Windows编程学习笔记04-Windows编程字符集_windows字符集-程序员宅基地
技术标签: 学习 Windows编程 microsoft windows
概述
总的来讲,由于历史和发展的原因,产生了 Unicode 和 多字节字符集(MBCS、DBCS、ANSI)。在早期,使用Unicode占用内存多,使用多字节字符集又无法国际化。所以使用 WindowsAPI 以及C\C++ 进行Windows编程时有两种字符集,如一些WindowsAPI都会存在两个版本(比如MessageBoxA和MessageBoxW),C\C++语言有char和wchar_t两种字符类型。学习Windows编程,了解Unicode和 多字节字符集之间的区别是必不可少的。
现在内存没那么紧张了,尽量用Unicode字符集。
WINUSERAPI int WINAPI MessageBoxA(
_In_opt_ HWND hWnd,
_In_opt_ LPCSTR lpText,
_In_opt_ LPCSTR lpCaption,
_In_ UINT uType);
WINUSERAPI int WINAPI MessageBoxW(
_In_opt_ HWND hWnd,
_In_opt_ LPCWSTR lpText,
_In_opt_ LPCWSTR lpCaption,
_In_ UINT uType);
#include <windows.h>
#include <iostream>
int main()
{
char char1 = '1';
char char2 = '中';
wchar_t wchar_t1 = '1';
wchar_t wchar_t2 = '中';
std::cout << char1 << std::endl;//1
std::cout << char2 << std::endl;//无法显示
std::cout << wchar_t1 << std::endl;//49
std::cout << wchar_t2 << std::endl;//54992
char str1[] = "1111";//长度5 包含 \0
char str2[] = "中中中中";//长度9 包含 \0
wchar_t wstr1[] = L"1111";//5个双字符,必须带L
wchar_t wstr2[] = L"中中中中";//5个双字符,必须带L
std::cout << str1 << std::endl;//1111
std::cout << str2 << std::endl;//中中中中
std::cout << wstr1 << std::endl;//00000033D22FF7B8
std::cout << wstr2 << std::endl;//00000033D22FF7E8
return 0;
}
为了方便编程,写一份代码就可以编译成ASCII 或 Unicode两种版本,使用下面说的通用解决方案。
《Windows核心编程》
缓冲区溢出错误(这是处理字符串时的典型错误)已成为针对应用程序乃至操作系统的各个组件发起安全攻击的媒介。这几年,Microsoft 从内部和外部两个方面主动出击,倾尽全力提升 Windows世界的安全水平。本章将介绍 Microsoft在C运行库中新增的函数。我们应该使用这些新函数来防止应用程序在处理字符串时发生缓冲区溢出。
本章的位置之所以如此靠前,是由于我极力主张在应用程序始终使用Unicode字符串,而且始终应该通过新的安全字符串函数来处理这些字符串。如果源代码尚未使用Unicode,最好能将源代码迁移至Unicode,这会增强应用程序的执行性能,并为本地化工作奠定基础。理由如下:1.Unicode有利于应用程序的本地化。
2.使用Unicode,只需发布一个二进制(.exe或 DLL)文件,即可支持所有语言。Unicode提升了应用程序的效率,因为代码执行速度更快,占用内存更少。Windows内部的一切工作都是使用Unicode字符和Unicode字符串来进行的。所以,假如我们坚持传入ANSI字符或字符串,Windows就会被迫分配内存,并将ANSI字符或字符串转换为等价的Unicode形式。
