【掌握Spring事务管理】深入理解事务传播机制的秘密_datasourcetransactionmanager和transcational注解的作用-程序员宅基地

点进来你就是我的人了
博主主页:戳一戳,欢迎大佬指点!欢迎志同道合的朋友一起加油喔

目录
1.2 Spring 声明式事务 ( @Transactional )
4.5.4 嵌套事务(NESTED)和加入事务(REQUIRED)有什么区别?
1.Spring 中事务的实现方式
Spring 中的操作主要分为两类:
- 编程式事务 (了解)
- 声明式事务
编程式事务就是手写代码操作事务, 而声明式事务是利用注解来自动开启和提交事务. 并且编程式事务用几乎不怎么用. 这就好比汽车的手动挡和自动挡, 如果有足够的的钱, 大部分人应该都会选择自动挡.
声明式事务也是如此, 它不仅好用, 还特别方便.
1.1 Spring 编程式事务 (了解)
编程式事务和 MySQL 中操作事务类似, 也是三个重要步骤:
- 开启事务
- 提交事务
- 回滚事务
【代码实现】
//这是一个组合注解,它组合了@Controller和@ResponseBody
//表明这个类是一个控制器,会处理HTTP请求,并且返回的数据会自动转换为JSON或其他格式
@RestController
//这个注解表明这个控制器会处理以"/user"开头的URL
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService; //这是一个业务逻辑服务类,用于处理与用户相关的业务逻辑
//编程式事务
//Spring的事务管理可以确保当在执行数据库操作时,如果出现错误,所有的操作都可以回滚,以保证数据的一致性。
@Autowired
//transactionManager 负责管理数据库事务
private DataSourceTransactionManager transactionManager;
@Autowired
//transactionDefinition 它定义了事务的各种属性,比如隔离级别、传播行为、超时时间、是否为只读事务等。
private TransactionDefinition transactionDefinition;
@RequestMapping("/del")
public int del(Integer id) {
if(id == null || id <= 0) {
return 0;
}
//1.开启事务, 以便后续的事务操作,比如提交或回滚事务。
TransactionStatus transactionStatus = null;
int result = 0;
try {
transactionStatus = transactionManager.getTransaction(transactionDefinition);
// 业务操作, 删除用户
result = userService.del(id);
System.out.println("删除: " + result);
//2.提交事务/回滚事务
// transactionManager.commit(transactionStatus); //提交事务
}catch (Exception e) {
if(transactionStatus != null) {
transactionManager.rollback(transactionStatus);
} //回滚事务
}
return result;
}
}
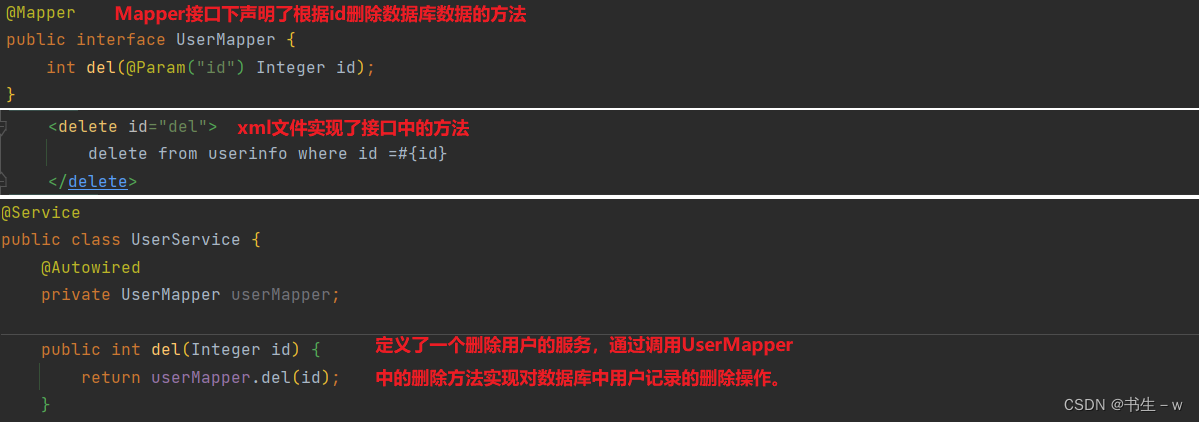
- DataSourceTransactionManager 和 TransactionDefinition 是 SpringBoot 内置的两个对象.
- DataSourceTransactionManager : 用来获取事务(开启事务)、提交或回滚事务.
- TransactionDefinition : 它是事务的属性,在获取事务的时候需要将这个对象传递进去从而获得⼀个事务 TransactionStatus.
测试事务功能:
- 在浏览器输入url : 127.0.0.1:8080/user/del?id=3
- 然后观察控制台日志: (显示我们删除成功了)
 查看数据库结果: (显示要删除的数据还存在数据库)
查看数据库结果: (显示要删除的数据还存在数据库)
 我们可以发现,事务成功的进行了回滚,但是这样的方式太繁琐了,我们来学习更简单的声明式事务
我们可以发现,事务成功的进行了回滚,但是这样的方式太繁琐了,我们来学习更简单的声明式事务
1.2 Spring 声明式事务 ( @Transactional )
声明式事务的实现相较于编程式事务来说, 就要简单太多了, 只需要在需要的方法上添加 @Transactional注解就可以实现了.
@Transactional 注解的作用:
当进入方法的时候, 它就会自动开启事务, 当方法结束后, 它就会自动提交事务. 说白了它就是 AOP 的一个环绕通知. 只要加了 @Transactional 注解的方法, 都有一个事务的 AOP , 这都是 Spring 帮我们封装好的.
@Transactional 注解的执行流程:
- 方法执行之前, 先开启事务, 当方法成功执行完成之后会自动提交事务.
- 如果方法在执行过程中发生了异常, 那么事务会自动回滚.
【代码实现】
//这是一个组合注解,它组合了@Controller和@ResponseBody
//表明这个类是一个控制器,会处理HTTP请求,并且返回的数据会自动转换为JSON或其他格式
@RestController
//这个注解表明这个控制器会处理以"/user"开头的URL
@RequestMapping("/user2")
public class UserController2 {
@Autowired
private UserService userService;
@RequestMapping("/del")
@Transactional //声明式事务
public int del(Integer id) {
if(id == null || id <= 0) {
return 0;
}
return userService.del(id);
}
}
对于方法执行成功的情况就不测试了, 它和普通的插入数据没有多大区别, 重点在于理解 @Transactional注解的含义和作用即可.
【异常情况一】(自动回滚成功)
@RequestMapping("/del")
@Transactional //声明式事务
public int del(Integer id) {
if(id == null || id <= 0) {
return 0;
}
int result = userService.del(id);
System.out.println("删除: " + result);
int num = 10 / 0; //如果途中发生异常会回滚事务
return result;
}当我们写出 int num = 10 / 0; 这样一条语句的时候, 看看 @Transactional 是否会进行回滚操作:
启动程序, 浏览器访问 :127.0.0.1:8080/user2/del?id=3

