执行的返回值 -->
<arr name="args"> <str>arg1</str> <str>arg2</str> </arr> <!--args--传递给程序的参数 默认nothing-->
<arr name="env"> <str>MYVAR=val1</str> </arr> <!-- env 环境变量的设置 默认nothing -->
</listener>
<autoSoftCommit>
<maxTime>${solr.autoSoftCommit.maxTime:-1}</maxTime>
</autoSoftCommit>
</updateHandler>1.8 query
属性 说明
maxBooleanClauses 最大的BooleanQuery数量. 当值超出时,抛出 TooManyClausesException.注意这个是全局的,如果是多个SolrCore都会使用一个值,每个Core里设置不一样的化,会使用最后一个的.
filterCache filterCache存储了无序的lucene document id集合,1.存储了filter queries(“fq”参数)得到的document id集合结果。2还可用于facet查询3. 3)如果配置了useFilterForSortedQuery,那么如果查询有filter,则使用filterCache。
queryResultCache 缓存搜索结果,一个文档ID列表
documentCache 缓存Lucene的Document对象,不会自热
fieldValueCache 字段缓存使用文档ID进行快速访问。默认情况下创建fieldValueCache即使这里没有配置。
enableLazyFieldLoading 若应用程序预期只会检索 Document 上少数几个 Field,那么可以将属性设置为 true。延迟加载的一个常见场景大都发生在应用程序返回和显示一系列搜索结果的时候,用户常常会单击其中的一个来查看存储在此索引中的原始文档。初始的 显示常常只需要显示很短的一段信息。若考虑到检索大型 Document 的代价,除非必需,否则就应该避免加载整个文档。
queryResultWindowSize 一次查询中存储最多的doc的id数目.
queryResultMaxDocsCached 查询结果doc的最大缓存数量, 例如要求每页显示10条,这里设置是20条,也就是说缓存里总会给你多出10条的数据.让你点示下一页时很快拿到数据.
listener 选项定义 newSearcher 和 firstSearcher 事件,您可以使用这些事件来指定实例化新搜索程序或第一个搜索程序时应该执行哪些查询。如果应用程序期望请求某些特定的查询,那么在创建新搜索程序或第一 个搜索程序时就应该反注释这些部分并执行适当的查询。
useColdSearcher 是否使用冷搜索,为false时使用自热后的searcher
maxWarmingSearchers 最大自热searcher数量
对于所有缓存模式而言,在设置缓存参数时,都有必要在内存、cpu和磁盘访问之间进行均衡。统计信息管理页(管理员界面的Statistics)对于分析缓存的 hit-to-miss 比例以及微调缓存大小的统计数据都非常有用。而且,并非所有应用程序都会从缓存受益。实际上,一些应用程序反而会由于需要将某个永远也用不到的条目存储在缓存中这一额外步骤而受到影响。
1.9 requestDispatcher
<requestDispatcher handleSelect="false" >
<!-- 这些设置说明Solr Requests如何被解析,以及对ContentStreams有什么限制。 -->
<requestParsers enableRemoteStreaming="true"
multipartUploadLimitInKB="2048000"
formdataUploadLimitInKB="2048"
addHttpRequestToContext="false"/>
<!-- 设置HTTP缓存的相关参数。Never304 即告诉服务器,不管我访问的资源有没有更新过,都给我重新返回不走 Http 缓存。-->
<httpCaching never304="true" />
</requestDispatcher>定义当有请求访问Solr core时SolrDispatchFilter如何处理。
handleSelect是一个以前版本中遗留下来的属性,会影响请求的对应行为(比如/select?qt=XXX)。
当handleSelect=”true”时导致SolrDispatchFilter将请求转发给qt指定的处理器(前提是/select已经注册)。
当handleSelect=”false”时会直接访问/select,若/select未注册则为404。
1.10 requestHandler
<requestHandler name="/query" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="wt">json</str>
<str name="indent">true</str>
<str name="df">text</str>
</lst>
</requestHandler>定义请求处理器行为。
这个 requestHandler 配置的是请求 URL /query 跟请求处理类 SearcherHandler 之间的一个映射关系,即你访问http://localhost:8080/solr/core/query?q=xxx 时,会交给 SearcherHandler 类来处理这个 http 请求,你可以配置一些参数来干预 SearcherHandler 处理细节。
其他的一些 requestHandler 说明就略过了,其实都大同小异,就是一个请求 URL 跟请求处理类的一个映射 , 就好比 SpringMVC 中请求 URL 和 Controller 类的一个映射。
1.11 searchComponent
用来配置查询组件比如 SpellCheckComponent 拼写检查,有关拼写检查的详细配置说明留到以后说到 SpellCheck 时再说吧。
<searchComponent name="terms" class="solr.TermsComponent"/>
用来返回所有的 Term 以及每个 document 中 Term 的出现频率
<searchComponent class="solr.HighlightComponent" name="highlight">
用来配置关键字高亮的, Solr 高亮配置的详细说明这里暂时先略过,这篇我们只是先暂时大致了解下每个配置项的含义即可,具体如何使用留到后续再深入研究。
有关 searchComponent 查询组件的其他配置我就不一一说明了,太多了。你们自己看里面的英文注释吧,如果你实在看不懂再来问我。
<searchComponent name="suggest" class="solr.SuggestComponent">
<lst name="suggester">
<str name="name">mySuggester</str>
<str name="lookupImpl">FuzzyLookupFactory</str>
<str name="dictionaryImpl">DocumentDictionaryFactory</str>
<str name="field">cat</str>
<str name="weightField">price</str>
<str name="suggestAnalyzerFieldType">string</str>
</lst>
</searchComponent>1.12 queryResponseWriter
这个是用来配置 Solr 响应数据转换类, JSONResponseWriter 就是把 HTTP 响应数据转成 JSON 格式, content-type 即 response 响应头信息中的 content-type, 即告诉客户端返回的数据的 MIME 类型为 text/plain ,且 charset 字符集编码为 UTF-8.