3.使用Unicode,应用程序能轻松调用所有尚未弃用(nondeprecated)的 Windows函数,因为一些 Windows函数提供的版本只能处理 Unicode字符和字符串。
4.使用Unicode,应用程序的代码很容易与COM集成(后者要求使用 Unicode字符和Unicode字符串)。
5.使用 Unicode,应用程序的代码很容易与.NET Framework集成(后者要要求使用Unicode字符和 Unicode字符串)。
6.使用Unicode,能保证应用程序的代码能够轻松操纵我们自己的资源(其中的字符串总是 Unicode形式的)。在 Windows Vista中,每个Unicode 字符都使用UTF-16 编码。UTF-16将每个字符编码为2个字节(或者说16位)。在本书中,在谈到Unicode时,除非专门声明,否则一般都是指UTF-16编码。Windows之所以使用UTF-16,是因为全球各地使用的大部分语言中,每个字符很容易用一个16位值来表示。这样一来,应用程序很容易遍历字符串并计算出它的长度。但是,16位不足以表示某些语言的所有字符。对于这些语言,UTF-16支持使用代理(surrogate),后者是用32位(或者说4个字节)来表示一个字符的一种方式。由于只有少数应用程序需要表示这些语言中的字符,所以 UTF-16在节省空间和简化编码这两个目标之间,提供了一个很好的折衷。注意,.NET Framework 始终使用UTF-16来编码所有字符和字符串,所以在我们开发的Windows应用程序中,如果需要在本机代码(native code)和托管代码(managed code)之间传递字符或字符串,使用UTF-16能改进性能和减少内存消耗。
字符集发展简史
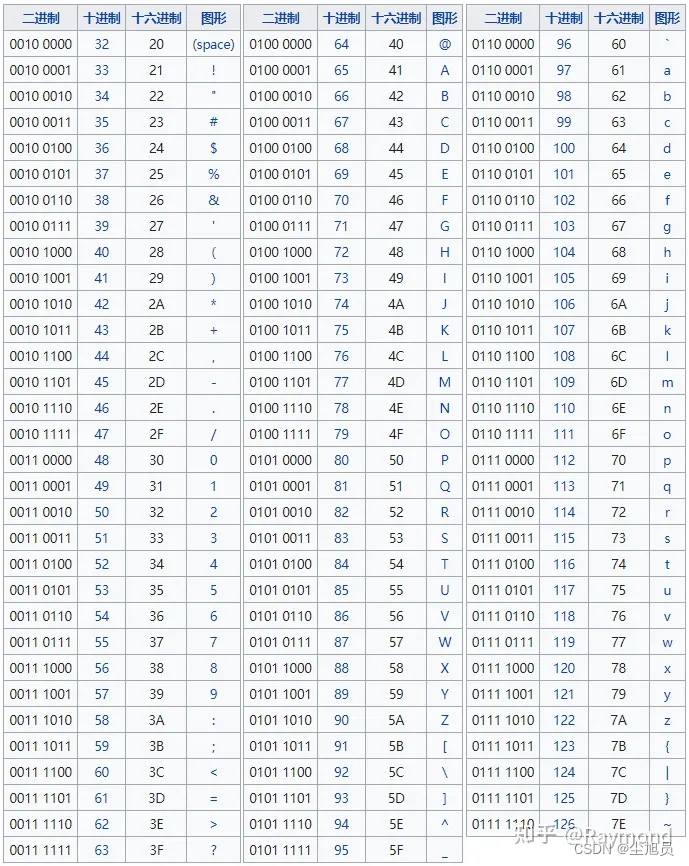
ASCII字符集定义了0x00 - 0x7F范围内的字符。还有许多其他字符集,主要是欧洲字符集,它们与ASCII字符集一样定义0x00 - 0x7F范围内的字符,也定义0x80 - 0xFF范围内的扩展字符集。8位**单字节字符集(SBCS)足以表示ASCII字符集和许多欧洲语言的字符集。但是,一些非欧洲字符集(如日语汉字)包含的字符比单字节编码方案所能表示的要多得多,因此需要多字节字符集(MBCS)**编码。并且Windows在所有平台上支持一种称为双字节字符集(DBCS)的多字节字符集(MBCS)形式。
ASCII-单字节
计算机是由美国搞出来的,他们觉得一个字节(可以表示256个编码)表示英语世界里所有的字母、数字和常用特殊符号已经绰绰有余了(其实ASCII只用了前127个编码)。
美国标准
7位码 128个字符。其中 33 个字符无法显示;可显示的字符为 95 个,编号范围是 32-126(0x20-0x7E)
扩展ASCII-单字节 欧洲字符集
后来欧洲人不干了,法国人说:我需要在小写字母加上变音符号(如:é),德国人说:我也要加几个字母(Ä ä、Ö ö、Ü ü、ß)。于是,欧洲人就将ASCII没用完的编码(128-255)为自己特有的符号编码(后来称之为“扩展字符集”)。
8位码 256个字符

多字节字符集(MBCS)、双字节字符集(DBCS)
等到我们中国人开始使用计算机的时候,尼玛,256个编码哪够?我泱泱大中华,汉字起码也得N多万吧,就连小学生都得要求掌握两三千字。国标局最后拍板:一个字节不够,那我们就用多个字节来为汉字编码吧,但是,国情那么穷,字节那么贵,三个字节伤不起,那就用俩字节吧,先给常用的几千汉字编个码,等以后国家强盛了人民富裕了,咱再扩展呗—于是GB2312就产生了。
台湾同胞一看,尼玛,全是简体字,还让不让我们写繁体字的活了,于是台湾同胞也自己弄了个繁体字编码—大五码(Big-5)。同时,其它国家也在为自己的文字编码。最后,微软苦逼了:顾客就是上帝啊,你们的编码我都得满足啊.
