机器学习之数据集_机器学习数据集-程序员宅基地
技术标签: python 机器学习 人工智能 chatgpt
目录
所属专栏:人工智能
文中提到的代码如有需要可以私信我发给你
1、简介
当谈论数据集时,通常是指在机器学习和数据分析中使用的一组数据样本,这些样本通常代表了某个特定问题领域的实际观测数据。数据集可以用于开发、训练和评估机器学习模型,从而使模型能够从数据中学习并做出预测或分类。
数据集通常由以下几个组成部分组成:
- 特征(Features):也称为自变量、属性或输入变量,是用来描述每个数据样本的不同方面的数据。特征可以是数值型、类别型、文本型等。在监督学习中,特征被用来训练模型。
- 目标变量(Target Variable):也称为因变量、标签或输出变量,是我们希望模型预测或分类的值。在监督学习中,模型使用特征来预测或分类目标变量。
- 样本(Samples):每个样本是数据集中的一行,包含特征和目标变量的值。样本代表了问题领域中的一个观测点或数据点。
- 特征名称(Feature Names):如果数据集中的特征有名称,通常会提供一个特征名称列表,以便更好地理解和解释特征。
- 目标变量的类别(Target Variable Classes):对于分类问题,目标变量可能有多个类别,每个类别表示一个不同的类或标签。
- 数据集描述(Dataset Description):通常包括数据集的来源、数据采集方法、特征和目标变量的含义,以及数据的格式和结构等信息。
数据集可以在各种领域和问题中使用,例如医疗诊断、自然语言处理、计算机视觉、金融预测等。不同类型的数据集可能需要不同的预处理和特征工程步骤,以便为模型提供有意义的数据。
在机器学习中,一个常见的任务是将数据集划分为训练集和测试集,用于模型的训练和评估。这样可以确保模型在未见过的数据上能够进行泛化。数据集的质量和适用性对机器学习模型的性能和效果有很大影响,因此选择合适的数据集和进行有效的特征工程非常重要。
2、可用数据集
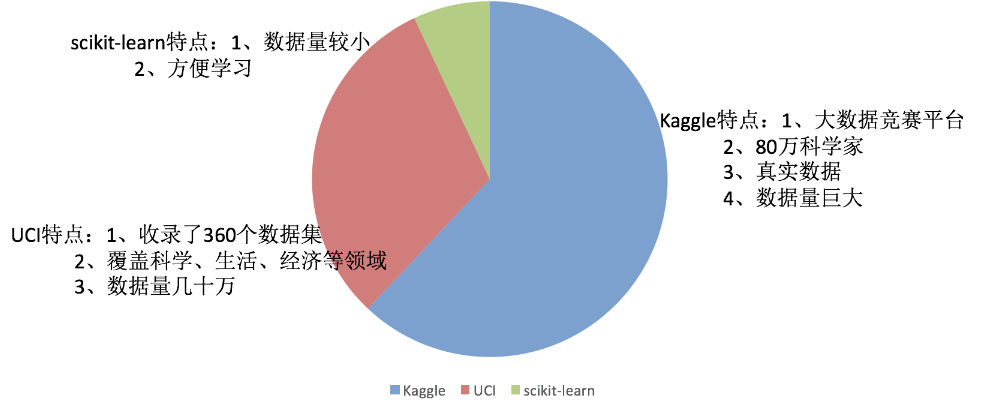
Kaggle网址:Find Open Datasets and Machine Learning Projects | Kaggle
UCI数据集网址: UCI Machine Learning Repository
scikit-learn网址:http://scikit-learn.org/stable/datasets/index.html#datasets
Scikit-learn工具介绍:

- Python语言的机器学习工具
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API
- 目前稳定版本0.19.1
安装:pip3 install Scikit-learn==0.19.1 (安装scikit-learn需要Numpy, Scipy等库)
Scikit-learn包含的内容:
scikitlearn接口
- 分类、聚类、回归
- 特征工程
- 模型选择、调优
3、scikit-learn数据集API
- sklearn.datasets 加载获取流行数据集
- datasets.load_*() 获取小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None) 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
3.1、小数据集
sklearn.datasets.load_iris() 加载并返回鸢尾花数据集

sklearn.datasets.load_boston() 加载并返回波士顿房价数据集
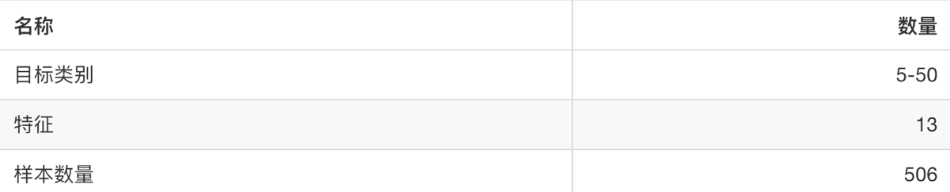
3.2、大数据集
- sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
-
- subset:'train'或者'test','all',可选,选择要加载的数据集。
- 训练集的“训练”,测试集的“测试”,两者的“全部”
4、数据集使用
这里使用的是鸢尾花数据集

数据集返回值介绍:
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
DESCR:数据描述
feature_names:特征名,新闻数据,手写数字、回归数据集没有
target_names:标签名
from sklearn.datasets import load_iris
'''
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
DESCR:数据描述
feature_names:特征名,新闻数据,手写数字、回归数据集没有
target_names:标签名
'''
def getIris_1():
# 获取鸢尾花数据集
iris = load_iris()
