Flink 将数据写入MySQL(JDBC)_flink-connector-jdbc-程序员宅基地
一、写在前面
在实际的生产环境中,我们经常会把Flink处理的数据写入MySQL、Doris等数据库中,下面以MySQL为例,使用JDBC的方式将Flink的数据实时数据写入MySQL。
二、代码示例
2.1 版本说明
<flink.version>1.14.6</flink.version>
<spark.version>2.4.3</spark.version>
<hadoop.version>2.8.5</hadoop.version>
<hbase.version>1.4.9</hbase.version>
<hive.version>2.3.5</hive.version>
<java.version>1.8</java.version>
<scala.version>2.11.8</scala.version>
<mysql.version>8.0.22</mysql.version>
<scala.binary.version>2.11</scala.binary.version>
2.2 导入相关依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!--mysql连接器依赖-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.22</version>
</dependency>
2.3 连接数据库,创建表
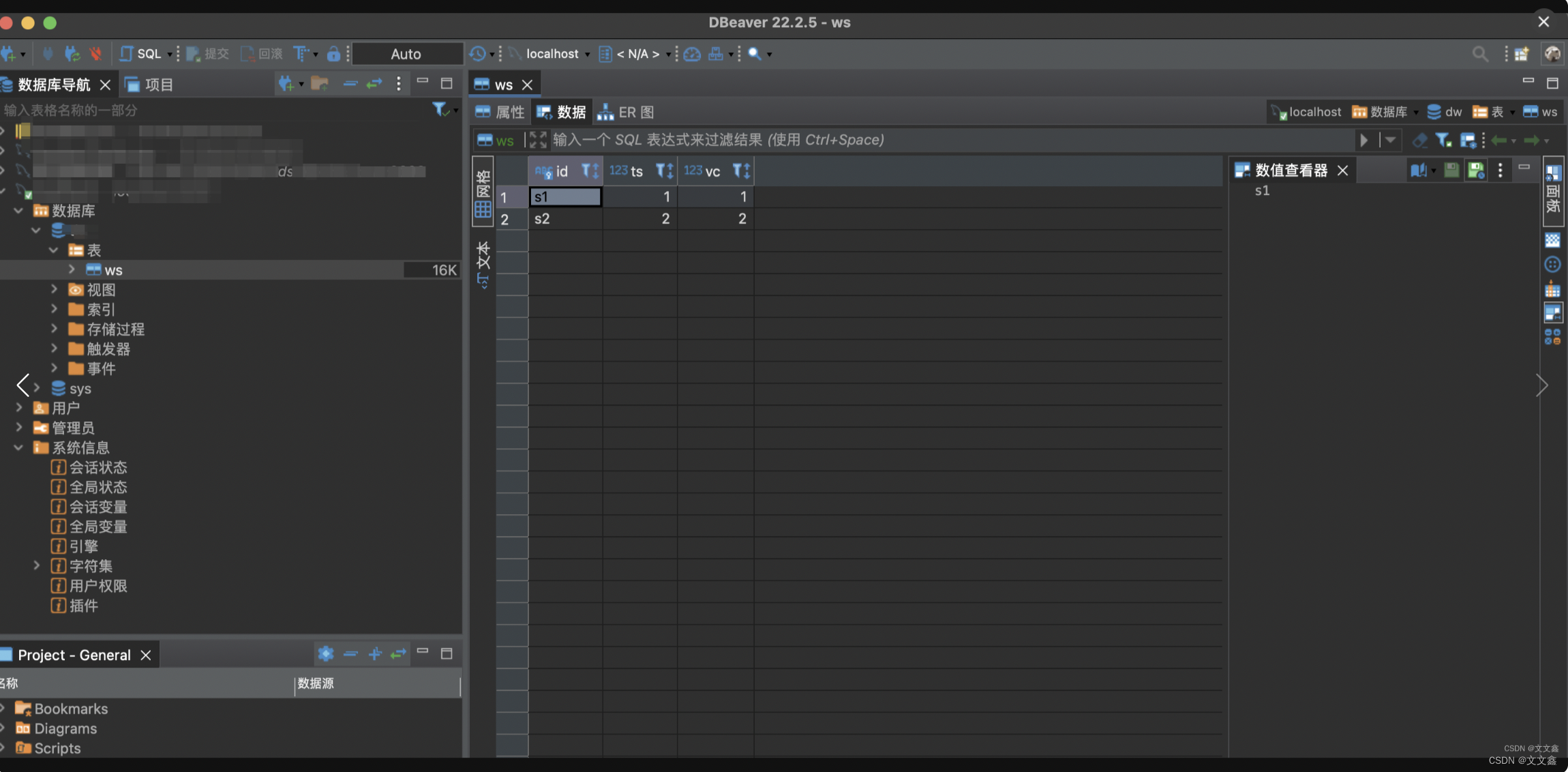
mysql> CREATE TABLE `ws` (
`id` varchar(100) NOT NULL
,`ts` bigint(20) DEFAULT NULL
,`vc` int(11) DEFAULT NULL, PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
2.4 创建POJO类
package com.flink.POJOs;
import java.util.Objects;
/**
* TODO POJO类的特点
* 类是公有(public)的
* 有一个无参的构造方法
* 所有属性都是公有(public)的
* 所有属性的类型都是可以序列化的
*/
public class WaterSensor {
//类的公共属性
public String id;
public Long ts;
public Integer vc;
//无参构造方法
public WaterSensor() {
//System.out.println("调用了无参数的构造方法");
}
public WaterSensor(String id, Long ts, Integer vc) {
this.id = id;
this.ts = ts;
this.vc = vc;
}
//生成get和set方法
public void setId(String id) {
this.id = id;
}
public void setTs(Long ts) {
this.ts = ts;
}
public void setVc(Integer vc) {
this.vc = vc;
}
public String getId() {
return id;
}
public Long getTs() {
return ts;
}
public Integer getVc() {
return vc;
}