GB2312 和 Big5 就是多字节字符集。因为Windows中用得最多的字符是双字节字符,所以MBCS通常被**双字节字符集(DBCS)**代替。双字节字符集(DBCS)是多字节字符集(MBCS)的一种形式。
DBCS前128个代码是ASCII。但是,后面的128个代码中有些还跟随有第二个字节。这两个字节(称为前导字节和尾随字节)在一起代表一个单独的字符,常常是一个复杂的象形文字。128+128*256 = 32896
双字节字符集的问题不在于字符是由两个字节组成的。问题是有些字符是由一个字节组成的,有些是两个。这就导致了奇怪的编程问题。例如,一个字符串的字符长度不能因字节数量而决定。字符串的长度要解析后才能判断,每个字节都要被检查是不是双字节的前导字节。如果你有一个指针指向一个 DBCS字符串的中间,那前一个字符的地址是什么呢?常规做法是回到字符串的开始,一直解析到指针的位置!
Unicode的解救方案
这里存在的一个基本问题是世界上的书面语言文字根本无法用256个8位代码来表示。以前那些涉及代码页和 DBCS 的解决方法已经被证明是不足和笨拙的。那么什么是真正的解救方案呢?
作为程序员,我们有处理这类问题的经验。与其用很容易混淆的多个256字符的代码映射或者是混合使用有1字节的代码和2字节代码的双字节字符集,还不如使用Unicode一种统一的16位系统,它可以代表65536个字符。这对世界上的所有书面语言的所有字符和象形文字来说都已经足够了,其中还可以包括一批数学、符号以及装饰标志的集合。(这里说的Unicode当作16位 是因为微软默认把Unicode 当做 UTF-16 LB,在之前字符集学习中讲过,历史问题)
了解Unicode和 DBCS之间的区别是必不可少的。Unicode被认为是(特别是在C编程语言环境中)“宽字符”。每一个在 Unicode里的字符是16位宽。与此相反,在双字节字符集中我们仍在处理8位值,某些单字节本身就定义了一个字符,而另一些字节则需要一个额外字节才能完全定义一个字符。
Unicode最棒的地方是,它只有一个字符集。这就避免了二义性,适合国际化。Unicode是通过个人计算机行业几乎所有重要公司间的合作而出现的,而且代码的编制是与ISO 10646-1标准相似的。
然而Unicode是否就尽善尽美了呢?非也。Unicode字符的字符串占用的内存比 ASCII字符串大两倍。但也许最严重的缺点是Unicode仍然相对地还很少被使用。作为程序员,这正是我们要改变的。现今内存大了。
ANSI 代码页
其实ANSI并不是某一种特定的字符编码,而是在不同的系统中,ANSI表示不同的编码。你的美国同事Bob的系统中ANSI编码其实是ASCII编码(ASCII编码不能表示汉字,所以汉字为乱码),而你的系统中(“汉字”正常显示)ANSI编码其实是GBK编码,而韩文系统中(“한국어”正常显示)ANSI编码其实是EUC-KR编码。在日文Windows操作系统中,ANSI 编码代表 JIS 编码
这样吧,卖给美国国内的系统默认就用ASCII编码吧,卖给中国人的系统默认就用GBK编码吧,卖给韩国人的系统默认就用EUC-KR编码,但是为了避免你们误会我卖给你们的系统功能有差异,我就统一把你们的默认编码都显示成ANSI吧。—本故事纯属虚构,但“ANSI编码”确实只存在于Windows系统,不同的语言和区域设置可能使用不同的代码页。
Windows系统如何区分ANSI背后的真实编码?
