机器学习应用——无监督学习(实例:31省市居民家庭消费调查&学生上网时间分布聚类&鸢尾花数据&人脸数据特征提取)_31个省份的聚类分析-程序员宅基地
技术标签: 聚类 Python——机器学习应用 python 机器学习 无监督学习 降维
前言
机器学习应用博客中,将核心介绍三大类学习,即:无监督学习、监督学习、强化学习。
本篇将简要介绍:
1.无监督学习概念(最常应用场景:聚类(clustering)和降维(Dimension Reduction))
2.聚类——kmeans方法(居民家庭消费调查)、DBSCAN方法(学生上网时间分布)
3.降维——PCA方法(鸢尾花数据)、NMF方法(人脸数据特征提取)
一、无监督学习简要介绍
1.目标&定义
(1)无监督学习:利用无标签的数据,学习数据的分布或数据与数据之间的关系被称作无监督学习
(2)有监督学习和无监督学习的最大区别在于数据是否有标签
(3)无监督学习最常应用的场景是聚类(clustering)和降维(Dimension Reduction)
2.聚类(clustering)
(1)聚类:根据数据的“相似性”将数据分为多类的过程
(2)评估两个不同样本之间的“相似性”,通常使用的方法就是计算两个样本之间的“距离”
(3)使用不同的方法计算样本间的距离会关系到聚类结果的好坏
(4)常用距离计算方法
①欧氏距离:最常用的一种距离度量方法,源于欧式空间中两点的距离
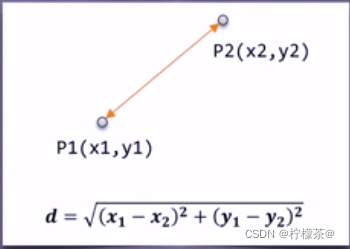
该图为二维空间中欧式距离的计算
②曼哈顿距离:称作“城市街区距离”,类似于在城市之中驾车行驶,从一个十字路口到另外一个十字楼口的距离。
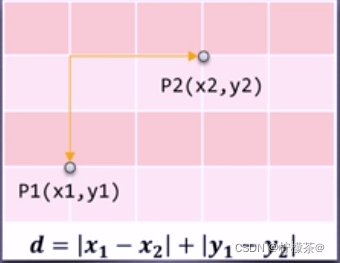
该图为二维空间中曼哈顿距离的计算
③马氏距离:表示数据的协方差距离,是一种尺度无关的度量方式。也就是说马氏距离会先将样本点的各个属性标准化,再计算样本间的距离。


其中,s是协方差矩阵
④余弦相似度:用向量空间中两个向量夹角的余弦值作为衡量两个样本差异的大小。余弦值越接近1,说明两个向量夹角越接近0度,表明两个向量越相似。

3.sklearn.cluster
(1)scikit-learn库(简称sklearn库)提供的常用聚类算法函数包含在sklearn.cluster这个模块中,如:K-Means,近邻传播算法,DBSCAN,等。
(2)注:以同样的数据集应用于不同的算法,可能会得到不同的结果,算法所耗费的时间也不尽相同,这是由算法的特性决定的。
(3)sklearn.cluster模块提供的各聚类算法函数可以使用不同的数据形式作为输入
①相似性矩阵输人格式:即由[样本数目]定义的矩阵形式,矩阵中的每一个元素为两个样本的相似度,如DBSCAN,AffinityPropagation(近邻传播算法)接受这种输人。
② 如果以余弦相似度为例,则对角线元素全为1。矩阵中每个元素的取值范围为[0,1]。
4.降维
(1)定义:在保证数据所具有的代表性特性或者分布的情况下,将高维数据转化为低维数据的过程。
(2)作用
①数据的可视化
②精简数据
(3)分类vs.降维
①聚类和分类都是无监督学习的典型任务,任务之间存在关联
②比如某些高纬数据的分类可以通过降维处理更好的获得
③另外学界研究也表明代表性的分类算法如k-means与降维算法如NMF之间存在等价性
(4)sklearn vs.降维
①降维是机器学习领域的一个重要研究内容,有很多被工业界和学术界接受的典型算法,截止到目前sklearn库提供7种降维算法。
②降维过程也可以被理解为对数据集的组成成份进行分解(decomposition)的过程,因此sklearn为降维模块命名为decomposition,在对降维算法调用需要使用sklearn.decomposition模块。
③几个常用降维算法
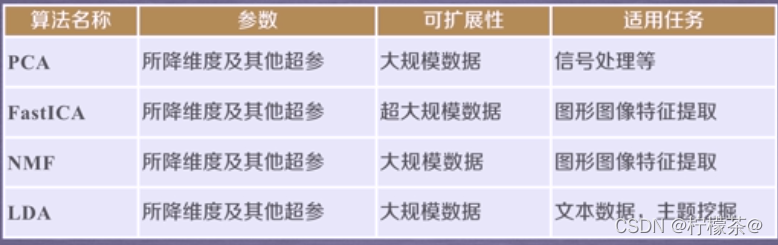
(5)在后续中将通过实例展示如何利用sklearn库提供的分类和降维算法解决具体问题
①31省市居民家庭消费调查
②学生月上网时间分布调查
③人脸图像特征抽取
④图像分割
二、聚类
1.K-means方法
(1)k-means算法以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。
(2)主要处理过程
①随机选择k个点作为初始的聚类中心。
②对于剩下的点,根据其与聚类中心的距离,将其归人最近的簇。
③对每个簇,计算所有点的均值作为新的聚类中心。
④重复2、3直到聚类中心不再发生改变。
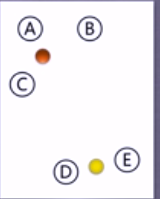
(3)举例
①在5个点中随机选取两个聚类中心

