论文阅读——CMT_cmt 视觉架构-程序员宅基地
技术标签: 论文阅读
论文阅读——CMT
目标:优化transformer模型,使其复杂度低于transformer且性能优于高性能卷积模型。
创新点
1、提出了一种新颖的 CMT(CNNs meet transformers)架构用于视觉识别
2、 提出了局部感知单元(LPU)和反向残差前馈网络(IRFFN)
Introduction
Transformer在视觉任务中性能出色,但是性能低于同等大小下的CNN。原因有三:1)在ViT 和其他基于Transformer的模型中,将图像分成patch,它忽略了基于序列的NLP任务和基于图像的视觉任务之间的根本区别,即在每个patch分块中的2维结构和空间局部信息。 2)由于patch大小的固定,Transformer难以明确提取低分辨率和多尺度的特征,这给检测和分割等密集的预测任务带来了很大的挑战。 3)与基于CNN的O(NC^2) 相比Transformer中自注意力模块的计算和存储成本是输入分辨率的平方倍(O(NC^2),使用Transformer来处理这些图像将不可避免地会导致GPU内存不足和计算效率低的问题。
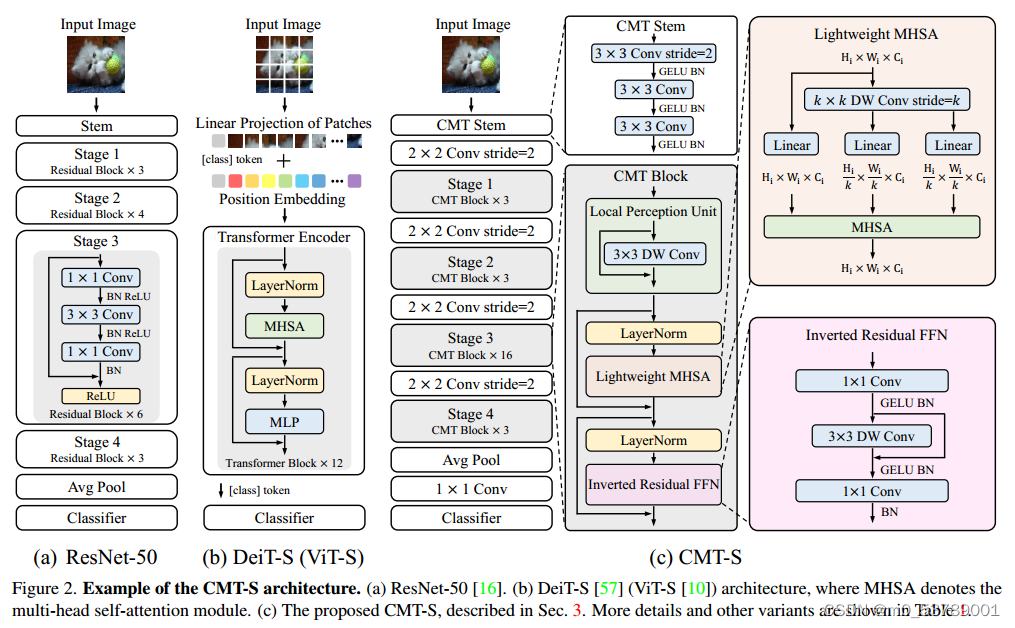
输入图像首先经过stem进行细粒度特征提取,然后将其送入CMT块堆栈进行表示学习。具体而言,引入的CMT块是变压器块的改进变体,其局部信息通过深度卷积增强。相比于ViT,CMT第一阶段生成的特征可以保持更高的分辨率,即H/4×W/4/ViT中的H/16×W/16,此外,采用了类似于cnn的分阶段架构设计,采用步长为2的4个卷积层,逐步降低分辨率(序列长度),灵活增加维数。分阶段设计有助于提取多尺度特征,减轻高分辨率带来的计算负担。CMT块中的局部感知单元(LPU)和反向残差前馈网络(IRFFN)可以同时捕获中间特征中的局部和全局结构信息,提高网络的表示能力。最后,利用平均池化代替ViT中的cls token,获得更好的分类效果。
给定一个输入图像,可以得到四个不同分辨率的层次特征图,类似于典型的cnn。利用上述特征图的输入步幅分别为4、8、16和32,我们的CMT可以获得输入图像的多尺度表示,并可以很容易地应用于目标检测和语义分割等下游任务。
相关工作
CNN
| 网络 | 特点 |
|---|---|
| LeNet | - |
| AlexNet & VGGNet & GoogleNet & InceptionNet | - |
| ResNet | 增强泛化能力 |
| SENet | 自适应地重新校准通道特征响应 |
Vision Transformer
| 网络 | 特点 |
|---|---|
| ViT | 将NLP中的Transformer引入到CV领域 |
| DeiT | 蒸馏的方式,使用teacher model来指导Vision Transformer的训练 |
| T2T-ViT | 递归的将相邻的tokens聚合成为一个,transformer对visual tokens进行建模 |
| TNT | outer block建模patch embedding 之间的关系,inner block建模pixel embedding之间的关系 |
