Elasticsearch介绍及如何使用_elasticsearch match_phrase_prefix-程序员宅基地
技术标签: elasticsearch
是什么
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
基本概念:
- 节点(Node):
一个节点是一个单一的服务器,是你的集群的一部分,存储数据,并且参与集群的索引和搜索功能。
一个节点可以通过配置特定的集群名称来加入特定的集群。默认情况下,每个节点被设定加入一个名称为 “elasticsearch” 的集群,这意味着如果你在你的网络中启动了一些节点,并且假设它们能相互发现,它们将会自动组织并加入一个名称是 “elasticsearch” 的集群。 - 索引(Index):
可以近似的理解SQL中的数据库,虽然官方文档上说这是不好的。可以包涵表和数据。 - 类型(Type):(警告!Type在6.0.0版本中已经不赞成使用):
可以近似的理解成是SQL中的表,里面会包涵许多数据 - 文档(Document):
可以近似的理解是SQL中的表里的每一条数据。
去哪下:
官网下载传送
官网下载window版(我的是6.6.1版本)。
双击运行bin目录下的 elasticsearch.bat
怎么玩:
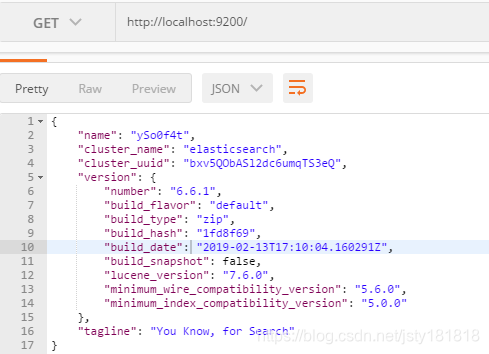
看到这个结果,说明安装,启动成功。
- 列出所有的索引:(GET)
http://localhost:9200/_cat/indices?v
- 创建一个索引:(PUT)
http://localhost:9200/customer
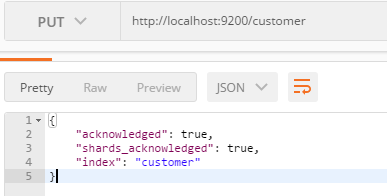
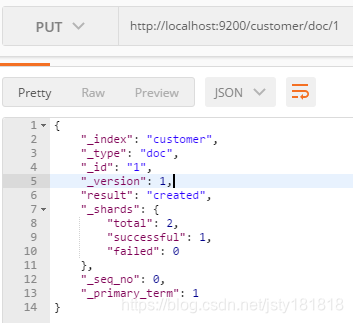
- 向索引中添加文档(PUT)
http://localhost:9200/customer/doc/1
//其中doc是类型。
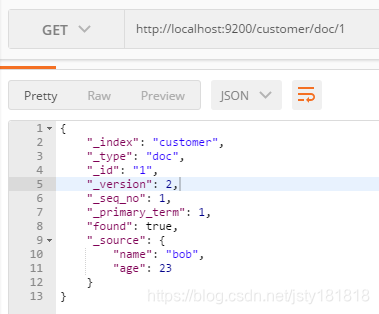
- 获取刚刚加入索引的文档:(GET)
http://localhost:9200/customer/doc/1
- 删除一个索引:(DELETE)
http://localhost:9200/customer
- 更新文档(POST)
除了能够新增和替换文档,我们也可以更新文档。注意虽然 Elasticsearch 在底层并没有真正更新文档,而是当我们更新文档时,Elasticsearch 首先去删除旧的文档,然后加入新的文档。
http://localhost:9200/customer/doc/1/_update?pretty
{
"doc": { "name": "Jane Doe" }
}
更新操作也可以使用简单的脚本来执行。如下的示例使用一个脚本将age增加了5:
http://localhost:9200/customer/doc/1/_update?pretty
{
"script" : "ctx._source.age += 5"
}
- 删除文档(DELETE):
http://localhost:9200/customer/doc/2?pretty
推荐使用Kibana进行数据查询
搜索:
- _mget(批量获取文档)
类似sql中的 id in(1,2,3)这样。
GET _mget
{
"docs":[