//重写toString方法
@Override
public String toString() {
return "WaterSensor{" +
"id='" + id + '\'' +
", ts=" + ts +
", vc=" + vc +
'}';
}
//重写equals和hasCode方法
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
WaterSensor that = (WaterSensor) o;
return id.equals(that.id) && ts.equals(that.ts) && vc.equals(that.vc);
}
@Override
public int hashCode() {
return Objects.hash(id, ts, vc);
}
}
//scala的case类?
2.5 自定义map函数
package com.flink.POJOs;
import org.apache.flink.api.common.functions.MapFunction;
public class WaterSensorMapFunction implements MapFunction<String, WaterSensor> {
@Override
public WaterSensor map(String value) throws Exception {
String[] datas = value.split(",");
return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));
}
}
2.5 Flink2MySQL
package com.flink.DataStream.Sink;
import com.flink.POJOs.WaterSensor;
import com.flink.POJOs.WaterSensorMapFunction;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
* Flink 输出到 MySQL(JDBC)
*/
public class flinkSinkJdbc {
public static void main(String[] args) throws Exception {
//TODO 创建Flink上下文执行环境
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
streamExecutionEnvironment.setParallelism(1);
//TODO Source
DataStreamSource<String> dataStreamSource = streamExecutionEnvironment.socketTextStream("localhost", 8888);
//TODO Transfer
SingleOutputStreamOperator<WaterSensor> waterSensorSingleOutputStreamOperator = dataStreamSource.map(new WaterSensorMapFunction());
/**TODO 写入 mysql
* 1、只能用老的 sink 写法
* 2、JDBCSink 的 4 个参数:
* 第一个参数: 执行的 sql,一般就是 insert into
* 第二个参数: 预编译 sql, 对占位符填充值