②计算距离后,归入簇

③重新计算聚类中心,重新计算距离,将点归入簇
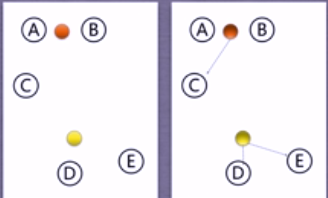
④直到簇的组成稳定
2.K-means应用
(1)问题分析
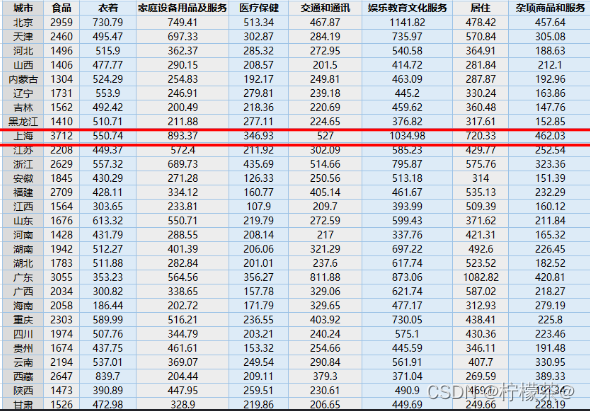
①数据介绍:现有1999年全国31个省份城镇居民家庭平均每人全年消费性支出的八个主要变量数据,这八个变量分别是:食品、衣着、家庭设备用品及服务、医疗保健、交通和通讯、娱乐教育文化服务、居住以及杂项商品和服务。利用已有数据,对31个省份进行聚类。
②实验目的:通过聚类,了解1999年各个省份的消费水平在国内的情况。
③技术路线:sklearn.cluster.Kmeans
④数据实例
(2)过程
①使用算法:K-means聚类算法
②实现过程
1)建立过程,导入sklearn相关包
import numpy as np
from sklearn.cluster import KMeans
2)加载数据,创建K-means算法实例,并进行训练,获得标签
注1:调用K-Means方法所需参数
1)n_cluster:用于指定聚类中心的个数
2)init:初始聚类中心的初始化方法
3)max_iter:最大的迭代次数
4)一般调用时只给出n_clusters即可,init默认是k-means++,max_iter默认是300
注2:其他参数
1)data:加载的数据
2)label:聚类后数据所属的标签
3)fit_predict():计算簇中心以及为簇分配序号
③输出标签,查看结果
1)将城市按照消费水平n clusters类,消费水平相近的城市聚集在一类中。
import numpy as np
from scipy.sparse import data
from sklearn.cluster import KMeans
def loadData(filePath):
fr = open(filePath, 'r+') # 读写打开一个文本文件
lines = fr.readline() # 一次读取整个文件
retData = [] #存储城市的各项消费信息
retCityName = [] #用于存储城市名称
for line in lines:
items = line.strip().split(",")
retCityName.append(items[0])
retData.append([float(items[i])
for i in range(1, len(items))])
for i in range(1,len(items)):
return retData, retCityName # 返回城市名称及各项消费信息
# 加载数据,创建K-means算法实例,并进行训练,获得标签
if __name__ == '__main__':
data.cityName = loadData('city.txt') #利用loadData方法读取数据,此处文件需自行准备
km = KMeans(n_clusters=3) # 创建实例
lable = km.fit_predict(data) # 调用Kmeans() fit_predict()进行聚类计算
expenses = np.num(km.cluster_centers_,axis=1) #expenses:聚类中心的数值加和,即平均消费水平
# print
CityCluster = [[],[],[]] # 将城市按lable分成设定的簇
for i in range(len(cityName)):
CityCluster[lable[i]].append(data.cityName[i])
for i in range(len(CityCluster)):
print("Expenses:%.2f"%expenses[i]) # 将每个簇的平均花费输出
print(CityCluster[i]) # 将每个簇的城市输出
2)结果展示:
-1:聚成2类:km = KMeans(n_clusters=2)

