NLP实战之BERTopic主题分析-程序员宅基地
在自然语言处理(NLP)领域,主题分析一直是一个讨论比较火热的话题。通过主题分析,我们可以揭示文本数据中的隐藏主题,这对于信息检索、文本分类、舆情分析等任务非常有用。本篇博客将介绍一种基于BERT和Topic Modeling的主题分析方法——BERTopic,它的强大之处在于可以自动发现文本数据中的主题,而无需预先定义主题数。
BERTopic简介
BERTopic是一种结合了预训练模型BERT和主题建模的强大工具。它允许我们将大规模文本数据集中的文档映射到主题空间,并自动识别潜在的主题。它背后的核心思想是通过BERT模型来捕获文档的语义信息,并然后使用主题建模技术来对这些语义信息进行聚类,从而得出主题。对于大部分小伙伴而言,知道如何去使用BERTopic模型进行主题分析就足够了。所以BERTopic原理就不做过多解释了,感兴趣的小伙伴可以自己去了解一下。
1 数据准备与预处理
在pycharm上运行的小伙伴去看我的另一篇NLP实战之BERTopic主题模型分析(pycharm)
在进行主题分析之前,先进行数据准备和预处理:
1.1 数据准备:首先,我们需要准备文本数据。这可以是一组文档,例如新闻文章、论文摘要或任何其他文本数据。这里我选取的是WOS核心合集中图情领域关于VR和metaverse的500篇论文摘要。文件类型是xlsx格式的excel文件。如果要加载csv只需要将读取文件部分的代码修改一下即可。
import os
import pandas as pd
import re
output_path = 'D:/notebook/LDAsklearn_origin/result'
file_path = 'D:/notebook/BERTopic/data'
os.chdir(file_path)
data=pd.read_excel("dataset.xlsx").astype(str)#content type
#加载csv文件
#data=pd.read_csv("dataset.csv").astype(str)#content type
os.chdir(output_path)
dic_file = "D:/notebook/LDAsklearn_origin/stop_dic/dict.txt"
