C11 lambda、线程库、包装器-程序员宅基地
目录
一、lambda表达式
1、产生背景
在C++98标准中,对数组或容器内的元素进行排序时,常常使用std::sort函数。比如,对于整型数组的升序排序,可以直接调用std::sort;若需降序排序,则需指定一个比较函数,如greater<int>。而对于自定义类型的排序,用户需要自行定义比较规则。
比如下面的代码:假设有一个Goods结构体代表商品信息,包括名称、价格和评价。要按价格进行升序或降序排序,需要分别创建两个比较函数对象结构体——ComparePriceLess和ComparePriceGreater,它们分别实现了小于和大于的价格比较操作。
#include <algorithm>
#include <string>
struct Goods {
std::string _name; // 商品名称
double _price; // 商品价格
int _evaluate; // 商品评价
Goods(const char* str, double price, int evaluate)
: _name(str), _price(price), _evaluate(evaluate) {}
};
// 按照价格升序比较的函数对象
struct ComparePriceLess {
bool operator()(const Goods& gl, const Goods& gr) {
return gl._price < gr._price;
}
};
// 按照价格降序比较的函数对象
struct ComparePriceGreater {
bool operator()(const Goods& gl, const Goods& gr) {
return gl._price > gr._price;
}
};
int main() {
std::vector<Goods> v = { {"苹果", 2.1, 5}, {"香蕉", 3.0, 4}, {"橙子", 2.2, 3}, {"菠萝", 1.5, 4} };
// 按价格升序排序
std::sort(v.begin(), v.end(), ComparePriceLess());
// 按价格降序排序
std::sort(v.begin(), v.end(), ComparePriceGreater());
return 0;
}然而,在实际开发中,这种做法有时显得较为繁琐,尤其是当频繁需要为不同的排序逻辑编写多个比较函数对象时,这无疑增加了编程负担。鉴于此,C++11引入了lambda表达式,它允许开发者更简洁地定义临时、匿名的函数对象,极大地简化了此类问题的处理方式。通过lambda表达式,无需为每个排序需求单独创建并命名一个类,而是可以直接在调用std::sort的地方写出相应的比较逻辑。
2、使用方法
Lambda表达式是C++11引入的一种简洁定义匿名函数的机制,其基本语法格式如下:
[capture-list] (parameters) mutable -> return-type { statement; }参数介绍:
-
[capture-list]:捕捉列表,位于lambda函数的起始位置,用于捕获上下文中的变量供lambda内部使用。若无需要捕获外部变量,可以留空(即写作[]),此时编译器会识别出后续代码为lambda表达式。-
值传递捕获:
[var]:单个变量按照值复制方式进行捕获,这意味着lambda内部将会获得外部变量的一个副本,对lambda内部副本的修改不会影响外部原始变量。[=]:默认值传递方式捕获所有父作用域中的可见变量(除了volatile限定的局部变量)。这意味着lambda创建时会将所有需要的变量复制一份到其封闭环境中。
-
引用传递捕获:
[&var]:单个变量通过引用方式捕获,这样lambda可以直接访问并修改外部变量的原始值。[&]:引用传递方式捕获所有父作用域中的可见变量,同样包括this指针(如果在类作用域内),此时lambda可以直接更改外部变量。
-
特殊捕获:
[this]:专门用来值传递方式捕获当前类作用域内的this指针,确保lambda可以访问当前对象的成员。 -
组合捕获:可以混合使用不同的捕获方式,例如
[=, &a, &b]表示大部分变量按值捕获,但变量a和b按引用捕获。
-
-
(parameters):参数列表,与常规函数参数列表的写法相同。如果没有参数传递,可以省略括号及其中内容。 -
mutable:关键字表明lambda函数并非默认的常量函数,取消其常量性。需要注意的是,若使用了mutable关键字,即使无参数传递,参数列表的括号也不能省略。 -
-> return-type:返回类型声明,采用追踪返回类型的形式声明函数的返回类型。若lambda函数无返回值或者返回类型可由编译器自动推断,则这部分可以省略。int main() { auto add = [](int x, int y) {return x + y; }; cout << [](int x, int y)->int {return x + y; }(1, 3) << endl; cout << add(1, 3) << endl; return 0; }
-
{statement}:函数体,包含了lambda函数的具体实现逻辑。在此区域内,不仅可以使用参数,还能引用所有被捕获的外部变量。
注意事项:
- 在lambda函数定义中,参数列表和返回值类型都可以选择性省略,但捕捉列表和函数体不能为空。因此,C++11中最简单的lambda函数形式为
[]{};,不过这样的lambda函数不具备实际功能。 - 重复捕获:不能同时以不同方式捕获同一个变量,比如
[=, a]是非法的,因为=已经包含了a的值捕获。 - 块作用域外的lambda:如果lambda不在任何函数或者块作用域之内(例如在全局作用域中定义),则它的捕获列表必须为空。
- lambda不可赋值:尽管lambda表达式的结果是一个可调用对象,但这些对象本身不能互相赋值,即使它们看起来功能相同,因为每个lambda都有独立的封闭环境和可能不同的捕获状态。
示例:
int main()
{
// 最简单的lambda表达式,不接受任何参数且不执行任何操作
[]{};
// 省略参数列表和显式返回值类型,编译器自动推断返回值类型为int
int a = 3, b = 4;
[=]{return a + 3; }; // 此处未被调用,仅展示lambda表达式定义
// 省略返回值类型声明,编译器根据内部逻辑推断返回值类型
// 此lambda捕获外部变量a和b(按值捕获),并接受一个int型参数c
auto fun1 = [&](int c){b = a + c; };
fun1(10);
cout << a << " " << b << endl;
// 完整的lambda表达式,显式指定返回值类型为int
// 按值捕获外部变量a,按引用捕获外部变量b,并接受一个int型参数c
auto fun2 = [=, &b](int c)->int{ return b += a + c; };
cout << fun2(10) << endl;
// 按值捕获外部变量x,由于使用了mutable关键字,可以在lambda体内修改x的值
int x = 10;
auto add_x = [x](int a) mutable { x *= 2; return a + x; };
cout << add_x(10) << endl;
return 0;
}从以上示例中我们可以看出,lambda表达式相当于定义了一个无名函数对象,它不能直接调用。但可以通过`auto`关键字将其赋值给一个变量,从而实现间接调用。这种特性使得lambda表达式在处理一些需要临时定义函数场景时尤为方便。
3、使用lambda解决排序问题
struct Goods
{
string _name; // 名字
double _price; // 价格
int _evaluate; // 评价
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
{}
};
// 按照价格升序比较的函数对象
struct ComparePriceLess {
bool operator()(const Goods& gl, const Goods& gr) {
return gl._price < gr._price;
}
};
// 按照价格降序比较的函数对象
struct ComparePriceGreater {
bool operator()(const Goods& gl, const Goods& gr) {
return gl._price > gr._price;
}
};
void Print(const vector<Goods>& v)
{
for (const auto& r : v)
{
cout << "商品名称:" << r._name << ", 价格:" << r._price << ", 评价:" << r._evaluate << endl;
}
}
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } };
auto priceLess = [](const Goods& g1, const Goods& g2)->bool {return g1._price < g2._price; };
sort(v.begin(), v.end(), priceLess);
Print(v); cout << endl;
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)->bool {
return g1._price > g2._price;
});
Print(v); cout << endl;
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)->bool {
return g1._evaluate < g2._evaluate;
});
Print(v); cout << endl;
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)->bool {
return g1._evaluate > g2._evaluate;
});
Print(v);
}-
为了在C++98或C++03中按照价格升序或降序对
Goods对象进行排序,我们定义了两个结构体ComparePriceLess和ComparePriceGreater,分别重载了operator(),作为仿函数(函数对象)用于std::sort函数的第三个参数,实现自定义排序逻辑。 -
然后使用lambda表达式替代传统的结构体比较函数。例如,
auto priceLess = [](const Goods& g1, const Goods& g2)->bool {return g1._price < g2._price; };,这个lambda表达式接收两个Goods对象作为参数,并返回一个布尔值,表示第一个商品的价格是否小于第二个商品的价格。这种方式下,我们不再需要显式定义独立的结构体来进行比较。 -
接下来,分别使用lambda表达式对商品列表按照价格升序、价格降序、评价升序、评价降序进行排序,并在排序后调用
Print函数显示排序结果。
通过C++11引入的lambda表达式大大简化了自定义排序逻辑的实现,使得在调用std::sort等算法时,可以直接在代码执行的位置定义临时、简洁的比较函数,避免了为不同排序逻辑创建大量相似结构体的麻烦。
商品名称:菠萝, 价格:1.5, 评价:4
商品名称:苹果, 价格:2.1, 评价:5
商品名称:橙子, 价格:2.2, 评价:3
商品名称:香蕉, 价格:3, 评价:4
商品名称:香蕉, 价格:3, 评价:4
商品名称:橙子, 价格:2.2, 评价:3
商品名称:苹果, 价格:2.1, 评价:5
商品名称:菠萝, 价格:1.5, 评价:4
商品名称:橙子, 价格:2.2, 评价:3
商品名称:香蕉, 价格:3, 评价:4
商品名称:菠萝, 价格:1.5, 评价:4
商品名称:苹果, 价格:2.1, 评价:5
商品名称:苹果, 价格:2.1, 评价:5
商品名称:香蕉, 价格:3, 评价:4
商品名称:菠萝, 价格:1.5, 评价:4
商品名称:橙子, 价格:2.2, 评价:34、组合捕捉
混合捕捉 (func1):
auto func1 = [&x, y]() {...};这个Lambda表达式使用了混合捕捉。其中,x通过引用方式进行捕捉,这意味着在Lambda体内部可以直接修改外部变量x的值。而y则是通过值方式进行捕捉,即在Lambda内部得到的是y的一个副本,对副本的修改不会影响到外部的y。
全部引用捕捉 (func2):
auto func2 = [&]() {...};这个Lambda表达式通过引用方式捕捉所有在其外部作用域可见的变量。这意味着在Lambda体内部可以修改所有捕获到的外部变量的值。
全部传值捕捉 (func3):
auto func3 = [=]() {...};这个Lambda表达式通过值方式捕捉所有在其外部作用域可见的变量。这意味着在Lambda体内部得到的是捕获到的所有变量的副本,对这些副本的修改不会影响到外部的原始变量。
全部引用捕捉,特定变量传值捕捉 (func4):
auto func4 = [&, x]() {...};这个Lambda表达式大部分变量通过引用捕捉,但对x这个特定变量采用了值捕捉。这就意味着除了x以外的所有其他外部变量在Lambda体内部可以直接修改,而x则是在Lambda内部得到的一个副本,对它的修改不影响外部的x。
5、捕获外部变量的应用
正常交换:
int main()
{
int a = 9, b = 0;
auto swap1 = [](int& A, int& B) {
int tmp = A;
A = B;
B = tmp;
};
swap1(a, b);
