论文笔记:A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild-程序员宅基地
技术标签: 论文阅读 深度学习论文阅读 计算机视觉 深度学习 talking face
文章目录
介绍
这篇论文提出Wav2Lip的方法,做到了根据提供的语音和视频来合成嘴唇配对的新视频。
以前相关方面的方法都有一些缺点:
- 只能针对训练时使用的speaker来合成视频,不能做到speaker-generic;
- 只能对静态的图像来合成视频,无法做到输入视频来合成;
- 训练需要一个特定的speaker的大量的数据,或者是需要非常clean的没有noisy的数据。
- 能够合成的词汇量是有限的。
而Wav2Lip做到了训练完后对任意speaker、语言、视频都可以进行合成,而且合成的视频的嘴唇与audio是非常同步的。
Wav2Lip的整体架构
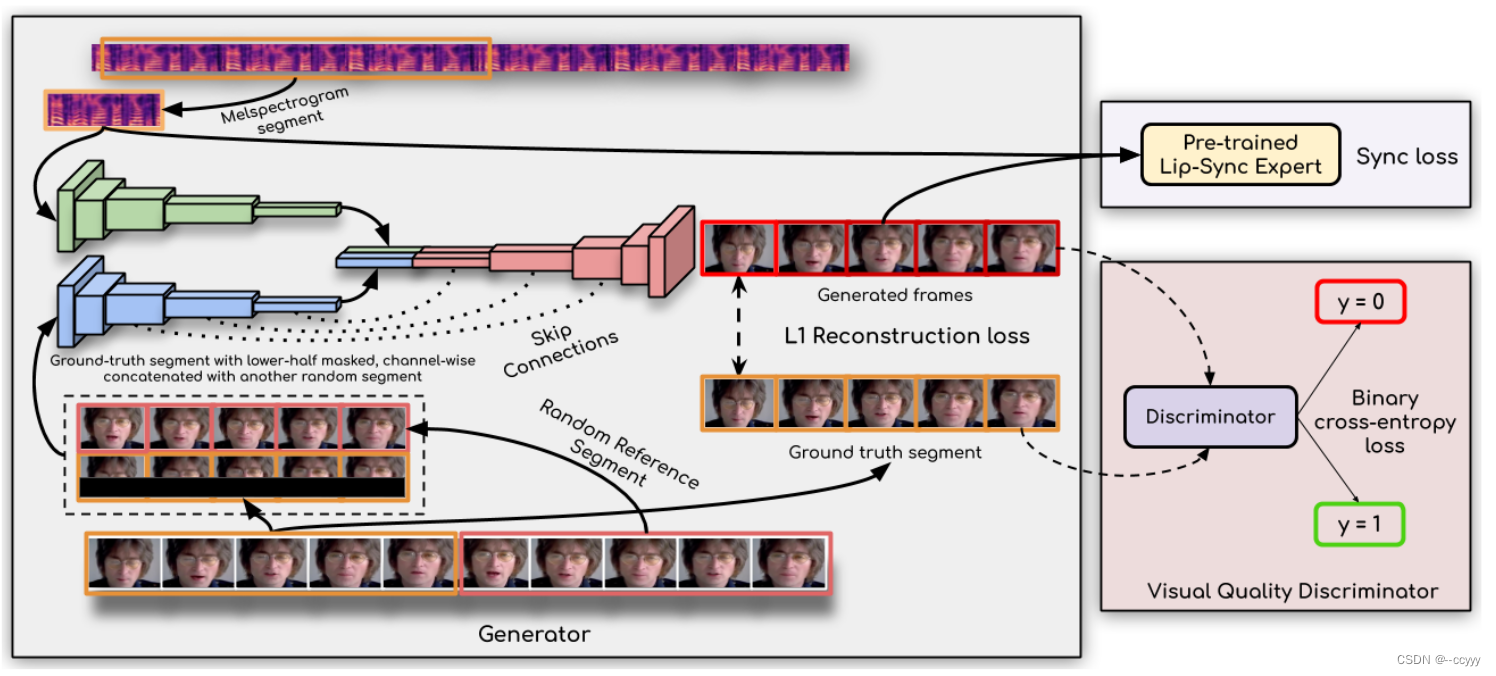
从图可以看出,Wav2Lip有一个generator,还有一个pre-trained好的判断lip-sync的判别器,以及一个判断视频质量的判别器。
下面一一介绍一下这些部分。
Lip-sync Expert
论文分析,以前的方法不能做到lip-sync的原因是:对不准确的嘴唇同步的惩罚太小了。
第一,用L1 reconstruction loss来判断嘴唇是否同步是很weak的,因为嘴唇只占了一张图片的很小的一部分,那loss更加注重的是图片的其他部分。(这个原因可以从一个事实来证实:就是在训练过程中,到训练中期才开始改变嘴唇的形状。)
所以我们需要一个专门针对嘴唇是否同步的判别器。
第二,确实有方法这么做了,就是以前的LipGAN。但是它只用了一张图片来判断嘴唇是否同步,在后面的实验中可以证实一小段视频会更好地检测。而且,LipGAN把这个判别器跟生成器一起训练了,导致会有noisy generated images进入到判别器中,这会导致判别器会过于在意生成图像中的artifacts而不是嘴唇的同步。
所以,为了解决这个问题,论文提出了一个pre-trained好的expert Lip-sync discriminator。它不会在训练生成器的时候再去微调。
这个判别器是模仿SyncNet的。
SyncNet的输入是一段长度为 T v T_v Tv的连续的face frames(只有下半张脸)和大小为 T a × D T_a\times D Ta×D的speech segment,判别器判别这两个是in-sync还是out-of-sync。SyncNet有一个face encoder和一个audio encoder(都是二维卷积层组成的),SyncNet要最大化unsynced pairs的两个embeddings之间的L2 distance,最小化synced pairs之间的L2 distance。
论文的判别器做了几点改变:
- SyncNet输入的是灰度图像的堆叠,这里输入的是彩色图像;
- 网络使用残差连接,让网络可以更深;
- 使用不同的损失函数:cosine-similarity with binary cross-entropy loss。
余弦相似度就是,设v和s是video and speech embeddings,计算audio-video pair同步的概率:
P s y n c = v ⋅ s m a x ( ∥ v ∥ 2 ⋅ ∥ s ∥ 2 , ϵ ) P_{sync}=\frac{v\cdot s}{max(\Vert v \Vert_2 \cdot \Vert s \Vert_2, \epsilon)} Psync=max(∥v∥2⋅∥s∥2,ϵ)v⋅s
generator
生成器的结构是参考LipGAN的。有三个组成部分:identity encoder;speech encoder;face decoder。