stop_file = "D:/notebook/LDAsklearn_origin/stop_dic/stop_words.txt"1.2 数据预处理:这里可以采用jieba(中文分词)、NLTK(英文分词)等库做相应的处理。我只是做了一个简单的示例,所以在数据预处理时,只是进行了去除停用词,后续可以使用NLTK进行完善。
def english_word_cut(mytext):
stop_list = []
try:
with open(stop_file, encoding='utf-8') as stopword_list:
stop_list = [line.strip() for line in stopword_list]
except FileNotFoundError:
print(f"Error: Stop file '{stop_file}' not found.")
word_list = []
# 使用正则表达式将文本分割为单词
words = re.findall(r'\b\w+\b', mytext)
for word in words:
# 将单词转换为小写,以便统一处理
word = word.lower()
# 如果单词在停用词列表中,跳过该单词
if word in stop_list or len(word) < 2:
continue
word_list.append(word)
return " ".join(word_list)
data["content_cutted"] = data.content.apply(english_word_cut)
print(data["content_cutted"])2 BERTopic Moudel构建
接下来,让我们看一下BERTopic主题模型分析的流程:
2.1 导入bertopic及相关第三方库
from bertopic import BERTopic
from sentence_transformers import SentenceTransformer
from umap import UMAP
from hdbscan import HDBSCAN
from bertopic.vectorizers import ClassTfidfTransformer在安装bertopic第三方库时可能会出现很多问题,后续我会专门写一篇讲解如何安装bertopic的文章
2.2 嵌入文档