cout << a << " " << b << endl;
return 0;
}定义了一个Lambda表达式swap1,它接收两个int类型的引用作为参数,然后在Lambda函数体内部交换这两个参数的值。在这里,直接传递了外部变量a和b的引用给swap1,成功交换了a和b的值。
未捕获外部变量的尝试(编译错误)
int main()
{
// 使用Lambda表达式试图交换外部变量,但未捕获外部变量,导致编译错误
int x = 9, y = 0;
auto swap2 = []() {
int tmp = x;
x = y;
y = tmp;
};
swap2();
cout << x << " " << y << endl;
return 0;
}尝试定义一个Lambda表达式swap2,它没有捕获任何外部变量,所以在Lambda函数体内部直接使用x和y会导致编译错误,因为它们在Lambda作用域内未被声明。
传值捕获尝试(编译错误)
int main()
{
// 传值捕捉也会报错,因为交换的是捕获的局部变量副本,而非外部变量本身
int c = 9, d = 0;
auto swap3 = [c, d](){
int tmp = c;
c = d;
d = tmp;
};
swap3();
cout << c << " " << d << endl;
return 0;
} 定义了一个Lambda表达式
定义了一个Lambda表达式swap3,它通过值捕获了外部变量c和d。在Lambda函数体内部交换的是被捕获的局部变量副本,而不是外部变量本身,因此即便执行swap3,外部变量c和d的值也不会改变。
使用mutable关键字的传值捕获
int main()
{
// 使用mutable关键字虽然能消除编译错误,但因传值捕获,依旧交换的是外部变量的副本
int e = 9, f = 0;
auto swap4 = [e, f]() mutable{
int tmp = e;
e = f;
f = tmp;
};
swap4();
cout << e << " " << f << endl;
return 0;
}使用mutable关键字定义了一个Lambda表达式swap4,即使如此,由于仍然是值捕获,所以在Lambda内部交换的是外部变量的副本,即使Lambda函数体中可以修改捕获的变量(mutable特性),但外部变量e和f的值仍然不会改变。
引用捕获
int main()
{
// 引用捕捉,正确交换外部变量的值
int g = 9, h = 0;
auto swap5 = [&g, &h]() {
int tmp = g;
g = h;
h = tmp;
};
swap5();
cout << g << " " << h << endl;
return 0;
}定义了一个Lambda表达式swap5,它通过引用捕获了外部变量g和h。在Lambda函数体内部,通过引用交换了g和h的值,由于是引用捕获,所以这次成功地改变了外部变量g和h的值。
6、lambda与函数对象
函数对象,又称为仿函数,即可以想函数一样使用的对象,就是在类中重载了operator()运算符的 类对象。
class Rate
{
public:
Rate(double rate) : _rate(rate)
{}
double operator()(double money, int year)
{
return money * _rate * year;
}
private:
double _rate;
};
int main()
{
// 函数对象
double rate = 0.49;
Rate r1(rate);
r1(10000, 2);
// lambda
auto r2 = [=](double monty, int year)->double {return monty * rate * year; };
r2(10000, 2);
return 0;
} 234: // 函数对象
235: double rate = 0.49;
00007FF652FA2A1D movsd xmm0,mmword ptr [__real@3fdf5c28f5c28f5c (07FF652FABC10h)]
00007FF652FA2A25 movsd mmword ptr [rate],xmm0
236: Rate r1(rate);
00007FF652FA2A2A movsd xmm1,mmword ptr [rate]
00007FF652FA2A2F lea rcx,[r1]
00007FF652FA2A33 call Rate::Rate (07FF652FA149Ch)
237: r1(10000, 2);
00007FF652FA2A38 mov r8d,2
00007FF652FA2A3E movsd xmm1,mmword ptr [__real@40c3880000000000 (07FF652FABC18h)]
00007FF652FA2A46 lea rcx,[r1]
00007FF652FA2A4A call Rate::operator() (07FF652FA14A1h)
238:
239: // lambda
240: auto r2 = [=](double monty, int year)->double {return monty * rate * year; };
00007FF652FA2A4F lea rdx,[rate]
00007FF652FA2A53 lea rcx,[r2]
00007FF652FA2A57 call `main'::`2'::<lambda_1>::<lambda_1> (07FF652FA2440h)
241: r2(10000, 2);
00007FF652FA2A5C mov r8d,2
00007FF652FA2A62 movsd xmm1,mmword ptr [__real@40c3880000000000 (07FF652FABC18h)]
00007FF652FA2A6A lea rcx,[r2]
00007FF652FA2A6E call `main'::`2'::<lambda_1>::operator() (07FF652FA2980h)从汇编代码可以看出,无论是创建函数对象还是lambda表达式,编译器都进行了类似的处理:
-
对于函数对象
Rate:- 首先初始化外部变量
rate的值。 - 然后调用构造函数
Rate::Rate创建Rate类型的对象r1,并将rate的值传递进去。 - 调用
r1的operator()函数进行计算。
- 首先初始化外部变量
-
对于lambda表达式:
- 同样初始化外部变量
rate的值。 - 编译器为lambda表达式生成了一个闭包类,并调用其构造函数创建了闭包对象
r2,并将rate的值捕获到闭包对象中。 - 调用
r2的operator()函数进行计算。
- 同样初始化外部变量
尽管底层细节不同,但实际在底层编译器对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的,即:如果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()。
二、线程库
1、thread类
在C++11标准之前,处理多线程编程时通常需要依赖操作系统提供的特定接口,例如Windows平台上的CreateThread API与Linux系统中的pthread_create函数等。这样的做法导致跨平台的C++代码在处理多线程问题时可移植性不强,增加了开发复杂性和维护成本。
C++11标准的一大革新之处在于引入了标准化的线程支持,从而简化了并行编程任务,允许开发者在编写多线程应用时无需再倚赖第三方库。同时,为了更好地管理和同步线程间的操作,C++11标准还引入了原子操作类(atomic classes)的概念,增强了对低级别并发控制的支持。
在C++11标准库中,通过包含 <thread> 头文件,程序员可以利用std::thread类来进行线程的创建与管理。以下是std::thread类的一些核心成员函数及其功能:
-
thread() 构造函数
- 默认构造函数:创建一个线程对象而不启动任何线程,此时线程对象未与任何线程函数关联。
- 带参数构造函数:创建一个线程对象,并立即关联指定的线程函数
fn,同时将args1, args2, ...作为线程函数的参数传递。线程在构造完成后随即开始执行。
-
get_id() 成员函数 返回当前线程对象所代表的线程ID,每个线程都有唯一的标识符。
-
joinable() 成员函数 判断线程对象是否仍然代表着一个可加入(join)的线程,即该线程是否仍在执行。如果线程仍在运行,则joinable()返回true。
-
join() 成员函数 当调用线程对象的join()方法时,主线程会阻塞直到目标线程执行完毕。一旦目标线程结束,join()函数返回,主线程得以继续执行。
-
detach() 成员函数 调用detach()方法后,线程对象与其代表的线程分离。分离后的线程成为一个后台线程,不再受原线程对象的生命周期约束。这意味着即使主线程结束,被detach的子线程仍将继续独立运行,其执行状态与主线程不再直接相关联。主线程不再负责等待或管理这个分离线程的终止。
使用方法
1、线程是一种操作系统级别的概念,它允许在同一进程内并发执行多个控制流。在C++11标准库中,std::thread对象是对操作系统线程的一种抽象和封装,它可以关联并控制一个线程,同时也提供了获取线程状态的方法。
2、当仅创建一个std::thread对象而不指定线程函数时,该对象实际上并未关联任何实际的线程执行实体。
#include <iostream>
#include <thread>
int main()
{
std::thread t1; // 创建一个空线程对象,未关联任何线程函数
std::cout << "线程ID:" << t1.get_id() << std::endl; // 输出线程ID
// 此处由于t1未关联线程函数,所以get_id()可能返回一个无效或默认的线程ID
return 0;
}std::thread::get_id()函数用于获取与线程对象关联的线程唯一标识符,其返回类型为std::thread::id。虽然不同编译器和操作系统下的实现细节各异,但在Visual Studio(VS)环境下,std::thread::id类型背后可能会封装一个名为_Thrd_imp_t的结构体。这个结构体在VS中定义如下:
// VS下的内部实现细节(简化版)
typedef struct _Thrd_imp_t
{
void *_Hnd; // 在Win32环境下,此成员保存着操作系统提供的线程句柄
unsigned int _Id; // 这里可能是线程的一个整数ID或其他标识信息
} _Thrd_imp_t;需要注意的是,上述_Thrd_imp_t结构体是VS内部对线程标识符的具体实现细节,实际编程过程中并不直接接触此类底层结构,而是通过std::thread::id这一高层抽象接口来获取和比较线程ID。
3、在C++11中,当我们创建一个std::thread对象并为其关联一个线程函数时,该线程就会被启 动,并与主线程同时运行。线程函数可以通过三种形式提供:
-
函数指针:直接指定一个全局或类静态成员函数作为线程执行体。
void ThreadFunc(int a); thread t1(ThreadFunc, 10); -
Lambda表达式:利用C++11的Lambda特性,创建一个匿名函数作为线程执行体。
thread t2([]{cout << "Thread2" << endl; }); -
函数对象:通过重载
operator()的类对象(函数对象)作为线程执行体。class TF { public: void operator()() { cout << "Thread3" << endl; } }; TF tf; thread t3(tf);
4、std::thread类遵循不可拷贝原则,即禁止拷贝构造和赋值操作,因为拷贝线程对象会导致逻辑混乱,无法确定应该向哪个线程发送指令。然而,std::thread支持移动构造和移动赋值,这意味着可以将一个线程对象的所有权及与其关联的线程状态安全地转移到另一个线程对象,而不会影响原有线程的执行。
5、利用joinable()函数可以检测一个std::thread对象是否有效或仍处于活动状态。若满足以下任一条件,则表明该线程对象无效:
-
使用无参构造函数创建的线程对象,因为它尚未关联任何线程函数。
#include <iostream> #include <thread> int main() { std::thread t1; // 使用无参构造函数创建线程对象,未关联任何线程函数 if (t1.joinable()) { std::cout << "线程t1有效且活动" << std::endl; } else { std::cout << "线程t1无效或非活动" << std::endl; // 实际输出将是"线程t1无效或非活动" } return 0; }在这个例子中,
t1是一个使用无参构造函数创建的线程对象,它并没有关联任何线程函数,因此t1.joinable()会返回false,表示线程对象无效或非活动。 -
已经通过移动构造或移动赋值将线程对象的状态转移给了其他线程对象,原始线程对象不再拥有任何关联的线程状态。
#include <iostream> #include <thread> void thread_func() { std::cout << "线程正在运行..." << std::endl; } int main() { std::thread t1(thread_func); // 创建并启动一个线程 std::thread t2(std::move(t1)); // 使用移动构造将线程状态转移给t2 if (t1.joinable()) { std::cout << "线程t1有效且活动" << std::endl; } else { std::cout << "线程t1无效或非活动" << std::endl; // 实际输出将是"线程t1无效或非活动" } t2.join(); // 确保t2关联的线程正常结束 return 0; }在这个例子中,
