Stable_diffsuion代码解析_ldm self.model_channels-程序员宅基地
Stable_diffusion代码解析
零 代码文件结构
assets文件夹 存放项目中使用的静态资源
config文件夹 存放配置信息
- autoencoder文件夹 自动编码器参数配置
- latent-diffusion文件夹 ldm参数配置
- retrieval-augmented-diffusion文件夹
- stable-diffusion文件夹
data文件夹 存放一些条件和图片案例
models文件夹 存放预训练模型和参数配置
- first_stage_models文件夹 存放AutoEncoderKL和VQModel的参数设置
- ldm文件夹 存放ldm不同工作的配置文件,例如文生图,语言生图,风格迁移等等
scripts文件夹 存放拓展脚本,例如实现文生图、图生图的py代码
ldm文件夹 存放ldm主要代码文件
- data文件夹 存放各种定义Dataset的代码
- models文件夹 存放diffusion文件夹和autoencoder文件(VQ-VAE)
- diffusion文件夹 存放DDPM/DDIM等等的diffusion Scheduler代码文件
- modules文件夹
- diffusionmodules文件夹 存放diffusion策略代码文件
- distributions文件夹
- encoder文件夹 存放条件编码器代码
- image_degradation文件夹 存放图像渐变工具代码
- loss文件夹
main.py 主代码,改这里就行
一 ldm文件夹
1 data文件夹
2 models文件夹
2.1 ddpm.py
2.1.1 class DDPM(图像空间中具有高斯扩散的经典DDPM)
a.参数初始化部分
传入参数:
unet_config: U-Net模型的配置参数。
timesteps: 模型的时间步数,默认为1000。
beta_schedule: 控制beta参数的调度方式。
loss_type: 损失函数的类型,默认为"L2"。
ckpt_path: 模型的检查点路径。
ignore_keys: 要忽略的键值列表。
load_only_unet: 是否仅加载U-Net模型。
monitor: 用于监控的指标,默认为"val/loss"。
use_ema: 是否使用指数移动平均。
first_stage_key: 第一个阶段的关键键值。
image_size: 图像大小,默认为256。
channels: 输入图像的通道数。
log_every_t: 每隔多少时间步记录一次日志。
clip_denoised: 是否剪裁去噪结果。
linear_start和linear_end: 用于线性调度的起始和结束值。
cosine_s: 余弦调度的参数。
given_betas: 给定的参数列表。
original_elbo_weight: 原始ELBO权重。
v_posterior: 选择后验方差的权重。
l_simple_weight: 简单权重。
conditioning_key: 条件键值。
parameterization: 参数化方式,目前支持"eps"和"x0"。
scheduler_config: 调度器配置。
use_positional_encodings: 是否使用位置编码。
learn_logvar: 是否学习对数方差。
logvar_init: 对数方差的初始值。
初始化操作:
作者将大多数输入参数都本地化,少数参数进行特殊处理
self.model = DiffusionWrapper(unet_config, conditioning_key)
if self.use_ema:
self.model_ema = LitEma(self.model)
print(f"Keeping EMAs of {len(list(self.model_ema.buffers()))}."
self.logvar = torch.full(fill_value=logvar_init, size=(self.num_timesteps,))
if self.learn_logvar:
self.logvar = nn.Parameter(self.logvar, requires_grad=True)
b.register_schedule方法
"""
该方法的作用:1.设置beta、alphas
2.
"""
def register_schedule(self, given_betas=None, beta_schedule="linear", timesteps=1000,
linear_start=1e-4, linear_end=2e-2, cosine_s=8e-3):
#生成beta
if exists(given_betas):
betas = given_betas
else:
betas = make_beta_schedule(beta_schedule, timesteps, linear_start=linear_start, linear_end=linear_end,
cosine_s=cosine_s)
#计算alphas
alphas = 1. - betas
#计算alphas_cumprod
alphas_cumprod = np.cumprod(alphas, axis=0)
#将alphas_cumprod第一个元素变成1
alphas_cumprod_prev = np.append(1., alphas_cumprod[:-1])
timesteps, = betas.shape
self.num_timesteps = int(timesteps)
self.linear_start = linear_start
self.linear_end = linear_end
#有多少个t就得有多少个alphas_cumprod
assert alphas_cumprod.shape[0] == self.num_timesteps, 'alphas have to be defined for each timestep'
#确保数据转换为tensor时数据类型时f32
to_torch = partial(torch.tensor, dtype=torch.float32)
#register_buffer是PyTorch中nn.Module类提供的一个方法,用于将一个缓冲区(buffer)注册到模型中。
#缓冲区是一些在模型训练期间不需要梯度的参数,比如常数、移动平均值等。
#通过register_buffer,这些缓冲区可以与模型的状态一起保存和加载。
self.register_buffer('betas', to_torch(betas))
self.register_buffer('alphas_cumprod', to_torch(alphas_cumprod))
self.register_buffer('alphas_cumprod_prev', to_torch(alphas_cumprod_prev))
# calculations for diffusion q(x_t | x_{t-1}) and others
self.register_buffer('sqrt_alphas_cumprod', to_torch(np.sqrt(alphas_cumprod)))
self.register_buffer('sqrt_one_minus_alphas_cumprod', to_torch(np.sqrt(1. - alphas_cumprod)))
self.register_buffer('log_one_minus_alphas_cumprod', to_torch(np.log(1. - alphas_cumprod)))
self.register_buffer('sqrt_recip_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod)))
self.register_buffer('sqrt_recipm1_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod - 1)))
# 计算扩散过程中后验分布的真实的方差和均值,方差是一个常数可以直接计算,均值和xt有关,但是均值的两个系数是可以先确定的
posterior_variance = (1 - self.v_posterior) * betas * (1. - alphas_cumprod_prev) / (
1. - alphas_cumprod) + self.v_posterior * betas
# above: equal to 1. / (1. / (1. - alpha_cumprod_tm1) + alpha_t / beta_t)
self.register_buffer('posterior_variance', to_torch(posterior_variance))
# 由于扩散链开始时的后验方差为0,因此对数计算被截断
self.register_buffer('posterior_log_variance_clipped', to_torch(np.log(np.maximum(posterior_variance, 1e-20))))
#求解均值的两个参数
self.register_buffer('posterior_mean_coef1', to_torch(
betas * np.sqrt(alphas_cumprod_prev) / (1. - alphas_cumprod)))
self.register_buffer('posterior_mean_coef2', to_torch(
(1. - alphas_cumprod_prev) * np.sqrt(alphas) / (1. - alphas_cumprod)))
if self.parameterization == "eps":
lvlb_weights = self.betas ** 2 / (
2 * self.posterior_variance * to_torch(alphas) * (1 - self.alphas_cumprod))
elif self.parameterization == "x0":
lvlb_weights = 0.5 * np.sqrt(torch.Tensor(alphas_cumprod)) / (2. * 1 - torch.Tensor(alphas_cumprod))
else:
raise NotImplementedError("mu not supported")
# TODO how to choose this term
lvlb_weights[0] = lvlb_weights[1]
self.register_buffer('lvlb_weights', lvlb_weights, persistent=False)
assert not torch.isnan(self.lvlb_weights).all()
c.init_from_ckpt方法
def init_from_ckpt(self, path, ignore_keys=list(), only_model=False):
#加载检查点模型
sd = torch.load(path, map_location="cpu")
if "state_dict" in list(sd.keys()):
sd = sd["state_dict"]
keys = list(sd.keys())
for k in keys:
for ik in ignore_keys:
if k.startswith(ik):
print("Deleting key {} from state_dict.".format(k))
del sd[k]
#如果 only_model 为 True,则仅加载模型的状态字典,否则加载整个模型
missing, unexpected = self.load_state_dict(sd, strict=False) if not only_model else self.model.load_state_dict(
sd, strict=False)
print(f"Restored from {path} with {len(missing)} missing and {len(unexpected)} unexpected keys")
if len(missing) > 0:
print(f"Missing Keys: {missing}")
if len(unexpected) > 0:
print(f"Unexpected Keys: {unexpected}")
c.q_mean_variance 计算加噪的均值方差
def q_mean_variance(self, x_start, t):
"""
得到分布q(x_t|x_0)。
param x_start:无噪声输入的[N x C x…]张量。
param t:扩散步骤数(减1)。这里,0表示一步。
return:一个元组(均值、方差、对数方差),所有x_start的形状。
"""
mean = (extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start)
variance = extract_into_tensor(1.0 - self.alphas_cumprod, t, x_start.shape)
log_variance = extract_into_tensor(self.log_one_minus_alphas_cumprod, t, x_start.shape)
return mean, variance, log_variance
d.predict_start_from_noise 根据x_t和噪声得出x_0
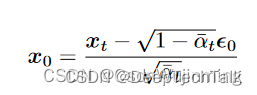
def predict_start_from_noise(self, x_t, t, noise):
return (
extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * noise
)
e.q_posterior 根据x_t和x_0计算q(x_t-1|x_t,x_0)的均值方差

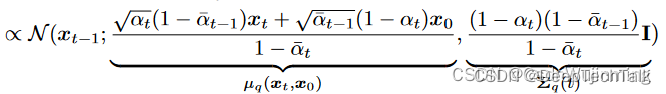
def q_posterior(self, x_start, x_t, t):
posterior_mean = (
extract_into_tensor(self.posterior_mean_coef1, t, x_t.shape) * x_start +
extract_into_tensor(self.posterior_mean_coef2, t, x_t.shape) * x_t
)
posterior_variance = extract_into_tensor(self.posterior_variance, t, x_t.shape)
posterior_log_variance_clipped = extract_into_tensor(self.posterior_log_variance_clipped, t, x_t.shape)
return posterior_mean, posterior_variance, posterior_log_variance_clipped
f.p_mean_variance
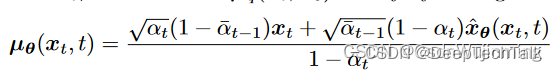
# 计算神经网络重构的原始图片下的去噪分布p(x_t-1|x_t)
def p_mean_variance(self, x, t, clip_denoised: bool):
model_out = self.model(x, t)
if self.parameterization == "eps":
x_recon = self.predict_start_from_noise(x, t=t, noise=model_out)# 送入模型,得到t时刻的随机噪声预测值
elif self.parameterization == "x0":
# 从神经网络预测的噪声中重构出样本,即网络预测的x_0
x_recon = model_out
if clip_denoised:
x_recon.clamp_(-1., 1.)
