Python爬虫详解(一看就懂)-程序员宅基地
爬虫
爬虫是什么
爬虫简单的来说就是用程序获取网络上数据这个过程的一种名称。
爬虫的原理
如果要获取网络上数据,我们要给爬虫一个网址(程序中通常叫URL),爬虫发送一个HTTP请求给目标网页的服务器,服务器返回数据给客户端(也就是我们的爬虫),爬虫再进行数据解析、保存等一系列操作。
流程
爬虫可以节省我们的时间,比如我要获取豆瓣电影 Top250 榜单,如果不用爬虫,我们要先在浏览器上输入豆瓣电影的 URL ,客户端(浏览器)通过解析查到豆瓣电影网页的服务器的 IP 地址,然后与它建立连接,浏览器再创造一个 HTTP 请求发送给豆瓣电影的服务器,服务器收到请求之后,把 Top250 榜单从数据库中提出,封装成一个 HTTP 响应,然后将响应结果返回给浏览器,浏览器显示响应内容,我们看到数据。我们的爬虫也是根据这个流程,只不过改成了代码形式。
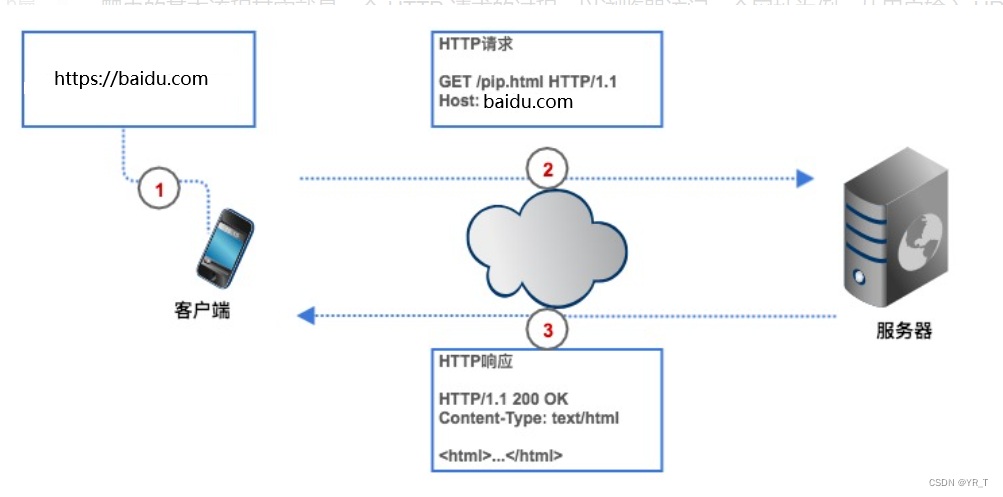
HTTP请求
HTTP 请求由请求行、请求头、空行、请求体组成。
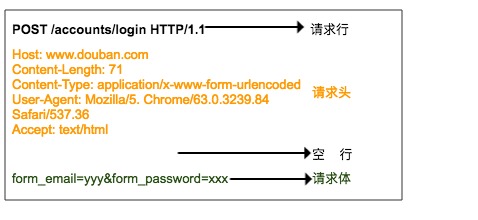
请求行由三部分组成:
1.请求方法,常见的请求方法有 GET、POST、PUT、DELETE、HEAD
2.客户端要获取的资源路径
3.是客户端使用的 HTTP 协议版本号
请求头是客户端向服务器发送请求的补充说明,比如说明访问者身份,这个下面会讲到。
请求体是客户端向服务器提交的数据,比如用户登录时需要提高的账号密码信息。请求头与请求体之间用空行隔开。请求体并不是所有的请求都有的,比如一般的GET都不会带有请求体。
上图就是浏览器登录豆瓣时向服务器发送的HTTP POST 请求,请求体中指定了用户名和密码。
HTTP 响应
HTTP 响应格式与请求的格式很相似,也是由响应行、响应头、空行、响应体组成。
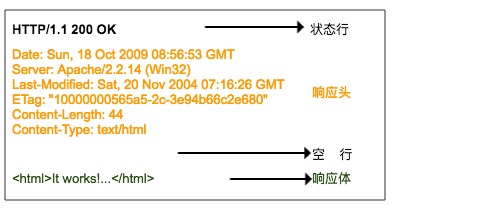
响应行也包含三部分,分别是服务端的 HTTP 版本号、响应状态码和状态说明。
这里状态码有一张表,对应了各个状态码的意思



第二部分就是响应头,响应头与请求头对应,是服务器对该响应的一些附加说明,比如响应内容的格式是什么,响应内容的长度有多少、什么时间返回给客户端的、甚至还有一些 Cookie 信息也会放在响应头里面。
第三部分是响应体,它才是真正的响应数据,这些数据其实就是网页的 HTML 源代码。
爬虫代码怎么写
爬虫可以用很多语言比如 Python、C++等等,但是我觉得Python是最简单的,
因为Python有现成可用的库,已经封装到几乎完美,
C++虽然也有现成的库,但是它的爬虫还是比较小众,仅有的库也不足以算上简单,而且代码在各个编译器上,甚至同一个编译器上不同版本的兼容性不强,所以不是特别好用。所以今天主要介绍python爬虫。
安装requests库
cmd运行:pip install requests ,安装 requests。
然后在 IDLE 或者编译器(个人推荐 VS Code 或者 Pycharm )上输入
import requests 运行,如果没有报错,证明安装成功。
安装大部分库的方法都是:pip install xxx(库的名字)