t1原来关联了一个线程函数并启动了线程,但通过移动构造将线程状态转移到了t2,此时t1就变得无效了,t1.joinable()将返回false。
-
线程已经调用了
join()函数完成执行并等待完毕,或者调用了detach()函数使其与线程对象分离,这两种情况下,线程虽仍在运行(detach后),但已与原线程对象失去了关联,故原线程对象被视为无效。#include <iostream> #include <thread> void thread_func() { std::cout << "线程正在运行..." << std::endl; std::this_thread::sleep_for(std::chrono::seconds(1)); // 模拟线程执行耗时操作 } int main() { std::thread t1(thread_func); t1.join(); // 等待线程执行完毕 if (t1.joinable()) { std::cout << "线程t1有效且活动" << std::endl; } else { std::cout << "线程t1无效或非活动" << std::endl; // 实际输出将是"线程t1无效或非活动" } // 或者 // t1.detach(); // 使线程与线程对象分离,若在此处detach后,t1.joinable()也会返回false return 0; }在这个例子中,线程
t1关联了线程函数并启动了线程,但在调用t1.join()后,主线程等待t1执行完毕,此后t1与线程失去关联,所以t1.joinable()将返回false,表示线程对象无效。如果在这里调用t1.detach(),也会有同样的效果。
2、线程函数参数
- 在C++中,当你创建一个线程并将一个函数作为线程入口点时,如果你直接传递引用类型的参数,虽然在函数声明中参数是引用类型,但实际上在线程创建过程中,这个引用参数会被当作值拷贝到线程的栈空间中。这意味着,即便在新的线程中修改了引用参数,也不会影响到主线程或其他线程中原始变量的值。
#include <iostream>
#include <thread>
#include <utility>
// 普通函数,接收引用类型参数
void ThreadFunc1(int& x)
{
x += 10;
}
// 普通函数,接收指针类型参数
void ThreadFunc2(int* x)
{
(*x) += 10;
}
// 假设有一个类,其成员函数需要修改类成员变量
class MyClass
{
public:
int member_var = 10;
void MemberThreadFunc()
{
member_var += 10;
}
};
int main()
{
int a = 10;
// 由于默认是值拷贝,所以此处修改不会影响主线程中的a
std::thread t1(ThreadFunc1, a);
t1.join();
std::cout << "After t1 join, a = " << a << std::endl;
// 使用std::ref传递引用,此时线程中的修改会影响主线程中的a
std::thread t2(ThreadFunc1, std::ref(a));
t2.join();
std::cout << "After t2 join, a = " << a << std::endl;
// 传递指针,线程中的修改会影响主线程中的a
std::thread t3(ThreadFunc2, &a);
t3.join();
std::cout << "After t3 join, a = " << a << std::endl;
// 类成员函数作为线程函数
MyClass myObj;
std::thread t4(&MyClass::MemberThreadFunc, &myObj);
t4.join();
std::cout << "After t4 join, myObj.member_var = " << myObj.member_var << std::endl;
return 0;
}在给出的代码示例中:
-
ThreadFunc1(int& x)函数接受一个引用类型的参数,当创建线程t1并调用ThreadFunc1(a)时,实际上是将a的值拷贝到了线程t1的栈空间,所以在t1线程中对x的修改不会影响到主线程中的a。 -
若要使线程中的修改反映到外部实参,可以使用
std::ref()函数,它创建一个std::reference_wrapper对象,这个对象可以保持对原始变量的引用。所以在创建线程t2时,使用std::ref(a),此时t2线程中的修改将影响到主线程中的a。 -
ThreadFunc2(int* x)函数接受一个指针类型的参数,当创建线程t3并调用ThreadFunc2(&a)时,传递的是a的地址,所以在t3线程中对x指向的内容的修改同样会影响主线程中的a。 -
当你需要将类成员函数作为线程函数时,确实需要传递
this指针,因为成员函数默认隐含了一个指向对象本身的this参数。例如,如果有类MyClass及其成员函数void MyClass::ThreadFunc(),创建线程时应写作:MyClass obj; thread t(obj.ThreadFunc, &obj);通过传递
this指针(即对象的地址),线程可以访问并修改类成员函数所作用的对象的成员变量。
3、mutex的种类
std::mutex
在C++11标准库中,mutex家族共包含了四种类型的互斥量,旨在提供线程同步的基础工具。其中最基本的互斥量类型是std::mutex。此类型的互斥量实例不具备拷贝或移动的能力,其关键的三个操作方法如下:
-
lock()函数:用于锁定互斥量。当调用此方法的线程成功获取互斥量时,该线程将独占互斥量直至调用unlock()为止。在此期间,其他试图锁定该互斥量的线程将会被阻塞,等待互斥量解锁。- 若互斥量当前未被任何线程锁定,调用线程将成功获取并锁定互斥量。
- 若互斥量已被其他线程锁定,调用线程将进入阻塞状态,等待互斥量解锁。
- 如果同一线程尝试再次锁定已经被其锁定的互斥量,会导致死锁情况的发生。
-
unlock()函数:用于解除互斥量锁定状态,释放当前线程对互斥量的所有权,从而使等待该互斥量的其他线程有机会获取锁。 -
try_lock()函数:尝试非阻塞地锁定互斥量。- 若互斥量当前未被任何线程锁定,调用线程将成功锁定互斥量,直到后续调用
unlock()为止。 - 若互斥量已被其他线程锁定,调用线程不会被阻塞,而是立即返回
false。 - 如果同一线程尝试锁定已经被其锁定的互斥量,同样会导致死锁。
- 若互斥量当前未被任何线程锁定,调用线程将成功锁定互斥量,直到后续调用
-
std::this_thread是C++11标准库中<thread>头文件中定义的一个命名空间,主要用于对当前执行线程进行操作和管理。它提供了一系列方便快捷的函数来控制当前线程的行为,包括但不限于以下几个常见函数:-
std::this_thread::get_id() 返回当前线程的唯一标识符(类型为
std::thread::id),可用于区分不同的线程实例。 -
std::this_thread::yield() 让当前线程主动放弃CPU时间片,促使操作系统调度器选择其他可执行的线程。调用此函数后,当前线程会回到就绪态,等待再次被调度。不过,具体的行为依赖于操作系统实现,不是所有平台都能保证调用yield后一定会切换到其他线程。
-
std::this_thread::sleep_for() 和 std::this_thread::sleep_until() 这两个函数用于让当前线程挂起一段时间。
sleep_for()按照指定的持续时间暂停线程,而sleep_until()则是直到指定的时间点才恢复线程执行。这两个函数接受std::chrono::duration或std::chrono::time_point作为参数,可以精确地控制线程的休眠时间。 -
这些函数主要是为了在多线程编程中提供对当前线程的基本控制手段,如调整线程优先级、控制线程执行顺序、同步线程执行等。通过使用
std::this_thread提供的功能,开发者能够更加有效地管理和协调多个并发执行的线程。
-
下面代码来测试一下串行和并行的时间消耗情况
#include <mutex>
mutex mtx;
int x = 0;
void Func1(int n)
{
//并行
for (int i = 0; i < n; i++)
{
mtx.lock();
++x;
mtx.unlock();
}
}
void Func2(int n)
{
//串行
mtx.lock();
for (int i = 0; i < n; i++)
{
++x;
}
mtx.unlock();
}
void test1()//并行测试
{
size_t begin = clock();
thread t1(Func1, 1000000);
thread t2(Func1, 1000000);
t1.join();
t2.join();
size_t end = clock();
cout << x << endl << end - begin << endl;
}
void test2()//串行测试
{
size_t begin = clock();
thread t1(Func2, 1000000);
thread t2(Func2, 1000000);
t1.join();
t2.join();
size_t end = clock();
cout << x << endl << end - begin << endl;
}
int main()
{
test1();
// 输出结果:
// 2000000
// 244
//test2();
// 2000000
// 4
return 0;
}
Func1函数模拟了并行操作的情况:循环1000000次,每次循环都将x的值加1,但每次操作前都会锁定互斥锁mtx,操作后解锁。这意味着当多个线程同时调用Func1时,同一时间只有一个线程能对x进行修改,以防止数据竞争(data race)。但由于锁定和解锁的操作频繁,且两个线程交替执行,实际运行结果可能会小于预期的2000000(理论上应该是2000000,因为有两个线程各执行了一百万次加1操作)。-
Func2函数模拟了串行操作的情况:首先锁定互斥锁mtx,然后在一个线程内循环1000000次对x进行加1操作,结束后才释放互斥锁。这样,在一个线程未完成对x的所有操作之前,另一个线程是无法访问和修改x的。因此,无论多少个线程调用Func2,x的最终值总是2000000,并且由于两个线程实际上是按照顺序执行的,所以总耗时应该接近单线程执行的时间。 -
test1函数创建了两个线程,分别调用Func1,并在所有线程完成后输出最终的x值和执行所花费的时间。 -
注释掉的
test2函数与test1类似,只是调用的是Func2。如果运行test2,则会发现虽然也是两个线程各自执行1000000次加1操作,但因为互斥锁的作用,它们实际上是以串行的方式执行的,所以总耗时比并行情况下要短得多。
通过对比test1和test2的结果,可以看出互斥锁在多线程编程中的作用:确保同一时间内只有一个线程可以访问共享资源(这里是变量x),从而避免数据竞争带来的问题。但在需要高效利用多核CPU进行并行计算的场景下,过度依赖互斥锁会导致性能下降。
std::recursive_mutex:
std::recursive_mutex是另一种互斥量类型,与std::mutex不同的是,它允许同一个线程对互斥量进行多次锁定,也就是说,同一个线程可以递归地获取互斥锁的所有权。- 当线程首次调用
lock()时,互斥量被锁定,再次调用lock()时,不会引起死锁,而是增加锁的计数。同样,必须调用相同次数的unlock()才能完全释放互斥锁,使得其他线程有机会获取锁。 - 其他特性方面,
std::recursive_mutex与std::mutex类似,均提供了基础的互斥访问控制功能。
示例:
#include <iostream>
#include <mutex>
// 假设有一个类,其中包含一些需要保护的共享数据
class SharedResource {
private:
int counter = 0;
std::recursive_mutex mtx; // 使用递归互斥量保护数据
public:
void incrementCounter(int n) {
// 在修改counter之前锁定互斥量
std::unique_lock<std::recursive_mutex> lock(mtx);
// 这个函数内部可能会调用另一个需要用到互斥量的方法
process(n);
// 假设我们递增计数器n次
for (int i = 0; i < n; ++i) {
++counter;
std::cout << "Incrementing counter from thread ID: " << std::this_thread::get_id() << std::endl;
}
// 当函数结束时,由于使用了RAII(Resource Acquisition Is Initialization)的unique_lock,
// 它会自动调用unlock(),但如果函数内部进行了多次lock(),这里的unlock()会匹配最后一次lock()
}
void process(int n) {
// 再次锁定互斥量,由于是递归锁,所以不会死锁
std::unique_lock<std::recursive_mutex> innerLock(mtx);
// 执行某些操作...
