【C++】 内联函数详解(搞清内联的本质及用法)_c++内联函数-程序员宅基地
目录
一.什么是内联函数
1.直观上定义:
联函数的定义与普通函数基本相同,只是在函数定义前加上关键字 inline。
inline void print(char *s)
{
printf("%s", s);
}2.更深入的思考:
- 函数前面加上inline一定会有效果吗?
- 如果不加inline就不是内联函数了吗?
后面让我们慢慢来解答这两个问题 内联函数和编译过程的相爱相杀
二.为什么使用内联函数
- 内联函数最初的目的:代替部分 #define 宏定义;
- 使用内联函数替代普通函数的目的:提高程序的运行效率;
针对上述两个方面我们展开讨论:
1.为什么要代替部分宏定义
- 宏是预处理指令,在预处理的时候把所有的宏名用宏体来替换;内联函数是函数,在编译阶段把所有调用内联函数的地方把内联函数插入;
- 宏没有类型检查,无论对还是错都是直接替换;而内联函数在编译时进行安全检查;
- 宏的编写有很多限制,例如只能写一行,不能使用return控制流程等;
- 对于C++ 而言,使用宏代码还有另一种缺点:无法操作类的私有数据成员。
2.普通函数频繁调用的过程消耗栈空间
函数是一个可以重复使用的代码块,CPU 会一条一条地挨着执行其中的代码。CPU 在执行主调函数代码时如果遇到了被调函数,主调函数就会暂停,CPU 转而执行被调函数的代码;被调函数执行完毕后再返回到主调函数,主调函数根据刚才的状态继续往下执行。
一个 C/C++程序的执行过程可以认为是多个函数之间的相互调用过程,它们形成了一个或简单或复杂的调用链条,这个链条的起点是main(),终点也是main()。当main()调用完了所有的函数,它会返回一个值(例如return 0;)来结束自己的生命,从而结束整个程序。
函数调用是有时间和空间开销的。程序在执行一个函数之前需要做一些准备工作,要将实参、局部变量、返回地址以及若干寄存器都压入栈中,然后才能执行函数体中的代码;函数体中的代码执行完毕后还要清理现场,将之前压入栈中的数据都出栈,才能接着执行函数调用位置以后的代码。
栈空间就是指放置程式的局部数据也就是函数内数据的内存空间,在系统下,栈空间是有限的,假如频繁大量的使用就会造成因栈空间不足所造成的程式出错的问题,函数的死循环递归调用的最终结果就是导致栈内存空间枯竭。
如果函数体代码比较多,需要较长的执行时间,那么函数调用机制占用的时间可以忽略;如果函数只有一两条语句,那么大部分的时间都会花费在函数调用机制上,这种时间开销就就不容忽视。
具体的一个调用效率讨论在第六章节 内联函数的类方法实现
为了消除函数调用的时空开销,C++ 提供一种提高效率的方法,即在编译时将函数调用处用函数体替换,类似于C语言中的宏展开。这种在函数调用处直接嵌入函数体的函数称为内联函数(Inline Function)。但也存在缺点,就是每一调用处均会展开,增加了重复的代码量。
可以理解为内联函数的关键词是:替换
3.更深入的思考
通过上述内容我们知道内联函数是在调用的地方展开函数定义,那么问题又来了,展开也好,替换也好,都存在下面两个问题:
- 内联函数一定就会展开吗?
- 在什么情况下内联函数会展开?
三.内联函数和编译过程的相爱相杀
在这一节,我们先一口气回答前两节的所有问题,然后慢慢引出后面的话题。
- 函数前面加上inline一定会有效果吗?
答:不会,使用内联inline关键字修饰函数只是一种提示,编译器不一定认。
- 如果不加inline就不是内联函数了吗?
答:存在隐式内联,不用inline关键字,C++中在类内定义的所有函数都自动称为内联函数。
- 内联函数一定就会展开吗?
答:其实和第一个问题类似,还是看编译器认不认。
- 在什么情况下内联函数会展开?
答:首先需要满足有inline修饰或者是类中的定义的函数,然后再由编译器决定。
其实说白了,内联函数管不管用是由编译器说了算的!
那如何要求编译器展开内联函数呢?