此时程序已经报错了, 并且控制台打印了删除成功的语句, 是否真正删除成功, 还是说进行了回滚操作, 就要查询数据库

【异常情况二】(自动回滚失效)
对于上述代码抛出异常后, @Transactional 注解帮我们进行回滚, 这一点很好理解, 那么如果我们将这个异常捕获了, @Transactional 注解是否还会进行回滚操作呢 >>
@RequestMapping("/del")
@Transactional(isolation = Isolation.DEFAULT ) //声明式事务
public int del(Integer id) {
if(id == null || id <= 0) {
return 0;
}
int result = userService.del(id);
System.out.println("删除: " + result);
try {
int num = 10 / 0; //如果途中发生异常会回滚事务
} catch (Exception e) {
e.printStackTrace();
}
return result;
}执行结果: 此时程序没有发生报错,异常被我们捕捉打印在控制台了

为了验证是否进行回滚, 继续查询数据库

此时我们发现, 为什么捕捉异常以后, @Transactional 注解并没有进行回滚操作, 而是提交了事务. 这是为什么 ??
因为当我们捕捉到异常的时候, Spring 框架会认为我们有能力处理, 所以就不会进行回滚, 而当发生异常我们不处理的时候, Spring 框架就会采取保守的做法, 他知道我们没有能力去处理这个异常, 所以就会帮我们回滚. 所以当出现异常的时候, 我们要根据这个异常是否被处理来判断最终是提交数据了, 还是进了回滚操作.
1.3 声明式事务的手动回滚 (解决自动回滚失效问题)
当第二种异常情况, 捕获异常之后, 事务并没有进行回滚, 我们是需要做出一些处理的. 既然程序发生了异常, 我们一般就需要进行回滚操作的. 对于这种捕获异常的情况,我们有两种方式进行回滚:
- 将异常继续抛出.
- 通过代码手动回滚事务.
【代码示例】- 将异常继续抛出

测试代码是否回滚,还是和前面一样的操作,就不赘述了. 代码的最终执行结果肯定是进行了回滚操作. (但是这种写法浏览器会报500的错误)
【代码示例】- 手动回滚事务