// ...
// 当process函数结束时,其内部的unique_lock也会自动调用unlock()
}
};
int main() {
SharedResource resource;
// 假设在一个线程中操作
std::thread t([&]() {
resource.incrementCounter(5);
});
t.join();
return 0;
}- 在这个例子中,
SharedResource类使用了一个std::recursive_mutex对象mtx来保护其成员变量counter。incrementCounter函数首先获取互斥锁,然后调用process函数,在这个过程中,由于process也需要对同一互斥量进行锁定,如果是普通互斥量(如std::mutex),这会导致死锁。然而,因为这里使用的是std::recursive_mutex,所以在process内部再次锁定互斥量是安全的,不会造成死锁。 - 当
incrementCounter函数递增计数器时,无论实际执行了多少次lock()操作(直接调用和间接通过process调用),只要在函数结束前所有的lock()都有相应的unlock()匹配,互斥量就会最终释放给其他线程使用。在这种情况下,由于我们使用了std::unique_lock,它会确保每次lock()都会有对应的unlock()自动调用,从而简化了递归锁定和解锁的管理。
std::timed_mutex:
-
std::timed_mutex是带有超时功能的互斥量,除了提供std::mutex的基础锁定和解锁功能外,还额外提供了两个尝试锁定并带超时控制的方法。 -
try_lock_for(const std::chrono::duration& rel_time): 这个函数尝试在给定的时间范围内获取互斥锁。如果在指定的时间段内互斥锁仍然被其他线程持有,函数将返回false,表示未能获取锁。反之,如果在这段时间内互斥锁被释放,则线程成功获取锁并返回true。 -
try_lock_until(const std::chrono::time_point& abs_time): 这个函数尝试在指定的绝对时间点前获取互斥锁。如果在指定的时间点之前互斥锁仍然被其他线程持有,函数将返回false。如果在这段时间内互斥锁被释放,则线程成功获取锁并返回true。
示例:
#include <iostream>
#include <thread>
#include <chrono>
#include <mutex>
std::timed_mutex mtx;
void threadFunction()
{
using namespace std::chrono_literals;
// 尝试在500毫秒内获取互斥锁
if (mtx.try_lock_for(500ms))
{
std::cout << "Thread acquired the lock." << std::endl;
// 执行临界区代码...
std::this_thread::sleep_for(1s); // 假设这里有耗时操作
mtx.unlock(); // 完成操作后释放锁
}
else
{
std::cout << "Thread failed to acquire the lock within 500 milliseconds." << std::endl;
}
}
int main()
{
mtx.lock(); // 主线程先锁定互斥锁
std::thread worker(threadFunction); // 创建一个新的工作线程
std::this_thread::sleep_for(1000ms); // 主线程等待1秒后释放锁
mtx.unlock();
worker.join(); // 等待工作线程完成
return 0;
}- 在这个例子中,主线程首先锁定了
std::timed_mutex,然后创建了一个新的工作线程。工作线程尝试在500毫秒内获取互斥锁(通过try_lock_for(500ms)实现)。由于主线程在1秒后才释放锁,所以在工作线程开始尝试获取锁的时候,互斥锁仍被主线程持有,因此工作线程会在尝试获取锁500毫秒后失败,并输出提示信息“Thread failed to acquire the lock within 500 milliseconds.”。 - 如果主线程提前释放了锁,那么工作线程将在500毫秒内成功获取到锁并执行临界区代码。
- 同样的,
try_lock_until()方法可以根据绝对时间点来尝试获取互斥锁,例如设置为从当前时间点开始算起的某个时间点之前尝试获取锁。
std::recursive_timed_mutex
std::recursive_timed_mutex 是 C++11 标准库中提供的一个互斥量(Mutex)类型,它结合了 std::recursive_mutex 和 std::timed_mutex 的特性,允许同一线程多次对互斥量进行加锁,并且提供了超时锁定的功能。
-
递归锁定:一个线程可以多次成功地对同一个
std::recursive_timed_mutex对象调用lock()或lock_shared()函数,只要每次锁定都是由最初获得锁的线程执行即可。这种互斥量允许递归锁定而不死锁,因为它会跟踪内部锁计数,当锁的次数与解锁次数相匹配时才真正释放互斥量。 -
超时锁定:此类型的互斥量还提供了带有超时限制的锁定函数,例如
try_lock_for()和try_lock_until()。这些函数允许线程尝试获取互斥锁,但会在指定的时间段过后自动放弃,如果在这段时间内无法获得锁,则函数会返回false,而不是无期限地阻塞线程。这对于避免线程因无法获取锁而无限期等待的情况非常有用。 -
std::recursive_timed_mutex m; if (m.try_lock_for(std::chrono::seconds(5))) { // 成功在5秒内获得锁 } else { // 未能在5秒内获得锁 }
总结起来,std::recursive_timed_mutex 主要用于需要在同一线程内进行递归同步,并希望在尝试锁定时具有超时控制能力的场景。通过它可以确保即使在递归调用或复杂逻辑中也能安全地管理共享资源访问,并能设定合理的等待时间以避免线程被永久性地卡住。
4、lock_guard与unique_lock
在多线程环境中,如果我们需要确保某个变量的并发访问安全,使用原子类型(atomic)是一种简单高效的方案,可以避免数据竞争和死锁问题。然而,当需要保护一段复杂的代码逻辑而非单个变量时,就需要借助锁机制来确保代码块的原子性。
例如,设想这样一个场景:两个线程分别对同一个变量number进行100次加一和减一操作,并且每次操作后立即输出number的值,最终期望number的值恢复为1。
#include <thread>
#include <mutex>
int number = 0;
mutex g_lock;
int ThreadProc1()
{
for (int i = 0; i < 100; i++)
{
g_lock.lock();
++number;
cout << "thread 1 :" << number << endl;
g_lock.unlock();
}
return 0;
}
int ThreadProc2()
{
for (int i = 0; i < 100; i++)
{
g_lock.lock();
--number;
cout << "thread 2 :" << number << endl;
g_lock.unlock();
}
return 0;
}
int main()
{
thread t1(ThreadProc1);
thread t2(ThreadProc2);
t1.join();
t2.join();
cout << "number:" << number << endl;
system("pause");
return 0;
}- 上面代码中直接使用
mutex进行加锁和解锁操作,这种做法有可能在异常处理或提前返回时忘记解锁,导致资源泄露或死锁等问题。
为了解决这些问题,C++11引入了基于Resource Acquisition Is Initialization (RAII)原则的智能锁包装类,如std::lock_guard和std::unique_lock。
- 在下面修改过的代码中,我们使用了
std::lock_guard,它会在构造时自动锁定互斥锁,并在析构时自动解锁,从而确保即使在代码块中抛出异常或通过return语句提前退出,互斥锁也能得到妥善释放,有效避免了死锁和资源泄露的风险。
#include <thread>
#include <mutex>
#include <iostream>
int number = 0;
std::mutex g_lock;
void ThreadProc1()
{
for (int i = 0; i < 100; i++)
{
std::lock_guard<std::mutex> guard(g_lock); // RAII方式自动管理锁的生命周期
++number;
std::cout << "thread 1 : " << number << std::endl;
}
}
void ThreadProc2()
{
for (int i = 0; i < 100; i++)
{
std::lock_guard<std::mutex> guard(g_lock); // RAII方式自动管理锁的生命周期
--number;
std::cout << "thread 2 : " << number << std::endl;
}
}
int main()
{
std::thread t1(ThreadProc1);
std::thread t2(ThreadProc2);
t1.join();
t2.join();
std::cout << "number: " << number << std::endl;
// system("pause"); // 通常不推荐在跨平台代码中使用,这里仅作演示目的
getchar(); // 更通用的暂停程序运行的方式
return 0;
}lock_guard
std::lock_guard是C++11标准库内定义的一个模板类,专为简便且安全地管理互斥量而设计。
- 在实际应用中,只需针对所需的互斥量实例化一个
lock_guard对象,通过调用其构造函数即可实现对互斥量的自动锁定。 - 当
lock_guard对象超出其作用域时,编译器会触发对象的析构过程,进而确保互斥量被正确地解锁。这种基于RAII的机制有力地保障了线程安全,降低了在手动管理锁时可能引入的死锁风险。
template<typename _Mutex>
class lock_guard
{
public:
// 默认构造函数,在构造时自动锁定传入的互斥量
explicit lock_guard(_Mutex& _Mtx) : _MyMutex(_Mtx) { _MyMutex.lock(); }
// 特殊构造函数,用于已锁定的互斥量,此处不会再次锁定
lock_guard(_Mutex& _Mtx, std::adopt_lock_t) : _MyMutex(_Mtx) {}
