Linux 高并发服务器开发_linux高并发服务器开发-程序员宅基地
该文章是通过观看牛客网的视频整理所得,以及在实践过程中遇到的问题及解决方案的整理总结。
Linux 高并发服务器开发
linux 系统编程
linux 环境的搭建
可以在Linux环境下开发 C、C++程序。
俯瞰整个流程:
配置一个 Linux 下 Ubuntu 系统
- 下载一个虚拟机软件 VMware,非免费的,需要破解,B站有教程。(网盘已经保存了软件及密钥)
- 下载 Ubuntu 镜像文件
- 在虚拟机上创建虚拟机,安装 Ubuntu 系统,安装 vmware tools 工具实现 Linux系统的屏幕适配、文件拖拽等。
至此 Linux下 Ubuntu系统安装成功。
在 Windows 下通过 xshell 和 xftp 或者 VS code 远程连接控制 Ubuntu 来实现 web server。
我们实际操作的环境并非 Linux环境,而是在 Windows下远程连接到 Linux 来操作的。
- 下载 xshell, xftp,一个是命令控制终端,一个是文件传输工具。
都需要连接后才可以远程控制传输。连接需要 Ubuntu 系统的用户名+密码即可。
文件传输 可以通过 ftp,也可以通过 VMware tools 实现的直接文件拖拽的方式。- vscode 可以作为 Windows 环境下的编辑工具,来实现远程代码的编辑来代替 Linux 下的 vim 编辑。
当然了,需要安装一系列的插件来实现,具体看下边。
重点:一个是远程连接的插件;一个是每次远程连接都需要输入被链接端的密码的解决方法;- 所以我们还需要了解一些常用的 Linux 命令,来通过 xsheel/VS code下的终端来键入 Linux命令实现一些功能。
环境搭建需要的软件
- VMware 虚拟机,用来安装一个Linux Ubuntu 系统。需要破解,在b站有教程,已经将软件及破解密钥保存在百度网盘。
下边的都免费: - Ubuntu iOS 镜像文件
- Xshell,xfpt 用来远程连接控制 Linux 系统
- vs code,windows 端编辑器
虚拟机中安装 ubuntu 并使用
-
创建新的虚拟机
-
安装 vm tool,可以使安装好的系统界面适配电脑屏幕,可以直接通过拖动的方式交换 windows 和 Linux 的文件。 安装方式:在VMware界面 > 虚拟机 > 安装vmtool
桌面的 vmware tools 提取出来后打开,里边的 vmwarere-install.pl 才是我们的安装文件。右键打开终端,输入sudo ./vmware-install.pl即可 -
因为我们不直接在Linux界面操作,而是通过xshell 来远程登陆操作,所以先 通过Linux终端 命令行安装 ssh服务器
sudo apt install openssh-server -
当安装好 ssh 协议后,我们就可以通过 xshell 软件通过 ssh协议登陆到 Linux 系统。
xshell 连接到 Linux
- 打开软件,新建会话。需要在主机的位置填写虚拟主机的 ip地址(查看方式:终端键入
ifconfig指令,ifconfig也是一个软件,需要事先安装才能使用,安装方式:sudo apt install net-tools),最后输入虚拟机的用户名+密码即可
VS code 插件
官网下载好 code 后,使用命令
sudo dpkg -i code_1.66.2-1649664567_amd64.deb安装 code
-
chinese:将编辑器语言装换成中文的一个插件
-
remote development:可以远程连接到服务器的插件
配置(config):默认是放在 windows下的 (C:\Users\yule\.ssh\config)。 配置的内容是关于 Linux系统的。
host 随便起
hostname 远程要控制连接的主机的 IP 地址,当 Linux 或者说远程连接服务器 ip发生变化,就需要重新配置。 已经配置好的 VS code 远程连接每次需要输入密码,解决方法 不需要重新配置。
user 用户名,远程主机的用户名 -
C/C++: 开发的时候会有一些相关提示
-
tabout 制表符 tab键 跳出引号、括号等
VS code 远程连接每次需要输入密码,解决方法
Windows 端 命令行窗口下 ssh-keygen -t rsa 在本机生成一个公密钥,生成的 公密钥保存在Windows下用户名下的.ssh文件夹中,id_rsa密钥,id_rsa.pub公钥。
把Windows本机的公钥发送给虚拟机即可:
- 方法一: 在Windows命令行下键入
ssh-copy-id,前提是有ssh客户端。 - 方法二:通过xshell 在虚拟机中生成一个同样的文件,xshell 连接好后键入
ssh-keygen -t rsa, 生成后cd .ssh/,ll即可查看生成的公钥私钥。
在当前.ssh目录下创建一个文件vim authorized_keys, 然后打开本机上的公钥,复制到 vim 创建的文件夹中。完成。之后在通过vs远程连接到Linux就不需要每次输入密码了。
总结
在本机上通过ssh-keygen -t rsa生成一个公钥私钥;在虚拟机上同样的方式生成一个公钥私钥,并且在虚拟机的.ssh文件下创建一个文件夹vim authorized_keys;最后将本机的公钥拷贝到该文件中即可。
GCC编译工具
对源程序进行编译生成可执行文件。
在 Linux Ubuntu系统下安装GCC
sudo apt install gcc g++ 安装命令。apt,Ubuntu下的包管理器。(版本>4.8.5的支持 C++11特性)
gcc/g++ -v/-version 查看gcc版本
安装好GCC 后就可以远程通过 gcc 命令来实现。而gcc命令只要是远程控制了虚拟机的终端都可以使用,可以通过 xshell,也可以通过VS code中的终端使用 gcc 命令。
gcc工作流程
gcc 和g++的区别
对于 .c 文件,用 gcc 命令就认为 .c 文件是C程序;用g++命令就认为 .cpp是C++程序。
而 .cpp 文件,两者都会认为其是一个 c++程序。编译可以用 gcc/g++, 链接可以用个 g++/gcc -lstdc++。因为对于C++程序而言,gcc 命令不能完成和C++程序使用的库链接,所以链接那步通常使用 g++。
 预处理
预处理
头文件的展开,注释的删除,宏的替换等
链接
静态库/动态库的区别 体现在 制作过程不同,使用方法不同(也就是说链接阶段对两个库的处理方式不同)。
静态库 是在链接阶段直接将静态库文件和源程序打包成一个整体,在程序运行时可以直接运行,因为程序中用到的库文件相关内容已经拷贝到程序中了,就可以直接加载运行了。
而 动态库 在链接时并不会把库中的代码打包到可执行文件中,只是写一些信息链接过去(比如动态库的名称等),当程序运行过程中有调用到动态库中的 api 时,再根据配置好的库的位置信息找到库文件,动态加载器将其加载到内存中供程序使用。
所以说动态库多了环境配置的步骤,要将库的绝对位置配置到环境中,让动态加载器每次在需要的时候可以成功定位到该库,从而可以正常加载到内存中。
优缺点
静态库
加载速度快;程序移植方便。因为静态库已经被打包到应用程序中了。
也正因为如此,所以如果有几个程序用到同一个静态库,则在运行时会占用多份的内存空间,消耗系统资源。且每次静态库有改动,就需要重新编译一下程序,进行新的链接,所以程序的更新部署发布麻烦。
动态库 可以实现进程间的资源共享,即当一个程序用到的了一个动态库,此动态库已经被加载到内存了,那么当另一个程序也调用到该动态库时,就不需要在内存中重新加载,而是直接用内存的资源就可以了。
更新/部署/发布简单,因为程序中包含的并不是整个库文件,只是库文件的名字等简单信息,更新库后下次调用只要库的绝对路径不变就不会有影响。
并且是实时内存加载,节省内存空间。
但 加载速度慢点,且发布时需要提供依赖的动态库,因为链接动态库的程序中并没有整个库文件数据,而是需要动态的加载。
链接阶段 静态库和动态库
库:可以理解为一个代码仓库,提供给使用者直接拿来用的。内部存储的是二进制代码,并且不能单独使用,在链接阶段和使用了库文件的目标文件链接用的。
- 静态库:在链接阶段被用到的代码会被复制到 源程序生成的目标代码中 打包成一个整体,生成可执行文件。那么当可执行程序运行时,静态库的代码也会随之加载到内存中去,直接调用即可。
- 动态库:而动态库在链接阶段不会被复制到目标文件中,而是程序在运行时由系统动态的加载到内存中供程序调用。也就是说即使在运行过程中,也不是将动态库中被用到的代码实时复制到程序中,而是动态加载到内存中供程序调用。
动态库是在程序运行后,当程序调用到库文件中的 api 时再实时动态的将库加载到内存中,通过ldd(list dynamic dependencies) 命令可以检查动态库依赖关系。这个过程时通过动态加载器来完成的,通过库的绝对路径找到库文件后将其载入内存。对于linux 下的的可执行程序(elf格式),加载器时 ld-linux.so,它先后搜索 elf 文件的 DT_RPATH段(改变不了,所以我们的动态库的地址不能加在这里),环境变量LD_LIBRARY_PATH(终端临时环境变量配置),/etc/ld.so.cache文件列表,/lib/或/usr/lib/目录 来找到库文件后将其载入到内存。
库的好处
- 代码保密。即使被反编译,还原度也很低。
- 方便部署和分发。如果想给另一个人发送好多个 源文件,可以将其源文件生成的目标文件统一打包,制作成一个 库,方便分发。分发的时候不仅要把库给别人,还要把库所依赖的头文件一并分发。
静态库的制作和使用
-
命名规则
Linux:libxxx.a | Windows:libxxx.lib- lib:前缀(固定的)
- xxx:库的名字,自己定
- .a/.lib:后缀(不同的平台不同,是固定的)
-
制作
- gcc 编译获得 .o 的二进制目标文件
gcc -c xxx.c xxx.c xxx.c对若干源文件进行编译,得到 .o 二进制文件 - 将 .o 文件打包,使用的是 Linux 中的 ar (archive) 工具
ar rcs libxxx.a xxx.o xxx.o将 libxxx.a 后边跟着的 .o 文件(打包备份 建立索引)创建成库文件
r - 将准备打包的目标文件插入到备存文件中
c - 建立备存文件,也就是我们最后生成的库文件中的内容,可以这么理解
s - 建立备存文件的索引
- gcc 编译获得 .o 的二进制目标文件
-
使用
要同时将 头文件和库文件 一块发给别人使用,头文件中是声明,库文件中是定义。gcc xxx.c -o exe_name -I include_头文件的位置 -L 用到的函数对应库的位置 -l 具体库的名字(libxxx.a 中的 xxx)即可编译成功,生成一个可执行文件 exe_name,该程序在链接阶段就用到了静态库的链接,是在程序的链接阶段就将静态库给复制到源程序生成的目标文件中了。
动态库的制作和使用
-
命名规则
linux: libxxx.so | windows: libxxx.dll- lib:固定前缀
- xxx: 库的名字,自己起
- .so/.dll,固定后缀,.so是Linux下的动态库后缀,.dll是Windows下的动态库后缀。
-
制作
- gcc 编译得到 .o 文件,并且是得到 和位置无关的代码
gcc -c -fpic xxx.c xxx.c xxx.c - gcc 得到动态库
gcc -shared xxx.o xxx.o -o libxxx.so
- gcc 编译得到 .o 文件,并且是得到 和位置无关的代码
-
使用
使用之前需要 将动态库的绝对路劲进行环境配置,使得动态加载器可以定位加载到该动态库。可以用命令ldd exename来查看可执行程序的动态库依赖关系。环境变量配置
1.配置环境:LD_LIBRARY_PATH-
临时变量配置:
配置在当前终端,重启终端后环境变量失效。
直接在当前终端export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:要添加的环境变量,即动态库的绝对路径 -
永久变量配置:
- 用户级别:
配置位置:cd 到 根目录home > .bashrc 下进行编辑~/.bashrc
vim .bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:要添加的环境变量,即动态库的绝对路径
. ./.bashrc配置保存后,通过该命令使其生效。.等同于source。source ./.bashrc - 系统级别:
任意位置下都可以编辑,需要管理员权限
sudo vim /etc/profile
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:要添加的环境变量,即动态库的绝对路径
source /etc/profile
- 用户级别:
2.文件:
/etc/ld.so.cache配置
/etc/ld.so.cache该文件是一个二进制文件,不能直接修改。需要间接修改,通过/etc/ld.so.conf来配置。
sudo vim /etc/ld.so.conf,进入到文件中,然后将 环境变量值(动态库的绝对路径)添加到里边保存即可。
sudo ldconfig更新环境配置3.
