0、基本知识
基本数据类型
char、short( int)、int、long( int)、long long (int)、float、double、long doulbe,括号内内容表示可省略。除了上述几种外,前5中还有对应的unsigned类型。3u、3ul、1.2f、1.2L。

常量:整型常量、浮点型常量、符号常量(用#define定义)、字符常量、字符串常量、枚举常量
字符常量中有一些比较特别,成为转义字符,ANSI C中的全部转义字符序列如下:
\a 响铃符 \\ 反斜杠
\b 回退符 \? 问号
\f 换页符 \' 单引号
\n换行符 \" 双引号
\r 回车符 \ooo八进制数,ooo代表1~3个八进制数字(0~7)
\t 横向制表符 \xhh 十六进制数,hh为一或多个十六进制数字(0~9,a~f,A~F)
\v 纵向制表符 \0
运算符优先级及结合性:

函数与程序结构
如果函数中省略了返回值类型,则默认为int类型。
函数间的通信可以通过参数、返回值、外部变量进行。
1、struct与typedef struct
struct Student{int a;int b}stu1; //定义名为Student的结构体,及一个Student变量stu1
struct {int a;int b;}stu1; //只定义了一个结构体变量stu1,未定义结构体名,无法再定义其他变量
typedef struct Student{int a;int b;}Stu1,Stu2; //定义结构体类型为Student,别名为Stu1或Stu2,此时有三种定义相应变量的方式:
struct Student st; 或 Stu1 st; 或 Stu2 st;
typedef struct{int a;int b;}Stu1,Stu2; //未指定结构体类型名,但给了别名Stu1或Stu2,可用之定义变量
2、struct 内存空间分配原则 http://zhidao.baidu.com/link?url=bWqgw8n8ck6zBwaYAzeBOcAFM7ZIErMtYz8XznIyLcoid9tZkw_5LlOz0JQg5othMWEVXeHOj557KRu3gaxVeK
原则1、数据成员对齐规则:结构(struct或联合union)的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小的整数倍开始(比如int在32位机为4字节,则要从4的整数倍地址开始存储)
原则2、结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储。(struct a里存有struct b,b里有char,int,double等元素,那b应该从8的整数倍开始存储)
原则3、收尾工作:结构体的总大小,也就是sizeof的结果,必须是其内部最大成员的整数倍,不足的要补齐。
获取结构体成员在结构体内的偏移量:(将0强制转换成这个结构体的指针,来访问这个结构体中的成员,然后,取这个成员的地址,得到的就是成员相对结构体起始的偏移)
1 #define OFFSET(type, field) (&((type *)0)->field) 2 3 struct Node { 4 int a; 5 char b; 6 short c; 7 char *d; 8 }; 9 10 int main(int argc, char *argv[]) 11 { 12 printf("%p\n", OFFSET(struct Node, a)); 13 printf("%p\n", OFFSET(struct Node, b)); 14 printf("%p\n", OFFSET(struct Node, c)); 15 printf("%p\n", OFFSET(struct Node, d)); 16 return 0; 17 }
3、typedef struct node{int a; struct node*lchild; struct node* rchild;}BNode,*BTree;
这里:
BNode为struct node 的别名,相当于 typedef struct node BNode
BTree为struct node*的别名,相当于typedef struct node* BTree
4、*p++,(*p)++,*++p
char data[100]={ 'c','x'}; char *p=data;
printf("%c\n",*p++);//c printf("%c\n",*p);//x printf("%s\n",data);//cx
printf("%c\n",(*p)++);//c printf("%c\n",*p);//d printf("%s\n",data);//dx
printf("%c\n",*++p);//x printf("%c\n",*p);//x printf("%s\n",data);//cx
5、中缀表达式转后缀表达式:
手算:
用手算的方式来计算后序式相当的简单,将运算子两旁的操作数依先后顺序全括号起来,然后将所有的右括号取代为左边最接近的运算子(从最内层括号开始),最后去掉所有的左括号就可以完成后序表示式,例如:
