使用MindStudio开发铝材表面缺陷检测_铝材缺陷检测算法流程图-程序员宅基地
技术标签: 深度学习 目标检测 AI 人工智能 ai MindStudio
BiliBili视频链接:使用MindStudio开发铝材表面缺陷检测_哔哩哔哩_bilibili
使用MindStudio开发铝材表面缺陷检测
目 录
3 未修改pipeline中后处理插件的postProcessLibPath属性
1. MindStudio介绍
MindStudio提供AI开发所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够使开发者在一个工具上就能高效便捷地完成AI应用开发 ·MindStudio采用了插件化扩展机制,开发者可以通过开发插件来扩展已有功能。MindStudio-昇腾社区 (hiascend.com)
2. 案例模型
在本案例中,目的是基于MindX SDK,在华为云昇腾平台上,使用MindStudio开发端到端铝材缺陷检测的参考设计,实现对图像中的铝材进行缺陷类型分类和定位的功能,达到功能要求,并对精度进行测试。
3. 环境搭建
开发环境为windows版本的MindStudio,运行环境在远端linux上。
3.1 安装MindX SDK和CANN包并配置环境变量
请先确保远端环境上MindX SDK软件包已安装完成,安装方式请参见安装MindX SDK开发套件。
确保远端环境上CANN包已安装完成,安装方式请参见该链接
在远端服务器上配置环境变量
- 执行如下命令,打开.bashrc文件
vim ~/.bashrc
在.bashrc文件中添加以下环境变量
. ${MX_SDK_HOME}/set_env.sh
. ${HOME}/Ascend/ascend-toolkit/set_env.sh
其中${MX_SDK_HOME}为MindX SDK安装目录,${HOME}为用户目录(如果CANN 开发包装在用户目录,否则为/usr/local/),配置的时候请自行替换成相应目录
保存退出.bashrc文件
执行如下命令使环境变量生效
source ~/.bashrc
查看环境变量
env
3.2 在windows开发环境同步CANN
工具栏点击“File > Settings > Appearance & Behavior > System Settings > CANN”进入CANN管理界面。点击Change CANN配置CANN包。
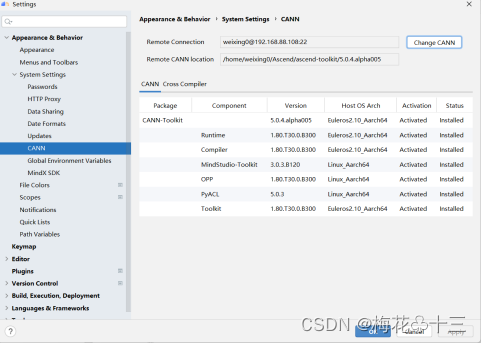
配置远程连接以及远端CANN包路径(配置到版本号一级)
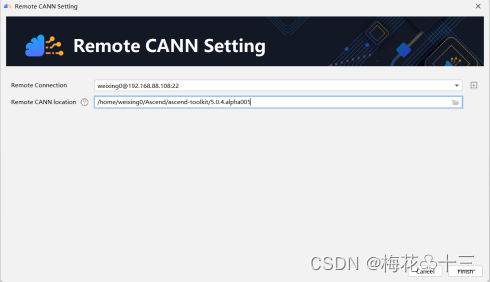
3.3 在windows开发环境同步MindX SDK
工具栏点击“File > Settings > Appearance & Behavior > System Settings > MindX SDK”或依次点击“Ascend>MindX SDK Manager”进入MindX SDK管理界面。界面中“MindX SDK Location”为软件包的默认安装路径,默认安装路径为“C:\Users*用户名*\Ascend\mindx_sdk”。单击“Install SDK”进入“Installation settings”界面。
在“Installation settings”界面
-
- “Remote Connection”:远程连接的用户及IP。