/lib或者/usr/lib文件配置(不推荐)
将我们的动态库添加到这两个文件夹中去。因为两个文件中本来就有大量的系统文件,以防我们的动态库文件名和系统文件名重复 出现问题,所以不推荐这种方式。 -
gcc命令(参考gcc工作流程和常用参数)
gcc -E test.c -o app 生成只经过预处理的 app文件
gcc -S test.c -o app 生成经过编译后生成的汇编文件
gcc -c test.c -o app 生成经过汇编的目标文件,即二进制文件
gcc test.c -o app test.c:编译的文件; -o: 指定要生成的文件的名字;app:生成的目标文件名。
对于生成的目标文件(可执行程序,Linux下都是绿色的)可以直接 ./app 打开。
gcc main.c -o app -I 库文件所在目录 main.c 在编译链接时,可以成功找到包含的不在同一级目录下的头文件
gcc main.c -o app -I 源文件包含的头文件所在目录 -L 头文件中声明的和其他库文件所在的位置 -l 调用库名 main.c 在编译链接时,可以成功找到包含的不在同一级目录下的头文件
gcc 常用参数

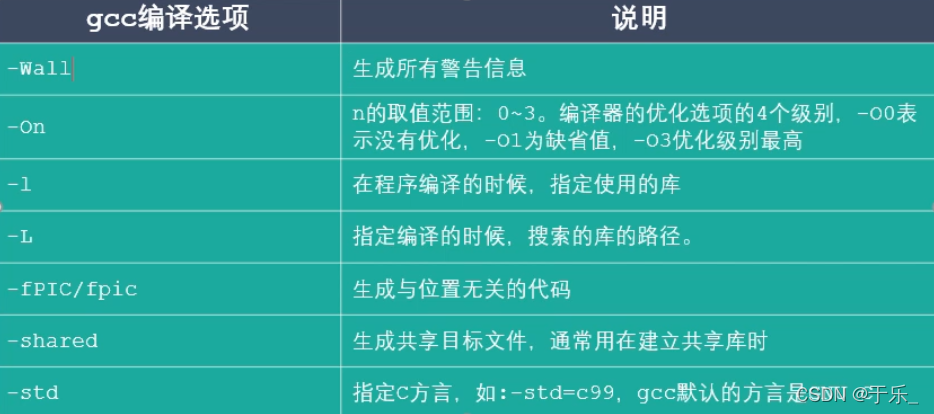
Makefile 文件
Makefile 是一个文件,其中定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译等。好处是“自动化编译”,而不是对每个源文件都需要 gcc 指令。
make 是一个解释 makefile 文件中指令的命令工具。通过 make 命令,整个工程就可以完全自动编译,提高开发效率。
makefile规则
一个 makefile 文件中可以有一个或者多个规则,其他规则都是为第一条规则服务的。其他规则也只有为第一条规则服务的时候才会被执行。
目标:依赖
命令(一般时 shell 命令)
//目标:最终要生成的文件,比如说可执行文件
//依赖:生成目标所需要的文件或者目标,比如若干源文件和库文件
//命令:通过执行命令 对依赖操作 生成目标
# 1. makefile 工作原理:
# makefile 中可以写多条规则,第一条是必执行的,之后的规则如果和第一条规则相关,是生成第一条规则的依赖的话,也会执行。
# 并且在第二次运行makefile文件时,会通过比较 目标和依赖的时间 来决定是否执行对应命令。如果目标晚于依赖,不执行更新;反之更新。
# 更新时,对于没有依赖的目标,是去当前目录下是否已经存在该目标,存在则不在更新。不存在则继续更新。 对伪规则不适用
# 2. 内容的书写 有何高效写法:
# 在内容的书写上可以通过 定义变量和使用函数来高效的完成第一条规则的书写,使用模式匹配来完成之后的规则书写。
一个 Makefile 文件的实例
# 定义变量+使用函数
src=$(wildcard ./*.c) # 获取当前目录下 符合后缀是 .c 的文件列表
objs=$(patsubst %.c, %.o, $(src)) # 将src 中的单词和 %.c 进行模式匹配,匹配成功的就替换成 %.o
target=app
$(target):$(objs)
$(CC) $(objs) -o $(target)
# 第一条规则中的 objs 都不存在,则会继续往下执行,下边的规则用来通过某个依赖生成需要的目标
%.o:%.c # 模式匹配 目标和依赖,下边指令 将对应的依赖编译成目标文件
$(CC) -c $< -o $@
.PHONY:clean
clean:
rm ./*.o -f
make命令
make 解释当前目录下的 Makefile 文件中的规则命令
make 指定目标 只执行指定目标所在规则的指令
GDB 调试工具
和 GCC 编译工具 组成了一套完整的开发环境。
准备工作,编译时加 调试参数 得到可调试的程序
- 可选:通过 gcc常用参数 关掉编译器的优化选项
-O0’ - 必选:打开调试选项
-g; 在不影响程序行为的情况下打开所有 warning-Wall
例子:gcc program.c -o program -g -Wall
-g 选项的作用并不是把整个源代码给嵌入到可执行文件中,而是将源代码位置信息加入到可执行文件中,使得在调试时 gdb 能够找到源文件,通过发现bug 的机器指令的位置对应到 源程序相应的位置。
GDB 命令
启动,退出,查看代码

断点操作

断点调试命令

gdb 多进程调试
因为使用 gdb 进行调试的时候,gdb 默认只能跟踪一个进程。所以对于多进程调试,需要用过一些指令来设置跟踪的是哪个进程。
又因为任何一个进程(除init进程)都是由另一个进程创建出来的,比如说 A 进程创建了 B进程,则 A进程称为父进程,B称为子进程。对于这种调用 fork 函数而出现的父子进程 在调试的时候 gdb 默认跟踪父进程;并且子进程自动脱离父进程,父进程的调试和子进程无关,子进程如果是就绪状态的话,会在到了自己的时间片时就去执行。
我们可以通过指令来设置 gdb 调试跟踪的进程以及 fork创建的函数是否脱离父进程:
show follow-fork-mode 查看gdb跟踪的是父进程还是子进程
set follow-fork-mode parent|child 设置 gdb 调试跟踪的进程
show detach-on-fork 查看 调试模式,默认为 on, 表示调试当前进程时,其他进程继续运行
set detach-on-fork on|off 可以设置为 off,表示调试当前进程时,其他进程被 gdb 挂起
info inferiors 查看调试的进程有哪些
inferior id 切换当前调试的进程
detach inferiors id 使 进程id 脱离gdb调试
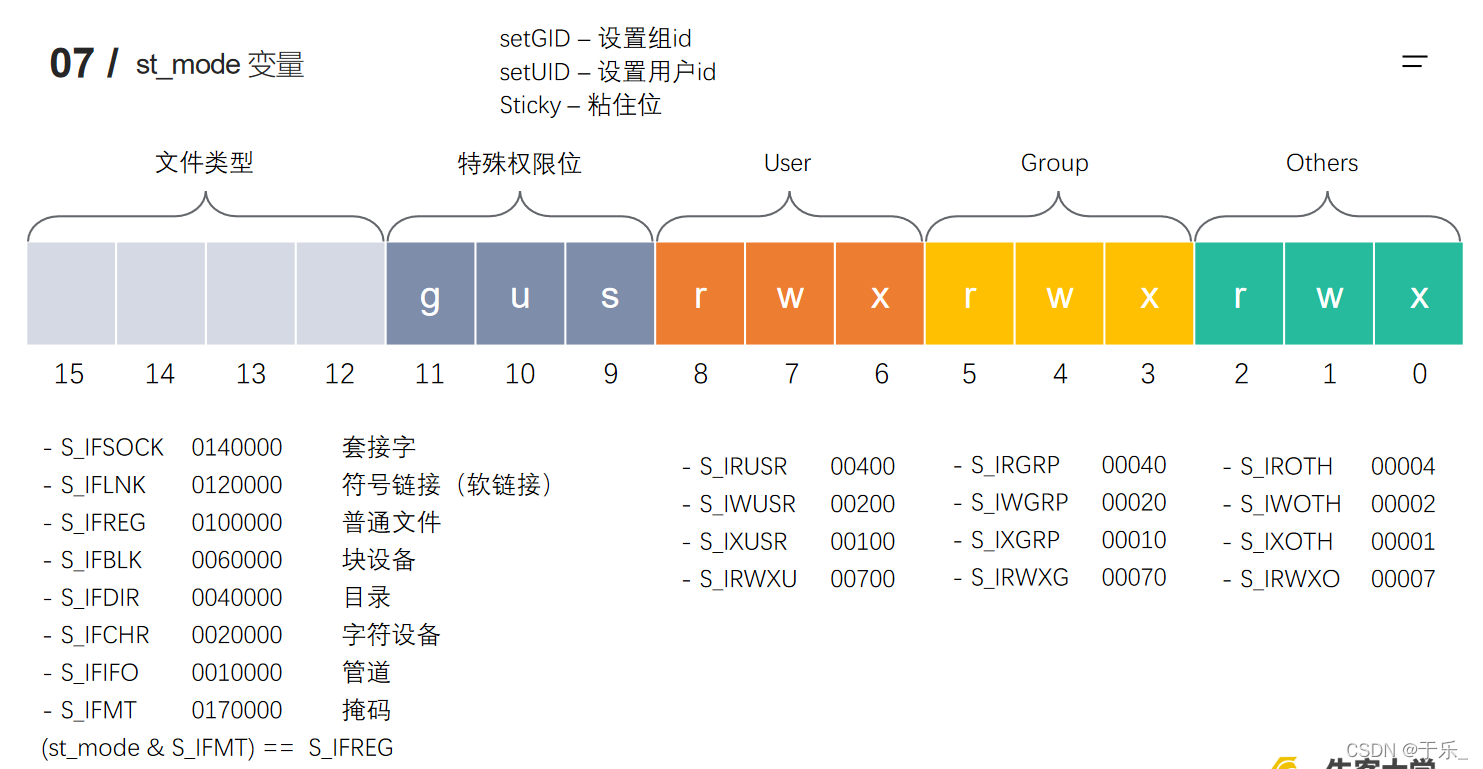
文件IO - 站在内存的角度考虑文件IO
Linux 中有 7 中文件类型,FIFO管道类型算一种。
每种类型都可以跟普通文件一样 open(), read(), write(), close()。
程序 和 进程
程序的源程序以及可执行文件,都是文件,是存储在磁盘上的,占用磁盘空间,不占用内存空间。那当可执行程序想要运行的话,系统就会为其创建一个进程,为该程序分配一些资源,占用内存空间。
一个程序启动以后,会有一个虚拟地址空间(内存),虚拟地址空间会通过 cpu 中的 内存管理单元(MMU)将数据映射到物理内存中区。
linux系统 IO函数
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
int close(int fd);
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
off_t lseek(int fd, off_t offset, int whence);
//移动文件指针位置,根据第二个和第三个参数将指针移动到文件头,获取当前指针位置,移动到文件尾,扩展文件大小等。
int stat(const char *pathname, struct stat *statbuf);
int lstat(const char *pathname, struct stat *statbuf);
//stat用来获取普通的文件信息,lstat用来获取软链接文件的信息,像ll 打印出来的那些信息,可以通过 stat,lstat函数获取到。得到的文件信息 保存在 statbuf 指向的 buf中,可以通过指针 statbuf 得到。
文件属性操作函数
int access(const char *pathname, int mode);
// 判断文件是否存在以及文件的权限。mode:F_OK,R_OK,W_OK,X_OK
int chmod(const char *filename, int mode);
// 修改文件权限
int chown(consdpt char *path, uid_t owner, gid_t group);
// 修改文件的所有者,所在组.
// 查看用户的id,组别id:`vim /etc/passwd` `vim /etc/group`
int truncate(const char *path, off_t length);
// 缩减/扩展文件大小到指定的大小
int dup(int oldfd);
// 复制文件描述符。复制得到的文件描述符返回值和 oldfd值不同,却指向同一个文件。
int dup2(int oldfd, int newfd);
// 重定向文件描述符。将 newfd 指向的文件 close(如果有的话),并且重定向指向 oldfd 指向的文件。同样是 oldfd,newfd 维护同一个文件。
// 该返回值和 newfd 相同。
int fcntl(int fd, int cmd, ...);
// 根据 cmd 的不同,可以做好多事。可以通过手册看 cmd都有哪些。
// F_GETFL, F_SETFL
目录操作、遍历函数
int mkdir(const char *pathname, mode_t mode);
// 创建一个目录,并且指定权限
int rmdir(const char *pathname);
// 移除空目录
int rename(const char *oldpath, const char *newpath);
char *getcwd(char *buf, size_t size);
// 获取当前工作目录。buf 是存储路径,指向一个数组
int chdir(const char *path);
// 修改进程的工作目录。
// 参数是需要修改的工作目录;返回值是一个指针,指向一块内存,也就是第一个参数
// 目录遍历操作组合:打开目录>读取目录>关闭目录
DIR *opendir(const char *name);
// 打开一个目录,针对该目录中的文件会返回一个 目录流,流中是当前目录下的各个文件
struct dirent *readdir(DIR *dirp);
// 将 目录流对象作为参数进行 read,会遍历目录流中的文件,并且遍历每个文件会有一个 结构体返回值,结构体中含有该文件的一些信息,如文件名、文件类型等。
int closedir(DIR *dirp);
Linux 多进程开发
从进程入手,了解什么是进程,进程的状态、状态间的转移,进程的创建、退出和回收,因为进程创建而出现的孤儿、僵尸进程怎么处理(通过进程回收 wait/waitpid 来解决等。)
然后是多进程,多进程之间是如何通讯的。针对同一台主机上的进程和不同主机上的进程有不同的通信方式:不同主机的通信是网络编程涉及到的东西(socket通信);同一主机的通信方式有很多种:管道通信(匿名、有名)、信号、信号量、共享内存、内存映射、消息队列。
程序和进程
程序
是包含一系列信息的文件,存储在磁盘中,不占用内存和CPU资源;它描述如何在程序运行时创建一个进程。(程序中的文件包括:二进制格式标识文件的元信息,机器语言指令,程序入口地址,数据,共享库和动态链接信息,等。)
进程
是正在运行的程序的实例,会占用内存空间和CPU资源等各项系统资源来执行程序。每个进程对应一个虚拟地址空间,进程是一个抽象出来的实体,可以理解为由用户内存区和内核区组成,用户区包含程序代码和变量常量等数据信息,内核区则用于维护进程状态信息(如进程标识号、当前工作目录、打开的文件描述符、进程资源使用及限制等)。
进程的虚拟地址空间如下:
 不是真实存在的,都会被映射到真实的物理内存
不是真实存在的,都会被映射到真实的物理内存
时间片
是操作系统为正在运行的进程分配的 CPU执行时间,因为一个 CPU 在同一时刻只能处理一个进程,宏观上看我们的程序好像是在同时运行,就是因为 进程其实是在 轮流被CPU处理,cpu 不停的在多个进程之间来回切换。
PCB 进程控制块
为了管理进程,内核为每个进程分配一个 pcb 来维护进程相关信息。
pcb 是一个 task_struct 结构体(在Linux中),常用成员有:
- 进程id:每个进程有唯一的 id
- 进程状态:就绪、运行、挂起、停止等
- 进程切换时需要保存和恢复的信息
- 描述虚拟地址空间的信息
- 描述控制终端的信息:每个进程运行会绑定好自己的终端
- 当前工作目录
- umask 掩码
- 文件描述符表:包含指向 FILE 结构体的指针
- 和信号相关的信息
- 用户 id,组 id
- 会话和 进程组
- 进程可以拥有的资源上限:
ulimit -a显示当前进程的资源上限
进程 父子进程 进程组 父子进程号 进程组号
每个进程有唯一的进程号来标识,进程号 pid,父进程号 ppid;
除 init 进程外的 任何进程都是由另一个进程创建的,任何进程为子进程,另一个进程为父进程;
进程组是一个或多个进程的集合,进程组号 pgid。
//通过 进程号 获取 进程组 的函数
pid_t getpid(void);
pid_t getppid(void);
pid_t getpgid(pid_t pid);
进程的状态
进程的状态 可以反映进程执行过程的变化。这种状态随着进程的执行和外界条件的变化为转换,比如说运行态的进程在时间片用完后进入到就绪态或者终止态,阻塞态的进程在其他进程所占用资源释放后 具备了除CPU以外的所有必须资源 就会进入到就绪队列等待运行。
三态模型
- 运行态:进程占有处理器正在运行
- 就绪态:进程具备了除 CPU 所有以外的所有必要资源, 只要在获得处理器,就可以立即执行的状态。
而在一个系统中处于就绪态的进程可能有多个,通常将他们排成一个对列,成为就绪队列 - 阻塞态:指进程不具备除CPU以外的运行条件,正在等待某个事件的完成。有 等待态(wait) 和 睡眠态(sleep),等待态等待如 io请求。
五态模式
- 新建态:进程刚被创建时的状态,尚未进入就绪队列
- 终止态:进程正常执行完毕到达结束点、或出现错误而异常终止、或被操作系统及有终止权的进程所终止时所处的状态。
进入终止态的进程不在执行,但依然保留在操作系统中等待善后,一旦其他进程完成了对终止态进程的内核信息的释放之后,该进程被彻底删除。
创建进程
我们在 Linux 系统编程、多进程开发的过程中其实是在不断的熟悉使用
linux programmer's manual中的函数的过程。可以通过man 2/3 函数名来查看函数的手册。
创建进程用到的函数 - fork - create a child process
man 2 fork
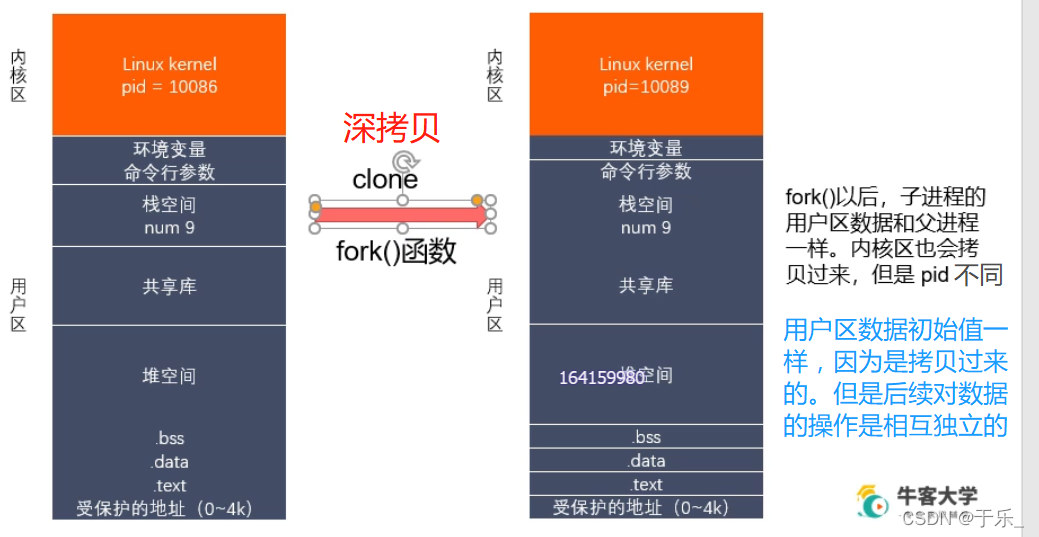
fork() 时两个内存空间的内容时一样的,但是之后对数据的操作相互独立,互不干扰。
系统允许一个进程创建新进程,新进程即为子进程,子进程还可以创建新的子进程,形成进程树状结构。
fork() 函数
实现新进程的创建用调用的函数为 fork() 函数。
fork() 函数用到了 读时共享、写时拷贝(copy-on-write)的机制。也就是说父子进程刚开始时共享同一个地址空间的,子进程以只读的方式共享父进程资源;只有在进程需要写入数据时才会复制该数据的地址空间到进程(父进程写就拷贝一份该数据的地址空间,子进程写就拷贝一份数据的地址空间),从而使各个进程拥有各自的地址空间。
exec 函数族
exec 函数族的作用和 fork() 函数不一样,fork 会创建一个子进程,也就是说当前进程 调用fork 后,会创建处一个新进程;
而一个进程如果执行过程中调用了 exec函数族的话,并不会新创建一个进程,而是由 exec函数族指定的程序来 取代当前程序继续执行,前后是执行的是两个不同的程序内容,但是用一个进程号。也就是说内核区不变,而用户区会做变化,由新的用户区取代原来的用户区继续执行。
常用的 exec函数族
int execl(const char * path, const char * arg, ...)指定要继续执行的程序的路径,后续参数 第一个为程序名、最后一个为null、中间是该程序运行时需要的参数
(execl("/home/yule/exe", "exe", null))int execlp(const char * file, const char * arg, ...)直接指定程序名即可,他会去环境变量中找对应的可执行文件,比如说 ps;后续和第一个一样
(execlp("ps", "ps", "aux", null)则 ps aux 的进程取代该进程继续执行)
进程退出(解决孤儿进程)
通过调用 函数来退出当前进程。
Linux中的 _exit(int status)
该函数会立即终止调用该函数的进程;
并且会将该进程打开的文件描述符关闭;
该进程的子进程会被 init进程所继承(孤儿进程的处理)。并且会返回给父进程一个进程退出状态(进程退出状态由 参数status&0377 计算得来)。无返回值。
C标准库中的 exit()
该函数会导致正常的进程终止,并且会调用 _exit 返回给父进程一个退出状态。无返回值。
缓冲区中的流数据会被刷新并关闭;临时创建的文件会被移除。
在每个进程退出的时候,内核会释放掉该进程的所有资源,包括打开的文件、占用的内存空间等。
但是还有一些内核区信息 进程控制块pcb的信息(包括进程号、退出状态等)仍然没有被释放,需要由其父进程进行回收释放。
进程回收(解决僵尸进程)
子进程退出后需要父进程来回收资源。可以通过 wait() waitpid() 以及 发送信号给父进程,父进程进行信号捕捉来 回收子进程资源。
进程退出时会返回给父进程一个进程退出状态,父进程可以通过得到的子进程退出状态进行进程回收。
父进程可以通过调用 wait / waitpid 得到进程的退出状态同时彻底清除该进程。对于父进程循环执行,而此时子进程已经执行完毕,退出进程但还没有被完全回收 的僵尸进程,通过调用 wait 函数可以接收到子进程的退出状态,从而对进程的剩余资源做回收操作。
一次 wait / waitpid 调用只能清理一个子进程,清理多个子进程需要循环。
wait 函数
调用wait函数的进程会被挂起(阻塞),直到它的一个子进程退出或者收到一个不能被忽略的信号时才被唤醒(相当于继续往下执行)
如果没有子进程了,函数立刻返回,返回-1;如果子进程都已经结束了,也会立即返回,返回-1.