| PVT | 将金字塔结构引入到 ViT 中,可以为各种像素级密集预测任务生成多尺度特征图。 |
| CPVT和CvT | cnn引入到transformer之中 |
CMT
整体结构
CMT stem(减小图片大小,提取本地信息)
Conv Stride(用来减少feature map,增大channel)
CMT block(捕获全局和局部关系)
CMT模型的核心是CMT Block,其主要由以下几个模块构成:
1)Local Perception Unit(局部感知单元)
- 位置编码会破坏卷积中的平移不变性,忽略了patch之间的局部信息和patch内部的结构信息。
- LPU来缓解这个问题。
2)Lightweight Multi-head Self-attention(轻量级的多头注意力机制)
- 使用深度卷积来减少KV的大小,加入相对位置偏置,构成了轻量级的自注意力计算。
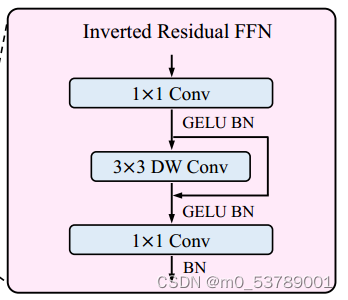
3)Inverted Residual Feed-forward Network(反向残差前馈网络)
- 深度卷积增强局部信息的提取,残差结构来促进梯度的传播能力。
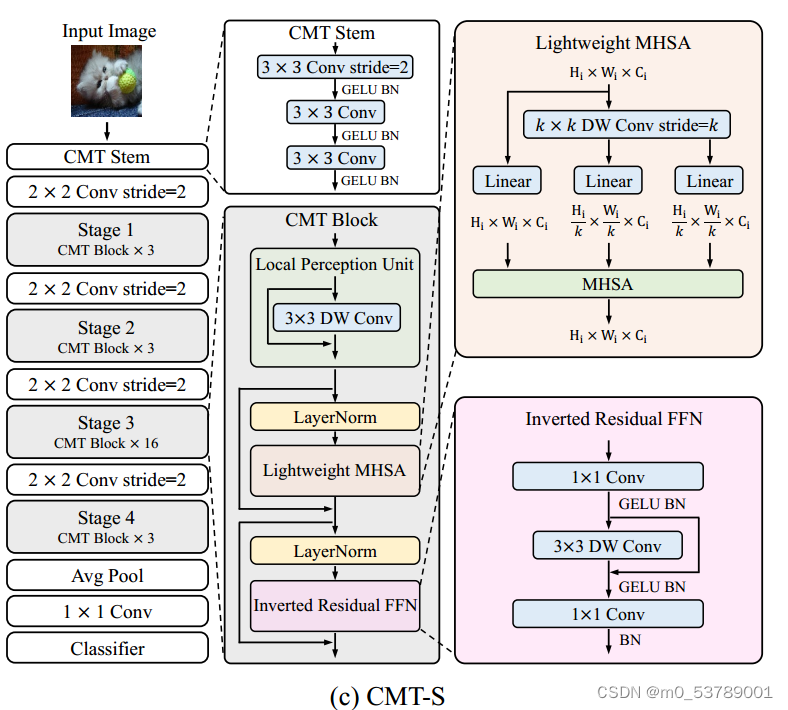
1)Local Perception Unit(局部感知单元)
本质就是,将输入图片信息,与 3*3 的卷积操作后相加,旨在增加了空间信息,可以和 ViT 的绝对位置编码的对应理解。
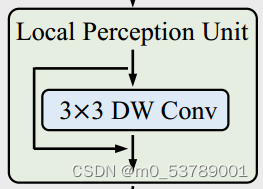

2)Lightweight Multi-head Self-attention (轻量级的多头注意力机制)
在原始的self-attention模块中,输入 X 被线性变换为 query、key、value 再进行计算,运算成本高。
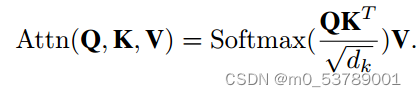
此模块主要功能就是使用深度卷积计算代替了 key 和 value 的计算,从而减轻了计算开销。
在这里插入图片描述
3)Inverted Residual Feed-forward Network (反向残差前馈网络)
向残差前馈网络(IRFFN)类似于反向残差块,由扩展层、深度卷积和投影层组成。具体来说,我们改变了快捷方式连接的位置,以获得更好的性能。 其中,省略了激活层。深度卷积用于提取局部信息,而额外的计算成本可以忽略不计。插入快捷方式的动机与经典的残差网络相似,可以提高梯度跨层的传播能力。

代码
LPU
class LocalPerceptionUint(nn.Module):
def __init__(self, dim, act=False):
super(LocalPerceptionUint, self).__init__()
self.act = act
# 增强本地信息的提取
self.conv_3x3_dw = ConvDW3x3(dim)
if self.act:
self.actation = nn.Sequential(
nn.GELU(),
nn.BatchNorm2d(dim)
)
def forward(self, x):
if self.act:
out = self.actation(self.conv_3x3_dw(x))