使用默认的英文文本嵌入模型all-MiniLM-L6-v2进行文档嵌入,paraphrase-multilingual-MiniLM-L12-v2 支持中文或其他50多种语言,该模型与基本模型非常相似,但经过多种语言训练,并且体系结构略有不同。这里建议大家在使用的时候先去huggingface.co网站把模型下载到本地。一方面,可以大大减少嵌入的时间,另一方面,避免在使用SentenceTransformer时访问失败。
# Step 1 - Embed documents
embedding_model = SentenceTransformer('D:/notebook/BERTopic/all-MiniLM-L6-v2')SentenceTransformer:all-MiniLM-L6-v2(英文)、paraphrase-multilingual-MiniLM-L12-v2(中文或其他)
2.3 聚类文档
先利用UMAP算法降低嵌入的维数,再运用HDBSCAN算法创建语义相似文档的聚类。
2.3.1 向量降维
使用UMAP进行词嵌入向量降维,
# Step 2 - Reduce dimensionality
umap_model = UMAP(n_neighbors=15, n_components=5,min_dist=0.0,metric='cosine')
n_neighbors:近似最近邻数。它控制了UMAP局部结构与全局结构的平衡,数值较小时,UMAP会更加关注局部结构,反之,会关注全局结构,丢掉一些细节。
n_components:设置将数据嵌入的降维空间的维数。
min_dist:点之间的最小距离。此参数控制UMAP聚集在一起的紧密程度,值较小时,会更紧密,反之,会更松散。
2.3.2 聚类
使用HDBSCAN对降维向量聚类,聚类方法不局限于HDBSCAN,也可以使用K-means聚类等。一般常用HDBSCAN聚类方法。
# Step 3 - Cluster reduced embeddings
hdbscan_model = HDBSCAN(min_cluster_size=10, metric='euclidean', prediction_data=True)min_cluster_size:控制集群的最小大小,它通常设置为默认值10。值越大,集群越少但规模更大,而值越小,微集群越多。
metric:用于计算距离,通常使用默认值euclidean.
prediction_data:一般始终将此值设置为True,可以预测新点。如果不进行预测,可以将其设置为False。
2.4 构建表征主题
2.4.1 c-TF-IDF
通过c-TF-IDF算法提取主题候选词。
