MySQL的Join_mysql join-程序员宅基地
1.Join用法
Join连接两张表,大致分为内连接,外连接,右连接,左连接,自然连接。
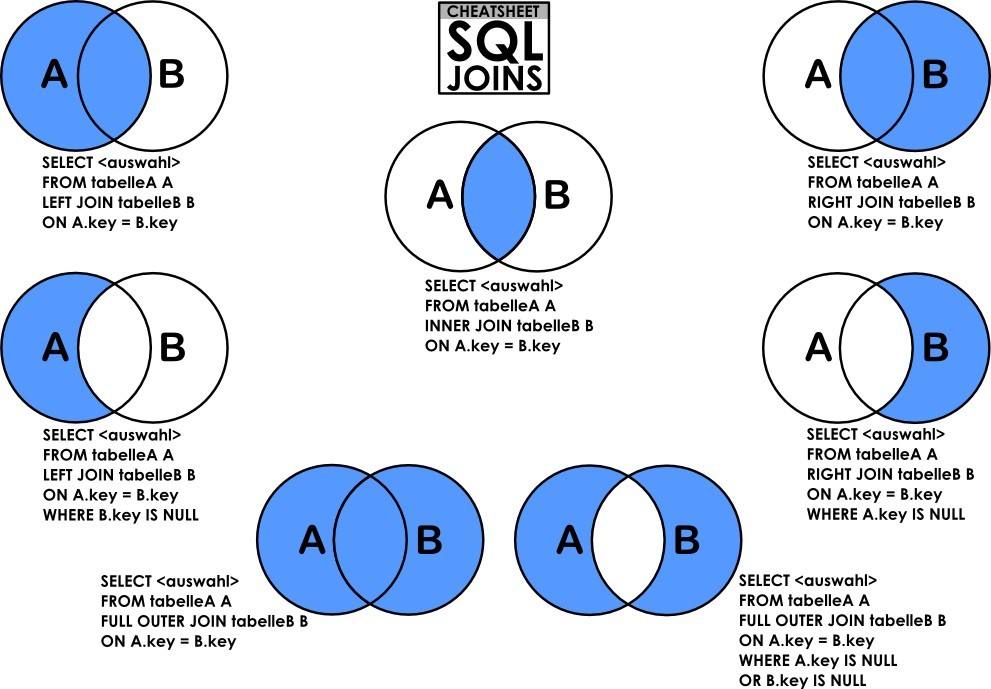
内连接又叫等值连接,此时的inner可以省略。
USING语句
MySQL中连接SQL语句中,ON子句的语法格式为:table1.column_name = table2.column_name。当模式设计对联接表的列采用了相同的命名样式时,就可以使用 USING语法来简化 ON 语法,格式为:USING(column_name)。 所以,USING的功能相当于ON,区别在于USING指定一个属性名用于连接两个表,而ON指定一个条件。另外,SELECT *时,USING会去除USING指定的列,而ON不会。
--USING select * from table1 inner join table2 using(column_name)
自然连接
自然连接就是USING子句的简化版,它找出两个表中相同的列作为连接条件进行连接。有左自然连接,右自然连接和普通自然连接之分。例如,两个表相同的列是id,所以会拿id作为连接条件。
--自然连接 select * from table1 natural left join table2 select * from table1 natural right join table2 select * from table1 natural join table2
2.Join连接过程
连接操作的本质就是把各个连接表中的记录都取出来依次匹配的组合加入结果集并返回给用户。如果没有任何限制条件的话,多表联接起来产生的笛卡尔积可能是非常巨大的。所以在联接的时候过滤掉特定记录组合是有必要的。
连接查询的过滤条件可能会涉及单表和多表,以下面的连接语句为例,连接查询的大致过程如下。
select * from t1, t2 where t1.m1 > 1 and t1.m1 = t2.m2 and t2.n2 < 'd'
在这个查询中我们指明了这三个过滤条件:
-
t1.m1 > 1
-
t1.m1 = t2.m2
-
t2.n2 < ‘d’
那么这个联接查询的大致执行过程如下:
首先确定第一个需要查询的表,这个表称之为驱动表。此处假设使用t1作为驱动表,那么就需要到t1表中找满足t1.m1 > 1的记录,所以查询过程就如下图所示:
针对上一步骤中从驱动表产生的结果集中的每一条记录,分别需要到t2表中查找匹配的记录,所谓匹配的记录,指的是符合过滤条件的记录。因为是根据t1表中的记录去找t2表中的记录,所以t2表也可以被称之为被驱动表。比如上一步骤从驱动表中得到了2条记录,所以需要查询2次t2表。此时涉及两个表的列的过滤条件t1.m1 = t2.m2就派上用场了:
-
当t1.m1 = 2时,过滤条件t1.m1 = t2.m2就相当于t2.m2 = 2,所以此时t2表相当于有了t1.m1 = 2、t2.n2 < ‘d’这两个过滤条件,然后到t2表中执行单表查询。
-
当t1.m1 = 3时,过滤条件t1.m1 = t2.m2就相当于t2.m2 = 3,所以此时t2表相当于有了t1.m1 = 3、t2.n2 < ‘d’这两个过滤条件,然后到t2表中执行单表查询。
所以整个联接查询的执行过程就如下图所示:
也就是说整个联接查询最后的结果只有两条符合过滤条件的记录:
+------+------+------+------+ | m1 | n1 | m2 | n2 | +------+------+------+------+ | 2 | b | 2 | b | | 3 | c | 3 | c | +------+------+------+------+