return out
else:
out = self.conv_3x3_dw(x)
return out
IRFFN
class InvertedResidualFeedForward(nn.Module):
def __init__(self, dim, dim_ratio=4.):
super(InvertedResidualFeedForward, self).__init__()
output_dim = int(dim_ratio * dim)
self.conv1x1_gelu_bn = ConvGeluBN(
in_channel=dim,
out_channel=output_dim,
kernel_size=1,
stride_size=1,
padding=0
)
self.conv3x3_dw = ConvDW3x3(dim=output_dim)
self.act = nn.Sequential(
nn.GELU(),
nn.BatchNorm2d(output_dim)
)
self.conv1x1_pw = nn.Sequential(
nn.Conv2d(output_dim, dim, 1, 1, 0),
nn.BatchNorm2d(dim)
)
def forward(self, x):
x = self.conv1x1_gelu_bn(x)
out = x + self.act(self.conv3x3_dw(x))
out = self.conv1x1_pw(out)
return out
LMHSA
class LightMutilHeadSelfAttention(nn.Module):
"""calculate the self attention with down sample the resolution for k, v, add the relative position bias before softmax
Args:
dim (int) : features map channels or dims
num_heads (int) : attention heads numbers
relative_pos_embeeding (bool) : relative position embeeding
no_distance_pos_embeeding (bool): no_distance_pos_embeeding
features_size (int) : features shape
qkv_bias (bool) : if use the embeeding bias
qk_scale (float) : qk scale if None use the default
attn_drop (float) : attention dropout rate
proj_drop (float) : project linear dropout rate
sr_ratio (float) : k, v resolution downsample ratio
Returns:
x : LMSA attention result, the shape is (B, H, W, C) that is the same as inputs.