- “Remote CANN Location”:远端环境上CANN开发套件包的路径,请配置到版本号一级。
- “Remote SDK Location”:远端环境上SDK的路径,请配置到版本号一级。IDE将同步该层级下的“include”、“opensource”、“python”、“samples”文件夹到本地Windows环境,层级选择错误将导致安装失败。
- “Local SDK Location”:同步远端环境上SDK文件夹到本地的路径。默认安装路径为“C:\Users*用户名*\Ascend\mindx_sdk”。
安装完成之后,界面如图所示:
4. 开发过程
4.1 创建工程
工具栏点击“File > New > Project
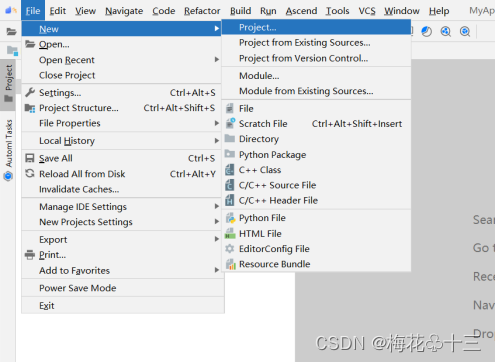
选择左侧Ascend APP,创建Ascend APP应用工程,,创建MindX SDK空白工程(提供MindX SDK开发框架,不包含代码逻辑),点击finish完成创建。
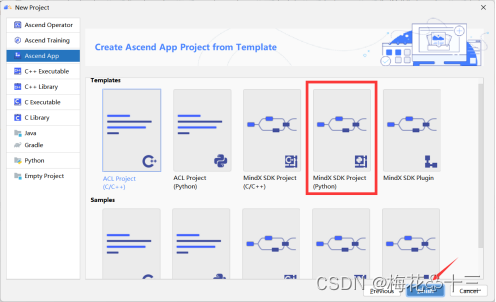
创建完成之后目录结构如下图所示
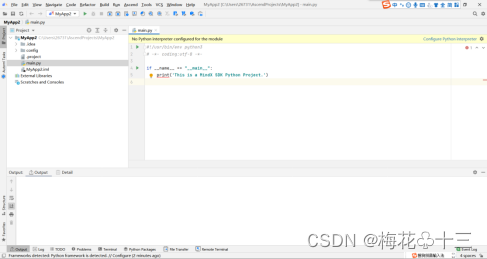
删除config文件夹,创建models和pipeline里的文件,以备后续开发自己的业务流程,目录结构如图所示。
4.2 配置python解释器
依次点击File->Project Structure,选择SDKs,添加Python SDK如下图所示:
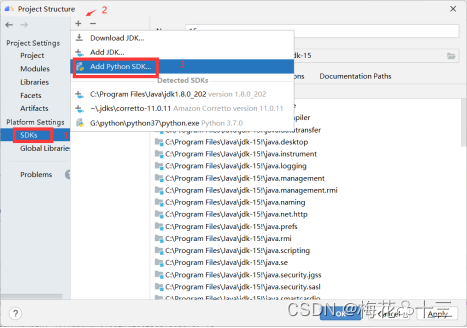
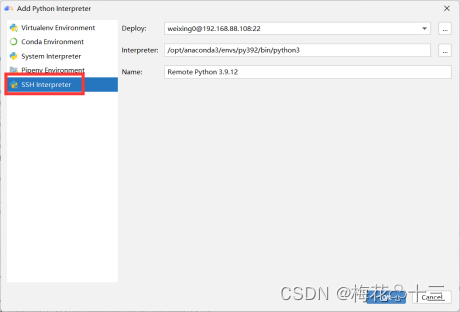
选择SSH interpreter,配置远程服务器,MindStudio会自动侦测远程python环境(如果PATH环境变量已正确配置python的路径),点击OK
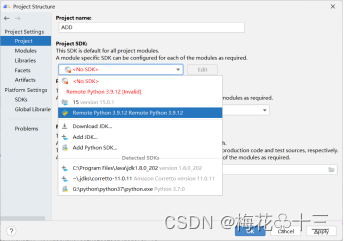
Project中选择配置好的远程SDK,点击Apply点击OK。完成python解释器的配置。
4.3 开发步骤
4.3.1 确定业务流程
根据铝材表面缺陷检测SDK推理的具体需求,这里将流程依次划分为图片获取、图片解码、图像缩放、目标检测、序列化、结果发送。
4.3.2 寻找合适的插件
首先根据已有SDK插件的功能描述和规格限制来匹配业务功能(SDK插件列表详见已有插件介绍)。当SDK提供的插件无法满足功能需求时,用户可以参考插件开发介绍开发自定义插件,该部分为SDK高阶特性。在本案例中,已有SDK插件已经满足业务需求。铝材表面缺陷检测流程图以及pipeline编排流程图如下所示:

- 1 铝材表面缺陷检测流程图
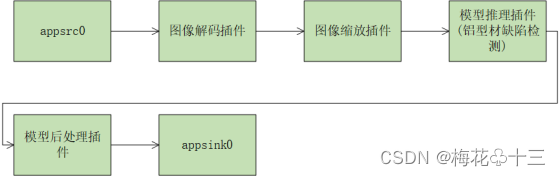
- 2 铝材表面缺陷检测pipeline示意图
4.3.3 准备模型推理文件和数据
步骤1 训练铝材缺陷检测对应的yolov5模型,输出pt模型文件。
步骤2 将pt模型文件转换成onnx,也可直接通过以下链接下载onnx模型。
下载yolov5官方源码6.1版本Releases · ultralytics/yolov5 (github.com),进入项目根目录,将best.pt模型文件复制到项目目录,执行命令
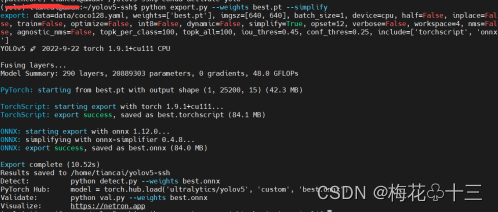
python export.py --weights best.pt –simplify