* 第三个参数: 执行选项 ---->攒批、重试
* 第四个参数: 连接选项---->url、用户名、密码
*/
SinkFunction<WaterSensor> sinkFunction = JdbcSink.sink("insert into ws values(?,?,?)",
new JdbcStatementBuilder<WaterSensor>() {
@Override
public void accept(PreparedStatement preparedStatement, WaterSensor waterSensor) throws SQLException {
preparedStatement.setString(1, waterSensor.getId());
preparedStatement.setLong(2, waterSensor.getTs());
preparedStatement.setInt(3, waterSensor.getVc());
System.out.println("数据写入成功:"+'('+waterSensor.getId()+","+waterSensor.getTs()+","+waterSensor.getVc()+")");
}
}
, JdbcExecutionOptions
.builder()
.withMaxRetries(3) // 重试次数
.withBatchSize(100) // 批次的大小:条数
.withBatchIntervalMs(3000) // 批次的时间
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/dw?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8")
.withUsername("root")
.withPassword("********")
.withConnectionCheckTimeoutSeconds(60) // 重试的超时时间
.build()
);
//TODO 写入到Mysql
waterSensorSingleOutputStreamOperator.addSink(sinkFunction);
streamExecutionEnvironment.execute();
}
}
2.6 启动necat、Flink,观察数据库写入情况
nc -lk 9999 #启动necat、并监听8888端口,写入数据
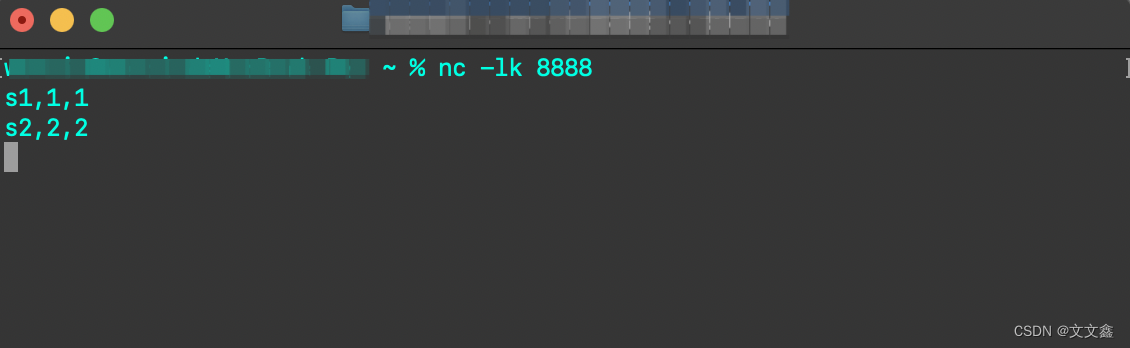
启动Flink程序
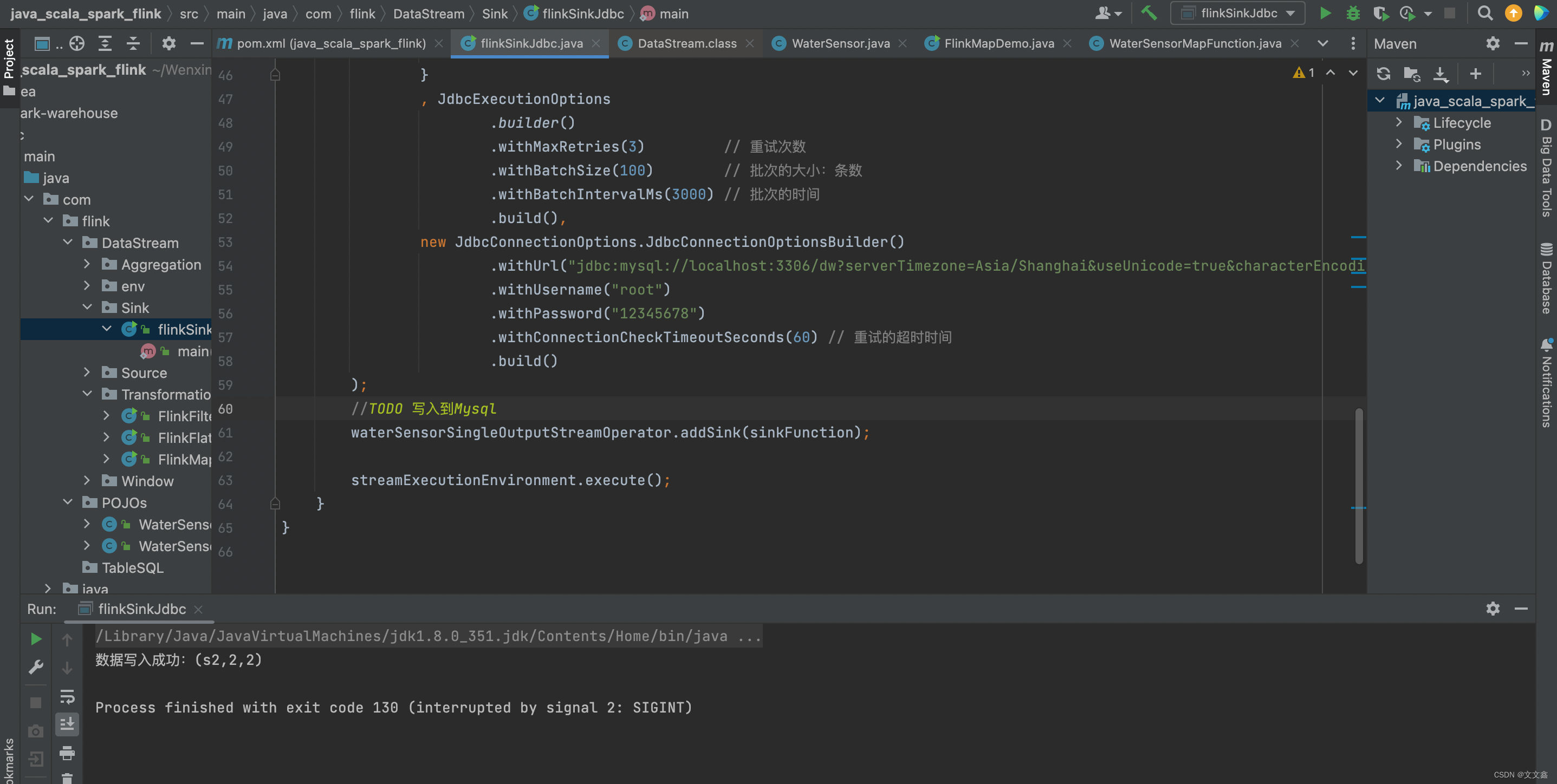
查看数据库写入是否正常
智能推荐
Eclipse中配置WebMagic(已配置好Maven)_使用eclipse搭建webmagic工程-程序员宅基地
文章浏览阅读364次。1.WebMagicWebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。2.在Eclipse中配置WebMagic1.首先需要下载WebMagic的压缩包官网地址为:WebMagic官网最新版本为:WebMagic-0.7.3,找到对应版本,打开下载界面,注意,下载要选择Source code(zip)版本,随便下载到哪里都可以;2.下载好的压缩包需要解压,此时解压到的位置即为后续新建的Eclipse的project位置,比如我的Ecli_使用eclipse搭建webmagic工程
