Python 实现日志监控_python监控日志脚本-程序员宅基地
日志监控,是一种外挂式的采集。通过读取进程打印的日志,来进行监控数据的采集与汇聚计算。汇聚成标准的时间序列数据之后,推送给统一的后端存储。日志监控是一种典型的应用、业务监控的手段,如果我们没法在应用程序里内嵌SDK埋点,使用日志监控不失为一种折中方案。
这么说好像还不太明白日志监控到底能够做什么,简单点就是说就是对程序的日志内容进行过滤,如果出现了我们设定的关键字,对其进行计数当达到一定数量时可以触发报警。
下面来看一下需要哪些步骤:
1、不断的监听日志文件,获取最新的日志内容
2、正则功能对日志内容进行过滤
3、计数功能,触发报警
第一步的实现其实很简单,我参考了 python实现tail -f 功能 这篇文章有兴趣的话可以看一下。
思路是什么呢
-
打开一个文件,把指针移到最后。
-
每隔1秒钟获取一下日志内容
看一下代码吧
import time
import sys
file = '/Users/cyt/work/my_python/script/logMonitoring/test.txt'
with open(file,'r') as f:
f.seek(0,2)
while True:
line = f.readline()
if line and line!= '\n': #空行不打印
sys.stdout.write(line)
time.sleep(1)
这样就可以实现一个不断监听日志文件并打印最新内容的功能了
代码中用到了seek , stdout.write。stdout.write 和 print 的区别就是 print 会打印换行符,stdout.write 打印换行符。
在上面的代码中
sys.stdout.write(line)
#等同
line.strip()
print(line)
这里有个问题,那就是 sleep(1) 当我们同时写入多行内容到一个文件时,会一行一行很慢的打印出来。你可以把时间调小一点,但下面会说一个更好的方法。(你会说直接不用sleep不就行了,你可以尝试一下,然后观察该进程在系统中的cpu使用率)
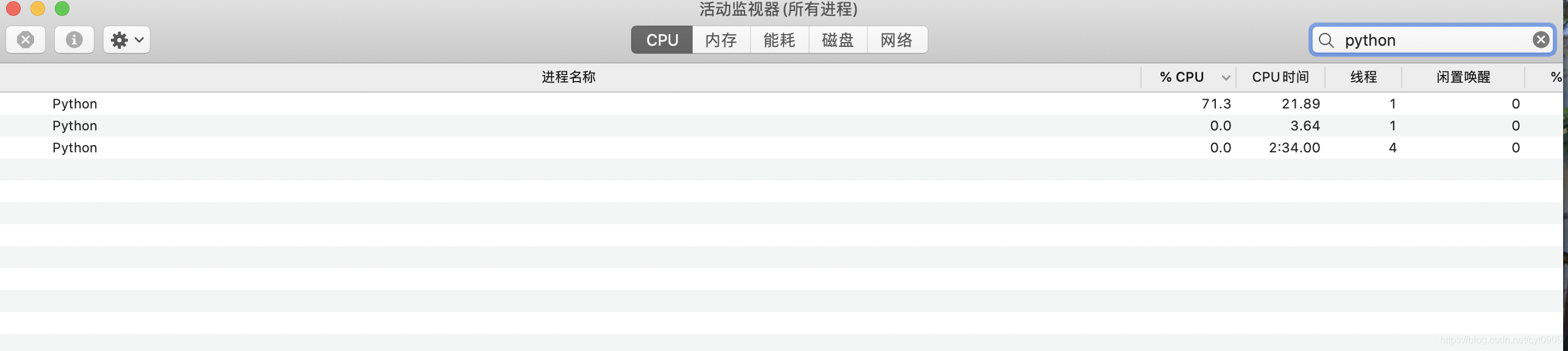
你哪怕设置为0.1 都要比不设置sleep好很多,下图是设置为0.1的效果
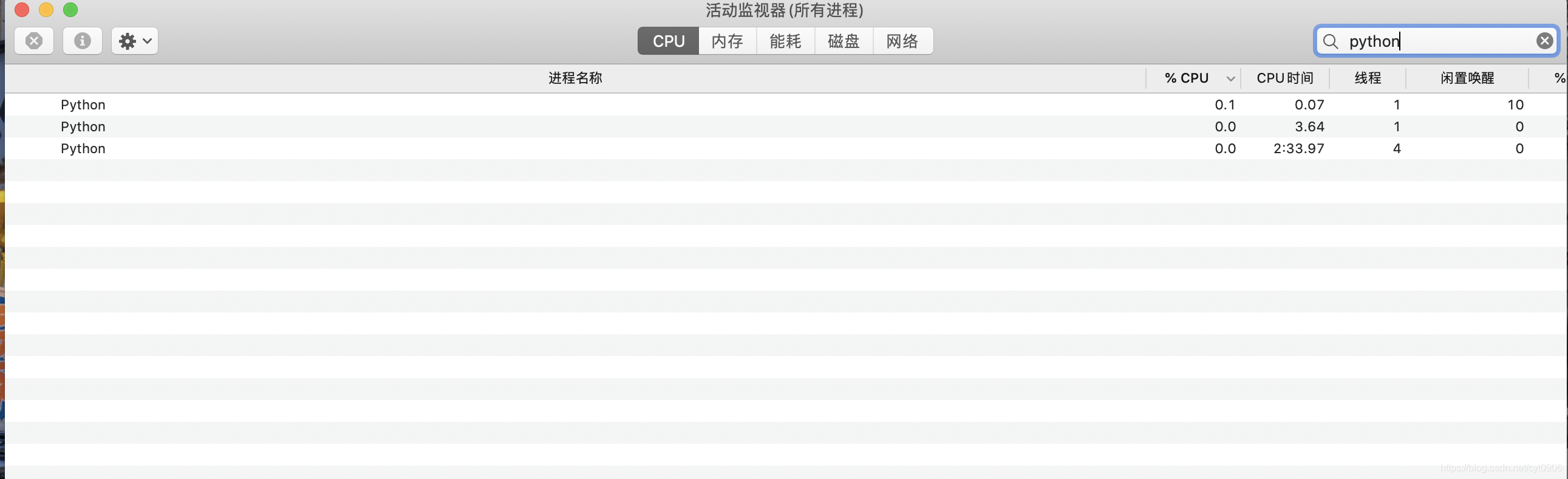
使用类实现上面的逻辑,并改进打印速度的问题。
class LogMonitoring():
def __init__(self,file_name):