"""
def __init__(self, dim, num_heads=8, features_size=56,
relative_pos_embeeding=False, no_distance_pos_embeeding=False, qkv_bias=False, qk_scale=None,
attn_drop=0., proj_drop=0., sr_ratio=1.):
super(LightMutilHeadSelfAttention, self).__init__()
assert dim % num_heads == 0, f"dim {
dim} should be divided by num_heads {
num_heads}"
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads # used for each attention heads
self.scale = qk_scale or head_dim ** -0.5
self.relative_pos_embeeding = relative_pos_embeeding
self.no_distance_pos_embeeding = no_distance_pos_embeeding
self.features_size = features_size
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim*2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.softmax = nn.Softmax(dim=-1)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
if self.relative_pos_embeeding:
self.relative_indices = generate_relative_distance(self.features_size)
self.position_embeeding = nn.Parameter(torch.randn(2 * self.features_size - 1, 2 * self.features_size - 1))
elif self.no_distance_pos_embeeding:
self.position_embeeding = nn.Parameter(torch.randn(self.features_size ** 2, self.features_size ** 2))
else:
self.position_embeeding = None
if self.position_embeeding is not None:
trunc_normal_(self.position_embeeding, std=0.2)
def forward(self, x):
B, C, H, W = x.shape
N = H*W
x_q = rearrange(x, 'B C H W -> B (H W) C') # translate the B,C,H,W to B (H X W) C
q = self.q(x_q).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # B,N,H,DIM -> B,H,N,DIM
# conv for down sample the x resoution for the k, v
if self.sr_ratio > 1:
x_reduce_resolution = self.sr(x)
x_kv = rearrange(x_reduce_resolution, 'B C H W -> B (H W) C ')
x_kv = self.norm(x_kv)
else:
x_kv = rearrange(x, 'B C H W -> B (H W) C ')
kv_emb = rearrange(self.kv(x_kv), 'B N (dim h l ) -> l B h N dim', h=self.num_heads, l=2) # 2 B H N DIM
k, v = kv_emb[0], kv_emb[1]
attn = (q @ k.transpose(-2, -1)) * self.scale # (B H Nq DIM) @ (B H DIM Nk) -> (B H NQ NK)
# TODO: add the relation position bias, because the k_n != q_n, we need to split the position embeeding matrix
q_n, k_n = q.shape[1], k.shape[2]
if self.relative_pos_embeeding:
attn = attn + self.position_embeeding[self.relative_indices[:, :, 0], self.relative_indices[:, :, 1]][:, :k_n]
elif self.no_distance_pos_embeeding:
attn = attn + self.position_embeeding[:, :k_n]
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # (B H NQ NK) @ (B H NK dim) -> (B NQ H*DIM)
x = self.proj(x)
x = self.proj_drop(x)
x = rearrange(x, 'B (H W) C -> B C H W ', H=H, W=W)
return x
总结
本文提出了一种新的混合结构CMT,用于视觉识别和其他下游计算机视觉任务,如目标检测和实例分割,并解决了在计算机视觉领域以野蛮力方式使用变压器的局限性。所提出的CMT结构利用cnn和变压器来捕获局部和全局信息,提高了网络的表示能力。
智能推荐
稀疏编码的数学基础与理论分析-程序员宅基地
文章浏览阅读290次,点赞8次,收藏10次。1.背景介绍稀疏编码是一种用于处理稀疏数据的编码技术,其主要应用于信息传输、存储和处理等领域。稀疏数据是指数据中大部分元素为零或近似于零的数据,例如文本、图像、音频、视频等。稀疏编码的核心思想是将稀疏数据表示为非零元素和它们对应的位置信息,从而减少存储空间和计算复杂度。稀疏编码的研究起源于1990年代,随着大数据时代的到来,稀疏编码技术的应用范围和影响力不断扩大。目前,稀疏编码已经成为计算...
