并发爬虫-python-HyperSpy_hyperspy库安装-程序员宅基地
并发爬虫-python-HyperSpy
HyperSpy结构
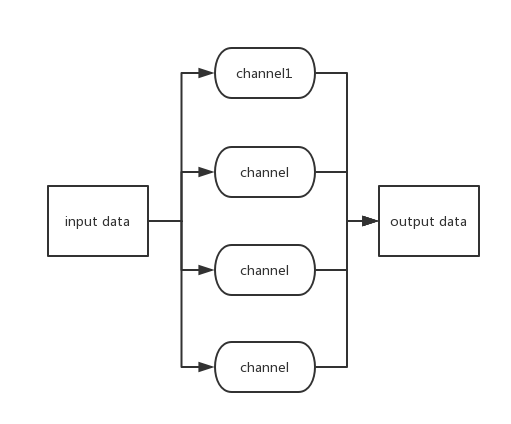
- 参考
HyperSpy().addChanel(urlGen, urlFilter, contentSpy, storeRoutine).start(),其中使用addChanel方法添加了四个channel(被@channel修饰的函数). - HyperSpy的关键思想是数据流入一个通道,再从通道中流出新的数据,作为下一个通道的输入数据: 在调用start方法后,HyperSpy首先为urlGen创建5个线程,随后循环执行urlGen方法主体,直到urlGen返回的二元组的第一个元素为True(表示urlGen已经运行完了),随后HyperSpy会将urlGen输出的数据作为第二个通道urlFilter的输入数据,开始进入通道二.
- 编写通道方法时记得使用@channel装饰器,并且在每个通道方法内一定要返回一个二元组
(finished, result),并且其中result必须是一个列表. - 你可能注意到通道方法都有四个参数:
session, ctx, lock, data. session是requests.Session的一个实例, ctx是单个通道所有线程共享的数据,对齐修改你可能需要使用lock进行同步,data是上个通道输出的数据,如果没有前一个通道那么data就是一个空列表.
实例代码
# 这个实例目标是爬取一个网站的新闻,需要先从列表页面获取文章的url.对于获取到的文章url,会先查询数据库url是
# 否存在,如果存在则直接过滤掉,如果不存在则可以根据url爬取文章标题和正文,然后按(url, title, content)的格式存入
# 数据.所以实例设计了四个通道,urlGen负责爬取文章url,urlFilter负责过滤掉爬过的url,contentSpy负责爬取文章title
# 和content,storeRoutine负责数据库接入.注意数据库连接是不能线程共享的...所以urlFilter和storeRoutine都只用了
# 一个线程来跑
import pymysql
from hyperspy import HyperSpy, channel
from bs4 import BeautifulSoup, element
host = 'http://news.nwpu.edu.cn'
basePattern = host + '/gdyw'
db = pymysql.connect("localhost","root","root","test")
cursor = db.cursor()
# channel装饰器参数含义:
# nt: 线程数
# sp: 指示每次从数据输入中拿多少数据,如果sp<=0,表示一次取完,每次拿取的数据作为data实参传入
# initParams: 初始化参数,会被存放到ctx(channel context)中
@channel(nt=5, initParams={'limit': 10, 'counter': -1, 'perProcessNum': 10})
def urlGen(session, ctx, lock, data):
target = []
result = []
lock.acquire()
num = ctx.limit - ctx.counter
if num == 0:
lock.release()
return (True, None)
elif num > ctx.perProcessNum:
num = ctx.perProcessNum
for _ in range(num + 1):
ctx.counter += 1
if ctx.counter == 0: target.append(basePattern + '.htm')
elif ctx.counter < ctx.limit: target.append(basePattern + '/' + str(ctx.counter) + '.htm')
else: break
lock.release()
for u in target:
r = session.get(u)
soup = BeautifulSoup(r.content, 'html.parser')
for li in soup.select('body .list-main .wrapper .fl ul li'):
if not 'style' in li:
href = li.select('.fr a')[0]['href'].replace('../', '')
result.append(host + '/' + href)
return (False, result)
@channel(nt=1, sp=0)
def urlFilter(session, ctx, lock, data):
result = []
sql = "select id from XiGongDa where url=%s"
for url in data:
cursor.execute(sql, (url))
if len(cursor.fetchall()) == 0:
result.append(url)
return (True, result)
@channel(nt=5)
def contentSpy(session, ctx, lock, data):
def findText(p):
content = ''
if isinstance(p, element.Tag):
for child in p.contents:
content += findText(child)
elif isinstance(p, element.NavigableString):
return p
return content
if data:
result = []
for url in data:
r = session.get(url)
if r.status_code == 200:
try:
soup = BeautifulSoup(r.content, 'html.parser')
div = soup.select('body .list-main .wrapper .fl .artical form div')[0]
title = div.select('h5')[0].contents[0]