// 析构函数,在对象销毁时自动解锁互斥量
~lock_guard() noexcept { _MyMutex.unlock(); }
// 禁止拷贝构造和赋值操作,确保唯一性和线程安全
lock_guard(const lock_guard&) = delete;
lock_guard& operator=(const lock_guard&) = delete;
private:
// 保存互斥量引用,用于锁定和解锁操作
_Mutex& _MyMutex;
};lock_guard的缺陷:太单一,用户没有办法对该锁进行控制,因此C++11又提供了 unique_lock。
unique_lock
std::lock_guard在C++11中为互斥量管理提供了便利,但其功能相对有限,为了满足更多场景的需求,C++11标准库中还引入了std::unique_lock类模板。
- 如同
std::lock_guard一样,std::unique_lock同样采用了RAII原理来封装互斥量的锁定和解锁操作,确保资源在进入作用域时自动上锁,在离开作用域时自动解锁,有效防止了死锁问题。
示例:
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
std::mutex mtx;
void worker(int id) {
std::unique_lock<std::mutex> lock(mtx, std::defer_lock); // 创建unique_lock,但不立即锁定互斥量
std::this_thread::sleep_for(std::chrono::milliseconds(id * 100)); // 模拟延时操作
// 使用try_lock_for尝试在50毫秒内获取锁
if (lock.try_lock_for(std::chrono::milliseconds(50))) {
std::cout << "Worker " << id << " got the lock.\n";
// 执行临界区代码
std::cout << "Critical section for Worker " << id << ".\n";
// 在结束临界区后,unique_lock将在离开当前作用域时自动解锁互斥量
} else {
std::cout << "Worker " << id << " could not acquire the lock within 50ms.\n";
}
}
int main() {
std::thread t1(worker, 1);
std::thread t2(worker, 2);
t1.join();
t2.join();
std::cout << "Both workers have finished.\n";
return 0;
}- 在这个例子中,我们创建了两个工作线程,每个线程都有一个
std::unique_lock对象,但并未在构造时立即锁定互斥量。线程在执行过程中尝试使用try_lock_for方法在一定时间内获取锁,成功获取锁后执行临界区代码,最后在unique_lock对象离开作用域时自动解锁互斥量。 - 此外,
std::unique_lock还可以通过unlock()方法手动解锁互斥量,或者通过release()方法主动放弃锁的所有权但不解锁互斥量,以及通过swap()方法与其他unique_lock对象交换所管理的互斥量所有权。
二者区别:
相比于std::lock_guard,std::unique_lock在保证互斥量管理安全的同时,提供了更多的控制选项和灵活性,使其适用于更复杂、需要精细控制锁状态的多线程同步场景。
-
上锁/解锁操作: 除了自动在构造时上锁并在析构时解锁的基本功能外,
std::unique_lock还提供了多种上锁和解锁方式,如:lock()(尝试锁定并阻塞直到成功)、try_lock()(尝试非阻塞锁定,锁定失败立即返回)、try_lock_for(duration)(在指定时间段内尝试锁定)、try_lock_until(time_point)(在指定时间点前尝试锁定)以及unlock()(显式解锁互斥量)。 -
修改操作:
std::unique_lock支持移动赋值和交换互斥量所有权的操作,这意味着可以将一个unique_lock对象的锁状态转移给另一个对象。另外,通过release()方法,unique_lock对象可以释放其所管理的互斥量的所有权,并返回该互斥量的原始指针。 -
获取属性: 提供了多种查询方法以检查和获取互斥量的状态和指针,如:
owns_lock()(返回当前对象是否拥有锁)、operator bool()(类似于owns_lock(),可用于布尔表达式判断是否拥有锁)、mutex()(返回当前unique_lock所管理的互斥量对象的指针)。
5、原子性操作库(atomic)
产生原因
据。但是,当一个或多个线程要修改共享数据时,就会产生很多潜在的麻烦。
示例1:未使用同步机制导致数据竞争
#include <iostream>
using namespace std;
unsigned long sum = 0L;
void incrementCounter(size_t num)
{
for (size_t i = 0; i < num; ++i)
sum++; // 未保护的并发写入,存在数据竞争
}
int main()
{
cout << "Before thread execution, sum = " << sum << endl;
thread t1(incrementCounter, 10000000);
thread t2(incrementCounter, 10000000);
t1.join();
t2.join();
cout << "After thread completion, sum = " << sum << endl;
return 0;
}#include <iostream>
#include <thread>
#include <mutex>
std::mutex m; // 用于保护共享数据sum的互斥锁
unsigned long sum = 0L;
void safeIncrementCounter(size_t num)
{
for (size_t i = 0; i < num; ++i)
{
m.lock();
sum++;
m.unlock();
}
}
int main()
{
cout << "Before thread execution, sum = " << sum << endl;
thread t1(safeIncrementCounter, 10000000);
thread t2(safeIncrementCounter, 10000000);
t1.join();
t2.join();
cout << "After thread completion, sum = " << sum << endl;
return 0;
}- 然而,这种方式也存在一些局限性。每当一个线程持有互斥锁并对`sum`进行累加时,其他试图访问该变量的线程将被迫等待,这可能导致性能下降。此外,如果互斥锁的使用不当(例如,嵌套锁、死锁等),可能会引发程序的死锁状况,严重影响程序的正确性和可靠性。
- 因此,尽管互斥锁是解决多线程数据竞争的有效手段之一,但在实际开发中还需谨慎处理,合理安排锁的使用,以兼顾线程安全和程序性能。随着C++11标准引入了原子操作(std::atomic)、条件变量(std::condition_variable)等更高级的同步原语,开发者有了更多的方式来优化和改进多线程环境下的数据同步机制。
C++11中引入了原子操作。所谓原子操作:即不可被中断的一个或一系列操作,C++11引入的原子操作类型,使得线程间数据的同步变得非常高效。
使用方法
在C++11标准之前,当多线程程序需要同步访问共享数据时,通常需要使用互斥锁(mutexes)或其他同步原语来防止数据竞争。然而,互斥锁的使用往往伴随着一定的开销,特别是在频繁加解锁的场景下,可能会影响到程序的执行效率。
为此,C++11引入了原子操作(Atomic Operations)的概念,它提供了一种更为细粒度的同步机制。原子操作是指在多线程环境下,对某些操作进行特殊的底层硬件级别的支持,使得这些操作能够在没有其他线程干扰的情况下完成,即一个原子操作要么全部执行完毕,要么根本不执行,不会被其他线程“切割”打断。
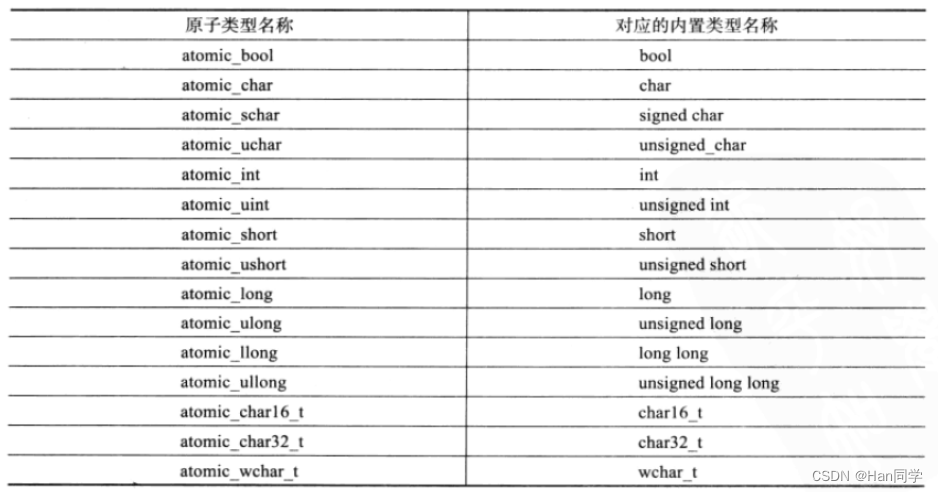
在C++11标准库中,通过<atomic>头文件提供了std::atomic模板类来支持原子操作。通过定义一个std::atomic<T>类型的变量,可以确保对该变量的所有操作(如读取、写入、递增、递减等)都是原子性的,从而避免了多线程环境下的数据竞争问题。
- 例如,声明一个原子整型变量:
std::atomic<int> counter;- 然后可以安全地在多线程环境下进行如下操作:
counter.fetch_add(1); // 原子递增操作
int current_value = counter.load(); // 原子读取操作通过原子操作,不仅能够保证数据的一致性,而且相比传统的互斥锁,如果应用场景合适的话,还能显著提升程序在多线程环境下的执行效率。不过,需要注意的是,原子操作并不能替代互斥锁解决所有同步问题,例如在涉及多个条件判断和更新的复杂逻辑中,仍需使用互斥锁或信号量等同步机制。
例如,以下代码展示了如何声明和使用一个原子长整型变量sum,并通过两个线程安全地对其进行递增:
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<long> sum{ 0 }; // 声明一个原子类型的long型变量
void fun(size_t num)
{
for (size_t i = 0; i < num; ++i)
sum++; // 这是一个原子操作,无需担心数据竞争问题
}
int main()
{
std::cout << "Before starting threads, sum = " << sum << std::endl;
std::thread t1(fun, 1000000);
std::thread t2(fun, 1000000);
t1.join();
t2.join();
std::cout << "After joining threads, sum = " << sum << std::endl;
return 0;
}std::atomic模板类的设计允许用户定义任意类型的原子变量,只需将所需的类型作为模板参数传递。然而,值得注意的是,原子类型的数据被视为“资源型”数据,指每个线程只能独立地访问各自的原子类型实例。出于对并发安全性的严格要求,C++11标准库对std::atomic模板类的拷贝构造、移动构造和赋值操作进行了默认删除处理,从而防止意外的复制和移动操作导致数据竞争问题。如下所示:
#include <atomic>
int main()
{
std::atomic<int> a1(0);
// 下面的语句因拷贝构造和赋值操作被禁用而不能编译通过
