5. 数据预处理_5.数据预处理-程序员宅基地
技术标签: # python - 数据分析
5. 数据清洗与准备
文章目录
在数据分析和建模的过程中,相当多的时间要用在数据准备上:加载、清理、转换以及重塑。pandas和内置的Python标准库提供了一组高级的、灵活的、快速的工具,可以让你轻松地将数据规整为想要的格式。
1. 处理缺失数据
-
在许多数据分析工作中,缺失数据是经常发生的。pandas的目标之一就是尽量轻松地处理缺失数据。例如,pandas对象的所有描述性统计默认都不包括缺失数据。
-
缺失数据在pandas中呈现的方式有些不完美,但对于大多数用户可以保证功能正常。对于数值数据,pandas使用浮点值NaN(Not a Number)表示缺失数据。我们称其为哨兵值,可以方便的检测出来:
import pandas as pd
import numpy as np
string_data = pd.Series(['aardvark', 'artichoke', np.nan, 'avocado'])
string_data
--------------------------------------------------------------------
0 aardvark
1 artichoke
2 NaN
3 avocado
dtype: object
string_data.isnull()
-----------------------------------------------------------------
0 False
1 False
2 True
3 False
dtype: bool
string_data.describe()
------------------------------------------------------------------------------
count 3
unique 3
top artichoke
freq 1
dtype: object
-
在pandas中将缺失值表示为NA,它表示不可用not available。在统计应用中,NA数据可能是不存在的数据或者虽然存在,但是没有观察到(例如,数据采集中发生了问题)。当进行数据清洗以进行分析时,最好直接对缺失数据进行分析,以判断数据采集的问题或缺失数据可能导致的偏差。
-
Python内置的None值在对象数组中也可以作为NA:
string_data
-----------------------------------------------
0 aardvark
1 artichoke
2 NaN
3 avocado
dtype: object
string_data[0] = None
string_data.isnull()
----------------------------------------------------------------------------
0 True
1 False
2 True
3 False
dtype: bool
下表列出了一些关于缺失数据处理的函数:

滤除缺失数据
过滤掉缺失数据的办法有很多种。你可以通过pandas.isnull或布尔索引的手工方法,但dropna可能会更实用一些。对于一个Series,dropna返回一个仅含非空数据和索引值的Series:
from numpy import nan as NA
data = pd.Series([1, NA, 3.5, NA, 7])
data
---------------------------------------------------------------------------
0 1.0
1 NaN
2 3.5
3 NaN
4 7.0
dtype: float64
data.dropna()
-----------------------------------------------------------------------
0 1.0
2 3.5
4 7.0
dtype: float64
这等价于:
data[data.notnull()]
-----------------------------------------------------------------------
0 1.0
2 3.5
4 7.0
dtype: float64
- 而对于DataFrame对象,事情就有点复杂了。你可能希望丢弃全NA或含有NA的行或列。dropna默认丢弃任何含有缺失值的行:
- data = pd.DataFrame([[1., 6.5, 3.], [1., NA, NA],
[NA, NA, NA], [NA, 6.5, 3.]])
data
-----------------------------------------------------------------------------------
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
******************************************************************
cleaned = data.dropna()
cleaned
------------------------------------------
0 1 2
0 1.0 6.5 3.0
- 传入how='all’将只丢弃全为NA的那些行:
data.dropna(how='all')
--------------------------------------
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
3 NaN 6.5 3.0
- 用这种方式丢弃列,只需传入axis=1即可:
data[4] = NA
data
data.dropna(axis=1, how='all')
-------------------------------------------------
0 1 2 4
0 1.0 6.5 3.0 NaN
1 1.0 NaN NaN NaN
2 NaN NaN NaN NaN
3 NaN 6.5 3.0 NaN
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
- 另一个滤除DataFrame行的问题涉及时间序列数据。假设你只想留下一部分观测数据,可以用thresh参数实现此目的:
df = pd.DataFrame(np.random.randn(7,3))
df.iloc[:4,1] = NA
df.iloc[:2,2] = NA
df
df.dropna()
df.dropna(thresh=2)
--------------------------------------------------------------------
0 1 2
0 0.603531 NaN NaN
1 -0.664478 NaN NaN
2 1.574308 NaN -2.026062
3 -0.796888 NaN -0.550593
4 -0.146118 0.090815 1.564721
5 0.766400 0.971270 -0.779148
6 -1.802502 -1.139013 -1.289828
0 1 2
4 -0.146118 0.090815 1.564721
5 0.766400 0.971270 -0.779148
6 -1.802502 -1.139013 -1.289828
0 1 2
2 1.574308 NaN -2.026062
3 -0.796888 NaN -0.550593
4 -0.146118 0.090815 1.564721
5 0.766400 0.971270 -0.779148
6 -1.802502 -1.139013 -1.289828
填充缺失数据
- 你可能不想滤除缺失数据(有可能会丢弃跟它有关的其他数据),而是希望通过其他方式填补那些“空洞”。对于大多数情况而言,fillna方法是最主要的函数。通过一个常数调用fillna就会将缺失值替换为那个常数值:
df.fillna(0)
-----------------------------------------------------------
0 1 2
0 0.603531 0.000000 0.000000
1 -0.664478 0.000000 0.000000
2 1.574308 0.000000 -2.026062
3 -0.796888 0.000000 -0.550593
4 -0.146118 0.090815 1.564721
5 0.766400 0.971270 -0.779148
6 -1.802502 -1.139013 -1.289828
- 若是通过一个字典调用
fillna,就可以实现对不同的列填充不同的值:
df.fillna({
1:0.5, 2:0})
- fillna默认会返回新对象,但也可以利用
inplace对现有对象进行就地修改:
df.fillna(0, inplace=True)
df
----------------------------------------------------------------------
0 1 2
0 0.603531 0.000000 0.000000
1 -0.664478 0.000000 0.000000
2 1.574308 0.000000 -2.026062
3 -0.796888 0.000000 -0.550593
4 -0.146118 0.090815 1.564721
5 0.766400 0.971270 -0.779148
6 -1.802502 -1.139013 -1.289828
- 对
reindexing有效的那些插值方法也可用于fillna:
df = pd.DataFrame(np.random.randn(6,3))
df.iloc[2:, 1] = NA
df.iloc[4:, 2] = NA
df
df.fillna(method='ffill')
df.fillna(method='ffill', limit=2)
----------------------------------------------------------------------------
0 1 2
0 0.786754 -1.180053 2.165359
1 -0.802301 0.124125 -0.737388
