四、新图片、新视频预测(Datawhale组队学习)-程序员宅基地
文章目录
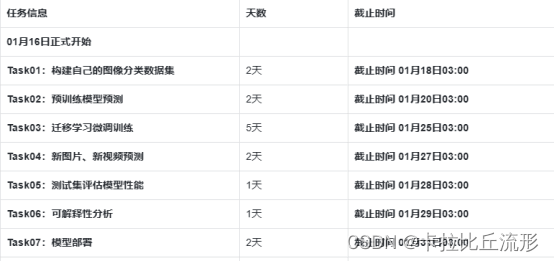
【教程地址】
同济子豪兄教学视频:https://space.bilibili.com/1900783/channel/collectiondetail?sid=606800
项目代码:https://github.com/TommyZihao/Train_Custom_Dataset
配置环境
# 下载安装依赖包
pip install numpy pandas matplotlib requests tqdm opencv-python pillow
# 下载安装Pytorch
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
# 安装mmcv -full
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10.0/index.html
创建目录
# 存放测试图片
os.mkdir('test_img')
# 存放结果文件
os.mkdir('output')
# 存放训练得到的模型权重
os.mkdir('checkpoints')
下载在三、利用迁移学习进行模型微调(Datawhale组队学习)得到的模型文件fruit30_pytorch_20230123.pth和“类别名称和ID索引号”的映射字典文件idx_to_labels.npy,如果没有也可以通过以下方式进行下载。最后下载一些图片和视频的测试文件存放在test_img文件夹中
# 下载样例模型文件
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/checkpoints/fruit30_pytorch_20220814.pth -P checkpoints
# 下载 类别名称 和 ID索引号 的映射字典
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/fruit30/idx_to_labels.npy
# 下载测试图像文件 至 test_img 文件夹
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_fruits.jpg -P test_img
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_orange_2.jpg -P test_img
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_bananan.jpg -P test_img
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_kiwi.jpg -P test_img
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_石榴.jpg -P test_img
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_orange.jpg -P test_img
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_lemon.jpg -P test_img
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/test_火龙果.jpg -P test_img
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/test/watermelon1.jpg -P test_img
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/test/banana1.jpg -P test_img
# 下载测试视频文件 至 test_img 文件夹
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220716-mmclassification/test/0818/fruits_video.mp4 -P test_img
设置中文字体正常显示并测试一下
import matplotlib.pyplot as plt
%matplotlib inline
# windows操作系统
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
plt.plot([1,2,3], [100,500,300])
plt.title('matplotlib中文字体测试', fontsize=25)
plt.xlabel('X轴', fontsize=15)
