Jetson Nano (八) PaddlePaddle 环境配置 PaddleHub—OCR测试_jetson nano ocr-程序员宅基地
技术标签: paddlepaddle Jetson linux 深度学习
Jetson Nano PaddlePaddle 环境配置 及 PaddleHub—OCR测试
文章目录
一.软硬件版本
Jetson Nano 4G
JP 4.4.1
CUDA 10.2
CUDNN 8.0
TensorRT 7.1.3.0
二.安装NCLL2
git clone https://github.com/NVIDIA/nccl.git
cd nccl
make -j4
sudo make install
此步编译过程很久。
已下为安装成功截图: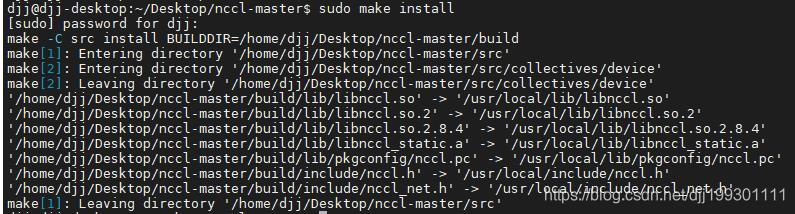
三.安装Paddlepaddle-gpu
##注意以下python环境安装强烈推荐在虚拟环境下操作##
- 3.1 下载paddle
git clone -b release/2.0 https://gitee.com/paddlepaddle/Paddle.git
- 3.2 CUDA 的环境变量配置,已经配置的跳过该步骤。
sudo vim ~/.bashrc
#在最后添加以下内容
export CUDA_HOME=/usr/local/cuda-10.2
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda-10.2/bin:$PATH
#保存生效一下
source ~/.bashrc
- 3.3 安装编译工具
sudo apt-get install unrar swig patchelf
- 3.4 编译
cd Paddle
#需要编译python包的话先安装下需要的库
pip install -r python/requirements.txt
mkdir build
cd build
cmake \
-DWITH_CONTRIB=OFF \
-DWITH_MKL=OFF \
-DWITH_MKLDNN=OFF \
-DWITH_TESTING=OFF \
-DCMAKE_BUILD_TYPE=Release \
-DON_INFER=ON \
-DWITH_PYTHON=ON \
-DWITH_XBYAK=OFF \
-DWITH_NV_JETSON=ON \
-DPY_VERSION=3.6 \
-DTENSORRT_ROOT=/home/djj/Tensorrt/ \
-DCUDA_ARCH_NAME=All \
..
#时间很久
make -j4
#生成预测lib
make inference_lib_dist
#python环境安装编译好的paddlepaddle-gpu的whl
pip install paddlepaddle*******.whl
填坑记录:
- 1.numpy没找到,卸载重装。
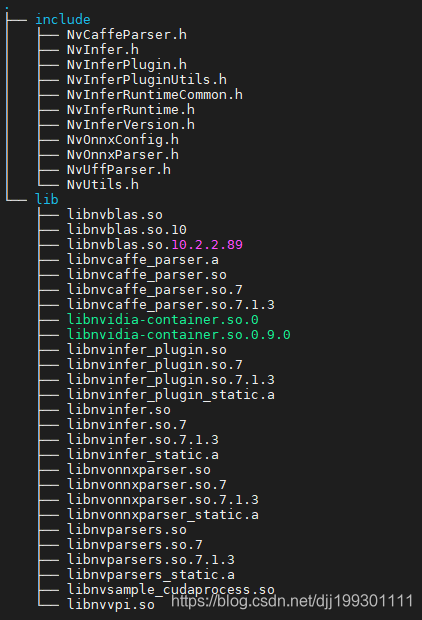
- 2.cmake使找不到CUPTI报错,通过拷贝TensorRT环境,来适应cmake文件的编译命令。拷贝后TensorRT呈现以下结构:
- 3.编译时三方库无法下载,本人在此步骤卡了2天,目前没找到可行方案。
四.测试
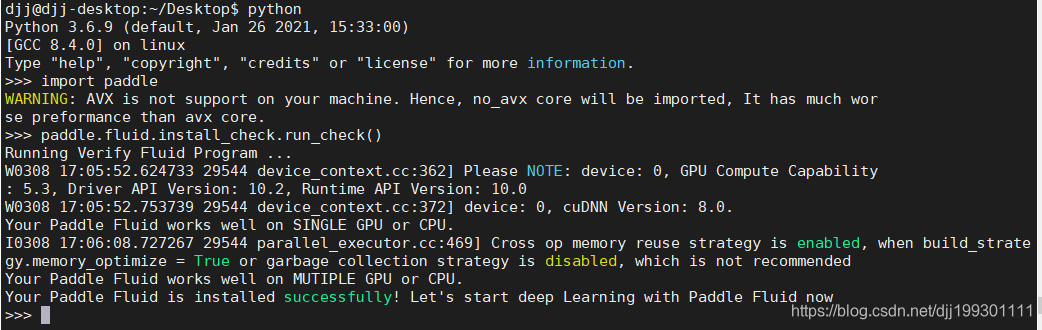
在python中测试,出现下图说明成功。
python
import paddle
#2.0以下API
paddle.fluid.install_check.run_check()
#2.0以上的API
paddle.utils.run_check()
五.pip安装方式whl包下载资源
- 百度云链接(版本:1.5.2,1.6.2,2.0.0):
链接:https://pan.baidu.com/s/1ZOaKk-tE77qWuIpYMhxnJg
提取码:ldql
- 官网下载链接:
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/Tables.html#whl-release
六.PaddleHub 安装/测试
- 首先需要安装sentencepiece
源码编译安装sentencepiece,编译环境安装:
sudo apt-get install cmake build-essential pkg-config libgoogle-perftools-dev