// std::atomic<int> a2(a1); // 编译错误,禁止拷贝构造
// a2 = a1; // 编译错误,禁止赋值操作
std::atomic<int> a2(0); // 正确做法,直接初始化一个新的原子变量
return 0;
}6、lambda表达式封装线程
int main()
{
int n = 100000;
int x = 0;
mutex mtx;
size_t begin = clock();
thread t1([&, n]() {
mtx.lock();
for (int i = 0; i < n; i++)
{
++x;
}
mtx.unlock();
});
thread t2([&, n]() {
mtx.lock();
for (int i = 0; i < n; i++)
{
++x;
}
mtx.unlock();
});
t1.join();
t2.join();
size_t end = clock();
cout << x << endl;
cout << end - begin << endl;
return 0;
}讲解一下thread使用lambda上述代码通过C++11的lambda表达式技术封装了线程的执行函数,下面具体讲解如何实现的:
Lambda表达式允许你创建匿名函数,可以直接在代码中定义并使用。语法格式大致如下:
[capture list](parameters) -> return type { function body }[&, n]是捕获列表,&表示捕获外部作用域内的所有引用类型的变量,n表示捕获值类型的变量n的副本。- 参数列表为空,因为这里定义的函数并不需要额外的输入参数。
- 返回类型省略了,编译器可以通过函数体推断出返回类型是void。
创建线程: 在C++11标准库中,std::thread类可以用来创建和管理线程。这里创建了两个线程t1和t2,它们分别执行不同的lambda表达式作为线程函数。
thread t1([&, n]() { ... });
thread t2([&, n]() { ... });这里的lambda表达式分别定义了两个线程需要执行的任务,即对共享变量x进行n次自增操作。同时,它们都捕获了外部作用域中的引用类型变量mtx和值类型变量n。
- 线程同步: 在lambda表达式内部,通过调用互斥锁
mtx.lock()和mtx.unlock()来实现线程同步。当一个线程获取到锁时,其他线程尝试获取锁时将被阻塞,直至该线程调用unlock()释放锁。
7、condition_variable 线程同步机制
std::condition_variable 是 C++11 标准库中提供的一个线程同步机制,它是 C++ 线程库的一部分,主要用于线程之间的条件同步。condition_variable 主要与互斥量(如 std::mutex)一起使用,帮助线程在满足某个特定条件时睡眠,并在条件变为真时唤醒。
基本使用步骤:
-
声明和初始化: 首先,需要声明一个
std::condition_variable变量。std::condition_variable cv; -
与互斥量配合: 为了正确使用
condition_variable,通常会与一个互斥量关联起来,确保在检查和更改条件变量所关注的状态时是线程安全的。std::mutex m; bool data_ready = false; -
线程等待条件: 当线程需要等待某个条件成立时,会调用
condition_variable的wait()函数,该函数需要一个与之关联的std::unique_lock<std::mutex>参数。在调用wait()之前,线程必须先锁定互斥量。std::unique_lock<std::mutex> lock(m); cv.wait(lock, []{ return data_ready; }); // 当 data_ready 为真时才会返回上述代码中,线程会释放互斥锁并进入等待状态,直到另一线程改变了
data_ready的值并调用了notify_one()或notify_all()来唤醒等待的线程。唤醒后,线程会重新获取互斥锁并继续执行。 -
通知条件变化: 另一线程在改变条件后,可以调用
condition_variable的通知函数:lock.lock(); data_ready = true; // 改变条件 lock.unlock(); cv.notify_one(); // 唤醒一个等待的线程 // 或者唤醒所有等待线程 // cv.notify_all(); -
超时等待:
condition_variable还提供了带超时的等待函数wait_for()和wait_until(),允许线程在等待一段时间或直到某一时刻仍未满足条件时退出等待。std::cv_status status = cv.wait_for(lock, std::chrono::seconds(5), []{ return data_ready; }); if (status == std::cv_status::timeout) { // 等待超时 } else { // 条件满足,继续执行 }
注意事项:
- 在调用
wait()之前,务必确保互斥锁已被正确锁定,且在等待期间互斥锁会被自动释放,等待结束后会重新获取。 notify_one()和notify_all()仅仅是发送唤醒信号,被唤醒的线程能否立刻执行还需视乎互斥锁的状态。- 由于可能存在“虚假唤醒”现象,通常在
wait()的谓词中会检查条件是否真正满足,如果条件尚未满足,则继续等待。
示例代码:
std::condition_variable cv;
std::mutex cv_m;
bool data_ready = false;
void producer() {
// 生产数据...
data_ready = true;
cv.notify_one(); // 数据准备好后通知等待的线程
}
void consumer() {
std::unique_lock<std::mutex> lk(cv_m);
cv.wait(lk, []{return data_ready;}); // 等待数据准备完成
// 消费数据...
data_ready = false;
}8、支持两个线程交替打印,一个打印奇数,一个打印偶数
我们实现了一个简单的并发编程示例,让两个线程(t1和t2)交替打印从1到99的奇数和偶数。它利用了C++11标准库中的std::mutex(互斥锁)和std::condition_variable(条件变量)来进行线程间的同步与通信。
#include <mutex>
#include <iostream>
using namespace std;
int main()
{
mutex mtx;
condition_variable cv;
int n = 100;
int x = 1;
thread t1([&]()
{
while (1) {
unique_lock<mutex> lock(mtx);
if (x >= n) break;
cv.wait(lock, [&x] {return x % 2 != 0; });
cout << "t1->" << this_thread::get_id() << "t1 :" << x++ << endl;
cv.notify_one();
}
});
thread t2([&] {
while (1) {
unique_lock<mutex> lock(mtx);
if (x > n) break;
cv.wait(lock, [&x] {return x % 2 == 0; });
cout << "t2->" << this_thread::get_id() << ":" << x++ << endl;
cv.notify_one();
}
});
t1.join();
t2.join();
return 0;
}问题1:如何保证t1先运行,t2阻塞?
- 在左上角的代码中,我们看到两个线程t1和t2。为了确保t1先运行,t2阻塞,我们可以使用条件变量(condition variable)配合互斥锁(mutex)。在t1线程中,它首先获取锁,然后等待条件变量,这会释放锁并让t2有机会尝试获取锁。当t2获取到锁时,它会立即调用wait方法,这会释放锁并使t1从等待状态中恢复。这样,t1就可以继续执行,而t2则被阻塞,直到t1完成其任务并通知t2。
问题2:如何防止一个线程连续打印?
- 在右下角的代码中,我们看到线程t1和t2交替打印奇数和偶数。为了实现这个功能,我们需要使用互斥锁和条件变量。t1线程在打印奇数后,会等待一个条件变量,然后释放锁。t2线程在打印偶数后,会唤醒条件变量,然后释放锁。这样,t1和t2可以交替打印奇数和偶数,而不会连续打印。
//运行结果
t1->102624t1 :1
t2->43532:2
t1->102624t1 :3
t2->43532:4
t1->102624t1 :5
t2->43532:6
t1->102624t1 :95
t2->43532:96
t1->102624t1 :97
t2->43532:98
t1->102624t1 :99
t2->43532:100详细讲解:
-
初始化部分:
- 首先定义了一个互斥锁
mtx和一个条件变量cv,用于线程间的同步。 - 定义一个整数变量
n,其值为100,作为总的打印次数上限。 - 定义一个整数变量
x,其初始值为1,作为当前打印的数字。
- 首先定义了一个互斥锁
-
创建线程t1:
- 线程t1内部是一个无限循环,通过
unique_lock<mutex> lock(mtx);锁定互斥锁mtx,确保在同一时刻只有一个线程能够访问x。 - 当
x >= 100时,线程t1跳出循环。 - 使用
cv.wait(lock, [&x]() {return x % 2 != 0; });使线程t1在条件不满足(即x不是奇数)时等待,并释放互斥锁,这样可以让线程t2有机会执行。 - 条件满足时(即
x为奇数),线程t1打印当前的x值,然后将其加1。 - 最后,通过
cv.notify_one();唤醒一个等待在条件变量上的线程(这里是线程t2)。
- 线程t1内部是一个无限循环,通过
-
创建线程t2:
- 线程t2的结构与t1类似,只是它等待的条件相反,即
cv.wait(lock, [&x]() {return x % 2 == 0; });,当x为偶数时才打印并继续执行。 - 其他部分与线程t1相同,打印偶数并递增
x,然后通过cv.notify_one();唤醒等待的线程。
- 线程t2的结构与t1类似,只是它等待的条件相反,即
-
主函数最后:
- 通过
t1.join();和t2.join();等待两个线程都执行完毕后,主程序才结束。
- 通过
通过这样的设计,线程t1和线程t2能够在互斥锁和条件变量的配合下,按照奇数-偶数的顺序交替打印从1到100的数字。
三、包装器
1、为什么需要function
std::function 是一个通用的函数包装器(或称为函数适配器),它允许我们将不同类型的可调用实体(包括函数、函数指针、lambda 表达式和函数对象)以统一的方式存储和传递。这样做的好处是可以编写更加灵活和泛化的代码,不必为每种不同的可调用类型编写特定的接口。
那么为什么需要function?