# 计算q(x_t-1|xt, x_recon)的分布参数 详情见上公式
model_mean, posterior_variance, posterior_log_variance = self.q_posterior(x_start=x_recon, x_t=x, t=t)
return model_mean, posterior_variance, posterior_log_variance
g.Sample 正向过程和反向过程
反向去噪:
#去噪一步
@torch.no_grad()
def p_sample(self, x, t, clip_denoised=True, repeat_noise=False):
b, *_, device = *x.shape, x.device
#计算分布的均值标准差
model_mean, _, model_log_variance = self.p_mean_variance(x=x, t=t, clip_denoised=clip_denoised)
noise = noise_like(x.shape, device, repeat_noise)
# no noise when t == 0
nonzero_mask = (1 - (t == 0).float()).reshape(b, *((1,) * (len(x.shape) - 1)))
#返回去噪的图像
return model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise
#进行全部去噪
def p_sample_loop(self, shape, return_intermediates=False):
# 获取设备信息
device = self.betas.device
# 获取 batch size
b = shape[0]
# 生成一个形状为 shape 的随机张量 img
img = torch.randn(shape, device=device)
# 创建一个列表 intermediates 用于存储中间结果,初始时包含随机生成的 img
intermediates = [img]
# 使用 tqdm 迭代从 self.num_timesteps 到 0 的范围
for i in tqdm(reversed(range(0, self.num_timesteps)), desc='Sampling t', total=self.num_timesteps):
# 调用 self.p_sample 方法进行采样
img = self.p_sample(img, torch.full((b,), i, device=device, dtype=torch.long),
clip_denoised=self.clip_denoised)
# 每隔 self.log_every_t 个步骤或在最后一个步骤时,将当前结果添加到 intermediates 列表中
if i % self.log_every_t == 0 or i == self.num_timesteps - 1:
intermediates.append(img)
# 如果 return_intermediates 为 True,则返回最终结果和中间结果列表 intermediates
if return_intermediates:
return img, intermediates
# 否则,只返回最终结果
return img
正向加噪
@torch.no_grad()
def sample(self, batch_size=16, return_intermediates=False):
image_size = self.image_size
channels = self.channels
return self.p_sample_loop((batch_size, channels, image_size, image_size),
return_intermediates=return_intermediates)
#根据x_0加噪获得x_t
def q_sample(self, x_start, t, noise=None):
noise = default(noise, lambda: torch.randn_like(x_start))
return (extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start +
extract_into_tensor(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise)
h.计算重构损失 代码比较简单
def get_loss(self, pred, target, mean=True):
if self.loss_type == 'l1':
loss = (target - pred).abs()
if mean:
loss = loss.mean()
elif self.loss_type == 'l2':
if mean:
loss = torch.nn.functional.mse_loss(target, pred)
else:
loss = torch.nn.functional.mse_loss(target, pred, reduction='none')
else:
raise NotImplementedError("unknown loss type '{loss_type}'")
return loss
以下代码为计算整个训练过程的损失:
def p_losses(self, x_start, t, noise=None):
#初始化随机噪声
noise = default(noise, lambda: torch.randn_like(x_start))
#加噪
x_noisy = self.q_sample(x_start=x_start, t=t, noise=noise)
#预测噪声
model_out = self.model(x_noisy, t)
loss_dict = {
}
if self.parameterization == "eps":
target = noise
elif self.parameterization == "x0":
target = x_start
else:
raise NotImplementedError(f"Paramterization {self.parameterization} not yet supported")
#计算loss
loss = self.get_loss(model_out, target, mean=False).mean(dim=[1, 2, 3])
log_prefix = 'train' if self.training else 'val'
loss_dict.update({
f'{log_prefix}/loss_simple': loss.mean()})
loss_simple = loss.mean() * self.l_simple_weight
loss_vlb = (self.lvlb_weights[t] * loss).mean()
loss_dict.update({
f'{log_prefix}/loss_vlb': loss_vlb})
loss = loss_simple + self.original_elbo_weight * loss_vlb
loss_dict.update({
f'{log_prefix}/loss': loss})
return loss, loss_dict
2.1.2 class LatentDiffusion(DDPM):
崩溃了,这代码又臭又多
2.2 autoencoder.py
2.2.1 class VQModel
a.初始化:
class VQModel(pl.LightningModule):
def __init__(self,
ddconfig, # 数据加载和处理配置
lossconfig, # 损失函数配置
n_embed, # 嵌入的数量
embed_dim, # 嵌入的维度
ckpt_path=None, # 模型的检查点路径,默认为 None
ignore_keys=[], # 初始化时要忽略的键的列表
image_key="image", # 输入图像的键名,默认为 "image"
colorize_nlabels=None, # 要着色的标签数量,可选,默认为 None
monitor=None, # 监控器,可选,默认为 None
batch_resize_range=None, # 批量调整大小的范围,可选,默认为 None
scheduler_config=None, # 调度器配置,可选,默认为 None
lr_g_factor=1.0, # 学习率缩放因子,默认为 1.0
remap=None, # 重映射参数,可选,默认为 None
sane_index_shape=False, # 告诉矢量量化器将索引返回为 bhw(batch, height, width)形状,默认为 False
use_ema=False # 是否使用指数移动平均(EMA),默认为 False
):
super().__init__()
# 设置模型的各种属性
self.embed_dim = embed_dim
self.n_embed = n_embed
self.image_key = image_key
#定义encoder和decoder,都是使用的unet架构,
self.encoder = Encoder(**ddconfig)
self.decoder = Decoder(**ddconfig)
self.loss = instantiate_from_config(lossconfig)
#VQ编码层
self.quantize = VectorQuantizer(n_embed, embed_dim, beta=0.25,
remap=remap,
sane_index_shape=sane_index_shape)
self.quant_conv = torch.nn.Conv2d(ddconfig["z_channels"], embed_dim, 1)
self.post_quant_conv = torch.nn.Conv2d(embed_dim, ddconfig["z_channels"], 1)
# 如果指定了要着色的标签数量,则注册颜色缓冲区
if colorize_nlabels is not None:
assert type(colorize_nlabels) == int
self.register_buffer("colorize", torch.randn(3, colorize_nlabels, 1, 1))
# 如果指定了监控器,则设置监控器
if monitor is not None:
self.monitor = monitor
# 如果指定了批量调整大小的范围,则进行相应的设置
self.batch_resize_range = batch_resize_range
if self.batch_resize_range is not None:
print(f"{self.__class__.__name__}: Using per-batch resizing in range {batch_resize_range}.")
# 设置是否使用指数移动平均(EMA)
self.use_ema = use_ema
if self.use_ema:
# 如果使用 EMA,则创建 EMA 模型
self.model_ema = LitEma(self)
print(f"Keeping EMAs of {len(list(self.model_ema.buffers()))}.")