- 手动回滚事务 : 通过事务的 AOP 拿到当前的事务, 然后设置回滚.
- 这种方式来处理事务的回滚, 显得更加优雅, 更推荐使用 (返回给浏览器的页面不会报错).
2. @Transactional的使用
@Transactional的作用范围:@Transactional既可以用来修饰方法也可以用来修饰类
- 修饰方法:只能应用到public方法上,否则不生效,推荐用法
- 修饰类:表明该注解对所有的public方法都生效
2.1 @Transactional中的参数作用
我们可以通过设置@Transactional的一些参数来决定事务的一些具体的功能
| 参数 | 作用 |
| value | 当配置了多个事务管理器时,可以使用该属性指定选择哪个事务管理器 |
| transactionManager | 当配置了多个事务管理器时,可以使用该属性指定选择哪个事务管理器 |
| propagation | 事务传播行为【事务传播机制是,下文中有详解】 |
| isolation | 事务的隔离级别,默认值为Isolation.DEFAULT |
| timeout | 事务的超时时间,默认值为-1【无时间限制】。如果超过该时长但事务还没有完成,则自动进行回滚事务 |
| readOnly | 指定事务是否为只读事务,默认值为false;为了忽略那些不需要事务的方法,比如读取数据可以设置read-only为true |
| rollbackFor | 用户指定能够触发事务回滚的异常类型,可以指定多个异常类型 |
| rollbackForClassName | 用于指定能够触发事务回滚的异常类型,可以指定多个异常类型 |
| noRollbackFor | 抛出指定的异常类型,不回滚事务,也可以指定多个异常类型 |
| noRollbackForClassName | 抛出指定的异常类型,不回滚事务,也可以指定多个异常类型 |
2.2 @Transactional工作原理
- @Transactional是基于AOP实现的,AOP是使用动态代理实现的。如果目标对象实现了接口,默认情况下会采用JDK的动态代理,如果目标对象没有实现了接口,会使用CGLIB动态代理
- @Transactional在开始执行业务之前,通过代理先开启事务,在执行之后再提交事务。如果中途遇到异常,则回滚事务
- @Transactional实现思路:

切面会拦截所有加了 @Transactional 注解的方法, 于是切点就有了, 然后开启事务与提交事务/回滚事务之间相当于是一个环绕通知.
3. 事务隔离级别
3.1 事务特性回顾
事务有4 ⼤特性(ACID):原⼦性、持久性、⼀致性和隔离性,具体概念如下:
- 原⼦性: ⼀个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执⾏过程中发⽣错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执⾏过⼀样。
- ⼀致性: 在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写⼊的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以⾃发性地完成预定的⼯作。
- 持久性: 事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
- 隔离性: 数据库允许多个并发事务同时对其数据进⾏读写和修改的能⼒,隔离性可以防⽌多个事务并发执⾏时由于交叉执⾏⽽导致数据的不⼀致。事务隔离分为不同级别,包括读未提交(Readuncommitted)、读提交(read committed)、可重复读(repeatable read)和串⾏化(Serializable)。
上⾯ 4 个属性,可以简称为ACID。
- 原⼦性(Atomicity,或称不可分割性)
- ⼀致性(Consistency)
- 隔离性(Isolation,⼜称独⽴性)
- 持久性(Durability)
⽽这 4 种特性中,只有隔离性(隔离级别)是可以设置的。
3.2 Spring 中设置事务隔离级别
Spring 中事务隔离级别可以通过 @Transactional 中的 isolation 属性进⾏设置,具体操作如下图所示:

3.2.1 MySQL 事务隔离级别有 4 种
- READ UNCOMMITTED:读未提交,也叫未提交读,该隔离级别的事务可以看到其他事务中未提交的数据。该隔离级别因为可以读取到其他事务中未提交的数据,⽽未提交的数据可能会发⽣回滚,因此我们把该级别读取到的数据称之为脏数据,把这个问题称之为脏读。
- READ COMMITTED:读已提交,也叫提交读,该隔离级别的事务能读取到已经提交事务的数据,因此它不会有脏读问题。但由于在事务的执⾏中可以读取到其他事务提交的结果,所以在不同时间的相同 SQL 查询中,可能会得到不同的结果,这种现象叫做不可重复读。
- REPEATABLE READ:可重复读,是 MySQL 的默认事务隔离级别,它能确保同⼀事务多次查询的结果⼀致。但也会有新的问题,⽐如此级别的事务正在执⾏时,另⼀个事务成功的插⼊了某条数据,但因为它每次查询的结果都是⼀样的,所以会导致查询不到这条数据,⾃⼰重复插⼊时⼜失败(因为唯⼀约束的原因)。明明在事务中查询不到这条信息,但⾃⼰就是插⼊不进去,这就叫幻读(Phantom Read)。
- SERIALIZABLE:序列化,事务最高隔离级别,它会强制事务排序,使之不会发⽣冲突,从⽽解决了脏读、不可重复读和幻读问题,但因为执⾏效率低,所以真正使⽤的场景并不多
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交 (READ UNCOMMITTED) | √ | √ | √ |
| 读已经提交 (READ COMMITTED) | × | √ | √ |
| 可重复读 (REPEATABLE READ) | × | × | √ |
| 序列化 (SERIALIZABLE) | × | × | × |
- 脏读:⼀个事务读取到了另⼀个事务修改的数据之后,后⼀个事务⼜进⾏了回滚操作,从⽽导致第⼀个事务读取的数据是错的。
- 不可重复读:⼀个事务两次查询得到的结果不同,因为在两次查询中间,有另⼀个事务把数据修改了。
- 幻读:⼀个事务两次查询中得到的结果集不同,因为在两次查询中另⼀个事务有新增了⼀部分数据。
3.2.2 Spring 事务隔离级别有 5 种
- Isolation.DEFAULT:以连接的数据库的事务隔离级别为主。
- Isolation.READ_UNCOMMITTED:读未提交,可以读取到未提交的事务,存在脏读。
- Isolation.READ_COMMITTED:读已提交,只能读取到已经提交的事务,解决了脏读,存在不可重复读。
- Isolation.REPEATABLE_READ:可重复读,解决了不可重复读,但存在幻读(MySQL默认级别)。
- Isolation.SERIALIZABLE:串⾏化,可以解决所有并发问题,但性能太低。从上述介绍可以看出,相⽐于 MySQL 的事务隔离级别,Spring 的事务隔离级别只是多了⼀个Isolation.DEFAULT(以数据库的全局事务隔离级别为主)