2 0.285469 NaN 0.210286
3 0.647529 NaN 1.124584
4 -0.706682 NaN NaN
5 1.418289 NaN NaN
0 1 2
0 0.786754 -1.180053 2.165359
1 -0.802301 0.124125 -0.737388
2 0.285469 0.124125 0.210286
3 0.647529 0.124125 1.124584
4 -0.706682 0.124125 1.124584
5 1.418289 0.124125 1.124584
0 1 2
0 0.786754 -1.180053 2.165359
1 -0.802301 0.124125 -0.737388
2 0.285469 0.124125 0.210286
3 0.647529 0.124125 1.124584
4 -0.706682 NaN 1.124584
5 1.418289 NaN 1.124584
- 只要有些创新,你就可以利用fillna实现许多别的功能。比如说,你可以传入Series的平均值或中位数:
data = pd.Series([1., NA, 3.5, NA, 7])
data
data.fillna(data.mean())
-------------------------------------------------------------------
0 1.0
1 NaN
2 3.5
3 NaN
4 7.0
dtype: float64
0 1.000000
1 3.833333
2 3.500000
3 3.833333
4 7.000000
dtype: float64
- 下表列出了fillna的参考:


2. 数据转换
移除重复数据
DataFrame中出现重复行有多种原因。下面就是一个例子:
data = pd.DataFrame({
'k1': ['one', 'two'] * 3 + ['two'],
'k2': [1, 1, 2, 3, 3, 4, 4]})
data
data.duplicated()
data.drop_duplicates()
----------------------------------------------------------------
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
6 two 4
0 False
1 False
2 False
3 False
4 False
5 False
6 True
dtype: bool
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
这两个方法默认会判断全部列,你也可以指定部分列进行重复项判断。假设我们还有一列值,且只希望根据k1列过滤重复项:
data['v1'] = range(7)
data
data.drop_duplicates(['k1'])
----------------------------------------------------------------------
k1 k2 v1
0 one 1 0
1 two 1 1
2 one 2 2
3 two 3 3
4 one 3 4
5 two 4 5
6 two 4 6
k1 k2 v1
0 one 1 0
1 two 1 1
duplicated和drop_duplicates默认保留的是第一个出现的值组合。传入keep='last'则保留最后一个:
data.drop_duplicates(['k1', 'k2'], keep='last')
----------------------------------------------------------------------
k1 k2 v1
0 one 1 0
1 two 1 1
2 one 2 2
3 two 3 3
4 one 3 4
6 two 4 6
利用函数或映射进行数据转换
- 对于许多数据集,你可能希望根据数组、Series或DataFrame列中的值来实现转换工作。我们来看看下面这组有关肉类的数据:
data = pd.DataFrame({
'food': ['bacon', 'pulled pork', 'bacon',
'Pastrami', 'corned beef', 'Bacon',
'pastrami', 'honey ham', 'nova lox'],
'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})
data
----------------------------------------------------------------------
food ounces
0 bacon 4.0
1 pulled pork 3.0
2 bacon 12.0
3 Pastrami 6.0
4 corned beef 7.5
5 Bacon 8.0
6 pastrami 3.0
7 honey ham 5.0
8 nova lox 6.0
- 假设你想要添加一列表示该肉类食物来源的动物类型。我们先编写一个不同肉类到动物的映射:
meat_to_animal = {
'bacon': 'pig',
'pulled pork': 'pig',
'pastrami': 'cow',
'corned beef': 'cow',
'honey ham': 'pig',
'nova lox': 'salmon'
}
- Series的
map方法可以接受一个函数或含有映射关系的字典型对象,但是这里有一个小问题,即有些肉类的首字母大写了,而另一些则没有。因此,我们还需要使用Series的str.lower方法,将各个值转换为小写:
lowercased = data['food'].str.lower()
lowercased
data['animal'] = lowercased.map(meat_to_animal)
data
-----------------------------------------------------------------------------
0 bacon
1 pulled pork
2 bacon
3 pastrami
4 corned beef
5 bacon
6 pastrami
7 honey ham
8 nova lox
Name: food, dtype: object
food ounces animal
0 bacon 4.0 pig
1 pulled pork 3.0 pig
2 bacon 12.0 pig
3 Pastrami 6.0 cow
4 corned beef 7.5 cow
5 Bacon 8.0 pig
6 pastrami 3.0 cow
7 honey ham 5.0 pig
8 nova lox 6.0 salmon
- 我们也可以传入一个能够完成全部这些工作的函数:
data['food'].map(lambda x: meat_to_animal[x.lower()])
-----------------------------------------------------------
0 pig
1 pig
2 pig
3 cow
4 cow
5 pig
6 cow
7 pig
8 salmon
Name: food, dtype: object
- 使用
map是一种实现元素级转换以及其他数据清理工作的便捷方式。
替换值:replace
- 利用
fillna方法填充缺失数据可以看做值替换的一种特殊情况。前面已经看到,map可用于修改对象的数据子集,而replace则提供了一种实现该功能的更简单、更灵活的方式。我们来看看下面这个Series:
data = pd.Series([1., -999., 2., -999., -1000., 3.])
data
----------------------------------------------------------------
0 1.0
1 -999.0
2 2.0
3 -999.0
4 -1000.0
5 3.0
dtype: float64
- -999这个值可能是一个表示缺失数据的标记值。要将其替换为pandas能够理解的NA值,我们可以利用replace来产生一个新的Series(除非传入
inplace=True):
data.replace(-999, np.nan)
-----------------------------------------------------------------
0 1.0
1 NaN
2 2.0
3 NaN
4 -1000.0
5 3.0
dtype: float64
- 如果你希望一次性替换多个值,可以传入一个由待替换值组成的列表以及一个替换值:
data.replace([-999, -1000], np.nan)
-----------------------------------------------------------------
0 1.0
1 NaN
2 2.0
3 NaN
4 NaN
5 3.0
dtype: float64
要让每个值有不同的替换值,可以传递一个替换列表:
data.replace([-999, -1000], [np.nan, 0])
-----------------------------------------------------------------
0 1.0
1 NaN
2 2.0
3 NaN
4 0.0
5 3.0
dtype: float64
传入的参数也可以是字典:
data.replace({
-999: np.nan, -1000: 0})
-----------------------------------------------------------------------
0 1.0
1 NaN
2 2.0
3 NaN
4 0.0
5 3.0
dtype: float64
重命名轴索引
- 跟Series中的值一样,轴标签也可以通过函数或映射进行转换,从而得到一个新的不同标签的对象。轴还可以被就地修改,而无需新建一个数据结构。接下来看看下面这个简单的例子:
data = pd.DataFrame(np.arange(12).reshape((3, 4)),
index=['Ohio', 'Colorado', 'New York'],