# 如果指定了检查点路径,则从检查点初始化模型,同时忽略指定的键
if ckpt_path is not None:
self.init_from_ckpt(ckpt_path, ignore_keys=ignore_keys)
b.调用encoder和decode
def encode(self, x):
h = self.encoder(x)
#添加卷积层改变通道数为embed_dim
h = self.quant_conv(h)
quant, emb_loss, info = self.quantize(h)
return quant, emb_loss, info
#完成了编码器到codebook通道数转换
def encode_to_prequant(self, x):
h = self.encoder(x)
h = self.quant_conv(h)
return h
def decode(self, quant):
quant = self.post_quant_conv(quant)
dec = self.decoder(quant)
return dec
#codebook到解码器的通道数转换
def decode_code(self, code_b):
quant_b = self.quantize.embed_code(code_b)
dec = self.decode(quant_b)
return dec
2.2.2 class AutoencoderKL
略
3 modules文件夹
3.1 diffusionmodules文件夹
3.1.1 model.py
**a.get_timestep_embedding 计算timestep_embedding
其中生成方法如下图所示:
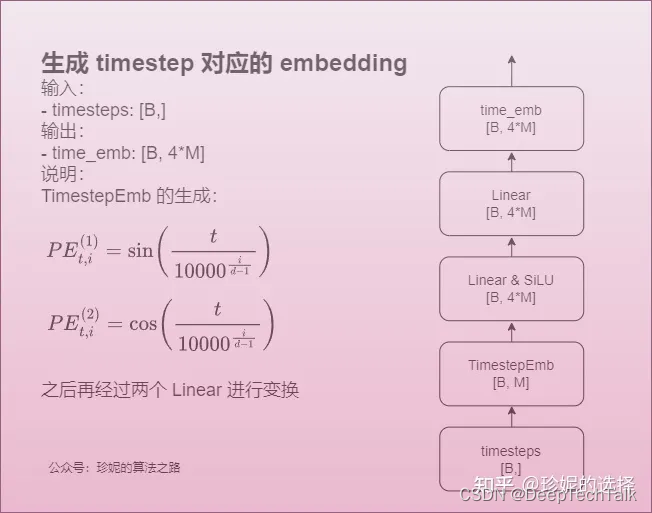
def get_timestep_embedding(timesteps, embedding_dim):
assert len(timesteps.shape) == 1
#计算dim的一半
half_dim = embedding_dim // 2
#计算基于指数的缩放因子,用于给嵌入向量中每个维度赋予不同的重要性
emb = math.log(10000) / (half_dim - 1)
#创建了一个指数级别的权重张量,用于加权每个时间步的不同维度
emb = torch.exp(torch.arange(half_dim, dtype=torch.float32) * -emb)
emb = emb.to(device=timesteps.device)
#: 将每个时间步乘以权重张量,这样每个时间步都被映射到嵌入空间的一部分
emb = timesteps.float()[:, None] * emb[None, :]
#将计算出的嵌入值分别进行正弦和余弦变换,并将结果连接起来,以增加嵌入的多样性和表示能力
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
if embedding_dim % 2 == 1: # zero pad
emb = torch.nn.functional.pad(emb, (0,1,0,0))
return emb
b.用于unet网络的组件 上采样、下采样、ResnetBlock、LinAttnBlock、AttnBlock、make_attn
resnetblock结构如下:
class ResnetBlock(nn.Module):
def __init__(self, *, in_channels, out_channels=None, conv_shortcut=False,
dropout, temb_channels=512):
super().__init__()
self.in_channels = in_channels
out_channels = in_channels if out_channels is None else out_channels
self.out_channels = out_channels
self.use_conv_shortcut = conv_shortcut
self.norm1 = Normalize(in_channels)
self.conv1 = torch.nn.Conv2d(in_channels,
out_channels,
kernel_size=3,
stride=1,
padding=1)
if temb_channels > 0:
self.temb_proj = torch.nn.Linear(temb_channels,
out_channels)
self.norm2 = Normalize(out_channels)
self.dropout = torch.nn.Dropout(dropout)
self.conv2 = torch.nn.Conv2d(out_channels,
out_channels,
kernel_size=3,
stride=1,
padding=1)
if self.in_channels != self.out_channels:
if self.use_conv_shortcut:
self.conv_shortcut = torch.nn.Conv2d(in_channels,
out_channels,
kernel_size=3,
stride=1,
padding=1)
else:
self.nin_shortcut = torch.nn.Conv2d(in_channels,
out_channels,
kernel_size=1,
stride=1,
padding=0)
def forward(self, x, temb):
h = x
h = self.norm1(h)
h = nonlinearity(h)
h = self.conv1(h)
if temb is not None:
h = h + self.temb_proj(nonlinearity(temb))[:,:,None,None]
h = self.norm2(h)
h = nonlinearity(h)
h = self.dropout(h)
h = self.conv2(h)
if self.in_channels != self.out_channels:
if self.use_conv_shortcut:
x = self.conv_shortcut(x)
else:
x = self.nin_shortcut(x)
return x+h
上/下采样如下:
class Upsample(nn.Module):
def __init__(self, in_channels, with_conv):
super().__init__()
self.with_conv = with_conv
if self.with_conv:
self.conv = torch.nn.Conv2d(in_channels,
in_channels,
kernel_size=3,
stride=1,
padding=1)
def forward(self, x):
x = torch.nn.functional.interpolate(x, scale_factor=2.0, mode="nearest")
if self.with_conv:
x = self.conv(x)
return x
class Downsample(nn.Module):
def __init__(self, in_channels, with_conv):
super().__init__()
self.with_conv = with_conv
if self.with_conv:
# no asymmetric padding in torch conv, must do it ourselves
self.conv = torch.nn.Conv2d(in_channels,
in_channels,
kernel_size=3,
stride=2,
padding=0)
def forward(self, x):
if self.with_conv:
pad = (0,1,0,1)
x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
x = self.conv(x)
else:
x = torch.nn.functional.avg_pool2d(x, kernel_size=2, stride=2)
return x
attention_block如下:
class AttnBlock(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.in_channels = in_channels
self.norm = Normalize(in_channels)
self.q = torch.nn.Conv2d(in_channels,
in_channels,
kernel_size=1,
stride=1,
padding=0)
self.k = torch.nn.Conv2d(in_channels,
in_channels,
kernel_size=1,
stride=1,
padding=0)
self.v = torch.nn.Conv2d(in_channels,
in_channels,
kernel_size=1,
stride=1,
padding=0)
self.proj_out = torch.nn.Conv2d(in_channels,
in_channels,
kernel_size=1,
stride=1,
padding=0)
def forward(self, x):
h_ = x
h_ = self.norm(h_)
q = self.q(h_)
k = self.k(h_)
v = self.v(h_)
# compute attention
b,c,h,w = q.shape
q = q.reshape(b,c,h*w)
q = q.permute(0,2,1) # b,hw,c
k = k.reshape(b,c,h*w) # b,c,hw
w_ = torch.bmm(q,k) # b,hw,hw w[b,i,j]=sum_c q[b,i,c]k[b,c,j]
w_ = w_ * (int(c)**(-0.5))
w_ = torch.nn.functional.softmax(w_, dim=2)
# attend to values
v = v.reshape(b,c,h*w)
w_ = w_.permute(0,2,1) # b,hw,hw (first hw of k, second of q)
h_ = torch.bmm(v,w_) # b, c,hw (hw of q) h_[b,c,j] = sum_i v[b,c,i] w_[b,i,j]
h_ = h_.reshape(b,c,h,w)
h_ = self.proj_out(h_)
return x+h_
最终的unet网络如下:
class Model(nn.Module):
def __init__(self, *, ch, out_ch, ch_mult=(1,2,4,8), num_res_blocks,
attn_resolutions, dropout=0.0, resamp_with_conv=True, in_channels,
resolution, use_timestep=True, use_linear_attn=False, attn_type="vanilla"):
super().__init__()
if use_linear_attn: attn_type = "linear"
self.ch = ch
self.temb_ch = self.ch*4
self.num_resolutions = len(ch_mult)
self.num_res_blocks = num_res_blocks
self.resolution = resolution
self.in_channels = in_channels
self.use_timestep = use_timestep
if self.use_timestep:
# timestep embedding
self.temb = nn.Module()
self.temb.dense = nn.ModuleList([
torch.nn.Linear(self.ch,
self.temb_ch),
torch.nn.Linear(self.temb_ch,
self.temb_ch),
])
# downsampling
self.conv_in = torch.nn.Conv2d(in_channels,
self.ch,
kernel_size=3,
stride=1,
padding=1)
curr_res = resolution
in_ch_mult = (1,)+tuple(ch_mult)
self.down = nn.ModuleList()
for i_level in range(self.num_resolutions):
block = nn.ModuleList()
attn = nn.ModuleList()
block_in = ch*in_ch_mult[i_level]
block_out = ch*ch_mult[i_level]
for i_block in range(self.num_res_blocks):
block.append(ResnetBlock(in_channels=block_in,
out_channels=block_out,
temb_channels=self.temb_ch,
dropout=dropout))
block_in = block_out
if curr_res in attn_resolutions:
attn.append(make_attn(block_in, attn_type=attn_type))
down = nn.Module()
down.block = block
down.attn = attn
if i_level != self.num_resolutions-1:
down.downsample = Downsample(block_in, resamp_with_conv)
curr_res = curr_res // 2
self.down.append(down)
# middle
self.mid = nn.Module()
self.mid.block_1 = ResnetBlock(in_channels=block_in,
out_channels=block_in,
temb_channels=self.temb_ch,
dropout=dropout)
self.mid.attn_1 = make_attn(block_in, attn_type=attn_type)
self.mid.block_2 = ResnetBlock(in_channels=block_in,
out_channels=block_in,
temb_channels=self.temb_ch,
dropout=dropout)
# upsampling
self.up = nn.ModuleList()
for i_level in reversed(range(self.num_resolutions)):
block = nn.ModuleList()
attn = nn.ModuleList()
block_out = ch*ch_mult[i_level]
skip_in = ch*ch_mult[i_level]
for i_block in range(self.num_res_blocks+1):
if i_block == self.num_res_blocks:
skip_in = ch*in_ch_mult[i_level]
block.append(ResnetBlock(in_channels=block_in+skip_in,
out_channels=block_out,
temb_channels=self.temb_ch,
dropout=dropout))
block_in = block_out
if curr_res in attn_resolutions:
attn.append(make_attn(block_in, attn_type=attn_type))
up = nn.Module()
up.block = block
up.attn = attn
if i_level != 0:
up.upsample = Upsample(block_in, resamp_with_conv)
curr_res = curr_res * 2
self.up.insert(0, up) # prepend to get consistent order
# end
self.norm_out = Normalize(block_in)