linux启动mysql_linux如何启动mysql服务_linux启动mysql服务命令是什么-系统城-程序员宅基地
文章浏览阅读1.9k次。mysql数据库是一种开放源代码的关系型数据库管理系统,有很多朋友都在使用。一些在linux系统上安装了mysql数据库的朋友,却不知道该如何对mysql数据库进行配置。那么linux该如何启动mysql服务呢?接下来小编就给大家带来linux启动mysql服务的命令教程。具体步骤如下:1、首先,我们需要修改mysql的配置文件,一般文件存放在/etc下面,文件名为my.cnf。2、对于mysql..._linux中 mysql 启动服务命令
php实现在线oj,详解OJ(Online Judge)中PHP代码的提交方法及要点-程序员宅基地
文章浏览阅读537次。详解OJ(Online Judge)中PHP代码的提交方法及要点Introduction of How to submit PHP code to Online Judge SystemsIntroduction of How to commit submission in PHP to Online Judge Systems在目前常用的在线oj中,codeforces、spoj、uva、zoj..._while(fscanf(stdin, "%d %d", $a, $b) == 2)
java快捷键调字体_设置MyEclipse编码、补全快捷键、字体大小-程序员宅基地
文章浏览阅读534次。一、设置MyEclipse编码(1)修改工作空间的编码方式:Window-->Preferences-->General-->Workspace-->Text file encoding(2)修改一类文件的编码方式:Window-->Preferences-->General-->content Types-->修改default Encoding(..._java修改快捷缩写内容
解析蓝牙原理_蓝牙原理图详解-程序员宅基地
文章浏览阅读1.4w次,点赞19次,收藏76次。1.前言市面上关于Android的技术书籍很多,几乎每本书也都会涉及到蓝牙开发,但均是上层应用级别的,而且篇幅也普遍短小。对于手机行业的开发者,要进行蓝牙模块的维护,就必须从Android系统底层,至少框架层开始,了解蓝牙的结构和代码实现原理。这方面的文档、网上的各个论坛的相关资料却少之又少。分析原因,大概因为虽然蓝牙协议是完整的,但是并没有具体的实现。蓝牙芯片公司只负责提供最底层的API_蓝牙原理图详解
从未在一起更让人遗憾_“从未在一起和最终没有在一起哪个更遗憾”-程序员宅基地
文章浏览阅读7.7k次。图/源于网络文/曲尚菇凉1.今天早上出门去逛街,在那家冰雪融城店里等待冰淇淋的时候,听到旁边两个女生在讨论很久之前的一期《奇葩说》。那期节目主持人给的辩论题是“从未在一起和最终没有在一起哪个更遗憾”,旁边其中一个女生说,她记得当时印象最深的是有个女孩子说了这样一句话。她说:“如果我喜欢一个人呢,我就从第一眼到最后一眼,把这个人爱够,把我的感觉用光,我只希望那些年让我成长的人是他,之后的那些年他喝过..._从未在一起更遗憾
随便推点
Spring Cloud Alibaba 介绍_sprngcloud alba-程序员宅基地
文章浏览阅读175次。Spring Cloud Alibaba 介绍Sping体系Spring 以 Bean(对象) 为中心,提供 IOC、AOP 等功能。Spring Boot 以 Application(应用) 为中心,提供自动配置、监控等功能。Spring Cloud 以 Service(服务) 为中心,提供服务的注册与发现、服务的调用与负载均衡等功能。Sping Cloud介绍官方介绍 Tools for building common patterns in distributed systems_sprngcloud alba