-2:聚成3类:km= KMeans(n_clusters=3)

-3:聚成4类:km= KMeans(n_clusters=4)

(3)拓展&&改进
①计算两条数据相似性时,Sklearn的K-Means默认用的是欧式距离。虽然还有余弦相似度,马氏距离等多种方法,但没有设定计算距离方法的参数。
②想自定义计算距离的方式时,可更改此处源代码

建议使用scipy.spatial.distance.cdist方法
3.DBSCAN方法
(1)DBSCAN算法是一种基于密度的聚类算法
①聚类的时候不需要预先指定簇的个数最终的
②簇的个数不定
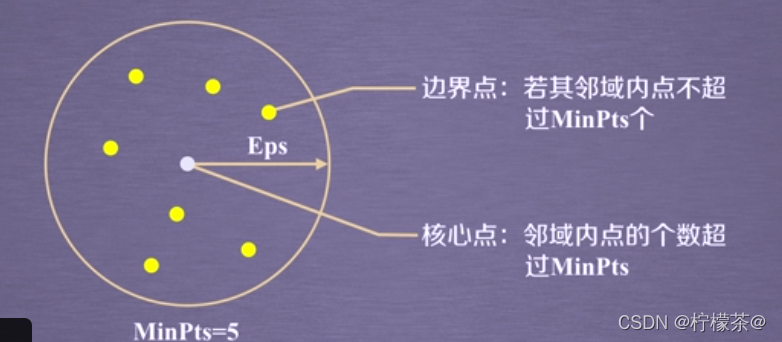
(2)DBSCAN算法将数据点分为三类:
①核心点:在半径Eps内含有超过MinPts数目的点。
②边界点:在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内。
③噪音点:既不是核心点也不是边界点的点。
(3)DBSCAN算法流程
①将所有点标记为核心点、边界点或噪声点
②删除噪声点
③为距离在Eps之内的所有核心点之间赋予一条边
④每组连通的核心点形成一个簇
⑤将每个边界点指派到一个与之关联的核心点的簇中(即在哪一个核心点的半径范围之内)
(4)举例:如下13个样本点,使用DBSCAN进行聚类

①取Eps=3,MinPts=3,依据DBSACN对所有点进行聚类(这里使用曼哈顿距离)
②对每个点计算其邻域Eps=3内的点的集合,集合内点的个数超过MinPts=3的点为核心点
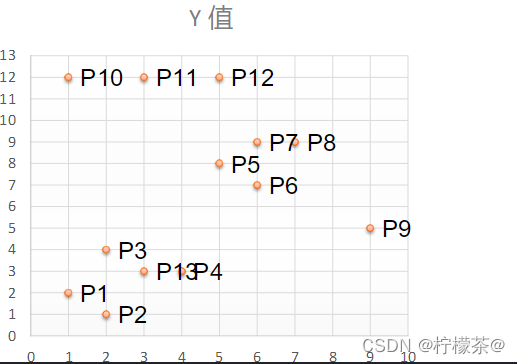
③查看剩余点是否在核心点的邻域内,若在,则为边界点,否则为噪声点。
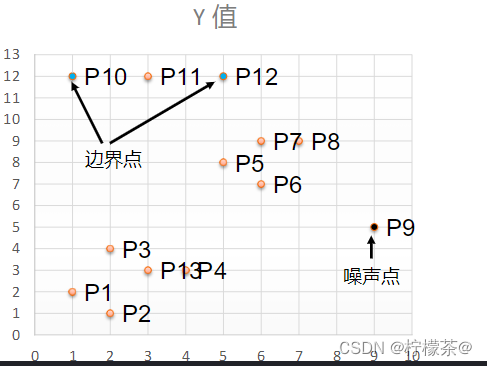
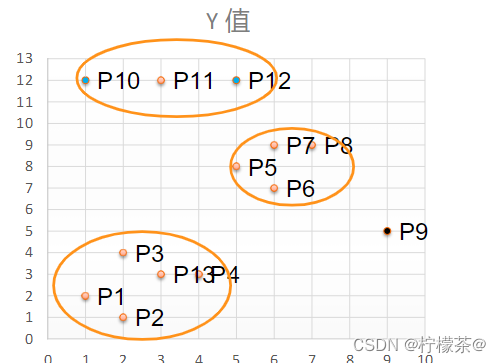
④将距离不超过Eps=3的点相互连接构成一个簇,核心点邻域内的点也会被加入到这个簇中。
4.DBSCAN应用
(1)问题分析
①现有大学校园网的日志数据,为290条大学生的校园网使用情况数据
②数据包括用户ID,设备的MAC地址,IP地址,开始上网时间,停止上网时间,上网时长,校园网套餐等。
③利用已有数据,分析学生上网的模式。
(2)实验目的
通过DBSCAN聚类,分析学生上网时间和上网时长的模式。
(3)技术路线
采用sklearn.cluster.DBSCAN模块
(4)数据实例