self.conv_out = torch.nn.Conv2d(block_in,
out_ch,
kernel_size=3,
stride=1,
padding=1)
def forward(self, x, t=None, context=None):
#assert x.shape[2] == x.shape[3] == self.resolution
if context is not None:
# assume aligned context, cat along channel axis
x = torch.cat((x, context), dim=1)
if self.use_timestep:
# timestep embedding
assert t is not None
temb = get_timestep_embedding(t, self.ch)
temb = self.temb.dense[0](temb)
temb = nonlinearity(temb)
temb = self.temb.dense[1](temb)
else:
temb = None
# downsampling
hs = [self.conv_in(x)]
for i_level in range(self.num_resolutions):
for i_block in range(self.num_res_blocks):
h = self.down[i_level].block[i_block](hs[-1], temb)
if len(self.down[i_level].attn) > 0:
h = self.down[i_level].attn[i_block](h)
hs.append(h)
if i_level != self.num_resolutions-1:
hs.append(self.down[i_level].downsample(hs[-1]))
# middle
h = hs[-1]
h = self.mid.block_1(h, temb)
h = self.mid.attn_1(h)
h = self.mid.block_2(h, temb)
# upsampling
for i_level in reversed(range(self.num_resolutions)):
for i_block in range(self.num_res_blocks+1):
h = self.up[i_level].block[i_block](
torch.cat([h, hs.pop()], dim=1), temb)
if len(self.up[i_level].attn) > 0:
h = self.up[i_level].attn[i_block](h)
if i_level != 0:
h = self.up[i_level].upsample(h)
# end
h = self.norm_out(h)
h = nonlinearity(h)
h = self.conv_out(h)
return h
def get_last_layer(self):
return self.conv_out.weight
下面是VQ-VAE中的encoder和decoder:
class Encoder(nn.Module):
def __init__(self, *, ch, out_ch, ch_mult=(1,2,4,8), num_res_blocks,
attn_resolutions, dropout=0.0, resamp_with_conv=True, in_channels,
resolution, z_channels, double_z=True, use_linear_attn=False, attn_type="vanilla",
**ignore_kwargs):
super().__init__()
if use_linear_attn: attn_type = "linear"
self.ch = ch
self.temb_ch = 0
self.num_resolutions = len(ch_mult)
self.num_res_blocks = num_res_blocks
self.resolution = resolution
self.in_channels = in_channels
# downsampling
self.conv_in = torch.nn.Conv2d(in_channels,
self.ch,
kernel_size=3,
stride=1,
padding=1)
curr_res = resolution
in_ch_mult = (1,)+tuple(ch_mult)
self.in_ch_mult = in_ch_mult
self.down = nn.ModuleList()
for i_level in range(self.num_resolutions):
block = nn.ModuleList()
attn = nn.ModuleList()
block_in = ch*in_ch_mult[i_level]
block_out = ch*ch_mult[i_level]
for i_block in range(self.num_res_blocks):
block.append(ResnetBlock(in_channels=block_in,
out_channels=block_out,
temb_channels=self.temb_ch,
dropout=dropout))
block_in = block_out
if curr_res in attn_resolutions:
attn.append(make_attn(block_in, attn_type=attn_type))
down = nn.Module()
down.block = block
down.attn = attn
if i_level != self.num_resolutions-1:
down.downsample = Downsample(block_in, resamp_with_conv)
curr_res = curr_res // 2
self.down.append(down)
# middle
self.mid = nn.Module()
self.mid.block_1 = ResnetBlock(in_channels=block_in,
out_channels=block_in,
temb_channels=self.temb_ch,
dropout=dropout)
self.mid.attn_1 = make_attn(block_in, attn_type=attn_type)
self.mid.block_2 = ResnetBlock(in_channels=block_in,
out_channels=block_in,
temb_channels=self.temb_ch,
dropout=dropout)
# end
self.norm_out = Normalize(block_in)
self.conv_out = torch.nn.Conv2d(block_in,
2*z_channels if double_z else z_channels,
kernel_size=3,
stride=1,
padding=1)
def forward(self, x):
# timestep embedding
temb = None
# downsampling
hs = [self.conv_in(x)]
for i_level in range(self.num_resolutions):
for i_block in range(self.num_res_blocks):
h = self.down[i_level].block[i_block](hs[-1], temb)
if len(self.down[i_level].attn) > 0:
h = self.down[i_level].attn[i_block](h)
hs.append(h)
if i_level != self.num_resolutions-1:
hs.append(self.down[i_level].downsample(hs[-1]))
# middle
h = hs[-1]
h = self.mid.block_1(h, temb)
h = self.mid.attn_1(h)
h = self.mid.block_2(h, temb)
# end
h = self.norm_out(h)
h = nonlinearity(h)
h = self.conv_out(h)
return h
class Decoder(nn.Module):
def __init__(self, *, ch, out_ch, ch_mult=(1,2,4,8), num_res_blocks,
attn_resolutions, dropout=0.0, resamp_with_conv=True, in_channels,
resolution, z_channels, give_pre_end=False, tanh_out=False, use_linear_attn=False,
attn_type="vanilla", **ignorekwargs):
super().__init__()
if use_linear_attn: attn_type = "linear"
self.ch = ch
self.temb_ch = 0
self.num_resolutions = len(ch_mult)
self.num_res_blocks = num_res_blocks
self.resolution = resolution
self.in_channels = in_channels
self.give_pre_end = give_pre_end
self.tanh_out = tanh_out
# compute in_ch_mult, block_in and curr_res at lowest res
in_ch_mult = (1,)+tuple(ch_mult)
block_in = ch*ch_mult[self.num_resolutions-1]
curr_res = resolution // 2**(self.num_resolutions-1)
self.z_shape = (1,z_channels,curr_res,curr_res)
print("Working with z of shape {} = {} dimensions.".format(
self.z_shape, np.prod(self.z_shape)))
# z to block_in
self.conv_in = torch.nn.Conv2d(z_channels,
block_in,
kernel_size=3,
stride=1,
padding=1)
# middle
self.mid = nn.Module()
self.mid.block_1 = ResnetBlock(in_channels=block_in,
out_channels=block_in,
temb_channels=self.temb_ch,
dropout=dropout)
self.mid.attn_1 = make_attn(block_in, attn_type=attn_type)
self.mid.block_2 = ResnetBlock(in_channels=block_in,
out_channels=block_in,
temb_channels=self.temb_ch,
dropout=dropout)
# upsampling
self.up = nn.ModuleList()
for i_level in reversed(range(self.num_resolutions)):
block = nn.ModuleList()
attn = nn.ModuleList()
block_out = ch*ch_mult[i_level]
for i_block in range(self.num_res_blocks+1):
block.append(ResnetBlock(in_channels=block_in,
out_channels=block_out,
temb_channels=self.temb_ch,
dropout=dropout))
block_in = block_out
if curr_res in attn_resolutions:
attn.append(make_attn(block_in, attn_type=attn_type))
up = nn.Module()
up.block = block
up.attn = attn
if i_level != 0:
up.upsample = Upsample(block_in, resamp_with_conv)
curr_res = curr_res * 2
self.up.insert(0, up) # prepend to get consistent order
# end
self.norm_out = Normalize(block_in)
self.conv_out = torch.nn.Conv2d(block_in,
out_ch,
kernel_size=3,
stride=1,
padding=1)
def forward(self, z):
#assert z.shape[1:] == self.z_shape[1:]
self.last_z_shape = z.shape
# timestep embedding
temb = None
# z to block_in
h = self.conv_in(z)
# middle
h = self.mid.block_1(h, temb)
h = self.mid.attn_1(h)
h = self.mid.block_2(h, temb)
# upsampling
for i_level in reversed(range(self.num_resolutions)):
for i_block in range(self.num_res_blocks+1):
h = self.up[i_level].block[i_block](h, temb)
if len(self.up[i_level].attn) > 0:
h = self.up[i_level].attn[i_block](h)
if i_level != 0:
h = self.up[i_level].upsample(h)
# end
if self.give_pre_end:
return h
h = self.norm_out(h)
h = nonlinearity(h)
h = self.conv_out(h)
if self.tanh_out:
h = torch.tanh(h)
return h
3.1.1 model.py 工具类
a.make_beta_schedule
这个方法在之前ddpm就用过,主要作用就是获得betas:
def make_beta_schedule(schedule, n_timestep, linear_start=1e-4, linear_end=2e-2, cosine_s=8e-3):
if schedule == "linear":
betas = (
torch.linspace(linear_start ** 0.5, linear_end ** 0.5, n_timestep, dtype=torch.float64) ** 2
)
elif schedule == "cosine":
timesteps = (
torch.arange(n_timestep + 1, dtype=torch.float64) / n_timestep + cosine_s
)
alphas = timesteps / (1 + cosine_s) * np.pi / 2
alphas = torch.cos(alphas).pow(2)
alphas = alphas / alphas[0]
betas = 1 - alphas[1:] / alphas[:-1]
betas = np.clip(betas, a_min=0, a_max=0.999)
elif schedule == "sqrt_linear":
betas = torch.linspace(linear_start, linear_end, n_timestep, dtype=torch.float64)
elif schedule == "sqrt":
betas = torch.linspace(linear_start, linear_end, n_timestep, dtype=torch.float64) ** 0.5
else:
raise ValueError(f"schedule '{schedule}' unknown.")
