数据治理 Python桑基图处理表关系_sankey is a dag, the original data has cycle!-程序员宅基地
技术标签: python 数据仓库 数据治理 血缘关系 数据可视化 Python
数据治理 Python桑基图处理表关系
需求
随着hive库表越来越多,调度出问题后,排查时间越来越长。计划通过桑基图以及血缘图谱解决,当前先用桑基图页面顶一段时间。后期做成web服务,如果有可能,尽量嵌入到hive metastore
预期
- 桑基图:
业务DB/中间件 – ods – cdm – ads – 大数据服务DB
- 图谱:
业务DB/中间件 – 调度 – ods – 调度 – cdm – 调度 – ads – 调度 – 大数据服务DB
环境与版本
- Anaconda – Python3.6
- IED – PyCharm
- 前端可视化图表 – echarts(pycharts 1.+)
数据处理
整理hive表
方案一: 从hive metastore关联表获取(DBS + TBLS)
## 所有库表一次获取
SELECT concat(b.NAME,'.',a.TBL_NAME) FROM TBLS a
LEFT JOIN DBS b ON a.DB_ID = b.DB_ID;
方案二: 从hdfs 获取
## 分库表多次获取
hadoop fs -ls /user/hive/warehouse/tmp.db/ | awk -F ' ' '{print $8}' | sed 's/\/user\/hive\/warehouse\/tmp\.db\//tmp\./g'
方案三: 从hive客户端获取
## 分库表多次获取
use tmp; # a库,b库...
show tables;
整理表间关系
- 通过步骤【整理hive表】拿到表,找到代码里的管理关系
比如a与b关联,生成c, c与d关联生成e
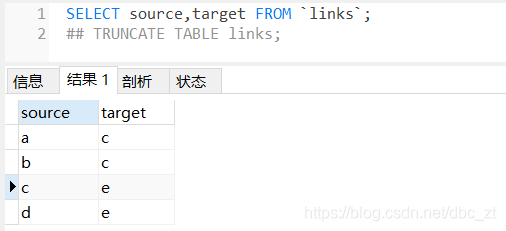
| source | target |
|---|---|
| a | c |
| b | c |
| c | f |
| d | f |
- 将如上数据插入mysql
CREATE TABLE `links` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`source` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL,
`target` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL,
`is_deleted` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL,
`gmt_create` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
SELECT source,target FROM `links`;
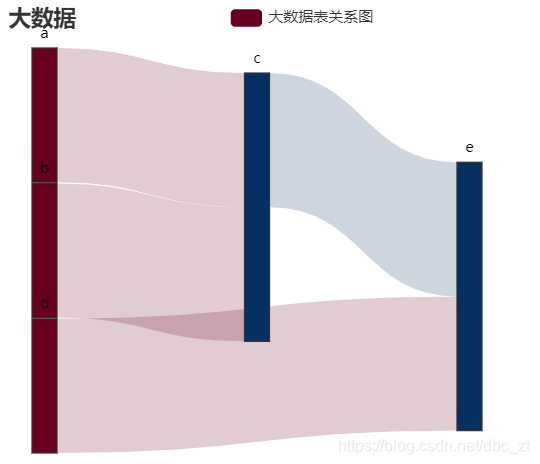
Python可视化
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import pymysql
import pandas as pd
import json
from pyecharts.charts import Sankey
from pyecharts import options as opts
# 获取数据库数据
def load_links_frame_from_mysql():
conn = pymysql.connect(host="127.0.0.1",
port=3306,
user="账号",
password="密码",
db="数据库",
charset="utf8")
sql = "SELECT source,target FROM links"
data_frame = pd.read_sql(sql, conn)
conn.close()
return data_frame
# 获取nodes
def get_nodes(df):
nodes = []
for value in pd.concat([df['target'],df['source']]).unique():
dic = {
}
dic['name'] = value
nodes.append(dic)
return nodes
# 获取links
def get_links(df):
links = []
for i in df.values:
links.append({
'source': i[0], 'target': i[1], 'value': 1})
return links
if __name__=="__main__":
link = load_links_frame_from_mysql()
colors = [
"#67001f",
"#b2182b",
"#d6604d",
"#f4a582",
"#fddbc7",
"#d1e5f0",
"#92c5de",
"#4393c3",
"#2166ac",
"#053061"]
pic = (
Sankey(init_opts=opts.InitOpts(width="480px",height="720px")).set_colors(colors)
.add('大数据表关系图',
get_nodes(link),
get_links(link),
pos_bottom="50%",
focus_node_adjacency="allEdges",
linestyle_opt=opts.LineStyleOpts(opacity=0.2, curve=0.5, color='source'),
label_opts=opts.LabelOpts(position='top'),
node_gap=1,
)
.set_global_opts(title_opts=opts.TitleOpts(title='大数据'))
)
pic.render('xueyuan_sankey.html')
实际使用中的报错
- Cannot set property ‘dataIndex’ of undefined
此错误由重复数据引起
- Sankey is a DAG, the original data has cycle!