columns=['one', 'two', 'three', 'four'])
data
-----------------------------------------------------------------------
one two three four
Ohio 0 1 2 3
Colorado 4 5 6 7
New York 8 9 10 11
- 跟Series一样,轴索引也有一个map方法:
transform = lambda x: x[:4].upper()
data.index.map(transform)
-------------------------------------------------------------------------
Index(['OHIO', 'COLO', 'NEW '], dtype='object')
data.index = data.index.map(transform)
data
-------------------------------------------------------------------------
one two three four
OHIO 0 1 2 3
COLO 4 5 6 7
NEW 8 9 10 11
如果想要创建数据集的转换版(而不是修改原始数据),比较实用的方法是rename:
data.rename(index=str.title, columns=str.upper)
str.title('this is a test')
-------------------------------------------------------------------------
ONE TWO THREE FOUR
Ohio 0 1 2 3
Colo 4 5 6 7
New 8 9 10 11
'This Is A Test'
- 特别说明一下,
rename可以结合字典型对象实现对部分轴标签的更新:
data.rename(index={
'OHIO': 'INDIANA'},
columns={
'three': 'peekaboo'})
-------------------------------------------------------------------------
one two peekaboo four
INDIANA 0 1 2 3
COLO 4 5 6 7
NEW 8 9 10 11
rename可以实现复制DataFrame并对其索引和列标签进行赋值。如果希望就地修改某个数据集,传入inplace=True即可
data.rename(index={
'OHIO': 'INDIANA'}, inplace=True)
data
-------------------------------------------------------------------------
one two three four
INDIANA 0 1 2 3
COLO 4 5 6 7
NEW 8 9 10 11
离散化和面元划分
为了便于分析,连续数据常常被离散化或拆分为“面元”(bin)。假设有一组人员数据,而你希望将它们划分为不同的年龄组:
ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
- 接下来将这些数据划分为“18到25”、“26到35”、“35到60”以及“60以上”几个面元。要实现该功能,你需要使用pandas的
cut函数:
bins = [18, 25, 35, 60, 100]
cats = pd.cut(ages, bins)
cats
-------------------------------------------------------------------------
[(18, 25], (18, 25], (18, 25], (25, 35], (18, 25], ..., (25, 35], (60, 100], (35, 60], (35, 60], (25, 35]]
Length: 12
Categories (4, interval[int64]): [(18, 25] < (25, 35] < (35, 60] < (60, 100]]
pandas返回的是一个特殊的Categorical对象。结果展示了pandas.cut划分的面元。你可以将其看做一组表示面元名称的字符串。它的底层含有一个表示不同分类名称的类型数组,以及一个codes属性中的年龄数据的标签:
cats.codes
-------------------------------------------------------------------------
array([0, 0, 0, 1, 0, 0, 2, 1, 3, 2, 2, 1], dtype=int8)
cats.categories
-------------------------------------------------------------------------
IntervalIndex([(18, 25], (25, 35], (35, 60], (60, 100]]
closed='right',
dtype='interval[int64]')
# pd.value_counts(cats)是pandas.cut结果的面元计数。
pd.value_counts(cats)
-------------------------------------------------------------------------
(18, 25] 5
(35, 60] 3
(25, 35] 3
(60, 100] 1
dtype: int64
- 跟“区间”的数学符号一样,圆括号表示开端,而方括号则表示闭端(包括)。哪边是闭端可以通过
right=False进行修改:
pd.cut(ages, [18, 26, 36, 61, 100], right=False)
-------------------------------------------------------------------------
[[18, 26), [18, 26), [18, 26), [26, 36), [18, 26), ..., [26, 36), [61, 100), [36, 61), [36, 61), [26, 36)]
Length: 12
Categories (4, interval[int64]): [[18, 26) < [26, 36) < [36, 61) < [61, 100)]
- 可以通过传递一个列表或数组到labels,设置自己的面元名称:
group_names = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior']
pd.cut(ages, bins, labels=group_names)
-------------------------------------------------------------------------
[Youth, Youth, Youth, YoungAdult, Youth, ..., YoungAdult, Senior, MiddleAged, MiddleAged, YoungAdult]
Length: 12
Categories (4, object): [Youth < YoungAdult < MiddleAged < Senior]
- 如果向cut传入的是面元的数量而不是确切的面元边界,则它会根据数据的最小值和最大值计算等长面元。下面这个例子中,我们将一些均匀分布的数据分成四组:
data = np.random.rand(20)
pd.cut(data, 4, precision=2)
-------------------------------------------------------------------------
[(0.67, 0.9], (0.67, 0.9], (0.011, 0.23], (0.23, 0.45], (0.23, 0.45], ..., (0.45, 0.67], (0.011, 0.23], (0.23, 0.45], (0.011, 0.23], (0.67, 0.9]]
Length: 20
Categories (4, interval[float64]): [(0.011, 0.23] < (0.23, 0.45] < (0.45, 0.67] < (0.67, 0.9]]
qcut是一个非常类似于cut的函数,它可以根据样本分位数对数据进行面元划分。根据数据的分布情况,cut可能无法使各个面元中含有相同数量的数据点。而qcut由于使用的是样本分位数,因此可以得到大小基本相等的面元:
data = np.random.randn(1000) # Normally distributed
cats = pd.qcut(data, 4) # Cut into quartiles
cats
-------------------------------------------------------------------------
[(-3.627, -0.665], (-0.665, -0.0236], (-3.627, -0.665], (-3.627, -0.665], (0.595, 3.352], ..., (-3.627, -0.665], (0.595, 3.352], (-0.0236, 0.595], (-0.0236, 0.595], (-0.0236, 0.595]]
Length: 1000
Categories (4, interval[float64]): [(-3.627, -0.665] < (-0.665, -0.0236] < (-0.0236, 0.595] < (0.595, 3.352]]
pd.value_counts(cats)
-------------------------------------------------------------------------
(0.595, 3.352] 250
(-0.0236, 0.595] 250
(-0.665, -0.0236] 250
(-3.627, -0.665] 250
dtype: int64
- 与
cut类似,你也可以传递自定义的分位数(0到1之间的数值,包含端点):
pd.qcut(data, [0, 0.1, 0.5, 0.9, 1.])