(5)实验过程
(6)代码实现
①建立工程,导入sklearn相关包
import numpy as np
from sklearn.cluster import DBSCAN
②DBSCAN主要参数
1)eps:两个样本被看作邻居节点的最大距离
2)min_samples:簇的样本数
3)metric:距离计算方式
例:sklearn.cluster.DBSCAN(eps=0.5,min_samples=5,metric=‘euclidean’)
③对上网时间聚类,创建DBSCAN算法实例,并进行训练,获得标签
附码import numpy as np
import sklearn.cluster
from sklearn import metrics
from sklearn.cluster import DBSCAN
mac2id=dict() # 字典
onlinetimes=[]
f = open('TestData.txt')
for line in f:
mac = line.split(',')[2] # 读取每条中的mac地址
onlinetime = int(line.split(',')[6]) # 读取上网时长
starttime=int(line.split(',')[4].split(' ')[1].split(':')[0]) # 读取开始上网时间
if mac not in mac2id:
mac2id[mac]=len(onlinetimes) # 其中key是mac地址
onlinetimes.append((starttime,onlinetime)) # value是对应mac地址的上网时长以及开始上网时间
else:
onlinetimes[mac2id[mac]]=[(starttime,onlinetime)]
real_X=np.array(onlinetimes).reshape((-1,2))
#对上网时间聚类,创建DBSCAN算法实例,并进行训练,获得标签
X = real_X[:,0:1]
db = sklearn.cluster.DBSCAN(eps=0.01,min_samples=20).fit(X) #调用DBSCAN方法进行训练
labels=db.labels # labels为每个数据的簇标签
print('Labels:')
print(labels) # 打印数据被记上的标签
ratio=len(labels[labels:]==-1)/len(labels) #计算标签为-1,即噪声数据的比例
print('Noise ratio:',format(ratio,'.2%'))
# Number of clusters in labels,ignoring noise if present
n_clusters_=len(set(labels))-(1 if -1 in labels else 0) # 计算簇的个数并打印
print('Estimated number of clusters: %d'% n_clusters_)
print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X,labels)) #评价聚类效果
for i in range(n_clusters_): # 打印各簇标号及簇内数据
print('Cluster',i,':')
print(list(X[labels==i].flatten()))
#对上网时长聚类,创建DBSCAN算法实例,并进行训练,获得标签
X = np.log(1+real_X[:,1:])
db = sklearn.DBSCAN(eps=0.1401,min_samples=10).fit(X) #调用DBSCAN方法进行训练
labels=db.labels # labels为每个数据的簇标签
print('Labels:')
print(labels) # 打印数据被记上的标签
ratio=len(labels[labels:]==-1)/len(labels) #计算标签为-1,即噪声数据的比例
print('Noise ratio:',format(ratio,'.2%'))
# Number of clusters in labels,ignoring noise if present
n_clusters_=len(set(labels))-(1 if -1 in labels else 0) # 计算簇的个数并打印
print('Estimated number of clusters: %d'% n_clusters_)
print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X,labels)) #评价聚类效果
for i in range(n_clusters_): # 统计每一个簇内的样本个数,均值,标准差
print('Cluster',i,':')
count=len(X[labels==i])
mean=np.mean(real_X[labels==i][:,1])
std=np.std(real_X[labels==i][:,1])
print('\t number of sample:',count)
print('\t mean of sample:',format(mean,'.1f'))
print('\t std of sample:',format(std,'.1f'))
④输出标签,查看结果

⑤画直方图,分析实验结果
import matplotlib.pyplot as pet
plt.hist(X,24)
观察得出:上网时间大多聚集在22:00和23:00
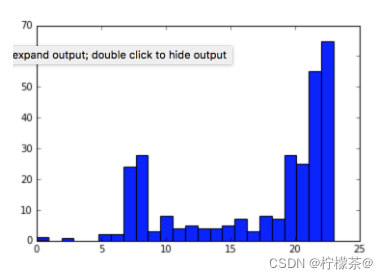
⑥数据分布vs聚类
技巧:对数变换