- 编译器开优化:gcc -O2 test.c -o test,只有在编译器开启优化选项的时候,才会有inline行为的存在,比如对g++在-O0时就不会作任何的inline处理,对于-O2的优化方式,编译器会通过启发式算法决定是否值得对一个函数进行内联,同时要保证不会对生成文件的大小产生较大影响。 而-O3模式则不在考虑生成文件的大小;
- 使用attribute属性:static inline __attribute__((always_inline)) int add_i(int a,int b);
- 使用auto_inline:#pragma auto_inline(on/off),当使用#pragma auto_inline(off)指令时,会关闭对函数的inline处理,这时即使在函数前面加了inline指令,也不会对函数进行内联处理。
上述操作都仅仅是对编译器提出内联的建议,最终是否进行内联由编译器自己决定,大多数编译器拒绝它们认为太复杂的内联函数(例如,那些包含循环或者递归的),而且类的构造函数、析构函数和虚函数往往不是内联函数的最佳选择。
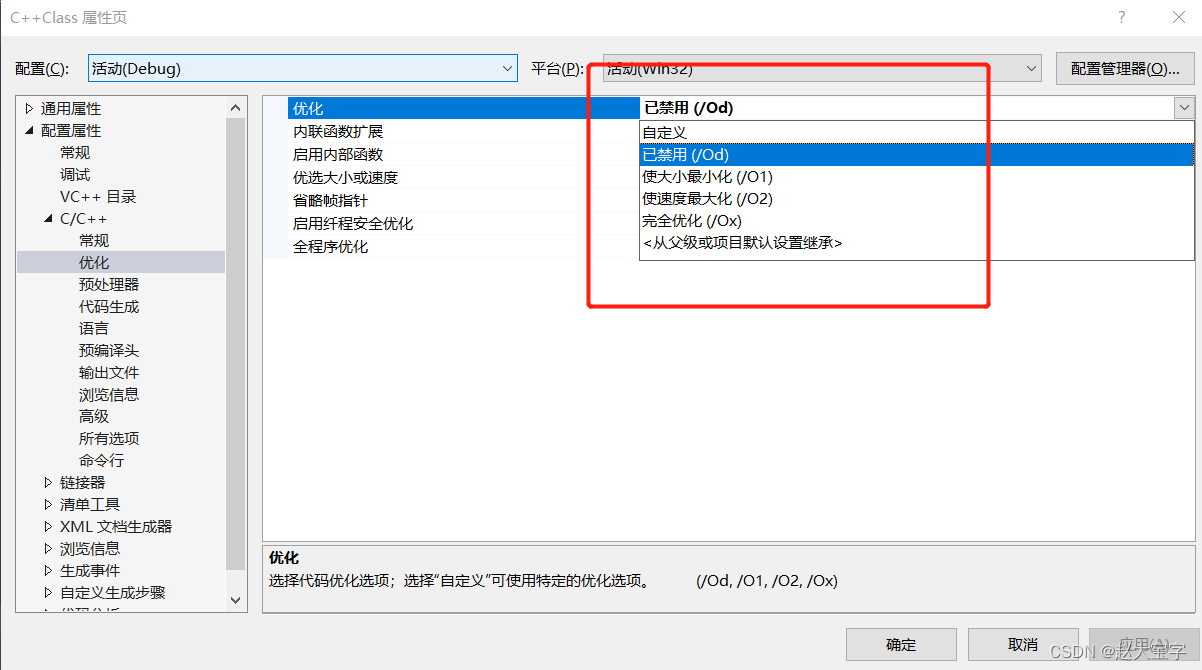
有关visual studio中编译优化选择的位置如图,gcc编译见上面的例子也可以直接man gcc查看。
四.内联函数怎么用,在哪儿用?
基本介绍完内联的概念,接下来说说内联怎么用,在哪儿用?
内联函数是定义在头文件还是源文件?