----------------------------------------------------------------------------------
[(-1.319, -0.0236], (-1.319, -0.0236], (-3.627, -1.319], (-1.319, -0.0236], (1.218, 3.352], ..., (-3.627, -1.319], (1.218, 3.352], (-0.0236, 1.218], (-0.0236, 1.218], (-0.0236, 1.218]]
Length: 1000
Categories (4, interval[float64]): [(-3.627, -1.319] < (-1.319, -0.0236] < (-0.0236, 1.218] < (1.218, 3.352]]
检测和过滤异常值
- 过滤或变换异常值(outlier)在很大程度上就是运用数组运算。来看一个含有正态分布数据的DataFrame:
data = pd.DataFrame(np.random.randn(1000,4))
data.describe()
----------------------------------------------------------------------------------
0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean 0.000284 0.003834 0.052079 0.021614
std 1.010268 1.006346 1.007687 1.029508
min -3.261766 -3.762325 -3.544134 -3.124230
25% -0.741905 -0.643554 -0.613592 -0.651136
50% -0.019509 -0.039399 0.036878 0.094302
75% 0.695546 0.676507 0.737588 0.712619
max 3.026675 3.482009 3.390924 3.116602
# 假设你想要找出某列中绝对值大小超过3的值:
col = data[2]
col[np.abs(col) > 3]
----------------------------------------------------------------------------------
156 3.174432
406 3.312773
708 -3.544134
788 3.390924
Name: 2, dtype: float64
- 要选出全部含有“超过3或-3的值”的行,你可以在布尔型DataFrame中使用any方法:
data[(np.abs(data) > 3).any(1)]
----------------------------------------------------------------------------------
0 1 2 3
32 -0.464433 -3.762325 0.593019 -3.124230
156 0.771649 0.483199 3.174432 0.117988
257 1.056537 1.435697 -1.161737 3.095851
307 -3.056003 -1.987528 -0.628526 0.297810
406 0.912561 -0.073800 3.312773 -0.802398
526 3.026675 -0.463901 -0.486543 -1.458392
628 -1.211783 -1.272122 -1.051027 3.116602
708 -0.276584 -0.283202 -3.544134 -0.418665
713 -3.261766 -1.122042 0.869456 -0.035866
779 0.082870 3.482009 0.439070 -0.291009
788 -0.111096 -0.608896 3.390924 -0.688649
837 0.884890 -3.544678 -0.799940 -1.402440
883 -0.140538 -3.086551 -2.524166 -2.525502
901 -0.949264 3.354125 1.301728 0.192881
- 根据这些条件,就可以对值进行设置。下面的代码可以将值限制在区间-3到3以内:
# sign()是Python的Numpy中的取数字符号(数字前的正负号)的函数
data[np.abs(data) > 3] = np.sign(data) * 3
data.describe()
----------------------------------------------------------------------------------
0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean 0.000575 0.004392 0.051745 0.021525
std 1.009208 0.999045 1.003169 1.028508
min -3.000000 -3.000000 -3.000000 -3.000000
25% -0.741905 -0.643554 -0.613592 -0.651136
50% -0.019509 -0.039399 0.036878 0.094302
75% 0.695546 0.676507 0.737588 0.712619
max 3.000000 3.000000 3.000000 3.000000
- 根据数据的值是正还是负,np.sign(data)可以生成1和-1:
np.sign(data).head()
----------------------------------------------------------------------------------
0 1 2 3
0 1.0 1.0 1.0 -1.0
1 1.0 1.0 -1.0 -1.0
2 1.0 1.0 1.0 1.0
3 -1.0 1.0 -1.0 -1.0
4 -1.0 1.0 -1.0 -1.0
排列和随机采样
- 利用
numpy.random.permutation函数可以轻松实现对Series或DataFrame的列的排列工作(permuting,随机重排序)。通过需要排列的轴的长度调用permutation,可产生一个表示新顺序的整数数组:
df = pd.DataFrame(np.arange(5 * 4).reshape((5,4)))
sampler = np.random.permutation(5)
sampler
----------------------------------------------------------------------------------
array([1, 0, 2, 3, 4])
- 然后就可以在基于
iloc的索引操作或take函数中使用该数组了:
df
----------------------------------------------------------------------------------
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
df.take(sampler)
----------------------------------------------------------------------------------
0 1 2 3
1 4 5 6 7
0 0 1 2 3
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
- 如果不想用替换的方式选取随机子集,可以在Series和DataFrame上使用sample方法:
df.sample(n=3)
----------------------------------------------------------------------------------
0 1 2 3
2 8 9 10 11
4 16 17 18 19
1 4 5 6 7
- 要通过替换的方式产生样本(允许重复选择),可以传递
replace=True到sample:
choices = pd.Series([5,7,-1,6,4])
draws = choices.sample(n=10, replace=True)
draws
----------------------------------------------------------------------------------
4 4
2 -1
1 7
0 5
0 5
3 6
3 6
3 6
1 7
4 4
dtype: int64
计算指标/哑变量
另一种常用于统计建模或机器学习的转换方式是:将分类变量(categorical variable)转换为“哑变量”或“指标矩阵”。
如果DataFrame的某一列中含有k个不同的值,则可以派生出一个k列矩阵或DataFrame(其值全为1和0)。pandas有一个get_dummies函数可以实现该功能(其实自己动手做一个也不难)。使用之前的一个DataFrame例子:
df = pd.DataFrame({
'key': ['b', 'b', 'a', 'c', 'a', 'b'],
'data1': range(6)})
df
----------------------------------------------------------------------------------
data1 key
0 0 b
1 1 b
2 2 a
3 3 c
4 4 a
5 5 b
pd.get_dummies(df['key'])
----------------------------------------------------------------------------------
a b c
0 0 1 0
1 0 1 0
2 1 0 0
3 0 0 1
4 1 0 0
5 0 1 0
有时候,你可能想给指标DataFrame的列加上一个前缀,以便能够跟其他数据进行合并。get_dummies的prefix参数可以实现该功能:
dummies = pd.get_dummies(df['key'], prefix='key')
df_with_dummy = df[['data1']].join(dummies)
df_with_dummy
----------------------------------------------------------------------------------
data1 key_a key_b key_c
0 0 0 1 0
1 1 0 1 0
2 2 1 0 0
3 3 0 0 1
4 4 1 0 0
5 5 0 1 0
如果DataFrame中的某行同属于多个分类,则事情就会有点复杂。看一下MovieLens 1M数据集
mnames = ['movie_id', 'title', 'genres']
movies = pd.read_table('data/movie/movies.dat', sep='::',
header=None, names=mnames)
movies[:10]
----------------------------------------------------------------------------------
movie_id title genres
0 1 Toy Story (1995) Animation|Children's|Comedy
1 2 Jumanji (1995) Adventure|Children's|Fantasy
2 3 Grumpier Old Men (1995) Comedy|Romance
3 4 Waiting to Exhale (1995) Comedy|Drama
4 5 Father of the Bride Part II (1995) Comedy
5 6 Heat (1995) Action|Crime|Thriller
6 7 Sabrina (1995) Comedy|Romance
7 8 Tom and Huck (1995) Adventure|Children's
8 9 Sudden Death (1995) Action