模型转换成功之后,显示的日志信息如下图所示,在项目根目录会生成best.onnx模型文件
步骤3 将转化后的YOLOv5模型onnx文件存放至./models/yolov5/。
步骤4 AIPP配置
由于yolov5模型的输入为rgb格式,pipeline中的图像解码为yuv格式,且数据类型不同,需要在atc转换模型时使用aipp预处理,该案例所需进行的aipp预处理包括色域转化以及归一化操作,aipp配置步骤如下:
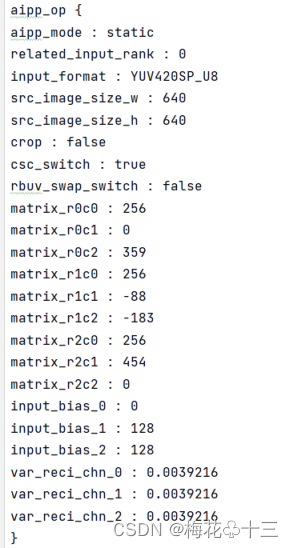
在./models/yolov5文件夹创建insert_op.cfg配置文件,所需添加的配置内容的属性:
| 参数 |
参数说明 |
| aipp_mode |
每次模型推理过程采用固定的AIPP预处理参数进行处理 |
| Related_input_rank |
related_input_rank参数为可选,标识对模型的第几个输入做AIPP处理,从0开始,默认为0。例如模型有两个输入,需要对第2个输入做AIPP,则配置related_input_rank为1。 # 类型: 整型 |
| Input_format |
输入图像格式,必选。取值范围:YUV420SP_U8、XRGB8888_U8、RGB888_U8、YUV400_U8 |
| src_image_size_w src_image_size_h |
原始图像的宽度、高度 宽度取值范围为[2,4096]或0;高度取值范围为[1,4096]或0,对于YUV420SP_U8类型的图像,要求原始图像的宽和高取值是偶数 |
| crop |
AIPP处理图片时是否支持抠图 类型:bool 取值范围:true/false,true表示支持,false表示不支持 |
| Csc_switch |
色域转换开关,静态AIPP配置 类型:bool 取值范围:true/false,true表示开启色域转换,false表示关闭 |
| rbuv_swap_switch |
R通道与B通道交换开关/U通道与V通道交换开关 类型:bool 取值范围:true/false,true表示开启通道交换,false表示关闭 |
| matrix_rxcy |
X和y代表矩阵的行和列 一旦确认了AIPP处理前与AIPP处理后的图片格式,即可确定色域转换相关的参数值(matrix_r*c*配置项的值是固定的,不需要调整) |
| var_reci_chn |
归一化配置参数 把需要处理的数据经过处理后限制在一定范围内,方便后面数据的处理。 pixel_out_chx(i)=[pixel_in_chx(i)-mean_chn_i-min_chn_i]*var_reci_chn |
最终配置参数如下图所示:
配置文件的教程请参考如下链接:配置文件模板 - CANN 5.0.4 ATC工具使用指南 01 - 华为 (huawei.com)
- 5 模型转换
模型转换有两种方式,一种是通过MindStudio可视化操作,另一种是通过命令行的方式,使用MindStudio进行模型转换参考该链接。
使用命令方式进行模型转换步骤如下:
首先开启一个SSH会话

切换到项目根目录,运行如下命令:
atc --input_shape="images:1,3,640,640" --out_nodes="Transpose_286:0;Transpose_336:0;Transpose_386:0" --output_type=FP32 --input_format=NCHW --output="./models/yolov5/yolov5_add_bs1_fp16" --soc_version=Ascend310 --framework=5 --model="./models/yolov5/best.onnx" --insert_op_conf=./models/yolov5/insert_op.cfg