return betas.numpy()
b.make_ddim_timesteps
略
c.extract_into_tensor
将张量 a 中根据张量 t 中的索引提取的元素按照输入张量 x 的形状进行重新排列,并返回结果
def extract_into_tensor(a, t, x_shape):
b, *_ = t.shape
out = a.gather(-1, t)
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
3.1 encoders文件夹
3.1.1 modules.py
a.BERTTokenizer方法
class BERTTokenizer(AbstractEncoder):
""" Uses a pretrained BERT tokenizer by huggingface. Vocab size: 30522 (?)"""
def __init__(self, device="cuda", vq_interface=True, max_length=77):
super().__init__()
#导包
from transformers import BertTokenizerFast # TODO: add to reuquirements
#设置tokenizer已经预训练模型
self.tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
self.device = device
self.vq_interface = vq_interface
self.max_length = max_length
def forward(self, text):
batch_encoding = self.tokenizer(text, truncation=True, max_length=self.max_length, return_length=True,
return_overflowing_tokens=False, padding="max_length", return_tensors="pt")
#提取token列表
tokens = batch_encoding["input_ids"].to(self.device)
return tokens
@torch.no_grad()
def encode(self, text):
tokens = self(text)
if not self.vq_interface:
return tokens
return None, None, [None, None, tokens]
def decode(self, text):
return text
b.BERTEmbedder方法
使用BERT tokenizr模型并添加一些transformer编码器层
class BERTEmbedder(AbstractEncoder):
"""“使用BERT tokenizr模型并添加一些transformer编码器层”"""
def __init__(self, n_embed, n_layer, vocab_size=30522, max_seq_len=77,
device="cuda",use_tokenizer=True, embedding_dropout=0.0):
super().__init__()
self.use_tknz_fn = use_tokenizer
if self.use_tknz_fn:
self.tknz_fn = BERTTokenizer(vq_interface=False, max_length=max_seq_len)
self.device = device
self.transformer = TransformerWrapper(num_tokens=vocab_size, max_seq_len=max_seq_len,
attn_layers=Encoder(dim=n_embed, depth=n_layer),
emb_dropout=embedding_dropout)
def forward(self, text):
if self.use_tknz_fn:
tokens = self.tknz_fn(text)#.to(self.device)
else:
tokens = text
z = self.transformer(tokens, return_embeddings=True)
return z
def encode(self, text):
# output of length 77
return self(text)
c.FrozenCLIPEmbedder
class FrozenCLIPEmbedder(AbstractEncoder):
"""Uses the CLIP transformer encoder for text (from Hugging Face)"""
def __init__(self, version="openai/clip-vit-large-patch14", device="cuda", max_length=77):
super().__init__()
self.tokenizer = CLIPTokenizer.from_pretrained(version)
self.transformer = CLIPTextModel.from_pretrained(version)
self.device = device
self.max_length = max_length
self.freeze()
def freeze(self):
self.transformer = self.transformer.eval()
for param in self.parameters():
param.requires_grad = False
def forward(self, text):
batch_encoding = self.tokenizer(text, truncation=True, max_length=self.max_length, return_length=True,
return_overflowing_tokens=False, padding="max_length", return_tensors="pt")
tokens = batch_encoding["input_ids"].to(self.device)
outputs = self.transformer(input_ids=tokens)
z = outputs.last_hidden_state
return z
def encode(self, text):
return self(text)
d.FrozenClipImageEmbedder
class FrozenClipImageEmbedder(nn.Module):
"""
Uses the CLIP image encoder.
"""
def __init__(
self,
model,
jit=False,
device='cuda' if torch.cuda.is_available() else 'cpu',
antialias=False,
):
super().__init__()
self.model, _ = clip.load(name=model, device=device, jit=jit)
self.antialias = antialias
self.register_buffer('mean', torch.Tensor([0.48145466, 0.4578275, 0.40821073]), persistent=False)
self.register_buffer('std', torch.Tensor([0.26862954, 0.26130258, 0.27577711]), persistent=False)
def preprocess(self, x):
# normalize to [0,1]
x = kornia.geometry.resize(x, (224, 224),
interpolation='bicubic',align_corners=True,
antialias=self.antialias)
x = (x + 1.) / 2.
# renormalize according to clip
x = kornia.enhance.normalize(x, self.mean, self.std)
return x
def forward(self, x):
# x is assumed to be in range [-1,1]
return self.model.encode_image(self.preprocess(x))
3.2.image_degradation文件夹
主要存放一些处理图像的方法,以后用到再总结
3.3.loss文件夹
class LPIPSWithDiscriminator 感知损失:用于度量两张图像之间的差别
cass VQLPIPSWithDiscriminator VQ感知损失
3.4.attention.py
a.GEGLU类
#GELU可以看作dropout的思想和relu的结合,主要是为激活函数引入了随机性使得模型训练过程更加鲁棒
class GEGLU(nn.Module):
def __init__(self, dim_in, dim_out):
super().__init__()
self.proj = nn.Linear(dim_in, dim_out * 2)
def forward(self, x):
x, gate = self.proj(x).chunk(2, dim=-1)
return x * F.gelu(gate)
b.FeedForward/多层感知机
class FeedForward(nn.Module):
def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.):
super().__init__()
inner_dim = int(dim * mult)
dim_out = default(dim_out, dim)
project_in = nn.Sequential(
nn.Linear(dim, inner_dim),
nn.GELU()
) if not glu else GEGLU(dim, inner_dim)
self.net = nn.Sequential(
project_in,
nn.Dropout(dropout),
nn.Linear(inner_dim, dim_out)
)
def forward(self, x):
return self.net(x)
c. LinearAttention类
和普通attention不同的就是去掉softmax,先计算kv,再乘q,降低复杂度
class LinearAttention(nn.Module):
def __init__(self, dim, heads=4, dim_head=32):
super().__init__()
self.heads = heads
hidden_dim = dim_head * heads
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias = False)
self.to_out = nn.Conv2d(hidden_dim, dim, 1)
def forward(self, x):
b, c, h, w = x.shape
qkv = self.to_qkv(x)
#将b c h w变成三个 b heads c h w维度的张量
q, k, v = rearrange(qkv, 'b (qkv heads c) h w -> qkv b heads c (h w)', heads = self.heads, qkv=3)
k = k.softmax(dim=-1)
#计算kv
context = torch.einsum('bhdn,bhen->bhde', k, v)
#乘q
out = torch.einsum('bhde,bhdn->bhen', context, q)
#维度变换
out = rearrange(out, 'b heads c (h w) -> b (heads c) h w', heads=self.heads, h=h, w=w)
#多头合并
return self.to_out(out)
d.SpatialSelfAttention
一个单头自注意力机制块
class SpatialSelfAttention(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.in_channels = in_channels
self.norm = Normalize(in_channels)
self.q = torch.nn.Conv2d(in_channels,
in_channels,
kernel_size=1,
stride=1,
padding=0)
self.k = torch.nn.Conv2d(in_channels,
in_channels,
kernel_size=1,
stride=1,
padding=0)
self.v = torch.nn.Conv2d(in_channels,
in_channels,
kernel_size=1,
stride=1,
padding=0)
self.proj_out = torch.nn.Conv2d(in_channels,
in_channels,
kernel_size=1,
stride=1,
padding=0)
def forward(self, x):
h_ = x
h_ = self.norm(h_)
q = self.q(h_)
k = self.k(h_)
v = self.v(h_)
# compute attention
b,c,h,w = q.shape
q = rearrange(q, 'b c h w -> b (h w) c')
k = rearrange(k, 'b c h w -> b c (h w)')
w_ = torch.einsum('bij,bjk->bik', q, k)
w_ = w_ * (int(c)**(-0.5))
w_ = torch.nn.functional.softmax(w_, dim=2)
# attend to values
v = rearrange(v, 'b c h w -> b c (h w)')
w_ = rearrange(w_, 'b i j -> b j i')
h_ = torch.einsum('bij,bjk->bik', v, w_)
h_ = rearrange(h_, 'b c (h w) -> b c h w', h=h)
h_ = self.proj_out(h_)
return x+h_
d.CrossAttention
多头交叉注意力块
class CrossAttention(nn.Module):
def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.):
super().__init__()
inner_dim = dim_head * heads
context_dim = default(context_dim, query_dim)
self.scale = dim_head ** -0.5
self.heads = heads
self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, query_dim),
nn.Dropout(dropout)
)
def forward(self, x, context=None, mask=None):
h = self.heads
q = self.to_q(x)
context = default(context, x)
k = self.to_k(context)
v = self.to_v(context)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h=h), (q, k, v))
sim = einsum('b i d, b j d -> b i j', q, k) * self.scale
if exists(mask):
mask = rearrange(mask, 'b ... -> b (...)')