content = ''
for p in div.select('.nr .v_news_content')[0].contents:
content += findText(p)
result.append((url, title, content))
except Exception as e:
print(e)
return (False, result)
else: return (True, None)
@channel(nt=1)
def storeRoutine(session, ctx, lock, data):
if data:
for url, title, content in data:
sql = "insert into XiGongDa(url, title, content) values (%s, %s, %s)"
try:
cursor.execute(sql, (url, title, content))
db.commit()
except Exception as e:
print (e)
db.rollback()
return (False, None)
else: return (True, None)
# 添加四个函数作为channel,HyperSpy将根据添加顺序,依次执行四个函数
HyperSpy().addChanel(urlGen, urlFilter, contentSpy, storeRoutine).start()
db.close()
实例运行结果

HyperSpy完整实现
import threading
import time
import datetime
from requests import session
def timestamp():
return datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
def getFuncName(func):
s = str(func)
i = s.find('function ')
s = s[i + 9:]
i = s.find(' ')
return s[:i]
class DynamicObject(object):
pass
class Channel(object):
def __init__(self, name, handler, nt = 1):
self.name = name
self.handler = handler
self.nt = nt
self.next = None
self.counter = 0
self._din = []
self._dinSize = 0
self._dout = []
self.ilock = threading.Lock()
self.olock = threading.Lock()
def setDin(self, data):
self.counter = 0
self._din = data
self._dinSize = len(data)
def getDin(self, n):
self.ilock.acquire()
data = None
if self.counter < self._dinSize:
if n <= 0:
data = self._din[:]
self._din.clear()
self.counter += self._dinSize
else:
tmp = self._dinSize - self.counter
if n > tmp: n = tmp
data = self._din[self.counter:self.counter + n]
self.counter += n
self.ilock.release()
return data
def putDout(self, data):
if data and isinstance(data, list):
self.olock.acquire()
self._dout.extend(data)
print ("channel data size: %d" % len(self._dout), end='\r')
self.olock.release()
def getDout(self):
data = self._dout[:]
self._dout.clear()
return data
class Pipeline(object):
def __init__(self):
self.head = Channel(None, None)
self.tail = self.head
self.size = 0
def addLast(self, c):
self.tail.next = c
self.tail = c
self.size += 1
def channels(self):
channel = self.head.next
i = 0
while i < self.size:
yield channel
i += 1
channel = channel.next
class HyperSpy(object):
def __init__(self):
self.pipeline = Pipeline()
self.session = session()
self.session.headers.update({
'Accept': 'text/html, application/xhtml+xml, image/jxr, */*',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-Hans-CN, zh-Hans; q=0.5',
'Connection':'Keep-Alive',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'
})
def __wrapChannel(self, name, handler, nt, sp, initParams):
hlock = threading.Lock()
ctx = DynamicObject()
for k, v in initParams.items(): ctx.__setattr__(k, v)
channel = Channel(name, None, nt)
def inner():
finished = False
while not finished:
finished, dout = handler(self.session, ctx, hlock, channel.getDin(sp))
channel.putDout(dout)
channel.handler = inner
return channel
def addChanel(self, *params):
for p in params:
name, handler, nt, sp, initParams = p
self.pipeline.addLast(self.__wrapChannel(name, handler, nt, sp, initParams))
return self
def start(self):
tstart = time.time()
ltstart, ltend = tstart, None
print('[%s] hyperspy started' % timestamp())
data = []
for c in self.pipeline.channels():
c.setDin(data)
t = []
for i in range(c.nt):
t.append(threading.Thread(target=c.handler, args=()))
t[i].start()
for i in range(c.nt):
t[i].join()
data = c.getDout()
ltend = time.time()
print ("[%s] channel <%s> finished, data size: %d, time used: %fs" % (timestamp(), c.name, len(data), ltend - ltstart))
ltstart = ltend
print('[%s] hyperspy finished, time used: %fs' % (timestamp(), time.time() - tstart))
return data
def channel(nt, sp=10, initParams={}):
'''nt: total thread num, sp: data quantity processed by single thread at one time'''
def wrap(handler):
return (getFuncName(handler), handler, nt, sp, initParams)
return lambda handler: wrap(handler)
智能推荐
攻防世界_难度8_happy_puzzle_攻防世界困难模式攻略图文-程序员宅基地
文章浏览阅读645次。这个肯定是末尾的IDAT了,因为IDAT必须要满了才会开始一下个IDAT,这个明显就是末尾的IDAT了。,对应下面的create_head()代码。,对应下面的create_tail()代码。不要考虑爆破,我已经试了一下,太多情况了。题目来源:UNCTF。_攻防世界困难模式攻略图文
达梦数据库的导出(备份)、导入_达梦数据库导入导出-程序员宅基地
文章浏览阅读2.9k次,点赞3次,收藏10次。偶尔会用到,记录、分享。1. 数据库导出1.1 切换到dmdba用户su - dmdba1.2 进入达梦数据库安装路径的bin目录,执行导库操作 导出语句:./dexp cwy_init/[email protected]:5236 file=cwy_init.dmp log=cwy_init_exp.log 注释: cwy_init/init_123..._达梦数据库导入导出
js引入kindeditor富文本编辑器的使用_kindeditor.js-程序员宅基地
文章浏览阅读1.9k次。1. 在官网上下载KindEditor文件,可以删掉不需要要到的jsp,asp,asp.net和php文件夹。接着把文件夹放到项目文件目录下。2. 修改html文件,在页面引入js文件:<script type="text/javascript" src="./kindeditor/kindeditor-all.js"></script><script type="text/javascript" src="./kindeditor/lang/zh-CN.js"_kindeditor.js
STM32学习过程记录11——基于STM32G431CBU6硬件SPI+DMA的高效WS2812B控制方法-程序员宅基地
文章浏览阅读2.3k次,点赞6次,收藏14次。SPI的详情简介不必赘述。假设我们通过SPI发送0xAA,我们的数据线就会变为10101010,通过修改不同的内容,即可修改SPI中0和1的持续时间。比如0xF0即为前半周期为高电平,后半周期为低电平的状态。在SPI的通信模式中,CPHA配置会影响该实验,下图展示了不同采样位置的SPI时序图[1]。CPOL = 0,CPHA = 1:CLK空闲状态 = 低电平,数据在下降沿采样,并在上升沿移出CPOL = 0,CPHA = 0:CLK空闲状态 = 低电平,数据在上升沿采样,并在下降沿移出。_stm32g431cbu6
计算机网络-数据链路层_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏8次。数据链路层习题自测问题1.数据链路(即逻辑链路)与链路(即物理链路)有何区别?“电路接通了”与”数据链路接通了”的区别何在?2.数据链路层中的链路控制包括哪些功能?试讨论数据链路层做成可靠的链路层有哪些优点和缺点。3.网络适配器的作用是什么?网络适配器工作在哪一层?4.数据链路层的三个基本问题(帧定界、透明传输和差错检测)为什么都必须加以解决?5.如果在数据链路层不进行帧定界,会发生什么问题?6.PPP协议的主要特点是什么?为什么PPP不使用帧的编号?PPP适用于什么情况?为什么PPP协议不_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输
软件测试工程师移民加拿大_无证移民,未受过软件工程师的教育(第1部分)-程序员宅基地
文章浏览阅读587次。软件测试工程师移民加拿大 无证移民,未受过软件工程师的教育(第1部分) (Undocumented Immigrant With No Education to Software Engineer(Part 1))Before I start, I want you to please bear with me on the way I write, I have very little gen...