identity encoder是残差卷积层组成的,它的输入是:一段任意选取的reference frames R R R 和 pose prior P P P (就是遮住下半张脸)在通道维度上concatenated的。它这种输入使得生成的下半张脸可以无缝粘贴回原视频中,而不再需要后处理。
speech encoder是2维卷积层组成的,它是给 speech segment S S S 编码的。
face decoder由卷积层和反卷积层组成,输入就是前面两个encoder的输出concatenated在一起的feature map。
注意,生成器生成frames是一帧一帧生成的。假设batch size是 N N N,图像形状为 ( H , W , 3 ) (H, W, 3) (H,W,3),当要输入reference frames时,要把它们在batch size维度堆叠,即输入reference frames的形状为 ( N ⋅ T v , H , W , 3 ) (N\cdot T_v, H, W, 3) (N⋅Tv,H,W,3);当输入expert disciminator时,要把生成的frames在通道维度上堆叠,也就是是输入的形状为 ( N , H / 2 , W , 3 ⋅ T v ) (N, H/2, W, 3\cdot T_v) (N,H/2,W,3⋅Tv)。(H/2是因为只输入下半张脸去判断嘴唇是否同步。注意,训练生成器的时候expert disciminator是不参与训练的。)
生成器要最小化生成frames和真实frames的L1重建误差 L r e c o n L_{recon} Lrecon,以及最小化“expert sync-loss" E s y n c E_{sync} Esync:


Visual Quality Discriminator
因为生成的图像会模糊或者有一些artifacts,所以要再加上一个判别图像质量的判别器,从而提高图像质量。
这个判别器是会和生成器一起训练的。
判别器要最大化 L d i s c L_{disc} Ldisc,生成器要最小化 L g e n L_{gen} Lgen:

其中 L g L_g Lg对应生成器生成的图片, L G L_G LG对应真实图片。
在后面的实验中会看到,如果加入了这个质量判别器,图像的质量上去了,但是嘴唇的同步效果会受到一点点影响。所以可以根据实际情况对它们做权衡。
从而,生成器的总损失函数为:
L t o t a l = ( 1 − s w − s g ) ⋅ L r e c o n + s w ⋅ E s y n c + s g ⋅ L g e n L_{total} = (1-s_w-s_g)\cdot L_{recon} + s_w \cdot E_{sync} + s_g \cdot L_{gen} Ltotal=(1−sw−sg)⋅Lrecon+sw⋅Esync+sg⋅Lgen
新的lip-sync evaluation framework
在Wav2Lip的测试阶段,每一time-step,visual输入的是current face crop 和 同一段但是遮掉下半张脸的current face crop concatenate在一起的图像;audio输入的是对应的audio segment。
但是,在现在的evaluation framework中,输入的reference frames不能是current frames,而是任意选择的frames,以防泄露了真实的嘴唇形状。
但是这样是不好的一种方法。
第一,就如前面提到的,Wav2Lip在测试阶段不会改变人物的姿势。如果输入的reference frames与要嘴唇同步的current frames是不一致的话,Wav2Lip做不到改变姿势。这样就不能很好地评价模型的效果;
第二,对于不同的模型,选择的reference frames是不同的,导致评价并不公平;