a+b*d+c/d => ((a+(b*d))+(c/d)) -> abd*+cd/+
中缀转前缀类似
计算机算:用堆栈
6、C/C++中的 a和&a
#include <stdio.h> int main(void) { int a[5] = { 1,2,3,4,5}; int *ptr = (int *)(&a + 1); int temp1 = *( a + 1 );//2 int temp2 = *( ptr - 1 );5 return 1; } &为取址运算符,&a得到a类型的指针;对指针进行加1操作,得到的是下一个元素的地址,而不是原有地址值直接加1.所以,一个类型为T的指针的移动,以sizeof(T)为移动单位。 &a + 1:取数组a的首地址,该地址的值加上sizeof(a)的值,即&a +5* sizeof(int),也就是下一个数组的首地址,显然当前指针已经越过了数组的界限。 *(a + 1):a和&a的值是一样的,但是意思是不一样的:a是数组首元素的首地址,也就是a[0]的首地址,&a是数组的首地址。a + 1是数组下一个元素的首地址即a[1]的首地址;&a + 1 是下一个数组的首地址 *(ptr - 1)因为ptr指向的是a[5],并且ptr是int *类型,所以*(ptr - 1)是指向a[4]
7、预处理的妙用
#define swap(type, i, j) {type t = i; i = j; j = t; int main() { int a = 23, b = 47; printf("Before swap. a: %d, b: %d\n", a, b); swap(int, a, b) printf("After swap. a: %d, b: %d\n", a, b); return 0; }
8、关于swap,C中可以通过指针实现,C++中除了用指针外,还可以通过引用&实现
方式一:如同C语言使用指针。 方式二:使用“引用”(&) void swap(int& i, int& j) { int t = i; i = j; j = t; } C++的函数参数使用引用(&),值通过引用传递(pass by reference),函数中的参数不被 copy(如果传的是类就不会调用拷贝构造函数),所以在函数中能正确交换两个变量的值。
另,不用临时变量的swap实现方法:


//利用异或运算 void swap(int &x,int &y) { x^=y; y^=x; x^=y; } //利用加减 void swap(int &x,int &y) { x+=y; y=x-y; x-=y; }
需要特别注意的是:若自己和自己交换,这时这两种方法都会得到错误的结果即都会变成0,这种情况在数组交换元素时很可能遇到。因此应注意判断是不是同一个数组元素。看如下例子:若left和last相等,则结果执行后两者皆为0
data[left]^=data[last]; data[last]^=data[left]; data[left]^=data[last];
还有一种方法,用宏替换:
#define swap(t,a,b) {t c=a; a=b; b=c;}
int a=1,b=2;
swap(int ,a,b);//由于是宏替换而非函数调用,因此这里a、b值交换了
9、关于结构体成员访问
typedef struct node
{
int value;
struct node*lchild;
struct node*rchild;
}BNode,*BTree;
BNode p;//结构体变量
Btree q;//结构体指针
对成员的访问: 1、结构体变量 p.value 2、结构体指针 (*q).value 或 q->value
10、负数二进制原码补码转换(负数在计算机内为什么用补码?只有这样才能正确实现加减法,计算机其实只能做加法,1-2变为1+(-2),1和-2只有用补码表示,所加结果才正确):
符号位不变,然后:
1、原码求补码:(1)a 取反加一得b 或 (2)a减一取反得b
2、补码求原码:(逆2)b取反加一得a 或 (逆1)b减一取反得a
即不论原码求补码还是补码求原码,都可用取反加一或减一取反这两种方法(注:当然,符号位不参加运算)
注:移码——移码(又叫增码)是对真值补码的符号位取反(不管补码是正是负),一般用作浮点数的阶码,引入的目的是便于浮点数运算时的对阶操作。
11、一个负整数与它的补码间的相互转换:
求补码表示的整数:
- 非负整数的补码与原码一样,所以补码二进制串的值即为所求;
- 对于负整数,补码表示的整数可有两种求法:
- 1)转为原码再求和:不看符号位的二进制串按位取反后加1(或减一后按位取反),得到对应的十进制值,再加个负号;
- 2)直接计算:直接将补码里为1的位的权值“求和”——不过符号位的权值乘上-1,其他位的权值乘上1
关于2.2),实际意义可以联系现实中的时钟,补码的作用就是把倒退x格表示为进128-x格。
负数x->补码十进制值(不包括负号):x+128。(退|x|格等于进128+|x|格)
补码十进制值x(不包括负号)->负数:x-128。(进x格等于进x-128格,即退128-x格)