⑦对上网时长聚类,创建DBSCAN算法实例,并进行训练,获得标签
⑧输出标签,查看结果


1)按照上网时长DBSCAN聚了5类,上图所示,显示了每个聚类的样本数量、聚类的均值、标准差。
2)时长聚类效果不如时间的聚类效果明显。
三、降维
1.PCA方法
(1)主成分分析(PCA)
①主成分分析(Principal Component Analysis,PCA)是最常用的一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等。
②PCA可以把具有相关性的高维变量合成为线性无关的低维变量,称为主成分。主成分能够尽可能保留原始数据的信息。
(2)涉及到的相关术语:
①方差:是各个样本和样本均值的差的平方和的均值,用来度量一组数据的分散程度
②协方差:用于度量2个变量直接的线性相关性程度,若为0,则可认为二者线性无关。
③协方差矩阵:由变量的协方差值构成的矩阵(对称阵)
④特征向量:描述数据集结构的非零向量
公式如图
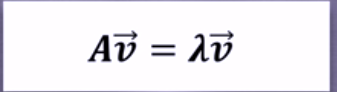
A是方阵,v是特征向量,λ是特征值
(3)原理
①矩阵的主成分:其协方差矩阵对应的特征向量,按照对应的特征值大学进行排序
②最大特征值为第一主成分,其次是第二主成分,以此类推
(4)算法过程

(5)主要参数
在sklearn库中,可使用sklearn.decomposition.PCA加载PCA进行降维
①n_components:指定主成分的个数,即降维后数据的维度
②svd_solver:设置特征值分解的方法,默认为’auto’,其他可选有’full’,‘arpack’,‘randomized’,可参考官网API
2.PCA应用实例:鸢尾花数据
————PCA实现高维数据可视化
(1)问题分析
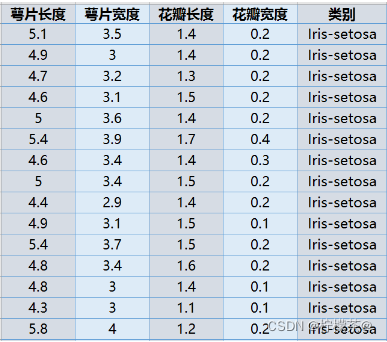
①已知鸢尾花数据是4维的,共三类样本。
②使用PCA实现对鸢尾花数据进行降维,实现在二维平面上的可视化。
(2)代码实现
①建立工程,导入sklearn相关工具包
# 加载matplotlib用于数据可视化
import matplotlib.pyplot as plt
#加载PCA算法包
from sklearn.decomposition import PCA
#加载鸢尾花数据集导入函数
from sklearn.datasets import load_iris
②加载数据并进行降维
③按类别对降维后的数据进行保存
④降维后数据点的可视化
#建立工程,导入sklearn相关工具包
# 加载matplotlib用于数据可视化
import matplotlib.pyplot as plt
#加载PCA算法包
from sklearn.decomposition import PCA
#加载鸢尾花数据集导入函数
from sklearn.datasets import load_iris
#加载数据并进行降维
data = load_iris() #以字典形式加载鸢尾花数据集
y = data.target #使用y表示数据集中的标签
X = data.data #使用x表示数据集中的属性标签
pca = PCA(n_components=2) # 加载PCA算法,设置降维后主成分数目为2
reduced_X = pca.fit_transform(X) #对原始数据进行降维,保存在reduce_X中
# 按类别对降维后的数据进行保存
red_x,red_y = [],[] #第一类数据点
blue_x,blue_y = [],[]#第二类数据点
green_x,green_y = [],[] #第三类数据点
for i in range(len(reduced_X)): #按照鸢尾花的类别,将降维后的数据点保存在不同的列表中
if y[i]==0:
red_x.append(reduced_X[i][0])
red_y.append(reduced_X[i][1])
elif y[i]==1:
blue_x.append(reduced_X[i][0])
blue_y.append(reduced_X[i][1])
else:
green_x.append(reduced_X[i][0])
green_y.append(reduced_X[i][1])
#降维后数据点的可视化
plt.scatter(red_x,red_y,c='r',marker='x') #第一类数据点
plt.scatter(blue_x,blue_y,c='b',marker='D') #第二类数据点
plt.scatter(green_x,green_y,c='g',marker='.') #第三类数据点
plt.show() #可视化
(3)结果展示
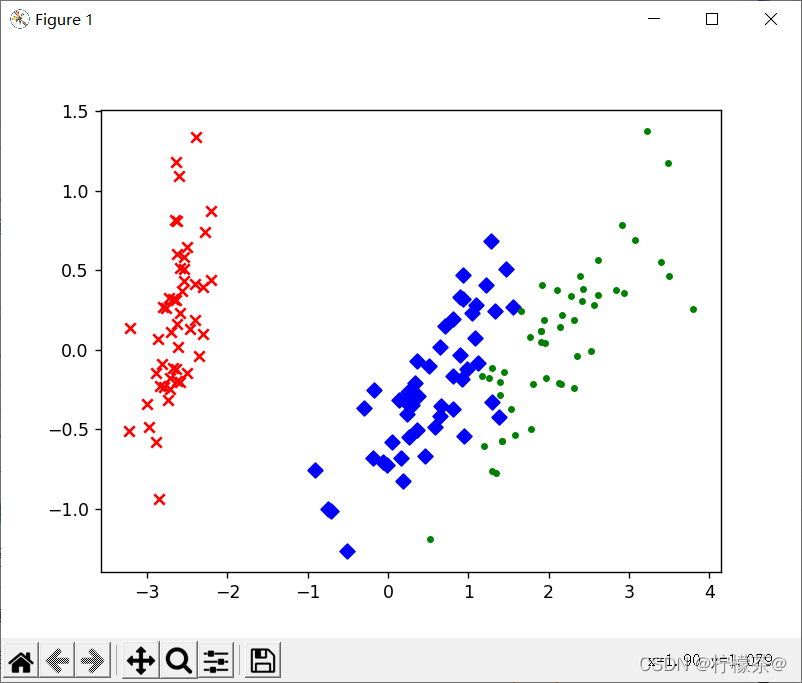
①可以看出,降维后的数据仍能够清晰地分成三类。
②这样不仅能削减数据的维度,降低分类任务的工作量,还能保证分类的质量。
3.NMF方法
(1)非负矩阵分解(Non-negative Matrix Factorization,NMF)是在矩阵中所有元素均为非负数约束条件之下的矩阵分解方法
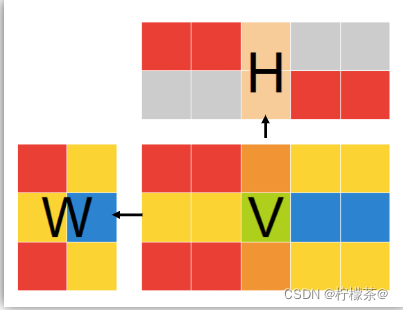
(2)基本思想:给定一个非负矩阵V,NMF能够找到一个非负矩阵W和一个非负矩阵H,使得矩阵W和H的乘积近似等于矩阵V中的值