while(1) {
int st; // 进程退出状态
int ret = wait(&st);
if(ret == -1) {
break;
}
if(WIFEXITED(st)) {
// 是不是正常退出
printf("退出的状态码:%d\n", WEXITSTATUS(st));
}
if(WIFSIGNALED(st)) {
// 是不是异常终止
printf("被哪个信号干掉了:%d\n", WTERMSIG(st));
}
}
waitpid 函数
wait 和 waitpid 函数的功能一样,区别是 wait 的调用是阻塞的,而 waitpid可以设置不阻塞。
while(1) {
int st;
// int ret = waitpid(-1, &st, 0);
int ret = waitpid(pid, &st, options); /*参数:
- pid:
pid > 0 : 某个子进程的pid
pid = 0 : 回收当前进程组的所有子进程
pid = -1 : 回收所有的子进程,相当于 wait() (最常用)
pid < -1 : 某个进程组的组id的绝对值,回收指定进程组中的子进程
- options:设置阻塞或者非阻塞
0 : 阻塞
WNOHANG : 非阻塞
- 返回值:
> 0 : 返回子进程的id
= 0 : options=WNOHANG, 表示还有子进程或者
= -1 :错误,或者没有子进程了*/
if(ret == -1) {
break;
} else if(ret == 0) {
// 说明还有子进程存在
continue;
} else if(ret > 0) {
if(WIFEXITED(st)) {
// 是不是正常退出
printf("退出的状态码:%d\n", WEXITSTATUS(st));
}
if(WIFSIGNALED(st)) {
// 是不是异常终止
printf("被哪个信号干掉了:%d\n", WTERMSIG(st));
}
}
}
多进程通信
进程是一个独立的资源分配单元,不同进程之间的资源是相互独立的,不能在一个进程中直接访问另一个进程的资源。
但是进程不是孤立的,进程之间需要进行信息的交互和状态的传递等,因此需要 进程间通信(IPC - inter process communication)。
进程间通信的目的:
- 数据传输:一个进程需要将其数据发送给另一个进程;
- 资源共享:多个进程之间共享同样的数据。这块会涉及到内核提供的互斥和同步机制。
- 通知事件:一个进程需要向另一个进程发送消息,通知另一个进程发生了某种事件(如子进程终止时需要通知父进程)。
- 进程控制:一个进程希望完全控制另一个进程的执行(如 debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
进程间通信的方式有很多种:
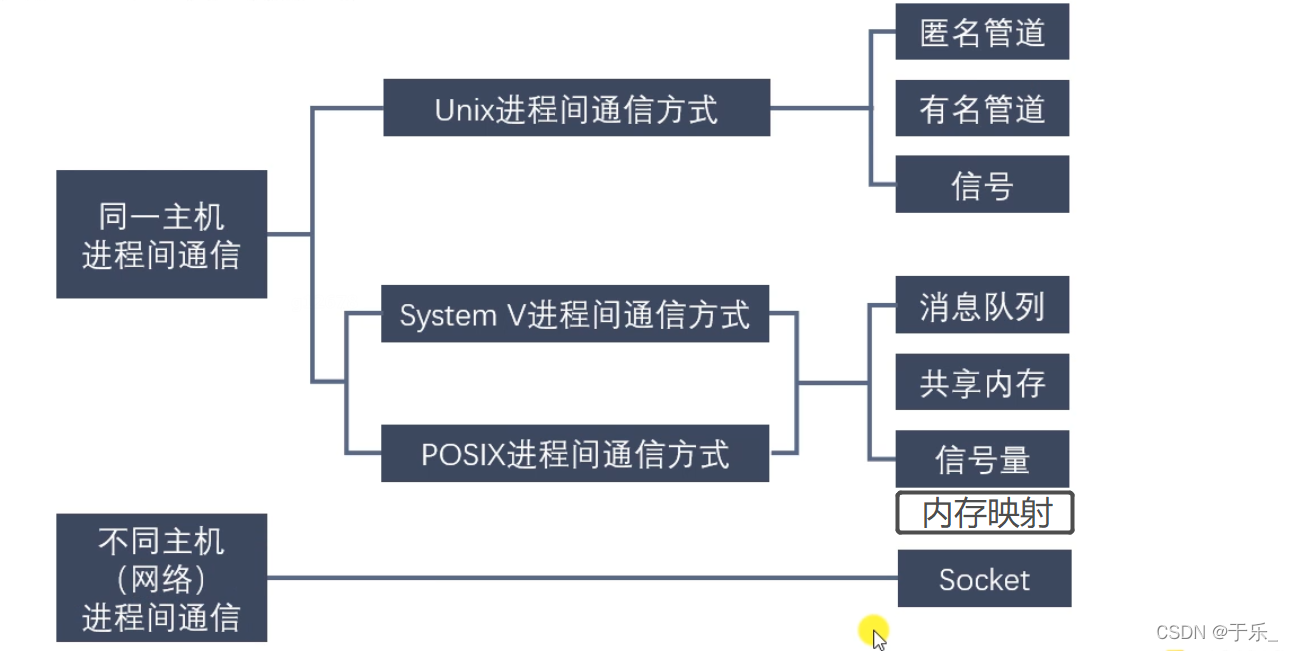
匿名管道 pipe
匿名管道只能用在具有公共祖先的进程间使用。
匿名管道可以理解为 两个进程都可以操作的一个中间文件,它有缓冲区,来存储一个进程写的数据,供另一个进程读取,从而实现两个进程间的通信。
两个进程想要通过 匿名管道 进行通信,就需要先创建一个管道(通过 pipe 函数创建),创建好管道后会有两个管道口生成,pipefd[0] 用来读取管道中的数据,pipefd[1]用来向管道中写数据。这样两个进程就可以通过对管道的读写数据实现进程间的通信了。
pipe create a pipe
ulimit -a 查看管道的缓冲区大小
fpathconf 函数,可以通过该函数来实现查看管道的缓冲区大小
管道通信存在的问题
使用管道通信时如果在父子进程中 同时有读写数据 的操作,则有可能会出现自己写的数据自己读取的情况。比如说 父进程中同时有往管道中读写数据的实现,刚往管道中写完数据后时间片还没用完,就会继续往下执行,然后就会把自己写进去的数据读取出来。
所以对于管道通信,都只进行单方向的通信,如果父进程时读取管道,则会关闭写操作,以免发生错误。
close pipefd[0] 关闭读端
close pipefd[1] 关闭写端
管道的特点
管道拥有文件的特质,可以进行对齐进行读写操作,它是在内核内存中维护的缓冲器,在不同的操作系统中有固定的大小。
一个管道是一个字节流,使用管道时不存在消息或者消息边界的概念,从管道读取数据的进程可以读取任意大小的数据块,而不管写入进程写入管道的数据块大小是多少。
管道可以看作是一个循环数组,传递的数据是顺序的,传递方向是单向的,一端用于写入,一端用于读取,管道是半双工的。
默认是 阻塞的。
管道的读写特点
四种情况:
- 指向读端的文件描述符为0:也就是说没得读,所以不能在往管道写数据,向管道中写数据的进程会收到一个 SIGPIPE信号,通常会导致进程异常终止。
- 指向读端的文件描述符大于0:读端有的读并且有在读,则管道中的数据会被不断清空,所以可以不断往里写数据 直到管道写满,阻塞;如果虽然读端可以读但没有读,则进程会在写满后阻塞;直到有空位置才能写。
- 指向写端的文件描述符为0:也就是没有新的数据写入,管道中的数据被读完后 再读则返回0。
- 指向写端的文件描述符大于0:有新的数据写入,所以读完数据后会进入阻塞状态,等待写端写入数据。
匿名管道实现 ps aux | grep root
子进程实现 ps aux, 将左右的进程输出
父进程将子进程中的信息进行处理,最后只输出 root 相关的进程信息
此时就会涉及到父子进程通信的知识,因为需要先子进程实现 ps aux,然后将 得到的数据写到管道中,父进程再读取管道中的数据进而处理并显示。
创建管道 pipe
创建父子进程 fork
用另一个进程取代子进程 execlp 来实现 ps aux 的操作,而 exec族默认输出到终端,我们需要其输出到 管道中,所以需要重定向输出 dup2
有名管道 FIFO
Linux 中有 7 中文件类型,FIFO管道类型算一种。
有名管道有文件实体,但内存并不在磁盘存储,而是存放在内核内存缓冲区中;匿名管道没有文件实体,其实是内核区的一段缓冲区。
就是说我们通过命令行也好,通过函数也好,创建出来的有名管道是有文件实体的,可以 ll 看到,并且向普通文件一样使用,open write read access先判断管道是否已经存在等。但是存储数据为 0,写读数据都是在内核缓冲区就完成了,不会存储到管道文件中。
而创建出来的匿名管道是没有文件实体的,是通过固定的 pipefd[0], pipefd[1] 来读写数据的,也是在内核缓冲区完成。
内存映射
通过内存映射可以实现进程间的通信,原理 是多个进程共享同一个映射内存,一个进程对给内存进行修改,其他进程都可以通过该共享内存的地址访问到。(文件映射)
以及文件间的拷贝。原理 是分别将两个文件映射到内存中,然后做内存间的拷贝 memcpy,内存间的拷贝将同步到文件的拷贝。
以及父子进程间的通信(匿名映射),此时不需要文件实体,涉及到文件描述符和文件大小的参数 -1 和 自定义,其他步骤相同。
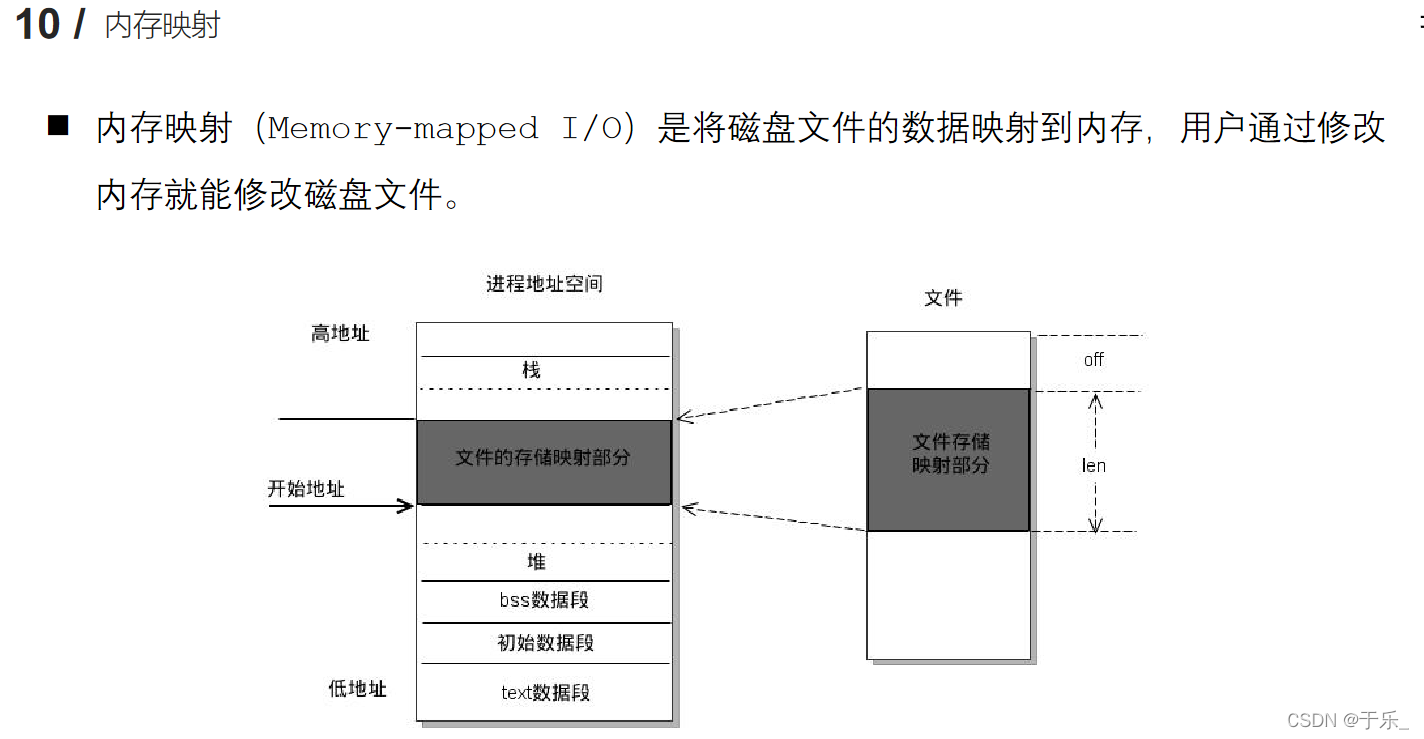
void * ptr = mmap(NULL, file_size, 内存映射区的读写权限, MAP_SHARE, fd, 0) 将文件映射到内存中
将指定文件描述符fd 的文件映射到内存中,映射大小为文件内容的大小file_size 或者任意大小,并且指定该区的读写权限和 同步到磁盘否。 返回一个指向该内存映射区的指针。
munmap(ptr, file_size) 通过维护该区的指针和区域大小 释放该内存。
信号
如 SIGINT, SIGQUIT, SIGALRM, SIGCHLD 信号等
-
用于进程间的通信,是事件发生时对进程的通知机制,告知另一个进程发生了某个事件。(软件中断)他是在软件层次上对中断机制的一种模拟,是一种异步通信方式。信号可以导致一个正在运行的进程被另一个正在运行的异步进程中断,转而去处理某一个突发事件。
-
引发内核为进程产生信号的事件有:
- 前台进程接收到了 ctrl + c
- 硬件发生异常:硬件检测到一个错误条件并通知内核,随即再由内核发送相应信号给相关内核。
- 系统状态发生变化:如 alarm定时器到期 会引发 SIGALRM 信号,进程执行的 CPU时间超限等。
- 运行kill 命令 或调用 kill函数
-
信号的状态
- 创建
- 未决:信号没有被处理
- 递达:信号被处理了
ulimit -a 中的 core file size 的用法:当访问了非法内存等时会报 段错误的提示,并且核心已转储,生成一个 core 文件。前提是 编译xxx.c文件时 加上调试信息,并且ulimit -a 查看core file size 不为0,则会生成一个 core文件。用来调试用。
gcc xxx.c -g -o xxx
gdb xxx
core-file core 可以查看具体的段错误的位置及错误详情。
kill(pid, sig_宏值或编号) 给指定进程或进程组 pid,发送 sig信号
- pid: >0, 将信号发给指定进程
- pid = 0, 将信号发给当前进程所在组
- pid = -1, 将信号发给所有有权限接收该信号的进程
- pid < -1, 将信号发给 |pid| 指定的进程组
raise( signal ) 发送信号给 当前进程
abort(void) 无参调用,默认给当前进程发送 SIGABRT,放弃当前进程
alarm(seconds_倒计时时长) 设置定时器。运行到该函数时开始倒计时,倒计时为0 函数会发送一个 SIGALRM 信号给当前进程,默认终止当前进程。
返回值是上一次定时器的剩余时长。
setitimer(which, &new_value, old_value ) 也是设置间隔定时器,区别是 精度更到,可以到 微秒级,并且可以实现周期性定时。
- which(ITIMER_REAL, ITIMER_VIRTUAL, ITIMER_PROF). 决定定时器的时间按哪个来,真实时间、虚拟时间(用户时间),用户时间+内核时间
- new_value,一个结构体,设置这次的时间延时it_value 时 和 时间间隔it_interval. 多长时间后 按 时间间隔为多少进行计时
- old_value(NULL, 上次的时间属性,一般为 Null)
信号捕捉
SIGKILL\ SIGSTOP 不能被捕捉,不能被阻塞,不能被忽略。
因为间隔定时器延时时间倒计时为0后,就会给进程发送一个SIGALRM 信号将进程杀死,所以后续的时间间隔定时器作用就相当于没有用。需要信号捕捉来实现时间间隔的操作。
signal(signal _要捕捉的信号, handler_捕捉到信号后如何处理)
- SIG_IGN: 忽略信号,对于接收到的 signal 信号忽略,会出现信号不起作用的现象,因为信号被忽略了。
- SIG_DFL: 使用信号默认的行为,signal 信号默认杀死当前进程,所以正常杀死当前进程。
- 回调函数的函数指针:根据自定义的函数来执行,即接收到 signal 信号后执行回调函数。
推荐使用
sigaction(signum, struct sigaction * act, struce oldact) 和 signal函数 一样,不过涉及到了 信号集。
- signum 要捕捉的信号
- oldact 上一次信号捕捉相关的设置,一般位 null
- act, 一个结构体. 可以设置捕捉到信号后的处理函数、设置临时阻塞信号集。
- sa_flags = 0, 使用回调函数处理捕捉到的信号
- sa_handler = 回调函数,处理函数
- sigemptyset(&sigaction.sa_mask); 清空结构体中的临时阻塞信号集
信号集
信号的集合即为信号集,存储在内核中,有 未决信号集(由内核决定,不能修改) 和 阻塞信号集(用户可修改)。64位信号集
- 用户通过键盘键入 CTRL+C, 产生信号 SIGINT (信号被创建);
- 信号被创建但还没被处理,处于 未决 状态,所有的未决信号存储在内核中的一个集合 未决信号集 中。标志位值为 1,说明信号处于未决状态;0 说明已被处理,为递送态。
- 处于未决信号集中的未决信号在被递送前要和另一个集合(阻塞信号集)进行对位比较,如果阻塞信号集的该信号为 0 非阻塞,未决信号就被处理;如果阻塞信号集中该信号为 1为阻塞态,则该信号就继续等待,直到阻塞解除,该信号被处理。
- 这块涉及到的 set 都是自定义信号集,对自定义信号集进行操作。
sigset_t set; 创建一个信号集,其内数据随机。
int sigemptyset(sigset_t *set); 清空信号集中的数据,将全部标志位置为0
sigset_t 64位信号集
int sigfillset(sigset_t *set); 将信号集中的标志位全部置为 1
int sigaddset(sigset_t *set, int signum); 将信号集中的 signum 信号置为 1,设置为阻塞这个信号
int sigdelset(sigset_t *set, int signum); 将信号集中的 signum 信号置为 0,设置为不阻塞这个信号
int sigismember(const sigset_t *set, int signum); 判断某个信号是否阻塞,通过判断该信号是否是自定义信号集的成员。是返回 1 为阻塞,不是返回 0 不阻塞,返回 -1 失败。
- 对 内核的信号集 进程操作,需要通过系统提供的 api 进行操作。
int sigprocmask(int how, const sigset_t *set, sigset_t *oldset); 检查或改变内核中的 阻塞信号集,将自定义信号集设置到内核中。
原理是我们先自定义一个阻塞信号集,将其设置为我们想要的信号阻塞状态,然后调用该函数来将其映射到 内核中。
how:
- SIG_BLOCK :将用户信号集中的阻塞位添加到内核中。mask | set
- SIG_UNBLOCK :将用户信号集中的 1 的位置的信号 在内核中解除阻塞。mask & ~set. set取反即把想要非阻塞的信号置为0了,然后和内核中的信号 &
oldset : 保存设置之前的内核中阻塞信号集的状态。一般位null
int sigpending(sigset_t *set); 获取内核中的未决信号集
SIGINT 信号
ctrl + c 产生的信号,2号信号
SIGQUIT 信号
ctrl + \ 产生的信号,3号信号
SIGKILL 信号
命令行 kill -9 或者 kill 函数 或者 raise函数 产生的信号
SIGABRT 信号
abort 函数产生的信号。
SIGALRM 信号
定时器倒计时为 0 后产生的信号。定时器有 alarm函数,setitimer函数
SIGCHLD 信号
当子进程终止、暂停、继续运行时,都会给父进程发送 SIGCHLD 信号,父进程会默认忽略该信号。
可以通过捕捉该信号修改接收到信号之后的处理方式,来解决 僵尸进程 的问题。原来的解决方案:在父进程中循环调用 wait() waitpid() 函数 来回收子进程 pcb 资源,并且 wait函数 是阻塞的,使得父进程没法做自己的事情;
SIGPIPE 信号
正常客户端调用 close() 是先断开自己的发送信息通道,还可以继续接收数据。但如果客户端不是正常的调用 close() 断开的连接,而是收发通道都断开了,此时服务器继续给客户端发送数据,就会产生 SIGPIPE信号。
共享内存
步骤:
-
int shmget(key_t key, size_t size, int shmflg)创建一个新的共享内存段 或 获取一个既有共享内存段 的标识符,新创建的内存段中数据会被初始化为0.
key: 共享内存区的编号可以理解为,通过这个 key 值找到或创建一个共享内存,16进程表示。
size: 共享内存的大小
shmflg: 属性。创建 IPC_CREAT | 判断共享内存是否存在 IPC_EXCL | 权限 0664
返回值:成功 > 0, 返回共享内存段引用的 shmid, 后续操作该共享内存都是通过这个值。 -
