spring-cloud gateway 网关调优-程序员宅基地
技术标签: memcached java tomcat 乱码 redis

网关线程数的增加,对吞吐量有较大提升;
网关对CPU要求较高,建议提升CPU性能,但需要权衡单台高配和多台低配的整体性能对比;
网关对内存、硬盘要求较低;
在吞吐量追求和CPU负载升高之间,做权衡选择机器配置;
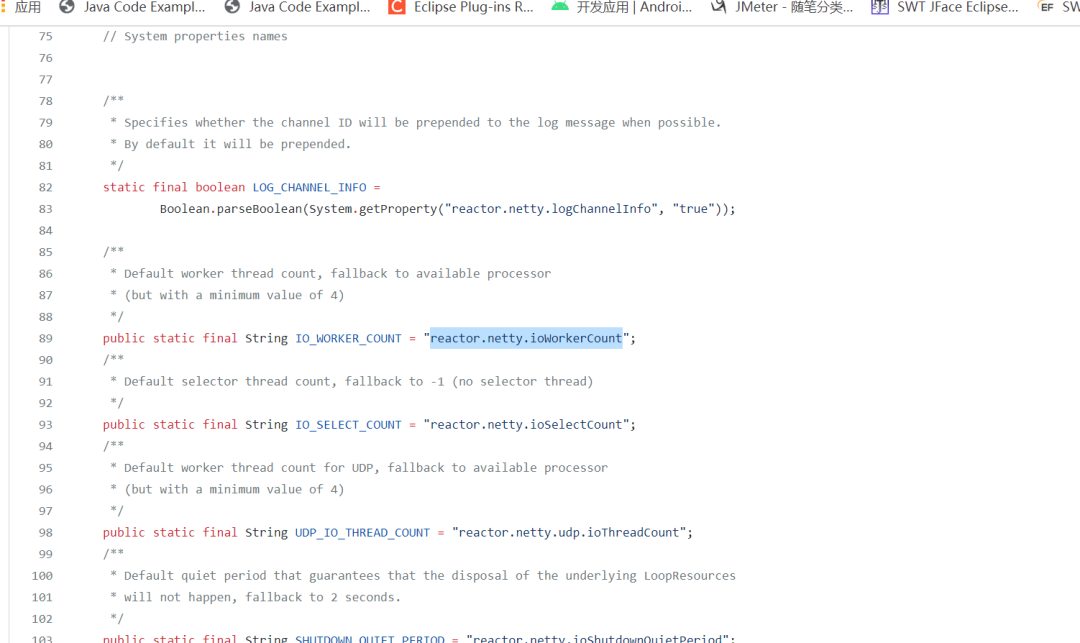
reactor.netty.ioWorkerCount参数调整netty工作线程数,在文件reactor.netty.ReactorNetty中
Spring Cloud Gateway 工作原理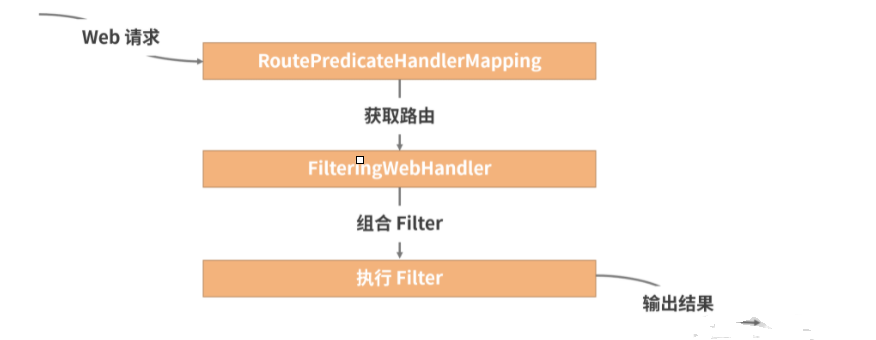
找到源码
org.springframework.cloud.gateway.handler.RoutePredicateHandlerMapping
再看RoutePredicateHandlerMapping#lookupRoute的实现
protected Mono<Route> lookupRoute(ServerWebExchange exchange) {
return this.routeLocator
.getRoutes()
//individually filter routes so that filterWhen error delaying is not a problem
.concatMap(route -> Mono
.just(route)
.filterWhen(r -> {
// add the current route we are testing
exchange.getAttributes().put(GATEWAY_PREDICATE_ROUTE_ATTR, r.getId());
return r.getPredicate().apply(exchange);
})
//instead of immediately stopping main flux due to error, log and swallow it
.doOnError(e -> logger.error("Error applying predicate for route: "+route.getId(), e))
.onErrorResume(e -> Mono.empty())
)
// .defaultIfEmpty() put a static Route not found
// or .switchIfEmpty()
// .switchIfEmpty(Mono.<Route>empty().log("noroute"))
.next()
//TODO: error handling
.map(route -> {
if (logger.isDebugEnabled()) {
logger.debug("Route matched: " + route.getId());
}
validateRoute(route, exchange);
return route;
});
/* TODO: trace logging
if (logger.isTraceEnabled()) {
logger.trace("RouteDefinition did not match: " + routeDefinition.getId());
}*/
}遍历所有的路由规则直到找到一个符合的,路由过多是排序越往后自然越慢,但是也考虑到地方项目只有10个,但是我们还是试一试。
我们把这部分源码抽出来自己修改一下,先写死一个路由
protected Mono<Route> lookupRoute(ServerWebExchange exchange) {
if (this.routeLocator instanceof CachingRouteLocator) {
CachingRouteLocator cachingRouteLocator = (CachingRouteLocator) this.routeLocator;
// 这里的getRouteMap()也是新加的方法
return cachingRouteLocator.getRouteMap().next().map(map ->
map.get(“api-user”))
//这里写死一个路由id
.switchIfEmpty(matchRoute(exchange));
}
return matchRoute(exchange);
}重新压测后速度提升了10倍,cpu也只有在请求进入时较高,但是仍然存在被拒绝的请求以及卡顿。
于是根据这个情况以及我们实际设定的路由规则,在请求进入时对重要参数以及path进行hash保存下次进入时不再走原来的判断逻辑。
protected Mono<Route> lookupRoute(ServerWebExchange exchange) {
//String md5Key = getMd5Key(exchange);
String appId = exchange.getRequest().getHeaders().getFirst("M-Sy-AppId");
String serviceId = exchange.getRequest().getHeaders().getFirst("M-Sy-Service");