# Step 4 - Create topic representation
from sklearn.feature_extraction.text import CountVectorizer
vectorizer_model = CountVectorizer(stop_words="english")
ctfidf_model = ClassTfidfTransformer()stop_words: 设置停用词语言。
2.4.2 训练bertopic主题模型
topic_model = BERTopic(
embedding_model=embedding_model, # Step 1 - Extract embeddings
umap_model=umap_model, # Step 2 - Reduce dimensionality
hdbscan_model=hdbscan_model, # Step 3 - Cluster reduced embeddings
vectorizer_model=vectorizer_model, # Step 4 - Tokenize topics
ctfidf_model=ctfidf_model, # Step 5 - Extract topic words
diversity=0.5, # Step 6 - Diversify topic words
nr_topics='none',
top_n_words = 10
)top_n_words:设置提取的每个主题的字数,通常为10-30之间。
min_topic_size:设置主题最小大小,值越低,创建的主题就越多。值太高,则可能根本不会创建任何主题。
nr_topics:设置主题数量,可以设置为一个具体的数字,也可设置为‘none’不进行主题数量约束,设置为‘auto’则自动进行约束。
diversity:是否使用MMR(最大边际相关性)来多样化主题表示,可以设置0~1之间的值,0表示完全不多样化,1表示最多样化,设置为‘none’,不会使用MMR。
2.4.3 文档主题概率
使用fit_transform对输入文本向量化,然后使用topic_model模型提取主题topics,并且计算主题文档概率probabilities
filtered_text = data["content_cutted"].tolist()
topics, probabilities = topic_model.fit_transform(filtered_text)