EasyGBS国标流媒体服务器GB28181国标方案安装使用文档-程序员宅基地
文章浏览阅读217次。EasyGBS - GB28181 国标方案安装使用文档下载安装包下载,正式使用需商业授权, 功能一致在线演示在线API架构图EasySIPCMSSIP 中心信令服务, 单节点, 自带一个 Redis Server, 随 EasySIPCMS 自启动, 不需要手动运行EasySIPSMSSIP 流媒体服务, 根..._easygbs-windows-2.6.0-23042316使用文档
【Web】记录巅峰极客2023 BabyURL题目复现——Jackson原生链_原生jackson 反序列化链子-程序员宅基地
文章浏览阅读1.2k次,点赞27次,收藏7次。2023巅峰极客 BabyURL之前AliyunCTF Bypassit I这题考查了这样一条链子:其实就是Jackson的原生反序列化利用今天复现的这题也是大同小异,一起来整一下。_原生jackson 反序列化链子
一文搞懂SpringCloud,详解干货,做好笔记_spring cloud-程序员宅基地
文章浏览阅读734次,点赞9次,收藏7次。微服务架构简单的说就是将单体应用进一步拆分,拆分成更小的服务,每个服务都是一个可以独立运行的项目。这么多小服务,如何管理他们?(服务治理 注册中心[服务注册 发现 剔除])这么多小服务,他们之间如何通讯?这么多小服务,客户端怎么访问他们?(网关)这么多小服务,一旦出现问题了,应该如何自处理?(容错)这么多小服务,一旦出现问题了,应该如何排错?(链路追踪)对于上面的问题,是任何一个微服务设计者都不能绕过去的,因此大部分的微服务产品都针对每一个问题提供了相应的组件来解决它们。_spring cloud
Js实现图片点击切换与轮播-程序员宅基地
文章浏览阅读5.9k次,点赞6次,收藏20次。Js实现图片点击切换与轮播图片点击切换<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title></title> <script type="text/ja..._点击图片进行轮播图切换
tensorflow-gpu版本安装教程(过程详细)_tensorflow gpu版本安装-程序员宅基地
文章浏览阅读10w+次,点赞245次,收藏1.5k次。在开始安装前,如果你的电脑装过tensorflow,请先把他们卸载干净,包括依赖的包(tensorflow-estimator、tensorboard、tensorflow、keras-applications、keras-preprocessing),不然后续安装了tensorflow-gpu可能会出现找不到cuda的问题。cuda、cudnn。..._tensorflow gpu版本安装
随便推点
物联网时代 权限滥用漏洞的攻击及防御-程序员宅基地
文章浏览阅读243次。0x00 简介权限滥用漏洞一般归类于逻辑问题,是指服务端功能开放过多或权限限制不严格,导致攻击者可以通过直接或间接调用的方式达到攻击效果。随着物联网时代的到来,这种漏洞已经屡见不鲜,各种漏洞组合利用也是千奇百怪、五花八门,这里总结漏洞是为了更好地应对和预防,如有不妥之处还请业内人士多多指教。0x01 背景2014年4月,在比特币飞涨的时代某网站曾经..._使用物联网漏洞的使用者
Visual Odometry and Depth Calculation--Epipolar Geometry--Direct Method--PnP_normalized plane coordinates-程序员宅基地
文章浏览阅读786次。A. Epipolar geometry and triangulationThe epipolar geometry mainly adopts the feature point method, such as SIFT, SURF and ORB, etc. to obtain the feature points corresponding to two frames of images. As shown in Figure 1, let the first image be and th_normalized plane coordinates
开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先抽取关系)_语义角色增强的关系抽取-程序员宅基地
文章浏览阅读708次,点赞2次,收藏3次。开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先关系再实体)一.第二代开放信息抽取系统背景 第一代开放信息抽取系统(Open Information Extraction, OIE, learning-based, 自学习, 先抽取实体)通常抽取大量冗余信息,为了消除这些冗余信息,诞生了第二代开放信息抽取系统。二.第二代开放信息抽取系统历史第二代开放信息抽取系统着眼于解决第一代系统的三大问题: 大量非信息性提取(即省略关键信息的提取)、_语义角色增强的关系抽取
10个顶尖响应式HTML5网页_html欢迎页面-程序员宅基地
文章浏览阅读1.1w次,点赞6次,收藏51次。快速完成网页设计,10个顶尖响应式HTML5网页模板助你一臂之力为了寻找一个优质的网页模板,网页设计师和开发者往往可能会花上大半天的时间。不过幸运的是,现在的网页设计师和开发人员已经开始共享HTML5,Bootstrap和CSS3中的免费网页模板资源。鉴于网站模板的灵活性和强大的功能,现在广大设计师和开发者对html5网站的实际需求日益增长。为了造福大众,Mockplus的小伙伴整理了2018年最..._html欢迎页面
计算机二级 考试科目,2018全国计算机等级考试调整,一、二级都增加了考试科目...-程序员宅基地
文章浏览阅读282次。原标题:2018全国计算机等级考试调整,一、二级都增加了考试科目全国计算机等级考试将于9月15-17日举行。在备考的最后冲刺阶段,小编为大家整理了今年新公布的全国计算机等级考试调整方案,希望对备考的小伙伴有所帮助,快随小编往下看吧!从2018年3月开始,全国计算机等级考试实施2018版考试大纲,并按新体系开考各个考试级别。具体调整内容如下:一、考试级别及科目1.一级新增“网络安全素质教育”科目(代..._计算机二级增报科目什么意思
conan简单使用_apt install conan-程序员宅基地
文章浏览阅读240次。conan简单使用。_apt install conan