String token = exchange.getRequest().getHeaders().getFirst("M-Sy-Token");
String path = exchange.getRequest().getURI().getRawPath();
StringBuilder value = new StringBuilder();
String md5Key = "";
if(StringUtils.isNotBlank(token)) {
try {
Map<String, Object> params = (Map<String, Object>) redisTemplate.opsForValue().get("token:" + token);
if(null !=params && !params.isEmpty()) {
JSONObject user = JSONObject.parseObject(params.get("user").toString());
appId = user.getString("appId");
serviceId = user.getString("serviceid");
}
}catch(Exception e) {
e.printStackTrace();
}
}
if(StringUtils.isBlank(appId) || StringUtils.isBlank(serviceId)) {
md5Key = DigestUtils.md5Hex(path);
}else {
value.append(appId);
value.append(serviceId);
value.append(path);
md5Key = DigestUtils.md5Hex(value.toString());
}
if (logger.isDebugEnabled()) {
logger.info("Route matched before: " + routes.containsKey(md5Key));
}
if ( routes.containsKey(md5Key)
&& this.routeLocator instanceof CachingRouteLocator) {
final String key = md5Key;
CachingRouteLocator cachingRouteLocator = (CachingRouteLocator) this.routeLocator;
// 注意,这里的getRouteMap()也是新加的方法
return cachingRouteLocator.getRouteMap().next().map(map ->
map.get(routes.get(key)))
// 这里保证如果适配不到,仍然走老的官方适配逻辑
.switchIfEmpty(matchRoute(exchange,md5Key));
}
return matchRoute(exchange,md5Key);
}
private Mono<Route> matchRoute(ServerWebExchange exchange,String md5Key) {
//String md5Key = getMd5Key(exchange);
return this.routeLocator
.getRoutes()
//individually filter routes so that filterWhen error delaying is not a problem
.concatMap(route -> Mono
.just(route)
.filterWhen(r -> {
// add the current route we are testing
exchange.getAttributes().put(GATEWAY_PREDICATE_ROUTE_ATTR, r.getId());
return r.getPredicate().apply(exchange);
})
//instead of immediately stopping main flux due to error, log and swallow it
.doOnError(e -> logger.error("Error applying predicate for route: "+route.getId(), e))
.onErrorResume(e -> Mono.empty())
)
// .defaultIfEmpty() put a static Route not found
// or .switchIfEmpty()
// .switchIfEmpty(Mono.<Route>empty().log("noroute"))
.next()
//TODO: error handling
.map(route -> {
if (logger.isDebugEnabled()) {
logger.debug("Route matched: " + route.getId());
logger.debug("缓存"+routes.get(md5Key));
}