requests的方法
| requests.request() | 构造一个请求,支撑一下各方法的基本方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() |
获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch( ) | 向HTML网页提交局部修改请求,对应于HTTP的PATCT |
| requests.delete() | 向HTML网页提交删除请求,对应于HTTP的DELETE |
最常用的get方法
r = requests.get(url)
包括两个重要的对象:
构造一个向服务器请求资源的Request对象;返回一个包含服务器资源的Response对象
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式(如果header中不存在charset,则认为编码为ISO-8859-1) |
| r.apparent_encoding | 从内容中分析的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
爬虫小demo
requests是最基础的爬虫库,但是我们可以做一个简单的翻译
我先把我做的一个爬虫的小项目的项目结构放上,完整源码可以私聊我下载。
下面是翻译部分的源码
import requests
def English_Chinese():
url = "https://fanyi.baidu.com/sug"
s = input("请输入要翻译的词(中/英):")
dat = {
"kw":s
}
resp = requests.post(url,data = dat)# 发送post请求
ch = resp.json() # 将服务器返回的内容直接处理成json => dict
resp.close()
dic_lenth = len(ch['data'])
for i in range(dic_lenth):
print("词:"+ch['data'][i]['k']+" "+"单词意思:"+ch['data'][i]['v'])代码详解:
导入requests模块,设置 url为百度翻译网页的网址。
然后通过 post 方法发送请求,再把返回的结果打成一个 dic (字典),但是这个时候我们打印出来结果发现是这样的。

这是一个字典里套列表套字典的样子,大概就是这样的
{ xx:xx , xx:[ {xx:xx} , {xx:xx} , {xx:xx} , {xx:xx} ] }
我标红的地方是我们需要的信息。
假如说我标蓝色的列表里面有 n 个字典,我们可以通过 len() 函数获取 n 的数值,
并使用 for 循环遍历,得到结果。
dic_lenth = len(ch['data']
for i in range(dic_lenth):
print("词:"+ch['data'][i]['k']+" "+"单词意思:"+ch['data'][i]['v'])最后
好了,今天的分享就到这里了,拜拜~
哎?忘了一件事,再给你们一个爬取天气的代码!