template<class F, class T>
T useF(F f, T x)
{
static int count = 0;
cout << "count:" << ++count << endl;
cout << "count:" << &count << endl;
return f(x);
}
double f(double i)
{
return i / 2;
}
struct Functor
{
double operator()(double d)
{
return d / 3;
}
};
int main()
{
// 函数名
cout << useF(f, 11.11) << endl;
// 函数对象
cout << useF(Functor(), 11.11) << endl;
// lamber表达式
cout << useF([](double d)->double { return d / 4; }, 11.11) << endl;
return 0;
}三种不同的可调用实体调用方式:
- 函数名:直接使用普通函数
f,该函数接收一个 double 类型参数并返回一个 double 类型的结果。 - 函数对象:通过 Functor 类的对象实例来调用, Functor 类重载了
operator()运算符,使其成为一个可以像函数一样调用的对象。 - Lambda 表达式:使用 C++11 引入的 lambda 表达式来创建一个匿名函数对象,并将其作为参数传递给
useF。
输出结果:

然而,如果直接使用这样的模板函数,在处理多种多样的可调用实体时,编译器可能会为每种不同的可调用实体生成不同的实例化版本,这在某些情况下可能导致代码膨胀和效率降低。
为了应对这一问题,std::function 就派上用场了。它可以存储任何匹配其签名的可调用实体,并提供统一的接口进行调用。例如,如果我们修改 useF 为接受 std::function<double(double)> 类型参数,那么无论传入的是函数、函数指针、函数对象还是 lambda 表达式,都可以高效地封装和调用,而无需额外生成多个模板实例化版本。
2、function定义
std::function是C++11引入的一个通用类型 erased 的可调用对象包装器,它可以存储并调用任何符合其签名的可调用对象,包括函数指针、lambda表达式、重载的运算符()的对象(如仿函数)、以及类的成员函数指针。
template <class T> function; // undefined
template <class Ret, class... Args>
class function<Ret(Args...)>;模板参数说明:
- Ret:表示可调用对象被调用时的返回类型。
- Args...:表示可调用对象接受的参数类型,这里使用了C++11的模板参数包语法,意味着
std::function可以接受任意数量和类型的参数。
#include <iostream>
#include <functional>
// 定义全局函数
int f(int a, int b)
{
return a + b;
}
// 定义函数对象(Functor)
struct Functor
{
public:
int operator()(int a, int b)
{
return a + b;
}
};
// 定义类Plus
class Plus
{
public:
static int plusi(int a, int b)
{
return a + b;
}
double plusd(double a, double b)
{
return a + b;
}
};
int main()
{
// 使用std::function封装函数指针
std::function<int(int, int)> func1 = f;
std::cout << func1(1, 2) << std::endl;
// 使用std::function封装函数对象
std::function<int(int, int)> func2 = Functor();
std::cout << func2(1, 2) << std::endl;
// 使用std::function封装lambda表达式
std::function<int(int, int)> func3 = [](const int a, const int b)
{
return a + b;
};
std::cout << func3(1, 2) << std::endl;
// 使用std::function封装类的静态成员函数
std::function<int(int, int)> func4 = &Plus::plusi;
std::cout << func4(1, 2) << std::endl;
// 使用std::function封装类的非静态成员函数
std::function<double(Plus, double, double)> func5 = &Plus::plusd;
std::cout << func5(Plus(), 1.1, 2.2) << std::endl;
return 0;
}func1是一个可以接受两个int参数并返回一个int结果的可调用对象,它存储了函数f的地址,因此可以直接像调用函数一样调用func1(1, 2)。-
func2同样接受两个int参数并返回int结果,但它存储的是一个Functor对象实例,由于Functor类重载了operator(),所以也可以作为可调用对象使用。 -
func3是一个lambda表达式,它同样匹配std::function<int(int, int)>的签名,可以捕获环境并实现相应的逻辑。 -
func4存储的是类Plus的静态成员函数plusi的地址,因为静态成员函数不需要类实例就可以调用,所以可以直接通过func4(1, 2)调用。 -
func5存储的是类Plus的非静态成员函数plusd的地址,但不同于静态成员函数,非静态成员函数需要一个类实例作为隐含的第一个参数(即this指针),所以在调用时需要传入一个Plus类的实例,即func5(Plus(), 1.1, 2.2)。

总结来说,std::function的强大之处在于它的灵活性和泛型性,使得我们可以创建统一接口处理各种不同类型的可调用对象,这对于事件处理、策略模式、回调函数等应用场景尤其有用。
示例二: 有了包装器,如何解决模板的效率低下,实例化多份的问题呢?
#include <functional>
#include <map>
int f(int a, int b)
{
cout << "int f(int a, int b): ";
return a + b;
}
struct Functor
{
public:
int operator()(int a, int b)
{
cout << "int operator()(int a, int b): ";
return a + b;
}
};
int main()
{
function<int(int, int)> f1 = f;
function<int(int, int)> f2 = Functor();
function<int(int, int)> f3 = [](int a, int b) {
cout << "[](int a, int b): ";
return a + b;
};
cout << f1(1, 2) << endl;
cout << f2(11, 22) << endl;
cout << f3(111, 222) << endl;
map<string, function<int(int, int)>> FuncMap;
FuncMap["函数指针"] = f;
FuncMap["仿函数"] = Functor();
FuncMap["lambda"] = [](int a, int b) {
cout << "[](int a, int b) {return a + b;}" << endl;
return a + b;
};
cout << FuncMap["函数指针"](1, 2) << endl;
cout << FuncMap["仿函数"](1, 2) << endl;
cout << FuncMap["lambda"](1, 2) << endl;
return 0;
}
在这个示例中,我们首先展示了三种不同的方式来封装可调用对象:函数指针、仿函数(Functor 类)以及 lambda 表达式,并利用 <functional> 头文件中的 std::function 对象将它们包装起来。std::function 是一种通用的可调用对象包装器,它可以存储任何具有匹配签名的可调用实体。
-
函数指针: 我们有一个全局函数
f(int a, int b),并通过std::function<int(int, int)> f1 = f;将其转换为一个std::function对象f1。调用f1(1, 2)时,实际上会调用原始的f函数。 -
仿函数(Functor): 定义了一个名为
Functor的类,其中重载了operator(),使得该类对象可以像函数一样被调用。创建一个Functor实例并赋值给std::function<int(int, int)> f2,调用f2(11, 22)时,会调用Functor类的operator()。 -
Lambda 表达式: 使用 C++11 引入的 lambda 表达式创建了一个匿名函数,并将其赋值给
std::function<int(int, int)> f3。调用f3(111, 222)时,会执行 lambda 函数体中的代码。 -
作为类型参数:接下来,我们创建了一个
std::map<string, function<int(int, int)>> FuncMap,用来存储不同类型(函数指针、仿函数、lambda 表达式)的可调用对象。这样做的好处是可以在运行时动态选择并调用对应的函数,提高了程序的灵活性。
3、function其他使用场景
类Solution定义了一个名为evalRPN的方法,它们的作用是计算逆波兰表达式(Reverse Polish Notation,简称RPN)的结果。逆波兰表达式是一种后缀表达式形式,操作符位于其操作数之后,因此无需括号也能明确运算顺序。
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> st;
for (auto& str : tokens)
{
if (str == "+" || str == "-" || str == "*" || str == "/")
{
int right = st.top();
st.pop();
int left = st.top();
st.pop();
switch (str[0])
{
case '+':
st.push(left + right);
break;
case '-':
st.push(left - right);
break;
case '*':
st.push(left * right);
break;
case '/':
st.push(left / right);
break;
}
}
else
{
// 1、atoi itoa
// 2、sprintf scanf
// 3、stoi to_string C++11
st.push(stoi(str));
}
}
return st.top();
}
};原始版本:
- 遍历输入的tokens(字符串数组)。
- 如果当前token是操作符("+"、"-"、"*"、"/"),则从栈顶弹出两个操作数(假设右操作数在栈顶,然后是左操作数),执行相应的算术运算,并将结果压回栈中。
- 如果当前token不是操作符,则将其转换为整数并压入栈中。
使用包装器以后的玩法
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> st;
map<string, function<int(int, int)>> opFuncMap =
{
{ "+", [](int i, int j) {return i + j; } },
{ "-", [](int i, int j) {return i - j; } },
{ "*", [](int i, int j) {return i * j; } },
{ "/", [](int i, int j) {return i / j; } }
};
for (auto& str : tokens)
{
if (opFuncMap.find(str) != opFuncMap.end())
{
int right = st.top();
st.pop();
int left = st.top();
st.pop();
st.push(opFuncMap[str](left, right));
}
else
{
// 1、atoi itoa
// 2、sprintf scanf
// 3、stoi to_string C++11
st.push(stoi(str));
}
}
return st.top();
}
};改进后的版本:
- 同样遍历输入的tokens。
- 引入了一个map
opFuncMap,它将操作符字符串映射到对应的lambda函数,这些函数接受两个整数作为参数并返回运算结果。 - 当遇到操作符时,不再使用switch语句,而是查找该操作符在
opFuncMap中的关联函数,然后同样从栈中弹出两个操作数进行计算,并将结果压回栈中。 - 对于非操作符的token,仍然使用
stoi将其转换为整数并压入栈中。