此错误为 source 与 target数据相同引起
参考
- echarts桑基图
- echarts关系图
- 桑基图有何作用,桑基图又是怎么做出来的
- 数据可视化 Python实现Sankey桑基图
- Vue+D3.js实现桑基图 流向图
- Python绘制桑基图之可视化神器pyecharts
- springboot2.0+Neo4j+d3.js构建知识图谱
- 基于Python 利用桑基图
- 用Python绘制诱人的桑基图
- D3.js数据可视化实战
- Sankey图的制作
- Apache Atlas元数据血缘关系(Lineage)功能研究
- 使用Apache Atlas 2.0.0解决数据溯源问题
- python可视化动态图表: 关于pyecharts的sankey桑基图绘制
- pyecharts初步认识
补充
- 后期调色忽略,图谱后期再处理;
- 有相关数据治理方面的,可以相互探讨和学习
智能推荐
python difflib 编辑距离_Python Edit_Distance包_程序模块 - PyPI - Python中文网-程序员宅基地
文章浏览阅读413次。编辑距离用于计算序列之间编辑距离和对齐的python模块。我需要一种方法来计算python中序列之间的编辑距离。我没有能够找到任何合适的库来实现这一点,所以我自己编写了一个。在那里似乎有许多可用于计算编辑的编辑距离库两个字符串之间的距离,但不是两个序列之间的距离。这完全是用python编写的。这种实现可能是在python中优化为更快。如果在C中实现。库API是根据difflib.sequencem..._edit distance python lib
antd upload组件 手动上传-程序员宅基地
文章浏览阅读3.8k次,点赞2次,收藏15次。antd 的upload组件是点开对话框后,按下确实就会上传,而且如果多选文件也会反复调用后端接口来完成上传。因为项目需要,所以要实现手动上传,和一次性上传多个文件(调用一次后端接口)在实现这个功能时,我翻阅了很多博客,可能是因为版本原因,很多代码都无用,最后还是通过翻阅官方文档,才最终实现。..._antd upload
sqlite3 环境搭建_sqlite 部署-程序员宅基地
文章浏览阅读246次。注意 第一步在一个文件下打开终端然后 sqlite3 student.db(创建一个数据库),然后再create stu。callback 回调函数 (只有sql为查询语句的时候,才会执行此语句)6--删除一列(sqlite3 不支持) 用下面方法。功能 :打开sqlite 数据库。功能 :关闭sqlite 数据库。基本sql命令,不以 . 夹头,db:指向sqlite句柄的指针。将新表的名字改为原来表的名字。sqlite3的基本命令。功能:执行一条sql语句。以 . 开头的命令。_sqlite 部署
canal-adapter趟坑实践:canal-server的kafka SASLPLAIN方式鉴权适配_canal adapter kafka sasl-程序员宅基地
文章浏览阅读1.4w次。前言canal-server同步到kafka本身是支持Kerberos方式的鉴权的,但是鉴于项目现在使用的kafka集群使用的是SASL/PLAIN的鉴权方式,所以需要对canal-server同步kafka做一下适配改造。准备kafka SASL/PLAIN鉴权的搭建我参考的这篇文章kafka SASL/PLAIN鉴权的搭建了解如何使用java向以SASL/PLAIN方式鉴权的kafk..._canal adapter kafka sasl