// redisTemplate.opsForValue().set(ROUTE_KEY+md5Key, route.getId(), 5, TimeUnit.MINUTES);
routes.put(md5Key, route.getId());
validateRoute(route, exchange);
return route;
});
/* TODO: trace logging
if (logger.isTraceEnabled()) {
logger.trace("RouteDefinition did not match: " + routeDefinition.getId());
}*/
}此次修改后路由有了一个较大的提升,开始继续分析拒绝请求以及卡顿问题。
考虑到是不是netty依据电脑的配置做了限制?在自己的笔记本上限制连接在200左右,在服务器上在2000左右
查了许多资料发现netty的对外配置并不是很多,不像tomcat、undertow等等
目前使用的scg版本较旧没有办法将netty修改为tomcat或者undertow,于是我在官网下载了最新的scg并将启动容器修改为tomcat和undertow依次进行了尝试,发现都没有200的限制。
然后开始查找netty方面的资料,发现了reactor.ipc.netty.workerCount
DEFAULT_IO_WORKER_COUNT:如果环境变量有设置reactor.ipc.netty.workerCount,则用该值;没有设置则取Math.max(Runtime.getRuntime().availableProcessors(), 4)))
JSONObject message = new JSONObject();
try {
Thread.sleep(30000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
ServerHttpResponse response = exchange.getResponse();
message.put("code", 4199);
message.put("msg", "模拟堵塞");
byte[] bits = message.toJSONString().getBytes(StandardCharsets.UTF_8);
DataBuffer buffer = response.bufferFactory().wrap(bits);
response.setStatusCode(HttpStatus.UNAUTHORIZED);
// 指定编码,否则在浏览器中会中文乱码
response.getHeaders().add("Content-Type", "application/json;charset=UTF-8");
return response.writeWith(Mono.just(buffer));通过模拟堵塞测试,发现该参数用于控制接口的返回数量,这应该就是压测时接口卡顿返回的原因了,通过压测发现该参数在16核cpu的3倍时表现已经较好。16核cpu4倍时单机scg压测时没有卡顿,但是单机压15000时cpu大概在70-80。
通过找到该原因,怀疑人生的自己重拾信心通过百度reactor.ipc.netty.workerCount发现了另一个参数reactor.ipc.netty.selectCount
DEFAULT_IO_SELECT_COUNT:如果环境变量有设置reactor.ipc.netty.selectCount,则用该值;没有设置则取-1,表示没有selector thread
找到源码reactor.ipc.netty.resources.DefaultLoopResources
看到这段代码
if (selectCount == -1) {
this.selectCount = workerCount;
this.serverSelectLoops = this.serverLoops;
this.cacheNativeSelectLoops = this.cacheNativeServerLoops;
}else {
this.selectCount = selectCount;
this.serverSelectLoops =
new NioEventLoopGroup(selectCount, threadFactory(this, "select-nio"));
this.cacheNativeSelectLoops = new AtomicReference<>();
}历经漫长的怀疑人生与越挫越勇(并没有),总共修改了2处,达成了一个10倍提升的小目标
总结
修改原生路由查找逻辑
设置系统变量reactor.ipc.netty.workerCount为cpu核数的3倍或4倍;设置reactor.ipc.netty.selectCount的值为1(只要不是-1即可)
另外,httpclient的配置情况可以参考org.springframework.cloud.gateway.config.GatewayAutoConfiguration.NettyConfiguration
source: www.icode9.com/content-4-1057716.html
喜欢,在看
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象