plt.ylabel('Y轴', fontsize=15)
plt.show()

预测新图像
导入所需的工具包,并设置中文字体
import torch
import torchvision
import torch.nn.functional as F
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# windows操作系统设置中文字体
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
#导入pillow中文字体
from PIL import Image, ImageFont, ImageDraw
# 导入中文字体,指定字号
font = ImageFont.truetype('SimHei.ttf', 32)
载入图像并进行预处理
载入类别
idx_to_labels = np.load('idx_to_labels.npy', allow_pickle=True).item()
print(idx_to_labels)
{0: ‘哈密瓜’, 1: ‘圣女果’, 2: ‘山竹’, 3: ‘杨梅’, 4: ‘柚子’, 5: ‘柠檬’, 6: ‘桂圆’, 7: ‘梨’, 8: ‘椰子’, 9: ‘榴莲’, 10: ‘火龙果’, 11: ‘猕猴桃’, 12: ‘石榴’, 13: ‘砂糖橘’, 14: ‘胡萝卜’, 15: ‘脐橙’, 16: ‘芒果’, 17: ‘苦瓜’, 18: ‘苹果-红’, 19: ‘苹果-青’, 20: ‘草莓’, 21: ‘荔枝’, 22: ‘菠萝’, 23: ‘葡萄-白’, 24: ‘葡萄-红’, 25: ‘西瓜’, 26: ‘西红柿’, 27: ‘车厘子’, 28: ‘香蕉’, 29: ‘黄瓜’}
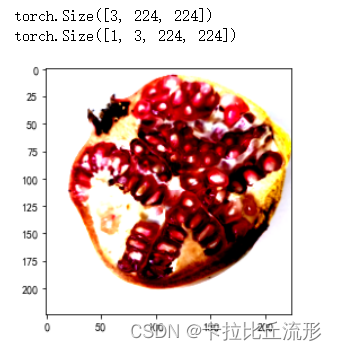
载入一张测试图片并对图片进行预处理
from PIL import Image
img_path = 'test_img/test_石榴.jpg'
img_pil = Image.open(img_path)
input_img = test_transform(img_pil) # 预处理
print(input_img.shape)
images = input_img.numpy()
plt.imshow(images.transpose((1,2,0))) # 转为(224, 224, 3)
input_img = input_img.unsqueeze(0).to(device)
print(input_img.shape)
导入训练好的模型
这里要注意训练的模型是用CPU版本训练得到的,而现在用GPU版本导入可能会报错,大家一定要注意版本的统一
model = torch.load('checkpoints/fruit30_pytorch_20230123.pth')
model = model.eval().to(device)#调成评估状态并加入到计算设备里面
前向预测
得到预测为各个类别的概率
# 执行前向预测,得到所有类别的 logit 预测分数
pred_logits = model(input_img)
# 对 logit 分数做 softmax 运算
pred_softmax = F.softmax(pred_logits, dim=1)
tensor([[1.5778e-07, 2.4981e-05, 2.5326e-05, 3.8147e-05, 6.1754e-05, 3.5412e-07,
3.0071e-07, 2.2314e-08, 6.2592e-07, 3.9356e-09, 5.2626e-06, 2.3320e-08,
9.9664e-01, 1.9379e-07, 3.9359e-08, 3.8175e-08, 4.4834e-06, 8.2782e-07,
1.9294e-04, 2.3078e-08, 2.7421e-04, 3.1726e-04, 1.0331e-05, 2.2196e-08,
5.5011e-04, 6.8984e-05, 1.5381e-04, 1.6270e-03, 6.9369e-07, 1.3640e-08]],
grad_fn=)
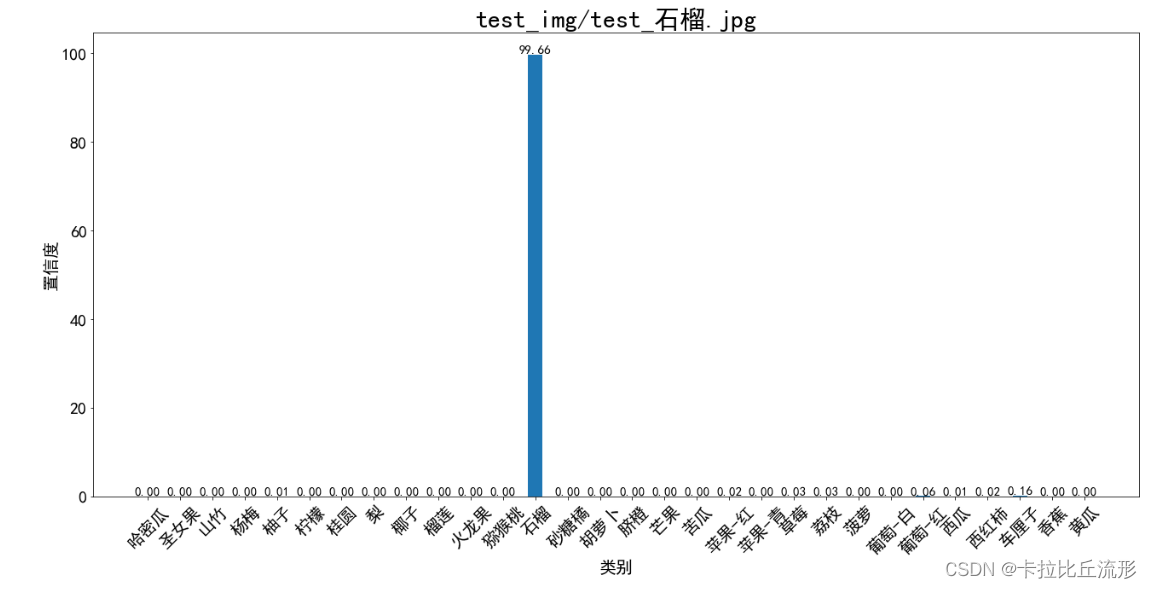
对预测结果进行可视化
plt.figure(figsize=(22, 10))
x = idx_to_labels.values()
y = pred_softmax.cpu().detach().numpy()[0] * 100
width = 0.45 # 柱状图宽度
ax = plt.bar(x, y, width)
plt.bar_label(ax, fmt='%.2f', fontsize=15) # 置信度数值
plt.tick_params(labelsize=20) # 设置坐标文字大小
