机器学习Sklearn学习总结_from sklearn.metrics-程序员宅基地
技术标签: 数据分析与数据挖掘 python 机器学习 编程语言 sklearn 人工智能 回归
Sklearn学习资料推荐:
Sklean介绍
sklearn是机器学习中一个常用的python第三方模块,里面对一些常用的机器学习方法进行了封装,在进行机器学习任务时,并不需要每个人都实现所有的算法,只需要简单的调用sklearn里的模块就可以实现大多数机器学习任务。
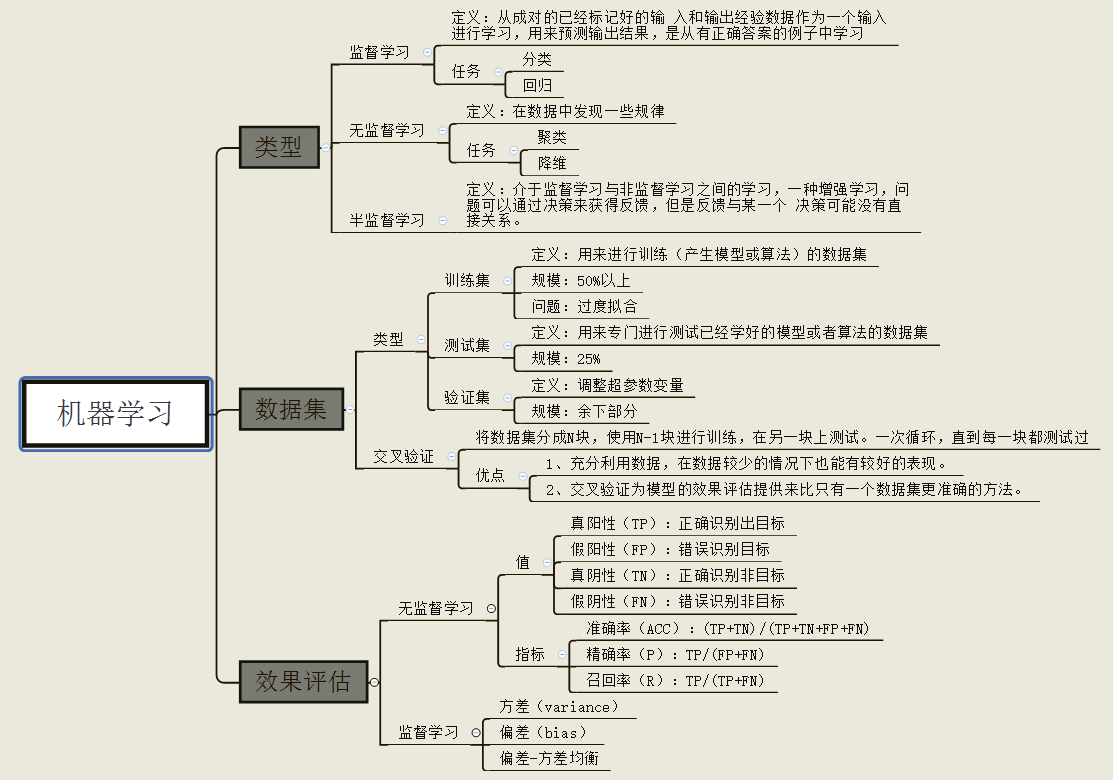
机器学习任务通常包括分类(Classification)和回归(Regression),常用的分类器包括SVM、KNN、贝叶斯、线性回归、逻辑回归、决策树、随机森林、xgboost、GBDT、boosting、神经网络NN。常见的降维方法包括TF-IDF、主题模型LDA、主成分分析PCA等等。

Sklearn速查表

scikit-learn是数据挖掘与分析的简单而有效的工具。依赖于NumPy, SciPy和matplotlib。Scikit-learn 中,所有的估计器都带有 fit() 和 predict() 方法。fit() 用来分析模型参数(拟合),predict() 是通过 fit() 算出的模型参数构成的模型,对解释变量(特征)进行预测获得的值(预测)。
它主要包含以下几部分内容:
- 从功能来分:
- classification 分类
- Regression 回归
- Clustering 聚类
- Dimensionality reduction 降维
- Model selection 模型选择
- Preprocessing 预处理
- 从API模块来分:
sklearn.base: Base classes and utility functionsklearn.cluster: Clusteringsklearn.cluster.bicluster: Biclusteringsklearn.covariance: Covariance Estimatorssklearn.model_selection: Model Selectionsklearn.datasets: Datasetssklearn.decomposition: Matrix Decompositionsklearn.dummy: Dummy estimatorssklearn.ensemble: Ensemble Methodssklearn.exceptions: Exceptions and warningssklearn.feature_extraction: Feature Extractionsklearn.feature_selection: Feature Selectionsklearn.gaussian_process: Gaussian Processessklearn.isotonic: Isotonic regressionsklearn.kernel_approximation: Kernel Approximationsklearn.kernel_ridge: Kernel Ridge Regressionsklearn.discriminant_analysis: Discriminant Analysissklearn.linear_model: Generalized Linear Modelssklearn.manifold: Manifold Learningsklearn.metrics: Metricssklearn.mixture: Gaussian Mixture Modelssklearn.multiclass: Multiclass and multilabel classificationsklearn.multioutput: Multioutput regression and classificationsklearn.naive_bayes: Naive Bayessklearn.neighbors: Nearest Neighborssklearn.neural_network: Neural network modelssklearn.calibration: Probability Calibrationsklearn.cross_decomposition: Cross decompositionsklearn.pipeline: Pipelinesklearn.preprocessing: Preprocessing and Normalizationsklearn.random_projection: Random projectionsklearn.semi_supervised: Semi-Supervised Learningsklearn.svm: Support Vector Machinessklearn.tree: Decision Treesklearn.utils: Utilities