Android adb shell相关命令_android的shell命令工具:设备规范管理-程序员宅基地
文章浏览阅读711次。adb(调试桥):debug工具。adb作用:借助adb工具,可以管理设备或手机模拟器状态。adb相关操作命令如下: 1. 显示系统中全部Android平台: android list targets2. 显示系统中全部AVD(模拟器): android list avd3. 创建AVD(模拟器): android create avd_android的shell命令工具:设备规范管理
Centos 7.9 在线安装 VirtualBox 7.0_centos安装virtualbox-程序员宅基地
文章浏览阅读769次,点赞10次,收藏7次。Centos 7.9 在线安装 VirtualBox 7.0_centos安装virtualbox
随便推点
Autodesk官方卸载工具软件安装教程-程序员宅基地
文章浏览阅读1.4w次,点赞9次,收藏10次。Autodesk卸载工具是一个专门用于Autodesk软件的卸载工具,可以自动识别电脑中的所有Autodesk软件,只需一键点击就能将Autodesk的软件完美卸载,并且不保留任何痕迹,这款卸载工具就可以帮助用户全面卸载Autodesk软件。_autodesk官方卸载工具
JDBC报错:Cannot find class: com.mysql.jdbc.Driver-程序员宅基地
文章浏览阅读4.9k次。1.配置书写错误:配置文件value值引号内不能有空格,属性文件配置信息末尾不能有空格(1)打开属性文件中com.mysql.jdbc.Driver后发现多了一个空格(如下我标出了),所以写属性文件时一定别多输入多余的空格了。 jdbc.driverClassName=com.mysql.jdbc.Driver(此处有空格)(2)配置文件中的value值的" "号中前面或..._cannot find class: com.mysql.jdbc.driver
软件常用术语_软件术语-程序员宅基地
文章浏览阅读1.8k次。软件常用术语,免得你面对各种设计模式头发晕_软件术语
Machine Learning 2 - 非线性回归算法分析_非线性回归分析方法-程序员宅基地
文章浏览阅读2.8k次。2017-08-02@erixhao 技术极客TechBoosterAI 机器学习第二篇 - 非线形回归分析。我们上文深入本质了解了机器学习基础线性回归算法后,本文继续研究非线性回归。非线性回归在机器学习中并非热点,并且较为小众,且其应用范畴也不如其他广。鉴于此,我们本文也将较为简单的介绍,并不会深入展开。非线性回归之后,我们会继续经典机器学习算法包括决策_非线性回归分析方法
hive基本函数_josn mincol-程序员宅基地
文章浏览阅读164次。一、关系运算:1.等值比较: =语法:A=B操作类型:所有基本类型描述:如果表达式A与表达式B相等,则为TRUE;否则为FALSE举例:hive>select 1 from lxw_dual where 1=1;12.不等值比较: <>语法: A <> B操作类型:所有基本类型描述:如果表达式A为NULL,或者表..._josn mincol
FI 与SD MM相关接口配置_sd 和fi 接口产生什么凭证?-程序员宅基地
文章浏览阅读767次。1 FI/SD 借口配置FI/SD通过tcode VKOA为billing设置过帐科目,用户可以创建自己的科目定义数据表。 科目是做到COA级的,通过KOFI/KOFK这两个condition type确定分别过帐到FI和CO凭证中。 由于PricingProc.是同Sale_sd 和fi 接口产生什么凭证?