plt.title(img_path, fontsize=30)
plt.xticks(rotation=45) # 横轴文字旋转
plt.xlabel('类别', fontsize=20)
plt.ylabel('置信度', fontsize=20)
plt.show()
将分类结果写入原图中
得到置信度最大的前10个结果
n = 10
top_n = torch.topk(pred_softmax, n) # 取置信度最大的 n 个结果
pred_ids = top_n[1].cpu().detach().numpy().squeeze() # 解析出类别
confs = top_n[0].cpu().detach().numpy().squeeze() # 解析出置信度
print(pred_ids)
print(confs)
[12 27 24 21 20 18 26 25 4 3]
[9.9664199e-01 1.6270019e-03 5.5011164e-04 3.1726481e-04 2.7420817e-04
1.9294333e-04 1.5380539e-04 6.8983565e-05 6.1754021e-05 3.8146878e-05]
将分类结果写在原图上
draw = ImageDraw.Draw(img_pil)
for i in range(n):
class_name = idx_to_labels[pred_ids[i]] # 获取类别名称
confidence = confs[i] * 100 # 获取置信度
text = '{:<15} {:>.4f}'.format(class_name, confidence)
print(text)
# 文字坐标,中文字符串,字体,rgba颜色
draw.text((50, 100 + 50 * i), text, font=font, fill=(255, 0, 0, 1))
img_pil
石榴 99.6642
车厘子 0.1627
葡萄-红 0.0550
荔枝 0.0317
草莓 0.0274
苹果-红 0.0193
西红柿 0.0154
西瓜 0.0069
柚子 0.0062
杨梅 0.0038
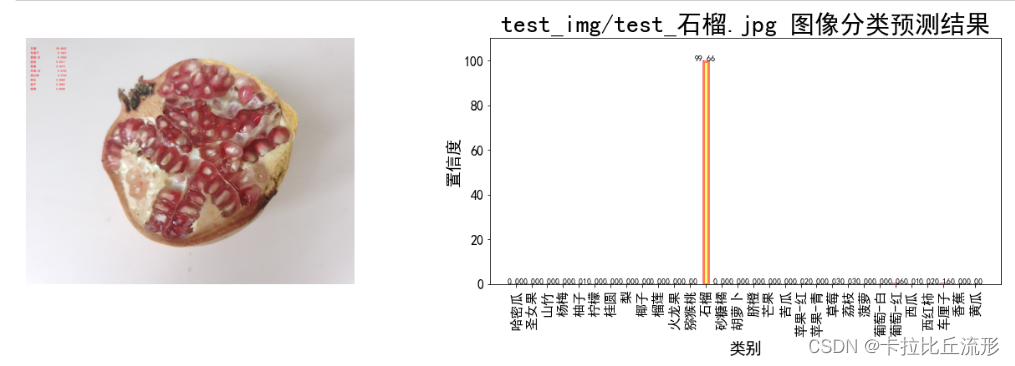
预测结果图和分类柱状图

fig = plt.figure(figsize=(18,6))
# 绘制左图-预测图
ax1 = plt.subplot(1,2,1)
ax1.imshow(img_pil)
ax1.axis('off')
# 绘制右图-柱状图
ax2 = plt.subplot(1,2,2)
x = idx_to_labels.values()
y = pred_softmax.cpu().detach().numpy()[0] * 100
ax2.bar(x, y, alpha=0.5, width=0.3, color='yellow', edgecolor='red', lw=3)
plt.bar_label(ax, fmt='%.2f', fontsize=10) # 置信度数值
plt.title('{} 图像分类预测结果'.format(img_path), fontsize=30)
plt.xlabel('类别', fontsize=20)
plt.ylabel('置信度', fontsize=20)
plt.ylim([0, 110]) # y轴取值范围
ax2.tick_params(labelsize=16) # 坐标文字大小
plt.xticks(rotation=90) # 横轴文字旋转
plt.tight_layout()
fig.savefig('output/预测图+柱状图.jpg')
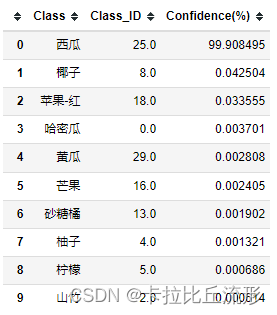
将预测结果以表格形式输出
pred_df = pd.DataFrame() # 预测结果表格
for i in range(n):
class_name = idx_to_labels[pred_ids[i]] # 获取类别名称
label_idx = int(pred_ids[i]) # 获取类别号
confidence = confs[i] * 100 # 获取置信度
pred_df = pred_df.append({
'Class':class_name, 'Class_ID':label_idx, 'Confidence(%)':confidence}, ignore_index=True) # 预测结果表格添加一行
display(pred_df) # 展示预测结果表格
预测新视频
import os
import time
import shutil
import tempfile
from tqdm import tqdm
import cv2
from PIL import Image