9 10 GoldenEye (1995) Action|Adventure|Thriller
- 要为每个genre添加指标变量就需要做一些数据规整操作。首先,我们从数据集中抽取出不同的genre值:
all_genres = []
for x in movies.genres:
all_genres.extend(x.split('|'))
genres = pd.unique(all_genres)
genres
----------------------------------------------------------------------------------
array(['Animation', "Children's", 'Comedy', 'Adventure', 'Fantasy',
'Romance', 'Drama', 'Action', 'Crime', 'Thriller', 'Horror',
'Sci-Fi', 'Documentary', 'War', 'Musical', 'Mystery', 'Film-Noir',
'Western'], dtype=object)
- 构建指标DataFrame的方法之一是从一个全零DataFrame开始:
zero_matrix = np.zeros((len(movies), len(genres)))
dummies = pd.DataFrame(zero_matrix, columns=genres)
现在,迭代每一部电影,并将dummies各行的条目设为1。要这么做,我们使用dummies.columns来计算每个类型的列索引:
gen = movies.genres[0]
gen.split('|')
----------------------------------------------------------------------------------
['Animation', "Children's", 'Comedy']
dummies.columns.get_indexer(gen.split('|'))
----------------------------------------------------------------------------------
array([0, 1, 2])
- 然后,根据索引,使用
.iloc设定值:
for i, gen in enumerate(movies.genres):
indices = dummies.columns.get_indexer(gen.split('|'))
dummies.iloc[i, indices] = 1
- 然后,和以前一样,再将其与movies合并起来:
movies_windic = movies.join(dummies.add_prefix('Genre_'))
movies_windic.iloc[0]
----------------------------------------------------------------------------------
movie_id 1
title Toy Story (1995)
genres Animation|Children's|Comedy
Genre_Animation 1
Genre_Children's 1
Genre_Comedy 1
Genre_Adventure 0
Genre_Fantasy 0
Genre_Romance 0
Genre_Drama 0
Genre_Action 0
Genre_Crime 0
Genre_Thriller 0
Genre_Horror 0
Genre_Sci-Fi 0
Genre_Documentary 0
Genre_War 0
Genre_Musical 0
Genre_Mystery 0
Genre_Film-Noir 0
Genre_Western 0
Name: 0, dtype: object
3. 字符串操作
Python能够成为流行的数据处理语言,部分原因是其简单易用的字符串和文本处理功能。大部分文本运算都直接做成了字符串对象的内置方法。对于更为复杂的模式匹配和文本操作,则可能需要用到正则表达式。pandas对此进行了加强,它使你能够对整组数据应用字符串表达式和正则表达式,而且能处理烦人的缺失数据。
字符串对象方法
对于许多字符串处理和脚本应用,内置的字符串方法已经能够满足要求了。例如,以逗号分隔的字符串可以用split拆分成数段:
val = 'a,b, guido'
val.split(',')
----------------------------------------------------------------------------------
['a', 'b', ' guido']
- split常常与
strip一起使用,以去除空白符(包括换行符):
pieces = [x.strip() for x in val.split(',')]
pieces
----------------------------------------------------------------------------------
['a', 'b', 'guido']
- 利用加法,可以将这些子字符串以双冒号分隔符的形式连接起来:
first, second, third = pieces
first + '::' + second + '::' + third
----------------------------------------------------------------------------------
'a::b::guido'
- 但这种方式并不是很实用。一种更快更符合Python风格的方式是,向字符串"::"的join方法传入一个列表或元组:
'::'.join(pieces)
----------------------------------------------------------------------------------
'a::b::guido'
- 其它方法关注的是子串定位。检测子串的最佳方式是利用Python的
in关键字,还可以使用index和find:
'guido' in val
True
----------------------------------------------------------------------------------
val.index(',')
1
----------------------------------------------------------------------------------
val.find(':')
-1
- 注意find和index的区别:如果找不到字符串,index将会引发一个异常(而不是返回-1):
val.index(':')
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-105-2c016e7367ac> in <module>()
----> 1 val.index(':')
ValueError: substring not found
与此相关,count可以返回指定子串的出现次数:
val.count(',')
2
replace用于将指定模式替换为另一个模式。通过传入空字符串,它也常常用于删除模式:
val.replace(',', '::')
'a::b:: guido'
val.replace(',','')
'ab guido'
下表列出了Python内置的字符串方法,这些运算大部分都能使用正则表达式实现:


正则表达式
正则表达式提供了一种灵活的在文本中搜索或匹配(通常比前者复杂)字符串模式的方式。正则表达式,常称作regex,是根据正则表达式语言编写的字符串。Python内置的re模块负责对字符串应用正则表达式。
re模块的函数可以分为三个大类:模式匹配、替换以及拆分。当然,它们之间是相辅相成的。一个regex描述了需要在文本中定位的一个模式,它可以用于许多目的。我们先来看一个简单的例子:假设想要拆分一个字符串,分隔符为数量不定的一组空白符(制表符、空格、换行符等)。描述一个或多个空白符的regex是\s+:
import re
text = 'foo bar\t baz \tqux'
re.split('\s+', text)
----------------------------------------------------------------------------------
['foo', 'bar', 'baz', 'qux']
- 调用
re.split('\s+',text)时,正则表达式会先被编译,然后再在text上调用其split方法。你可以用re.compile自己编译regex以得到一个可重用的regex对象:
regex = re.compile('\s+')
regex.split(text)
----------------------------------------------------------------------------------
['foo', 'bar', 'baz', 'qux']
如果只希望得到匹配regex的所有模式,则可以使用findall方法:
regex.findall(text)
----------------------------------------------------------------------------------
[' ', '\t ', ' \t']
如果打算对许多字符串应用同一条正则表达式,强烈建议通过re.compile创建regex对象。这样将可以节省大量的CPU时间。
match和search跟findall功能类似。findall返回的是字符串中所有的匹配项,而search则只返回第一个匹配项。match更加严格,它只匹配字符串的首部。来看一个小例子,假设我们有一段文本以及一条能够识别大部分电子邮件地址的正则表达式:
text = """Dave [email protected]
Steve [email protected]
Rob [email protected]
Ryan [email protected]
"""
pattern = r'[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}'
# re.IGNORECASE makes the regex case-insensitive
regex = re.compile(pattern, flags=re.IGNORECASE)
# 对text使用findall将得到一组电子邮件地址:
regex.findall(text)
----------------------------------------------------------------------------------------
['[email protected]', '[email protected]', '[email protected]', '[email protected]']
- search返回的是文本中第一个电子邮件地址(以特殊的匹配项对象形式返回)。对于上面那个regex,匹配项对象只能告诉我们模式在原字符串中的起始和结束位置。
m = regex.search(text)
m
----------------------------------------------------------------------------------------
<_sre.SRE_Match object; span=(5, 20), match='[email protected]'>
text[m.start():m.end()]
----------------------------------------------------------------------------------------
'[email protected]'
regex.match则将返回None,因为它只匹配出现在字符串开头的模式:
print(regex.match(text))
----------------------------------------------------------------------------------------
None
- 相关的,