然后进行源码编译:
https://github.com/google/sentencepiece
下载源码包 sentencepiece-master.zip
unzip sentencepiece-master.zip
cd sentencepiece
mkdir build
cd build
cmake ..
make -j4
sudo make install
sudo ldconfig -v
pip install scipy==1.3.1
#这里我安装的1.8版本
pip install paddlehub==1.8.0
安装成功后python下测试 import paddlehub 会出现缺少库的错误pip安装即可
- 测试超轻量级中文OCR模型
安装ocr依赖
sudo apt-get install libgeos-dev
sudo apt-get install python3-shapely
pip install shapely==1.6.2
pip install pyclipper
conda install geos
#使用hub下载模型
##韩文的##
hub install korean_ocr_db_crnn_mobile==1.0.0
##中文的##
hub install chinese_ocr_db_crnn_mobile==1.1.0
- 简单测试命令,测试环境是否正确
hub run chinese_ocr_db_crnn_mobile --input_path "/PATH/TO/IMAGE"
- 这里使用cpu可以正常推理,使用GPU的话需要改下源码,OCR源码中申请了8G显存。。。
- 不需要使用GPU的直接跳到 测试代码 步骤即可。
直接使用GPU这里会报错:
E0318 13:28:24.483968 4564 analysis_predictor.cc:585] Allocate too much memory for the GPU memory pool, assigned 8000 MB
E0318 13:28:24.484027 4564 analysis_predictor.cc:588] Try to shink the value by setting Analysis Config::EnableGpu(...)
- 修改源码:
~/.paddlehub/modules/chinese_ocr_db_crnn_mobile/model.py
修改此文件76行
config.enable_use_gpu(8000, 0)
改为:
config.enable_use_gpu(3000, 0)
修改后运行,无反应,目前可以查看paddle github lssues目前ocr对于显存还存在一些问题;本文还是采用cpu推理。
- 测试代码:
import paddlehub as hub
import cv2
import os
#如果使用GPU,需要先定义GPU;
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
result = ocr.recognize_text(images=[cv2.imread('./1.jpg')],
use_gpu= False, #设置是否使用gpu
output_dir='ocr_result',
visualization=True,
box_thresh=0.5,
text_thresh=0.5)
print(result)
可以看到保存后的结果:

六.参考文档
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/index_cn.html
https://zhuanlan.zhihu.com/p/319371293
https://blog.csdn.net/qq_44498043/article/details/107300374?spm=1001.2014.3001.5502
7.有待解决…
各位同学,问下有啥方法可以让编译的时候下载github文件速度快些??求大佬回复。。。
使用gpu推理时,显存问题无法解决,等后续paddle版本优化后再试试。。
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象