从上边两个步骤可以看出来,我们上边说的这个两表联接查询共需要查询1次t1表,2次t2表。当然这是在特定的过滤条件下的结果,如果我们把t1.m1 > 1这个条件去掉,那么从t1表中查出的记录就有3条,就需要查询3次t3表了。也就是说在两表联接查询中,驱动表只需要访问一次,被驱动表可能被访问多次,这种方式在MySQL中有一个专有名词,叫Nested-Loops Join(嵌套循环联接)。我们在真正使用MySQL的时候表动不动就是几百上千万数据,如果都按照Nested-Loops Join算法,一次Join查询的代价也太大了。所以下面就来看看MySQL支持的Join算法都有哪些?
3.Join算法
联接算法是MySQL数据库用于处理联接的物理策略。MySQL数据库根据不同的使用场合,支持两种Nested-Loops Join算法,一种是Simple Nested-Loops Join(NLJ)算法,另一种是Block Nested-Loops Join(BNL)算法。
计算两张表Join的成本,有下面几种概念:
外表的扫描次数,记为O。通常外表的扫描次数都是1,即Join时扫描一次外表(驱动表)的数据即可
内表的扫描次数,记为I。根据不同Join算法,内表(被驱动表)的扫描次数不同
读取表的记录数,记为R。根据不同Join算法,读取记录的数量可能不同
Join的比较次数,记为M。根据不同Join算法,比较次数不同
回表的读取记录的数,记为F。若Join的是辅助索引,可能需要回表取得最终的数据
评判一个Join算法是否优劣,就是查看上述这些操作的开销是否比较小。
1.Simple Nested-Loops Join(SNLJ,简单嵌套循环联接)
Simple Nested-Loops Join算法相当简单、直接。即外表(驱动表)中的每一条记录与内表(被驱动表)中的记录进行比较判断。对于两表联接来说,驱动表只会被访问一遍,但被驱动表却要被访问到好多遍,具体访问几遍取决于对驱动表执行单表查询后的结果集中的记录条数。对于内联接来说,选取哪个表为驱动表都没关系,而外联接的驱动表是固定的,也就是说左(外)联接的驱动表就是左边的那个表,右(外)联接的驱动表就是右边的那个表(这个只是一般情况,也有左联接驱动表选择右边的表)。
用伪代码表示一下这个过程就是这样:
For each row r in R do -- 扫描R表(驱动表) For each row s in S do -- 扫描S表(被驱动表) If r and s satisfy the join condition -- 如果r和s满足join条件 Then output the tuple <r, s> -- 返回结果集
下图能更好地显示整个SNLJ的过程:
其中R表为外部表(Outer Table),S表为内部表(Inner Table)。这是一个最简单的算法,这个算法的开销其实非常大。假设在两张表R和S上进行联接的列都不含有索引,外表的记录数为RN,内表的记录数位SN。根据上一节对于Join算法的评判标准来看,SNLJ的开销如下表所示:
| 开销统计 | SNLJ |
|---|---|
| 外表扫描次数(O) | 1 |
| 内表扫描次数(I) | RN |
| 读取记录数(R) | RN + SN*RN |
| Join比较次数(M) | SN*RN |
| 回表读取记录次数(F) | 0 |
可以看到读取记录数的成本和比较次数的成本都是SN*RN,也就是笛卡儿积。假设外表内表都是1万条记录,那么其读取的记录数量和Join的比较次数都需要上亿。实际上数据库并不会使用到SNLJ算法。
2.Index Nested-Loops Join(INLJ,基于索引的嵌套循环联接)
SNLJ算法虽然简单明了,但是也是相当的粗暴,需要多次访问内表(每一次都是全表扫描)。因此,在Join的优化时候,通常都会建议在内表建立索引,以此降低Nested-Loop Join算法的开销,减少内表扫描次数,MySQL数据库中使用较多的就是这种算法,以下称为INLJ。来看这种算法的伪代码:
For each row r in R do -- 扫描R表 lookup s in S index -- 查询S表的索引(固定3~4次IO,B+树高度) If find s == r -- 如果r匹配了索引s Then output the tuple <r, s> -- 返回结果集
由于内表上有索引,所以比较的时候不再需要一条条记录进行比较,而可以通过索引来减少比较,从而加速查询。整个过程如下图所示:
可以看到外表中的每条记录通过内表的索引进行访问,就是读取外部表一行数据,然后去内部表索引进行二分查找匹配;而一般B+树的高度为3~4层,也就是说匹配一次的io消耗也就3~4次,因此索引查询的成本是比较固定的,故优化器都倾向于使用记录数少的表作为外表(这里是否又会存在潜在的问题呢?)。故INLJ的算法成本如下表所示:
| 开销统计 | SNLJ | INLJ |
|---|---|---|
| 外表扫描次数(O) | 1 | 1 |
| 内表扫描次数(I) | R | 0 |
| 读取记录数(R) | RN + SN*RN | RN + Smatch |
| Join比较次数(M) | SN*RN | RN * IndexHeight |
| 回表读取记录次数(F) | 0 | Smatch (if possible) |
上表Smatch表示通过索引找到匹配的记录数量。同时可以发现,通过索引可以大幅降低内表的Join的比较次数,每次比较1条外表的记录,其实就是一次indexlookup(索引查找),而每次index lookup的成本就是树的高度,即IndexHeight。
INLJ的算法并不复杂,也算简单易懂。但是效率是否能达到用户的预期呢?其实如果是通过表的主键索引进行Join,即使是大数据量的情况下,INLJ的效率亦是相当不错的。因为索引查找的开销非常小,并且访问模式也是顺序的(假设大多数聚集索引的访问都是比较顺序的)。
大部分人诟病MySQL的INLJ慢,主要是因为在进行Join的时候可能用到的索引并不是主键的聚集索引,而是辅助索引,这时INLJ的过程又需要多一步Fetch的过程,而且这个过程开销会相当的大:
由于访问的是辅助索引,如果查询需要访问聚集索引上的列,那么必要需要进行回表取数据,看似每条记录只是多了一次回表操作,但这才是INLJ算法最大的弊端。首先,辅助索引的index lookup是比较随机I/O访问操作。其次,根据index lookup再进行回表又是一个随机的I/O操作。所以说,INLJ最大的弊端是其可能需要大量的离散操作,这在SSD出现之前是最大的瓶颈。而即使SSD的出现大幅提升了随机的访问性能,但是对比顺序I/O,其还是慢了很多,依然不在一个数量级上。
另外,在INNER JOIN中,两张联接表的顺序是可以变换的,即R INNER JOIN S ON Condition P等效于S INNER JOIN R ON Condition P。根据前面描述的Simple Nested-Loops Join算法,优化器在一般情况下总是选择将联接列含有索引的表作为内部表。如果两张表R和S在联接列上都有索引,并且索引的高度相同,那么优化器会选择记录数少的表作为外部表,这是因为内部表的扫描次数总是索引的高度,与记录的数量无关。所以,联接列只要有一个字段有索引即可,但最好是数据集多的表有索引;但是,但有WHERE条件的时候又另当别论了。
3.Block Nested-Loops Join(BNL,基于块的嵌套循环联接)
扫描一个表的过程其实是先把这个表从磁盘上加载到内存中,然后从内存中比较匹配条件是否满足。但内存里可能并不能完全存放的下表中所有的记录,所以在扫描表前边记录的时候后边的记录可能还在磁盘上,等扫描到后边记录的时候可能内存不足,所以需要把前边的记录从内存中释放掉。我们前边又说过,采用Simple Nested-Loop Join算法的两表联接过程中,被驱动表可是要被访问好多次的,如果这个被驱动表中的数据特别多而且不能使用索引进行访问,那就相当于要从磁盘上读好几次这个表,这个I/O代价就非常大了,所以我们得想办法:尽量减少访问被驱动表的次数。