void * shmat(int shmid, const void* shmaddr, int shmflg)通过共享内存段的 id 将共享内存段附到调用进程上,使其成为进行的虚拟内存的一部分。
参数地址有内核指定,null;
shmflg: 对共享内存的操作。 读 SHM_RDONLY, 必须有的 | 读写 0
返回一个内存段地址 shmaddr -
int shmdt(const void * shmaddr)分离共享内存段 -
int shmctl(int shmid, int cmd, struct shmid_ds * buf)操作共享内存段,常用来标记一个共享内存段被删除,但真正删除是当连接到该内存段的进程数为 0 才会被回收。
cmd : IPC_RMID, 标记共享内存被销毁
buf: null。
守护进程
创建步骤
- 创建子进程,退出父进程,继续运行子进程
- 将子进程提升为会话,即 子进程调用
setsid()重新创建一个会话,脱离父进程所在的会话,从而脱离控制终端。 - 设置掩码
umask(); - 更改工作目录为根目录
chdir("/") - 关闭及重定向文件描述符
int fd = open("dev/null", O_RDWR);
dup2(fd, STDIN_FILENO);
dup2(fd, STDOUT_FILENO);
dup2(fd, STDERR_FILENO); - 业务逻辑
Linux 多线程开发
从线程入手,什么是线程 线程的创建 终止 取消 连接 分离;
到线程的属性的自定义(先定义线程的属性,在初始化线程时可以属性参数来初始化出有自定义属性的线程,比如初始化一个自动分离的线程);
再到多线程开发会遇到的问题以及处理方法:涉及到线程同步,避免数据混乱。可以用 互斥锁、读写锁来解决。
互斥锁的使用又可能会带来死锁的问题,只能人为干涉解决死锁。
讲到了 生产者消费者模型,只用上述的知识可以实现该模型,可以保证线程同步问题,保证数据安全。但因为该模型有边界的概念,消费者在商品数为 0 的情况下不可以继续销售,需要不断的判断是否有新的商品,需要一直消耗电脑资源来完成该事件。
所以后来又提出了 条件变量和信号量,来解决该问题。条件变量和信号量 可以让两者做到在不能继续生成或者不能继续销售时 阻塞,等待对方的通知,然后再去做自己的事件,从而节省资源。
** 进程的创建** - 读时共享,写时复制
复制虚拟地址空间,堆栈是不享的;
线程的创建
虚拟地址空间是共享的,a进程创建出来的所有线程共享a 进程的虚拟地址空间(除.text段、栈空间),.text段、栈空间由每个线程使用进程对应区域的一部分;堆、共享库、内核区都是共享的。每个线程由自己的特有数据、阻塞信号掩码。
创建线程
线程的类型:pthread_t
pthread_create(pid_要创建的子线程pid 通过这个pid来标识线程, null_线程的属性 可以为 null, 函数指针_线程的任务函数 子线程执行的任务都在这里, 函数指针指向的函数的参数);
创建一个新线程。编译时需要链接第三方库 -pthread
pthread_selt() 获取当前线程的 id
pthread_equal(pthread_1 线程1的tid, pthread_2 线程2的tid); 比较两个线程的 id 是否相等
终止线程
terminate calling thread. 终止一个线程,哪个线程调用,就终止哪个线程。
并且主线程的退出不会影响其他线程的正常执行。
pthread_exit(retval_一个指针 作为一个返回值 可以在pthread_join()中获取得到 可为 null) 无返回值
连接已终止的线程
和一个已经终止的线程进行连接,接收子线程退出时的返回值,并且回收子线程的资源。是一个阻塞函数,调用一次只能回收一个子线程,和 wait() 很像。
不能去连接一个已经分离的线程。
pthread_join(thread_id 要回收的线程的id, retval_指针的指针 接收子线程退出时的返回值)
线程分离
分离一个线程。被分离出去的子线程终止后,其资源会自动释放掉返回给系统; 而不需要再去调用 join连接函数和已经终止的线程进行连接,然后再回收释放线程资源。
不能多次分离
pthread_detach(tid_想要分离的线程 id);
线程取消
取消某个线程,可以终止某个线程的运行,在线程还没有运行结束还在运行的时候终止线程。但不是立马终止,而是到了系统规定的 取消点 时线程才会终止。
取消点 是系统规定好的一些系统调用,可以理解为 用户区切换到内核区进行系统调用的时候
pthread_cancel(tid);
线程属性
// 线程的属性 创建线程的时候有一个参数是线程的属性相关,我们可以先设置好想要创建的线程的属性,然后传参创建这样的线程。
// 属性要先 初始化,最后线程属性资源需要被 销毁,还有一些 获取和设置属性的函数。
pthread_attr_t attr; // 属性类型
pthread_attr_init(&attr);
// 比如 设置分离线程属性
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
// 创建进程的时候把属性参数指定为自己定义的
int ret = pthread_create(&tid, &attr, callback, NULL);
pthread_attr_destroy(&attr);
pthread_exit(NULL);
线程同步
线程的优势是可以通过全局变量共享资源。那换个角度,也正因为共享全局区资源,就可能会出现一些问题 如果读写不当的话。比如说线程A正在对一 临界资源 读操作,此时线程B 也可以操作到该 临界资源 对其进行了写操作,就会发生时间片在回到A 线程后读到的数据发生了变化。
临界区 是指访问某一共享资源的代码片段,临界区的代码片段的执行应该是 原子操作 的,也就是说同时访问临界区资源的其他线程不能中断当前正在执行这段代码的线程。
线程同步:当有一个线程在对内存操作时,其他线程都不可以对这个内存地址进行操作。直到该线程完成操作,其他线程才能对该内存地址进程操作。
不同的线程在执行各自的代码区的代码和操作属于自己栈区空间的数据时 属于 并行操作;但操作临界区资源的时候就属于 串行操作了,此时就涉及的是并发的问题了。对于临界区资源的执行要保证其原子性。
互斥锁/互斥量
为了避免线程更新共享变量时出现问题,可以使用 互斥量(mutex, mutual exclusion),来确保同一时间只有一个线程可以访问某项共享资源,保证对任意共享资源的原子访问。
互斥量有两种状态:已锁定 和 未锁定。任意时候,最后只能有一个线程锁定某项共享资源。一旦线程锁定互斥量,随机成为互斥量的所有者,只有所有者才能给互斥量解锁。
- 针对共享资源 锁定互斥量
- 访问共享资源
- 对互斥量解锁
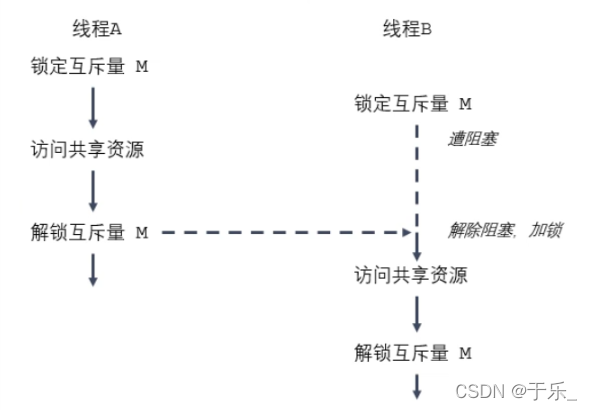
互斥量同样需要 初始化 和 销毁,还有一些关于 加锁、解锁 的函数。
互斥量的类型:pthread_mutex_t
pthread_mutex_init(&mutex, null); 初始化互斥量
pthread_mutex_destory(&mutex); 销毁互斥量
pthread_mutex_lock(&mutex); 给临界资源加锁,阻塞,当前资源被其他线程加锁访问时,其他线程会被阻塞,直到该资源被解锁
pthread_mutex_trylock(&mutex); 尝试加锁,非阻塞。
pthread_mutex_unlock(&mutex); 给临界资源解锁
条件变量
满足某一条件后 使线程阻塞或解除线程阻塞。不是锁,是配合锁来实现数据同步的问题的。
条件变量的类型: pthread_cond_t
pthread_cond_init()
pthread_cond_destroy()
pthread_cond_timedwait() 按时间进行等待,时间到解除阻塞
pthread_cond_wait() 阻塞,等待信号或者广播来解除阻塞。wait 参数有互斥锁,但这个互斥锁并不会一直拿着,而是会在当前线程阻塞后 先解锁,使得其他线程可以抢占该锁,当接到 信号后再将锁加到自己身上。
pthread_cond_signal() 发送信号给 wait() 的线程,最少一个 最多全部线程 解除阻塞。将一个或多个线程唤醒。
pthread_cond_broadcast() 广播给全部阻塞的线程 来解除阻塞。将所有线程唤醒。
信号量
主要作用是 阻塞线程,不能保证线程的数据安全问题;如果要保证数据安全,一定要和互斥锁一块使用。
下边用的车位比喻的。其实对于生产者和消费者而言的话,举生产和消费蛋糕可能会更好理解一点。 我们在创建了全局变量信号量后,需要先在 main线程中初始化才可以使用,初始化有一个参数是value,我们可以理解为是生产者可以生成的最大个数/消费者最多可以卖出的个数;也就是说同样一个容器,两者关注的侧重点是不同的,生产者关注还有多少空位置可以生产 有空位生产者工作 无空位生产者阻塞 等待消费者出售商品腾出空位再生产,而消费者关注的是有多少个蛋糕可以出售 有的卖则消费者工作 没有则阻塞 等待生产者生产 有了实体之后再去销售。两者通过对容器中的空位和商品个数的 wait 和 post 进行通信,从而避免一方不断的判断是否可以继续生产或者继续销售。
型号量的类型:sem_t semaphore 信号量
sem_init(sem_t *sem, int pshared 决定信号量是应用在线程间(0)还是进程间(非0), uint value);
初始化会初始化一个 信号量值。可以理解为信号量的数量,通过信号量数量的加加减减(post 和 wait ) 来通知两个线程,将两个线程联系起来。信号量值可以理解为容器的容量。
sem_destroy();
sem_wait(); 等待信号量,对信号量加锁,调用一次 信号量的值 -1。如果值为0,就阻塞。关注的是 车的数量,不断的减少车的数量。车少了,就有空闲车位了,就可以通知另一个线程 车位多了
sem_post(); 增加可用信号量,对信号量解锁,调用一次 信号量的值+1. 关注的是空闲车位的数量,不断的增加车位。车位被占了后,车辆加加,可以通知另一个线程加加。
sem_getvalue()
sem_t sem_prod;
sem_t sem_cust;
init(sem_prod, 0, 8); //生产者刚开始的数量是 8,需要不断--
init(sem_cust, 0, 0); //生产者刚开始的数量是 0,需要不断++
producer() {
sem_wait(&sem_prod);
sem_post(&sem_cust);
}
custmer() {
sem_wait(&sem_cust);
sem_post(&sem_prod);
}
死锁
死锁是在互斥锁的应用过程中加解锁操作不当导致的。
用互斥锁会共享资源先加锁在访问的机制可以实现线程同步了,但是如果加锁解锁不当或者某个线程的一个原子操作需要访问多个共享资源时,就会出现 死锁 的问题。
多个进程在执行过程中,争夺共享资源而造成的一种互相等待的现象,都需要等对方执行完后解锁占用资源才能继续执行。若无外力作用,他们将无法推进下去。此时就称系统产生了死锁。
产生死锁的几种场景:
- 加锁访问完数据后,忘记释放锁
- 一个线程中对一个共享资源 重复加同一把锁
- 两个资源,分别锁定了一个资源,又需要访问另一个资源才能完成操作。
读写锁
考虑到当一个线程在读数据的时候,其实后续的读操作其实也是可以同步进行的,因为读操作并不会引起程序出现错误。
所以对于大量读操作、少量写操作的程序而言,提出了读写锁。
对一个共享资源加读锁,其他线程也可以加读锁来读取该共享资源,但不可以对该资源加写锁;
对一个共享资源加写锁,其他线程既不可以加读锁,也不可以加写锁。并且写锁的优先级要更高。
读写锁的类型 :pthread_rwlock_t
pthread_rwlock_init(); 读写锁的初始化,读写锁是一把锁
pthread_rwlock_destory(); 销毁读写锁
pthread_rwlock_rdlock(); 加读锁
pthread_rwlock_tryrdlock();
pthread_rwlock_write(); 加写锁
pthread_rwlock_trywrite()
pthread_rwlock_unlock() 解锁读写锁
前三章的总结
- 静态库 动态库,概念、区别、制作、使用
- 虚拟地址空间
- 文件描述符
- 系统 API:open read write lseek stat lstat dup dup2 fcntl
进程开发
- 进程概念,状态间的转换
- 进程创建,退出
- 父子进程 虚拟地址空间
- exec
- 孤儿进程、僵尸进程。解决办法:wait waitpid 回收子进程资源
- 进程间通信方法和原理 :管道、信号、内存映射、共享内存、消息队列(没学)、信号量
- 守护进程 后台进程,周期性的执行某些事情
- 进程的调度策略和算法(没学)
线程开发
- 线程 进程的区别
- 线程概念 创建 终止 连接 分离 取消
- 线程同步 同步方式有哪些
- 生产者消费者模型 衍生出来的 条件变量和信号量
Linux 网络编程
网络结构模式
C/S 结构
客户机 - 服务器模式。(QQ, 英雄联盟等)
客户机负责与用户进行交互,接收用户的请求,发送请求给服务器进行处理;
服务器负责接收来自客户机的请求,对请求进行处理,操作数据库得到客户机想要的信息并发送给客户机。
优点
- 能充分发挥客户端pc 的处理能力,很多工作可以在客户端处理后 再交给服务器,所以 C/S 结构客户端响应速度快。
- 可以充分满足客户自身的个性化要求。
- 安全性较高,有更安全的存取模式,对信息安全的控制能力很强,一般高度机密的信息系统采用 C/S 结构适宜。
- 该结构管理信息系统有较强的事物处理能力,能实现复杂的业务逻辑。
缺点
- 需要安装专用的客户端软件。软件出问题需要重新安装、更新需要重新安装,且对于不同的操作系统平台,需要开发不同平台的客户端软件,不能跨平台。
B/S 结构
浏览器 - 服务器模式,这是 web 兴起后的一种网络结构模式。
因为 web 浏览器是客户端最主要的应用软件之一,我们可以将客户端统一到浏览器上,将系统功能实现的核心部分集中到服务器上,从而简化系统开发维护。客户机上只需要安装一个浏览器,服务器安装各种数据库,浏览器通过 web server 和数据库进行数据交互。
优点
最大的优点是 总体拥有成本低、开发简单、维护方便、分布性强,因为不需要开发专门的客户端软件,只要有浏览器就可以进行操作,客户端 0维护,系统扩展容易。
缺点
- 通信开销大、系统和数据安全较难保障;
- 个性化特点降低;
- 协议一般是固定的:http/https;
- 浏览器-服务器的交互是 请求-响应模式,通常是动态刷新页面,所以响应速度明显降低。
准备知识
网卡 与 MAC地址
网卡是一个硬件,使得计算机可以在网络上进行通信的设备,又称为网络适配器 或 网络接口卡NIC。有 以太网卡和无线网卡。
每个网卡有唯一的 mac地址 作为标识,mac地址 是一个独一无二的 48位串行号。MAC地址 是由48位 6字节组成的,每个字节由 2个十六进制表示。
网卡的主要功能:
- 数据的封装与解封;
- 数据链路管理;
- 数据编码与译码。
IP地址,IP协议
ip地址 全程是 Internet protocol address,是指互联网协议地址。 是IP协议分配的一个逻辑地址,提供统一的地址格式,以此来屏蔽物理地址的差异。
IP协议 是为计算机间连接通信而设计的协议,是一套可以使连接到网上的所有计算机实现相互通信的规则。
IP地址 是一个32位的二进制数,通常用 点分十进制 表示(a.b.c.d), abcd 都是0-255之间的十进制整数。IP地址 由 网络id和主机id 组成,可以通过 子网掩码 来区分。分为 A类IP地址,B类IP地址,C类IP地址;分别适用于大规模、中等规模、小规模的网络。
端口
端口 可以认为是设备与外界通讯交流的出口;如果把 IP地址 比作是一个房间,端口就是出入这间房的门。端口通过端口号来标识,端口的个数是 2^16 65536个,从 0-65535.