内置的响应数据转换器还有 velocity , xslt 等,如果你想自定义一个基于 FreeMarker 的转换器,那你需要实现 Solr 的 QueryResponseWriter 接口,模仿其他实现类,你懂的,然后在 solrconfig.xml 中添加类似的<queryResponseWriter> 配置即可
最后需要说明下的是 solrconfig.xml 中有大量类似 <arr> <list> <str> <int>
arr:即 array 的缩写,表示一个数组, name 即表示这个数组参数的变量名
lst即 list 的缩写,但注意它里面存放的是 key-value 键值对
bool:表示一个 boolean 类型的变量 ,name 表示 boolean 变量名,
同理还有int,long,float,str等等
str: 即 string 的缩写,唯一要注意的是 arr 下的 str 子元素是没有 name 属性的,而 list 下的 str 元素是有 name 属性的
1.13 initParams
在处理程序配置之外定义请求处理程序参数
<initParams path="/update/**,/query,/select,/tvrh,/elevate,/spell,/browse">
<lst name="defaults">
<str name="df">_text_</str>
</lst>
</initParams>
智能推荐
Python爬虫实战(1)-爬取“房天下”租房信息(超详细)-程序员宅基地
文章浏览阅读844次。#前言先看爬到的信息:今天主要用到了两个库:Requests和BeautifulSoup。所以我先简单的说一下这两个库的用法,提到的都是此文需要用到的。#Requestsrequests是一个很实用的Python HTTP客户端库。下面通过一个例子来了解一下:网址就用房天下的天津整租租房信息“http://zu.tj.fang.com/house/n31/”import re..._房天下爬虫可以爬之前的吗
HTML5期末大作业:210套 Dreamweaver网页设计与制作 HTML+CSS+JavaScript【建议收藏】-程序员宅基地
文章浏览阅读3.2w次,点赞45次,收藏136次。HTML5期末大作业:Dreamweaver网页设计与制作210例临近期末, 你还在为HTML网页设计结课作业,老师的作业要求感到头大?HTML网页作业无从下手?网页要求的总数量太多?没有合适的模板?等等一系列问题。你想要解决的问题,在这篇博文中基本都能满足你的需求~原始HTML+CSS+JS页面设计, web大学生..._html期末大作业模板
Linux C++ 读写Json文件_linux json 读写-程序员宅基地
文章浏览阅读3.1k次。使用Json模块开源项目,Github地址:https://github.com/nlohmann/json直接将json.hpp 放入到文件夹中即可。#include "json.hpp"#include <fstream>#include <iostream>using namespace std;using json = nlohmann::..._linux json 读写
如何防止运营商网络劫持,避免被他人强行插入广告?-程序员宅基地
文章浏览阅读2w次。主要的网络劫持形式:近年来流量劫持(运营商网络劫持)频频发生,各种方式也是层出不穷,易维信-EVTrust总结各种网络劫持现象和其带来的危害1、域名劫持,用户想要访问网站A,域名却被解析到其它地址,用户无法正常访问想要访问的页面,网站流量受损。如果域名被解析到恶意钓鱼网站,导致用户财产损失,例如网上用户本来想要访问某知名的金融网站,却被跳转到另一个见容极为相似的假冒网站,从而套取用户数据,_强行插入
Quartus II中关于IP核的破解_quartusii ddr3 ip核灰色-程序员宅基地
文章浏览阅读7k次,点赞7次,收藏41次。首先简单的说一下什么是IP核,它可以理解成Altera公司自己开发的一些接口模块,可实现相应的功能,用户在实现该功能的时候可以直接调用相应的IP核即可,不用再重新编写相应的底层代码。说白了它就类似于Matlab中封装好的函数,用户在使用过程中可以直接调用相应的函数,极大降低了编写程序的难度。 废话不多说,这里直奔主题。我们在Quartus II软件中调用的IP核分为两大类,一类是免费的IP,不需要另外的license,就是所谓的Basic Function的IP,例如浮点运算、..._quartusii ddr3 ip核灰色