topic_model.get_document_info(filtered_text)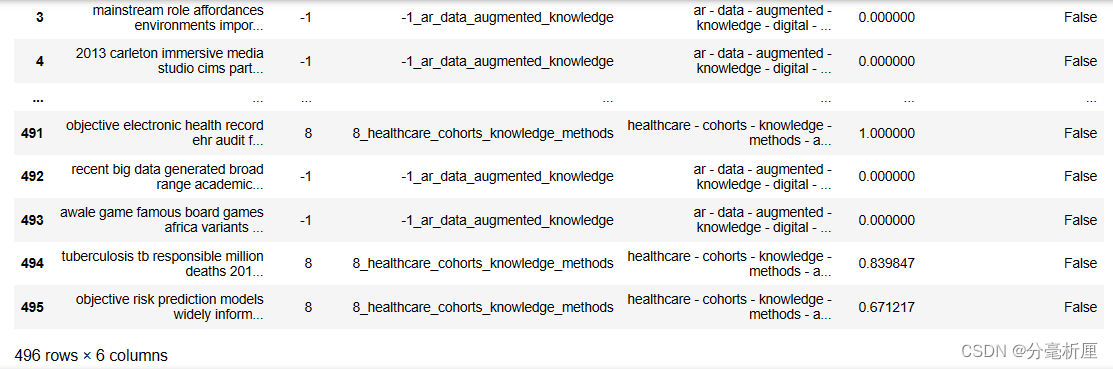
查看每个主题数量
topic_model.get_topic_freq()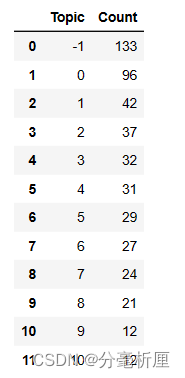
其中-1为噪声,没有聚到任何一类中。
查看某个主题-词的概率分布
topic_model.get_topic(0)
3 BERTopic可视化
BERTopic还提供了丰富的可视化工具,可以帮助您理解生成的主题。
3.1 主题-词概率分布
topic_model.visualize_barchart()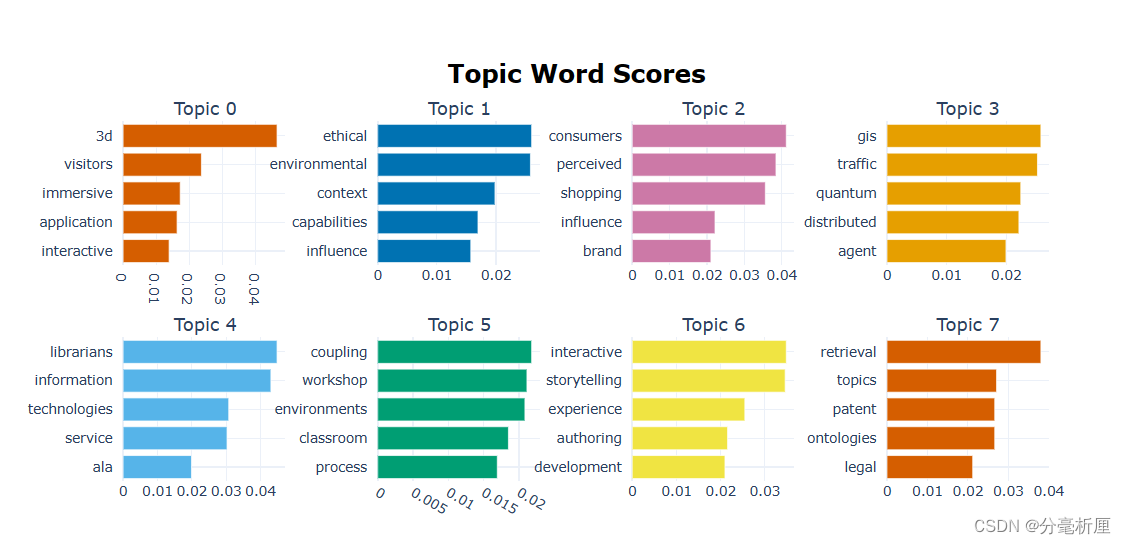
3.2 文档主题聚类
embeddings = embedding_model.encode(filtered_text, show_progress_bar=False)
# Run the visualization with the original embeddings
topic_model.visualize_documents(filtered_text, embeddings=embeddings)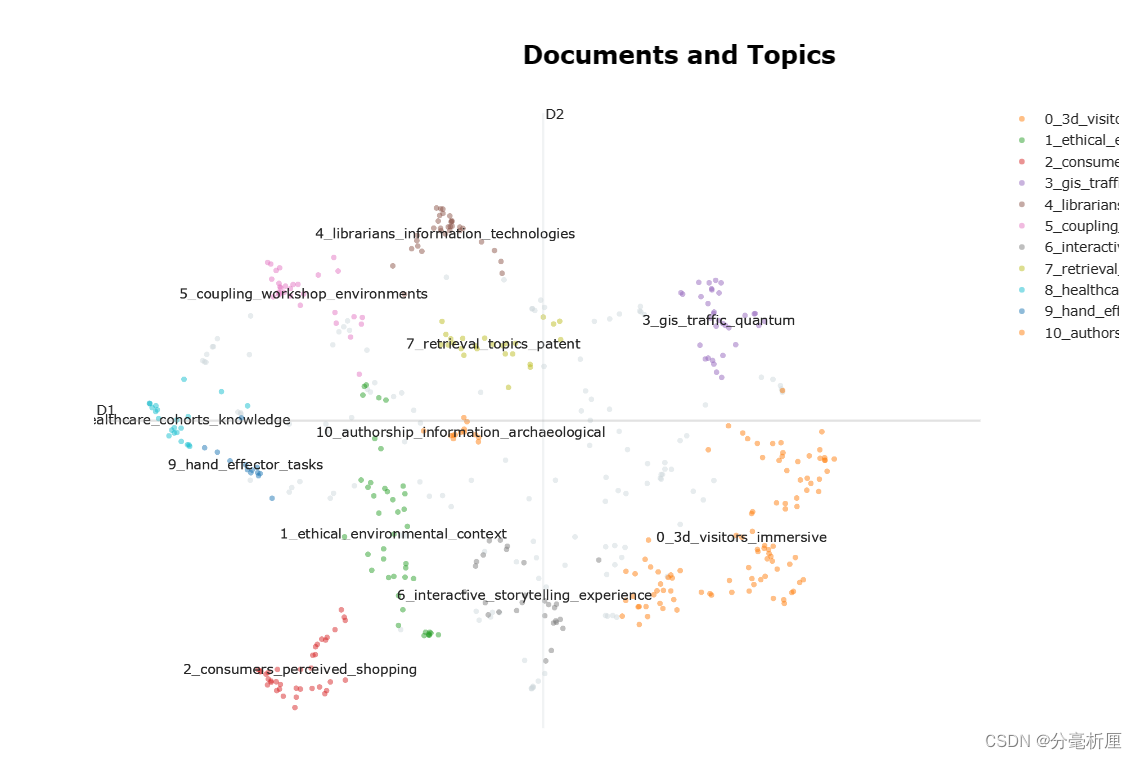
3.3 聚类分层
topic_model.visualize_hierarchy()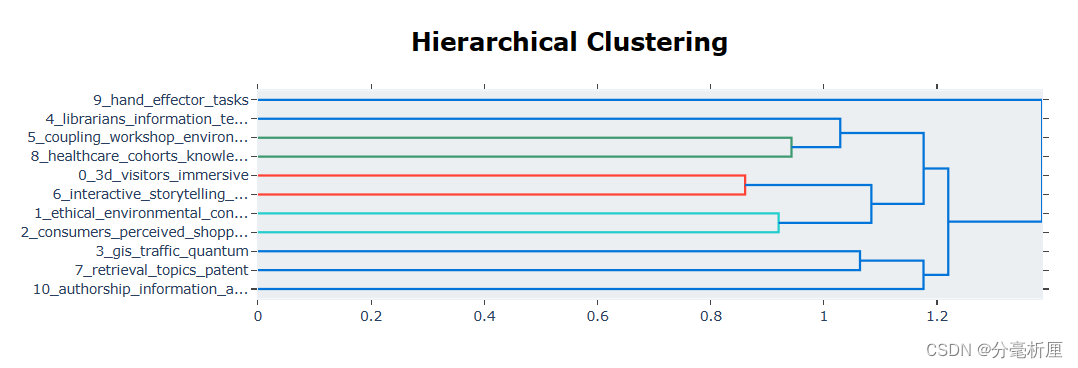
3.4 主题相似度热力图
topic_model.visualize_heatmap()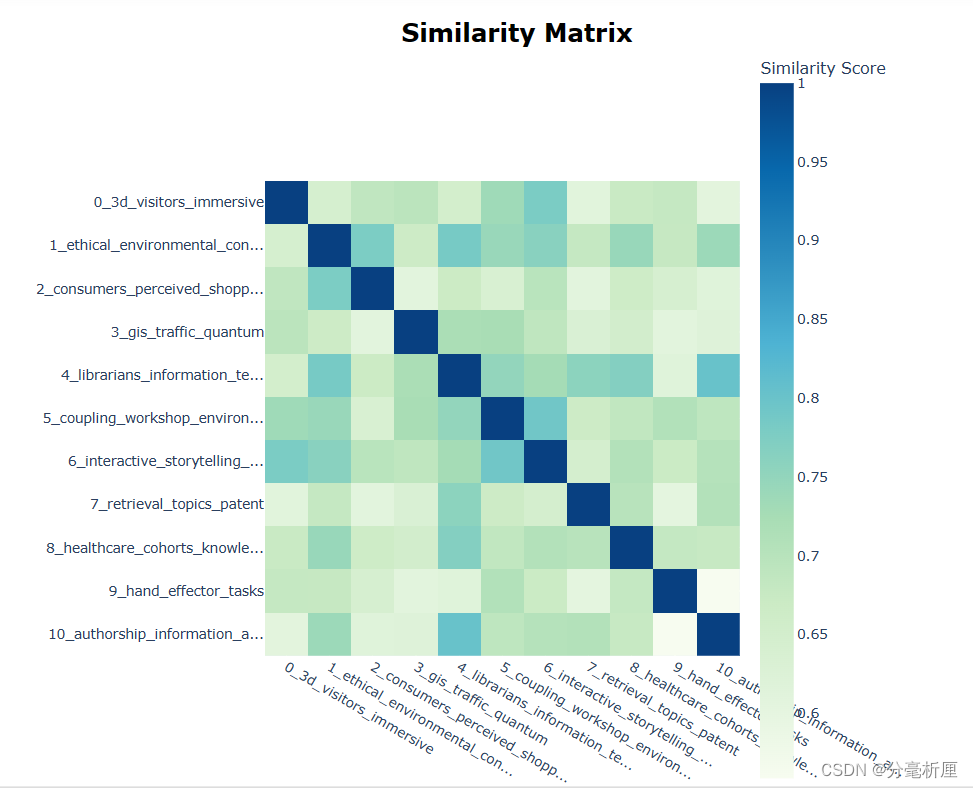 3.5 隐含主题主题分布图
3.5 隐含主题主题分布图
topic_model.visualize_topics()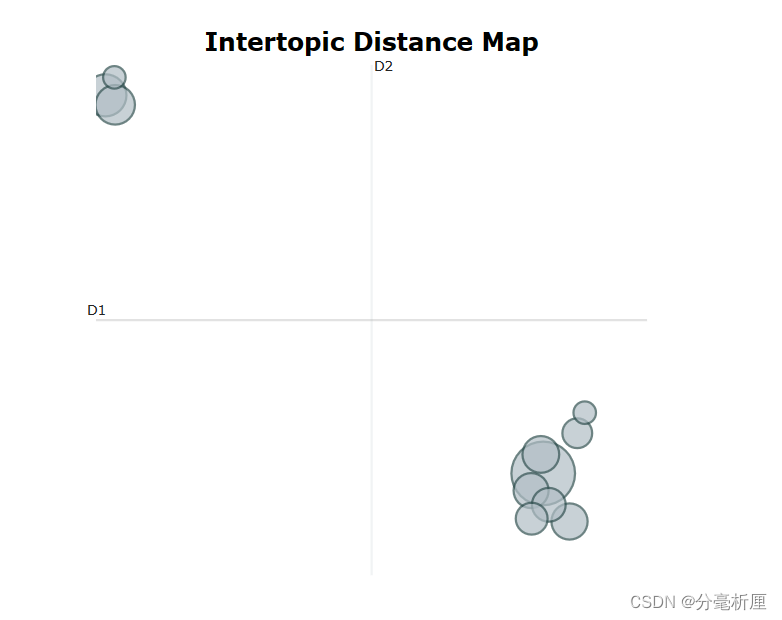
结语
BERTopic是一种强大的主题分析工具,它能够自动识别文本数据中的主题,而无需预先定义主题数。通过结合BERT的语义表示和传统主题建模技术,BERTopic为主题分析任务提供了一个高效而精确的解决方案。希望这篇博客能够帮助您入门BERTopic,并在NLP实战中发挥其潜力。如果您想深入了解BERTopic,不妨尝试在自己的数据集上应用它,以发掘更多有趣的主题!