端口可以分为 虚拟端口 和 物理端口。
虚拟端口只是逻辑意义上的端口,不可见,特指 TCP/IP协议 中的端口,如计算机中的 80端口、22端口等。
物理端口 是可见端口,如计算机 交换机 路由器内的 RJ45网口。
端口又分为 周知端口 和 ** 注册端口** 两种类型。
周知端口就是大家公认的端口,范围从0-1023。比如我们熟知的 80端口分配给 www服务,21端口分配给 FTP服务等。
剩余的端口 分配给用户进程或应用程序使用。
网络模型
OSI 七层参考模型
- 物理层:定义物理设备标准,如接口类型、介质传输速率等。主要作用是传输比特流,该层的数据叫做 比特。(就是由1、0转化为电流强弱来进行传输,到达目的地后再转化为1、0,也就是我们常说的数模转换与模数转换)
- 数据链路层:网卡起作用的层。硬件地址寻址,差错校验。将比特组合成字节 进而组合成 帧,用mac地址访问介质。
- 网络层:IP协议起作用的层。逻辑地址寻址,为不同位置网络中的主机之间提供连接和路径选择。
- 传输层:定义了一些传输数据的协议和端口号,进行数据传输。将下层接受到的数据进行分段和传输,到达目的地后再进行重组。 这一层的数据叫做 段。
- 会话层:session。通过传输层简历数据传输的通路,发起会话或接受会话请求。
- 表示层:将接收到的信息经过转换,将计算机能够识别的东西表示成用户可以识别的内容。对数据进行解释、加密解密、压缩解压缩。
- 应用层:网络服务和用户的一个接口,为用户的应用程序提供网络服务。
TCP/IP 四层模型
- 应用层:FTP协议(File Transfer Protocol 文件传输协议),HTTP协议(Hyper Text Transfer Protocol 超文本传输协议)
- 传输层:TCP协议(Transmission Control Protocol 传输控制协议)、UDP协议(User Datagram Protocol 用户数据报协议)
- 网络层:IP协议(Internet Protocol 因特网互联协议)、ICMP协议(Internet Control Message Protocol 因特网控制报文协议)(ping用的就是这个协议)
- 数据链路层:ARP协议(Address Resolution Protocol 地址解析协议)、TARP协议(Reverse Address Resolution Protocol 反向地址解析协议)
网络通信过程
-以传输一条 QQ消息 为例,发送方从应用层开始,经过传输层、网络层、数据链路层,在每一层都会根据所在层所采用的通信协议加对应的消息头和消息尾;
-发送到接收方后,接收方反向从下层依次向上将信息传递上去,每一层去解析对应的头部信息和尾部信息,然后根据信息发送给对应的上一层,最后到达应用层,应用层根据应用层头解析得到应用数据。通信完成。
过程中 如应用层的数据往传输层发送,发送给 UDP 就需要源端口号 目的端口号 数据报的长度 校验和 4个16位 2字节的数据 一共8字节的头部信息;
TCP需要 源端口号 目的端口号 位序号即该报文段数据的第一个字节的序号 确认号 数据偏移长度 几个标志位 窗口大小 校验和 紧急指针 20个字节头;
再往下 到达网络层,IP协议需要 版本号 头部长度 头部加数据部分的长度信息 标识 标志 片偏移 生存时间 协议 头部校验和 源IP地址 目的IP地址;
再往下到达数据链路层,需要加
以太网帧协议头 目的物理地址 源物理地址 类型 类型决定发给谁IP/arp/rarp 数据 校验位;
ARP协议通过 IP地址查询mac地址,需要 硬件类型即mac地址 协议类型即谁发来的ip地址 硬件地址长度6个字节的物理地址长度 协议地址长度 操作是ARP应答还是请求 发送端以太网地址 发送方IP地址 目的端以太网地址 目的端IP地址。
字节序
字节在内存中存储的顺序。
- 小端字节序:数据的高位字节存储在内存的高位地址,低位字节存储在低位地址;
- 大端字节序:数据的高位字节存储在内存的低位地址,低位字节存储在内存高位地址。
网络字节顺序:采用大端排序方式,是 TCP/IP 中规定好的一种数据表示格式。与具体的 CPU类型、操作系统等无关,从而保证数据在不同的主机之间传输时能够被正确解释。
字节序转换函数
当格式化的数据在两台字节序不同的主机间直接传递时,接收端必然错误的解释接收到的数据。
解决办法是:发送端总是要把发送的数据转换成大端字节序数据后再发送,即网络字节序都是一样的,为大端字节序。然后接收端通过判断自己采用的字节序来决定是否需要对接收到的数据进行转换,大端机不转换,小端机则需要转换后再对其进行解释。
#include <arpa/inet.h>
从主机字节序到网络字节序的转换函数:
uint16_t htons(uint16_t hostshort); 转端口
uint32_t htonl(uint32_t hostlong); 转 IP
从网络字节序到主机字节序的转换函数:
uint16_t ntohs(uint16_t netshort); 转端口
uint32_t ntohl(uint32_t netlong); 转 IP
socket 地址
socket 地址其实是一个结构体,封装端口号和IP 等信息。socket 相关的 api 中需要用到这个 socket地址。所有的 socket编程接口 使用的地址参数类型都是 sockaddr.
通用 socket 地址
只是留下了存放 IP和port 的内存空间,还需要自己写入,不方便。用专用的更方便。 最初的通用 socket地址是结构体 sockaddr:
#include <bits/socket.h>
struct sockaddr {
sa_family_t sa_family; //决定协议类型的协议族。有:PF_UNIX, PF_INET, PF_INET6
char sa_data[14]; // 根据协议族类型决定存放 socket地址值。
};
typedef unsigned short int sa_family_t;
sa_data 成员存放的 socket地址值。
| 协议族 | 地址值含义和长度 |
|---|---|
| PF_UNIX | 文件的路径名,长度可达到108字节 |
| PF_INET | 16 bit 端口号和 32 bit IPv4 地址,共 6 字节 |
| PF_INET6 | 16 bit 端口号,32 bit 流标识,128 bit IPv6 地址,32 bit 范围 ID,共 26 字节 |
可以发现该通用类型存放 ipv6的socket 地址值并不够,所以后来又提出了新的 socket地址结构体 sockaddr_storage. 有了更大的存储空间来存放协议地址值,并且是内存对齐的。
专用 socket 地址,常用,方便
已经对应不同的地址协议 封装好了ip和port,直接用即可。专门用于存放 ipv4 socket地址值的结构体 sockaddr_in, 和 专门存放 ipv6 地址值的结构体 sockaddr_in6。
#include <netinet/in.h>
struct sockaddr_in
{
sa_family_t sin_family; /* __SOCKADDR_COMMON(sin_) */
in_port_t sin_port; /* Port number. */
struct in_addr sin_addr; /* Internet address. */
/* Pad to size of `struct sockaddr'. */
unsigned char sin_zero[sizeof (struct sockaddr) - __SOCKADDR_COMMON_SIZE -
sizeof (in_port_t) - sizeof (struct in_addr)];
};
struct in_addr
{
in_addr_t s_addr;
};
struct sockaddr_in6
{
sa_family_t sin6_family;
in_port_t sin6_port; /* Transport layer port # */
uint32_t sin6_flowinfo; /* IPv6 flow information */
struct in6_addr sin6_addr; /* IPv6 address */
uint32_t sin6_scope_id; /* IPv6 scope-id */
};
typedef unsigned short uint16_t;
typedef unsigned int uint32_t;
typedef uint16_t in_port_t;
typedef uint32_t in_addr_t;
#define __SOCKADDR_COMMON_SIZE (sizeof (unsigned short int))
所有专用 socket 地址(以及 sockaddr_storage)类型的变量在实际使用时都需要转化为通用 socket 地址类型 sockaddr(强制转化即可),因为所有 socket 编程接口使用的地址参数类型都是 sockaddr。
IP地址转换
IP地址的 字符串表示到整数表示的转换;主机字节序和网络字节序的转换。
我们阅读时习惯用 点分十进制 表示,然后计算机处理的是二进制数,所以我们会进行字符串和整数之间的转换,所以需要掌握一些 用点分十进制字符串表示的 ip地址 到 用网络字节序整数表示的 IP地址 转到的函数:
#include <arpa/inet.h>
// p:点分十进制的IP字符串,n:表示network,网络字节序的整数
int inet_pton(int af, const char *src, void *dst);
af:地址族: AF_INET AF_INET6
src:需要转换的点分十进制的IP字符串
dst:转换后的结果保存在这个里面
// 将网络字节序的整数,转换成点分十进制的IP地址字符串
const char *inet_ntop(int af, const void *src, char *dst, socklen_t size);
af:地址族: AF_INET AF_INET6
src: 要转换的ip的整数的地址
dst: 转换成IP地址字符串保存的地方
size:第三个参数的大小(数组的大小)
返回值:返回转换后的数据的地址(字符串),和 dst 是一样的
TCP UDP 比较
两者都是传输层的协议
UDP: 用户数据报协议
- 它是面向无连接的,使用udp 通信的两端是不需要事先建立好连接的,直接发送数据;
- 传输方式 面向数据报 (报文) 的一种协议,发送的数据是数据报,一个个数据报包,有固定的大小,谁都可以接收;
- 可以单播、多播、广播,也就说 udp可以是一对一发送,也可以是一对多、多对多发送的;
- 不可靠,①个是因为它是无连接的,发送方随时可以发数据而不知道接收方的状态的情况下,接收方接收什么数据就向上层传递什么数据;②是因为 udp不考虑发送方的数据有没有送达,接收方对收到的数据也不会进行备份; ③是没有拥塞控制,即使网络不好,也会按照恒定的数据进行发送,而不会对发送速度进行调整,所以在网络不好的情况下就可能会丢失一些包。但同时也是一个优点,对于实时性要求高的场景,使用 udp 可以保证通信效率。
- 头部开销 小,8个字节
- 适用场景不同:实时应用(视频音频聊天,直播等)
TCP: 传输控制协议
- 面向连接的,建立连接相当于多了一个通道,内容在一个通道中收发,数据安全 指数据丢失不丢失
- 基于字节流的一种协议,有通道,在通道中发送数据就跟水管一样,内容流向另一端
- 仅支持单播传输,每条TCP传播只会有两个端点,只能进行点对点的传输
- 可靠的,有很多的方式来保证可靠性。比如 三次握手、四次挥手、超时重传、拥塞控制
- 头部开销大,最少 20个字节
- 适用场景不同:可靠性高的应用(文件传输)
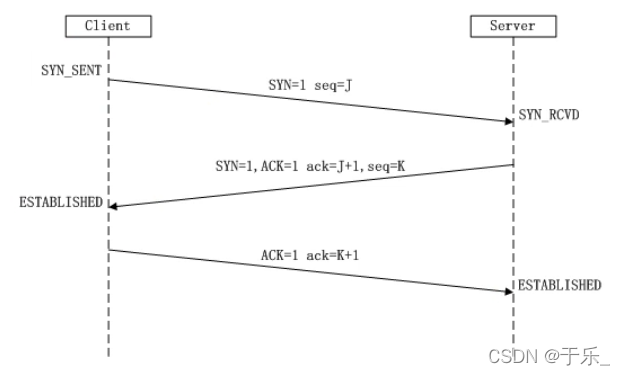
TCP三次握手
三次握手主要是为了保证通信双方之间建立起连接。发生在客户端连接到服务器端的时候,使用 socket通信 调用 connect() 时,底层会通过 TCP协议 进行三次握手。
tcp 头部结构 中包括 源端口和目标端口号4个字节,4个字节 序号,4个字节 确认号,几个标志位,两个字节 窗口大小,16位 校验和,16位紧急指针以及40字节的备选。
重点关注:32位序号,32位确认号,几个标志位(ACK, SYN, FIN),16位窗口大小。
 从这样两个方面来 考虑和理解三次握手
从这样两个方面来 考虑和理解三次握手
-
通信过程中的 标志位的变化
连接过程中起作用的标志位有: SYN = 1发起连接,ACK = 1确认收到连接请求 -
通信过程中 序号和确认号的变化
序号:tcp通信是面向字节流的嘛,字节流数据中的每个字节会通过序号作唯一标识,序号是根据一定的规则随机生成的,并不是每次都是固定的从0开始。
确认序号:接收到对应序号的字节流后,返回一个确认序号,为接收到的所有字节流最后一个字节的下一个字节对应的序号即为确认号。 -
其实还有 滑动窗口的大小,在建立连接时就有在发送。其实建立连接也好,收发数据也好,断开连接时也好,TCP头部中这些信息都存在。
//三次握手流程:
头部信息的变化:
第一次握手:客户端向服务器端
1.客户端向服务器端发起连接请求,将标志位 SYN=1;
2.客户端生成一个随机的32位序号 seq=j, 这个序号后边可以携带数据(数据的大小);
第二次握手:服务器端向客户端
1.服务器端响应客户端的连接请求,将 ACK标志位置为1;
2.服务器端回发一个序列确认信号:ack=客户端随机序号+数据长度+ SYN/FIN(按一个字节算).