微软用一个叫“Windows code pages”(在命令行下执行chcp命令可以查看当前code page的值)的值来判断系统默认编码,比如:简体中文的code page值为936(它表示GBK编码,win95之前表示GB2312,详见:Microsoft Windows’ Code Page 936),繁体中文的code page值为950(表示Big-5编码)。
缺点
为减少乱码问题,应用软件可以把字符页信息与文件一起保存,设计代码页之间的转换工作。
代码页的数量剧增。不统一标准,使用情况糟糕。
修改代码页
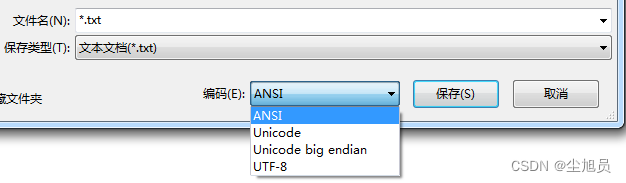
默认的“ANSI”编码方式可以通过修改Windows的区域来修改:
“控制面板” =>“时钟、语言和区域”=>“区域和语言”=>“管理”=>“更改系统区域设置…”
当系统的locale为简体中文,意味着当前“ANSI编码”实际是GBK编码。当你把它改成Korean(Korea)时,“ANSI编码”实际是EUC-KR编码,“한국어”就能正常显示了;当你把它改成English(US)时,“ANSI编码”实际是ASCII编码,“汉字”和“한국어”都成乱码了。(改了之后需要重启系统)
Windows中的Code Page,按照引用领域来划分,可以分为两类:ANSI Code Page和 OEM Code Page。
Windows编程
Windows NT从底层支持Unicode。在Windows NT 上,既可执行为 ASCII、Unicode单写的程序,也可执行为ASCII和 Unicode混合编写的程序。其实这是通过Windows NT支持可以接受8位和16位的字符串的API函数调用来实现的。Windows 98对 Unicode的支持比Windows NT少得多。只有几个Windows 98的API函数支持宽字符串。
为了在将来需要发行支持 Unicode的程序时,你能处于更有利的位置,你应该试着只拥有一个版本的源代码,它既可以被编译成ASCII,也可被编译成Unicode。这就是本书中所有程序的编写方式。
C/C++
两个版本字面量
char str1[] = "1111";//5字符,占5字节,包含 \0
char str2[] = "中中中中";//9字符,占9字节,包含 \0
wchar_t wstr1[] = L"1111";//5个双字符,占10字节,字符串字面量必须带L
wchar_t wstr2[] = L"中中中中";//5个双字符,占10字节,字符串字面量必须带L
两个版本字符类型
作为一个C语言程序员,使用16位字符的整个想法一定让人寒意顿生。
ANSI C标准通过一种叫“宽字符”的概念来支持用多个字节代表一个字符的字符集。宽字符并不一定是Unicode。Unicode只是宽字符编码的一种实现。然而,这里重点是Windows,在Windows中宽字符 和 Unicode作为同义词。
ANSI C还支持多字节字符集,如那些在中文、日语和韩语版本的Windows中支持的字符集。然而,这些多字节字符集被当作单字节值的字符串,在那些字符串里一些字符改变了后续字符的含义。多字节字符集主要影响C语言运行库函数。与此相反,宽字符不仅比正常字符宽,而且涉及编译器的一些问题。
C++提供了两种种字符类型,字符串可以用字符数组和字符串指针。
| 类型 | 大小 | 说明 |
|---|---|---|
| char | 1字节 | char是8位字符类型,最多只能包含256种字符,许多外文字符集所含的字符数目超过256个,char型无法表示。 |
| wchar_t | 2字节 | 一种扩展的字符存储方式,主要用在国际化程序的实现中。 wchar_t数据类型一般为16位或32位,不同的C++库有不同的规定 |
#include <windows.h>
#include <iostream>
int main()
{
char char1 = '1';
char char2 = '中';
wchar_t wchar_t1 = '1';
wchar_t wchar_t2 = '中';
std::cout << char1 << std::endl;//1
std::cout << char2 << std::endl;//无法显示
std::cout << wchar_t1 << std::endl;//49
std::cout << wchar_t2 << std::endl;//54992
char str1[] = "1111";//5字符,占5字节,包含 \0
char str2[] = "中中中中";//9字符,占9字节,包含 \0
wchar_t wstr1[] = L"1111";//5个双字符,占10字节,字符串字面量必须带L
wchar_t wstr2[] = L"中中中中";//5个双字符,占10字节,字符串字面量必须带L
std::cout << str1 << std::endl;//1111
std::cout << str2 << std::endl;//中中中中
std::cout << wstr1 << std::endl;//00000033D22FF7B8
std::cout << wstr2 << std::endl;//00000033D22FF7E8
std::cout << sizeof(char1) << sizeof(char2) << sizeof(wchar_t1) << sizeof(wchar_t2) << std::endl;//1 1 2 2
std::cout << sizeof(str1) << std::endl;//5
std::cout << sizeof(str2) << std::endl;//9
std::cout << sizeof(wstr1) << std::endl;//10
std::cout << sizeof(wstr2) << std::endl;//10
return 0;
}
typedef char CHAR;
typedef wchar_t WCHAR;
CHAR和 WCHAR是写Windows程序时推荐使用的数据类型,这样,我们就有了数据类型CHAR和WCHAR,以及指向CHAR和 WCHAR的各种指针。
两个版本字符指针
//6种 CHAR 指针
typedef CHAR *PCHAR, *LPCH, *PCH;//字符指针
typedef _Null_terminated_ CHAR *NPSTR, *LPSTR, *PSTR;//字符串指针
//4种常量 CHAR 指针
typedef CONST CHAR *LPCCH, *PCCH;//常量字符指针
typedef _Null_terminated_ CONST CHAR *LPCSTR, *PCSTR;//常量字符串指针
//6种 WCHAR 指针