max_neg_value = -torch.finfo(sim.dtype).max
mask = repeat(mask, 'b j -> (b h) () j', h=h)
sim.masked_fill_(~mask, max_neg_value)
# attention, what we cannot get enough of
attn = sim.softmax(dim=-1)
out = einsum('b i j, b j d -> b i d', attn, v)
out = rearrange(out, '(b h) n d -> b n (h d)', h=h)
return self.to_out(out)
e.BasicTransformerBlock
class BasicTransformerBlock(nn.Module):
def __init__(self, dim, n_heads, d_head, dropout=0., context_dim=None, gated_ff=True, checkpoint=True):
super().__init__()
self.attn1 = CrossAttention(query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout) # is a self-attention
self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
self.attn2 = CrossAttention(query_dim=dim, context_dim=context_dim,
heads=n_heads, dim_head=d_head, dropout=dropout) # is self-attn if context is none
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.norm3 = nn.LayerNorm(dim)
self.checkpoint = checkpoint
def forward(self, x, context=None):
return checkpoint(self._forward, (x, context), self.parameters(), self.checkpoint)
def _forward(self, x, context=None):
x = self.attn1(self.norm1(x)) + x
x = self.attn2(self.norm2(x), context=context) + x
x = self.ff(self.norm3(x)) + x
return x
f.SpatialTransformer
class SpatialTransformer(nn.Module):
"""
Transformer block for image-like data.
First, project the input (aka embedding)
and reshape to b, t, d.
Then apply standard transformer action.
Finally, reshape to image
"""
def __init__(self, in_channels, n_heads, d_head,
depth=1, dropout=0., context_dim=None):
super().__init__()
self.in_channels = in_channels
inner_dim = n_heads * d_head
self.norm = Normalize(in_channels)
self.proj_in = nn.Conv2d(in_channels,
inner_dim,
kernel_size=1,
stride=1,
padding=0)
self.transformer_blocks = nn.ModuleList(
[BasicTransformerBlock(inner_dim, n_heads, d_head, dropout=dropout, context_dim=context_dim)
for d in range(depth)]
)
self.proj_out = zero_module(nn.Conv2d(inner_dim,
in_channels,
kernel_size=1,
stride=1,
padding=0))
def forward(self, x, context=None):
# note: if no context is given, cross-attention defaults to self-attention
b, c, h, w = x.shape
x_in = x
x = self.norm(x)
x = self.proj_in(x)
x = rearrange(x, 'b c h w -> b (h w) c')
for block in self.transformer_blocks:
x = block(x, context=context)
x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
x = self.proj_out(x)
return x + x_in
3.5.ema.py
class LitEma(nn.Module):
def __init__(self, model, decay=0.9999, use_num_upates=True):
super().__init__()
if decay < 0.0 or decay > 1.0:
raise ValueError('Decay must be between 0 and 1')
self.m_name2s_name = {
}
self.register_buffer('decay', torch.tensor(decay, dtype=torch.float32))
#存储模型参数的更新次数
self.register_buffer('num_updates', torch.tensor(0,dtype=torch.int) if use_num_upates
else torch.tensor(-1,dtype=torch.int))
#遍历传入模型的所有参数
for name, p in model.named_parameters():
#检查参数是否需要梯度
if p.requires_grad:
#remove as '.'-character is not allowed in buffers
#将参数名中的点('.')替换为空字符串,因为点字符在缓冲区的名称中不被允许
s_name = name.replace('.','')
#将模型参数名和对应的EMA参数名添加到m_name2s_name字典中
self.m_name2s_name.update({
name:s_name})
#储模型参数的克隆数据,该数据在计算EMA时会用到
self.register_buffer(s_name,p.clone().detach().data)
#用于存储收集到的参数
self.collected_params = []
#公式: EMA_t = decay*EMA_t-1 + (1-decay)*w_t
def forward(self,model):
decay = self.decay
if self.num_updates >= 0:
self.num_updates += 1
#更新衰减系数,确保其不超过上限。
decay = min(self.decay,(1 + self.num_updates) / (10 + self.num_updates))
#计算EMA更新时的权重 也就是w之前的那个(1-decay)
one_minus_decay = 1.0 - decay
with torch.no_grad():
#获取传入模型的所有参数,并将其转换为字典
m_param = dict(model.named_parameters())
shadow_params = dict(self.named_buffers())
for key in m_param:
if m_param[key].requires_grad:
#计算EMA参数的更新
sname = self.m_name2s_name[key]
shadow_params[sname] = shadow_params[sname].type_as(m_param[key])
shadow_params[sname].sub_(one_minus_decay * (shadow_params[sname] - m_param[key]))
else:
assert not key in self.m_name2s_name
def copy_to(self, model):
m_param = dict(model.named_parameters())
shadow_params = dict(self.named_buffers())
for key in m_param:
if m_param[key].requires_grad:
m_param[key].data.copy_(shadow_params[self.m_name2s_name[key]].data)
else:
assert not key in self.m_name2s_name
3.6.embedding_manager.py
根据string获得token进而获得embedding
#一个进行embedding的类
"""
embedder 嵌入器
placeholder_strings 标记的字符串列表
initializer_words 初始嵌入的单词列表
num_vectors_per_token 每个标记的嵌入向量数
"""
class EmbeddingManager(nn.Module):
def __init__(
self,
embedder,
placeholder_strings=None,
initializer_words=None,
per_image_tokens=False,
num_vectors_per_token=1,
progressive_words=False,
**kwargs
):
super().__init__()
#存储字符串到标记的映射
self.string_to_token_dict = {
}
#存储字符串到参数的映射
self.string_to_param_dict = nn.ParameterDict()
#用于存储初始化的嵌入,不会被优化
self.initial_embeddings = nn.ParameterDict() # These should not be optimized
self.progressive_words = progressive_words
self.progressive_counter = 0
self.max_vectors_per_token = num_vectors_per_token
#使用clip encoder
if hasattr(embedder, 'tokenizer'): # using Stable Diffusion's CLIP encoder
self.is_clip = True
#选择相应的函数来获取字符串的token和标记的embedding
get_token_for_string = partial(get_clip_token_for_string, embedder.tokenizer)
get_embedding_for_tkn = partial(get_embedding_for_clip_token, embedder.transformer.text_model.embeddings)
token_dim = 768
else: # using LDM's BERT encoder
self.is_clip = False
get_token_for_string = partial(get_bert_token_for_string, embedder.tknz_fn)
get_embedding_for_tkn = embedder.transformer.token_emb
token_dim = 1280
if per_image_tokens:
placeholder_strings.extend(per_img_token_list)
#对于 placeholder_strings 中的每个占位符字符串
for idx, placeholder_string in enumerate(placeholder_strings):
#获取token
token = get_token_for_string(placeholder_string)
#如果存在初始化单词或者索引小于初始化单词长度
if initializer_words and idx < len(initializer_words):
#获取相应索引处的初始化单词的token
init_word_token = get_token_for_string(initializer_words[idx])
#获取embedding
with torch.no_grad():
init_word_embedding = get_embedding_for_tkn(init_word_token.cpu())
#为初始化单词的嵌入向量创建参数,并设置为可训练的(requires_grad=True)
token_params = torch.nn.Parameter(init_word_embedding.unsqueeze(0).repeat(num_vectors_per_token, 1), requires_grad=True)
#将初始化单词的嵌入向量存储到self.initial_embeddings中,但这个向量的参数不可训练(requires_grad=False)。
self.initial_embeddings[placeholder_string] = torch.nn.Parameter(init_word_embedding.unsqueeze(0).repeat(num_vectors_per_token, 1), requires_grad=False)
else:
#为当前占位符字符串创建一个随机初始化的参数,并设置为可训练的(requires_grad=True)