3.服务器端向客户端发起一个连接请求,将标志位 SYN=1;
4.服务器端生成一个随机序号:seq=k.
第三次握手:客户端向服务器端
1.客户端响应服务器端的连接请求:ACK=1
2.客户端回发一个序列确认信号,ack=服务器端序号+数据长度+ SYN/FIN一个字节
客户端和服务器端状态的变化:
客户端:
1.客户端在第一次握手时状态为 SYN_SEND,然后发送请求给服务器端;
2.当收到服务器端的回复后,客户端状态变为 ESTABLISHED.
服务器端:
1.服务器端初始为 LISTEN状态;
2.当接收到客户端的连接请求后,状态变为 SYN_RCVD,并作出相应;
3.当再次接收到客户端的回复后,状态变为 ESTABLISHED.
TCP 滑动窗口
滑动窗口是一种流量控制技术。是TCP 中实现像 ACK确认、流量控制、拥塞控制的承载结构。重点在接收方的接收缓冲区,通过接收方的处理能力来决定滑动窗口的大小。
滑动窗口的大小意味着接收方还有多大的缓冲区可以用于接收数据。发送方可以通过滑动窗口的大小来决定应该发送多少字节的数据(流量控制)。其大小会随着发送数据和接收数据而变化。
当滑动窗口的大小为 0 时,发送方会停止给接收方发送数据,阻塞等待接收方可以继续接收数据。(拥塞控制)
当通信双方建立连接后,开始收发数据。收发数据不是单纯的根据自己的发送能力来发送数据,而是根据接收方的接收能力来动态调整发送数据的量。发送方不是没发一条报文就会阻塞等待接收方的确认信息,而是根据接收方剩余缓冲区大小 连续发送报文,直到发送出去的数据够填充接收方缓冲区的大小后,阻塞等待接收方处理重新回复给自己非0的滑动窗口,再继续发送数据。
win 滑动窗口大小
mss(maxumum segment size) 最大报文段的长度,即一条报文最多发送的数据大小
TCP 四次挥手
四次挥手发生在断开连接的时候,在程序中调用 close() 会使用 TCP协议进行四次挥手。
客户端和服务器端都可以主动发起断开连接,谁先调用 close() 谁主动发起。
//以客户端主动断开为例
客户端
1.调用 close() 发起断开连接的请求,发送 FIN=1的报文段给服务器,状态由 established > fin_wait_1.
2.接收到服务器端的 ACK=1后,状态吧变为 fin_wait_2
3.接收到服务器端的断开连接请求后,状态变为 time_wait,此时当发送 ACK=1 的报文段给服务器,会等待 2msl(两倍的最大报文段生命周期时长),确保最后一次发送的数据到达了服务器。待等待 2msl后,变为 close状态。
服务器:
1.接收到客户端的断开连接请求后,状态变为 close_wait,并且发送 ACK=1给客户端。
2.处理完最后的业务后,调用 close()函数,发送断开连接请求 FIN=1 给客户端,状态变为 LAST_ACK。
3.待收到最后的确认标志后 ACK=1后,变为 established.
半关闭
当客户端向服务器端发起断开连接 FIN=1的请求后,并且接收到了服务器的 ACK=1 但服务器还没有给客户端发起断开连接请求时,客户端处于 半关闭 状态。
我们可以通过调用 api 来控制实现半连接状态:
#include <sys/socket.h>
int shutdown(int sockfd, int how);
- sockfd: 需要关闭的 socket描述符
- how: 以哪种方式执行 shutdown
- SHUT_RD(0): 关闭读功能,该套接字不在接收数据
- SHUT_WR(1): 关闭 sockfd 的写功能,不能再对该套接字发出写操作
- SHUT_RDWR(2):
shutdown 和 close 的区别
使用 close 终止一个连接,只是减少描述符的引用计数,并不直接关闭连接,只有当描述符的引用计数为 0 时才关闭连接。
shutdown 并不考虑描述符的引用计数,而是直接关闭描述符,当然 可以选择只终止读、只终止写或读写全部终止。也就是说如果一个描述符被多个进程打开着,只要有一个进程调用了 shutdown,其他进程也将无法进行通信;但调用 close() 不会影响到其他进程。
端口复用
什么时候用呢:
- 防止服务器重启时,之前绑定的端口还未释放
- 程序突然退出,而系统没有释放端口。
用 socket 实现网络通信
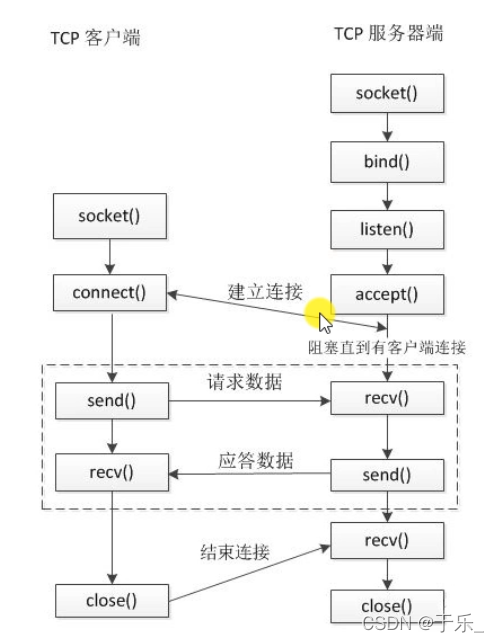
TCP 通信流程
TCP 通信无非就是两端,一端连接客户端,一端连接服务器端。
// 服务器端通信流程
1. 创建一个用于监听的 socket 套接字,用于监听客户端的连接请求。这个套接字其实就是一个文件描述符。
2. 将这个监听文件描述符绑定到本地 IP 和端口
3. 设置监听,监听的 fd 开始工作
4. 进入到阻塞等待状态。当有客户端发起连接请求时,解除阻塞,接受客户端的连接,会得到一个和客户端通信的套接字。
5. 开始通信,进行数据的发送与接受
6. 通信结束,断开连接
// 客户端通信流程
1. 创建一个同于通信的套接字
2. 向服务器发起连接,这步需要指定服务器的 IP和端口号
3. 连接成功,两端开始通信,发送数据和接收数据
4.通信结束,断开连接。
TCP 通信直接使用 套接字函数 实现
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h> // 包含了这个头文件,就相当于包含了上边两个
// 服务器端创建套接字,用来监听
int sockfd = socket(int domain, int type, int protocol);
- domain: 协议族
AF_INET: ipv4
AF_INET6:ipv6
AF_UNIX,AF_LOCAL:本地套接字通信
- type: 通信过程中使用的协议类型
SOCK_STREAM: 字节流协议
SOCK_DGRAM: 数据报协议
- protocol: 具体的一个协议,取决于 type类型,一般为0。
SOCK_STREAM: 默认使用 TCP
SOCK_DGRAM: 默认使用 UDP
- 返回值:
成功返回 文件描述符,操作的就是内核缓冲区
失败 -1
// 绑定到 本地IP和端口
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
- sockfd: socket 函数的返回值
- addr: 需要绑定的 socket地址,封装了 IP和端口号信息
- addlen: 第二个参数结构体占的内存大小
// 设置监听,监听这个套接字上的连接
int listen(int sockfd, int backlog);
- sockfd: socket 函数的返回值
- backlog: 未连接的和已连接的套接字个数的最大值, 5-128 即可。可以在/proc/sys/net/core/somaxconn中查看最大可以设置的值
// 接收客户端连接,默认阻塞,等待客户端连接
int tongxinfd = accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
- sockfd: socket 函数的返回值,用于监听的套接字文件描述符
- addr: 传出参数,记录了连接成功后的 客户端的地址信息(ip, port)
- addrlen: 指定第二个参数对应的结构体大小
返回值:
成功:用于通信的文件描述符 tongxinfd
失败 -1
// 读写通信
read
write
// 客户端 连接到服务器端
int accept(int sockfd, const struct sockaddr *addr, socklen_t *addrlen);
- sockfd: 用于通信的文件描述符
- addr: 要连接的服务器的地址信息 ip,port
- addlen: 第二个结构体占用内存的大小
返回值:成功 0, 失败 -1
并发服务器的实现
多进程实现
多进程实现并发服务器的开发,需要用到 fork() 来创建子进程,创建了子进程就需要在子进程执行完事务后 回收子进程资源(wait(), waitpid(), 信号捕捉)。
wait() 的处理方式会使父进程阻塞,不能去处理自己的事务,这里指的是不能不断的 accept() 新的客户端的连接。
信号捕捉 会导致 accept() 的软中断,也是一种错误,所以需要判断的时候对这种错误进行特殊处理,使其不会影响到 accept() 的阻塞。
若干个客户端已经和服务器端建立了连接 并且已经在通信,此时如果有客户端断开连接,则客户端不在给服务器写数据,服务器最后一次读取数据长度为0。可是其实此时走的是 返回值为-1的语句体,返回一个 read:Connection reset by peer 错误。
多线程实现
这个就考虑一个点,就是多线程在实现并发服务器时,因为每个线程的栈区和代码区是独立的,所以线程的数量需要有一个上限,而不能每个客户端连接进来就创建一个线程这么简单。而是定义一个数组专门用来负责连接到客户端负责通信。
io多路复用(io多路转接)
I/O 多路复用使程序能同时监听多个文件描述符,提高程序的性能。
Linux 下实现 io多路复用 的系统调用主要有 select、poll、epoll。
几种常见的 io模型
1.阻塞等待: BIO模型。accept(),read()
- 好处:不占用 cpu时间片
- 坏处:同一时间只能处理一个操作,效率低
解决办法:使用 多进程或者多线程 实现并发服务器。- 进程和线程会消耗资源
- 进程或线程的切换或者说调度消耗 cpu 资源
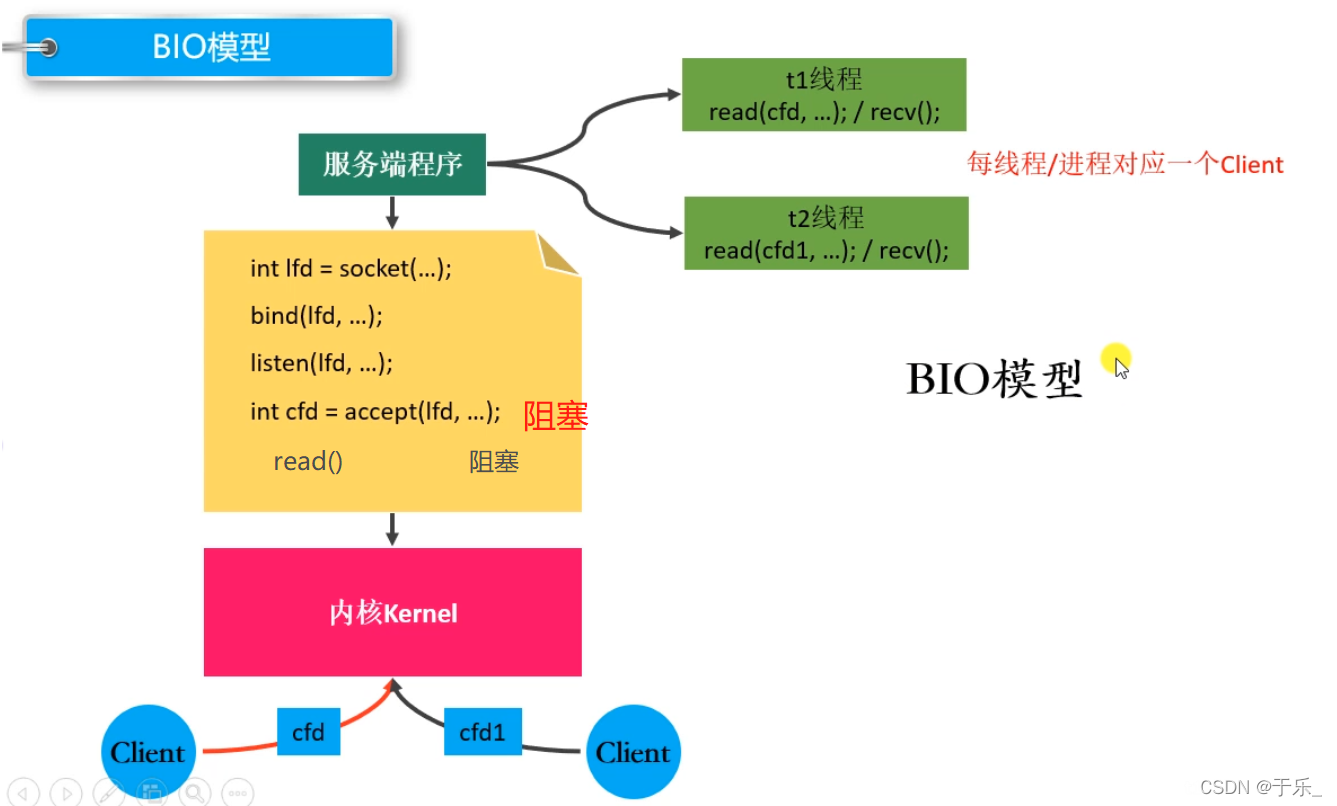 a客户端发起连接,被 accept(), 如果只有一个进程一个线程,则会被 read() 阻塞;当 b客户端此时也想建立连接,就没办法被 accept(),所以 accept() 由父进程或主线程负责,而 读写操作由子进程或子线程来负责,从而实现 并发服务器,同时和多个客户端建立连接并通信。
a客户端发起连接,被 accept(), 如果只有一个进程一个线程,则会被 read() 阻塞;当 b客户端此时也想建立连接,就没办法被 accept(),所以 accept() 由父进程或主线程负责,而 读写操作由子进程或子线程来负责,从而实现 并发服务器,同时和多个客户端建立连接并通信。
根本问题: blocking,阻塞导致的。
2.非阻塞,忙轮询,NIO模型
把 accept() read() 设置为非阻塞,然后每隔一定时间查看是否有 客户端的连接请求或者有数据可以读。
提高了程序的执行效率,但需要占用更多的 cpu和系统资源。
通过使用 io多路转接技术来解决。
 > 可以用 饭店来举例子。一个服务员和未知数量的客户。一方面需要负责新来的客户,一方面需要负责已经坐下的客户。 又要眼观六路、耳听八方,又要做好手头的事。
> 可以用 饭店来举例子。一个服务员和未知数量的客户。一方面需要负责新来的客户,一方面需要负责已经坐下的客户。 又要眼观六路、耳听八方,又要做好手头的事。
多路转接模型
多个客户端一个服务器,即并发服务器。
对于 NIO 模型,多个客户端需要服务器来轮询处理,虽然提高了程序的执行效率,但消耗大量的系统资源 占用cpu时间片。
所以有了多路转接技术,将多个客户端委托给内核来处理,内核再通知服务器是否需要读写或者处理连接请求。工作单一化。
select 和 poll 类似,epoll 效率更高。
select、poll: 同样是一个饭店,不同的是这个饭店除了有个服务员,还有一个经理。经理负责观察哪几桌客人有需要,将有需要的客人桌号置为1、有没有新客户进来,然后通知服务员说有几桌客人需要服务,然后服务员通过遍历桌号来判断是哪桌客人有需要,进而去服务。
和select、poll 不同的是 这次的服务器不需要去遍历就能知道到底是谁需要服务,因为中间人不仅告知有几桌需要服务,而且是谁也直接告知了。
select
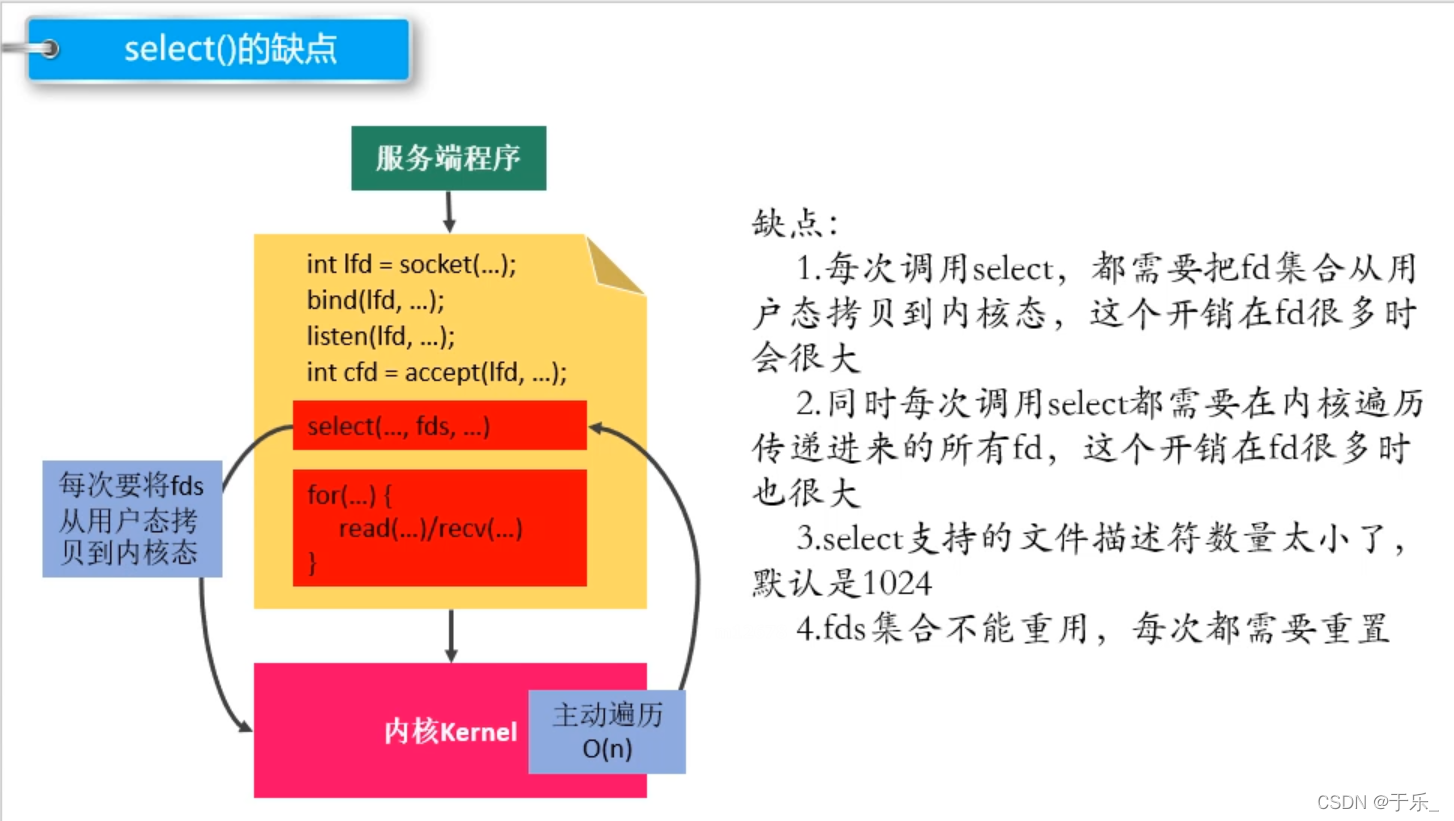
该系统调用 是委托内核对设置为需要检测的文件描述符进行检测,当有文件描述符对应的缓冲区发生改变,就返回,返回值为 number of ready descriptors.