typedef WCHAR *PWCHAR, *LPWCH, *PWCH;
typedef _Null_terminated_ WCHAR *NWPSTR, *LPWSTR, *PWSTR;
//4种常量 WCHAR 指针
typedef CONST WCHAR *LPCWCH, *PCWCH;
typedef _Null_terminated_ CONST WCHAR *LPCWSTR, *PCWSTR;
前缀N和L代表着“近”(near)和“远”(long),指的是16位Windows系统中的两种大小不同的指针。但在 Win32中near和 long指针则没有区别。
Null_terminated 代表空终止字符串,字符串标准库提供的头文件中包含操作以空字符结尾的字符串(null-terminated string)的函数。它们是C++标准特有的一组函数。即为在字符串结尾加上’\0’的字符串。
两个版本库函数
比如,找出一个字符串的长度。如果我们定义了一个指向字符串的指针,我们可以调用库函数strlen,
char * pc = "Hello!";
int iLength = strlen (pc) ;//变量 iLength会被设成6,也就是字符串中字符的个数。
wchar_t *pw = L"Hello! ";
int iLength = strlen (pw) ;//1 错误
现在问题出现了。首先,C编译器会给你一个警告消息,大概是下面这个意思: VS中没有警告
' function' : incompatible types - from 'unsigned short *' to 'const char *
这是在告诉你strlen函数被定义为接受一个指向char 的指针,但这里收到的是一个指向无符号短整型的指针。仍然可以编译运行程序,但你会发现 iLength变成了1。发生了什么呢?
字符串“Hello!”中的6个字符包含的16进制值如下:
0×0048 0x0065 0x006C 0x006c 0x006F Ox0021
这些值被Intel处理器以下面这种方式存储在内存中:
48 00 65 00 6c 00 6c 00 6F 00 21 00
strlen函数,假设它试图找到字符串的长度,计算第一个字节为字符,但然后会认为第二字节00是一个表明字符串结尾的零字节。
这个小小的实验清楚地表明了C语言自身和运行库函数的细微差别?意思时编程时无法检测到误???。编译器将字符串L"Hello! "解释为一个16位短整型的集合并把它们存储在 wchar_t数组。编译器还会处理所有数组索引和sizeof操作符,因此这些都会正常工作。但是,程序运行时,运行库函数(如strlen)是在链接时被增加进去的。这些函数期望收到由单字节字符构成的字符串。因此在遇到宽字符串时,它们不会像我们预期那样执行。
你说,哦,太倒霉了,现在每一个C库函数都要被重写,以接受宽字符。嗯,并非每一个C 库函数。只有那些有字符串参数的。而且你并不需要重写它们,因为重写已经完成了。
宽字符版本的strlen 函数被称为wcslen,也定义在string.h(也就是strlen被定义的地方)和 wchar.h中。函数的声明如下:
size_t __cdecl strlen (const char*);
size_t __cdecl wcslen (const wchar_t* );
请记住,在使用宽字符的时候,字符串的字符长度并没有改变,改变的只是字节长度。
所有你喜爱的C语言中那些使用字符串参数的运行库函数都有宽字符的版本。例如,wprintf 是宽字符版本的printf。这些函数都被定义在 WCHAR.H 和定义正常函数的头文件中。
通用解决方案-维护一个源代码文件
为了方便编程,写一份代码就可以编译成ASCII 或 Unicode两种版本,通用解决方案是使用通用字符类型 TCHAR、通用字符字面量TEXT()、通用函数定义、加上字符集切换。
#ifdef UNICODE
typedef wchar_t TCHAR;
#else
typedef unsigned char TCHAR;
#endif
#ifdef UNICODE
#define MessageBox MessageBoxW
#else
#define MessageBox MessageBoxA
#endif // !UNICODE
当然,使用Unicode肯定也有某些缺点。首先同时也是最重要的是,程序中的每一个字符串会占用两倍的空间。此外,你会看到,宽字符运行库函数比正常的函数要大。为此,你可能希望创建两个版本的程序,一个用ASCII字符串而另一个使用Unicode字符串。而最好的办法则是维护一个单一的源代码文件,但可以编译成ASCII 或 Unicode。
但这是有问题的,因为运行库函数具有不同名称,字符变量的定义也不同,还有那个讨厌的在字符串字面之前必须要加的L。
一个答案是使用包含在 Microsoft Visual C++中的TCHAR.H头文件。这个头文件并不是ANSI C标准的一部分,所以其中定义的每一个函数和宏都有一个下划线前缀。TCHAR.H为那些需要字符串参数的普通运行库函数(例如,_tprintf 和_tcslen)提供了一系列的替代名称。这些函数有时被称为“通用”的函数名字,因为它们可以指Unicode或非 Unicode版本的函数。
通用函数
比如字符串处理函数_tcslen
如果一个命名为_UNICODE的标识符被定义了并且TCHAR.H头文件被包含在你的程序中,_tcslen就被定义为wcslen,否则_tcslen就被定义为strlen::
#ifdef _UNICODE
#define _tcslen wcslen
#else
#define _tcslen strlen
#endif
TCHAR* pw = _TEXT("Hello! ");
int iLength2 = _tcslen(pw);
通用字符类型 TCHAR
以此类推。TCHAR.H也用一个命名为TCHAR的新的数据类型解决了两个字符数据类型的问题。如果_UNICODE标识符被定义了﹒TCHAR就是wchar_t,否则TCHAR就是一个简单的char:
#ifdef UNICODE
typedef WCHAR TCHAR, *PTCHAR;
#else
typedef char TCHAR, *PTCHAR;
#endif
//x86 使用Unicode字符集
TCHAR c1 = _T('a');//97 'a'
int a = sizeof(c1);//2
TCHAR* pc = _T('a');//0x00000070 读取字符串时出错
a = sizeof(pc);//4
TCHAR s1= _TEXT("Hello!");//这被当做一个字符 31536'笰'
a = sizeof(s1);//2
TCHAR* ps = _TEXT("Hello!");//0x00c67b30 "Hello!"