当被驱动表中的数据非常多时,每次访问被驱动表,被驱动表的记录会被加载到内存中,在内存中的每一条记录只会和驱动表结果集的一条记录做匹配,之后就会被从内存中清除掉。然后再从驱动表结果集中拿出另一条记录,再一次把被驱动表的记录加载到内存中一遍,周而复始,驱动表结果集中有多少条记录,就得把被驱动表从磁盘上加载到内存中多少次。所以我们可不可以在把被驱动表的记录加载到内存的时候,一次性和多条驱动表中的记录做匹配,这样就可以大大减少重复从磁盘上加载被驱动表的代价了。这也就是Block Nested-Loop Join算法的思想。
也就是说在有索引的情况下,MySQL会尝试去使用Index Nested-Loop Join算法,在有些情况下,可能Join的列就是没有索引,那么这时MySQL的选择绝对不会是最先介绍的Simple Nested-Loop Join算法,因为那个算法太粗暴,不忍直视。数据量大些的复杂SQL估计几年都可能跑不出结果。而Block Nested-Loop Join算法较Simple Nested-Loop Join的改进就在于可以减少内表的扫描次数,甚至可以和Hash Join算法一样,仅需扫描内表一次。其使用Join Buffer(联接缓冲)来减少内部循环读取表的次数。
For each tuple r in R do -- 扫描外表R store used columns as p from R in Join Buffer -- 将部分或者全部R的记录保存到Join Buffer中,记为p For each tuple s in S do -- 扫描内表S If p and s satisfy the join condition -- p与s满足join条件 Then output the tuple -- 返回为结果集
可以看到相比Simple Nested-Loop Join算法,Block Nested-LoopJoin算法仅多了一个所谓的Join Buffer,为什么这样就能减少内表的扫描次数呢?下图相比更好地解释了Block Nested-Loop Join算法的运行过程:
可以看到Join Buffer用以缓存联接需要的列(所以再次提醒我们,最好不要把*作为查询列表,只需要把我们关心的列放到查询列表就好了,这样还可以在join buffer中放置更多的记录呢),然后以Join Buffer批量的形式和内表中的数据进行联接比较。就上图来看,记录r1,r2 … rT的联接仅需扫内表一次,如果join buffer可以缓存所有的外表列,那么联接仅需扫描内外表各一次,从而大幅提升Join的性能。
MySQL数据库使用Join Buffer的原则如下:
-
系统变量Join_buffer_size决定了Join Buffer的大小。
-
Join Buffer可被用于联接是ALL、index、和range的类型。
-
每次联接使用一个Join Buffer,因此多表的联接可以使用多个Join Buffer。
-
Join Buffer在联接发生之前进行分配,在SQL语句执行完后进行释放。
-
Join Buffer只存储要进行查询操作的相关列数据,而不是整行的记录。
Join_buffer_size变量
所以,Join Buffer并不是那么好用的。首先变量join_buffer_size用来控制Join Buffer的大小,调大后可以避免多次的内表扫描,从而提高性能。也就是说,当MySQL的Join有使用到Block Nested-Loop Join,那么调大变量join_buffer_size才是有意义的。而前面的Index Nested-Loop Join如果仅使用索引进行Join,那么调大这个变量则毫无意义。
变量join_buffer_size的默认值是256K,显然对于稍复杂的SQL是不够用的。好在这个是会话级别的变量,可以在执行前进行扩展。建议在会话级别进行设置,而不是全局设置,因为很难给一个通用值去衡量。另外,这个内存是会话级别分配的,如果设置不好容易导致因无法分配内存而导致的宕机问题。