Ubuntu系统下Python的虚拟环境搭建方法简介:venv、virtualenv、pipenv_ubuntu venv-程序员宅基地
文章浏览阅读1w次,点赞19次,收藏78次。Python进阶:Ubuntu系统下Python的venv轻量级虚拟环境搭建简介一、Python虚拟环境的作用及创建方法简介二、venv搭建虚拟环境2.1 venv虚拟环境创建最简单的例子2.2 熟悉而陌生的pip2.2.1 从PyPI上安装2.2.2 pip根据Requirements文件配置环境三、virtualenv搭建虚拟环境四、pipenv搭建虚拟环境4.1 pipenv简介4.2 pipenv的安装与使用方法一、Python虚拟环境的作用及创建方法简介Python虚拟环境的作用:针对不同项_ubuntu venv
随便推点
Debug笔记:解决AttributeError: ‘bool‘ object has no attribute ‘all‘_bool' object has no attribute 'all-程序员宅基地
文章浏览阅读1.8w次,点赞10次,收藏9次。解决AttributeError: ‘bool‘ object has no attribute ‘all‘ 1. 当判断两个形状相同的numpy矩阵是否相等时,返回一个相同形状的矩阵(`np.ndarray`),每个位置是一个bool值** 2. 当判断两个形状不同的numpy矩阵是否相等时,不论两个矩阵的元素如何,都返回一个bool值—False。原因显而易见_bool' object has no attribute 'all
Canny处理图像不连续性(边缘检测)_canny边缘检测 不连续-程序员宅基地
文章浏览阅读3.3k次。这里写自定义目录标题边缘检测-CannyCanny算法整体流程非极大值抑制设置高低阈值调用opencv进行代码实现:Canny调用opencv执行结果边缘检测-Canny你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。Canny算法整体流程步骤:1. 用一个高斯滤波器平滑输入图像。2. 计算梯度副值图像和角度图像。3. 对梯度幅值图像应用非极大值抑制。4. 用双阈值处_canny边缘检测 不连续
基于STM32F103C8T6的IIC通信协议及硬件通信和软件OLED温度显示项目_stm32f103c8t6 i2c-程序员宅基地
文章浏览阅读5k次,点赞8次,收藏71次。I2C通讯_stm32f103c8t6 i2c
Apache Ignite 的并发控制:实现高性能事务处理的关键_apache ignite 性能-程序员宅基地
文章浏览阅读40次。分布式数据库和计算平台是大数据时代的基石,它们可以实现数据的水平和垂直分片,以及数据的并行处理。这些技术使得我们可以处理海量数据和复杂计算,从而实现高性能和高可用性。Apache Ignite 是一款开源的分布式数据库和计算平台,它可以提供实时性能和高可用性,同时支持事务处理和并发控制。Ignite 的核心设计理念是“数据库+计算引擎”,它可以实现高性能的数据存储和计算,同时支持事务和并发控制。答案:并发控制是事务处理系统的一部分,它可以确保多个事务在同时执行时不会互相干扰。_apache ignite 性能
OpenCV实践之路——使用imread()函数读取图片的六种正确姿势_imread函数读取文件中的图片-程序员宅基地
文章浏览阅读10w+次,点赞51次,收藏184次。经常看到有人在网上询问关于imread()函数读取图片失败的问题。今天心血来潮,经过实验,总结出imread()调用的四种正确姿势。通常我要获取一张图片的绝对路径是这样做的:在图片上右键——属性——安全——对象名称。然后复制对象名称就得到了图片的绝对路径。如图:然而这样得到的路径直接复制粘贴到vs里面会直接报错,如下:可以看出我们获取的绝对路_imread函数读取文件中的图片
vrep中的运动规划(主要是针对机械臂)(未完)_如何在v-rep中实现自己的规划算法-程序员宅基地
文章浏览阅读1w次,点赞8次,收藏75次。1.运动规划主要注意事项2.运动规划的两个主要步骤 2.1 Finding a goal configuration that matches a goal pose 2.2 Finding a collision-free path from a start configuration to a goal configuration 3...._如何在v-rep中实现自己的规划算法