{
"_index": "bank",
"_type": "account",
"_id": "1",
"_source": ["balance", "city"]
},
{
"_index": "bank",
"_type": "account",
"_id": "5",
"_source": "firstname"
}
]
}
也可以简写:
GET /bank/account/_mget
{
"ids": ["1", "2", "4"]
}
-
_bulk(批量操作)
1.格式:
{action:{metadata}}
{requestbody}
其中action(行为)可以取值:
1.create:文档不存在时创建
2.update:更新文档
3.index:创建新文档或覆盖已有文档
4.delete:删除一个文档
create和index的区别:如果数据存在,使用create操作失败,会提示文档以存在,使用index可以成功执行。
如果使用create创建多个,其中有存在的,那么存在的返回失败,不存在的添加成功
其中metadata可以取值:
_index,_type,_id示例:
1.create:POST /bank/account/_bulk { "create":{ "_id":"999"}} { "account_number":999, "balance": 999} { "create":{ "_id":"1000"}} { "account_number":1000, "balance": 1000} { "create":{ "_id":"1001"}} { "account_number":1001, "balance": 1001}2.delete:
POST bank/account/_bulk { "delete":{ "_index":"bank", "_type":"account", "_id":"1000"}}3.update:
POST /bank/account/_bulk { "update":{ "_id":"1001"}} { "doc":{ "balance":"0"}} -
term:
用于查询指定字段包含某个词项的文档。这个查询不知道分词器的存在,所以搜索的值不会进行分词。只会拿搜索的值去倒排索引中找。
GET /bank/account/_search
{
"query":{
"term":{
"address":{
"value":"heath"
}
}
}
}
- match:
知道分词器的存在,所以搜索的值会被分词在去查询。
GET /bank/account/_search
{
"query":{
"match":{
"address":"511 Heath Place"
}
}
}
- multi_match:
可以指定多个字段,意思是:查找fields字段值的字段中包含query字段中对应的值
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
}
}
- match_phrase:
短语搜索,就是搜索含有指定的短语的数据。意思是搜索的值经过分词之后和es中分词保存的一致,顺序也一致,两头的可以少,中间的不可以少
GET /bank/account/_search
{
"query":{
"match_phrase":{
"address":"511 Heath Place"
}
}
}