token_params = torch.nn.Parameter(torch.rand(size=(num_vectors_per_token, token_dim), requires_grad=True))
#将占位符字符串与其对应的标记token存储到self.string_to_token_dict字典中
self.string_to_token_dict[placeholder_string] = token
#将占位符字符串与其对应的参数token_params存储到self.string_to_param_dict字典中
self.string_to_param_dict[placeholder_string] = token_params
def forward(
self,
tokenized_text,
embedded_text,
):
b, n, device = *tokenized_text.shape, tokenized_text.device
#对字符串到token的字典进行循环迭代
for placeholder_string, placeholder_token in self.string_to_token_dict.items():
#embedding
placeholder_embedding = self.string_to_param_dict[placeholder_string].to(device)
#检查是否每个 token 只有一个嵌入向量。如果是,则直接通过 torch.where 找到占位符在 tokenized_text 中的位置,并将对应的嵌入向量替换原文本中的值
if self.max_vectors_per_token == 1: # If there's only one vector per token, we can do a simple replacement
placeholder_idx = torch.where(tokenized_text == placeholder_token.to(device))
#将embedding存入embedded_text
embedded_text[placeholder_idx] = placeholder_embedding
else: # otherwise, need to insert and keep track of changing indices
if self.progressive_words:
self.progressive_counter += 1
max_step_tokens = 1 + self.progressive_counter // PROGRESSIVE_SCALE
else:
max_step_tokens = self.max_vectors_per_token
num_vectors_for_token = min(placeholder_embedding.shape[0], max_step_tokens)
placeholder_rows, placeholder_cols = torch.where(tokenized_text == placeholder_token.to(device))
if placeholder_rows.nelement() == 0:
continue
sorted_cols, sort_idx = torch.sort(placeholder_cols, descending=True)
sorted_rows = placeholder_rows[sort_idx]
for idx in range(len(sorted_rows)):
row = sorted_rows[idx]
col = sorted_cols[idx]
new_token_row = torch.cat([tokenized_text[row][:col], placeholder_token.repeat(num_vectors_for_token).to(device), tokenized_text[row][col + 1:]], axis=0)[:n]
new_embed_row = torch.cat([embedded_text[row][:col], placeholder_embedding[:num_vectors_for_token], embedded_text[row][col + 1:]], axis=0)[:n]
embedded_text[row] = new_embed_row
tokenized_text[row] = new_token_row
return embedded_text
4 utils.py文件
定义了一些处理图像的工具方法
5 lr_scheduler.py文件
定义了些动态调整学习率的类
#在训练过程中根据给定的步数动态调整学习率,采用预热和余弦衰减的策略,以更好地训练深度学习模型
class LambdaWarmUpCosineScheduler:
"""
note: use with a base_lr of 1.0
warm_up_steps:学习率预热所需的步数
max_decay_steps:最大的衰减步数
verbosity_interval:打印日志信息的间隔步数,默认为0(不打印)
"""
def __init__(self, warm_up_steps, lr_min, lr_max, lr_start, max_decay_steps, verbosity_interval=0):
self.lr_warm_up_steps = warm_up_steps
self.lr_start = lr_start
self.lr_min = lr_min
self.lr_max = lr_max
self.lr_max_decay_steps = max_decay_steps
self.last_lr = 0.
self.verbosity_interval = verbosity_interval
"""
schedule 方法用于计算给定步数n对应的学习率值,主要包含两个阶段:
预热阶段:当步数n小于预热步数时,采用线性方式逐步增加学习率。
衰减阶段:步数超过预热步数后,根据余弦函数的变化模式动态调整学习率。
"""
def schedule(self, n, **kwargs):
if self.verbosity_interval > 0:
if n % self.verbosity_interval == 0: print(f"current step: {n}, recent lr-multiplier: {self.last_lr}")
if n < self.lr_warm_up_steps:
lr = (self.lr_max - self.lr_start) / self.lr_warm_up_steps * n + self.lr_start
self.last_lr = lr
return lr
else:
t = (n - self.lr_warm_up_steps) / (self.lr_max_decay_steps - self.lr_warm_up_steps)
t = min(t, 1.0)
lr = self.lr_min + 0.5 * (self.lr_max - self.lr_min) * (
1 + np.cos(t * np.pi))
self.last_lr = lr
return lr
def __call__(self, n, **kwargs):
return self.schedule(n,**kwargs)
#在训练过程中根据给定的步数动态调整学习率,与前一个类相比,这个类增加了对重复迭代的支持,并通过列表进行配置
class LambdaWarmUpCosineScheduler2:
"""
supports repeated iterations, configurable via lists
note: use with a base_lr of 1.0.
cycle_lengths:每个循环(cycle)的步数列表
"""
def __init__(self, warm_up_steps, f_min, f_max, f_start, cycle_lengths, verbosity_interval=0):
assert len(warm_up_steps) == len(f_min) == len(f_max) == len(f_start) == len(cycle_lengths)
self.lr_warm_up_steps = warm_up_steps
self.f_start = f_start
self.f_min = f_min
self.f_max = f_max
self.cycle_lengths = cycle_lengths
self.cum_cycles = np.cumsum([0] + list(self.cycle_lengths))
self.last_f = 0.
self.verbosity_interval = verbosity_interval
# find_in_interval 方法用于确定给定步数 n 在哪个循环(cycle)的区间内。
def find_in_interval(self, n):
interval = 0
for cl in self.cum_cycles[1:]:
if n <= cl:
return interval
interval += 1
"""
schedule 方法用于计算给定步数n对应的学习率值,主要包含两个阶段:
预热阶段:当步数n小于当前循环的预热步数时,采用线性方式逐步增加学习率。
衰减阶段:步数超过当前循环的预热步数后,根据余弦函数的变化模式动态调整学习率。
"""
def schedule(self, n, **kwargs):
cycle = self.find_in_interval(n)
n = n - self.cum_cycles[cycle]
if self.verbosity_interval > 0:
if n % self.verbosity_interval == 0: print(f"current step: {n}, recent lr-multiplier: {self.last_f}, "
f"current cycle {cycle}")
if n < self.lr_warm_up_steps[cycle]:
f = (self.f_max[cycle] - self.f_start[cycle]) / self.lr_warm_up_steps[cycle] * n + self.f_start[cycle]
self.last_f = f
return f
else:
t = (n - self.lr_warm_up_steps[cycle]) / (self.cycle_lengths[cycle] - self.lr_warm_up_steps[cycle])
t = min(t, 1.0)
f = self.f_min[cycle] + 0.5 * (self.f_max[cycle] - self.f_min[cycle]) * (
1 + np.cos(t * np.pi))
self.last_f = f
return f
def __call__(self, n, **kwargs):
return self.schedule(n, **kwargs)
#线性调整学习率
class LambdaLinearScheduler(LambdaWarmUpCosineScheduler2):
def schedule(self, n, **kwargs):
#首先,通过调用父类的 find_in_interval 方法确定当前步数 n 所在的循环(cycle)
cycle = self.find_in_interval(n)
#接着,计算相对于当前循环的步数 n
n = n - self.cum_cycles[cycle]
#如果 n 小于当前循环的预热步数,使用线性方式逐步增加学习率,这与父类中的预热阶段逻辑相同
if self.verbosity_interval > 0:
if n % self.verbosity_interval == 0: print(f"current step: {n}, recent lr-multiplier: {self.last_f}, "
f"current cycle {cycle}")
#如果 n 大于等于当前循环的预热步数,则采用线性方式逐步减小学习率,直到当前循环结束。具体的计算方式为:f_min + (f_max - f_min) * (cycle_lengths - n) / cycle_lengths
if n < self.lr_warm_up_steps[cycle]:
f = (self.f_max[cycle] - self.f_start[cycle]) / self.lr_warm_up_steps[cycle] * n + self.f_start[cycle]
self.last_f = f
return f
else:
f = self.f_min[cycle] + (self.f_max[cycle] - self.f_min[cycle]) * (self.cycle_lengths[cycle] - n) / (self.cycle_lengths[cycle])
self.last_f = f
return f
二 scripts文件夹
txt2img.py文件
仅展示重要代码
#加载模型配置
config = OmegaConf.load(f"{opt.config}")
#加载参数
model = load_model_from_config(config, f"{opt.ckpt}")
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model = model.to(device)
#选择采样策略
if opt.dpm_solver:
sampler = DPMSolverSampler(model)
elif opt.plms:
sampler = PLMSSampler(model)
else:
sampler = DDIMSampler(model)
os.makedirs(opt.outdir, exist_ok=True)
outpath = opt.outdir
print("Creating invisible watermark encoder (see https://github.com/ShieldMnt/invisible-watermark)...")