cluster聚类
阅读sklearn.cluster的API,可以发现里面主要有两个内容:一个是各种聚类方法的class如cluster.KMeans,一个是可以直接使用的聚类方法的函数如
sklearn.cluster.k_means(X, n_clusters, init='k-means++',
precompute_distances='auto', n_init=10, max_iter=300,
verbose=False, tol=0.0001, random_state=None,
copy_x=True, n_jobs=1, algorithm='auto', return_n_iter=False)所以实际使用中,对应也有两种方法。
在sklearn.cluster共有9种聚类方法,分别是
- AffinityPropagation: 吸引子传播
- AgglomerativeClustering: 层次聚类
- Birch
- DBSCAN
- FeatureAgglomeration: 特征聚集
- KMeans: K均值聚类
- MiniBatchKMeans
- MeanShift
- SpectralClustering: 谱聚类
拿我们最熟悉的Kmeans举例说明:
采用类构造器,来构造Kmeans聚类器,首先API中KMeans的构造函数为:
sklearn.cluster.KMeans(n_clusters=8,
init='k-means++',
n_init=10,
max_iter=300,
tol=0.0001,
precompute_distances='auto',
verbose=0,
random_state=None,
copy_x=True,
n_jobs=1,
algorithm='auto'
)参数的意义:
n_clusters:簇的个数,即你想聚成几类init: 初始簇中心的获取方法n_init: 获取初始簇中心的更迭次数max_iter: 最大迭代次数(因为kmeans算法的实现需要迭代)tol: 容忍度,即kmeans运行准则收敛的条件precompute_distances:是否需要提前计算距离verbose: 冗长模式(不太懂是啥意思,反正一般不去改默认值)random_state: 随机生成簇中心的状态条件。copy_x: 对是否修改数据的一个标记,如果True,即复制了就不会修改数据。n_jobs: 并行设置algorithm: kmeans的实现算法,有:'auto','full','elkan', 其中'full'表示用EM方式实现
虽然有很多参数,但是都已经给出了默认值。所以我们一般不需要去传入这些参数,参数的。可以根据实际需要来调用。下面给一个简单的例子:
import numpy as np
from sklearn.cluster import KMeans
data = np.random.rand(100, 3) #生成一个随机数据,样本大小为100, 特征数为3
#假如我要构造一个聚类数为3的聚类器
estimator = KMeans(n_clusters=3)#构造聚类器
estimator.fit(data)#聚类
label_pred = estimator.label_ #获取聚类标签
centroids = estimator.cluster_centers_ #获取聚类中心
inertia = estimator.inertia_ # 获取聚类准则的最后值直接采用kmeans函数:
import numpy as np
from sklearn import cluster
data = np.random.rand(100, 3) #生成一个随机数据,样本大小为100, 特征数为3
k = 3 # 假如我要聚类为3个clusters
[centroid, label, inertia] = cluster.k_means(data, k)- 当然其他方法也是类似,具体使用要参考API。(学会阅读API,习惯去阅读API)
classification分类
分类是数据挖掘或者机器学习中最重要的一个部分。不过由于经典的分类方法机制比较特性化,所以好像sklearn并没有特别定制一个分类器这样的class。
常用的分类方法有:
- KNN最近邻:
sklearn.neighbors - logistic regression逻辑回归:
sklearn.linear_model.LogisticRegression - svm支持向量机:
sklearn.svm - Naive Bayes朴素贝叶斯:
sklearn.naive_bayes - Decision Tree决策树:
sklearn.tree - Neural network神经网络:
sklearn.neural_network
那么下面以KNN为例(主要是Nearest Neighbors Classification):
KNN
from sklearn import neighbors, datasets