Join Buffer缓存对象
另外,Join Buffer缓存的对象是什么,这个问题相当关键和重要。然在MySQL的官方手册中是这样记录的:Only columns of interest to the join are stored in the join buffer, not whole rows.
可以发现Join Buffer不是缓存外表的整行记录,而是缓存“columns of interest”,具体指所有参与查询的列都会保存到Join Buffer,而不是只有Join的列。比如下面的SQL语句,假设没有索引,需要使用到Join Buffer进行链接:
SELECT a.col3 FROM a, b WHERE a.col1 = b.col2 AND a.col2 > …. AND b.col2 = …
假设上述SQL语句的外表是a,内表是b,那么存放在Join Buffer中的列是所有参与查询的列,在这里就是(a.col1,a.col2,a.col3)。
通过上面的介绍,我们现在可以得到内表的扫描次数为:
Scaninner_table = (RN * used_column_size) / join_buffer_size + 1
对于有经验的DBA就可以预估需要分配的Join Buffer大小,然后尽量使得内表的扫描次数尽可能的少,最优的情况是只扫描内表一次。
Join Buffer的分配
需要牢记的是,Join Buffer是在Join之前就进行分配,并且每次Join就需要分配一次Join Buffer,所以假设有N张表参与Join,每张表之间通过Block Nested-Loop Join,那么总共需要分配N-1个Join Buffer,这个内存容量是需要DBA进行考量的。
在MySQL 5.6(包括MariaDB 5.3)中,优化了Join Buffer在多张表之间联接的内存使用效率。MySQL 5.6将Join Buffer分为Regular join buffer和Incremental join buffer。假设B1是表t1和t2联接使用的Join Buffer,B2是t1和t2联接产生的结果和表t3进行联接使用的join buffer,那么:
-
如果B2是Regular join buffer,那么B2就会包含B1的Join Buffer中r1相关的列,以及表t2中相关的列。
-
如果B2是Incremental join buffer,那么B2包含表t2中的数据及一个指针,该指针指向B1中r1相对应的数据。
因此,对于第一次联接的表,使用的都是Regular join buffer,之后再联接,则使用Incremental join buffer。又因为Incremental join buffer只包含指向之前Join Buffer中数据的指针,所以Join Buffer的内存使用效率得到了大幅的提高。
此外,对于NULL类型的列,其实不需要存放在Join Buffer中,而对于VARCHAR类型的列,也是仅需最小的内存即可,而不是以CHAR类型在Join Buffer中保存。最后,在MySQL 5.5版本中,Join Buffer只能在INNER JOIN中使用,在OUTER JOIN中则不能使用,即Block Nested Loop算法不支持OUTER JOIN。从MySQL 5.6及MariaDB 5.3开始,Join Buffer的使用得到了进一步扩展,在OUTER JOIN中使join buffer得到支持。
Block Nested-Loop Join开销
Block Nested-Loop Join极大的避免了内表的扫描次数,如果Join Buffer可以缓存外表的数据,那么内表的扫描仅需一次,这和Hash Join非常类似。但是Block Nested-Loop Join依然没有解决的是Join比较的次数,其仍然通过Join判断式进行比较。综上所述,到目前为止各Join算法的成本比较如下所示:
| 开销统计 | SNLJ | INLJ | BNL |
|---|---|---|---|
| 外表扫描次数(O) | 1 | 1 | 1 |
| 内表扫描次数(I) | R | 0 | RN*used_column_size/join_buffer_size + 1 |
| 读取记录数(R) | RN + SN*RN | RN + Smatch | RN + S*I |
| Join比较次数(M) | SN*RN | RN * IndexHeight | SN*RN |
| 回表读取记录次数(F) | 0 | Smatch (if possible) | 0 |
Block Nested-Loop Join影响
在使用 Block Nested-Loop Join(BNL) 算法时,可能会对被驱动表做多次扫描。如果这个被驱动表是一个大的冷数据表,除了会导致 IO 压力大以外,还会对 buffer poll 产生严重的影响。
如果了解 InnoDB 的 LRU 算法就会知道,由于 InnoDB 对 Bufffer Pool 的 LRU 算法做了优化,即:第一次从磁盘读入内存的数据页,会先放在 old 区域。如果 1 秒之后这个数据页不再被访问了,就不会被移动到 LRU 链表头部,这样对 Buffer Pool 的命中率影响就不大。
但是,如果一个使用 BNL 算法的 join 语句,多次扫描一个冷表,而且这个语句执行时间超过 1 秒,就会在再次扫描冷表的时候,把冷表的数据页移到 LRU 链表头部。这种情况对应的,是冷表的数据量小于整个 Buffer Pool 的 3/8,能够完全放入 old 区域的情况。如果这个冷表很大,就会出现另外一种情况:业务正常访问的数据页,没有机会进入 young 区域。
由于优化机制的存在,一个正常访问的数据页,要进入 young 区域,需要隔 1 秒后再次被访问到。但是,由于我们的 join 语句在循环读磁盘和淘汰内存页,进入 old 区域的数据页,很可能在 1 秒之内就被淘汰了。这样,就会导致这个 MySQL 实例的 Buffer Pool 在这段时间内,young 区域的数据页没有被合理地淘汰。
也就是说,这两种情况都会影响 Buffer Pool 的正常运作。 大表 join 操作虽然对 IO 有影响,但是在语句执行结束后,对 IO 的影响也就结束了。但是,对 Buffer Pool 的影响就是持续性的,需要依靠后续的查询请求慢慢恢复内存命中率。
为了减少这种影响,你可以考虑增大 join_buffer_size 的值,减少对被驱动表的扫描次数。
也就是说,BNL 算法对系统的影响主要包括三个方面: 可能会多次扫描被驱动表,占用磁盘 IO 资源; 判断 join 条件需要执行 M*N 次对比(M、N 分别是两张表的行数),如果是大表就会占用非常多的 CPU 资源; 可能会导致 Buffer Pool 的热数据被淘汰,影响内存命中率。
4.性能优化
1.内循环次数
内循环的次数受驱动表的记录数所影响,驱动表记录数越多,内循环就越多,连接效率就越低下,所以尽量用小表驱动大表。
MySQL自带的Optimizer会优化内连接,优化策略就是小表驱动大表。所以,以后写内连接不要纠结谁内连接谁了,直接让MySQL去判断吧。
2.快速匹配
基于前面讲到的基于索引的嵌套循环联接,从快速匹配的角度优化JOIN,首先就是找出谁是驱动表,谁是被驱动表,然后在被驱动表上建立索引即可。
3.排序
对连接属性进行排序
假设有两张表,大表t1,小表t2,现要求对t1和t2做内连接,连接条件是t1.id=t2.id,并对连接属性id进行排序(MySQL为主键id建立了索引)。
有两种选择,方式一[...ORDER BY t1.id],方式二[...ORDER BY t2.id],选哪种呢?