- _source:
用来指定返回的字段:
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
},
"_source": ["firstname", "age"]
}
_可以写个数组来指定,也可以在 "source" 字段中加"includes"和"excludes"
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
},
"_source": {
"includes": ["age", "balance", "gen*"],
"excludes": ["gender"]
}
}
- sort:
用来排序,和关系型数据库的排序类似
GET /bank/account/_search
{
"query":{
"match_all":{
}
},
"sort":[
{
"balance":{
"order":"desc"
}
},
{
"age":{
"order":"asc"
}
}
]
}
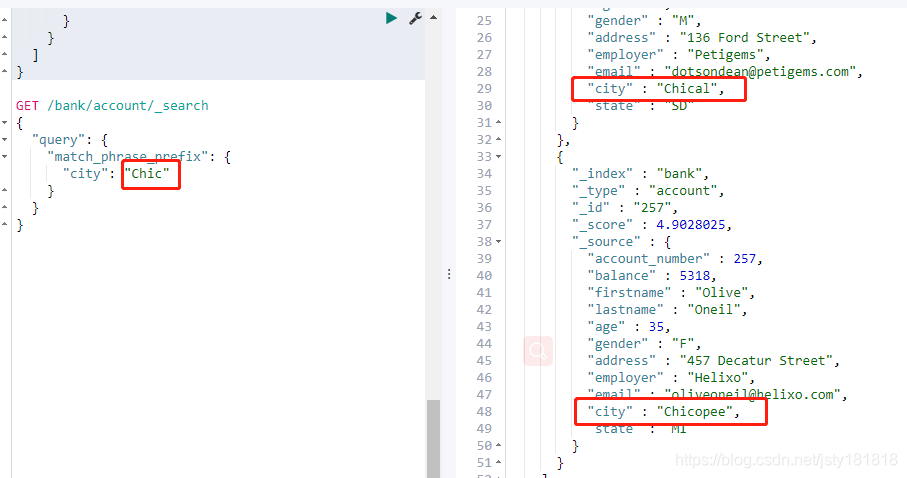
- match_phrase_prefix:
前缀匹配(查询的值不会分词,但是忽略大小写)
- range:
范围查询:
GET /bank/account/_search
{
"query":{
"range":{
"age":{
"gte": 20,
"lt": 30
}
}
}
}
- wildcard:
通配符匹配:
通配符:
* 代表任意多字符
? 代表一个字符
GET /bank/account/_search
{
"query":{
"wildcard":{
"city":{
"value": "nicho*n"
}
}
}
}
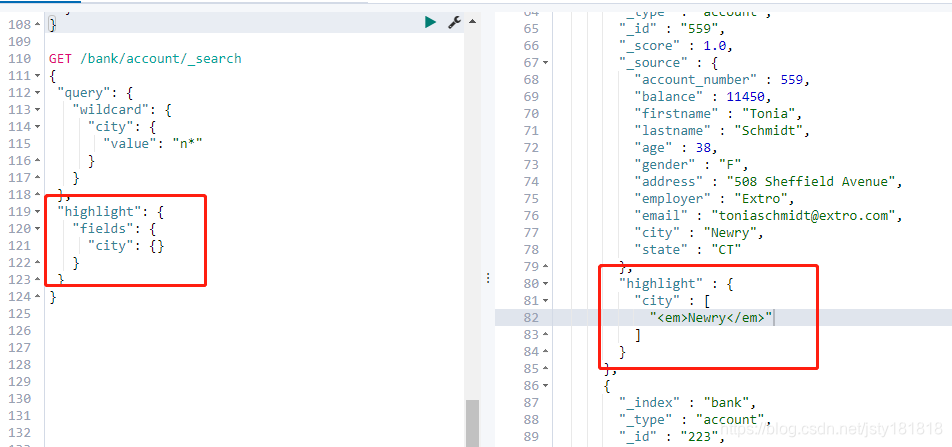
- highlight:
高亮显示:
GET /bank/account/_search
{
"query":{
"wildcard":{
"city":{
"value": "nicho*n"
}
}
},
"highlight":{
"fields":{
"city":{
}
}
}
}
- fuzzy:
模糊匹配,这个可不是mysql中的like,是可以错误的输入一些字 来进行匹配
GET /bank/account/_search
{
"query":{
"fuzzy":{
"city": "Nicho1so"
}
}
}
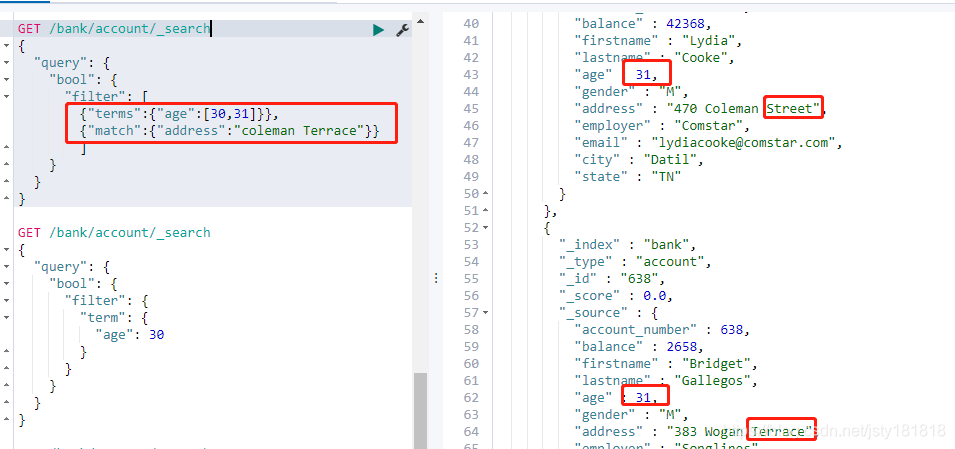
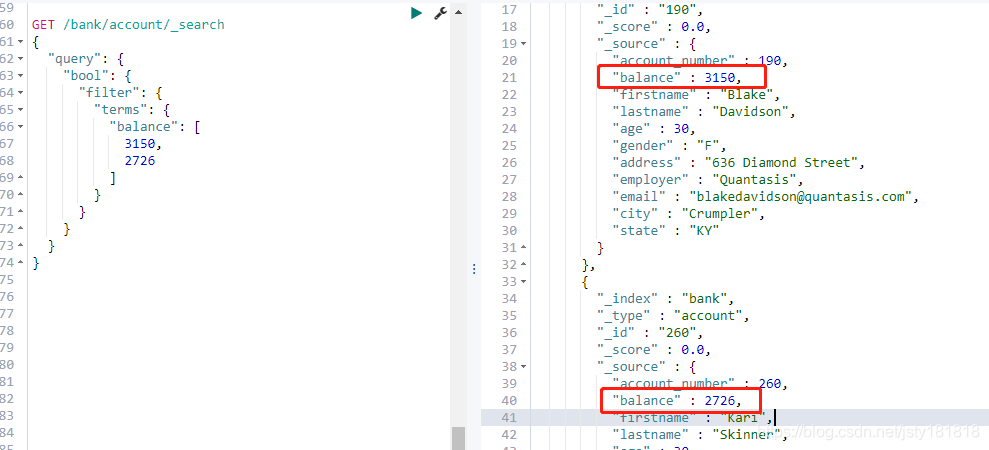
- filter查询:
过滤查询:
- must,should,must_not:
GET /bank/account/_search
{
"query":{
"bool":{
"must": [
{
"term":{
"age":{
"value" :20
}
}
}
]
}
}
}
- exists:
查询某个字段不为空
GET /bank/account/_search
{
"query":{
"bool":{
"filter": {
"exists":{
"field": "age"
}
}
}
}
}
- 聚合查询:
1.sum

智能推荐
微信小程序 淘宝_淘宝微信小程序-程序员宅基地