a = sizeof(ps);//4
//x86 使用多字节字符集
TCHAR c1 = _T('a');//97 'a'
int a = sizeof(c1);//1
TCHAR* pc = _T('a');//0x00000070 读取字符串时出错
a = sizeof(pc);//4
TCHAR s1= _TEXT("Hello!");//这被当做一个字符 48'0'
a = sizeof(s1);//1
TCHAR* ps = _TEXT("Hello! ");//0x00c67b30 "Hello!"
a = sizeof(ps);//4
通用字符指针
//解决指针的
#ifdef UNICODE
typedef WCHAR TCHAR,*PTCHAR;
typedef LPWCH LPTCH, PTCH;
typedef LPCWCH LPCTCH, PCTCH;
typedef LPWSTR PTSTR, LPTSTR;
typedef LPCWSTR PCTSTR, LPCTSTR;
#else
typedef char TCHAR, *PTCHAR;
typedef LPCH LPTCH, PTCH;
typedef LPCCH LPCTCH, PCTCH;
typedef LPSTR PTSTR, LPTSTR, PUTSTR, LPUTSTR;
typedef LPCSTR PCTSTR, LPCTSTR, PCUTSTR, LPCUTSTR;
#endif
通用字符字面量 _T _TEXT TEXT
char a = '1';
wchar_t a = L'1';//
现在是时候来解决字符字面量 L这一棘手的问题。有三个宏效果一样,一般用TEXT
-
_T 定义于tchar.h
-
_TEXT 同样定义于tchar.h
-
TEXT 定义于winnt.h (推荐)
为什么有三个?估计是历史遗留问题,兼容问题,Jeffrey Richter在《Windows核心编程》中说,_UNICODE宏用于C运行期头文件,而UNICODE宏则用于Windows头文件.当编译源代码模块时,通常必须同时定义这两个宏.
//tchar.h
#ifdef _UNICODE//如果_UNICODE标识符被定义
#define __T(x) L ## x
#else//如果_UNICODE标识符没有被定义,_T宏就简单地如下定义:
#define __T(x) x
#endif
//无论_UNICODE是否被定义
#define _T(x) __T(x)
#define _TEXT(x) _T(×)
--------------------------------------------------
//winnt.h
#define TEXT(quote) __TEXT(quote) // r_winnt
#ifdef UNICODE
#define __TEXT(quote) L##quote
#else
#define __TEXT(quote) quote
#endif
这样做的结果是,如果_UNICODE标识符被定义了,字符串就被解释为是由宽字符组成的,如果没有被定义,它则被解释为8位的字符串。
字符集切换
作用:让通用方案起作用。
Windows中使用printf
有个坏消息是:不能在 Windows程序中使用printf函数。虽然可以在Windows 中使用绝大多数的C语言运行库函数—实际上,相较于Windows中相应的函数,很多程序员更愿意使用C的内存管理和文件I/O函数─—但是Windows不存在标准输入和标准输出的概念。所以你可以在Windows程序中使用 fprintf 函数,但不能使用printf函数。
而好消息则是:你仍然可以使用sprintf和 sprintf系列的其他函数来显示文本。除了将格式化后的字符串内容输出到函数第一个参数所提供的字符串缓冲区以外,这些函数的功能和 printf函数一样。然后就可以用这个字符串做任何事(例如,可以将输出字符串传给MessageBox)。
-
printf
格式化并输出到标准输出
-
sprintf
格式化并返回一个字符串,不直接输出
-
fprintf
格式化并输出到指定的输出流(文件、标准输出等)
int printf (const char * szFormat, ...);//第一个参数是一个格式字符串,后面是与格式字符串中的代码相对应的不同类型的多个参数。
int sprintf (char* szBuffer,const char * szFormat, ...);//第一个参数是一个字符缓冲区;后面是一个格式字符串。sprintf并不是将格式化结果写到标准输出,而是将其存入 szBuffer。该函数返回该字符串的长度。
几乎每个人都有这样的经验,一旦格式字符串与被格式化的变量不合,就可能会导致printf出错并可能造成程序崩溃。使用sprintf时,除此之外还要考虑一点:定义的字符串缓冲区必须足够大以存放结果。Microsoft的专用函数_snprintf解决了这一问题,此函数引进了另一个参数来指定字符缓冲区的大小。
sprintf还有一个变形函数 vsprintf,它只有三个参数。当需要对可变参数执行像printf一样的格式化时,可以用vsprintf来实现你自己的函数。vsprintf 的前两个参数与sprintf相同:一个用于保存结果的字符缓冲区和一个格式字符串。第三个参数是指向待格式化的参数数组的指针。