测试 数据类型的一些测试点和经验_基础字段的测试点-程序员宅基地
文章浏览阅读3.2k次,点赞4次,收藏21次。我这里是根据之前在测试数据类项目过程中的一些总结经验和掉过个坑,记录一下,可以给其他人做个参考,没什么高深的东西,但是如果不注意这些细节点,后期也许会陷入无尽的扯皮当中。1 需求实现的准确度根据产品需求文档描述发现不明确不详细的或者存在歧义的地方一定要确认,例如数据表中的一些字段,与开发和产品确认一遍,如有第三方相关的,要和第三方确认,数据类项目需要的是细心,哪怕数据库中的一个字段如果没有提前对清楚,后期再重新补充,会投入更大的精力。2 数据的合理性根据业务场景/常识推理,提..._基础字段的测试点
一文看懂:行业分析怎么做?_码工小熊-程序员宅基地
文章浏览阅读491次。大家好,我是爱学习的小xiong熊妹。在工作和面试中,很多小伙伴会遇到“对XX行业进行分析”的要求。一听“行业分析”四个字,好多人会觉得特别高大上,不知道该怎么做。今天给大家一个懒人攻略,小伙伴们可以快速上手哦。一、什么是行业?在做数据分析的时候,“行业”两个字,一般指的是:围绕一个商品,从生产到销售相关的全部企业。以化妆品为例,站在消费者角度,就是简简单单的从商店里买了一支唇膏回去。可站在行业角度,从生产到销售,有相当多的企业在参与工作(如下图)在行业中,每个企业常常扮._码工小熊
LLaMA 简介:一个基础的、650 亿参数的大型语言模型_llma-程序员宅基地
文章浏览阅读1.6w次,点赞2次,收藏2次。还需要做更多的研究来解决大型语言模型中的偏见、有毒评论和幻觉的风险。我们在数万亿个令牌上训练我们的模型,并表明可以仅使用公开可用的数据集来训练最先进的模型,而无需诉诸专有和不可访问的数据集。在大型语言模型空间中训练像 LLaMA 这样的小型基础模型是可取的,因为它需要更少的计算能力和资源来测试新方法、验证他人的工作和探索新的用例。作为 Meta 对开放科学承诺的一部分,今天我们公开发布 LLaMA(大型语言模型元 AI),这是一种最先进的基础大型语言模型,旨在帮助研究人员推进他们在 AI 子领域的工作。_llma
强化学习在制造业领域的应用:智能制造的未来-程序员宅基地
文章浏览阅读223次,点赞3次,收藏5次。1.背景介绍制造业是国家经济发展的重要引擎,其产能和质量对于国家经济的稳定和发展具有重要意义。随着工业技术的不断发展,制造业的生产方式也不断发生变化。传统的制造业通常依赖于人工操作和手工艺,这种方式的缺点是低效率、低产量和不稳定的质量。随着信息化、智能化和网络化等新技术的出现,制造业开始向智能制造迈出了第一步。智能制造的核心是通过大数据、人工智能、计算机视觉等技术,实现制造过程的智能化、自动化...
ansible--安装与使用_pip安装ansible-程序员宅基地
文章浏览阅读938次。系列文章目录文章目录系列文章目录 前言 一、ansible是什么? 二、使用步骤 1.引入库 2.读入数据 总结前言菜鸟一只,刚开始使用,仅作以后参考使用。边学习,边记录,介绍一下最基础的使用,可能会有理解不到位的地方,可以共同交流,废话不多说,走起。一、ansible 简介?ansible是自动化运维工具的一种,基于Python开发,可以实现批量系统配置,批量程序部署,批量运行命令,ansible是基于模块工作的,它本身没有批量部署的能力,真正.._pip安装ansible