# import some data to play with
iris = datasets.load_iris()
n_neighbors = 15
X = iris.data[:, :2] # we only take the first two features. We could
# avoid this ugly slicing by using a two-dim dataset
y = iris.target
weights = 'distance' # also set as 'uniform'
clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)
clf.fit(X, y)
# if you have test data, just predict with the following functions
# for example, xx, yy is constructed test data
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) # Z is the label_predsvm:
from sklearn import svm
X = [[0, 0], [1, 1]]
y = [0, 1]
#建立支持向量分类模型
clf = svm.SVC()
#拟合训练数据,得到训练模型参数
clf.fit(X, y)
#对测试点[2., 2.], [3., 3.]预测
res = clf.predict([[2., 2.],[3., 3.]])
#输出预测结果值
print res
#get support vectors
print "support vectors:", clf.support_vectors_
#get indices of support vectors
print "indices of support vectors:", clf.support_
#get number of support vectors for each class
print "number of support vectors for each class:", clf.n_support_ 当然SVM还有对应的回归模型SVR
from sklearn import svm
X = [[0, 0], [2, 2]]
y = [0.5, 2.5]
clf = svm.SVR()
clf.fit(X, y)
res = clf.predict([[1, 1]])
print res-
逻辑回归
from sklearn import linear_model
X = [[0, 0], [1, 1]]
y = [0, 1]
logreg = linear_model.LogisticRegression(C=1e5)
#we create an instance of Neighbours Classifier and fit the data.
logreg.fit(X, y)
res = logreg.predict([[2, 2]])
print respreprocessing
这一块通常我要用到的是Scale操作。而Scale类型也有很多,包括:
StandardScalerMaxAbsScalerMinMaxScalerRobustScalerNormalizer- 等其他预处理操作
对应的有直接的函数使用:scale(), maxabs_scale(), minmax_scale(), robust_scale(), normaizer()。
例如:
import numpy as np
from sklearn import preprocessing
X = np.random.rand(3,4)
#用scaler的方法
scaler = preprocessing.MinMaxScaler()
X_scaled = scaler.fit_transform(X)
#用scale函数的方法
X_scaled_convinent = preprocessing.minmax_scale(X)decomposition降维
说一下NMF与PCA吧,这两个比较常用。
import numpy as np
X = np.array([[1,1], [2, 1], [3, 1.2], [4, 1], [5, 0.8], [6, 1]])
from sklearn.decomposition import NMF
model = NMF(n_components=2, init='random', random_state=0)
model.fit(X)
print model.components_
print model.reconstruction_err_
print model.n_iter_这里说一下这个类下面fit()与fit_transform()的区别,前者仅训练一个模型,没有返回nmf后的分支,而后者除了训练数据,并返回nmf后的分支。
PCA也是类似,只不过没有那些初始化参数,如下:
import numpy as np
X = np.array([[1,1], [2, 1], [3, 1.2], [4, 1], [5, 0.8], [6, 1]])
from sklearn.decomposition import PCA
model = PCA(n_components=2)
model.fit(X)
print model.components_
print model.n_components_
print model.explained_variance_
print model.explained_variance_ratio_
print model.mean_
print model.noise_variance_metrics评估
上述聚类分类任务,都需要最后的评估。
分类
比如分类,有下面常用评价指标与metrics:
accuracy_scoreaucf1_scorefbeta_scorehamming_losshinge_lossjaccard_similarity_scorelog_lossrecall_score- …
下面例子求的是分类结果的准确率:
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
ac = accuracy_score(y_true, y_pred)
print ac
ac2 = accuracy_score(y_true, y_pred, normalize=False)
print ac2其他指标的使用类似。
回归
回归的相关metrics包含且不限于以下:
mean_absolute_errormean_squared_errormedian_absolute_error- …
聚类
有以下常用评价指标(internal and external):
adjusted_mutual_info_scoreadjusted_rand_scorecompleteness_scorehomogeneity_scorenormalized_mutual_info_scoresilhouette_scorev_measure_score- …
下面例子求的是聚类结果的NMI(标准互信息),其他指标也类似。
from sklearn.metrics import normalized_mutual_info_score
y_pred = [0,0,1,1,2,2]
y_true = [1,1,2,2,3,3]
nmi = normalized_mutual_info_score(y_true, y_pred)
print nmi当然除此之外还有更多其他的metrics。参考API。
datasets 数据集
sklearn本身也提供了几个常见的数据集,如iris, diabetes, digits, covtype, kddcup99, boson, breast_cancer,都可以通过sklearn.datasets.load_iris类似的方法加载相应的数据集。它返回一个数据集。采用下列方式获取数据与标签。
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target 除了这些公用的数据集外,datasets模块还提供了很多数据操作的函数,如load_files, load_svmlight_file,以及很多data generators。
panda.io还提供了很多可load外部数据(如csv, excel, json, sql等格式)的方法。
还可以获取mldata这个repos上的数据集。
python的功能还是比较强大。
当然数据集的load也可以通过自己写readfile函数来读写文件。
其余Sklearn优秀博文推荐:
Python机器学习笔记:sklearn库的学习 - 战争热诚 - 博客园
Python机器学习库——Sklearn_韩明宇-程序员宅基地_python sklearn库
智能推荐
linux devkmem 源码,linux dev/mem dev/kmem实现访问物理/虚拟内存-程序员宅基地
文章浏览阅读451次。dev/mem: 物理内存的全镜像。可以用来访问物理内存。/dev/kmem: kernel看到的虚拟内存的全镜像。可以用来访问kernel的内容。调试嵌入式Linux内核时,可能需要查看某个内核变量的值。/dev/kmem正好提供了访问内核虚拟内存的途径。现在的内核大都默认禁用了/dev/kmem,打开的方法是在 make menuconfig中选中 device drivers --> ..._dev/mem 源码实现
vxe-table 小众但功能齐全的vue表格组件-程序员宅基地
文章浏览阅读7.1k次,点赞2次,收藏19次。vxe-table,一个小众但功能齐全并支持excel操作的vue表格组件_vxe-table
(开发)bable - es6转码-程序员宅基地