①W矩阵:基础图像矩阵,相当于从原矩阵V中抽取出来的特征
②H矩阵:系数矩阵
③NMF能够广泛应用于图像分析、文本挖掘和语音处理等领域
(3)矩阵分解优化目标:最小化“W与矩阵H的乘积”和“原始矩阵”之间的差别
①目标函数如下(基于欧氏距离)
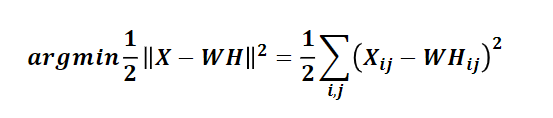
②基于KL散度的优化目标,损失函数如下
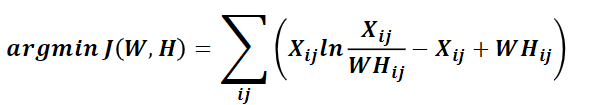
③W矩阵和H矩阵的求解为迭代算法,在此不详细讲述,参考链接:
http://blog.csdn.net/acdreamers/article/details/44663421/
(4)在sklearn库中,可以使用sklearn.decomposition.NMF加载NMF算法,主要参数有
①n_components:用于指定分解后矩阵的单个维度k
②init:W矩阵和H矩阵的初始化方式,默认为’nndsvdar’
③其他参数参考官网API
4.NMF应用:人脸数据特征提取
(1)问题分析
①目标:已知Olivetti人脸数据共400个,每个数据是64*64大小。由于NMF分解得到的W矩阵相当于从原始矩阵中提取的特征,那么就可以使用NMF对400个人脸数据进行特征提取。
②通过设置k的大小,设置提取的特征的数目。在本实验中设置k=6,随后将提取的特征以图像的形式展示出来。
(2)代码实现
①建立工程,导入sklearn相关工具包
# 加载matplotlib用于数据的可视化
import matplotlib.pyplot as plt
# 加载PCA算法包
from sklearn import decomposition
# 加载Olivetti人脸数据集导入函数
from sklearn.datasets import fetch_olivetti_faces
# 加载RandomState用于创建随机种子
from numpy.random import RandomState
②设置基本参数并加载数据
③设置图像的展示方式
④创建特征提取的对象NMF,使用PCA作为对比
# 建立工程,导入sklearn相关工具包
# 加载matplotlib用于数据的可视化
import matplotlib.pyplot as plt
# 加载PCA算法包
from sklearn import decomposition
# 加载Olivetti人脸数据集导入函数
from sklearn import datasets
# 加载RandomState用于创建随机种子
from numpy.random import RandomState
# 设置基本参数并加载数据
n_row, n_col = 2, 3 # 设置图像展示时的排列情况(2行3列),如图
n_components = n_row*n_col # 设置提取的特征的数目
image_shape = (64,64) #设置人脸数据图片的大小
dataset = datasets.fetch_olivetti_faces(shuffle=True,random_state=RandomState(0))
faces = dataset.data #加载数据并打乱顺序
# 设置图像的展示方式
def plot_gallery(title, images, n_col=n_col, n_row=n_row):
plt.figure(figsize=(2.*n_col, 2.26*n_row)) #创建图片并指定图片大小(英寸)
plt.suptitle(title,size=16) #设置标题及字号大小
for i,comp in enumerate(images):
plt.subplot(n_row,n_col,i+1) # 选择画制的子图
vmax = max(comp.max(),-comp.min())
plt.imshow(comp.reshape(image_shape),cmap=plt.cm.gray,
interpolation='nearest',vmin=-vmax,vmax=vmax) #对数值归一化,并以灰度图形式显示
plt.xticks(())
plt.yticks(()) #去除子图的坐标轴标签
plt.subplots_adjust(0.01,0.05,0.99,0.93,0.04,0.) # 对子图位置及间隔进行调整
plot_gallery("First centered Olivetti faces",faces[:n_components])
plt.show()
# 创建特征提取的对象NMF,使用PCA作为对比
estimators = {
# 将他们存放在一个列表中
('Eigenfaces - PCA using randomized SVD', # 提取方法名称
decomposition.PCA(n_components=6, whiten=True)), # PCA实例
('Non-nefative components - NMF', # 提取方法名称
decomposition.NMF(n_components=6, init='nndsvda', tol=5e-3))} # NMF实例
# 降维后数据点的可视化
for name,estimator in estimators: #分别调用PCA和NMF
print("Extracting the top %d %s..."%(n_components,name))
print(faces.shape)
estimator.fit(faces) # 调用PCA或NMF提取特征
components_ = estimator.components_
plot_gallery(name,components_[:n_components]) # 获取提取的特征
plt.show() # 按照固定格式进行排列
(3)效果展示