因为很多早期的Windows程序使用了sprintf和vsprintf,最终导致Microsoft在WindowsAPI中增添了两个相似的函数。Windows版的 wsprintf和 wvsprintf 函数在功能上与sprintf和 vsprintf相同,不同的是它们不能处理浮点格式。
当然,随着宽字符的引入,sprintf 系列的函数增加了许多,使得函数名让人困惑。下表列出了Microsoft版的C语言运行库和 Windows所支持的所有sprintf类函数。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8saJvLwG-1678928709425)(assets/image-20221208124127-fgr64uf.png)]](https://img-blog.csdnimg.cn/e83b42a21fef4638aebb613a8649f953.png)
格式化你的消息框
图2-3所示的SCRNSIZE程序展示了如何实现MessageBoxPrintf函数,该函数能像printf那样接收各种各样大量的参数并对它们进行格式化。
新版本中已经不能运行。把 _vsntprintf 换成 _vsntprintf_s 即可。
#include <windows.h>
#include <tchar.h>
#include <stdio.h>
int CDECL MessageBoxPrintf(TCHAR* szCaption, TCHAR* szFormat, ...)
{
TCHAR szBuffer[256];
va_list pArgList;
// va_start宏(在STDARG.H中定义)通常等价于:
// pArgList = (char *) &szFormat + sizeof (szFormat) ; 取常量字符串指针szFormat的指针
va_start(pArgList, szFormat);
// wvsprintf的最后一个参数指向这些参数
_vsntprintf_s(szBuffer, sizeof(szBuffer) / sizeof(TCHAR), 256,szFormat, pArgList);
// va_end宏只是把pArgList归零
va_end(pArgList);
return MessageBox(NULL, szBuffer, szCaption, 0);
}
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, PSTR szCmdLine, int iCmdShow)
{
int cxScreen, cyScreen;
cxScreen = GetSystemMetrics(SM_CXSCREEN);//1920
cyScreen = GetSystemMetrics(SM_CYSCREEN);//1080
MessageBoxPrintf(TEXT("屏幕大小"),
TEXT("The screen is %i pixels wide by %i pixels high."),
cxScreen, cyScreen);
return 0;
}
国际化
当你为准备国际市场而编写Windows程序时,它不仅仅只是使用Unicode那么简单。国际化已经超出了本书的范围,在 Nadine Kano所著的Developing International Software forWindows 95 and Windows NT(Microsoft Press,1995)一书中囊括了更多内容。
这里只讨论怎样通过定义UNICODE 标识符来编译程序。这包括使用TCHAR定义所有的字符和字符串,对字符串文本使用TEXT宏,以及注意不要混淆字节和字符。例如,注意SCRNSIZE 中的_vsntprintf调用。它的第二个参数是字符缓冲区的长度。通常,你会使用sizeof(szBuffer),但如果缓冲区中有宽字符,那么它返回的将不是缓冲区的字符长度,而是缓冲区按字节计算机的长度。所以必须把返回值除以sizeof(TCHAR)以得到正确的字符串长度。
智能推荐
c# 调用c++ lib静态库_c#调用lib-程序员宅基地
文章浏览阅读2w次,点赞7次,收藏51次。四个步骤1.创建C++ Win32项目动态库dll 2.在Win32项目动态库中添加 外部依赖项 lib头文件和lib库3.导出C接口4.c#调用c++动态库开始你的表演...①创建一个空白的解决方案,在解决方案中添加 Visual C++ , Win32 项目空白解决方案的创建:添加Visual C++ , Win32 项目这......_c#调用lib
deepin/ubuntu安装苹方字体-程序员宅基地
文章浏览阅读4.6k次。苹方字体是苹果系统上的黑体,挺好看的。注重颜值的网站都会使用,例如知乎:font-family: -apple-system, BlinkMacSystemFont, Helvetica Neue, PingFang SC, Microsoft YaHei, Source Han Sans SC, Noto Sans CJK SC, W..._ubuntu pingfang