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
import gc
import torch
import torch.nn.functional as F
from torchvision import models
import mmcv
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device:', device)
# 后端绘图,不显示,只保存
import matplotlib
matplotlib.use('Agg')
# windows操作系统
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
from PIL import ImageFont, ImageDraw
# 导入中文字体,指定字号
font = ImageFont.truetype('SimHei.ttf', 32)
导入训练好的模型
model = torch.load('checkpoints/fruit30_pytorch_20230123.pth')
model = model.eval().to(device)
视频预测
输入输出视频路径
input_video = 'test_img/fruits_video.mp4'
# 创建临时文件夹,存放每帧结果
temp_out_dir = time.strftime('%Y%m%d%H%M%S')
os.mkdir(temp_out_dir)
print('创建临时文件夹 {} 用于存放每帧预测结果'.format(temp_out_dir))
载入类别
idx_to_labels = np.load('idx_to_labels.npy', allow_pickle=True).item()
图像预处理
from torchvision import transforms
# 测试集图像预处理-RCTN:缩放裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
单帧图像分类预测
图像分类预测函数
def pred_single_frame(img, n=5):
'''
输入摄像头画面bgr-array,输出前n个图像分类预测结果的图像bgr-array
'''
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR 转 RGB
img_pil = Image.fromarray(img_rgb) # array 转 pil
input_img = test_transform(img_pil).unsqueeze(0).to(device) # 预处理
pred_logits = model(input_img) # 执行前向预测,得到所有类别的 logit 预测分数
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
top_n = torch.topk(pred_softmax, n) # 取置信度最大的 n 个结果
pred_ids = top_n[1].cpu().detach().numpy().squeeze() # 解析出类别
confs = top_n[0].cpu().detach().numpy().squeeze() # 解析出置信度
# 在图像上写字
draw = ImageDraw.Draw(img_pil)
# 在图像上写字
for i in range(len(confs)):
pred_class = idx_to_labels[pred_ids[i]]
text = '{:<15} {:>.3f}'.format(pred_class, confs[i])
# 文字坐标,中文字符串,字体,rgba颜色
draw.text((50, 100 + 50 * i), text, font=font, fill=(255, 0, 0, 1))
img_bgr = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR) # RGB转BGR
return img_bgr, pred_softmax
可视化方案一:原始图像+预测结果文字
# 读入待预测视频
imgs = mmcv.VideoReader(input_video)
prog_bar = mmcv.ProgressBar(len(imgs))
# 对视频逐帧处理
for frame_id, img in enumerate(imgs):
## 处理单帧画面
img, pred_softmax = pred_single_frame(img, n=5)
# 将处理后的该帧画面图像文件,保存至 /tmp 目录下
cv2.imwrite(f'{
temp_out_dir}/{
frame_id:06d}.jpg', img)