模型转换成功,模型保存在--output定义的路径下,输出结果如图所示:

Atc中各个参数代表的含义请参考这个链接:参数说明 - CANN 5.0.4 ATC工具使用指南 01 - 华为 (huawei.com)。常见的报错请参考这个链接:FAQ - CANN 5.0.4 ATC工具使用指南 01 - 华为 (huawei.com)
4.3.4 编写后处理配置文件
在./models/yolov5创建模型后处理配置文件yolov5addbs1_fp16.cfg,对后处理参数进行配置:
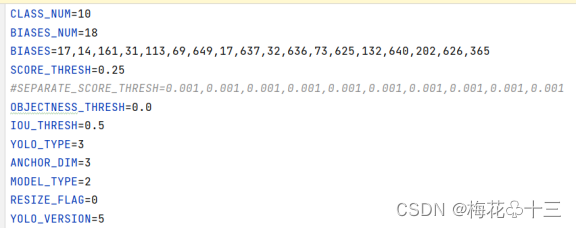
表1 配置文件中各个参数的意义
| 参数名称 |
参数介绍 |
修改方法 |
默认值 |
| CLASS_NUM |
铝材缺陷检测的类别数目。 |
在models/yolov5/yolov5_add_bs1_fp16.cfg文件中修改CLASS_NUM的大小即可 |
10 |
| BIASES_NUM |
铝材缺陷检测锚点框数量 |
在models/yolov5/yolov5_add_bs1_fp16.cfg文件中修改BIASES_NUM的大小即可 |
18 |
| BIASES |
铝材缺陷检测锚点框,用kmeans计算最合适的锚点框 |
在models/yolov5/yolov5_add_bs1_fp16.cfg文件中修改BIASES即可 |
17,14,161,31,113,69,649,17,637,32,636,73,625,132,640,202,626,365 |
| YOLO_TYPE |
YOLO输出特征向量的维度数,YOLOv5使用的是3 |
在models/yolov5/yolov5_add_bs1_fp16.cfg文件中修改YOLO_TYPE即可 |
3 |
| SCORE_THRESH |
是否为框的阈值,大于此值才认定为框 |
在models/yolov5/yolov5_add_bs1_fp16.cfg文件中修改SCORE_THRESH的大小即可 |
0.25 |
| IOU_THRESH |
两个框的IOU阈值,超过此值则被认定为同一个框,用于nms算法 |
在models/yolov5/yolov5_add_bs1_fp16.cfg文件中修改IOU_THRESH的大小即可 |
0.5 |
| OBJECTNESS_THRESH |
识别目标置信度的阈值,大于阈值才会认定为目标 |
在models/yolov5/yolov5_add_bs1_fp16.cfg文件中修改OBJECTNESS_THRESH的大小即可 |
0.0 |
| YOLO_VERSION |
YOLO版本号,本项目使用的YOLOv5,故取值为5 |
在models/yolov5/yolov5_add_bs1_fp16.cfg文件中修改YOLO_VERSION的大小即可 |
5 |
4.3.5 配置names文件
在./models/yolov5文件夹下创建aldefectdetection.names文件,按顺序配置相应类名,该文件为数据集中所有类别,后处理插件通过读取改文件,返回准确的类别名称,达到缺陷识别的目的:

4.3.6 可视化流程编排
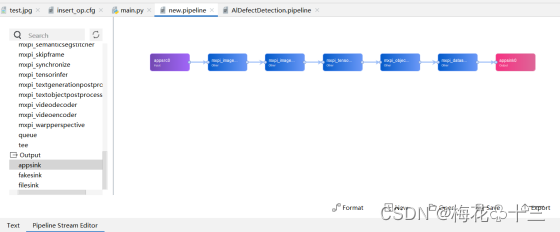