print("鸢尾花数据集的返回值:\n", iris)
# 返回值是一个继承自字典的Bench
print("鸢尾花的特征值:\n", iris["data"])
print("鸢尾花的目标值:\n", iris.target)
print("鸢尾花特征的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字:\n", iris.target_names)
print("鸢尾花的描述:\n", iris.DESCR)
if __name__ == '__main__':
getIris_1()数据集划分:
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 30%
数据集划分api:
sklearn.model_selection.train_test_split(arrays, *options)
x 数据集的特征值
y 数据集的标签值
test_size 测试集的大小,一般为float
random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
return 测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
from sklearn.model_selection import train_test_split # 数据集划分
'''
sklearn.model_selection.train_test_split(arrays, *options)
x 数据集的特征值
y 数据集的标签值
test_size 测试集的大小,一般为float
random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
return 测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
'''
def datasets_demo():
"""
对鸢尾花数据集的演示
:return: None
"""
# 1、获取鸢尾花数据集
iris = load_iris()
print("鸢尾花数据集的返回值:\n", iris)
# 返回值是一个继承自字典的Bench
print("鸢尾花的特征值:\n", iris["data"])
print("鸢尾花的目标值:\n", iris.target)
print("鸢尾花特征的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字:\n", iris.target_names)
print("鸢尾花的描述:\n", iris.DESCR)
# 2、对鸢尾花数据集进行分割
# 训练集的特征值x_train 测试集的特征值x_test 训练集的目标值y_train 测试集的目标值y_test
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
print("x_train:\n", x_train.shape)
# 随机数种子
x_train1, x_test1, y_train1, y_test1 = train_test_split(iris.data, iris.target, random_state=6)
x_train2, x_test2, y_train2, y_test2 = train_test_split(iris.data, iris.target, random_state=6)
print("如果随机数种子不一致:\n", x_train == x_train1)
print("如果随机数种子一致:\n", x_train1 == x_train2)
return None
if __name__ == '__main__':
datasets_demo()智能推荐
FX3/CX3 JLINK 调试_ezusbsuite_qsg.pdf-程序员宅基地
文章浏览阅读2.1k次。FX3 JLINK调试是一个有些麻烦的事情,经常有些莫名其妙的问题。 设置参见 c:\Program Files (x86)\Cypress\EZ-USB FX3 SDK\1.3\doc\firmware 下的 EzUsbSuite_UG.pdf 文档。 常见问题: 1.装了多个版本的jlink,使用了未注册或不适当的版本 选择一个正确的版本。JLinkARM_V408l,JLinkA_ezusbsuite_qsg.pdf
用openGL+QT简单实现二进制stl文件读取显示并通过鼠标旋转缩放_qopengl如何鼠标控制旋转-程序员宅基地