如补码10000111表示的数为7-128=-121(进7等于退121),-7的补码为11111001(退7等于进121),特别地,补码10000000表示的数为0-128=-128
12、printf
%5d:右对齐,左边不够不空格
%-5d:左对齐,右边不够不空格
int(4.7):4,强转直接截断;%.0f,4.7——>5,四舍五入
13、limits.h中定义了关于整型变量的取指范围
//注意 %u 与 %d //signed printf("%dB signed char :[%d,%d]\n",sizeof(char),SCHAR_MIN,SCHAR_MAX); printf("%dB signed short:[%d,%d]\n",sizeof(short),SHRT_MIN,SHRT_MAX); printf("%dB signed int :[%d,%d]\n",sizeof(int),INT_MIN,INT_MAX); printf("%dB signed long :[%ld,%ld]\n\n",sizeof(long),LONG_MIN,LONG_MAX); //unsigned printf("%dB usigned char :[%u,%u]\n",sizeof(char),0,UCHAR_MAX); printf("%dB usigned short:[%u,%u]\n",sizeof(short),0,USHRT_MAX); printf("%dB usigned int :[%u,%u]\n",sizeof(int),0,UINT_MAX); printf("%dB usigned long :[%lu,%lu]\n",sizeof(long),0,ULONG_MAX); //自己的方法获得unsigned的范围 printf("\n%dB usigned char :[%u,%u]\n",sizeof(char),0,(unsigned char)~0); printf("%dB usigned short:[%u,%u]\n",sizeof(short),0,(unsigned short)~0); printf("%dB usigned int :[%u,%u]\n",sizeof(int),0,(unsigned int)~0); printf("%dB usigned long :[%lu,%lu]\n",sizeof(long),0,(unsigned long)~0);
结果:
1B signed char :[-128,127] 2B signed short:[-32768,32767] 4B signed int :[-2147483648,2147483647] 4B signed long :[-2147483648,2147483647] 1B usigned char :[0,255] 2B usigned short:[0,65535] 4B usigned int :[0,4294967295] 4B usigned long :[0,4294967295] 1B usigned char :[0,255] 2B usigned short:[0,65535] 4B usigned int :[0,4294967295] 4B usigned long :[0,4294967295]
14、产生随机数:int rand(void),void srand(int seed)
srand(time(NULL));
rand()
15、c语言的 atol 函数与 strtol函数
// 将字符串转换成十进制长整数,直到遇到非数字字符为止;不支持将字母看成大于9的数字 long atol(const char* s); // 将字符串转换成十进制长整数,base为基数/进制[2,36],表示把待转换看做base进制数,base为0时自动根据s(0开头?,0x开头?)判断进制。支持将字母看成大于9的数字 // endptr指向未被识别的第一个字符 long strtol(const char*s, char** endptr, int base); long n1 = atol("13"); // n1 = 13 long n2 = atol("abc"); // n2 = 0 long n22 = atol("12abc"); // n22 = 12 long n23 = atol("012abc"); // n23=12,不会将012看成八进制 long n24 = atol("0x12abc"); // n24=0,同理,不会把0x12看成16进制 char* p = NULL; long n3 = strtol("123", &p, 10); // n3 = 123 long n4 = strtol("123", &p, 8); // n4 = 83 long n5 = strtol("123xyz", &p, 10); // n5 = 123, *p = x long n52 = strtol("012xyz", &p, 10); //n52=12 long n53 = strtol("0x12xyz", &p, 10); // n53=0 long n54 = strtol("012xyz", &p, 0); //n54=10,以0开头,自动按八进制解析 long n55 = strtol("0x12xyz", &p, 0); //n55=18,以0x开头,自动按十六进制解析 long n56 = strtol("12xyz", &p, 0); //n56=12,按十进制解析 实际上,有: long atol(const char* s); int atoi(const char *s) double atof(const char *s) long strtol(const char*s, char** endptr, int base); double strtod(const char *s,char **endptr) 后两者功能更强大,前3者可用后两者实现: atoi(s) <=> (int)strtol(s,(char **)NULL,10) atol(s) <=> (int)strtol(s,(char **)NULL,10) atof(s) <=> strtod(s,(char **)NULL)
16、负整数转正整数:
通常直接取反即可:n=-n;
但是,对于最大负整数转不了,如对于一个字节的有符号整数,范围为[-128,127],若果n=-128,则-n为128,超过了n能表示的范围,这点应注意
17、负整数取余运算%,与正整数一样,即不论正负,商的绝对值尽可能小(尽可能接近0)。如-5/2结果到底是-2还是-3,可以通过位操作验证:-5右移2位结果显然是-2
如-126%10=-12......-6 而不是 =-13......4;
8%3=2......2;
-8%3=-2......-2而不是-3......1
-8%-3=2......-2而不是3......1
18、一排数,里面除了一个数出现奇数次外其他均出现偶数次,如何快速找出这个独特的数?——所有数异或即可
19、parseInt函数可以将字符串转为整数
java中:Integer.parseInt(str,base)
javascript:parseInt(str,base)
base意为 str为base进制数,函数结果为该base进制数对应的十进制值
C中有类似的函数:strtol(*nptr,**endptr,base)转成长整数,endptr指向未被识别的第一个字符。如 char *endptr;strtol("1213ad",&endptr,4);——>103
21、当表达式中存在有符号数和无符号数类型时,所有的操作都自动转换为无符号类型。可见无符号数的运算优先级高于有符号数。
unsigned int a = 20; signed int b = -130; return a<b; //1
22、extern的使用:
1、可以用来声明在其他文件中定义的变量或函数(即将其他文件定义的函数或变量的作用域扩展到当前文件,include可以达到同样效果,但那样引入了很多不需要的东西)
2、可以用来声明同一个文件中先使用后定义的变量或函数。(要想先使用后定义函数,除了在使用前用extern声明外,也可以在使用前加函数原型声明)
1 #include<stdio.h> 2 int main() 3 { extern void mytest();//同一个文件中函数extern声明。若没有extern关键字也可以,此时相当于函数原型声明。 4 mytest();//函数先使用后定义 5 return 0; 6 } 7 void mytest() 8 { 9 extern int num;//同一个文件中变量extern声明 10 extern int data[];//同一个文件中变量extern声明。既然是“声明”,那就也可以不用写数组大小,但若写了大小就得跟后面定义里的大小一样,否则会报重复定义的错。 11 data[1]=20; 12 int a; 13 printf("\n%d %d %d\n",a,num,data[1]);//变量先使用后定义 14 } 15 int num=2; 16 int data[40];
23、C中的static。(局部变量存在栈中,动态申请的空间在堆中)
1、与extern相反,static限定所修饰的变量或函数的作用域,使其仅在定义它们的源文件内有效,其他文件内无法访问它们,这相当于面向对象中的private的功能!!
2、修饰局部变量时可提升局部变量的生存周期,使其在整个程序的生成周期内有效,但作用域仍只在所在的函数内。如果用户未初始化,则自动被初始化未0(这点与全局变量一样)示例如下:
#include <stdio.h> int test() { static int a=1; return a++; } int main() { printf("%d\n",test());//1 printf("%d\n",test());//2 return 0; }
24、寄存器变量:如register int x
register声明只适用于自动变量及形参,告诉编译器它所声明的变量在程序中使用频率较高,其思想是讲register变量放在机器的寄存器中,但编译器可以视情况忽略次选项。无论寄存器实际上是不是放在寄存器中,它的地址都是不能访问的。