根据已经确定的业务流程和合适的插件,利用MindStudio进行可视化插件编排,需要用到的为以下六个插件。
- 1. appsrc # 输入
- 2. mxpi_imagedecoder # 图像解码
- 3. mxpi_imageresize # 图像缩放
- 4. mxpi_tensorinfer # 模型推理(铝材缺陷检测)
- 5. mxpi_objectpostprocessor # 模型后处理(yolov5)
- 6. appsink # 输出
用MindStudio进行可视化流程编排,工具栏依次点击“Ascend > MindX SDK Pipeline :
搜索流程编排中需要用到的插件:
将插件依次拖动到如下界面并连接起来,Format选项可以整理插件连接的排列,让界面更加美观。
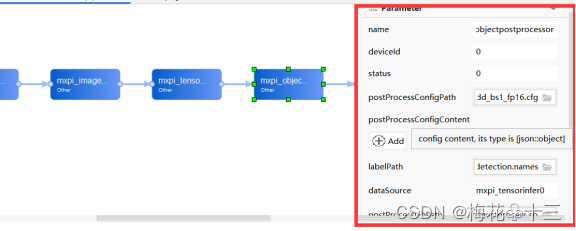
点击需要配置参数的插件,在如下区域设置合适的参数:
点击save,生成相应的pipeline代码,该代码会将可视化pipeline中设置的参数也加载到对应的插件中去:
{
"classification+detection": {
"stream_config": {
"deviceId": "0"
},
"appsrc0": {
"props": {
"blocksize": "409600"
},
"factory": "appsrc",
"next": "mxpi_imagedecoder0"
},
"mxpi_imagedecoder0": {
"factory": "mxpi_imagedecoder",
"next": "mxpi_imageresize0"
},
"mxpi_imageresize0": {
"props": {
"dataSource": "mxpi_imagedecoder0",
"resizeType": "Resizer_KeepAspectRatio_Fit",
"resizeWidth":"640",
"resizeHeight":"640",
"paddingType":"Padding_NO",
"interpolation":"2"
},
"factory": "mxpi_imageresize",
"next": "mxpi_tensorinfer0"
},
"mxpi_tensorinfer0": {
"props": {
"dataSource": "mxpi_imageresize0",
"modelPath": "./models/yolov5/yolov5_add_bs1_fp16.om"
},
"factory": "mxpi_tensorinfer",
"next": "mxpi_objectpostprocessor0"
},
"mxpi_objectpostprocessor0": {
"props": {
"dataSource": "mxpi_tensorinfer0",
"postProcessConfigPath": "./models/yolov5/yolov5_add_bs1_fp16.cfg",
"labelPath": "./models/yolov5/aldefectdetection.names",
"postProcessLibPath": "${HOME}/MindX_SDK/mxVision-2.0.4/lib/modelpostprocessors/libyolov3postprocess.so"
},