文章浏览阅读2.6k次。** 本文仅通过用openGL+QT简单实现二进制stl文件读取显示并通过鼠标旋转缩放, 是比较入门的级别,由于个人能力有限,新手级别,所以未能施加光影灯光等操作, 未能让显示的stl文件更加真实。****效果图:**1. main.cpp```cpp#include "widget.h"#include <QApplication>int main(int argc, char *argv[]){ QApplication a(argc, argv); _qopengl如何鼠标控制旋转
刘焕勇&王昊奋|ChatGPT对知识图谱的影响讨论实录-程序员宅基地
文章浏览阅读943次,点赞22次,收藏19次。以大规模预训练语言模型为基础的chatgpt成功出圈,在近几日已经给人工智能板块带来了多次涨停,这足够说明这一风口的到来。而作为曾经的风口“知识图谱”而言,如何找到其与chatgpt之间的区别,找好自身的定位显得尤为重要。形式化知识和参数化知识在表现形式上一直都是大家考虑的问题,两种技术都应该有自己的定位与价值所在。知识图谱构建往往是抽取式的,而且往往包含一系列知识冲突检测、消解过程,整个过程都能溯源。以这样的知识作为输入,能在相当程度上解决当前ChatGPT的事实谬误问题,并具有可解释性。
如何实现tomcat的热部署_tomcat热部署-程序员宅基地
文章浏览阅读1.3k次。最重要的一点,一定是degbug的方式启动,不然热部署不会生效,注意,注意!_tomcat热部署
用HTML5做一个个人网站,此文仅展示个人主页界面。内附源代码下载地址_个人主页源码-程序员宅基地
文章浏览阅读10w+次,点赞56次,收藏482次。html5 ,用css去修饰自己的个人主页代码如下:<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xh..._个人主页源码
程序员公开上班摸鱼神器!有了它,老板都不好意思打扰你!-程序员宅基地
文章浏览阅读201次。开发者(KaiFaX)面向全栈工程师的开发者专注于前端、Java/Python/Go/PHP的技术社区来源:开源最前线链接:https://github.com/svenstaro/gen..._程序员怎么上班摸鱼
随便推点
UG\NX二次开发 改变Block UI界面的尺寸_ug二次开发 调整 对话框大小-程序员宅基地
文章浏览阅读1.3k次。改变Block UI界面的尺寸_ug二次开发 调整 对话框大小
基于深度学习的股票预测(完整版,有代码)_基于深度学习的股票操纵识别研究python代码-程序员宅基地
文章浏览阅读1.3w次,点赞18次,收藏291次。基于深度学习的股票预测数据获取数据转换LSTM模型搭建训练模型预测结果数据获取采用tushare的数据接口(不知道tushare的筒子们自行百度一下,简而言之其免费提供各类金融数据 , 助力智能投资与创新型投资。)python可以直接使用pip安装tushare!pip install tushareCollecting tushare Downloading https://files.pythonhosted.org/packages/17/76/dc6784a1c07ec040e74_基于深度学习的股票操纵识别研究python代码
中科网威工业级防火墙通过电力行业测评_电力行业防火墙有哪些-程序员宅基地
文章浏览阅读2k次。【IT168 厂商动态】 近日,北京中科网威(NETPOWER)工业级防火墙通过了中国电力工业电力设备及仪表质量检验测试中心(厂站自动化及远动)测试,并成为中国首家通过电力协议访问控制专业测评的工业级防火墙生产厂商。 北京中科网威(NETPOWER)工业级防火墙专为工业及恶劣环境下的网络安全需求而设计,它采用了非X86的高可靠嵌入式处理器并采用无风扇设计,整机功耗不到22W,具备极_电力行业防火墙有哪些
第十三周 ——项目二 “二叉树排序树中查找的路径”-程序员宅基地
文章浏览阅读206次。/*烟台大学计算机学院 作者:董玉祥 完成日期: 2017 12 3 问题描述:二叉树排序树中查找的路径 */#include #include #define MaxSize 100typedef int KeyType; //定义关键字类型typedef char InfoType;typedef struct node
C语言基础 -- scanf函数的返回值及其应用_c语言ignoring return value-程序员宅基地
文章浏览阅读775次。当时老师一定会告诉你,这个一个"warning"的报警,可以不用管它,也确实如此。不过,这条报警信息我们至少可以知道一点,就是scanf函数调用完之后是有一个返回值的,下面我们就要对scanf返回值进行详细的讨论。并给出在编程时利用scanf的返回值可以实现的一些功能。_c语言ignoring return value
数字医疗时代的数据安全如何保障?_数字医疗服务保障方案-程序员宅基地
文章浏览阅读9.6k次。十四五规划下,数据安全成为国家、社会发展面临的重要议题,《数据安全法》《个人信息保护法》《关键信息基础设施安全保护条例》已陆续施行。如何做好“数据安全建设”是数字时代的必答题。_数字医疗服务保障方案