第三,由于reference frames选取是随机的,时间上的一致性已被破坏;
第四,现在的metrics没有专门针对lip-sync的。
为了解决这个问题,我们不随机选取reference frames,而是随机选取speech segments,这样嘴唇真实形状就不会泄露了。那为什么以前不这样做呢?因为它们evaluate的时候需要有speech segments对应的真实视频(之前的评估方法是计算图像的L2 reconstruct loss),但这是无法获取到的。
论文使用了三个metrics来评判lip-sync:
- 第一个是SyncNet里提出的,用来衡量生成的frames和随机选取的speech segment之间的lip-sync error。注意,这里评判并不需要对应speech segment真实的视频。
- 论文提出的新的metric:LSE-D(Lip Sync Error-Distance)。计算了lip和audio的representations之间的平均距离。
- 论文提出的新的metric:LSE-C(Lip Sync Error-Confidence)。计算了平均的 lip-sync confidence score。
总结
论文提出了能够对任意视频、演讲者、语言进行嘴唇同步的方法,且提出了新的lip-sync evaluation framework。
智能推荐
Java串口通讯基础概念-程序员宅基地
文章浏览阅读83次。串行通讯协议有很多种,像RS232,RS485,RS422,甚至现今流行的USB等都是串行通讯协议。而串行通讯技术的应用无处不在。可能大家见的最多就是电脑的串口与Modem的通讯。记得在PC机刚开始在中国流行起来时(大约是在90年代前五年),那时甚至有人用一条串行线进行两台电脑之间的数据共享。除了这些,手机,PDA,USB鼠标、键盘等等都是以串行通讯的方式与电脑连接。而笔者工作性质的关系,..._peak 串口
MySql索引失效及解决方案_mysql or索引失效如何解决-程序员宅基地
文章浏览阅读1.2k次。MySql索引失效及解决方案_mysql or索引失效如何解决
Android安卓实战项目(12)—关于身体分析,BMI计算,喝水提醒,食物卡路里计算APP【支持中英文切换】生活助手类APP(源码在文末)-程序员宅基地
文章浏览阅读1.1k次。Android安卓实战项目(12)---关于身体分析,BMI计算,喝水提醒,食物卡路里计算APP【支持中英文切换】生活助手类APP(源码在文末)
对于人工智能的理解_你对人工智能目的的理解-程序员宅基地
文章浏览阅读2.7k次。分享一下这几天对人工智能的想法人工智能,缩写AI。谈到人工智能,我们首先想到的,它是一门学科,要我们去学习,但人工智能的终极目标是对人的意识、思维过程的模拟,它能像人那样思考,甚至超过人的智能。人工智能是一个交叉学科,涉及多领域,多专业,所以其复杂度可想而知。虽然,现在的人工智能还处于初级阶段,但是,不缺我们对之想象探索。它将是现在以及未来社会建设和发展的主流之一,将会影响我们未来生活各个方面发生重大改变。当然,我们现在的生活中在很多运用人工智能,如很多网站的AI客服,网上购平台为了提前预见客户的需求_你对人工智能目的的理解
HBase实践-程序员宅基地
文章浏览阅读2.5k次。HBase实践1.下载HBase查看版本号对应的java,Hadoophttps://hbase.apache.org/book.html#configuration下载地址:https://archive.apache.org/dist/hbase/stable/我下载的版本是stable版本:2.HBase2.4.10安装1.1 解压安装包hbase-2.2.2-bin.tar.gz至路径 /usr/local,命令如下:cd ~/Downloads/解压到/usr/loca