内联展开是在编译时进行的,只有链接的时候源文件之间才有关系。所以内联要想跨源文件必须把实现写在头文件里。如果一个内联函数会在多个源文件中被用到,那么必须把它定义在头文件中
内联函数的定义不一定要跟声明放在一个头文件里面:定义可以放在一个单独的头文件中,里面需要给函数定义前加上inline 关键字,原因看下面第 2.点;然后声明 放在另一个头文件中,此文件include上一个头文件。这种用法 boost里很常见:优点1. 实现跟API分离封装。优点2. 可以解决有关inline函数的循环调用问题。
1.隐式内联:如第三节说的C++中在类内定义的所有函数都自动称为内联函数,类的成员函数的定义直接写在类的声明中时,不需要inline关键字
#include <stdio.h>
class Trace{
public:
Trace()
{
noisy = 0;
}
void print(char *s)
{
if (noisy)
{
printf("%s", s);
}
}
void on(){ noisy = 1; }
void off(){ noisy = 0; }
private:
int noisy;
};2.显示内联:需要使用inline关键字
#include <stdio.h>
class Trace{
public:
Trace()
{
noisy = 0;
}
void print(char *s); //类内没有显示声明
void on(){ noisy = 1; }
void off(){ noisy = 0; }
private:
int noisy;
};
//类外显示定义
inline void Trace::print(char *s)
{
if (noisy)
{
printf("%s", s);
}
}五.内联函数和重定义
这一部分我们带着问题一步步进行分析思考
- 什么是重定义?
答:C/C++语法中,如果变量、函数在同一个工程中被多次定义,链接期间会报类似“对 xxx 多重定义”的错误。
当内联函数的声明和定义分别在头文件和源文件中,并且在其他文件中被调用时,链接期间编译器会报“对 xxx 未定义的引用”错误。内联函数如果会在多处被调用,则需要将函数的定义写在头文件中。
- 为什么inline关键字修饰的函数定义在头文件中(函数可能会被多次定义),编译器不会报“对 xxx 多重定义”的错误呢?
答:编译器对被inline修饰的函数做了特殊处理,inline起到了内联的作用;
- inline为什么能起作用?
答:因为inline是一个弱符号;
- 什么是弱符号?
答:在C语言中,编译器默认函数和初始化了的全局变量为强符号(Strong Symbol),未初始化的全局变量为弱符号(Weak Symbol)。强符号之所以强,是因为它们拥有确切的数据,变量有值,函数有函数体;弱符号之所以弱,是因为它们还未被初始化,没有确切的数据。
链接器会按照如下的规则处理被多次定义的强符号和弱符号:
1) 不允许强符号被多次定义,也即不同的目标文件中不能有同名的强符号;如果有多个强符号,那么链接器会报符号重复定义错误。
2) 如果一个符号在某个目标文件中是强符号,在其他文件中是弱符号,那么选择强符号。
3) 如果一个符号在所有的目标文件中都是弱符号,那么选择其中占用空间最大的一个。
- 怎么知道inline是个弱符号的?
答:反汇编:objdump -dS test,看下面两个例子:
下面两个.cpp文件,除Function()的inline修饰符外其他内容完全一致
1.正常的函数
/* NormalMain.cpp */
#include <cstdio>
void Function()
{
printf("[Function]========= Get!!!\n");
}
int main() {
Function();
}
汇编结果 :
.file "NormalMain.cpp"
.section .rodata
.LC0:
.string "[Function]========= Get!!!"
.text
.globl _Z8Functionv
.type _Z8Functionv, @function
_Z8Functionv:
;...
2.内联函数
/* InlineMain.cpp */
#include <cstdio>
inline void Function()
{
printf("[Function]========= Get!!!\n");
}
int main() {
Function();
}
汇编结果 :
.file "InlineMain.cpp"
.section .rodata
.LC0:
.string "[Function]========= Get!!!"
.section .text._Z8Functionv,"axG",@progbits,_Z8Functionv,comdat
.weak _Z8Functionv
.type _Z8Functionv, @function
_Z8Functionv:
;...
很容易发现,inline修饰的Function()编译结果是.weak弱符号,而没有被inline修饰的Function()编译结果是.globl全局符号(强符号) 因此,如果一个符号在所有的目标文件中都是弱符号,那么选择其中占用空间最大的一个,那么问题又来了:
- 如果 1.obj 和 2.obj 中同名的 inline 函数体,它们的实现代码不一样会如何?
答:按理说选择其中占用空间最大的一个,但是链接器选了最偷懒的方案,会挑最先碰到的那个来用,甚至不会给出警告。
所以内联函数里面坑很多,即使因为inline的弱符号特性避免了重定义,但是也会出现其他坑,比如编译器优化开关关闭时,inline函数可能会被同名的其它函数替代,弱符号被强符号代替,从而影响业务逻辑的正确性。
/* InlineMain.cpp */
#include <cstdio>
inline void Function()
{
printf("[Function]========= Get!!!\n");
}
/* FunctionDef.cpp */
#include <cstdio>
void Function()
{
printf("[Another Function]========= Get!!!\n");
}
int main() {
Function();
}
运行结果为
[Another Function]========= Get!!!