当返回值大于0,比然有文件描述符丢应的缓存区发生变化,先判断是不是有新的客户端连接进来了,如果是,接收连接;然后是同通信,通信的话是遍历 文件描述符数组,直到需要检测的最大的文件描述符为止,遇到为1的文件描述符就是读缓冲区发生了变化,此时去读数据不会阻塞。
poll
poll 和 select 基本类似,不过改进了 select 的 文件描述符数组的数量大小限制以及不能重用的问题,因为 poll 用的不再是数组,而是结构体封装了文件描述符及处理事件,我们可以自定义其数量以及 重用文件描述符,因为我们每次只需要修改结构体中的参数即可,不会影响到需要继续检测的文件描述符有哪些。
poll 和 select 不同的是:
select 用的是已经封装好数量的文件描述符数组,大小为1024,和内核中的文件描述符数组大小相同。也是通过操作用户区创建的这样一个文件描述符数组,设置自己想要检测的文件描述符,然后调用 select 时将数组拷贝到内核中,内核根据数组中设置的需要检测的文件描述符去检测,有对应的缓冲区发生变化,返回,根据返回的描述符变化个数去操作。
poll 同样是创建一个管理文件描述符的数组,不同的是该文件描述符数组可以复用。因为数组中存放的是一个个封装好的结构体,委托给内核后内核操作的是结构体中的一个变量,不影响下次仍然需要检测的文件描述符有哪些,从而不需要每次都复制一份 专门用于让内核操作的文件描述符数组。 解决了select的第三个 第四个缺点。
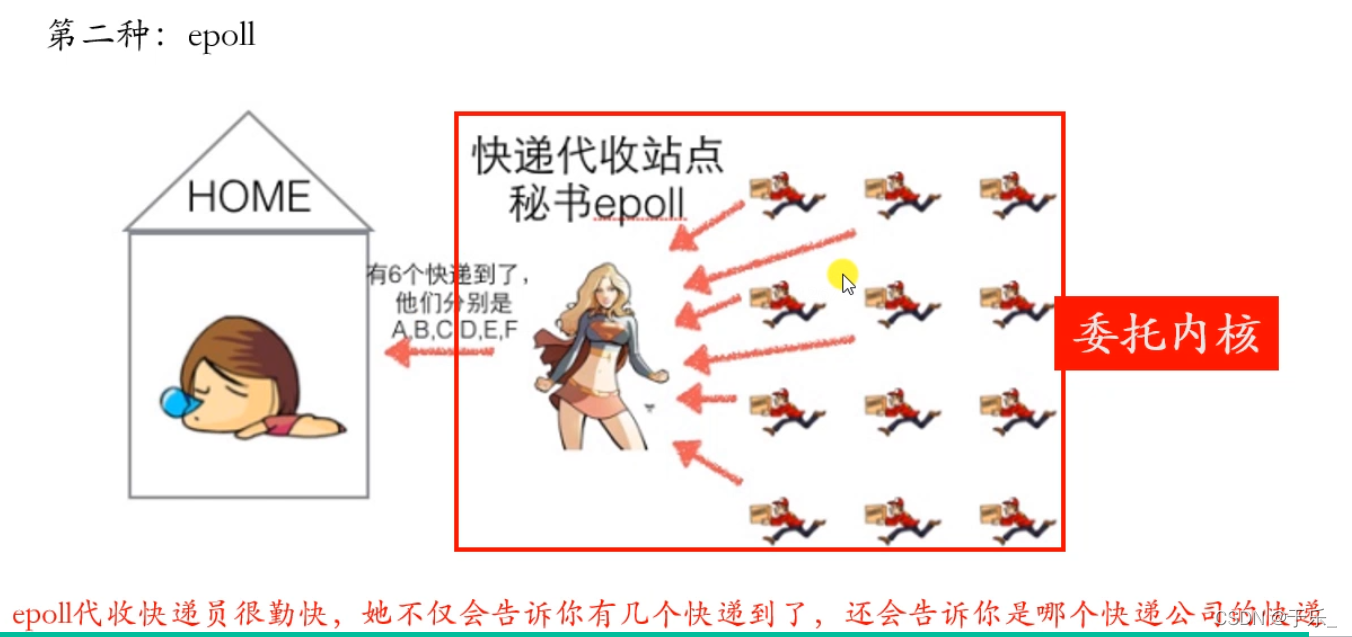
epoll
epoll - I/O event notification facility. 输入输出事件通知功能
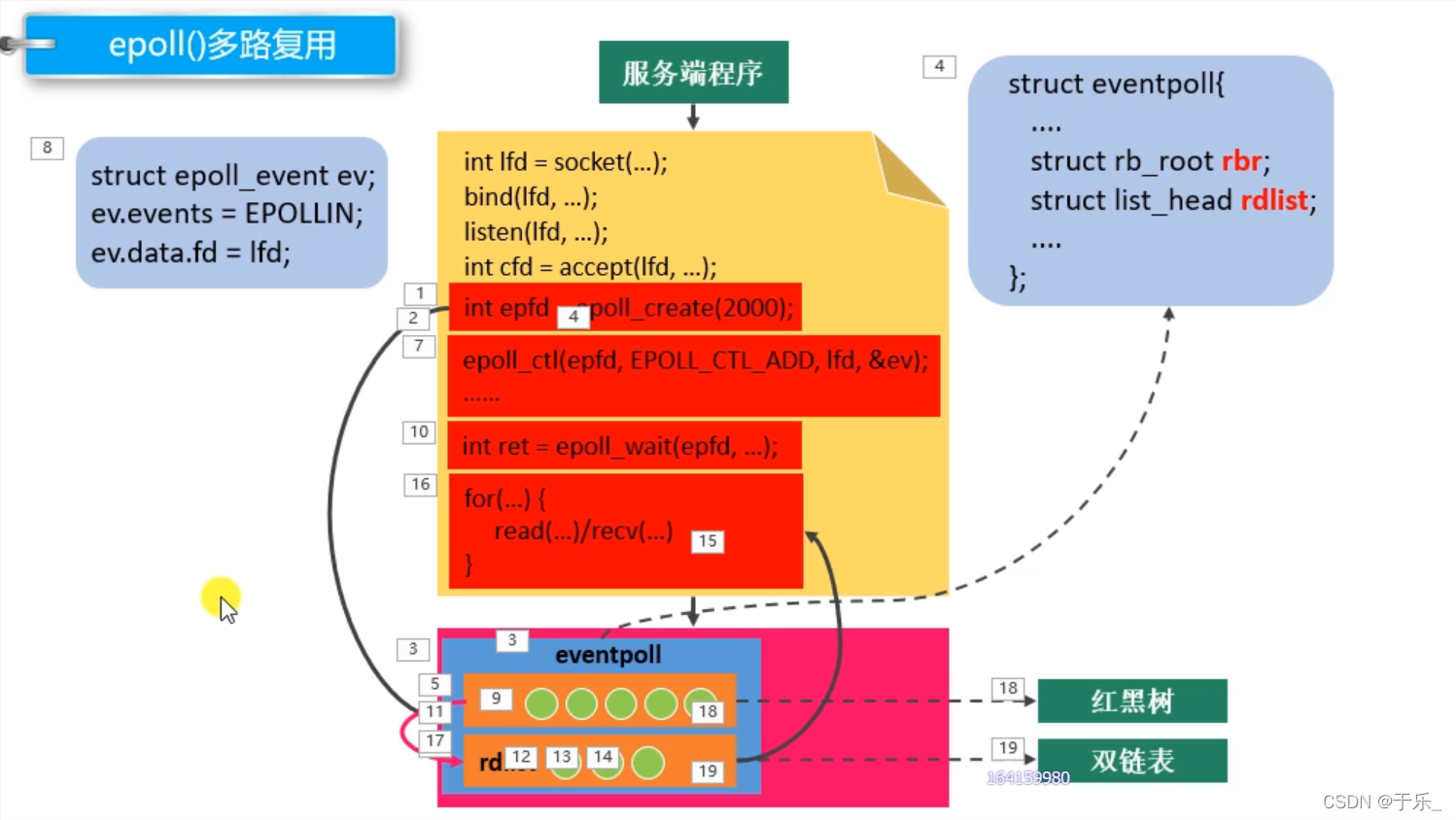
// epoll部分 代码思路流程
1. epoll_create() 创建一个 epoll实例 到内核中,
epoll实例是一个 event_poll类型的结构体,结构体中我们重点理解的是 **红黑树**和**双链表**,
红黑树 用来保存需要检测的文件描述符,双链表 用来保存检测到的有变化的文件描述符。
2. 往 epoll实例中 添加要检测的文件描述符。
先创建一个结构体,给结构体中的参数赋值:如我们要检测的文件描述符、要检测的读还是写
3. 调用 epoll_wait() 函数让 epoll实例工作,检测添加到红黑树中的需要检测的文件描述符以及需要检测的事件,检测到有变化的文件描述符就在链表中做记录,最终会输出到传入传出参数 epoll_event的数组中,并且返回发生变化的文件描述符的个数。
4. 我们可以通过遍历 返回值中的 结构体中的文件描述符,来进行和客户端的连接以及读写操作。
两种工作模式
LT 模式 (水平触发)- 只要有数据就通知
level-triggered, 是缺省的工作方式,默认是这种工作模式。同时支持 block和no-block socket。在这种模式下,当一个文件描述符就绪,内核返回就绪文件描述符个数以及具体的文件描述符信息,我们就可以就其进行 读写操作了。如果一次读操作并没有 将缓冲区中的数据读完,下一轮检测内核还会继续返回该文件描述符的信息。
ET 模式(边沿触发)- 数据只通知一次,这次没读完下次不再通知
edge-triggered,是高速工作方式,支支持 no-block socket. 在这种工作模式下,对于就绪的文件描述符,内核只会返回一次相关信息,如果一次读操作没有读完对应缓冲区,下次内核不会再返回这个文件描述符中还有数据没读完,所以在这种模式下,我们需要 while读写操作,只要内核返回一个文件描述符,我们就要把这个文件描述符对应缓冲区读写干净,并且要注意 read/write 操作必须为非阻塞。
也正因为这样,ET模式很大程度上减少了 epoll事件 被重复触发次数,从而提高了工作效率。
将文件描述符设置为非阻塞,然后在遍历到一个文件描述符需要读数据后,要 while循环 读取数据直到读完为止。这个时候要考虑:非阻塞文件描述符的缓冲区在读完数据后并不会返回 len=0,而是返回一个错误号 EAGAIN len=-1,所以在返回值为-1的语句体中 我们要加入错误号的判断,如果 errno=EAGAIN,就是正常读完数据了,继续下一轮循环即可,而不是错误退出。返回 0 意味着客户端断开连接了,所以才能返回读取数据为 0.