python3.9在各种环境安装实现_python 3.9-程序员宅基地
文章浏览阅读1.5k次。安装Python 3.9有多种方法,包括在不同操作系统上使用不同的包管理器进行安装。下面是在几种常见操作系统上安装Python 3.9的方法。_python 3.9
随便推点
Spring源码分析——Bean的加载_在spring中bean的创建过程-程序员宅基地
文章浏览阅读240次。Spring版本:5.1.14.RELEASEBean实例创建过程如下图,Bean的创建过程大部分是在docreateBean()里面完成的。_在spring中bean的创建过程
RTT Studio和Cubemx联合开发_rtt cube-程序员宅基地
文章浏览阅读892次。1. RTT studio创建工程创建工程## 创建完成以后的目录结构2. 配置CubuMx双击cubumx的图标打开CubeMx配置时钟生成代码构建后的代码结构编译代码满屏错误:不要慌3. 新增脚本新建scons脚本文件 SConscript脚本内容如下import osfrom building import *cwd = GetCurrentDir()src = Glob('*.c')# add cubemx driverssrc = Split('''_rtt cube
java string 去掉某个字符_JAVA String 如何去掉指定字符-程序员宅基地
文章浏览阅读3.2w次,点赞4次,收藏10次。展开全部i、replace方法该方法的作用是替换字符串中所有指定的字e69da5e6ba9062616964757a686964616f31333337616637符,然后生成一个新的字符串。经过该方法调用以后,原来的字符串不发生改变。例如:Strings=“abcat”;Strings1=s.replace(‘a’,‘1’);该代码的作用是将字符串s中所有的字符a替换成字符1,生成的..._string去掉指定字符
java:手动实现一个IOC_java手写ioc-程序员宅基地
文章浏览阅读749次,点赞3次,收藏11次。面试官特别爱问SpringIOC底层实现,Spring源码晦涩难懂 怎么办呢? 跟着老师手动实现一个mini ioc容器吧,实现后再回头看Spring源码事半功倍哦~,就算直接和面试官讲也完全可以哦,类名完全按照源码设计,话不多说 开干~!手动实现IOC容器的设计需要实现的IOC功能:可以通过xml配置bean信息 可以通过容器getBean获取对象 能够根据Bean的依赖属性实现依赖注入 可以配置Bean的单例多例实现简易IOC设计的类类之间关系模型..._java手写ioc
【计算机网络】应用层详解_应用层解析-程序员宅基地
文章浏览阅读558次。1.协议1.1 应用层自定制协议HTTP协议1.2 传输层UDP协议TCP协议1.3 自定制协议自定制协议是应用层协议,被程序员定义出来的协议(应用层对要传输的数据,进行数据格式的约定,消息发送方和接收方都必须遵守约定)TCP特性:面向字节流 2.TCP粘包问题 我们需要在应用层自定制协议,自定制协议增加报头和分隔符【定长报头(数据长度)】+数据【定长报头】+ 数据+分隔符【不定长报头】+数据+分隔符 对于定长报头,双方的收发都是遵守约定的 不定长的_应用层解析
wget 批量下载并且按序号重命名 windows版_wget批量下载文件并重命名-程序员宅基地
文章浏览阅读5k次。@echo offsetlocal enabledelayedexpansionset /a num=0FOR /F %%i in (URL.txt) do ( set /a num+=1 title !num! wget -c -q %%i -O !num!.jpg)各条命令按行解释关闭显示启用变量延迟,不然循环里获取不到上一次设置的值num=0FOR循环,批处理里变量必须用%%作..._wget批量下载文件并重命名