flink-cdc之读取mysql变化数据_java代码flink1.13.0 读取mysql表信息-程序员宅基地
pom
<properties>
<flink-version>1.13.0</flink-version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink-version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink-version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink-version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>${flink-version}</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.2.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
</dependencies>
代码
注意开启checkpoint 和不开启是有区别的(savepoint也可以 启动的flink指定时候 -s savepath)
不开启,如果项目重启了,会重新读取所有的数据
开启了,项目重启了额,会根据保留的信息去读取变化的数据
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import com.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkCDCTest {
public static void main(String[] args) throws Exception {
//1.获取Flink 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 开启CK
// env.enableCheckpointing(5000);
// env.getCheckpointConfig().setCheckpointTimeout(10000);
// env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//
// env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/cdc-test/ck"));
//2.通过FlinkCDC构建SourceFunction
DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
.hostname("9.134.70.1")
.port(3306)
.username("root")
.password("xxxxxxx")
.databaseList("cc")
.tableList("cc.student")
// .deserializer(new StringDebeziumDeserializationSchema())
.deserializer(new JsonDebeziumDeserializationSchema())
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> dataStreamSource = env.addSource(sourceFunction);
//3.数据打印
dataStreamSource.print("==FlinkCDC==");
//4.启动任务
env.execute("FlinkCDC");
}
}mysql
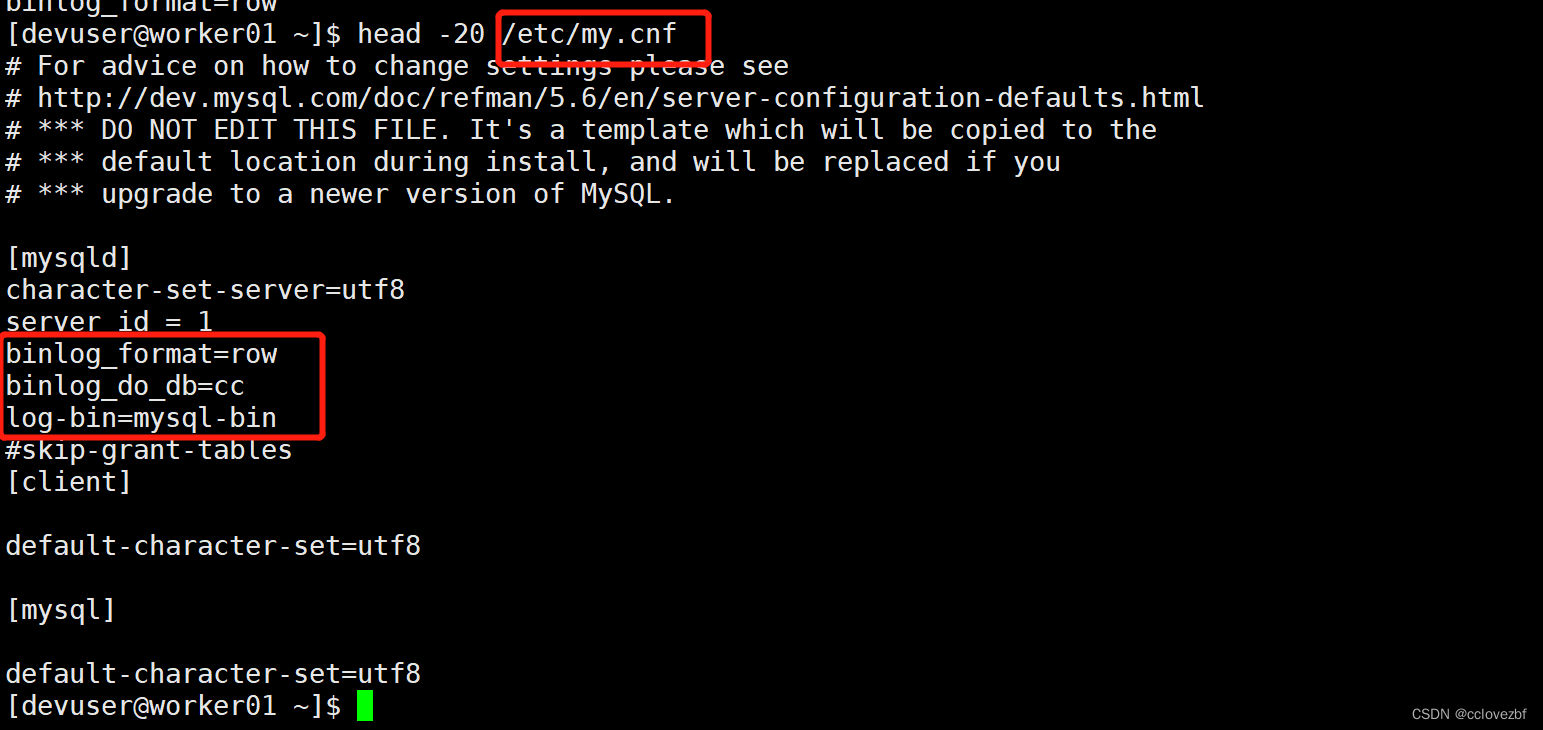
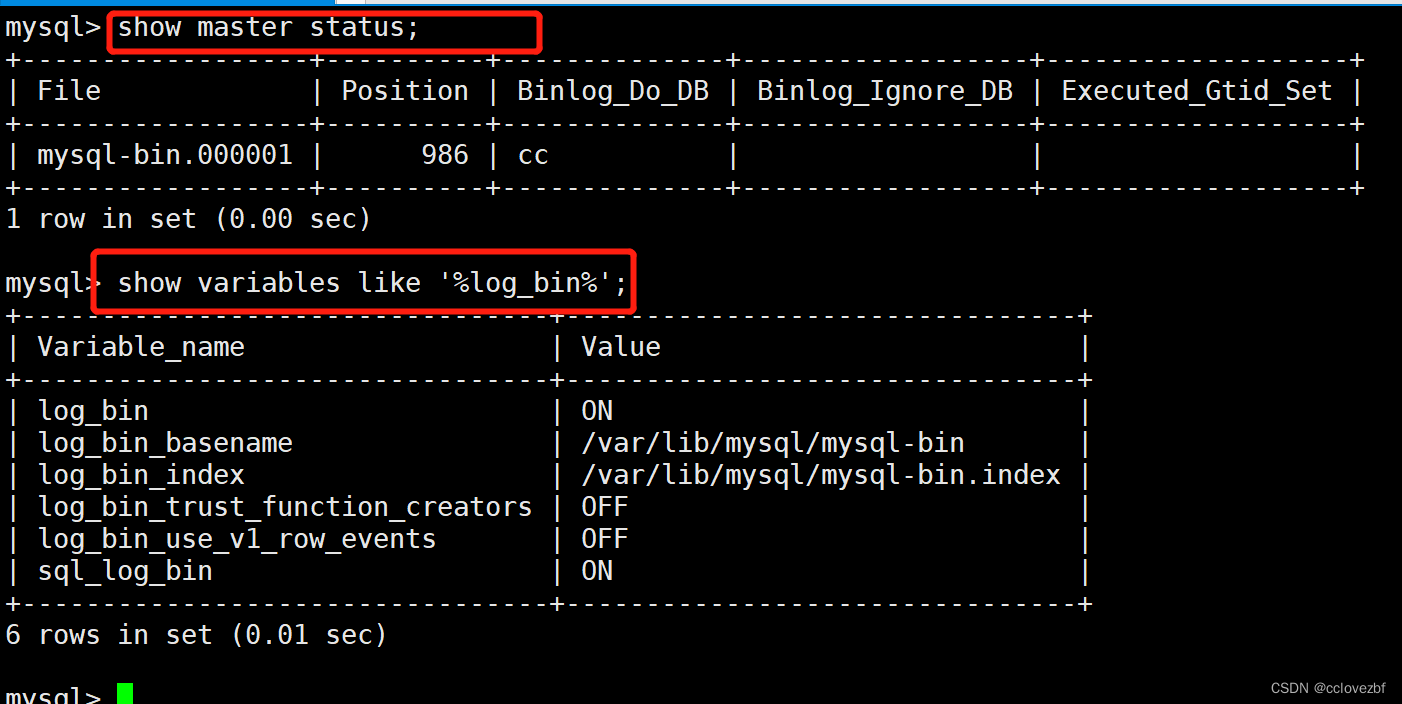
数据库表
增加一条数据
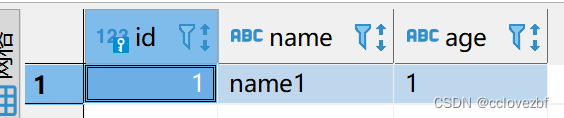
打印日志 op:c 是create
==FlinkCDC==> {"before":null,"after":{"id":1,"name":"name1","age":"1"},"source":{"version":"1.5.4.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1689245998000,"snapshot":"false","db":"cc","sequence":null,"table":"student","server_id":1,"gtid":null,"file":"mysql-bin.000001","pos":2781,"row":0,"thread":null,"query":null},"op":"c","ts_ms":1689246005928,"transaction":null}
修改一条数据 age=1 ->age=2 op=u 是update
flink打印日志
==FlinkCDC==> {"before":{"id":1,"name":"name1","age":"1"},"after":{"id":1,"name":"name1","age":"2"},"source":{"version":"1.5.4.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1689246092000,"snapshot":"false","db":"cc","sequence":null,"table":"student","server_id":1,"gtid":null,"file":"mysql-bin.000001","pos":3049,"row":0,"thread":null,"query":null},"op":"u","ts_ms":1689246099578,"transaction":null}
删除这条数据 op=d 是delete
==FlinkCDC==> { "before":{"id":1,"name":"name1","age":"2"},"after":null,"source":{"version":"1.5.4.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1689246163000,"snapshot":"false","db":"cc","sequence":null,"table":"student","server_id":1,"gtid":null,"file":"mysql-bin.000001","pos":3333,"row":0,"thread":null,"query":null},"op":"d","ts_ms":1689246170857,"transaction":null}
由于打印的日志太多 我们可以用fastjson稍微封装下 然后传给sink去处理,根据update delete insert实时更新下游数据,还有一个op=r 是读取的数据
还可以使用flinksql