随便推点
Thinkpad X250 secure boot failed 启动失败问题解决_安装完系统提示secureboot failure-程序员宅基地
文章浏览阅读304次。Thinkpad X250笔记本电脑,装的是FreeBSD,进入BIOS修改虚拟化配置(其后可能是误设置了安全开机),保存退出后系统无法启动,显示:secure boot failed ,把自己惊出一身冷汗,因为这台笔记本刚好还没开始做备份.....根据错误提示,到bios里面去找相关配置,在Security里面找到了Secure Boot选项,发现果然被设置为Enabled,将其修改为Disabled ,再开机,终于正常启动了。_安装完系统提示secureboot failure
C++如何做字符串分割(5种方法)_c++ 字符串分割-程序员宅基地
文章浏览阅读10w+次,点赞93次,收藏352次。1、用strtok函数进行字符串分割原型: char *strtok(char *str, const char *delim);功能:分解字符串为一组字符串。参数说明:str为要分解的字符串,delim为分隔符字符串。返回值:从str开头开始的一个个被分割的串。当没有被分割的串时则返回NULL。其它:strtok函数线程不安全,可以使用strtok_r替代。示例://借助strtok实现split#include <string.h>#include <stdio.h&_c++ 字符串分割
2013第四届蓝桥杯 C/C++本科A组 真题答案解析_2013年第四届c a组蓝桥杯省赛真题解答-程序员宅基地
文章浏览阅读2.3k次。1 .高斯日记 大数学家高斯有个好习惯:无论如何都要记日记。他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210后来人们知道,那个整数就是日期,它表示那一天是高斯出生后的第几天。这或许也是个好习惯,它时时刻刻提醒着主人:日子又过去一天,还有多少时光可以用于浪费呢?高斯出生于:1777年4月30日。在高斯发现的一个重要定理的日记_2013年第四届c a组蓝桥杯省赛真题解答
基于供需算法优化的核极限学习机(KELM)分类算法-程序员宅基地
文章浏览阅读851次,点赞17次,收藏22次。摘要:本文利用供需算法对核极限学习机(KELM)进行优化,并用于分类。
metasploitable2渗透测试_metasploitable2怎么进入-程序员宅基地
文章浏览阅读1.1k次。一、系统弱密码登录1、在kali上执行命令行telnet 192.168.26.1292、Login和password都输入msfadmin3、登录成功,进入系统4、测试如下:二、MySQL弱密码登录:1、在kali上执行mysql –h 192.168.26.129 –u root2、登录成功,进入MySQL系统3、测试效果:三、PostgreSQL弱密码登录1、在Kali上执行psql -h 192.168.26.129 –U post..._metasploitable2怎么进入
Python学习之路:从入门到精通的指南_python人工智能开发从入门到精通pdf-程序员宅基地
文章浏览阅读257次。本文将为初学者提供Python学习的详细指南,从Python的历史、基础语法和数据类型到面向对象编程、模块和库的使用。通过本文,您将能够掌握Python编程的核心概念,为今后的编程学习和实践打下坚实基础。_python人工智能开发从入门到精通pdf