总结
关于无监督学习,比较核心的就是聚类和降维问题,在此仅用4个实例说明两大核心的四大典型方法,其余便不多做赘述。关于代码之中的一些改进问题,由于用到库中的其他方法,且本人能力有限,大家感兴趣可自行查阅官网API。
两点问题:
(1)代码运行需要基础数据支撑,py的自带库中有些内含所需数据,有些则没有,本篇并未放上数据txt文件,只是为了展示无监督学习的体系流程以作演示
(2)在库的包导入若发生问题,看看版本更新问题,以及部分包在近年来命名和函数有所调整,各位客官可面向百度
ps:人脸数据运行结果出来真是把我送走了,机器学习让人头秃
代码非原创,内容乃课件整理所得。
如有问题,欢迎指正!
智能推荐
初始化时checkbox选中问题-程序员宅基地
文章浏览阅读746次。首先我们大家在写页面的时候可能回经常遇到checkbox、radio等一些使选中或者是不选中的问题。这是我在项目当中做的时候发现的一个小知识点,把它赶紧记录下来。以便以后复习与巩固。 现把代码写出来再解释: function operateCheckOrRadio() { var sForm = document.getElementById("sform"); var sStatus = d..._flutter checkbox用变量初始化无法设置为选中状态
UE5——问题——MediaPlayer的使用播放视频注意点_ue mediaplayer-程序员宅基地
文章浏览阅读1.1k次。UE5——问题——MediaPlayer的使用播放视频注意点_ue mediaplayer
毕设仿真分享 单片机非接触式红外感应体温计-程序员宅基地
文章浏览阅读311次,点赞9次,收藏7次。非接触式电子体温计主要利用红外测温原理,一切温度高于绝对零度(-273.35℃)的物体,由于分子热运动,物体会不停地向外辐射能量。物体辐射能量的大小与它的表面温度有十分密切的关系。因此,通过测量物体辐射的能量,就能够测量出物体的温度。本用户手册中的非接触式电子体温计就是利用这种测量方法,实现测量人体体温的功能。
Vista/Win7下普通权限进程动态提升权限_findwindow 没有权限-程序员宅基地
文章浏览阅读2k次。本文出自 “碧海笙箫” 博客,请务必保留此出处http://pyhcx.blog.51cto.com/713166/197073一、前提在Vista/Win7下,加强了对安全的管理,对注册表修改,系统目录的文件操作,都需要管理员权限才能完成(当然虚拟存储机制,表面上也相当于能操作)。所以,对于程序中有相关操作的,这时候,就要求我们的程序必须拥有管理员权限。通过mainfest文件,我们可以让程序总是需要管理员权限执行,但是,这将导致程序每次运行时,都需要弹出UAC框老骚扰用户,另外,有时候我们的程序只是在某_findwindow 没有权限
PCS7 入门指南 v9.0 SP3 v9.1 中文版 学习资料 (官方公开可用资料)_pcs7v9.1-程序员宅基地
文章浏览阅读1.8w次,点赞13次,收藏82次。链接:https://pan.baidu.com/s/1-p4h_QDL8BN04tnn3vSkOA提取码:nou3PCS7入门指南v9.0含APL(包含PDF和项目文件)官方地址:SIMATIC 过程控制系统 PCS 7 入门指南第1部分 (V9.0,含APL)https://support.industry.siemens.com/cs/document/109756196/simatic-%E8%BF%87%E7%A8%8B%E6%8E%A7%E5%88%B6%E7%B3%BB..._pcs7v9.1
c# 调用非托管代码_c# 声明kernel32 函数-程序员宅基地