编译器优化开关打开时,运行结果正常不存在问题。
[Function]========= Get!!!
六.内联函数的类方法实现
大家都知道,C++相比于C来说,多了Class这一用法,增加了面向对象编程的思想,也有很多人称C++为C With Class,C++比C语言上多了类这一特性,从函数内联的角度上来讨论分析一下类实现内联函数和不使用类的C风格函数在效率上直观的区别。
1.C++类实现
C++中在类内定义的所有函数都自动称为内联函数(隐式内联)
内联函数本身也是一个真正的函数,具有普通函数的所有行为,唯一不同之处在于内联函数会在适当地方像预定义宏一样展开,在程序运行时不再进行函数调用和返回,从而消除函数调用和返回的系统开销,提高了程序执行效率。
#include <stdio.h>
class Trace{
public:
Trace()
{
noisy = 0;
}
void print(char *s)
{
if (noisy)
{
printf("%s", s);
}
}
void on(){ noisy = 1; }
void off(){ noisy = 0; }
private:
int noisy;
};对于Trace类来说,其中的成员函数定义在类内,C++会内联扩展他们
int main()
{
Trace t;
t.print("inline function");
return 0;
}2.C语言不用类实现
在C语言中,如果一些函数被频繁调用,不断地有函数入栈,即函数栈,会造成栈空间或栈内存的大量消耗。
#include <stdio.h>
static int noisy = 1;
void trace(char *s)
{
if(noisy)printf("%s", s);
}
void trace_on(){ noisy = 1; }
void trace_off(){ noisy = 0; }
int main()
{
trace("trace");
return 0;
}上述代码中还引入了更多的全局变量,C++只有一个,C有三个
五.内联与宏
第二节已经基本说明为什么使用内联函数代替宏,下面举一个例子说明。
在C程序中,可以用宏代码提高执行效率。宏代码本身不是函数,但使用起来象函数。预处理器用复制宏代码的方式代替函数调用,省去了参数压栈、生成汇编语言的CALL调用、 返回参数、执行return等过程,从而提高了速度。
使用宏代码最大的缺点是容易出错,预处理器在复制宏代码时常常产生意想不到的边际效应。宏看起来像函数调用,但没有参数类型及返回值,实际会有隐藏的难以发现的问题,例如执行ans = MyAdd(2, 3)*2时会返回2+3*2。
六.内联的局限性
内联能提高函数的执行效率,为什么不把所有的函数都定义成内联函数?
1.内联是以代码膨胀(复制)为代价,仅仅省去了函数调用的开销,从而提高函数的执行效率。如果执行函数体内代码的时间,相比于函数调用的开销较大,那么效率的收获会很少。(一般情况,在函数频繁调用且函数内部代码很少的情况下使用内联)
2.每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。
3.类的构造函数和析构函数容易让人误解成使用内联更有效。要当心构造函数和析构函数可能会隐藏一些行为,如“偷偷地”执行了基类或成员对象的构造函数和析构函数。所以不要随便地将构造函数和析构函数的定义体放在类声明中。
4.一个好的编译器将会根据函数的定义体,自动地取消不值得的内联。对函数作inline声明只是程序员对编译器提出的一个建议,而不是强制性的,并非一经指定为inline编译器就必须这样做。编译器有自己的判断能力,它会根据具体情况决定是否这样做。一个好的编译器将会根据函数的定义体,自动地取消不值得的内联(这进一步说明了inline 不应该出现在函数的声明中)。具体是否会被编译器优化为内联也要看优化级别。有些函数即使声明为内联的也不一定会被编译器内联,这点很重要。比如虚函数和递归函数就不会被正常内联。通常,递归函数不应该声明成内联函数。(递归调用堆栈的展开并不像循环那么简单,比如递归层数在编译时可能是未知的,大多数编译器都不支持内联递归函数)。虚函数内联的主要原因则是想把它的函数体放在类定义内,为了图个方便,抑或是当作文档描述其行为, 比如精短的存取函数。将内联函数放在头文件里实现是合适的,省却你为每个文件实现一次的麻烦。而所以声明跟定义要一致,其实是指,如果在每个文件里都实现一次该内联函数的话,那么,最好保证每个定义都是一样的,否则,将会引起未定义的行为,即是说,如果不是每个文件里的定义都一样,那么,编译器展开的是哪一个,那要看具体的编译器而定。所以,最好将内联函数定义放在头文件中。
七.内联的使用建议
使用:
当对程序执行性能有要求时,那么就适当使用内联函数
当你想宏定义一个函数时,使用内联函数
写一些功能专一且性能关键的函数,这些函数的函数体不大,包含了很少的执行语句。通过inline声明,编译器不需要跳转到内存其他地址去执行函数调用,也不需要保留函数调用时的现场数据。
在类内部定义的函数会默认声明为inline函数,这有利于 类实现细节的隐藏。(但也需要斟酌如果不需要隐藏的时候,其实大部分是不推荐默认inline的)
不使用:
不使用:如果函数体内的代码比较长,使用内联将导致内存消耗代价较高。
不使用:如果函数体内出现循环或者开关语句;那么执行函数体内代码的时间要比函数调用的开销大。
八.内联和static
多数情况下,inline 前面会加static关键字。why?