sub方法可以将匹配到的模式替换为指定字符串,并返回所得到的新字符串:
print(regex.sub('REDACTED', text))
----------------------------------------------------------------------------------------
Dave REDACTED
Steve REDACTED
Rob REDACTED
Ryan REDACTED
- 假设你不仅想要找出电子邮件地址,还想将各个地址分成3个部分:用户名、域名以及域后缀。要实现此功能,只需将待分段的模式的各部分用圆括号包起来即可:
pattern = r'([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\.([A-Z]{2,4})'
regex = re.compile(pattern, flags=re.IGNORECASE)
- 由这种修改过的正则表达式所产生的匹配项对象,可以通过其
groups方法返回一个由模式各段组成的元组:
m = regex.match('[email protected]')
m.groups()
----------------------------------------------------------------------------------------
('wesm', 'bright', 'net')
对于带有分组功能的模式,findall会返回一个元组列表:
regex.findall(text)
----------------------------------------------------------------------------------------
[('dave', 'google', 'com'),
('steve', 'gmail', 'com'),
('rob', 'gmail', 'com'),
('ryan', 'yahoo', 'com')]
sub还能通过诸如\1、\2之类的特殊符号访问各匹配项中的分组。符号\1对应第一个匹配的组,\2对应第二个匹配的组,以此类推:
print(regex.sub(r'Username: \1, Domain: \2, Suffix: \3', text))
----------------------------------------------------------------------------------------
Dave Username: dave, Domain: google, Suffix: com
Steve Username: steve, Domain: gmail, Suffix: com
Rob Username: rob, Domain: gmail, Suffix: com
Ryan Username: ryan, Domain: yahoo, Suffix: com
pandas的矢量化字符串函数
清理待分析的散乱数据时,常常需要做一些字符串规整化工作。更为复杂的情况是,含有字符串的列有时还含有缺失数据:
data = {
'Dave': '[email protected]', 'Steve': '[email protected]',
'Rob': '[email protected]', 'Wes': np.nan}
data = pd.Series(data)
data
-----------------------------------------------------------------------
Dave dave@google.com
Rob rob@gmail.com
Steve steve@gmail.com
Wes NaN
dtype: object
data.isnull()
-----------------------------------------------------------------------
Dave False
Rob False
Steve False
Wes True
dtype: bool
- 通过
data.map,所有字符串和正则表达式方法都能被应用于(传入lambda表达式或其他函数)各个值,但是如果存在NA(null)就会报错。为了解决这个问题,Series有一些能够跳过NA值的面向数组方法,进行字符串操作。通过Series的str属性即可访问这些方法。例如,我们可以通过str.contains检查各个电子邮件地址是否含有"gmail":
data.str.contains('gmail')
-----------------------------------------------------------------------
Dave False
Rob True
Steve True
Wes NaN
dtype: object
- 也可以使用正则表达式,还可以加上任意
re选项(如IGNORECASE):
pattern
-----------------------------------------------------------------------
'([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\\.([A-Z]{2,4})'
data.str.findall(pattern, flags=re.IGNORECASE)
-----------------------------------------------------------------------
Dave [(dave, google, com)]
Rob [(rob, gmail, com)]
Steve [(steve, gmail, com)]
Wes NaN
dtype: object
- 有两个办法可以实现矢量化的元素获取操作:要么使用
str.get,要么在str属性上使用索引:
matches = data.str.match(pattern, flags=re.IGNORECASE)
matches
---------------------------------------------------------------------------
Dave True
Rob True
Steve True
Wes NaN
dtype: object
- 要访问嵌入列表中的元素,我们可以传递索引到这两个函数中:
data.str.get(1)
---------------------------------------------------------------------------
Dave a
Rob o
Steve t
Wes NaN
dtype: object
data.str[0]
---------------------------------------------------------------------------
Dave d
Rob r
Steve s
Wes NaN
dtype: object
- 你可以利用这种方法对字符串进行截取:
data.str[:5]
---------------------------------------------------------------------------
Dave dave@
Rob rob@g
Steve steve
Wes NaN
dtype: object
- 下表介绍了更多的
pandas字符串方法:
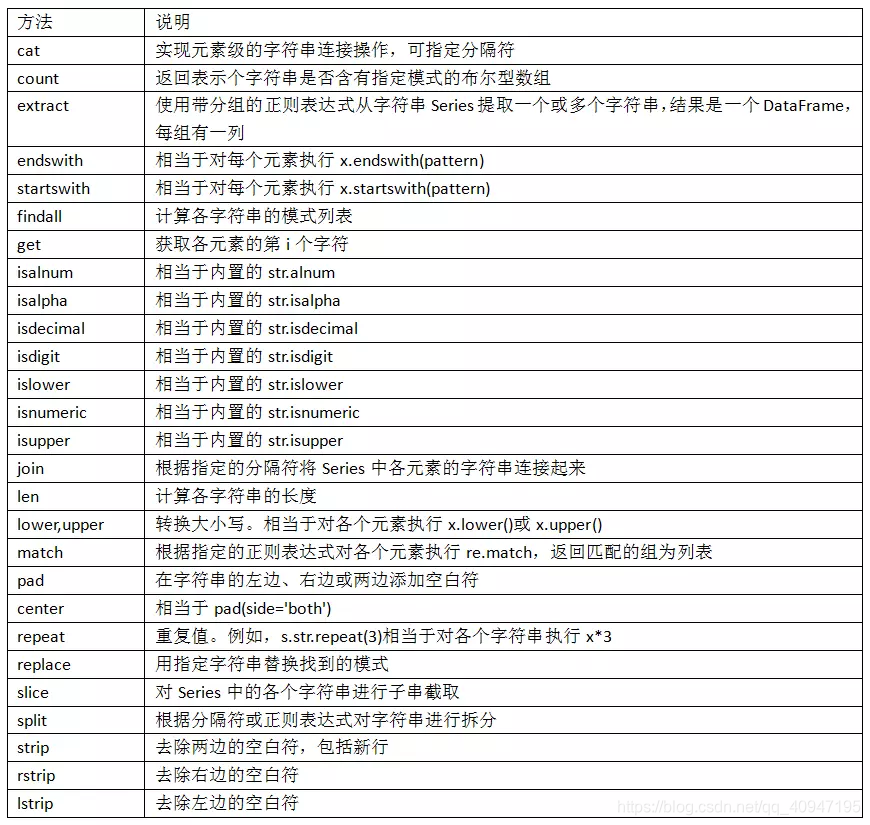
案例:食谱数据库
前面介绍的这些向量化字符串操作方法非常适合用来处理现实中那些凌 乱的数据。下面将通过一个从不同网站获取的公开食谱数据库的案例来 进行演示。我们的目标是将这些食谱数据解析为食材列表,这样就可以 根据现有的食材快速找到食谱。
获取数据的脚本可以在https://github.com/fictivekin/openrecipes上找到, 那里还有最新版的数据库链接。
这个数据库是 JSON 格式的,来试试通过 pd.read_json 读取数据:
try:
recipes = pd.read_json('data/openrecipes.txt')
except ValueError as e:
print("ValueError:", e)
---------------------------------------------------------------------------
ValueError: Trailing data
提示数据里有“trailing data”(数据断行)的 ValueError 错误。原因是虽然文件中的每一行都是一个有效的 JSON 对象,但是全文却不是这样。来看看文件是不是这样:
with open('data/openrecipes.txt') as f:
line = f.readline()
print(line)
---------------------------------------------------------------------------
{
"name": "Easter Leftover Sandwich", "ingredients": "12 whole Hard Boiled Eggs\n1/2 cup Mayonnaise\n3 Tablespoons Grainy Dijon Mustard\n Salt And Pepper, to taste\n Several Dashes Worcestershire Sauce\n Leftover Baked Ham, Sliced\n Kaiser Rolls Or Other Bread\n Extra Mayonnaise And Dijon, For Spreading\n Swiss Cheese Or Other Cheese Slices\n Thinly Sliced Red Onion\n Avocado Slices\n Sliced Tomatoes\n Lettuce, Spinach, Or Arugula", "url": "http://thepioneerwoman.com/cooking/2013/04/easter-leftover-sandwich/", "image": "http://static.thepioneerwoman.com/cooking/files/2013/03/leftoversandwich.jpg", "cookTime": "PT", "recipeYield": "8", "datePublished": "2013-04-01", "prepTime": "PT15M", "description": "Got leftover Easter eggs? Got leftover Easter ham? Got a hearty appetite? Good! You've come to the right place! I..."}
显然每一行都是一个有效的 JSON 对象,因此需要将这些字符串连接在 一起。解决这个问题的一种方法就是新建一个字符串,将所有行 JSON 对象连接起来,然后再通过 pd.read_json 来读取所有数据:
import pandas as pd
# 将文件内容读取成Python数组
with open('data/openrecipes.txt', 'r') as f:
# 提取每一行内容
data = (line.strip() for line in f)
# 将所有内容合并成一个列表
data_json = "[{0}]".format(','.join(data))
# 用JSON形式读取数据
recipes = pd.read_json(data_json)
recipes.shape
---------------------------------------------------------------------------
(1042, 9)
- 这样就会看到将1000多份食谱,共 9 列。抽一行看看具体内容:
recipes.iloc[0]
---------------------------------------------------------------------------
cookTime PT
datePublished 2013-04-01
description Got leftover Easter eggs? Got leftover East...