"factory": "mxpi_objectpostprocessor",
"next": "mxpi_dataserialize0"
},
"mxpi_dataserialize0": {
"props": {
"outputDataKeys": "mxpi_objectpostprocessor0"
},
"factory": "mxpi_dataserialize",
"next": "appsink0"
},
"appsink0": {
"props": {
"blocksize": "4096000"
},
"factory": "appsink"
}
}
}
可视化流程编排极大地提升了开发效率,通过这种方式用户可以很快的完成pipeline的编排。
4.3.7 编写main.py文件
main文件的编写逻辑如下图所示:
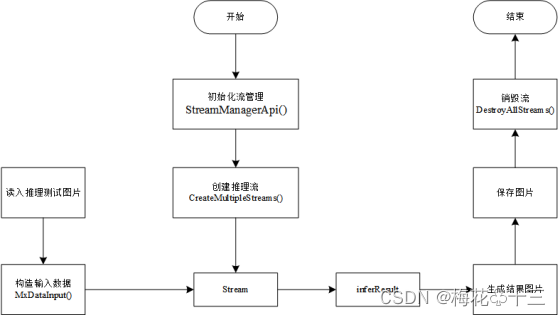
按照上述流程图,完成代码开发,其中,通过SendDataWithUniqueId将数据送入流里,GetResultWithUniqueId从流里获取数据,最终用opencv将位置信息和类别信息标记在图片上并保存。
主函数main.py:
-
- 初始化流管理器,如果初始化失败,则提示用户并退出程序:
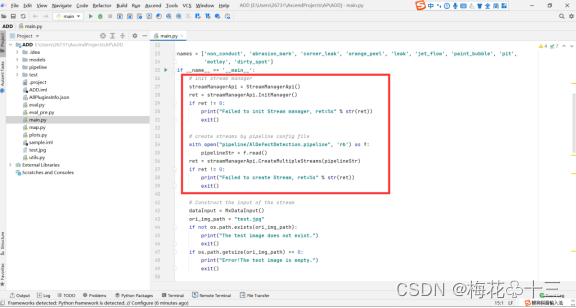
2.通过streamManagerApi创建流,导入pipeline文件,如果失败,则提示用户并退出程序

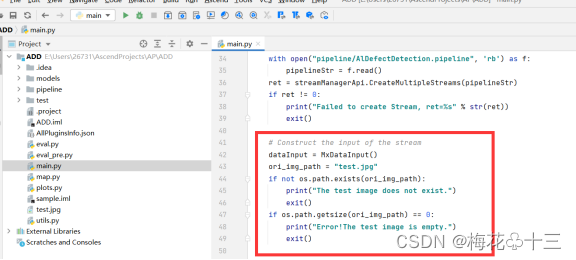
3. 构建输入数据,并对输入数据进行检查,确保输入的图片存在且不为空,否则提示用户并退出程序。
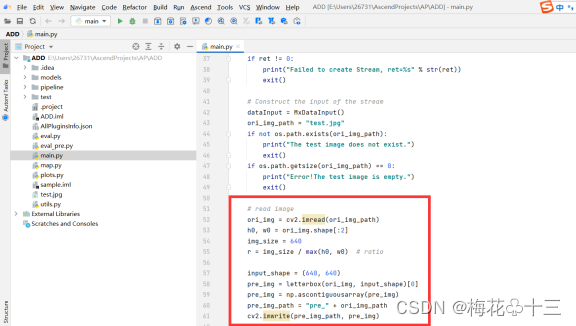
4. 对输入数据进行预处理,对齐YOLOv5数据预处理操作。
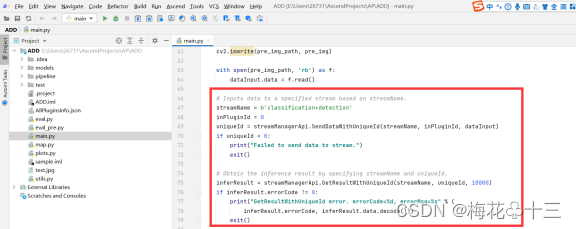
5. 将输入数据传入到指定流中,并通过uniqueId获取指定流的输出结果:
6. 读取流中的结果,并将位置信息和类别信息输出到图片上,保存图片
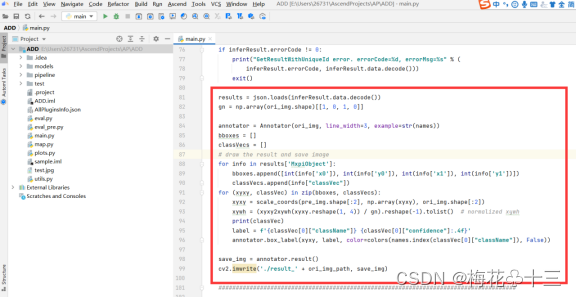
7. 销毁流
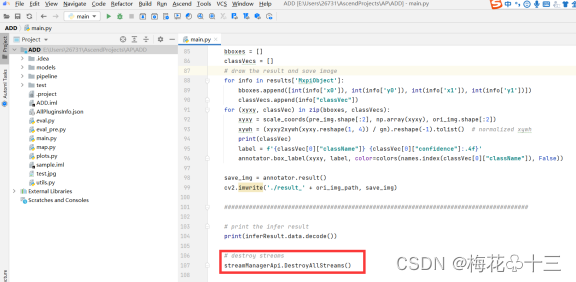
4.4 项目下载连接以及项目结构
完整项目请在此处下载:ascend_community_projects: MindX边缘开发套件社区代码仓库
项目目录结构如下所示:
├── models
│ ├── yolov5
│ │ ├── aldefectdetection.names # 铝材缺陷检测类别
│ │ ├── insert_op.cfg # yolov5 aipp转换配置
│ │ ├── yolov5_add_bs1_fp16.cfg # yolov5后处理配置
│ │ ├── yolov5_add_bs1_fp16.om # 铝材缺陷检测模型
│ │ ├── best.onnx # 用于模型转换
├── pipeline
│ └── AlDefectDetection.pipeline # pipeline文件
├── main.py
├── eval.py
├── eval_pre.py # letterbox预处理
├── plots.py # 绘图工具类
├── utils.py # 工具类
└── test.jpg5. 运行
5.1 配置远程映射