# -*- coding:utf-8 -*-
import requests
import bs4
def get_web(url):
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59"}
res = requests.get(url, headers=header, timeout=5)
# print(res.encoding)
content = res.text.encode('ISO-8859-1')
return content
def parse_content(content):
soup = bs4.BeautifulSoup(content, 'lxml')
'''
存放天气情况
'''
list_weather = []
weather_list = soup.find_all('p', class_='wea')
for i in weather_list:
list_weather.append(i.text)
'''
存放日期
'''
list_day = []
i = 0
day_list = soup.find_all('h1')
for each in day_list:
if i <= 6:
list_day.append(each.text.strip())
i += 1
# print(list_day)
'''
存放温度:最高温度和最低温度
'''
tem_list = soup.find_all('p', class_='tem')
i = 0
list_tem = []
for each in tem_list:
if i == 0:
list_tem.append(each.i.text)
i += 1
elif i > 0:
list_tem.append([each.span.text, each.i.text])
i += 1
# print(list_tem)
'''
存放风力
'''
list_wind = []
wind_list = soup.find_all('p', class_='win')
for each in wind_list:
list_wind.append(each.i.text.strip())
# print(list_wind)
return list_day, list_weather, list_tem, list_wind
def get_content(url):
content = get_web(url)
day, weather, tem, wind = parse_content(content)
item = 0
for i in range(0, 7):
if item == 0:
print(day[i]+':\t')
print(weather[i]+'\t')
print("今日气温:"+tem[i]+'\t')
print("风力:"+wind[i]+'\t')
print('\n')
item += 1
elif item > 0:
print(day[i]+':\t')
print(weather[i] + '\t')
print("最高气温:"+tem[i][0]+'\t')
print("最低气温:"+tem[i][1] + '\t')
print("风力:"+wind[i]+'\t')
print('\n')
好了,这下是真的拜拜了,明天见~
智能推荐
GY906 MLX90614 非接触式 红外测温传感器 LabVIEW i2c总线数据读取-程序员宅基地
文章浏览阅读5.3k次。GY906使用的红外测温芯片为MLX90614。使用LabVIEW读取i2c总线数据时,需要知道传感器的地址,出厂默认为0x5A。传感器地址支持自己修改,存放在芯片EEPROM的0x0E位置,可以通过访问EEPROM的0x0E单元来获得传感器的地址。具体修改和访问EEPROM参考链接:ARDUINO使用MLX90614红外温度传感器研究笔记_雨田大大的专栏-程序员宅基地_mlx90614红外传感器工作原理使用LabVIEW中封装好的I2C express vi可以对传感器的I2C总线进行访问_labview i2c
这些学习方法等于瞎忙-程序员宅基地
文章浏览阅读602次,点赞22次,收藏17次。任何不加验证的知识和经验都是一种空泛的存在,因为我们不掌握这些知识和经验可以使用或不可以使用的环境特征,就极容易导致关键时刻使用相关知识和经验造成严重后果,同时也会影响我们的使用积极性,所以我们所学知识、技能和经验的验证和学习本身一样重要。不注重学习的系统性、方向性和自身所处阶段的结合,投入时间去学习自身所能涉猎的任何内容,对所学学科不做阶段性规划,同一时期在学不同学科的内容,随手拿来就学,这样的学习方法无法避免知识体系之间互相的干扰和破坏,更不利于解决系统性问题。第七种、学习的过程中没有积累。
大数据运维实战第十二课 Hadoop 分布式资源管理器 Yarn、MR 运行机制剖析_yarn rmadmin-程序员宅基地
文章浏览阅读776次,点赞2次,收藏4次。本课时主要讲解了分布式资源管理器 Yarn、MR 运行机制,以及 Yarn 相关的 shell 命令,对于 Yarn 资源运行机制的了解有助于对 Hadoop 集群进行调优和故障排查,这部分内容非常重要,要求我们能熟练掌握。......_yarn rmadmin