self.__file_name = file_name
def source(self):
with open(self.__file_name) as f:
f.seek(0,2)
while True:
data = f.readlines()
# 可以添加日志量的监控,如果line列表越长说明单位时间产生的日志越多
# print(len(line))
for line in data:
if line != '\n': #空行不处理
sys.stdout.write(line)
time.sleep(1)
file = '/Users/cyt/work/my_python/script/logMonitoring/test.txt'
test = LogMonitoring(file)
test.source()
如何解决刚刚说过的那个问题呢,很简单把f.readline() 替换为 f.readlines()区别想必很多人都知道,这里再说明一下。前者每次获取一行内容,后者是获取到当前指针到末尾所有的内容,返回一个列表每一个列表元素就是一行内容。然后我们遍历这个列表,输出列表元素就可以了。
这个速度是非常快的,相当于不加sleep的速度,其实就算你设置sleep为0.1 如果一下写入上千行内容,那么要近两分钟的时间才能打印完(0.1 * 1000 =100s)。
然后你还可以使用len(line) 获取列表长度,以此来获取单位时间内产生日志的数量,这个单位时间就是sleep的时间。这个单位时间内产生的日志数量,这个指标在某些需求中很有用。
你不用担心列表会占用大量内存的问题,即使是一个长度为1000的列表也不会占用大量的内存(几MB吧),况且应该很难遇到1秒中写入这么多日志的情况吧,即使有也很好解决,调短sleep的时间。或者你可以测试一下一个长度1万的列表会占用多大的内存。使用sys.getsizeof 可以自己玩一下。
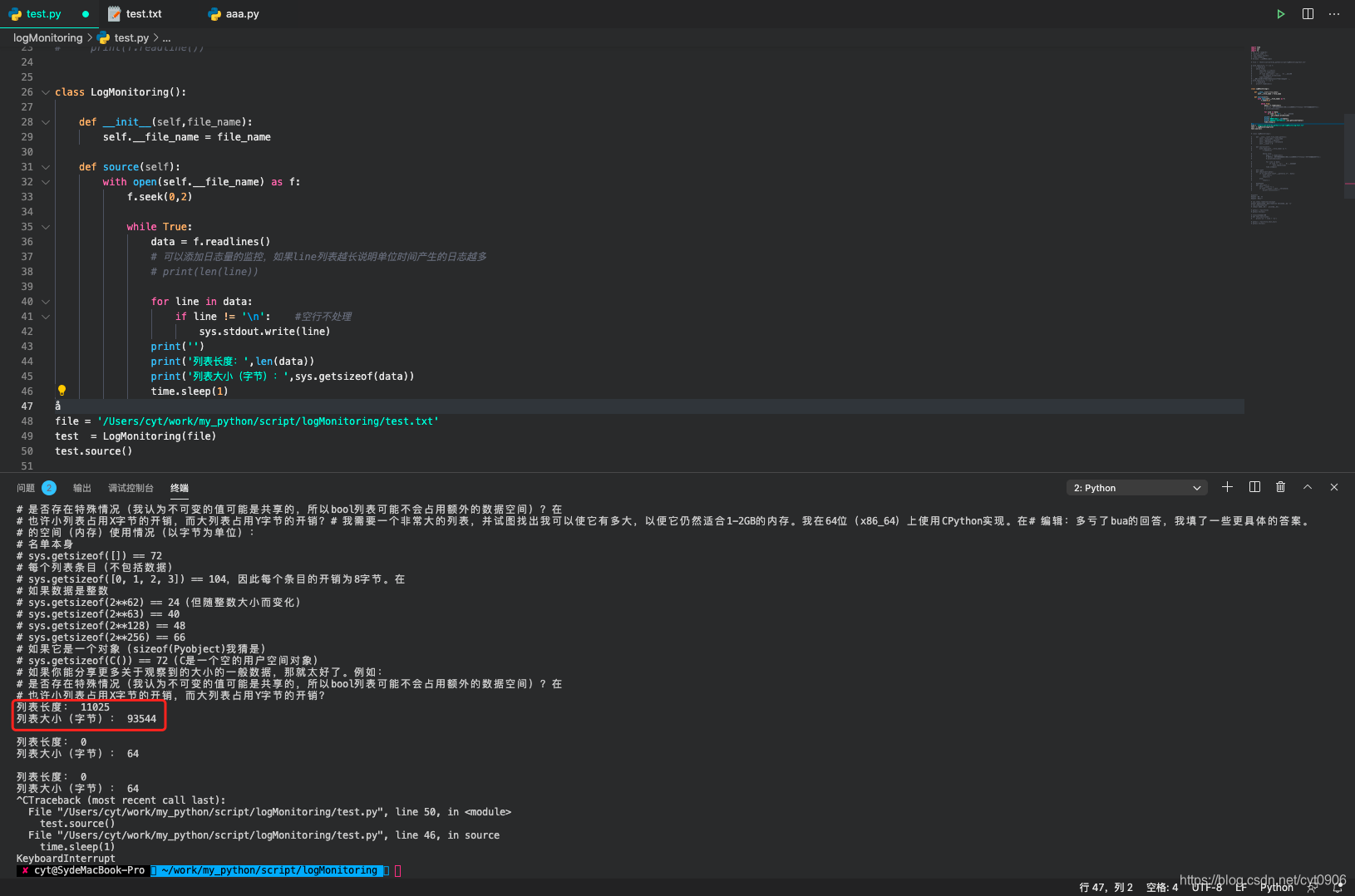
到这里第一个问题应该算是搞定了
剩下的的两个我先把完整代码贴出来再一起说吧
class LogMonitoring():
def __init__(self,file_name,pattern,threshold):
self.__file_name = file_name
self.__pattern = pattern
self.__threshold = threshold
self.__count = 0
def source(self):