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkSqlCdc {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.使用FLINKSQL DDL模式构建CDC 表
tableEnv.executeSql("CREATE TABLE user_info ( " +
" id STRING primary key, " +
" name int, " +
" age STRING " +
") WITH ( " +
" 'connector' = 'mysql-cdc', " +
" 'scan.startup.mode' = 'latest-offset', " +
" 'hostname' = '9.134.70.1', " +
" 'port' = '3306', " +
" 'username' = 'root', " +
" 'password' = 'xxxxx', " +
" 'database-name' = 'cc', " +
" 'table-name' = 'student' " +
")");
//3.查询数据并转换为流输出
Table table = tableEnv.sqlQuery("select * from user_info");
DataStream<Tuple2<Boolean, Row>> retractStream = tableEnv.toRetractStream(table, Row.class);
retractStream.print();
//4.启动
env.execute("FlinkSQLCDC");
}
}同样是增删改查,flink打印日志如下

智能推荐
手把手教你安装Eclipse最新版本的详细教程 (非常详细,非常实用)_eclipse安装教程-程序员宅基地
文章浏览阅读4.4k次,点赞2次,收藏16次。写这篇文章的由来是因为后边要用这个工具,但是由于某些原因有部分小伙伴和童鞋们可能不会安装此工具,为了方便小伙伴们和童鞋们的后续学习和不打击他们的积极性,因为80%的人都是死在工具的安装这第一道门槛上,这门槛说高也不高说低也不是太低。所以就抽时间水了这一篇文章。_eclipse安装教程
分享11个web前端开发实战项目案例+源码_前端项目实战案例-程序员宅基地
文章浏览阅读4.1w次,点赞12次,收藏193次。小编为大家收集了11个web前端开发,大企业实战项目案例+5W行源码!拿走玩去吧!1)小米官网项目描述:首先选择小米官网为第一个实战案例,是因为刚开始入门,有个参考点,另外站点比较偏向目前的卡片式设计,实现常见效果。目的为学者练习编写小米官网,熟悉div+css布局。学习资料的话可以加下web前端开发学习裙:600加上610再加上151自己去群里下载下。项目技术:HTML+CSS+Div布局2)迅雷官网项目描述:此站点特效较多,所以通过练习编写次站点,学生可以更多练习CSS3的新特性过渡与动画的实_前端项目实战案例
计算质数-埃里克森筛法(间隔黄金武器)-程序员宅基地
文章浏览阅读73次。素数,不同的质数,各种各样的问题总是遇到的素数。以下我们来说一下求素数的一种比較有效的算法。就是筛法。由于这个要求得1-n区间的素数仅仅须要O(nloglogn)的时间复杂度。以下来说一下它的思路。思路:如今又1-n的数字。素数嘛就是除了1和本身之外没有其它的约数。所以有约数的都不是素数。我们从2開始往后遍历,是2的倍数的都不是素数。所以我们把他们划掉然后如...