prog_bar.update() # 更新进度条
# 把每一帧串成视频文件
mmcv.frames2video(temp_out_dir, 'output/output_pred.mp4', fps=imgs.fps, fourcc='mp4v')
shutil.rmtree(temp_out_dir) # 删除存放每帧画面的临时文件夹
print('删除临时文件夹', temp_out_dir)

可视化方案二:原始图像+预测结果文字+各类别置信度柱状图
def pred_single_frame_bar(img):
'''
输入pred_single_frame函数输出的bgr-array,加柱状图,保存
'''
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR 转 RGB
fig = plt.figure(figsize=(18,6))
# 绘制左图-视频图
ax1 = plt.subplot(1,2,1)
ax1.imshow(img)
ax1.axis('off')
# 绘制右图-柱状图
ax2 = plt.subplot(1,2,2)
x = idx_to_labels.values()
y = pred_softmax.cpu().detach().numpy()[0] * 100
ax2.bar(x, y, alpha=0.5, width=0.3, color='yellow', edgecolor='red', lw=3)
plt.xlabel('类别', fontsize=20)
plt.ylabel('置信度', fontsize=20)
ax2.tick_params(labelsize=16) # 坐标文字大小
plt.ylim([0, 100]) # y轴取值范围
plt.xlabel('类别',fontsize=25)
plt.ylabel('置信度',fontsize=25)
plt.title('图像分类预测结果', fontsize=30)
plt.xticks(rotation=90) # 横轴文字旋转
plt.tight_layout()
fig.savefig(f'{
temp_out_dir}/{
frame_id:06d}.jpg')
# 释放内存
fig.clf()
plt.close()
gc.collect()
# 读入待预测视频
imgs = mmcv.VideoReader(input_video)
prog_bar = mmcv.ProgressBar(len(imgs))
# 对视频逐帧处理
for frame_id, img in enumerate(imgs):
## 处理单帧画面
img, pred_softmax = pred_single_frame(img, n=5)
img = pred_single_frame_bar(img)
prog_bar.update() # 更新进度条
# 把每一帧串成视频文件
mmcv.frames2video(temp_out_dir, 'output/output_bar.mp4', fps=imgs.fps, fourcc='mp4v')
shutil.rmtree(temp_out_dir) # 删除存放每帧画面的临时文件夹
print('删除临时文件夹', temp_out_dir)
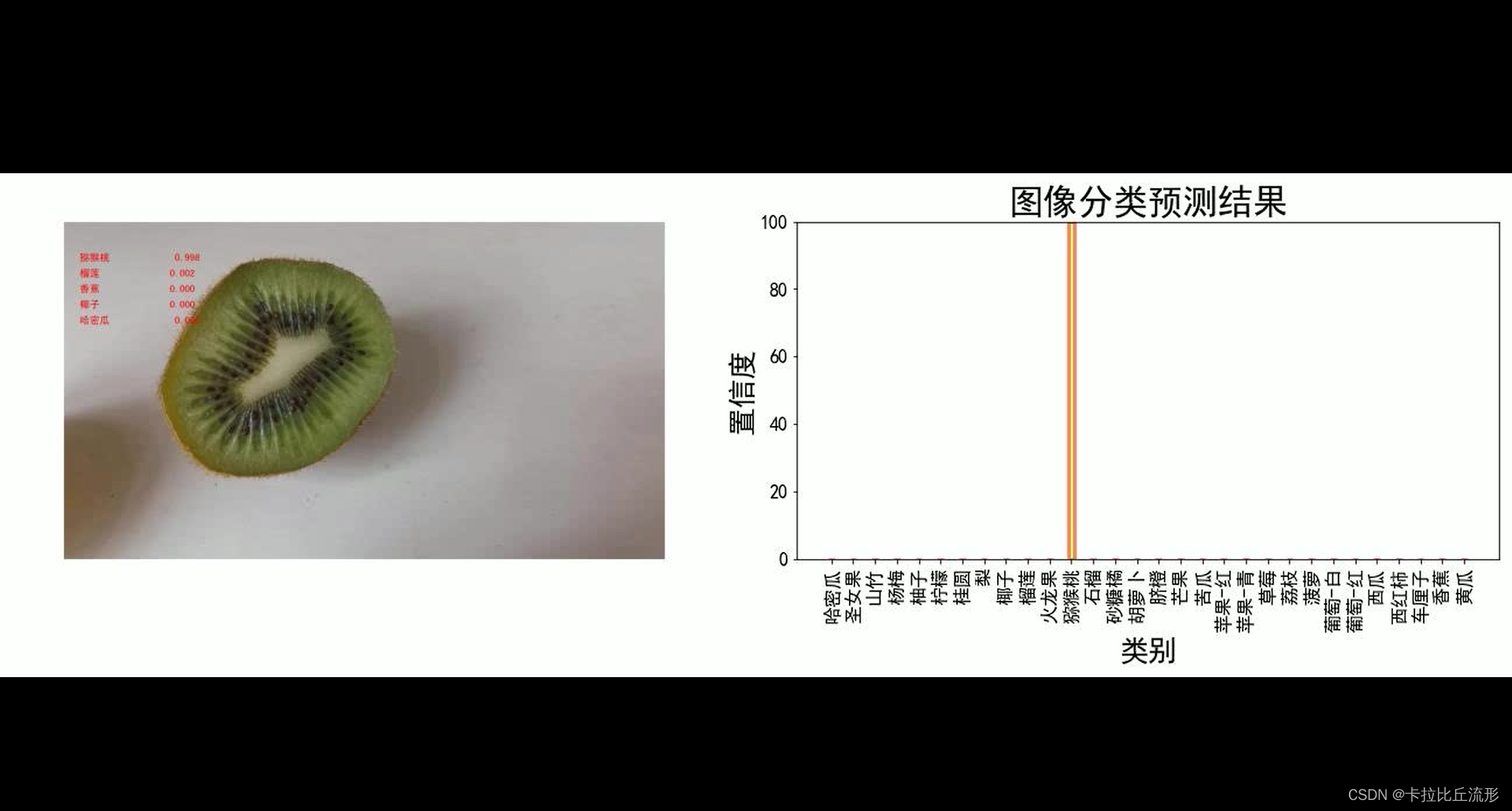
预测摄像头实时画面
导入依赖工具包
import os
import numpy as np
import pandas as pd
import cv2 # opencv-python
from PIL import Image, ImageFont, ImageDraw
from tqdm import tqdm # 进度条
import matplotlib.pyplot as plt
%matplotlib inline
import torch
import torch.nn.functional as F
from torchvision import models
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device:', device)
导入中文字体,指定字号
font = ImageFont.truetype('SimHei.ttf', 32)
载入类别
idx_to_labels = np.load('idx_to_labels.npy', allow_pickle=True).item()