IDEA-Tomcat-源服务器未能找到目标资源的表示或者是不愿公开一个已经存在的资源表示_idea源服务器未能找到目标资源的表示或者是不愿公开一个已经存在的资源表示。-程序员宅基地
文章浏览阅读6.4w次,点赞36次,收藏104次。IDEA-Tomcat-源服务器未能找到目标资源的表示或者是不愿公开一个已经存在的资源表示1起因2经过3说白了1起因在学习springMVC的过程中,写了一个demo需要部署到本地Tomcat上来运行(直接使用IDEA配置本地tomcat,不用再手动发war包到tomcat目录下)。因为之前用SpringBoot项目比较多(集成了Tomcat,不需要额外部署设置;也不需要额外配好多xml),所以这部分可以说是从0学起,踩了好多坑。出现上面“源服务器未能找到目标资源的表示或者是不愿公开一个已经存在的资源_idea源服务器未能找到目标资源的表示或者是不愿公开一个已经存在的资源表示。
CAPL通用函数整理---记录_capl控件-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏45次。ltoa | 整型转字符串,第三个参数选择转换出来的进制类型,2:二进制,10:十进制,16:十六进制 | long z = 255;|_gcvt |浮点数转字符串 | char s1[15];|_atoi64 | 64字节的字符串转为整形 | int i64 = _atoi64("4564616546516");| diagSendResponse | 用于发送诊断响应给诊断仪,仅用于ECU仿真节点时|_capl控件
【数据结构/C语言版】【栈】链式存储_operandtype在数据结构-程序员宅基地
文章浏览阅读72次。链式#include<iostream>using namespace std;#define SElemType char#define Status inttypedef char OperandType;typedef struct SNode { SElemType data; SNode* next;}SNode, * LinkStack;Status InitStack(LinkStack& S){ S = (LinkStack)malloc(_operandtype在数据结构
随便推点
Teamcenter二次开发介绍及资料_teamcenter soa二次开发-程序员宅基地
文章浏览阅读4k次。1、RCP客户端开发Teamcenter客户化RCP二次开发2、SOA集成开发Teamcenter客户化SOA二次开发3、ITK服务端开发Teamcenter客户化ITK二次开发4、UtilityTeamcenter客户化Utility二次开发5、AWCTeamcenter客户化AWC二次开发6、系统集成Teamcenter客户化之系统集成7、RCP,ITK及SOA二次..._teamcenter soa二次开发
基于单片机的智能控制家电开关系统的设计和实现_基于单片机的智能家电控制系统设计-程序员宅基地
文章浏览阅读1.3k次,点赞35次,收藏25次。本文首先介绍了单片机的原理和基本分类,之后分析了智能控制系统中单片机的实际应用,最后提出Wi-Fi模式和蓝牙模式的单片机智能控制家电开关系统,以此来达到智能控制家用电器的目的,为互联网智能控制体系的完善提供了有效保障。智能家居控制领域中单片机发挥着非常重要的作用,具有较为广泛的应用前景,在智能控制系统中,单片机的出现不仅实现了产品设计的优化,并且提高了效率和质量,因此文章基于单片机重点阐述了智能控制家电开关系统的具体设计,为现代人生活便捷提供有效保障。_基于单片机的智能家电控制系统设计
Vue封装websocket_vue websocket封装-程序员宅基地
文章浏览阅读4.6k次,点赞4次,收藏21次。Vue封装websocket_vue websocket封装
Unity拓展编辑器 一键导出图集工具_spritepath-程序员宅基地
文章浏览阅读1.4k次。在项目开发过程中我们必不可少的会将美术给的资源打包成图集来降低drawcall,减少包内存。为了方便的生成图集,以及生成图片路径配置来方便通过图片名称快速定位所在的图集以及图片位置。_spritepath
ka电器表示什么意思_电器上的KA是指的什么电流?-程序员宅基地
文章浏览阅读7.1k次。展开全部电器62616964757a686964616fe58685e5aeb931333431363039上的KA是指的电流继电器电流。电气中的符号“K”它首先是代表开关,然后是接触器,继电器,KA(电流继电器),KT(时间继电器),KF(频率继电器),KP(压力继电器),KS(信号继电器),KE(接地继电器),KM(接触器),KC(控制继电器,驱动器)。继电器具有控制系统(又称输入回路)和被控..._高温柜ka表示
3天掌握Flask开发项目系列博客之二,操作数据库_flask 数据库开发-程序员宅基地
文章浏览阅读1.9w次,点赞2次,收藏2次。flask 操作数据库,写入一条数据当 flask 基本环境运行起来之后,就要考虑数据入库相关内容了,本篇博客会将 flask 与 mysql 实现对接,完成一个入库操作。首先依旧是安装模块,flask 就是这点比较好,可扩展性特别强。pip install flask-sqlalchemy pymysql其中 flask-sqlalchemy 是一套ORM框架,在它的帮助下,可以让我们像操作数据对象一样操作数据库表数据。除了这些以外,你还要在电脑上安装 MySQL 数据库,最好在安装一个 na_flask 数据库开发