分开理解:
static 意味着本地化,每个包含头文件的C文件均在本地产生一个独立的内联函数。当有多个C文件包含头文件时,不会因为函数名相同而报重定义错误。(代价就是 代码所占的空间会变大)
谨慎使用 static:如果只是想把函数定义写在头文件中,用 inline,不要用static。static 和 inline 不一样:
- static 的函数是 internal linkage。不同编译单元可以有同名的static 函数,但该函数只对 对应的编译单元 可见。如果同一定义的 static 函数,被不同编译单元调用,每个编译单元有自己单独的一份拷贝,且此拷贝只对 对应的编译单元 可见。
- inline 的函数是 external linkage,如果被不同编译单元调用,每个编译单元引用/链接的是同一函数,同一定义。
- 上面的不同直接导致:如果函数内有 static 变量,对inline 函数,此变量对不同编译单元是共享的(Meyer's Singleton);对于static 函数,此变量不是共享的。看后面的代码就明白区别了。
static inline 函数,跟 static 函数单独没有差别,所以没有意义,只会混淆视听。
智能推荐
yii2框架-yii2的组件和服务定位器(四)_yii2 unknown component id: db-程序员宅基地
文章浏览阅读4.4k次,点赞3次,收藏4次。上一节主要是分析了yii2的自动加载函数,下面在分析一下yii2的核心组件与服务定位器。其实yii2的核心组件主要有以下://日志组件'log' => ['class' => 'yii\log\Dispatcher'],//视图组件,这个组件代表视图文件中的$this'view' => ['class' => 'yii\web\View'],//格式化组件,将一些输出按照一_yii2 unknown component id: db
SystemVerilog总结_systemverilog语法-程序员宅基地
文章浏览阅读6.9k次,点赞24次,收藏315次。基于SV绿皮书的systemverilog总结_systemverilog语法
2024 EasyRecovery三分钟帮你恢复 电脑硬盘格式化-程序员宅基地
文章浏览阅读1.5k次,点赞43次,收藏13次。在格式化过程中,硬盘上的所有数据并没有被擦除,而是被标记为可覆盖状态,这意味着只要数据没有被新数据完全覆盖,仍然有可能各种技术手段对其进行恢复性操作。需要注意的是,在对硬盘进行恢复性操作之前,我们需要让硬盘保持刚刚格式化的数据状态,不要再做任何删除或者存储的动作,以免对原数据产生覆盖。如果遇到电脑硬盘被格式化后,第一步要做的是暂停对该硬盘的使用,其次是搜索并下载一款专业性强且口碑不错的数据恢复软件自主恢复数据。4.等待软件扫描结束,从扫描结果中选择需要被恢复的数据后单击“恢复”即可找回丢失的数据。_easyrecovery
基于微信小程序的微信平台签到系统的设计与实现(源码+lw+部署文档+讲解等)_微信扫码签到小程序开发-程序员宅基地
文章浏览阅读999次,点赞15次,收藏20次。博主介绍:全网粉丝15W+,CSDN特邀作者、211毕业、高级全栈开发程序员、大厂多年工作经验、码云/掘金/华为云/阿里云/InfoQ/StackOverflow/github等平台优质作者、专注于Java、小程序技术领域和毕业项目实战,以及程序定制化开发、全栈讲解、就业辅导精彩专栏 推荐订阅2023-2024年最值得选的微信小程序毕业设计选题大全:100个热门选题推荐2023-2024年最值得选的Java毕业设计选题大全:500个热门选题推荐Java精品实战案例《500套》_微信扫码签到小程序开发
基于SpringBoot+Vue+uniapp的实验室考勤管理系统的详细设计和实现(源码+lw+部署文档+讲解等)-程序员宅基地