{0: ‘哈密瓜’, 1: ‘圣女果’, 2: ‘山竹’, 3: ‘杨梅’, 4: ‘柚子’, 5: ‘柠檬’, 6: ‘桂圆’, 7: ‘梨’, 8: ‘椰子’, 9: ‘榴莲’, 10: ‘火龙果’, 11: ‘猕猴桃’, 12: ‘石榴’, 13: ‘砂糖橘’, 14: ‘胡萝卜’, 15: ‘脐橙’, 16: ‘芒果’, 17: ‘苦瓜’, 18: ‘苹果-红’, 19: ‘苹果-青’, 20: ‘草莓’, 21: ‘荔枝’, 22: ‘菠萝’, 23: ‘葡萄-白’, 24: ‘葡萄-红’, 25: ‘西瓜’, 26: ‘西红柿’, 27: ‘车厘子’, 28: ‘香蕉’, 29: ‘黄瓜’}
图像预处理
from torchvision import transforms
# 测试集图像预处理-RCTN:缩放裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
导入训练好的模型
model = torch.load('checkpoints/fruit30_pytorch_20230123.pth', map_location=torch.device('cpu'))
model = model.eval().to(device)
对一帧画面进行预测
获取摄像头的一帧画面
# 导入opencv-python
import cv2
import time
# 获取摄像头,传入0表示获取系统默认摄像头
cap = cv2.VideoCapture(1)
# 打开cap
cap.open(0)
time.sleep(1)
success, img_bgr = cap.read()
# 关闭摄像头
cap.release()
# 关闭图像窗口
cv2.destroyAllWindows()
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) # BGR转RGB
img_pil = Image.fromarray(img_rgb)
img_pil

对画面进行预测
input_img = test_transform(img_pil).unsqueeze(0).to(device) # 预处理
pred_logits = model(input_img) # 执行前向预测,得到所有类别的 logit 预测分数
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
n = 5
top_n = torch.topk(pred_softmax, n) # 取置信度最大的 n 个结果
pred_ids = top_n[1].cpu().detach().numpy().squeeze() # 解析出类别
confs = top_n[0].cpu().detach().numpy().squeeze() # 解析出置信度
draw = ImageDraw.Draw(img_pil)
# 在图像上写字
for i in range(len(confs)):
pred_class = idx_to_labels[pred_ids[i]]
text = '{:<15} {:>.3f}'.format(pred_class, confs[i])
# 文字坐标,中文字符串,字体,rgba颜色
draw.text((50, 100 + 50 * i), text, font=font, fill=(255, 0, 0, 1))
img = np.array(img_pil) # PIL 转 array
plt.imshow(img)
plt.show()

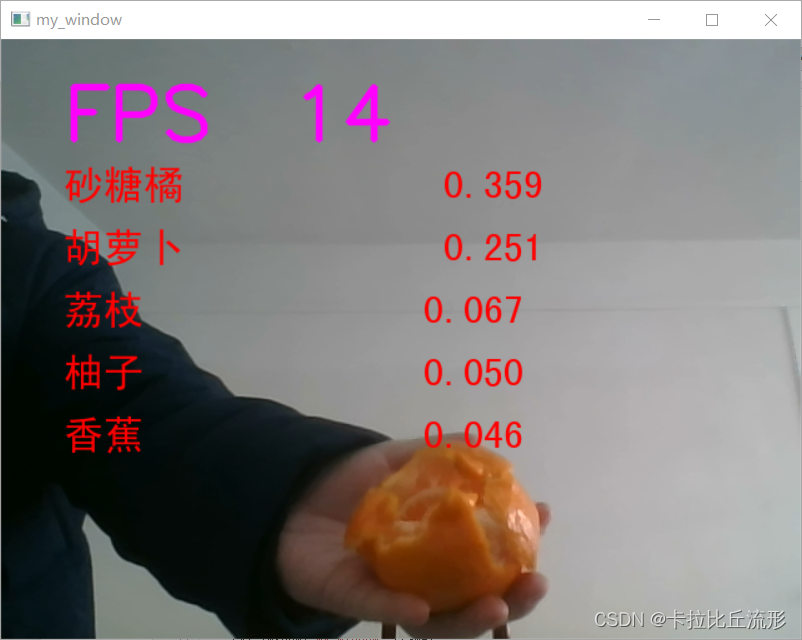
实时画面预测
处理单帧画面的函数
# 处理帧函数
def process_frame(img):
# 记录该帧开始处理的时间
start_time = time.time()
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR转RGB
img_pil = Image.fromarray(img_rgb) # array 转 PIL
input_img = test_transform(img_pil).unsqueeze(0).to(device) # 预处理
pred_logits = model(input_img) # 执行前向预测,得到所有类别的 logit 预测分数
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
top_n = torch.topk(pred_softmax, 5) # 取置信度最大的 n 个结果
pred_ids = top_n[1].cpu().detach().numpy().squeeze() # 解析预测类别
confs = top_n[0].cpu().detach().numpy().squeeze() # 解析置信度
# 使用PIL绘制中文
draw = ImageDraw.Draw(img_pil)
# 在图像上写字
for i in range(len(confs)):
pred_class = idx_to_labels[pred_ids[i]]