首先我们找出驱动表和被驱动表,按照小表驱动大表的原则,大表是t1,小表是t2,所以t2是驱动表,t1是非驱动表,t2驱动t1。然后进行分析,如果我们使用方式一的话,执行表连接算法后,对结果集进行排序,效率低下;如果我们使用方式二的话,先对t2进行排序,然后执行表连接算法,效率高。
当对连接属性进行排序时,应当选择驱动表的属性作为排序表中的条件。
对非连接属性进行排序
现要求对t1和t2做内连接,连接条件是t1.id=t2.id,并对非连接属性t1的type属性进行排序,[...ORDER BY t1.type]。
首先我们找出驱动表和被驱动表,按照小表驱动大表的原则,大表是t1,小表是t2,所以MySQL Optimizer会用t2驱动t1。现在我们要对t1的type属性进行排序,t1是被驱动表,必然导致对连接后结果集进行排序Using temporary(比Using filesort更严重)。所以,能不能不用MySQL Optimizer,用大表驱动小表呢?
答案是STRAIGHT_JOIN。但需要注意的是虽然Using temporary没有了,但是大表驱动小表,导致内循环次数增加,实际开发中要从实际出发,对此作出权衡。
STRAIGHT_JOIN只适用于内连接,因为left join、right join已经知道了哪个表作为驱动表,哪个表作为被驱动表,比如left join就是以左表为驱动表,right join反之,而STRAIGHT_JOIN就是在内连接中使用,而强制使用左表来当驱动表,所以这个特性可以用于一些调优,强制改变mysql的优化器选择的执行计划
【参考文章】
智能推荐
Linux升级nginx版本_linux 升级nginx-程序员宅基地
文章浏览阅读2.2k次,点赞11次,收藏16次。处于漏洞修复目的服务器所用nginx是1.16.0版本扫出来存在安全隐患,需要我们升级到1.17.7以上。一般nginx默认在目录,这里我的nginx是自定义的路径安装在。_linux 升级nginx
波形发生器设计c语言文件,波形发生器设计方案.doc-程序员宅基地
文章浏览阅读938次。五邑大学单片机课程设计报告题 目:波形发生器设计院 系 信息学院专 业 电子信息工程学 号 3112001979学生姓名 陈梓聪指导教师 黄辉波形发生器设计摘要本文以STC89C51片机为核心设计了一个低频函数信号发生器。信号发生器采用数字波形合成技术,通过硬件电路和软件程相结合,可输出自定义波形,如正弦波、方波、三角波、梯形波及其他任意波形,波形的频率和幅度在一定范..._数字式波形发生器课程设计+csdn
5款十分小众的软件,知道的人不多但却很好用_小众软件 启动软件-程序员宅基地
文章浏览阅读2.2k次,点赞3次,收藏26次。今天推荐5款十分小众的软件,知道的人不多,但是每个都是非常非常好用的,有兴趣的小伙伴可以自行搜索下载。_小众软件 启动软件
mysql 事务提交后数据没有更新_mysql 事务隔离级别之可能出现的问题:同一事务中无法查询已插入但未提交的数据...-程序员宅基地
文章浏览阅读1.8k次。若要实现查询事务中已插入但是未提交的数据则需要设置MySQL事务隔离级别为 read-uncommitted下面了解一下MySQL的事务隔离级别:一、事务的基本要素(ACID)1、原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学..._事务read committed 查询不到更新的数据
5分钟学会canvas的使用_e.offsetx/a[w].m_icanvaswidth-程序员宅基地
文章浏览阅读1.6w次。在HTML5新增新的标签,名为画布,可以使用JS在上面完成对应的画的操作。正常情况我们可以把它当成一个img看待。_e.offsetx/a[w].m_icanvaswidth
(19) 交通预测---基于时空注意力机制的图卷积神经网络-程序员宅基地