with open(self.__file_name) as f:
f.seek(0,2)
while True:
data = f.readlines()
# 可以添加日志量的监控,如果line列表越长说明单位时间产生的日志越多
# print(len(line))
for line in data:
if line != '\n': #空行不处理
self.check(line)
time.sleep(1)
#匹配规则
def check(self,data):
if re.search(f'{
self.__pattern}.*?', data):
self.call()
return 0
else:
return 1
#报警规则
def call(self,):
self.__count += 1
if self.__count > self.__threshold:
print('***********')
调用逻辑就是,source获取日志内容,把内容给到check方法去过滤如果匹配设置的规则,那么调用call方法进行计数并判断计算器是否超过阀值。
这两个功能我没有测试(因为我突然发现我要做的不是这个东西),整个逻辑就是这样了。
正则的使用可以看这两篇文章: Python 中的正则表达式 和 正则表达式
最后说一些可以优化的点吧。
1、call 报警规则哪里可以完善一下,添加自己想要的告警规则,还可以在写一个告警途径,发挥自己的想象。或者你这里只需要有一个计数的功能,返回计数器的值,结合现成的监控系统去做监控(zabbix就OK)
2、可以建一个单独的配置文件 conf.py ,文件的路径、正则表达式的规则,匹配规则、报警规则等等都可以在这里配置
3、还有一个问题就是程序运行的过程中,日志被备份清空或者切割了,怎么处理。其实很简单,你维护一个指针位置,如果下次循环发现文件指针位置变了(tell()方法返回文件的当前位置,即文件指针当前位置。),从最新的指针位置开始读就行
4、可以考虑使用异步(协程)、线程来提高速度。
这是滴滴开源监控系统夜莺的日志监控,可以参考一下它的功能,使用go语言实现的。
智能推荐
WCE Windows hash抓取工具 教程_wce.exe -s aaa:win-9r7tfgsiqkf:0000000000000000000-程序员宅基地
文章浏览阅读6.9k次。WCE 下载地址:链接:https://share.weiyun.com/5MqXW47 密码:bdpqku工具界面_wce.exe -s aaa:win-9r7tfgsiqkf:00000000000000000000000000000000:a658974b892e