参考资料
智能推荐
Python爬取B站TES VS FNC 八强赛弹幕,全网最具深度的三次握手、四次挥手讲解-程序员宅基地
文章浏览阅读451次,点赞23次,收藏17次。获得返回数据,可以利用正则匹配弹幕信息获取了弹幕信息保存到本地即可爬虫完整代码import rewith open(‘八强赛弹幕.txt’, mode=‘a’, encoding=‘utf-8’) as f:f.write(i)发现一共才 14行代码就搞定了~这只是爬取10月17日当天的弹幕数据,根据日期的变化可以改变日期参数,就可以达到爬取多页的数据了既然爬取了弹幕,就这样,还是有没有什么感觉,咱们可以对弹幕进行词云分析~词云图。
377-logger日志系统设计与实现_logger如何设计-程序员宅基地
文章浏览阅读652次,点赞2次,收藏2次。logger日志系统的设计图中画圆圈的是我们实现的mprpc框架,这个框架是给别人使用的,把本地的服务发布成远程的RPC服务,框架里最重要的两个成员就是RpcProvider和RpcChannel,他们在运行的过程中会有很多正常的输出信息和错误的信息,我们不可能都cout它们到屏幕上,因为运行时间长了,屏幕上输出的信息特别多,如果万一有什么问题,我们也不好定位,真正用起来的话不方便。所以,一般出问题,我们最直接的方式就是看日志!!!日志可以记录正常软件运行过程中出现的信息和错误的信息,当我们定位问题,_logger如何设计
MongoDB详解(有这一篇就够了)-程序员宅基地
文章浏览阅读4.1k次,点赞6次,收藏23次。MongoDB 是由C++语言编写的,基于分布式文件存储的数据库,是一个介于关系数据库和非关系数据库之间的产品,是最接近于关系型数据库的NoSQL数据库。MongoDB 旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于JSON对象。字段值可以包含其他文档,数组及文档数组类似于MongoDB优点:数据处理能力强,内存级数据库,查询速度快,扩展性强,只是不支持事务。_mongodb
两种内存池管理方法对比_非固定大小的内存池-程序员宅基地
文章浏览阅读1.9k次,点赞4次,收藏11次。目录一、问题背景二、两种内存池管理2.1 固定大小内存块分配(参考正点原子STM32F4 malloc.c)2.1.1 初始化2.1.3释放原理2.2 可变大小内存块分配(参考WSF BLE协议栈buffer management)2.2.1 初始化2.2.2 分配原理2.2.3 释放原理三、总结和对比一、问题背景最近在调试ambiq apollo..._非固定大小的内存池
MPEG TS流简介-程序员宅基地
文章浏览阅读3.1k次。TS简介MPEG-TS(Transport stream)即Mpeg传输流定义于ITU-T Rec. H.222.0和ISO 13818-1标准中,属于MPEG2的系统层。MPEG2-TS面向的传输介质是网络和卫星等可靠性较低的传输介质,这一点与面向较可靠介质如DVD等的MPEG PS不同。1. TS数据包TS流由TS数据包即Transport stream packet组成。TS p...