注意事项:
- 当 Spring 中设置了事务隔离级别和连接的数据库 (MySQL) 事务隔离级别发生冲突时,那么以 Spring 的为准
- Spring 中的事务隔离级别机制的实现是依靠连接数据库支持事务隔离级别为基础
4. Spring事务传播机制
4.1 事务传播机制是什么
Spring事务中传播机制定义了多个包含了事务的方法,相互调用时,事务是如何在这些方法间进行传递的
4.2 为什么需要事务传播机制
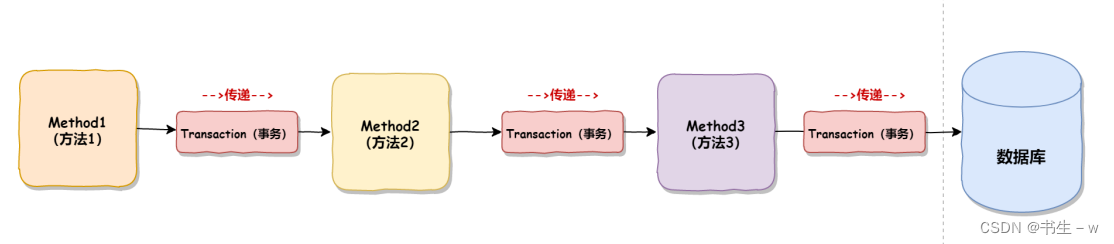
事务隔离级别是保证多个并发事务执行的可控性的(稳定性),而事务传播机制是保证一个事务在多个调用方法间的可控性(稳定性)
事务隔离解决的是多个事务同时调用一个数据库的问题,如图:

事务传播机制解决的是一个事务在多个节点(方法)中的传递问题,如下:
4.3 事务传播机制有哪些
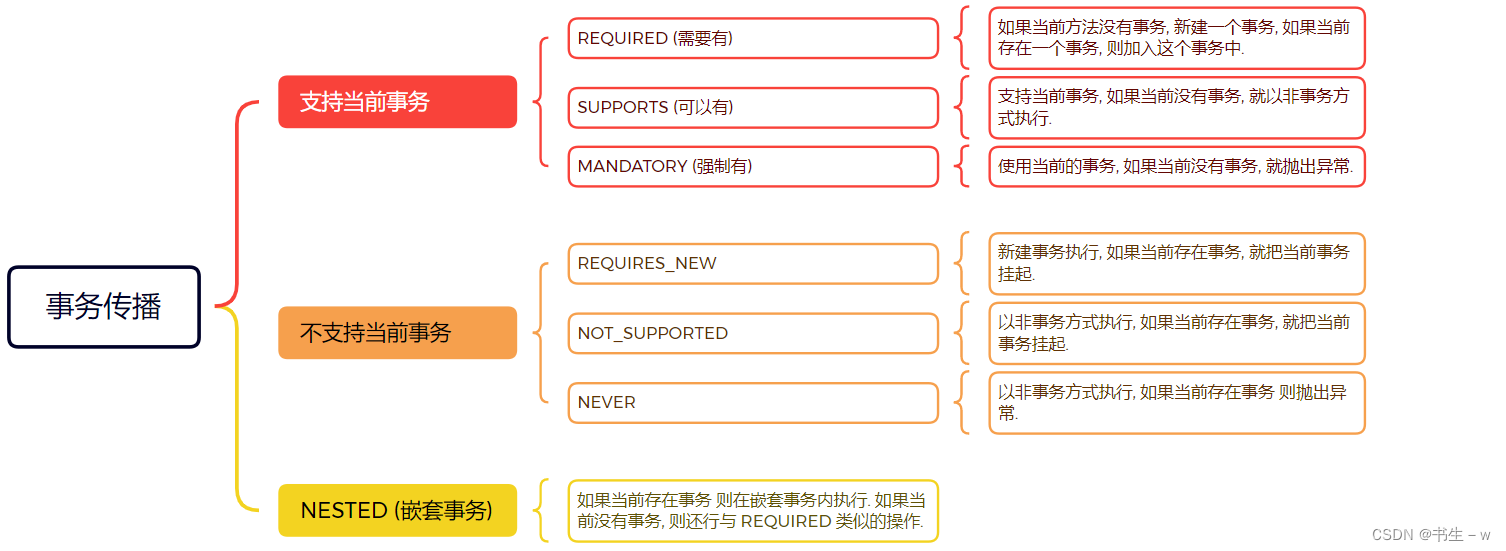
Spring事务的传播机制有以下7种:
- Propagation.REQUIRED:默认的事务传播机制,如果当前存在事务(调用该方法的外部方法已经开启了一个事务),那么就在该事务中运行(和外部方法共享同一个事务),否则,就开启一个新的事务。在这个级别中,参与者要么都提交成功,要么都回滚失败。
- Propagation.SUPPORTS:如果当前存在事务,那么就在该事务中运行,否则,可以以非事务方式运行。
- Propagation.MANDATORY:(mandatory强制性)如果当前存在事务,则加入事务;如果当前没有事务,则抛出异常
- Propagation.REQUIRES_NEW:表示创建一个新的事务,如果对当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务,Propagation.REQUIRES_NEW修饰的内部方法会新开启自己的事务,且启动的事务互相独立,互不干扰
- Propagation.NOT_SUPPORTED:总是以非事务方式运行,如果一个事务已经存在,那么将该存在的事务挂起。
- Propagation.NEVER:总是以非事务方式运行,如果存在一个事务,则抛出异常。
- Propagation.NESTED:如果一个事务已经存在,那么就在嵌套事务中运行,否则,就开启一个新的事务。对于嵌套事务,它是一个可以独立提交或回滚的子事务,但是,它的存在依赖于一个特定的外部事务。在外部事务未结束前,它不能独立提交或回滚。如果外部事务回滚,那么嵌套事务也会被回滚。与此同时,内部事务可以独立回滚而不影响外部事务。
4.4 事务传播的分类
这 7 中事务传播级别又可以分为三大类:
- 支持当前事务:REQUIRED + SUPPORTS + MANDATORY
- 不支持当前事务:REQUIRES_NEW + NOT_SUPPORTED + NEVER
- 嵌套事务 : NESTED
如果对于这三类事务传播机制, 不太理解的话, 下面把事务比做房子, 举一个生活中的例子 :
1. 支持当前事务 (普通伴侣)
- REQUIRED (需要有) : 有房子就一起住, 没房子就一起赚钱买房子. (愿意陪你吃苦, 但一定要有房子)
- SUPPORTS (可以有) : 有房子就一起住, 没房子就租房子住. (随缘的, 没房子也无所谓)
- MANDATORY (强制有) : 有房子一起住, 没房子就分手. (不愿陪你吃苦)
2. 不支持当前事务 (强势型伴侣)
- REQUIRES_NEW : 不要你的房子, 咱们必须一起赚钱买房子. (看不上你的房子, 必须买新房子)
- NOT_SUPPORTED : 不要你的房子, 咱们必须一起租房子. (不住你的房子, 必须租房子)
- NEVER : 必须一起租房子, 你要有房子就分手. (看不上你的房子, 还得陪你还房贷)
3. 嵌套事务 (懂事型伴侣)
- NESTED : 有房子就以房子为根据地做点小生意, 赚钱了就继续发展, 赔钱至少还有房子; 如果没房子就一起赚钱买房子. (无风险创业, 保本懂事型伴侣)
对于上述3 类事务传播机制, 主要就是 REQUIRED (默认级别) 和 NESTED (嵌套事务) 不好区分>>
REQUIRED和NESTED是最容易混淆的,因为它们都会参与到事务中,但差别在于REQUIRED是全局的,所有操作都是在同一个事务中,一起成功或失败,而NESTED是在当前事务中创建一个子事务,子事务可以独立于父事务进行回滚,这个子事务的回滚并不会影响到父事务。
4.5 Spring事务传播机制使用场景演示
4.5.1 支持当前事务(REQUIRED)
以下代码实现中,先开启事务先成功插⼊⼀条⽤户数据,然后再执⾏⽇志报错,⽽在⽇志报错时发⽣了异常,观察
propagation = Propagation.REQUIRED的执⾏结果。
- 准备工作:

UserController3:(Controller层主要负责处理用户请求并返回响应)
//这是一个组合注解,它组合了@Controller和@ResponseBody
//表明这个类是一个控制器,会处理HTTP请求,并且返回的数据会自动转换为JSON或其他格式
@RestController
//这个注解表明这个控制器会处理以"/user"开头的URL
@RequestMapping("/user3")
public class UserController3 {
@Autowired
private UserService userService;
@RequestMapping("/add")
@Transactional(propagation = Propagation.REQUIRED)
public int add (String username, String password) {
if(null == username || null == password || username.equals("") || password.equals("")) {
return 0;
}
Userinfo user = new Userinfo();
user.setUsername(username);
user.setPassword(password);
int result = userService.add(user);
// 用户添加操作
return result;
}
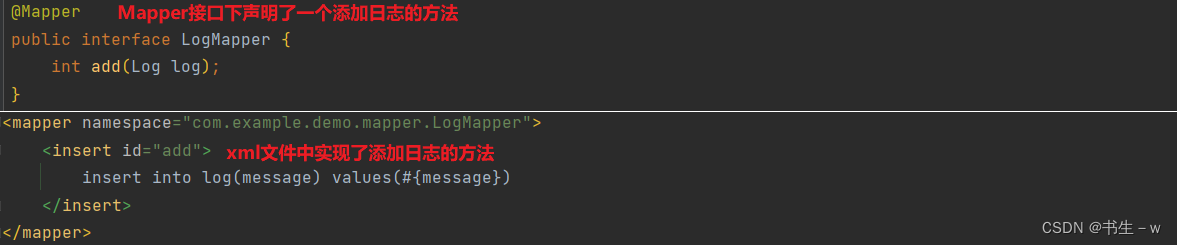
}LogService: (添加日志)
@Service
public class LogService {
@Autowired
private LogMapper logMapper;
@Transactional(propagation = Propagation.REQUIRED)
public int add(Log log) {
int result = logMapper.add(log);
System.out.println("添加日志结果: " + result);
int num = 10 / 0;
return result;
}
}UserService: (添加用户数据)
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Autowired
private LogService logService;
@Transactional(propagation = Propagation.REQUIRED)
public int add(Userinfo userinfo) {
// 给用户表添加用户信息
int addUserResult = userMapper.add(userinfo);
System.out.println("添加用户结果: " + addUserResult);
// 添加日志信息
Log log = new Log();
log.setMessage("添加用户信息");
logService.add(log);
return addUserResult;
}
}
代码调度执行流程图: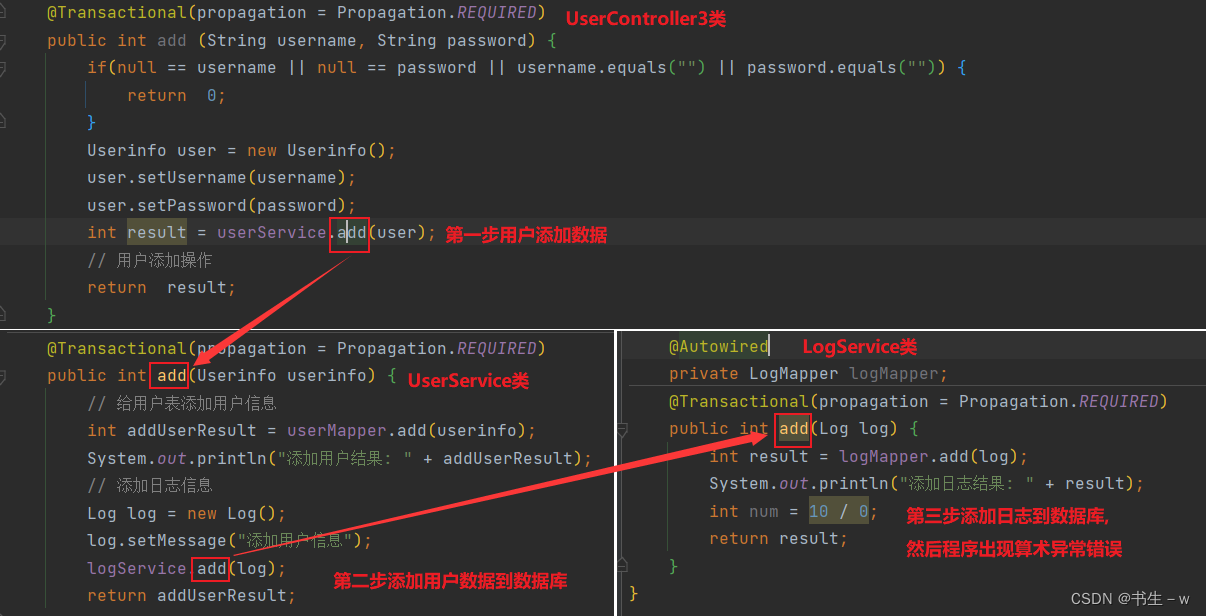
运行程序: 在浏览器页面输入url 127.0.0.1:8080/user3/add?username="小诗诗"&password="123" 发现报错了

观察控制台: (我们可以发现日志和用户数据添加成功了)
再观察数据库: (发现用户数据和日志都没有添加成功)