文章浏览阅读4.8k次,点赞2次,收藏33次。模仿淘宝写了一个小程序,主要目的还是练手并且以页面效果为主,写法肯定也会有更好的,后续继续加强。登录页面的话,就直接点登录进入到首页了,没有做过多的交互。其中做比较多的交互是购物车,应数据的形式做出的交互,实际的项目中可能会有更好的数据形式,产品数增减全选合计等,事件传参比较多;下面以购物车为例,贴上购物车的部分js 代码,里面有个“监听”是否勾选和计数的函数(watchSelec..._淘宝微信小程序
并发计算模型BSP与SEDA_bulk synchronous parallel-程序员宅基地
文章浏览阅读3.6k次。1 BSP批量同步并行计算BSP(Bulk Synchronous Parallel)批量同步并行计算用来解决并发编程难的问题。名字听起来有点矛盾,又是同步又是并行的。因为计算被分组成一个个超步(super-step),超步内并行计算并且结点间不能通信。在超步之间设置同步栅栏(barrier synchronization),计算完成后相互通信,全部完成后才能继续下一个超步。2 SEDA阶段_bulk synchronous parallel
企业微信的后台怎么进入和管理?_企业微信后台-程序员宅基地
文章浏览阅读1w次。企业微信的后台怎么进入和管理? _企业微信后台
【机器学习】QQ-plot深入理解与实现_python qqplot subplot-程序员宅基地
文章浏览阅读1.2w次。QQ-plot深入理解与实现26JUNJune 26, 2013最近在看关于CSI(Channel State Information)相关的论文,发现论文中用到了QQ-plot。Sigh!我承认我是第一次见到这个名词,异常陌生。维基百科给出了如下定义:“在统计学中,QQ-plot(Q代表分位数Quantile)是一种通过画出分位数来比较两个概率分布的图形方法。首先选定_python qqplot subplot
mybatis设置sql执行时间超时时间_mybatis timeout-程序员宅基地
文章浏览阅读2.8w次,点赞3次,收藏21次。存在这样的场景,当一些比较耗时的查询时,如果不中断,则会导致数据库堵塞,进而会拖垮整个数据库服务的正常运行。1.如果你使用的是HikariCP连接池的话,可以在配置文件设置connetion-timeout这个属性(如application.properties)2.如果你使用的是其他链接池,比如tomcat连接池,同时持久化框架用的是mybatis的话,那可以这样设置2.1 在配置文..._mybatis timeout
Windows Data Alignment on IPF, x86, and x86-64_data alignment is intrinsic-程序员宅基地
文章浏览阅读1.4k次。http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dv_vstechart/html/vcconwindowsdataalignmentonipfx86x86-64.asp?frame=trueWindows Data Alignment on IPF, x86, and x86-64Kang Su GatlinMic_data alignment is intrinsic
随便推点
iphone12文件管理连接服务器,iPhone手机打开服务器功能,和Windows电脑互传文件方法...-程序员宅基地