image http://static.thepioneerwoman.com/cooking/file...
ingredients 12 whole Hard Boiled Eggs\n1/2 cup Mayonnaise\...
name Easter Leftover Sandwich
prepTime PT15M
recipeYield 8
url http://thepioneerwoman.com/cooking/2013/04/eas...
Name: 0, dtype: object
这里有一堆信息,而且其中有不少都和从网站上抓取的数据一样,字段 形式混乱。值得关注的是,食材列表是字符串形式,我们需要从中抽取 感兴趣的信息。下面来仔细看看这个字段:
recipes.ingredients.str.len().describe()
---------------------------------------------------------------------------
count 1042.000000
mean 358.645873
std 187.332133
min 22.000000
25% 246.250000
50% 338.000000
75% 440.000000
max 3160.000000
Name: ingredients, dtype: float64
食材列表平均 250 个字符,最短的字符串是 22,最长的竟然3000多字符!
来看看这个拥有最长食材列表的究竟是哪道菜:
recipes.name[np.argmax(recipes.ingredients.str.len())]
---------------------------------------------------------------------------
'A Nice Berry Pie'
我们还可以再做一些累计探索,例如看看哪些食谱是早餐:
recipes.description.str.contains('[Bb]reakfast').sum()
---------------------------------------------------------------------------
11
或者看看有多少食谱用肉桂(cinnamon)作为食材:
recipes.ingredients.str.contains('[Cc]innamon').sum()
---------------------------------------------------------------------------
79
还可以看看究竟是哪些食谱里把肉桂错写成了“cinamon”:
recipes.ingredients.str.contains('[Cc]inamon').sum()
---------------------------------------------------------------------------
0
现在让我们更进一步,来制作一个简易的美食推荐系统:如果用户 提供一些食材,系统就会推荐使用了所有食材的食谱。这说起来是 容易,但是由于大量不规则(heterogeneity)数据的存在,这个任 务变得十分复杂,例如并没有一个简单直接的办法可以从每一行数 据中清理出一份干净的食材列表。因此,我们在这里简化处理:首 先提供一些常见食材列表,然后通过简单搜索判断这些食材是否在 食谱中。为了简化任务,这里只列举常用的香料和调味料:
spice_list = ['salt', 'pepper', 'oregano', 'sage', 'parsley', 'rosemary', 'tarragon', 'thyme', 'paprika', 'cumin']
现在就可以通过一个由 True 与 False 构成的布尔类型的 DataFrame 来判断食材是否出现在某个食谱中:
import time
start = time.time()
spice_df = pd.DataFrame(dict((spice, recipes.ingredients.str.contains(spice, re.IGNORECASE,)) for spice in spice_list))
print(time.time() - start)
#spice_df[spice_df.any(1)]
0.011888265609741211
现在,来找一份使用了pepper、salt和sage这三种食材的食谱。我们可以通过 DataFrame 的 query() 方法来快速完成计算
%timeit selection = spice_df.query('pepper & salt & sage')
# selection
# len(selection)
1.57 ms ± 6.94 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%timeit spice_df["pepper"] & spice_df["salt"]& spice_df["sage"]
391 µs ± 28 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
- 让我们用索引看看 究竟是哪些食谱:
recipes.iloc[selection.index][['name', 'ingredients']]
name ingredients
687 1 quart (4 cups) water\n1 bay leaf\n2 sage lea...
1014 Spiced Candied Walnuts Recipe Peanut or canola oil for deep-frying (hs note:...
recipes.head()
cookTime datePublished description image ingredients name prepTime recipeYield url
0 PT 2013-04-01 Got leftover Easter eggs? Got leftover East... http://static.thepioneerwoman.com/cooking/file... 12 whole Hard Boiled Eggs\n1/2 cup Mayonnaise\... Easter Leftover Sandwich PT15M 8 http://thepioneerwoman.com/cooking/2013/04/eas...
1 PT10M 2011-06-06 I finally have basil in my garden. Basil I can... http://static.thepioneerwoman.com/cooking/file... 3/4 cups Fresh Basil Leaves\n1/2 cup Grated Pa... Pasta with Pesto Cream Sauce PT6M 8 http://thepioneerwoman.com/cooking/2011/06/pas...
2 PT15M 2011-09-15 This was yummy. And easy. And pretty! And it t... http://static.thepioneerwoman.com/cooking/file... 2 whole Pork Tenderloins\n Salt And Pepper, to... Herb Roasted Pork Tenderloin with Preserves PT5M 12 http://thepioneerwoman.com/cooking/2011/09/her...
3 PT20M 2012-04-23 I made this for a late lunch Saturday, and it ... http://static.thepioneerwoman.com/cooking/file... 1 pound Penne\n4 whole Boneless, Skinless Chic... Chicken Florentine Pasta PT10M 10 http://thepioneerwoman.com/cooking/2012/04/chi...