探索Keras DCGAN:深度学习中的创新图像生成-程序员宅基地
文章浏览阅读532次,点赞9次,收藏14次。探索Keras DCGAN:深度学习中的创新图像生成项目地址:https://gitcode.com/jacobgil/keras-dcgan在数据驱动的时代,图像生成模型已经成为人工智能的一个重要领域。其中,Keras DCGAN 是一个基于 Keras 的实现,用于构建和训练 Deep Convolutional Generative Adversarial Networks(深度卷积生...
org.apache.ibatis.binding.BindingException: Invalid bound statement (not found):_spring-could org.apache.ibatis.binding.bindingexce-程序员宅基地
文章浏览阅读116次。今天在搭建springcloud项目时,发现如上错误,顺便整理一下这个异常:1. mapper.xml的命名空间(namespace)是否跟mapper的接口路径一致<mapper namespace="com.baicun.springcloudprovider.mapper.SysUserMapper">2.mapper.xml接口名是否和mapper.java接..._spring-could org.apache.ibatis.binding.bindingexception: invalid bound state
四种高效数据库设计思想——提高查询效率_数据库为什么能提高效率-程序员宅基地
文章浏览阅读1.1k次。四种高效数据库设计思想——提高查询效率:设计数据库表结构时,我们首先要按照数据库的三大范式进行建立数据。1. 1NF每列不可拆分2. 2NF确保每个表只做一件事情3. 3NF满足2NF,消除表中的依赖传递。三大范式的出现是在上世纪70年代,由于内存资源比较昂贵,所以严格按照三大范式进行数据库设计。而如今内存变得越来越廉价,在考虑效率和内存的基础上我们可以做出最优选择以达到最高效率。_数据库为什么能提高效率
随便推点
HTML标签分类及转义字符_ol是单标记还是双标记-程序员宅基地
文章浏览阅读302次。一. HTML标签分类1.根据标签个数分类。 单标签:只有一个标签。 <br>, <hr>,<img>,<meta>, 实现一个特定的功能。 双标签:既有开始标签,也有结束标签。 Html,head,Body,title,h1~h6,p,a,ul,li,ol,strong,em。2.根据标签特性分类(网页效果)。 2.1行属性..._ol是单标记还是双标记
什么是配置_基于配置是什么意思-程序员宅基地
文章浏览阅读1.6k次。应用程序在启动和运行的时候往往需要读取一些配置信息,配置基本上伴随着应用程序的整个生命周期,比如:数 据库连接参数、启动参数等。配置主要有以下几个特点:配置是独立于程序的只读变量配置对于程序是只读的,程序通过读取配置来改变自己的行为,但是程序不应该去改变配置配置伴随应用的整个生命周期配置贯穿于应用的整个生命周期,应用在启动时通过读取配置来初始化,在运行时根据配置调整行为。比如:启动时需要读取服务的端口号、系统在运行过程中需要读取定时策略执行定时任务等。配置可以有多种加载方式常见的有程序内部_基于配置是什么意思
二、使用GObject——一个简单类的实现-程序员宅基地
文章浏览阅读170次。Glib库实现了一个非常重要的基础类--GObject,这个类中封装了许多我们在定义和实现类时经常用到的机制: 引用计数式的内存管理 对象的构造与析构 通用的属性(Property)机制 Signal的简单使用方式 很多使用GObject..._
golang 定时任务处理-程序员宅基地
文章浏览阅读6.3k次,点赞2次,收藏9次。在 golang 中若写定时脚本,有两种实现。一、基于原生语法组装func DocSyncTaskCronJob() { ticker := time.NewTicker(time.Minute * 5) // 每分钟执行一次 for range ticker.C { ProcTask() }}func ProcTask() { log.Println("hello world")}二、基于 github 中封装的 cron 库实现package taskimport (_golang 定时任务
VC获取精确时间的方法_vc 通过线程和 sleep 获取精准时间-程序员宅基地
文章浏览阅读2.1k次。 来源:http://blog.csdn.net/clever101/archive/2008/10/18/3096049.aspx 声明:本文章是我整合网上的资料而成的,其中的大部分文字不是我所为的,我所起的作用只是归纳整理并添加我的一些看法。非常感谢引用到的文字的作者的辛勤劳动,所参考的文献在文章最后我已一一列出。 对关注性能的程序开发人员而言,一个好的计时部件既是益友,也_vc 通过线程和 sleep 获取精准时间
wml入门-程序员宅基地
文章浏览阅读58次。公司突然说要进行wap开发了,以前从没了解过,但我却异常的兴奋,因为可以学习新东西了,呵呵,我们大家一起努力吧。首先说说环境的搭建。可以把.wml的文件看做是另一种的html进行信息的展示,但并不是所有的浏览器都支持,好用的有Opera,还有WinWap。编写wml文件语法比较严格,不好的是我还没有找到好的提示工具,就先用纯文本吧。我找到了一个很好的学习网站:http://w3sc..._winwap学习