文章浏览阅读1.6w次,点赞11次,收藏160次。交通预见未来(19): 交通预测---基于时空注意力机制的图卷积神经网络1、文章信息《Attention Based Spatial-Temporal Graph Convolutional Networks for Traffc Flow Forecasting》。北京交通大学博士生校友2019年初发在AAAI顶会上的一篇文章。2、摘要针对交通流预测问题,提出了一种基于注意力..._时空注意力
随便推点
C语言中for循环的使用详解及注意点_c语言for循环语句用法-程序员宅基地
文章浏览阅读5.5k次,点赞3次,收藏25次。C语言中for循环的使用详解及注意点_c语言for循环语句用法
Mule与其它web应用服务器的区别_mule服务器-程序员宅基地
文章浏览阅读2.9k次。跟JBoss、Tomcat或其它web应用服务器相比,Mule有何不同?虽然他们有一些重要的相同点,不同点可以归结为你想达到的目标是什么。某些种类的应用对于Mule来说比较容易去编写、部署和管理,其它种类的应用可能对于web应用服务器来说比较容易编写、部署和管理。首先来看看相同点:它们都允许你同时运行多个应用。它们都提供应用容器。换句话说,两者都提供一个应用可以运行的环境,扮演一个_mule服务器
emq java_MQTT研究之EMQ:【eclipse的paho之java客户端使用注意事项】-程序员宅基地
文章浏览阅读296次。这里,简单记录一下自己在最近项目中遇到的paho的心得,这里也涵盖EMQX的问题。1. cleanSession这个标识,是确保client和server之间是否持久化状态的一个标志,不管是client还是server重启还是连接断掉。下面是来自paho客户端源码的注释。Sets whether the client and server should remember state across ..._due to message queue too long
kettle—http请求_kettle http-程序员宅基地
文章浏览阅读1.2w次。定义的数据常量就是我们做http 请求的时候需要的一些参数,例如这里就是我们请求的地址和请求的关键词,正常情况下这些参数应该是从我们的数据中来,也就是表中例如表输入组件,但是这里为了方便我们直接使用常量定义组件。接下来我们还有定义一下请求的参数字段,其实看到这里我们是完全可以将请求的参数字段和url 定义在一起,或者是通过转换组合在一起的,但是这里为了演示的完整性,我们还是去定义一下请求的参数。字段,命名参数就是我们发起请求的时候的参数名称,也就是说我们把。下面是我们一个常见的发起GET 请求的模式。_kettle http
C++11编译出现/usr/lib/libstdc++.so.6: version `GLIBCXX_3.4.14' not found (required by ./a.out)_./mysqld: /lib64/libstdc++.so.6: version `cxxabi_1-程序员宅基地
文章浏览阅读2.4k次。从源码编译安装升级了gcc以后,程序编译运行时偶尔会遇到这样的问题:_./mysqld: /lib64/libstdc++.so.6: version `cxxabi_1.3.11' not found (required
iOS常用小功能_ios 获取控件节点-程序员宅基地
文章浏览阅读223次。1、获取控件相对位置 UIWindow * window=[[[UIApplication sharedApplication] delegate] window]; CGRect rect=[_topView convertRect:_topView.bounds toView:window]; CGFloat viewY = rect.origin.y;2、页面返回指定控..._ios 获取控件节点