4 PT 2011-06-13 Iced coffee is my life. When I wake up, often ... http://static.thepioneerwoman.com/cooking/file... 1 pound Ground Coffee (good, Rich Roast)\n8 qu... Perfect Iced Coffee PT8H 24 http://thepioneerwoman.com/cooking/2011/06/per...
spice_list = ['salt', 'pepper', 'oregano', 'sage', 'parsley', 'rosemary', 'tarragon', 'thyme', 'paprika', 'cumin']
---------------------------------------------------------------------------
#init dict
dict_inverse_index = {
}
for i in spice_list:
dict_inverse_index[i] = set()
ingredients = recipes.ingredients.values
---------------------------------------------------------------------------
start = time.time()
for recipe_index in range(len(ingredients)):
for spice in spice_list:
if(spice in ingredients[recipe_index]):
dict_inverse_index[spice].add(recipe_index)
print(time.time() - start)
0.005366086959838867
#selection = spice_df.query('pepper | salt | sage')
%timeit dict_inverse_index["pepper"] & dict_inverse_index["salt"] & dict_inverse_index["sage"]
2.95 µs ± 24.8 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
智能推荐
使用nginx解决浏览器跨域问题_nginx不停的xhr-程序员宅基地
文章浏览阅读1k次。通过使用ajax方法跨域请求是浏览器所不允许的,浏览器出于安全考虑是禁止的。警告信息如下:不过jQuery对跨域问题也有解决方案,使用jsonp的方式解决,方法如下:$.ajax({ async:false, url: 'http://www.mysite.com/demo.do', // 跨域URL ty..._nginx不停的xhr
在 Oracle 中配置 extproc 以访问 ST_Geometry-程序员宅基地
文章浏览阅读2k次。关于在 Oracle 中配置 extproc 以访问 ST_Geometry,也就是我们所说的 使用空间SQL 的方法,官方文档链接如下。http://desktop.arcgis.com/zh-cn/arcmap/latest/manage-data/gdbs-in-oracle/configure-oracle-extproc.htm其实简单总结一下,主要就分为以下几个步骤。..._extproc
Linux C++ gbk转为utf-8_linux c++ gbk->utf8-程序员宅基地
文章浏览阅读1.5w次。linux下没有上面的两个函数,需要使用函数 mbstowcs和wcstombsmbstowcs将多字节编码转换为宽字节编码wcstombs将宽字节编码转换为多字节编码这两个函数,转换过程中受到系统编码类型的影响,需要通过设置来设定转换前和转换后的编码类型。通过函数setlocale进行系统编码的设置。linux下输入命名locale -a查看系统支持的编码_linux c++ gbk->utf8
IMP-00009: 导出文件异常结束-程序员宅基地
文章浏览阅读750次。今天准备从生产库向测试库进行数据导入,结果在imp导入的时候遇到“ IMP-00009:导出文件异常结束” 错误,google一下,发现可能有如下原因导致imp的数据太大,没有写buffer和commit两个数据库字符集不同从低版本exp的dmp文件,向高版本imp导出的dmp文件出错传输dmp文件时,文件损坏解决办法:imp时指定..._imp-00009导出文件异常结束
python程序员需要深入掌握的技能_Python用数据说明程序员需要掌握的技能-程序员宅基地
文章浏览阅读143次。当下是一个大数据的时代,各个行业都离不开数据的支持。因此,网络爬虫就应运而生。网络爬虫当下最为火热的是Python,Python开发爬虫相对简单,而且功能库相当完善,力压众多开发语言。本次教程我们爬取前程无忧的招聘信息来分析Python程序员需要掌握那些编程技术。首先在谷歌浏览器打开前程无忧的首页,按F12打开浏览器的开发者工具。浏览器开发者工具是用于捕捉网站的请求信息,通过分析请求信息可以了解请..._初级python程序员能力要求
Spring @Service生成bean名称的规则(当类的名字是以两个或以上的大写字母开头的话,bean的名字会与类名保持一致)_@service beanname-程序员宅基地
文章浏览阅读7.6k次,点赞2次,收藏6次。@Service标注的bean,类名:ABDemoService查看源码后发现,原来是经过一个特殊处理:当类的名字是以两个或以上的大写字母开头的话,bean的名字会与类名保持一致public class AnnotationBeanNameGenerator implements BeanNameGenerator { private static final String C..._@service beanname
随便推点
二叉树的各种创建方法_二叉树的建立-程序员宅基地
文章浏览阅读6.9w次,点赞73次,收藏463次。1.前序创建#include<stdio.h>#include<string.h>#include<stdlib.h>#include<malloc.h>#include<iostream>#include<stack>#include<queue>using namespace std;typed_二叉树的建立
解决asp.net导出excel时中文文件名乱码_asp.net utf8 导出中文字符乱码-程序员宅基地
文章浏览阅读7.1k次。在Asp.net上使用Excel导出功能,如果文件名出现中文,便会以乱码视之。 解决方法: fileName = HttpUtility.UrlEncode(fileName, System.Text.Encoding.UTF8);_asp.net utf8 导出中文字符乱码
笔记-编译原理-实验一-词法分析器设计_对pl/0作以下修改扩充。增加单词-程序员宅基地
文章浏览阅读2.1k次,点赞4次,收藏23次。第一次实验 词法分析实验报告设计思想词法分析的主要任务是根据文法的词汇表以及对应约定的编码进行一定的识别,找出文件中所有的合法的单词,并给出一定的信息作为最后的结果,用于后续语法分析程序的使用;本实验针对 PL/0 语言 的文法、词汇表编写一个词法分析程序,对于每个单词根据词汇表输出: (单词种类, 单词的值) 二元对。词汇表:种别编码单词符号助记符0beginb..._对pl/0作以下修改扩充。增加单词
android adb shell 权限,android adb shell权限被拒绝-程序员宅基地
文章浏览阅读773次。我在使用adb.exe时遇到了麻烦.我想使用与bash相同的adb.exe shell提示符,所以我决定更改默认的bash二进制文件(当然二进制文件是交叉编译的,一切都很完美)更改bash二进制文件遵循以下顺序> adb remount> adb push bash / system / bin /> adb shell> cd / system / bin> chm..._adb shell mv 权限
投影仪-相机标定_相机-投影仪标定-程序员宅基地
文章浏览阅读6.8k次,点赞12次,收藏125次。1. 单目相机标定引言相机标定已经研究多年,标定的算法可以分为基于摄影测量的标定和自标定。其中,应用最为广泛的还是张正友标定法。这是一种简单灵活、高鲁棒性、低成本的相机标定算法。仅需要一台相机和一块平面标定板构建相机标定系统,在标定过程中,相机拍摄多个角度下(至少两个角度,推荐10~20个角度)的标定板图像(相机和标定板都可以移动),即可对相机的内外参数进行标定。下面介绍张氏标定法(以下也这么称呼)的原理。原理相机模型和单应矩阵相机标定,就是对相机的内外参数进行计算的过程,从而得到物体到图像的投影_相机-投影仪标定
Wayland架构、渲染、硬件支持-程序员宅基地
文章浏览阅读2.2k次。文章目录Wayland 架构Wayland 渲染Wayland的 硬件支持简 述: 翻译一篇关于和 wayland 有关的技术文章, 其英文标题为Wayland Architecture .Wayland 架构若是想要更好的理解 Wayland 架构及其与 X (X11 or X Window System) 结构;一种很好的方法是将事件从输入设备就开始跟踪, 查看期间所有的屏幕上出现的变化。这就是我们现在对 X 的理解。 内核是从一个输入设备中获取一个事件,并通过 evdev 输入_wayland