各种“网络地球仪”-程序员宅基地
文章浏览阅读4.5k次。Weather Globe(Mackiev)Google Earth(Google)Virtual Earth(Microsoft)World Wind(NASA)Skyline Globe(Skylinesoft)ArcGISExplorer(ESRI)国内LTEarth(灵图)、GeoGlobe(吉奥)、EV-Globe(国遥新天地) 软件名称: 3D Weather Globe(http:/_网络地球仪
程序员的办公桌上,都出现过哪些神奇的玩意儿 ~_程序员展示刀,产品经理展示枪-程序员宅基地
文章浏览阅读1.9w次,点赞113次,收藏57次。我要买这些东西,然后震惊整个办公室_程序员展示刀,产品经理展示枪
霍尔信号、编码器信号与电机转向-程序员宅基地
文章浏览阅读1.6w次,点赞7次,收藏63次。霍尔信号、编码器信号与电机转向从电机出轴方向看去,电机轴逆时针转动,霍尔信号的序列为编码器信号的序列为将霍尔信号按照H3 H2 H1的顺序组成三位二进制数,则霍尔信号翻译成状态为以120°放置霍尔为例如不给电机加电,使用示波器测量三个霍尔信号和电机三相反电动势,按照上面所说的方向用手转动电机得到下图① H1的上升沿对应电机q轴与H1位置电角度夹角为0°,..._霍尔信号
个人微信淘宝客返利机器人搭建教程_怎么自己制作返利机器人-程序员宅基地
文章浏览阅读7.1k次,点赞5次,收藏36次。个人微信淘宝客返利机器人搭建一篇教程全搞定天猫淘宝有优惠券和返利,仅天猫淘宝每年返利几十亿,你知道么?技巧分享:在天猫淘宝京东拼多多上挑选好产品后,按住标题文字后“复制链接”,把复制的淘口令或链接发给机器人,复制机器人返回优惠券口令或链接,再打开天猫或淘宝就能领取优惠券啦下面教你如何搭建一个类似阿可查券返利机器人搭建查券返利机器人前提条件1、注册微信公众号(订阅号、服务号皆可)2、开通阿里妈妈、京东联盟、拼多多联盟一、注册微信公众号https://mp.weixin.qq.com/cgi-b_怎么自己制作返利机器人
【团队技术知识分享 一】技术分享规范指南-程序员宅基地
文章浏览阅读2.1k次,点赞2次,收藏5次。技术分享时应秉持的基本原则:应有团队和个人、奉献者(统筹人)的概念,同时匹配团队激励、个人激励和最佳奉献者激励;团队应该打开工作内容边界,成员应该来自各内容方向;评分标准不应该过于模糊,否则没有意义,应由客观的基础分值以及分团队的主观综合结论得出。应有心愿单激励机制,促进大家共同聚焦到感兴趣的事情上;选题应有规范和框架,具体到某个小类,这样收获才有目标性,发布分享主题时大家才能快速判断是否是自己感兴趣的;流程和分享的模版应该有固定范式,避免随意的格式导致随意的内容,评分也应该部分参考于此;参会原则,应有_技术分享