在工具栏"Tools > Deployment> Configuration"在Connection选项中配置远程连接。
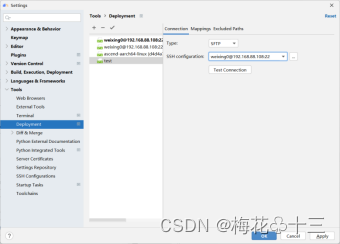
在Mappings选项中配置远程映射,同步远端和本地代码。配置远端路径之后点击OK完成映射。
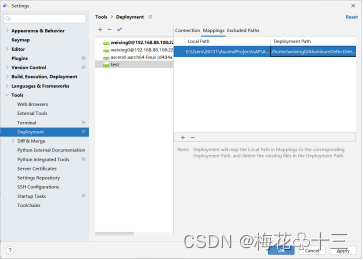
在工具栏点击"Tools > Deployment> Upload to"上传本地代码到远端服务器
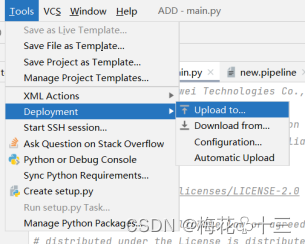
在精度测试下载的数据集中任意选择一张图片放在项目的根目录下,并命名为test.jpg
在main.py文件点击右键,Modify Run Configuration,配置python解释器,选择远端python解释器,配置完成之后点击apply,点击OK。
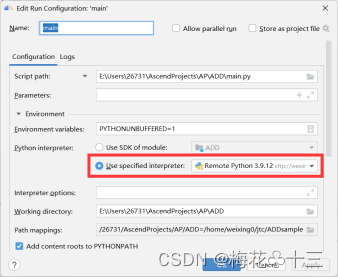
配置完成之后即可右键运行main.py文件得到结果,在程序中,通过输出流里取得的数据,我们可以看到图片的位置和类别信息。通过这些位置信息,我们进一步作出结果图:


5.2 精度测试
准备测试数据https://mindx.sdk.obs.cn-north-4.myhuaweicloud.com/ascend_community_projects/Aluminum_surface_defect_detection/testDatas.zip和om模型文件:https://mindx.sdk.obs.cn-north-4.myhuaweicloud.com/ascend_community_projects/Aluminum_surface_defect_detection/yolov5_add_bs1_fp16.om
运行项目根目录下的eval.py,该文件是在main.py的基础上循环输入测试数据集图片得到结果。
生成的位置信息和类别信息会以txt文件的形式保存在项目目录下的test/testouttxt/。在map.py界面右键,修改运行配置,添加路径参数
配置命令行参数:
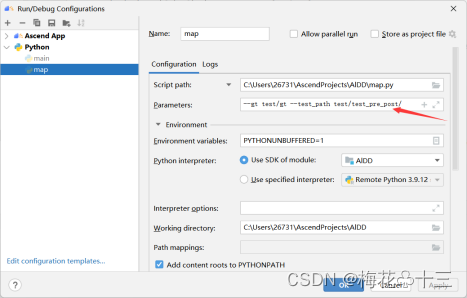
其中--gt为测试集数据的标签路径,--testpath为模型输出结果的路径(即上述test/testpre_post/),包括分类结果、位置信息和置信度参数。
结果如下图所示:
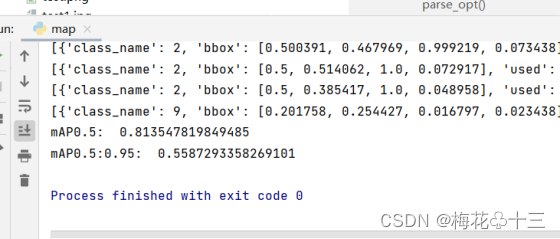
mAP0.5为0.8135478,mAP0.5:0.95为0.5587293358。
其中mAP是目标检测模型中常用的评价指标,它的英文全称是(Mean Average Precision),翻译过来就是平均精确率的平均。mAP0.5是指计算标准为IOU阈值大于0.5,也就是预测框和标签IOU>0.5为正样本。mAP0.5:0.95是指取IOU阈值为以0.05为步长,0.5为起始数据,一直到IOU阈值为0.95的十组数据的平均精度。
6. FAQ
1 尺寸不匹配
问题描述:
提示mxpi_tensorinfer0The input of the model does not match] The datasize of concated inputTensors0 does not match model inputTensors0. Tensor Dtype: TENSORDTYPEUINT8, model Dtype: TENSORDTYPEUINT8.