文章浏览阅读587次,点赞14次,收藏9次。博主介绍:全网粉丝15W+,CSDN特邀作者、211毕业、高级全栈开发程序员、大厂多年工作经验、码云/掘金/华为云/阿里云/InfoQ/StackOverflow/github等平台优质作者、专注于Java、小程序技术领域和毕业项目实战,以及程序定制化开发、全栈讲解、就业辅导精彩专栏 推荐订阅2023-2024年最值得选的微信小程序毕业设计选题大全:100个热门选题推荐2023-2024年最值得选的Java毕业设计选题大全:500个热门选题推荐Java精品实战案例《500套》
程序员有多难撩?网友:已读不回的都是渣男?-程序员宅基地
文章浏览阅读377次。作为打工人,相信很多小伙伴都有过这样的经历,在求职平台上主动给HR发消息,却总是“已读不回”.... 是HR 没有看到吗?还是HR觉得我不合适呢?但是,最近播妞在某平台上看到,有位公司的猎..._程序员 渣男
随便推点
快手app抓包方案常见的初探_快手抓包无网络-程序员宅基地
文章浏览阅读9k次,点赞3次,收藏14次。作为一个快手资深用户,每天使用快手app看老铁直播,出于兴趣,曾经对快手接口进行过简单研究,年前写过一个小玩意发送弹幕发送跟老铁互喷!前两天想看下是否好使,发现快手app新版本限制抓包了,那就先研究一下快手app抓包吧!经过一下午的研究,发现可以通过一下三种方式,对app就行http抓包!使用的工具: charles, root过的安卓手机一台 不同版本的快手apk1,降低apk版本[快手版本6.8]进过测试,发现降低版本可以进行抓包,测试版本6.8.0抓包通过!但缺点也很明显,apk过于老旧,_快手抓包无网络
万能数据恢复大师官方版_数据恢复大师新版-程序员宅基地
文章浏览阅读1.2k次。万能数据恢复大师是非常强大的数据恢复软件。它能够恢复误删除、误格式化、U盘\手机储存卡、分区丢失后的数据,及时拯救您宝贵的数据。_数据恢复大师新版
python distribute是什么-程序员宅基地
文章浏览阅读388次,点赞8次,收藏9次。你可以自己找到最新版本的Distribute,在这里https://pypi.python.org/pypi/distribute。可以通过distribute_setup.py 脚本来安装Distribute,也可以通过easy_install, pip,源文件来安装,不过使用distribute_setup.py来安装是最简单和受欢迎的方式。Distribute是对标准库disutils模块的增强,我们知道disutils主要是用来更加容易的打包和分发包,特别是对其他的包有依赖的包。
C语言printf函数-程序员宅基地
文章浏览阅读1.7w次,点赞124次,收藏262次。C语言printf函数_c语言printf函数
oracle的faq(zz)_dbms_repcat_internal_package-程序员宅基地
文章浏览阅读1.1k次。第一部分、SQL&PL/SQL[Q]怎么样查询特殊字符,如通配符%与_[A]select * from table where name like A/_% escape /[Q]如何插入单引号到数据库表中[A]可以用ASCII码处理,其它特殊字符如&也一样,如insert into t values(i||chr(39)||m); -- chr(39)代表字符或者用两个单引_dbms_repcat_internal_package
常见的网页错误-程序员宅基地
文章浏览阅读2.1k次,点赞4次,收藏16次。一些常见的状态码为:200 - 服务器成功返回网页404 - 请求的网页不存在503 - 服务不可用详细分解:1xx(临时响应)表示临时响应并需要请求者继续执行操作的状态代码。代码 说明100 (继续) 请求者应当继续提出请求。服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。 101 (切换协议) 请求者已要求服务器切换协议,服务器已确认_常见的网页错误