text = '{:<15} {:>.3f}'.format(pred_class, confs[i])
# 文字坐标,中文字符串,字体,bgra颜色
draw.text((50, 100 + 50 * i), text, font=font, fill=(255, 0, 0, 1))
img = np.array(img_pil) # PIL 转 array
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) # RGB转BGR
# 记录该帧处理完毕的时间
end_time = time.time()
# 计算每秒处理图像帧数FPS
FPS = 1/(end_time - start_time)
# 图片,添加的文字,左上角坐标,字体,字体大小,颜色,线宽,线型
img = cv2.putText(img, 'FPS '+str(int(FPS)), (50, 80), cv2.FONT_HERSHEY_SIMPLEX, 2, (255, 0, 255), 4, cv2.LINE_AA)
return img
调用摄像头获取每帧
# 调用摄像头逐帧实时处理模板
# 不需修改任何代码,只需修改process_frame函数即可
# 同济子豪兄 2021-7-8
# 导入opencv-python
import cv2
import time
# 获取摄像头,传入0表示获取系统默认摄像头
cap = cv2.VideoCapture(1)
# 打开cap
cap.open(0)
# 无限循环,直到break被触发
while cap.isOpened():
# 获取画面
success, frame = cap.read()
if not success:
print('Error')
break
## !!!处理帧函数
frame = process_frame(frame)
# 展示处理后的三通道图像
cv2.imshow('my_window',frame)
if cv2.waitKey(1) in [ord('q'),27]: # 按键盘上的q或esc退出(在英文输入法下)
break
# 关闭摄像头
cap.release()
# 关闭图像窗口
cv2.destroyAllWindows()
总结
本篇文章主要讲述了如何利用上次三、利用迁移学习进行模型微调(Datawhale组队学习)得到的图像分类模型,分别在新的图像文件、新的视频文件和摄像头实时画面上进行预测。
!!!注意:如果之前的图像分类模型是在CPU上训练得到的,这里用GPU版的pytorch导入模型的时候可能会出错,大家一定要注意版本的统一。
智能推荐
什么是内部类?成员内部类、静态内部类、局部内部类和匿名内部类的区别及作用?_成员内部类和局部内部类的区别-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏42次。一、什么是内部类?or 内部类的概念内部类是定义在另一个类中的类;下面类TestB是类TestA的内部类。即内部类对象引用了实例化该内部对象的外围类对象。public class TestA{ class TestB {}}二、 为什么需要内部类?or 内部类有什么作用?1、 内部类方法可以访问该类定义所在的作用域中的数据,包括私有数据。2、内部类可以对同一个包中的其他类隐藏起来。3、 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。三、 内部类的分类成员内部_成员内部类和局部内部类的区别
分布式系统_分布式系统运维工具-程序员宅基地
文章浏览阅读118次。分布式系统要求拆分分布式思想的实质搭配要求分布式系统要求按照某些特定的规则将项目进行拆分。如果将一个项目的所有模板功能都写到一起,当某个模块出现问题时将直接导致整个服务器出现问题。拆分按照业务拆分为不同的服务器,有效的降低系统架构的耦合性在业务拆分的基础上可按照代码层级进行拆分(view、controller、service、pojo)分布式思想的实质分布式思想的实质是为了系统的..._分布式系统运维工具
用Exce分析l数据极简入门_exce l趋势分析数据量-程序员宅基地
文章浏览阅读174次。1.数据源准备2.数据处理step1:数据表处理应用函数:①VLOOKUP函数; ② CONCATENATE函数终表:step2:数据透视表统计分析(1) 透视表汇总不同渠道用户数, 金额(2)透视表汇总不同日期购买用户数,金额(3)透视表汇总不同用户购买订单数,金额step3:讲第二步结果可视化, 比如, 柱形图(1)不同渠道用户数, 金额(2)不同日期..._exce l趋势分析数据量
宁盾堡垒机双因素认证方案_horizon宁盾双因素配置-程序员宅基地