- 实际得出的结果是符合我们预期的 ,因为在我们的@Transactional注解中使用了默认的事务传播机制(REQUIRED),该机制表示如果当前存在事务,那么就在该事务中运行,否则,就开启一个新的事务。在这个级别中,参与者要么都提交成功,要么都回滚失败。
- 这里由于最后添加日志的时候发生算术异常,导致添加日志这个操作发生了回滚,没有提交成功,进而导致全部提交失败
4.5.2 不支持当前事务(REQUIRES_NEW)
Propagation.REQUIRES_NEW修饰的方法总是会在新的事务中运行。这个新的事务和原来的事务是相互独立的,也就是说,它们的提交和回滚不会互相影响。- 例如,假设有一个方法A,它在一个事务中运行,并且调用了一个使用
Propagation.REQUIRES_NEW修饰的方法B。如果方法B成功完成并且提交了它的事务,但是方法A之后抛出了一个异常并且回滚了它的事务,那么方法B的结果不会被回滚。反之亦然,如果方法B抛出了一个异常并且回滚了它的事务,那么方法A可以选择捕获那个异常并且继续它的事务,而不会影响到方法A的事务。
代码演示: 整体代码与上面一致,我们只需要把@Transactional里面的参数Propagation.REQUIRED改成Propagation.REQUIRES_NEW即可
![]()
同时将上面的添加日志的代码从抛出异常改成手动回滚,目的就是为了测试REQUIRES_NEW是否能让多个事务提交和回滚不受影响

- 此时运行程序: 在浏览器页面输入url 127.0.0.1:8080/user3/add?username="小诗诗"&password="123" 发现没有报错
- 同时观察控制台: (我们可以发现日志和用户数据添加成功了)

再观察数据库: (发现用户数据添加成功,日志为空)
此时的数据库的结果符合我们的预期,同时也证明 REQUIRES_NEW 它们的提交和回滚不会互相影响
4.5.3 嵌套事务(NESTED)
Propagation.NESTED可以启动一个“嵌套事务”,这是在一个已经存在的事务中启动的新事务。嵌套事务是一种特殊类型的子事务,它的提交是可以独立于外部事务的。但是,它的回滚会回滚所有从它开始到现在的所有操作,而不会影响到外部事务在它开始之前的操作。
此处不做代码演示了,只需要把上面代码里@Transactional里面的参数Propagation.REQUIRES_NEW改成Propagation.NESTED即可,得到的结果与上面一致.
嵌套事务为什么能实现部分事务的回滚 (面试题)
参考文档: MySQL
- 嵌套事务之所以能实现部分事务的回滚,是因为当嵌套事务开始时,会在事务日志中设置一个保存点(Savepoint)。如果后续的操作出现错误需要回滚,只需要回滚到这个保存点,也就是嵌套事务开始的地方。这就相当于只回滚了嵌套事务的部分,而不会影响到外部事务在嵌套事务开始之前的操作。
- 这种行为使得在一个大事务中执行一系列的任务时,如果某个任务失败,可以只回滚这个任务的操作,而不会影响到其他任务的结果。这在处理复杂的业务逻辑时是非常有用的。
4.5.4 嵌套事务(NESTED)和加入事务(REQUIRED)有什么区别?
- 嵌套事务,可以实现部分事务回滚,也就是说回滚时,一直往上找调用它的方法和事务回滚,而不会回滚嵌套之前的事务
- 加入事务,相当我已经成了他的一部分,回滚时,整个一起回滚
- 加入事务和嵌套事务的主要区别在于,当一个方法在运行过程中抛出了一个未捕获的异常并且需要回滚时,加入事务会回滚整个事务,而嵌套事务只会回滚从嵌套事务开始的部分。如果整个事务都执行成功,那么这两种传播行为的效果是一样的。
总结
-
当我们说"当前存在事务"时,我们通常是指调用当前方法的外部方法已经开启了一个事务。
-
当我们说一个方法"加入事务"时,我们通常是指这个方法并不自己单独开启一个新的事务,而是使用(或者说,加入到)调用它的外部方法已经开启的事务。这意味着这个方法的操作会成为外部事务的一部分,如果事务提交,那么这个方法的操作会被永久地应用到数据库;如果事务回滚,那么这个方法的操作也会被回滚。
这些概念是理解Spring的事务管理和事务传播行为的关键。
如果你觉得这篇文章有价值,或者你喜欢它,那么请点赞并分享给你的朋友。你的支持是我创作更多有用内容的动力,感谢你的阅读和支持。祝你有个美好的一天!