文章浏览阅读5.2k次。iPhone手机打开服务器功能,和Windows电脑互传文件方法PC端设置:一、在计算机端新建一个文件夹,例如取名为:“iphone共享文件”。二、然后右键点击文件夹属,点击“共享”。三、打开共享后,再左键点击“共享”,下拉箭头选择“Everyone”然后继续选择“共享”,显示出共享文件夹的网络地址和共享文件夹的名字。PC端设置完成。Iphone手机端设置:一、选择iphone手机“文件”,点击右..._iphone 手机的连接服务器 怎么连接电脑
obb包围盒数组的含义_obb包络盒-程序员宅基地
文章浏览阅读257次。OBB包围盒通常用一个包含12个元素的数组来表示,这些元素描述了包围盒的位置、尺寸和旋转。总之,这个包含12个元素的数组描述了OBB包围盒的位置、旋转和尺寸信息。第二行这三个元素表示包围盒的旋转信息,通常以旋转矩阵的形式给出。第四行这三个元素表示包围盒每个轴上的半边长,通常是尺寸的一半。:旋转矩阵的第一行,通常是X轴的旋转分量。:旋转矩阵的第二行,通常是Y轴的旋转分量。:旋转矩阵的第三行,通常是Z轴的旋转分量。:包围盒的中心点在X轴上的坐标。:包围盒的中心点在Y轴上的坐标。:包围盒的中心点在Z轴上的坐标。_obb包络盒
明远智睿MY-IMX6-EK200 L3035测试手册(2)_imx6 五个串口-程序员宅基地
文章浏览阅读319次。【接上一章节明远智睿MY-IMX6-EK200 L3035测试手册(1)】2.7 串口测试MY-I.MX6评估板有5个串口,其中4个为用户串口(位于底板正面“J1”位置,丝印名称为“TTL_UART”),1个为调试串口(位于底板正面“P2”位置)。 测试说明系统设备文件说明:调试串口的在系统中的设备文件是ttymxc0,用户串口的设备文件是ttymxc1、ttymxc2、t..._imx6 五个串口
QT软件开发-基于FFMPEG设计视频播放器-GPU硬解、OpenGL渲染(四)_qt gpu渲染画面-程序员宅基地
文章浏览阅读1.3k次。前面几篇文章里分别介绍了ffmpeg软解、硬解、音频解码,完成视频帧渲染,音频解码播放。之前做的视频播放器里,虽然也使用了硬件加速解码,解码确实快,但是渲染都采用QWidget方式渲染绘制,占用CPU较高,并且采用QWidget方式渲染,需要将硬解码之后的数据转为RGB24,然后封装为QImage这个过程非常消耗时间,如果是高清4K视频整个视频解码播放就会非常卡顿,CPU占用直接100%。这篇文章将渲染方式换成OpenGL,解码方式还是采用硬件加速解码,充分利用GPU,降低CPU占用,提高整体视频播放效率。_qt gpu渲染画面
element 中手动上传文件_element手动上传-程序员宅基地
文章浏览阅读1.6k次。element手动上传文件_element手动上传
linux 后台计算,科学网-如何在Linux中做批处理和后台计算-张彦的博文-程序员宅基地
文章浏览阅读213次。单个计算任务的提交How to compute by Gaussian 03?1. Upload "xxx.gjf" to your folder.2. Perform "g03 xxx.gjf &" in your folder.3. See your tasks by "jobs", it's running. Ok!How to run a Fortran code?1. Uploa..._nohup gaussian