文章浏览阅读956次,点赞3次,收藏5次。编程过程中,一般c#调用非托管的代码有两种方式:1.直接调用从DLL中导出的函数。2.调用COM对象上的接口方法。首先说明第1种方式,基本步骤如下:1.使用关键字static,extern声明需要导出的函数。2.把DllImport 属性附加到函数上。3.掌握常用的数据类型传递的对应关系。4.如果需要,为函数的参数和返回值指定自定义数据封送处理信息,这将重写.net framework默认的封送处理。简单举例如下:托管函数原型:DWORD GetShortPathName(LPCTST_c# 声明kernel32 函数
随便推点
git:一、GIT介绍+安装+全局配置+基础操作_请确保本地完成了 git 的全局配置-程序员宅基地
文章浏览阅读490次。仅供学习使用。执行命令git init,发现文件夹出现.git目录即说明创建本地仓库成功。创建的文件名为空,拓展名是bashrc,所以要开启文件的拓展名选项并检查该文件的格式是否为Bash RC源文件。工作区的文件创建或修改后通过git add提交到暂存区,暂存区的文件通过git commit提交到仓库。创建一个测试用的文件夹,进入后右键打开Git Bash,设置用户信息。ATT:红色的是工作区的文件,绿色的是暂存区的文件。GIT的流程分为三大块:工作区、暂存区、仓库。_请确保本地完成了 git 的全局配置
文件服务(SMB)共享详解-程序员宅基地
文章浏览阅读517次。三种共享类型:微软的CIFS文件共享协议,可以让windows机器在网上邻居之间共享文件,也即是windows-windows之间的文件共享;NFS文件共享协议,可以让远程共享的共享目录挂载在本地端,就像本地端的一个partition分区一样,但是共享也只能在UNIX-UNIX之间来共享;SAMBA文件共享协议,可以实现WINDOWS-UNIX之间的文件的共享,WINDOWS机器在网上..._smb共享只抓到nbns报文
鸿蒙系统第五批升级名单,鸿蒙系统首批升级机型名单曝光,很多人失望了,支持的机型太少...-程序员宅基地
文章浏览阅读983次。5月30日早间,“鸿蒙系统首批升级机型名单”这则消息在微博刷屏。按照微博博主爆料称,华为Mate40系列、Mate X2、P40系列、nova8系列以及华为平板MatePadPro将在首批升级鸿蒙操作系统。值得注意的是,今年4月,华为消费者业务AI与智慧全场景业务部副总裁杨海松表示,16%的市场份额是一条生死线。5月30日上午,记者实探位于深圳的华为全球旗舰店发现,目前展示的机型仍搭载安卓系统。工..._鸿蒙5升级名单
ES6——Map和Set-程序员宅基地
文章浏览阅读608次。ES6新增的数据类型,Map、Set之间的关系,如何使用?Map和Set的属性和方法。
FP-Growth算法全解析:理论基础与实战指导_pyfpgrowth库-程序员宅基地
文章浏览阅读574次。FP-Growth(Frequent Pattern Growth,频繁模式增长)算法是一种用于数据挖掘中频繁项集发现的有效方法。它是由Jian Pei,Jiawei Han和Runying Mao在2000年的论文中首次提出的。该算法主要应用于事务数据分析、关联规则挖掘以及数据挖掘领域的其他相关应用。_pyfpgrowth库
MySQL安装与环境变量配置_mysql-installer-web-community-5.7.35.0.msi .net-程序员宅基地
文章浏览阅读299次。一、下载MySQL:mysql-installer-web-community-5.7.35.0.msi二、安装双击下载的msi安装文件,弹出安装界面根据指示进行下一步的安装。选择安装的产品,分别为:MySQL Server、MySQL Workbench,然后Next一路执行execute和next。直到设置root用户的密码一路next三、配置环境变量为了能在cmd中使用mysql,需要将安装路径的bin配置到环境变量path中。在 ._mysql-installer-web-community-5.7.35.0.msi .net