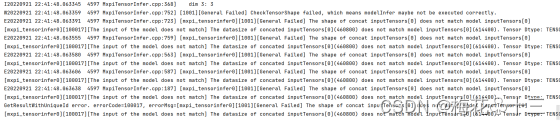
解决方案:
模型经过插件处理后的图像与模型输入不匹配,检查模型经过pipeline之后的尺寸大小是否和模型输入匹配。
2 模型路径未进行正确配置
问题描述:
提示 Failed to get model, the model path is invalidate.

解决方案:
检查模型存放路径,正确配置模型路径。
3 未修改pipeline中后处理插件的postProcessLibPath属性
问题描述:
提示[Object, file or other resource doesn't exist] The postprocessing DLL does not exist
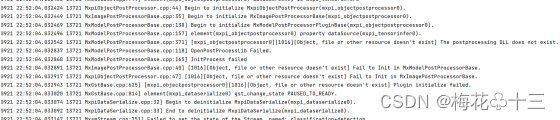
解决方案:
修改pipeline文件中mxpi_objectpostprocessor0插件的postProcessLibPath属性,修改为{SDK安装路径}/lib/modelpostprocessors/libyolov3postprocess.so
4 同步远端CANN开发包失败
问题描述:
提示[PermissionError: [Errno 13] Permission denied: '/usr/local/Ascend/ascend-toolkit/5.0.4/pyACL/scene.info' Command execute fail, exitStatus = 1]
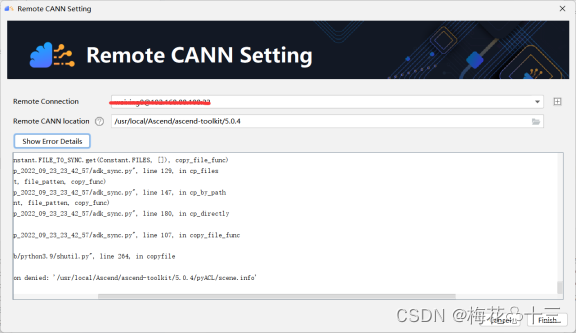
解决方案:
将CANN开发包安装到用户目录下。
7. 一些个人经验总结
在编写pipeline的时候,MindStudio提供的可视化流程编排极大地提高了开发效率,在MindStudio可以通过拖动的方式完成pipeline的编写,参数也可以很方便的在可视化流程编排中配置;
在开发中我们难免会遇到各种各样奇奇怪怪的问题,昇腾论坛是个不错的选择,有问必答,从大四开始已经陆陆续续问了挺多问题,答复速度比较快,开发中受阻,不妨在论坛里请求大佬寻求帮助,链接:华为云论坛云计算论坛开发者论坛_技术论坛-华为云 (huaweicloud.com)。
在做模型转换前,最好用netron确定一下输出节点,找到正确输出节点,才能让om模型正确输出,netron下载链接:lutzroeder/netron: Visualizer for neural network, deep learning, and machine learning models (github.com)
链接:(MindStudio下载-昇腾社区 (hiascend.com)
MindX SDK 2.0.4 mxVision 用户指南:MindX SDK 2.0.4 mxVision 用户指南 01 - 华为 (huawei.com)
CANN安装指南(在用MindStudio可能会由于权限问题,导致远端CANN开发包同步不到本地,可以安装该包到用户目录下) :在昇腾设备上安装 - CANN 5.0.4 软件安装指南 01 - 华为 (huawei.com)
基于MindStudio的MindX SDK应用开发全流程:基于MindStudio的MindX SDK应用开发全流程哔哩哔哩bilibili
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法