通过使用std::function和lambda表达式,改进版的代码提高了可读性和可维护性,同时也降低了耦合度。相比于原始版本的硬编码switch结构,这种方式使得添加新的操作符或者修改现有操作符的行为变得更加简单且模块化。此外,尽管实际性能差异可能微乎其微,但在大规模项目中,这样的重构通常会带来更好的代码组织结构和扩展性。
4、bind包装器
原型定义如下:
template <class Fn, class... Args>
std::function<unspecified_return_type> bind(Fn&& fn, Args&&... args);
// 对于明确指定返回类型的版本(通常编译器能自动推断)
template <class Ret, class Fn, class... Args>
std::function<Ret(typewrapped_args)> bind(Fn&& fn, Args&&... args);这里的"unspecified_return_type"代表由原始可调用对象及其绑定参数决定的具体返回类型。
使用std::bind的一般形式是这样的:
auto newCallable = std::bind(originalCallable, argumentList);- 在这个表达式中,
originalCallable是我们想要修改其参数行为的原始可调用对象,而argumentList是一个变长参数列表,包含了要绑定到原始函数上的具体值或者占位符。 - 特别地,
argumentList中可以包含形如_n的占位符,这里的n是一个正整数,它代表了新生成的可调用对象中待传入的实际参数的位置。 - 举例来说,
_1表示新可调用对象接收到的第一个参数,_2表示第二个参数,依此类推。当调用newCallable时,那些占位符对应的位置会被实际传入的参数所替换,随后newCallable会按调整后的参数列表去调用originalCallable。这种机制使得我们可以灵活地调整参数顺序,固定某些参数值,甚至忽略不必要的一些参数。
当调用 newCallable 时,它会按照参数绑定时设定的方式,将接收到的参数传递给 originalCallable 进行执行。通过这种方式,std::bind 不仅能预先填充值,还可以调整参数顺序,从而极大地增强了函数使用的灵活性。同时,如果绑定的参数数量少于原始可调用对象所需要的参数总数,那么剩余的参数将在调用 newCallable 时动态地补充进去。不过,尽管理论上 std::bind 可以创建一个接受更多参数的新可调用对象,但在实际应用中这样做通常没有明显意义,因为多出来的参数不会被原始可调用对象所使用。
// 使用举例
#include <functional>
int Plus(int a, int b)
{
return a + b;
}
class Sub
{
public:
int sub(int a, int b)
{
return a - b;
}
};
int main()
{
//表示绑定函数plus 参数分别由调用 func1 的第一,二个参数指定
std::function<int(int, int)> func1 = std::bind(Plus, placeholders::_1,
placeholders::_2);
//auto func1 = std::bind(Plus, placeholders::_1, placeholders::_2);
//func2的类型为 function<void(int, int, int)> 与func1类型一样
//表示绑定函数 plus 的第一,二为: 1, 2
auto func2 = std::bind(Plus, 1, 2);
cout << func1(1, 2) << endl;
cout << func2() << endl;
Sub s;
// 绑定成员函数
std::function<int(int, int)> func3 = std::bind(&Sub::sub, s,
placeholders::_1, placeholders::_2);
// 参数调换顺序
std::function<int(int, int)> func4 = std::bind(&Sub::sub, s,
placeholders::_2, placeholders::_1);
cout << func3(1, 2) << endl;
cout << func4(1, 2) << endl;
return 0;
}这段C++代码展示了如何使用std::bind函数模板来绑定不同的可调用对象,并通过std::function来存储和使用这些绑定后的可调用对象。下面逐行解释:
-
首先引入了
<functional>头文件,该头文件包含了std::bind和std::function等用于函数对象操作的组件。 -
定义了一个名为
Plus的全局函数,它接受两个整数参数a和b,并返回它们的和。 -
定义了一个名为
Sub的类,其中包含一个成员函数sub,它同样接受两个整数参数并返回它们的差值。 -
在
main函数内:a. 使用
std::bind将Plus函数与std::placeholders::_1和std::placeholders::_2结合,这意味着当func1被调用时,它会接收到两个参数,并将这两个参数作为Plus函数的a和b参数。然后将其转换为std::function<int(int, int)>类型的对象func1。b. 同样地,
func2也是通过std::bind绑定到Plus函数上,但这次直接绑定了常量值1和2作为前两个参数。因此,func2不再需要任何参数就能调用,并且始终计算的是1+2的结果。c. 创建一个
Sub类的对象s。d. 使用
std::bind绑定Sub类的成员函数sub到对象s上,并用占位符placeholders::_1和placeholders::_2指代sub函数的两个参数。这样得到的func3在调用时,将把传递给它的两个参数当作s.sub(a, b)中的a和b。e. 类似地,
func4也绑定到了s.sub上,但是交换了参数顺序,即将调用时的第二个参数传给sub的第一个参数,第一个参数传给第二个参数。f. 最后,通过调用
func1、func2、func3和func4并输出结果,验证上述绑定的效果。运行程序将会依次输出3(因为func1(1, 2)调用了Plus(1, 2))、3(func2()隐含调用了Plus(1, 2))、-1(func3(1, 2)调用了s.sub(1, 2))和-3(func4(1, 2)调用了s.sub(2, 1))。
智能推荐
艾美捷Epigentek DNA样品的超声能量处理方案-程序员宅基地
文章浏览阅读15次。空化气泡的大小和相应的空化能量可以通过调整完全标度的振幅水平来操纵和数字控制。通过强调超声技术中的更高通量处理和防止样品污染,Epigentek EpiSonic超声仪可以轻松集成到现有的实验室工作流程中,并且特别适合与表观遗传学和下一代应用的兼容性。Epigentek的EpiSonic已成为一种有效的剪切设备,用于在染色质免疫沉淀技术中制备染色质样品,以及用于下一代测序平台的DNA文库制备。该装置的经济性及其多重样品的能力使其成为每个实验室拥有的经济高效的工具,而不仅仅是核心设施。
11、合宙Air模块Luat开发:通过http协议获取天气信息_合宙获取天气-程序员宅基地
文章浏览阅读4.2k次,点赞3次,收藏14次。目录点击这里查看所有博文 本系列博客,理论上适用于合宙的Air202、Air268、Air720x、Air720S以及最近发布的Air720U(我还没拿到样机,应该也能支持)。 先不管支不支持,如果你用的是合宙的模块,那都不妨一试,也许会有意外收获。 我使用的是Air720SL模块,如果在其他模块上不能用,那就是底层core固件暂时还没有支持,这里的代码是没有问题的。例程仅供参考!..._合宙获取天气
EasyMesh和802.11s对比-程序员宅基地
文章浏览阅读7.7k次,点赞2次,收藏41次。1 关于meshMesh的意思是网状物,以前读书的时候,在自动化领域有传感器自组网,zigbee、蓝牙等无线方式实现各个网络节点消息通信,通过各种算法,保证整个网络中所有节点信息能经过多跳最终传递到目的地,用于数据采集。十多年过去了,在无线路由器领域又把这个mesh概念翻炒了一下,各大品牌都推出了mesh路由器,大多数是3个为一组,实现在面积较大的住宅里,增强wifi覆盖范围,智能在多热点之间切换,提升上网体验。因为节点基本上在3个以内,所以mesh的算法不必太复杂,组网形式比较简单。各厂家都自定义了组_802.11s
线程的几种状态_线程状态-程序员宅基地
文章浏览阅读5.2k次,点赞8次,收藏21次。线程的几种状态_线程状态
stack的常见用法详解_stack函数用法-程序员宅基地
文章浏览阅读4.2w次,点赞124次,收藏688次。stack翻译为栈,是STL中实现的一个后进先出的容器。要使用 stack,应先添加头文件include<stack>,并在头文件下面加上“ using namespacestd;"1. stack的定义其定义的写法和其他STL容器相同, typename可以任意基本数据类型或容器:stack<typename> name;2. stack容器内元素的访问..._stack函数用法
2018.11.16javascript课上随笔(DOM)-程序员宅基地
文章浏览阅读71次。<li> <a href = "“#”>-</a></li><li>子节点:文本节点(回车),元素节点,文本节点。不同节点树: 节点(各种类型节点)childNodes:返回子节点的所有子节点的集合,包含任何类型、元素节点(元素类型节点):child。node.getAttribute(at...
随便推点
layui.extend的一点知识 第三方模块base 路径_layui extend-程序员宅基地
文章浏览阅读3.4k次。//config的设置是全局的layui.config({ base: '/res/js/' //假设这是你存放拓展模块的根目录}).extend({ //设定模块别名 mymod: 'mymod' //如果 mymod.js 是在根目录,也可以不用设定别名 ,mod1: 'admin/mod1' //相对于上述 base 目录的子目录}); //你也可以忽略 base 设定的根目录,直接在 extend 指定路径(主要:该功能为 layui 2.2.0 新增)layui.exten_layui extend
5G云计算:5G网络的分层思想_5g分层结构-程序员宅基地
文章浏览阅读3.2k次,点赞6次,收藏13次。分层思想分层思想分层思想-1分层思想-2分层思想-2OSI七层参考模型物理层和数据链路层物理层数据链路层网络层传输层会话层表示层应用层OSI七层模型的分层结构TCP/IP协议族的组成数据封装过程数据解封装过程PDU设备与层的对应关系各层通信分层思想分层思想-1在现实生活种,我们在喝牛奶时,未必了解他的生产过程,我们所接触的或许只是从超时购买牛奶。分层思想-2平时我们在网络时也未必知道数据的传输过程我们的所考虑的就是可以传就可以,不用管他时怎么传输的分层思想-2将复杂的流程分解为几个功能_5g分层结构
基于二值化图像转GCode的单向扫描实现-程序员宅基地
文章浏览阅读191次。在激光雕刻中,单向扫描(Unidirectional Scanning)是一种雕刻技术,其中激光头只在一个方向上移动,而不是来回移动。这种移动方式主要应用于通过激光逐行扫描图像表面的过程。具体而言,单向扫描的过程通常包括以下步骤:横向移动(X轴): 激光头沿X轴方向移动到图像的一侧。纵向移动(Y轴): 激光头沿Y轴方向开始逐行移动,刻蚀图像表面。这一过程是单向的,即在每一行上激光头只在一个方向上移动。返回横向移动: 一旦一行完成,激光头返回到图像的一侧,准备进行下一行的刻蚀。
算法随笔:强连通分量-程序员宅基地
文章浏览阅读577次。强连通:在有向图G中,如果两个点u和v是互相可达的,即从u出发可以到达v,从v出发也可以到达u,则成u和v是强连通的。强连通分量:如果一个有向图G不是强连通图,那么可以把它分成躲个子图,其中每个子图的内部是强连通的,而且这些子图已经扩展到最大,不能与子图外的任一点强连通,成这样的一个“极大连通”子图是G的一个强连通分量(SCC)。强连通分量的一些性质:(1)一个点必须有出度和入度,才会与其他点强连通。(2)把一个SCC从图中挖掉,不影响其他点的强连通性。_强连通分量
Django(2)|templates模板+静态资源目录static_django templates-程序员宅基地
文章浏览阅读3.9k次,点赞5次,收藏18次。在做web开发,要给用户提供一个页面,页面包括静态页面+数据,两者结合起来就是完整的可视化的页面,django的模板系统支持这种功能,首先需要写一个静态页面,然后通过python的模板语法将数据渲染上去。1.创建一个templates目录2.配置。_django templates
linux下的GPU测试软件,Ubuntu等Linux系统显卡性能测试软件 Unigine 3D-程序员宅基地
文章浏览阅读1.7k次。Ubuntu等Linux系统显卡性能测试软件 Unigine 3DUbuntu Intel显卡驱动安装,请参考:ATI和NVIDIA显卡请在软件和更新中的附加驱动中安装。 这里推荐: 运行后,F9就可评分,已测试显卡有K2000 2GB 900+分,GT330m 1GB 340+ 分,GT620 1GB 340+ 分,四代i5核显340+ 分,还有写博客的小盒子100+ 分。relaybot@re...