文章浏览阅读62次。参考:http://www.ruanyifeng.com/blog/2016/01/babel.htmlBabelBabel是一个广泛使用的转码器,可以将ES6代码转为ES5代码,从而在现有环境执行// 转码前input.map(item => item + 1);// 转码后input.map(function (item) { return item..._让开发环境支持bable
FPGA 视频处理 FIFO 的典型应用_fpga 频分复用 视频-程序员宅基地
文章浏览阅读2.8k次,点赞6次,收藏29次。摘要:FPGA视频处理FIFO的典型应用,视频输入FIFO的作用,视频输出FIFO的作用,视频数据跨时钟域FIFO,视频缩放FIFO的作用_fpga 频分复用 视频
R语言:设置工作路径为当前文件存储路径_r语言设置工作目录到目标文件夹-程序员宅基地
文章浏览阅读575次。【代码】R语言:设置工作路径为当前文件存储路径。_r语言设置工作目录到目标文件夹
background 线性渐变-程序员宅基地
文章浏览阅读452次。格式:background: linear-gradient(direction, color-stop1, color-stop2, ...);<linear-gradient> = linear-gradient([ [ <angle> | to <side-or-corner>] ,]? &l..._background线性渐变
随便推点
【蓝桥杯省赛真题39】python输出最大的数 中小学青少年组蓝桥杯比赛 算法思维python编程省赛真题解析-程序员宅基地
文章浏览阅读1k次,点赞26次,收藏8次。第十三届蓝桥杯青少年组python编程省赛真题一、题目要求(注:input()输入函数的括号中不允许添加任何信息)1、编程实现给定一个正整数N,输出正整数N中各数位最大的那个数字。例如:N=132,则输出3。2、输入输出输入描述:只有一行,输入一个正整数N输出描述:只有一行,输出正整数N中各数位最大的那个数字输入样例:
网络协议的三要素-程序员宅基地
文章浏览阅读2.2k次。一个网络协议主要由以下三个要素组成:1.语法数据与控制信息的结构或格式,包括数据的组织方式、编码方式、信号电平的表示方式等。2.语义即需要发出何种控制信息,完成何种动作,以及做出何种应答,以实现数据交换的协调和差错处理。3.时序即事件实现顺序的详细说明,以实现速率匹配和排序。不完整理解:语法表示长什么样,语义表示能干什么,时序表示排序。转载于:https://blog.51cto.com/98..._网络协议三要素csdn
The Log: What every software engineer should know about real-time data's unifying abstraction-程序员宅基地
文章浏览阅读153次。主要的思想,将所有的系统都可以看作两部分,真正的数据log系统和各种各样的query engine所有的一致性由log系统来保证,其他各种query engine不需要考虑一致性,安全性,只需要不停的从log系统来同步数据,如果数据丢失或crash可以从log系统replay来恢复可以看出kafka系统在linkedin中的重要地位,不光是d..._the log: what every software engineer should know about real-time data's uni
《伟大是熬出来的》冯仑与年轻人闲话人生之一-程序员宅基地
文章浏览阅读746次。伟大是熬出来的 目录 前言 引言 时间熬成伟大:领导者要像狼一样坚忍 第一章 内圣外王——领导者的心态修炼 1. 天纵英才的自信心 2. 上天揽月的企图心 3. 誓不回头的决心 4. 宠辱不惊的平常心 5. 换位思考的同理心 6. 激情四射的热心 第二章 日清日高——领导者的高效能修炼 7. 积极主动,想到做到 8. 合理掌控自己的时间和生命 9. 制定目标,马..._当狼拖着受伤的右腿逃生时,右腿会成为前进的阻碍,它会毫不犹豫撕咬断自己的腿, 以
有源光缆AOC知识百科汇总-程序员宅基地
文章浏览阅读285次。在当今的大数据时代,人们对高速度和高带宽的需求越来越大,迫切希望有一种新型产品来作为高性能计算和数据中心的主要传输媒质,所以有源光缆(AOC)在这种环境下诞生了。有源光缆究竟是什么呢?应用在哪些领域,有什么优势呢?易天将为您解答!有源光缆(Active Optical Cables,简称AOC)是两端装有光收发器件的光纤线缆,主要构成部件分为光路和电路两部分。作为一种高性能计..._aoc 光缆
浏览器代理服务器自动配置脚本设置方法-程序员宅基地
文章浏览阅读2.2k次。在“桌面”上按快捷键“Ctrl+R”,调出“运行”窗口。接着,在“打开”后的输入框中输入“Gpedit.msc”。并按“确定”按钮。如下图 找到“用户配置”下的“Windows设置”下的“Internet Explorer 维护”的“连接”,双击选择“自动浏览器配置”。如下图 选择“自动启动配置”,并在下面的“自动代理URL”中填写相应的PAC文件地址。如下..._設置proxy腳本