Deepin wine QQ/微信中文显示为方块的原因之一_wine 字体方块-程序员宅基地
文章浏览阅读984次。问题原因:目录下~/.deepinwine,查找乱码的应用Deepin-QQ、Deepin-WeChat,相同路径/drive_c/windows/Fonts下查看是否有字体,笔者发现没有任何字体,这就是原因所致,wine程序会在此处寻找字体,而不能直接利用linux系统的字体解决方法:把/usr/share/fonts/Fonts_Win下字体复制到这里,使wine应用程序能找到至少一种fallback字体,也可以在别的地方的fonts问价夹下,拷贝.ttf字体文件到这里..._wine 字体方块
随便推点
操作系统文件系统实验报告16281027_i/o磁盘实验报告-程序员宅基地
文章浏览阅读3.6k次。实验五 文件系统1 实验简介本实验要求在模拟的I/O系统之上开发一个简单的文件系统。用户通过create, open, read等命令与文件系统交互。文件系统把磁盘视为顺序编号的逻辑块序列,逻辑块的编号为0至L − 1。2 I/O系统实际物理磁盘的结构是多维的:有柱面、磁头、扇区等概念。I/O系统的任务是隐藏磁盘的结构细节,把磁盘以逻辑块的面目呈现给文件系统。逻辑块顺序编号,编号取值范围为..._i/o磁盘实验报告
dwd明细粒度事实层设计_dwd层如何设计-程序员宅基地
文章浏览阅读1.8k次。目录1-数仓dwd事实层介绍2-数仓dwd层事实表设计原则3-数仓dwd层事实表设计规范4-建表示例1-数仓dwd事实层介绍明细粒度事实层以业务过程驱动建模,基于每个具体的业务过程特点,构建最细粒度的明细层事实表。您可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,即宽表化处理。公共汇总粒度事实层(DWS)和明细粒度事实层(DWD)的事实表作为数据仓库维度建模的核心,需紧绕业务过程来设计。通过获取描述业务过程的度量来描述业务过程,包括引用的维度和与业务过程有关的度量。度量通常为_dwd层如何设计
Ambari 2.7.3.0 安装部署 hadoop 3.1.0.0 集群视频完整版_ambari2.7.3 hadoop 部署-程序员宅基地
文章浏览阅读1.5k次。一、前言很多小伙伴也都知道,最近一直在做 Ambari 集成自定义服务的教学笔记和视频。之前在准备 Ambari 环境的时候,考虑到有朋友会在 Ambari 安装部署时遇到问题,所以贴心的我呢,就在搭建 Ambari 环境的时候,把这个视频录制好了,总共时长共 87 分钟,将近1个半小时,附带移除 SmartSense 服务及 FAQ 。也提前介绍一下搭建好的 Ambari 相关版本信息:..._ambari2.7.3 hadoop 部署
使用R语言保存CSV文件_r软件保存为csv文件-程序员宅基地
文章浏览阅读881次。本文介绍了如何使用R语言保存CSV文件。我们使用write.csv函数将数据框保存为CSV格式。您只需提供要保存的数据对象和文件路径,即可轻松创建CSV文件。CSV文件是一种通用的数据交换格式,在数据分析和数据处理中广泛使用。希望本文对您有所帮助,祝您在R语言中保存CSV文件时顺利进行数据处理和分析!_r软件保存为csv文件
VR技术赋能数字经济发展新机遇,加快构建双循环新发展格局_vr商城建设对区域经济-程序员宅基地
文章浏览阅读498次。当下,数字化浪潮正重塑世界经济发展格局,数字经济正在成为全球经济可持续增长新引擎。我国超大规模的市场经济优势为数字经济发展提供了广阔而丰富的应用场景,也成为推动传统产业升级改造、加快”构建国内国际双循环相互促进的新发展格局“的重要引擎。据国家统计局数据显示:2020年第一季度,我国GDP呈现出6.8%的负增长态势。今年1月份至5月份,与互联网相关的新业态、新模式却继续保持逆势增长。全国实物商品网上零售额同比增长11.5%;实物商品网上零售额占社会消费品零售总额比重为24.3%,比去年同期提高5.4个百分点_vr商城建设对区域经济
HCS12X–数据定义(如何在CodeWarrior中将数据定义到分页区)_codewarrior数组如何定义-程序员宅基地
文章浏览阅读384次。由于在暑假匆忙接收的嵌入式项目中需要使用特别大的数组,非分页RAM的内存不够用了,没办法,硬着头皮尝试使用分页RAM,但是完全没有单片机的基础,导致极其的困难。之前写程序都是按照纯软件的思维,主要考虑架构,不会考虑到每个变量具体存在哪个物理地址这么底层的问题,结果被飞思卡尔这分页地址、prm文件什么的搞得一头雾水,而网上的资料又少,讲的又大同小异的笼统,最后写出来的程序因为这分页地址的原因存在各种_codewarrior数组如何定义