文章浏览阅读3.3k次。堡垒机可以为企业实现服务器、网络设备、数据库、安全设备等的集中管控和安全可靠运行,帮助IT运维人员提高工作效率。通俗来说,就是用来控制哪些人可以登录哪些资产(事先防范和事中控制),以及录像记录登录资产后做了什么事情(事后溯源)。由于堡垒机内部保存着企业所有的设备资产和权限关系,是企业内部信息安全的重要一环。但目前出现的以下问题产生了很大安全隐患:密码设置过于简单,容易被暴力破解;为方便记忆,设置统一的密码,一旦单点被破,极易引发全面危机。在单一的静态密码验证机制下,登录密码是堡垒机安全的唯一_horizon宁盾双因素配置
谷歌浏览器安装(Win、Linux、离线安装)_chrome linux debian离线安装依赖-程序员宅基地
文章浏览阅读7.7k次,点赞4次,收藏16次。Chrome作为一款挺不错的浏览器,其有着诸多的优良特性,并且支持跨平台。其支持(Windows、Linux、Mac OS X、BSD、Android),在绝大多数情况下,其的安装都很简单,但有时会由于网络原因,无法安装,所以在这里总结下Chrome的安装。Windows下的安装:在线安装:离线安装:Linux下的安装:在线安装:离线安装:..._chrome linux debian离线安装依赖
烤仔TVの尚书房 | 逃离北上广?不如押宝越南“北上广”-程序员宅基地
文章浏览阅读153次。中国发达城市榜单每天都在刷新,但无非是北上广轮流坐庄。北京拥有最顶尖的文化资源,上海是“摩登”的国际化大都市,广州是活力四射的千年商都。GDP和发展潜力是衡量城市的数字指...
随便推点
java spark的使用和配置_使用java调用spark注册进去的程序-程序员宅基地
文章浏览阅读3.3k次。前言spark在java使用比较少,多是scala的用法,我这里介绍一下我在项目中使用的代码配置详细算法的使用请点击我主页列表查看版本jar版本说明spark3.0.1scala2.12这个版本注意和spark版本对应,只是为了引jar包springboot版本2.3.2.RELEASEmaven<!-- spark --> <dependency> <gro_使用java调用spark注册进去的程序
汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用_uds协议栈 源代码-程序员宅基地
文章浏览阅读4.8k次。汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用,代码精简高效,大厂出品有量产保证。:139800617636213023darcy169_uds协议栈 源代码
AUTOSAR基础篇之OS(下)_autosar 定义了 5 种多核支持类型-程序员宅基地
文章浏览阅读4.6k次,点赞20次,收藏148次。AUTOSAR基础篇之OS(下)前言首先,请问大家几个小小的问题,你清楚:你知道多核OS在什么场景下使用吗?多核系统OS又是如何协同启动或者关闭的呢?AUTOSAR OS存在哪些功能安全等方面的要求呢?多核OS之间的启动关闭与单核相比又存在哪些异同呢?。。。。。。今天,我们来一起探索并回答这些问题。为了便于大家理解,以下是本文的主题大纲:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JCXrdI0k-1636287756923)(https://gite_autosar 定义了 5 种多核支持类型
VS报错无法打开自己写的头文件_vs2013打不开自己定义的头文件-程序员宅基地
文章浏览阅读2.2k次,点赞6次,收藏14次。原因:自己写的头文件没有被加入到方案的包含目录中去,无法被检索到,也就无法打开。将自己写的头文件都放入header files。然后在VS界面上,右键方案名,点击属性。将自己头文件夹的目录添加进去。_vs2013打不开自己定义的头文件
【Redis】Redis基础命令集详解_redis命令-程序员宅基地
文章浏览阅读3.3w次,点赞80次,收藏342次。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。当数据量很大时,count 的数量的指定可能会不起作用,Redis 会自动调整每次的遍历数目。_redis命令
URP渲染管线简介-程序员宅基地
文章浏览阅读449次,点赞3次,收藏3次。URP的设计目标是在保持高性能的同时,提供更多的渲染功能和自定义选项。与普通项目相比,会多出Presets文件夹,里面包含着一些设置,包括本色,声音,法线,贴图等设置。全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,主光源和附加光源在一次Pass中可以一起着色。URP:全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,一次Pass可以计算多个光源。可编程渲染管线:渲染策略是可以供程序员定制的,可以定制的有:光照计算和光源,深度测试,摄像机光照烘焙,后期处理策略等等。_urp渲染管线