wm = "StableDiffusionV1"
wm_encoder = WatermarkEncoder()
wm_encoder.set_watermark('bytes', wm.encode('utf-8'))
batch_size = opt.n_samples
n_rows = opt.n_rows if opt.n_rows > 0 else batch_size
#加载提示
if not opt.from_file:
prompt = opt.prompt
assert prompt is not None
data = [batch_size * [prompt]]
else:
print(f"reading prompts from {opt.from_file}")
with open(opt.from_file, "r") as f:
data = f.read().splitlines()
data = list(chunk(data, batch_size))
#设置采样输出目录
sample_path = os.path.join(outpath, "samples")
os.makedirs(sample_path, exist_ok=True)
base_count = len(os.listdir(sample_path))
grid_count = len(os.listdir(outpath)) - 1
start_code = None
if opt.fixed_code:
start_code = torch.randn([opt.n_samples, opt.C, opt.H // opt.f, opt.W // opt.f], device=device)
precision_scope = autocast if opt.precision=="autocast" else nullcontext
with torch.no_grad():
with precision_scope("cuda"):
#启用指数移动平均(EMA)
with model.ema_scope():
tic = time.time()
all_samples = list()
for n in trange(opt.n_iter, desc="Sampling"):
for prompts in tqdm(data, desc="data"):
uc = None
if opt.scale != 1.0:
#使用模型的方法获取学习到的条件(conditioning),这里使用一个空的条件进行演示
uc = model.get_learned_conditioning(batch_size * [""])
#如果提示(prompts)是一个元组,将其转换为列表
if isinstance(prompts, tuple):
prompts = list(prompts)
#对提示编码
c = model.get_learned_conditioning(prompts)
shape = [opt.C, opt.H // opt.f, opt.W // opt.f]
#使用采样器(sampler)生成一些样本,具体的采样过程包括了条件、形状等参数
samples_ddim, _ = sampler.sample(S=opt.ddim_steps,
conditioning=c,
batch_size=opt.n_samples,
shape=shape,
verbose=False,
unconditional_guidance_scale=opt.scale,
unconditional_conditioning=uc,
eta=opt.ddim_eta,
x_T=start_code)
#对采样结果解码
x_samples_ddim = model.decode_first_stage(samples_ddim)
#对解码后的样本进行限制,确保像素值在 [0, 1] 范围内
x_samples_ddim = torch.clamp((x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0)
#将样本移到 CPU,调整维度的顺序,转换为 NumPy 数组
x_samples_ddim = x_samples_ddim.cpu().permute(0, 2, 3, 1).numpy()
x_checked_image, has_nsfw_concept = check_safety(x_samples_ddim)
#将检查后的图像转换为 PyTorch 张量,并调整维度的顺序
x_checked_image_torch = torch.from_numpy(x_checked_image).permute(0, 3, 1, 2)
#如果不跳过保存操作,保存图像
if not opt.skip_save:
for x_sample in x_checked_image_torch:
x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
img = Image.fromarray(x_sample.astype(np.uint8))
img = put_watermark(img, wm_encoder)
img.save(os.path.join(sample_path, f"{base_count:05}.png"))
base_count += 1
if not opt.skip_grid:
all_samples.append(x_checked_image_torch)
智能推荐
攻防世界_难度8_happy_puzzle_攻防世界困难模式攻略图文-程序员宅基地
文章浏览阅读645次。这个肯定是末尾的IDAT了,因为IDAT必须要满了才会开始一下个IDAT,这个明显就是末尾的IDAT了。,对应下面的create_head()代码。,对应下面的create_tail()代码。不要考虑爆破,我已经试了一下,太多情况了。题目来源:UNCTF。_攻防世界困难模式攻略图文
达梦数据库的导出(备份)、导入_达梦数据库导入导出-程序员宅基地
文章浏览阅读2.9k次,点赞3次,收藏10次。偶尔会用到,记录、分享。1. 数据库导出1.1 切换到dmdba用户su - dmdba1.2 进入达梦数据库安装路径的bin目录,执行导库操作 导出语句:./dexp cwy_init/[email protected]:5236 file=cwy_init.dmp log=cwy_init_exp.log 注释: cwy_init/init_123..._达梦数据库导入导出
js引入kindeditor富文本编辑器的使用_kindeditor.js-程序员宅基地
文章浏览阅读1.9k次。1. 在官网上下载KindEditor文件,可以删掉不需要要到的jsp,asp,asp.net和php文件夹。接着把文件夹放到项目文件目录下。2. 修改html文件,在页面引入js文件:<script type="text/javascript" src="./kindeditor/kindeditor-all.js"></script><script type="text/javascript" src="./kindeditor/lang/zh-CN.js"_kindeditor.js
STM32学习过程记录11——基于STM32G431CBU6硬件SPI+DMA的高效WS2812B控制方法-程序员宅基地
文章浏览阅读2.3k次,点赞6次,收藏14次。SPI的详情简介不必赘述。假设我们通过SPI发送0xAA,我们的数据线就会变为10101010,通过修改不同的内容,即可修改SPI中0和1的持续时间。比如0xF0即为前半周期为高电平,后半周期为低电平的状态。在SPI的通信模式中,CPHA配置会影响该实验,下图展示了不同采样位置的SPI时序图[1]。CPOL = 0,CPHA = 1:CLK空闲状态 = 低电平,数据在下降沿采样,并在上升沿移出CPOL = 0,CPHA = 0:CLK空闲状态 = 低电平,数据在上升沿采样,并在下降沿移出。_stm32g431cbu6
计算机网络-数据链路层_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏8次。数据链路层习题自测问题1.数据链路(即逻辑链路)与链路(即物理链路)有何区别?“电路接通了”与”数据链路接通了”的区别何在?2.数据链路层中的链路控制包括哪些功能?试讨论数据链路层做成可靠的链路层有哪些优点和缺点。3.网络适配器的作用是什么?网络适配器工作在哪一层?4.数据链路层的三个基本问题(帧定界、透明传输和差错检测)为什么都必须加以解决?5.如果在数据链路层不进行帧定界,会发生什么问题?6.PPP协议的主要特点是什么?为什么PPP不使用帧的编号?PPP适用于什么情况?为什么PPP协议不_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输
软件测试工程师移民加拿大_无证移民,未受过软件工程师的教育(第1部分)-程序员宅基地
文章浏览阅读587次。软件测试工程师移民加拿大 无证移民,未受过软件工程师的教育(第1部分) (Undocumented Immigrant With No Education to Software Engineer(Part 1))Before I start, I want you to please bear with me on the way I write, I have very little gen...
随便推点
Thinkpad X250 secure boot failed 启动失败问题解决_安装完系统提示secureboot failure-程序员宅基地
文章浏览阅读304次。Thinkpad X250笔记本电脑,装的是FreeBSD,进入BIOS修改虚拟化配置(其后可能是误设置了安全开机),保存退出后系统无法启动,显示:secure boot failed ,把自己惊出一身冷汗,因为这台笔记本刚好还没开始做备份.....根据错误提示,到bios里面去找相关配置,在Security里面找到了Secure Boot选项,发现果然被设置为Enabled,将其修改为Disabled ,再开机,终于正常启动了。_安装完系统提示secureboot failure
C++如何做字符串分割(5种方法)_c++ 字符串分割-程序员宅基地
文章浏览阅读10w+次,点赞93次,收藏352次。1、用strtok函数进行字符串分割原型: char *strtok(char *str, const char *delim);功能:分解字符串为一组字符串。参数说明:str为要分解的字符串,delim为分隔符字符串。返回值:从str开头开始的一个个被分割的串。当没有被分割的串时则返回NULL。其它:strtok函数线程不安全,可以使用strtok_r替代。示例://借助strtok实现split#include <string.h>#include <stdio.h&_c++ 字符串分割
2013第四届蓝桥杯 C/C++本科A组 真题答案解析_2013年第四届c a组蓝桥杯省赛真题解答-程序员宅基地
文章浏览阅读2.3k次。1 .高斯日记 大数学家高斯有个好习惯:无论如何都要记日记。他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210后来人们知道,那个整数就是日期,它表示那一天是高斯出生后的第几天。这或许也是个好习惯,它时时刻刻提醒着主人:日子又过去一天,还有多少时光可以用于浪费呢?高斯出生于:1777年4月30日。在高斯发现的一个重要定理的日记_2013年第四届c a组蓝桥杯省赛真题解答
基于供需算法优化的核极限学习机(KELM)分类算法-程序员宅基地
文章浏览阅读851次,点赞17次,收藏22次。摘要:本文利用供需算法对核极限学习机(KELM)进行优化,并用于分类。
metasploitable2渗透测试_metasploitable2怎么进入-程序员宅基地
文章浏览阅读1.1k次。一、系统弱密码登录1、在kali上执行命令行telnet 192.168.26.1292、Login和password都输入msfadmin3、登录成功,进入系统4、测试如下:二、MySQL弱密码登录:1、在kali上执行mysql –h 192.168.26.129 –u root2、登录成功,进入MySQL系统3、测试效果:三、PostgreSQL弱密码登录1、在Kali上执行psql -h 192.168.26.129 –U post..._metasploitable2怎么进入
Python学习之路:从入门到精通的指南_python人工智能开发从入门到精通pdf-程序员宅基地
文章浏览阅读257次。本文将为初学者提供Python学习的详细指南,从Python的历史、基础语法和数据类型到面向对象编程、模块和库的使用。通过本文,您将能够掌握Python编程的核心概念,为今后的编程学习和实践打下坚实基础。_python人工智能开发从入门到精通pdf