epoll 通知事件
EPOLLIN EPOLLRDHUP 连接对端断开连接后,会触发事件
EPOLLONESHOT 事件
想让一个 socket 连接在任一时刻都只被一个线程处理,可以使用 EPOLLONESHOT事件 来实现。

tcp 通信流程
// 本地套接字通信的流程 - tcp
// 服务器端
1. 创建监听的套接字
int lfd = socket(AF_UNIX/AF_LOCAL, SOCK_STREAM, 0);
2. 监听的套接字绑定本地的套接字文件 -> server端
struct sockaddr_un addr;
// 绑定成功之后,指定的sun_path中的套接字文件会自动生成。
bind(lfd, addr, len);
3. 监听
listen(lfd, 100);
4. 等待并接受连接请求
struct sockaddr_un cliaddr;
int cfd = accept(lfd, &cliaddr, len);
5. 通信
接收数据:read/recv
发送数据:write/send
6. 关闭连接
close();
// 客户端的流程
1. 创建通信的套接字
int fd = socket(AF_UNIX/AF_LOCAL, SOCK_STREAM, 0);
2. 监听的套接字绑定本地套接字文件 -> client端
struct sockaddr_un addr;
// 绑定成功之后,指定的sun_path中的套接字文件会自动生成。
bind(lfd, addr, len);
3. 连接服务器
struct sockaddr_un serveraddr;
connect(fd, &serveraddr, sizeof(serveraddr));
4. 通信
接收数据:read/recv
发送数据:write/send
5. 关闭连接
close();
webserver 开发
网络 io 分两个阶段:数据就绪 和 数据读写
数据就绪:阻塞,非阻塞。发生在操作系统中的 TCP缓冲区
阻塞会直到有数据就绪或者说有数据可以进行读写了,才会进行下一步 数据读写;没有数据可读写时会进入阻塞状态。
而非阻塞不管有无数据可以读写都会继续执行,所以我们需要每次对非阻塞io调用的进行判断,读取失败则退出程序;读取到数据则进行读写操作;读取到0则意味着另一方关闭连接。
数据读写:同步,异步。看是否需要自己去处理。自己处理为同步,系统处理好了通知你为异步。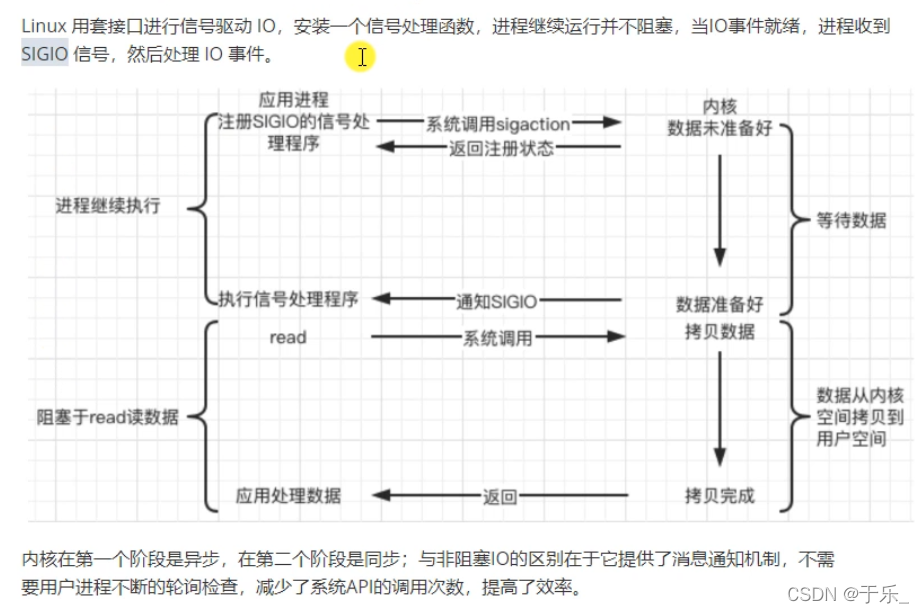
同步是指应用程序需要自己去操作数据,从 TCP缓冲区读取数据到应用程序提供的 buf中,写是从应用程序提供的 buf中写到 TCP缓冲区;异步是把要读写的数据相关的文件描述符、缓冲区、信号发给操作系统,有内核进行数据的读写。
一个典型的网络 io接口调用,分为两个阶段,分别是“数据就绪”和“数据读写”
数据就绪分为阻塞和非阻塞,是根据有无数据就绪时状态是否变为阻塞状态区分的,表现结果是阻塞当前进程/线程 还是 直接返回。阻塞会在没有数据可读可写时,阻塞当前进程/线程,直到有数据可以读写为止;而非阻塞则不论有无数据可读写,都会继续执行,所以需要根据返回值来判断是否读写数据:返回值>0 则有数据就绪,接下来可以进行数据读写操作;否则不可以,==0为另一端关闭,= =-1为错误。
同步异步是根据数据的读写操作是请求方自己来完成还是由内核来完成。同步表示 A向B请求调用一个网络 io接口时,数据读写是由请求方A 自己来完成的。异步则是 A向B 传入请求的事件以及事件发生时通知的方式,A继续去处理其他事务,当 B监听到事件处理完成后,用事先约定好的通知方式 通知A处理结果。
Unix/Linux 上的五种 io模型
1. 阻塞 blocking
阻塞不是函数本身是阻塞的,而是操作的文件描述符是阻塞的,所以 read() 时默认没有数据可读时阻塞等待,直到有数据就绪可以读取;然后才会进行数据读写,将数据从内核空间拷贝到用户空间的应用程序中。

2. 非阻塞 non-blocking
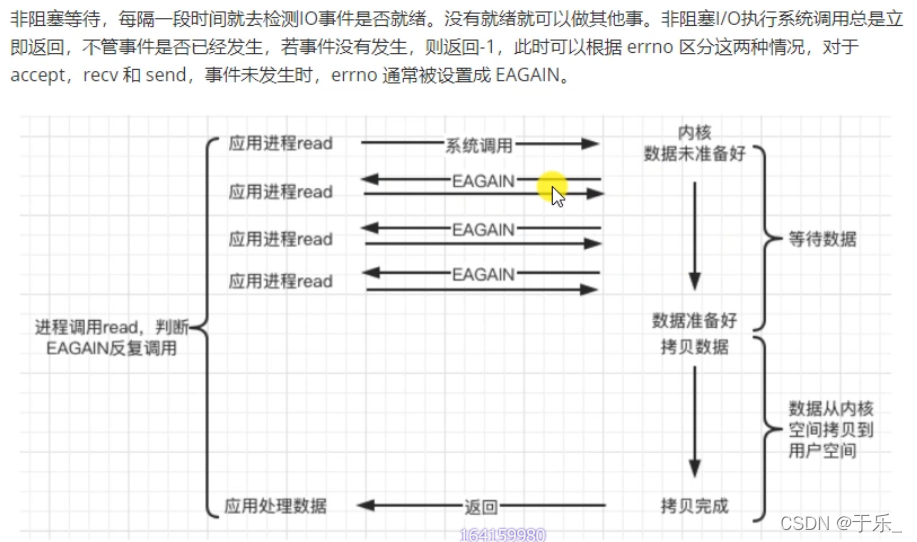
3. io多路复用 io-multiplexing
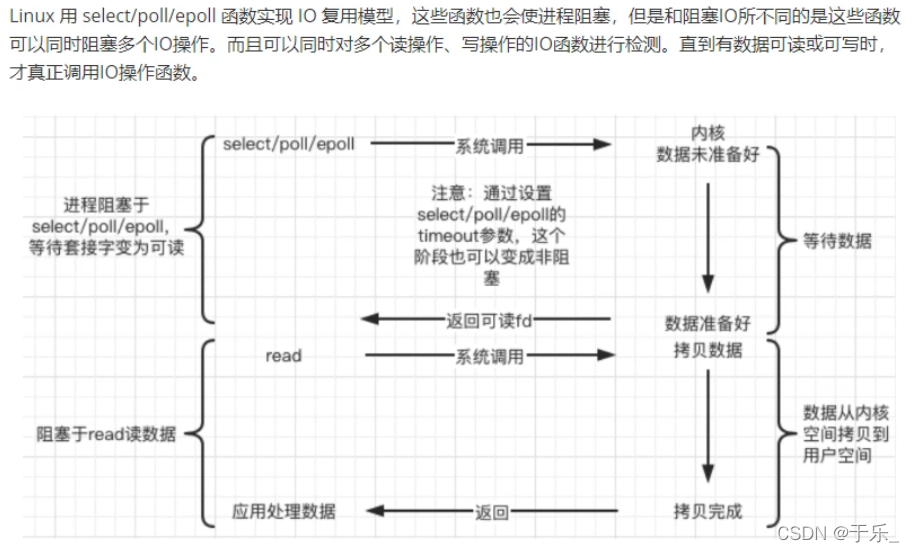
在单进程 单线程的模式下,阻塞非阻塞都是在同一时刻只能检测一个事件;而 io多路复用技术 可以在单进程或单线程下 实现同一时刻检测若干个客户的事件是否发生。
并不是处理高并发的,高并发是靠多进程多线程实现的;它是使得一个进程或线程可以同时检测多个客户端的事件的发生与否,处理的是一个服务器和多个客户端间的连接请求和通信操作。
4. 信号驱动 signal-driven
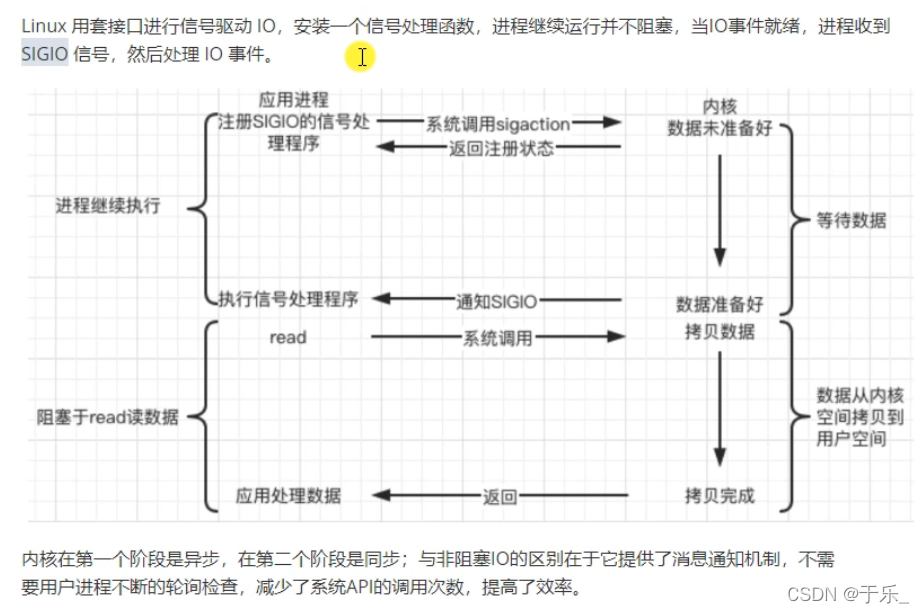
5. 异步 asynchronous
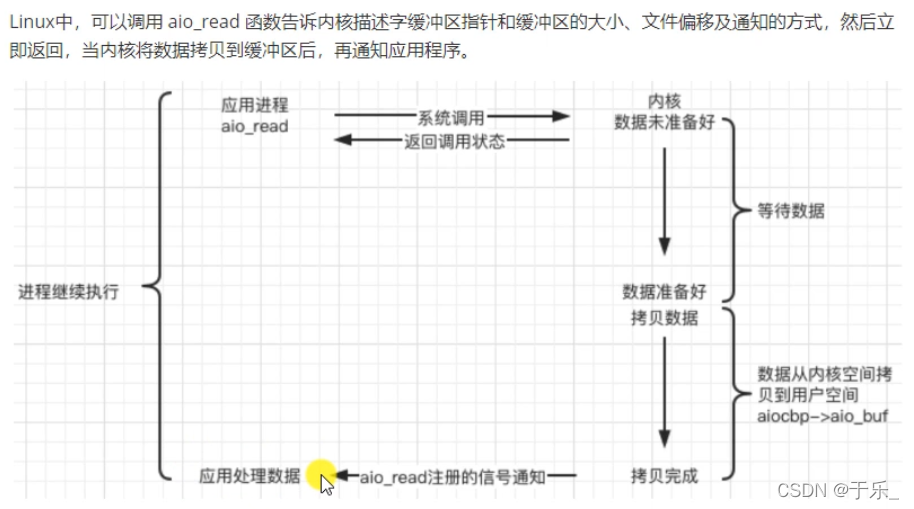
web server 和 client 的通信过程
在浏览器中键入 域名 或 IP地址:端口号
浏览器先将域名解析成相应的 IP地址或者 直接根据输入的IP地址及端口号,向对应的 web 服务器发送一个 HTTP请求
请求的过程:先通过 tcp协议 的三次握手与目标 web服务器 建立连接;然后 HTTP协议生成针对目标 web服务器的 HTTP请求报文;通过 TCP IP等协议发送到目标 web服务器上。
HTTP协议 (应用层协议)
上层协议会用到下层的协议,我们现实开发并没有用到 osi七层结构模型,而是 tcp/ip 四层模型。从下往上依次是 网际接口层 网络层 传输层 应用层。不同的应用会有不同的应用层协议,比如 web浏览器 用到的应用层协议是 HTTP协议,其实现会用到下层的 TCP、IP协议。
HTTP协议 采用的是 请求-响应模型。
- 客户端向服务器发送一个请求报文,请求报文中包含请求的 方法、url、协议版本、请求头部、请求数据。
- 服务器以一个状态行作为响应,响应的内容包括协议版本、成功/失败错误代码、服务器信息、响应头部、响应数据。
智能推荐
874计算机科学基础综合,2018年四川大学874计算机科学专业基础综合之计算机操作系统考研仿真模拟五套题...-程序员宅基地
文章浏览阅读1.1k次。一、选择题1. 串行接口是指( )。A. 接口与系统总线之间串行传送,接口与I/0设备之间串行传送B. 接口与系统总线之间串行传送,接口与1/0设备之间并行传送C. 接口与系统总线之间并行传送,接口与I/0设备之间串行传送D. 接口与系统总线之间并行传送,接口与I/0设备之间并行传送【答案】C2. 最容易造成很多小碎片的可变分区分配算法是( )。A. 首次适应算法B. 最佳适应算法..._874 计算机科学专业基础综合题型
XShell连接失败:Could not connect to '192.168.191.128' (port 22): Connection failed._could not connect to '192.168.17.128' (port 22): c-程序员宅基地
文章浏览阅读9.7k次,点赞5次,收藏15次。连接xshell失败,报错如下图,怎么解决呢。1、通过ps -e|grep ssh命令判断是否安装ssh服务2、如果只有客户端安装了,服务器没有安装,则需要安装ssh服务器,命令:apt-get install openssh-server3、安装成功之后,启动ssh服务,命令:/etc/init.d/ssh start4、通过ps -e|grep ssh命令再次判断是否正确启动..._could not connect to '192.168.17.128' (port 22): connection failed.
杰理之KeyPage【篇】_杰理 空白芯片 烧入key文件-程序员宅基地
文章浏览阅读209次。00000000_杰理 空白芯片 烧入key文件
一文读懂ChatGPT,满足你对chatGPT的好奇心_引发对chatgpt兴趣的表述-程序员宅基地
文章浏览阅读475次。2023年初,“ChatGPT”一词在社交媒体上引起了热议,人们纷纷探讨它的本质和对社会的影响。就连央视新闻也对此进行了报道。作为新传专业的前沿人士,我们当然不能忽视这一热点。本文将全面解析ChatGPT,打开“技术黑箱”,探讨它对新闻与传播领域的影响。_引发对chatgpt兴趣的表述
中文字符频率统计python_用Python数据分析方法进行汉字声调频率统计分析-程序员宅基地
文章浏览阅读259次。用Python数据分析方法进行汉字声调频率统计分析木合塔尔·沙地克;布合力齐姑丽·瓦斯力【期刊名称】《电脑知识与技术》【年(卷),期】2017(013)035【摘要】该文首先用Python程序,自动获取基本汉字字符集中的所有汉字,然后用汉字拼音转换工具pypinyin把所有汉字转换成拼音,最后根据所有汉字的拼音声调,统计并可视化拼音声调的占比.【总页数】2页(13-14)【关键词】数据分析;数据可..._汉字声调频率统计
linux输出信息调试信息重定向-程序员宅基地
文章浏览阅读64次。最近在做一个android系统移植的项目,所使用的开发板com1是调试串口,就是说会有uboot和kernel的调试信息打印在com1上(ttySAC0)。因为后期要使用ttySAC0作为上层应用通信串口,所以要把所有的调试信息都给去掉。参考网上的几篇文章,自己做了如下修改,终于把调试信息重定向到ttySAC1上了,在这做下记录。参考文章有:http://blog.csdn.net/longt..._嵌入式rootfs 输出重定向到/dev/console
随便推点
uniapp 引入iconfont图标库彩色symbol教程_uniapp symbol图标-程序员宅基地
文章浏览阅读1.2k次,点赞4次,收藏12次。1,先去iconfont登录,然后选择图标加入购物车 2,点击又上角车车添加进入项目我的项目中就会出现选择的图标 3,点击下载至本地,然后解压文件夹,然后切换到uniapp打开终端运行注:要保证自己电脑有安装node(没有安装node可以去官网下载Node.js 中文网)npm i -g iconfont-tools(mac用户失败的话在前面加个sudo,password就是自己的开机密码吧)4,终端切换到上面解压的文件夹里面,运行iconfont-tools 这些可以默认也可以自己命名(我是自己命名的_uniapp symbol图标
C、C++ 对于char*和char[]的理解_c++ char*-程序员宅基地
文章浏览阅读1.2w次,点赞25次,收藏192次。char*和char[]都是指针,指向第一个字符所在的地址,但char*是常量的指针,char[]是指针的常量_c++ char*
Sublime Text2 使用教程-程序员宅基地
文章浏览阅读930次。代码编辑器或者文本编辑器,对于程序员来说,就像剑与战士一样,谁都想拥有一把可以随心驾驭且锋利无比的宝剑,而每一位程序员,同样会去追求最适合自己的强大、灵活的编辑器,相信你和我一样,都不会例外。我用过的编辑器不少,真不少~ 但却没有哪款让我特别心仪的,直到我遇到了 Sublime Text 2 !如果说“神器”是我能给予一款软件最高的评价,那么我很乐意为它封上这么一个称号。它小巧绿色且速度非
对10个整数进行按照从小到大的顺序排序用选择法和冒泡排序_对十个数进行大小排序java-程序员宅基地
文章浏览阅读4.1k次。一、选择法这是每一个数出来跟后面所有的进行比较。2.冒泡排序法,是两个相邻的进行对比。_对十个数进行大小排序java
物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)_网络调试助手连接阿里云连不上-程序员宅基地
文章浏览阅读2.9k次。物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)其实作者本意是使用4G模块来实现与阿里云物联网平台的连接过程,但是由于自己用的4G模块自身的限制,使得阿里云连接总是无法建立,已经联系客服返厂检修了,于是我在此使用网络调试助手来演示如何与阿里云物联网平台建立连接。一.准备工作1.MQTT协议说明文档(3.1.1版本)2.网络调试助手(可使用域名与服务器建立连接)PS:与阿里云建立连解释,最好使用域名来完成连接过程,而不是使用IP号。这里我跟阿里云的售后工程师咨询过,表示对应_网络调试助手连接阿里云连不上
<<<零基础C++速成>>>_无c语言基础c++期末速成-程序员宅基地
文章浏览阅读544次,点赞5次,收藏6次。运算符与表达式任何高级程序设计语言中,表达式都是最基本的组成部分,可以说C++中的大部分语句都是由表达式构成的。_无c语言基础c++期末速成