html表单常见操作汇总_html表单的处理程序有那些-程序员宅基地
文章浏览阅读159次。表单表单概述表单标签表单域按钮控件demo表单标签表单标签基本语法结构<form action="处理数据程序的url地址“ method=”get|post“ name="表单名称”></form><!--action,当提交表单时,向何处发送表单中的数据,地址可以是相对地址也可以是绝对地址--><!--method将表单中的数据传送给服务器处理,get方式直接显示在url地址中,数据可以被缓存,且长度有限制;而post方式数据隐藏传输,_html表单的处理程序有那些
PHP设置谷歌验证器(Google Authenticator)实现操作二步验证_php otp 验证器-程序员宅基地
文章浏览阅读1.2k次。使用说明:开启Google的登陆二步验证(即Google Authenticator服务)后用户登陆时需要输入额外由手机客户端生成的一次性密码。实现Google Authenticator功能需要服务器端和客户端的支持。服务器端负责密钥的生成、验证一次性密码是否正确。客户端记录密钥后生成一次性密码。下载谷歌验证类库文件放到项目合适位置(我这边放在项目Vender下面)https://github.com/PHPGangsta/GoogleAuthenticatorPHP代码示例://引入谷_php otp 验证器
【Python】matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距-程序员宅基地
文章浏览阅读4.3k次,点赞5次,收藏11次。matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距
docker — 容器存储_docker 保存容器-程序员宅基地
文章浏览阅读2.2k次。①Storage driver 处理各镜像层及容器层的处理细节,实现了多层数据的堆叠,为用户 提供了多层数据合并后的统一视图②所有 Storage driver 都使用可堆叠图像层和写时复制(CoW)策略③docker info 命令可查看当系统上的 storage driver主要用于测试目的,不建议用于生成环境。_docker 保存容器
随便推点
网络拓扑结构_网络拓扑csdn-程序员宅基地
文章浏览阅读834次,点赞27次,收藏13次。网络拓扑结构是指计算机网络中各组件(如计算机、服务器、打印机、路由器、交换机等设备)及其连接线路在物理布局或逻辑构型上的排列形式。这种布局不仅描述了设备间的实际物理连接方式,也决定了数据在网络中流动的路径和方式。不同的网络拓扑结构影响着网络的性能、可靠性、可扩展性及管理维护的难易程度。_网络拓扑csdn
JS重写Date函数,兼容IOS系统_date.prototype 将所有 ios-程序员宅基地
文章浏览阅读1.8k次,点赞5次,收藏8次。IOS系统Date的坑要创建一个指定时间的new Date对象时,通常的做法是:new Date("2020-09-21 11:11:00")这行代码在 PC 端和安卓端都是正常的,而在 iOS 端则会提示 Invalid Date 无效日期。在IOS年月日中间的横岗许换成斜杠,也就是new Date("2020/09/21 11:11:00")通常为了兼容IOS的这个坑,需要做一些额外的特殊处理,笔者在开发的时候经常会忘了兼容IOS系统。所以就想试着重写Date函数,一劳永逸,避免每次ne_date.prototype 将所有 ios
如何将EXCEL表导入plsql数据库中-程序员宅基地
文章浏览阅读5.3k次。方法一:用PLSQL Developer工具。 1 在PLSQL Developer的sql window里输入select * from test for update; 2 按F8执行 3 打开锁, 再按一下加号. 鼠标点到第一列的列头,使全列成选中状态,然后粘贴,最后commit提交即可。(前提..._excel导入pl/sql
Git常用命令速查手册-程序员宅基地
文章浏览阅读83次。Git常用命令速查手册1、初始化仓库git init2、将文件添加到仓库git add 文件名 # 将工作区的某个文件添加到暂存区 git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件...
分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120-程序员宅基地
文章浏览阅读202次。分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120
【C++缺省函数】 空类默认产生的6个类成员函数_空类默认产生哪些类成员函数-程序员宅基地
文章浏览阅读1.8k次。版权声明:转载请注明出处 http://blog.csdn.net/irean_lau。目录(?)[+]1、缺省构造函数。2、缺省拷贝构造函数。3、 缺省析构函数。4、缺省赋值运算符。5、缺省取址运算符。6、 缺省取址运算符 const。[cpp] view plain copy_空类默认产生哪些类成员函数