智能推荐
目标检测系列5——Faster R-CNN2(代码实现)_from detection.datasets-程序员宅基地
文章浏览阅读672次。参考黑马程序员教程(1) train.py# trainimport osimport tensorflow as tffrom tensorflow import kerasimport numpy as npimport matplotlib.pyplot as pltfrom detection.datasets import coco, data_generatorfrom detection.models.detectors import faster_rcnnimport_from detection.datasets
idea lanyu方式激活_idea.lanyus-程序员宅基地
文章浏览阅读2.2w次。访问http://idea.lanyus.com/这个地址。根据提示将0.0.0.0 account.jetbrains.com添加到hosts文件中,hosts文件在C:\Windows\System32\drivers\etc目录下。点击获得注册码即可。..._idea.lanyus
GPS经纬度坐标转换_$bdgsv,1,1,03,03,44,189,40,07,50,191,43,02,33,224,-程序员宅基地
文章浏览阅读777次,点赞6次,收藏6次。GNGGA,142940.000,3036.74671,N,10408.54235,E,1,07,1.2,573.5,M,0.0,M,*75 22:29:38.958:GNGGA表示全球定位系统定位信息,142940.000表示定位时间,3036.74671表示纬度,N表示北纬,10408.54235表示经度,E表示东经,1表示定位质量指示,07表示使用的卫星数量,1.2表示水平精度因子,573.5表示海拔高度,M表示单位为米,0.0表示大地水准面的高度,M表示单位为米。2.将串口的数据转成WGS84。_$bdgsv,1,1,03,03,44,189,40,07,50,191,43,02,33,224,36,,,,*53
知乎神回复:计算机应届生月薪大多是多少?10K仅仅才是起薪!_计算机两年经验10k-程序员宅基地
文章浏览阅读826次。能做到以下四点,本科在北上广深拿到10K以上,硕士15K以上,非常容易:第一,学校内的课程,计算机基础知识,如C语言,数据结构,计算机组成原理,计算机网络,计算机操作系统等这些基础专业知识一定要理解掌握,在校招中,这些内容必考。第二,提升自己写代码的能力。不会配置环境,不会框架,就去找资料自学,B站,慕课很多免费视频课程。第三,做项目。这里不是指学校做的项目,而是真正可以部署上线的项目。你可以去GitHub上找,也可以从学长学姐或者老师看是否有合适的项目,或者找一些大厂实习岗位。第四,疯_计算机两年经验10k
自动化运维工具saltstack(二)---grains、pillar、job cache、jinja模板详解与nginx、keepalived服务的配置_saltstack 变量赋值-程序员宅基地
文章浏览阅读342次。1.配置管理(续)现在,在上一篇博文的基础上,继续讲一下配置管理。补充一下sls文件的知识: Salt 状态系统的核心是SLS,或者叫SaLt State 文件。 SLS表示系统将会是什么样的一种状态,而且是以一种很简单的格式来包含这些数据,常被叫做配置管理。 sls文件命名: sls文件以”.sls”后缀结尾,但在调用是不用写此后缀。 使用子目录来做组织是个很好的选择。 init..._saltstack 变量赋值
MySQL ERROR 1701 (42000): Cannot truncate a table referenced in a foreign key constraint错误解决-程序员宅基地
文章浏览阅读1k次。MySQL ERROR 1701 (42000): Cannot truncate a table referenced in a foreign key constraint错误解决方法_cannot truncate a table referenced in a foreign key constraint
随便推点
bugku PEN_AND_APPLE (狗师傅平日里比较害羞,但是又想追女神,于是他隐藏了一段信息在这段自拍中,这句话是他最想对女神说的话:) 你能找到信息,并帮助狗师傅表白成功么:) 视屏在这儿)-程序员宅基地
文章浏览阅读3k次。提示是Windows下的type命令,Windows下的type命令可以显示文件内容。利用NTFS流文件隐藏首先用记事本新建两个文本文档,分别名为“1.txt”“2.txt”,其内容为“正常文件、数据流文件”,打开CMD命令行窗口, 进入两个文件所在文件夹,输入 type 2.txt>1.txt: shujuliu.txt,回车.即可将文件2.txt的内容加入1.txt, 内容..._bugku pen_and_apple
SQL获取每个分类中,最新的10条数据_sqlsevere 按每天取十条数据-程序员宅基地
文章浏览阅读5.5k次。Oracel和MSsql可以用自带函数如row_number()可以解决,比较方便,如下:select * from (select *,row_number() over(PARTITION by c_prov order by c_publish_date) as rowid from spiderdata_virus_prov_status) a where rowid<=10_sqlsevere 按每天取十条数据
三大框架SSM基础知识点_ssm框架-程序员宅基地
文章浏览阅读6.5k次,点赞2次,收藏52次。本文是对于SSM三大框架的简单总结,涉及三大框架的主要功能和相关的一些工具,也希望此文是对于个人知识点的一个总结。_ssm框架
curl 获取 https 请求方法-程序员宅基地
文章浏览阅读6.1k次。使用curl如果想发起的https请求正常的话有2种做法: 方法一、设定为不验证证书和host。 代码如下:$url = 'https://www.jb51.net';$curl = curl_init();curl_setopt($curl, CURLOPT_URL, $url);curl_setopt($curl, CURLOPT_HEADER, 1);curl_setop...
vue3+ts+vue-grid-layout 实现组件拖拽效果以及解决Vue3使用 vue-grid-layout的问题_vue-grid-layout vue3 +ts-程序员宅基地
文章浏览阅读3.3k次,点赞3次,收藏5次。【代码】vue3+ts+vue-grid-layout 实现组件拖拽效果。_vue-grid-layout vue3 +ts
Element-ui中的分页(pagination)组件的current-page属性不同步更新视图的坑_elementui 分页对象里面的值 跟页面不同步-程序员宅基地
文章浏览阅读7.2k次,点赞5次,收藏11次。Element-ui中的分页(pagination)组件的current-page属性不同步更新视图的坑_elementui 分页对象里面的值 跟页面不同步