随便推点
[Lua]table使用随笔-程序员宅基地
文章浏览阅读222次。table是lua中非常重要的一种类型,有必要对其多了解一些。
JAVA反射机制原理及应用和类加载详解-程序员宅基地
文章浏览阅读549次,点赞30次,收藏9次。我们前面学习都有一个概念,被private封装的资源只能类内部访问,外部是不行的,但这个规定被反射赤裸裸的打破了。反射就像一面镜子,它可以清楚看到类的完整结构信息,可以在运行时动态获取类的信息,创建对象以及调用对象的属性和方法。
Linux-LVM与磁盘配额-程序员宅基地
文章浏览阅读1.1k次,点赞35次,收藏12次。Logical Volume Manager,逻辑卷管理能够在保持现有数据不变的情况下动态调整磁盘容量,从而提高磁盘管理的灵活性/boot分区用于存放引导文件,不能基于LVM创建PV(物理卷):基于硬盘或分区设备创建而来,生成N多个PE,PE默认大小4M物理卷是LVM机制的基本存储设备,通常对应为一个普通分区或整个硬盘。创建物理卷时,会在分区或硬盘的头部创建一个保留区块,用于记录 LVM 的属性,并把存储空间分割成默认大小为 4MB 的基本单元(PE),从而构成物理卷。
车充产品UL2089安规测试项目介绍-程序员宅基地
文章浏览阅读379次,点赞7次,收藏10次。4、Dielecteic voltage-withstand test 介电耐压试验。1、Maximum output voltage test 输出电压试验。6、Resistance to crushing test 抗压碎试验。8、Push-back relief test 阻力缓解试验。7、Strain relief test 应变消除试验。2、Power input test 功率输入试验。3、Temperature test 高低温试验。5、Abnormal test 故障试验。
IMX6ULL系统移植篇-系统烧写原理说明_正点原子 imx6ull nand 烧录-程序员宅基地
文章浏览阅读535次。镜像烧写说明_正点原子 imx6ull nand 烧录
Gradle配置阿里云Maven镜像仓库地址_gradle 配置阿里镜像-程序员宅基地
文章浏览阅读1.8k次。搭建maven本地仓库参考博客_gradle 配置阿里镜像