25、C中变量一般分为四种:外部变量、静态变量、局部变量(自动变量)、寄存器变量。前两者初始化表达式必须是常量表达式。
C预处理器:
宏定义#define、#undef
#define max(a,b) ( (a)>(b) ? (a) : (b) ) x=max(p+q,r+s); <=> x=( (p+q)>(r+s) ? (p+q) : (r+s) ); //若形参名以#为前缀则结果将被扩展为由实际参数替代该形参的带引号的字符串,此可作为很有用的调试打印宏 #define dprint(expr) printf(#expr "= %g\n",expr) dprint(x/y); <=> printf("x/y" "=%g\n",x/y ) ; <=> dprintf("x/y=%g\n",x/y);
文件包含#include
条件包含#if、#elif、#else、#endif、#ifdef、#inndef等
(typedef也有文本替换功能,但其功能不是由预处理器而是由编译器完成的,其文本替换功能远超#define:1)可以为类型取别名提高可读性,如tree节点;2)可以使程序参数化以提高可移植性,如果typedef声明的数据类型与机器有关,当移植到其他机器时只需改变typedef定义即可,如标准库的size_t类型, typedef unsigned __int64 size_t; )
****第五章、指针与地址****
26、
(1)指针中&为取址运算符,&a得到a类型的指针,指向a;*为间接寻址(或称间接引用)运算符,如*p就是以指针变量值(地址)为地址的内存区域的值,即指针所指向的值。
(2)指针与数组:
数组名表示数组首元素的地址,一个通过数组名和下标实现的表达式可等价地用指针加偏移量实现,如 a[1]<=>*(a+1) , &a[1]<=>a+1 。通过数组下标能完成的所有操作都可以通过指针完成,且一般前者的执行速度比后者快。 C语言内部在取数组元素值时就是通过转换成指针加偏移量再取值的,因此a[-1]在语法上也没错,等价于*(a-1)。
把数组名传给函数实际上传的是该数组首元素的地址,所以不论形参是数组还是指针,实参只要传递地址语法上就没有错误。
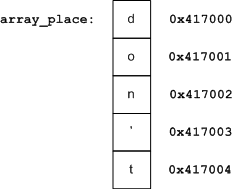
数组名和指针的区别:数组名表示数组首元素的地址,而指针则是一个变量,变量的内容为某个元素的地址。可通过如下两图看出区别:

(3)有效的指针运算:指针同整数加减;指向相同数组中元素的指针间的减法或比较;指针赋0或地址或指针与0比较(指针与整数不能相互转换,0除外,0代表NULL,C语言保证0永远不是有效的数据地址)。其他,如两指针加减乘除等运算都是非法的。
如下示例,本意是希望通过交换指针存的地址值实现swap,但是编译不能通过;再者,就算编译通过,函数也达不到期望的功能,因为地址也是传值传递进来的,在函数内部交换地址值堆外面没影响
void swap(int *a,int *b) { a^=b; b^=a; a^=b; }
再例:设low、high为指向数组首末元素的指针,求指向中点元素的指针,(low+high)/2是错的,因为两指针不允许加法运算,解决:low+(high-low+1)/2
(4)指针数组与数组指针:
指针数组(知道有几行):int * p[13]:是个一维数组,每个元素类型为 int * 。int a[3][4]; int *p[3]={a[0],a[1],a[2]};
数组指针(知道有几列):int (*p)[13](可以看成int p[][13]),是一个指针,指针类型为数组 int [13]。int a[3][4]; int (*p)[4]; p=a;(如果二维数组作为函数参数,则函数声明中必须指明该二维数组的列数,如void swap(char v[][10],int i,int j),可见相当于数组指针char (*v)[10])
由上可见,指针数组、数组指针都与二维数组有某些关联,示例如下:
1 int main() 2 { 3 int a[3][4]={ { 1,2,3,4},{ 5,6,7,8},{ 9,10,11,12}}; 4 int *p[3]={a[0],a[1],a[2]}; 5 int (*q)[4]=a; 6 int i,j; 7 for (i=0;i<3;i++) 8 { 9 for (j=0;j<4;j++) 10 { 11 printf("%d %d ",p[i][j],q[i][j]);//或*(*(p+i)+j),*(*(q+i)+j) 或*(p[i]+j),*(q[i]+j) 12 } 13 putchar('\n'); 14 } 15 return 0; 16 }
实际上,C语言数组访问方式本质就是指针访问,在C语言内部都转换为指针访问。对于二维来说,最后都转为上面的*(*(p+i)+j),*(*(q+i)+j)
(5)二维数组与指针数组
对于 int a[10][20] 与 int *b[10]; ,它们有相通之处如都可以通过a[2][3]、b[2][3]访问元素,但有本质区别:前者分配了10*20个int空间,后者分配了10个 int * 空间,若后者每个元素指向20个元素的int数组,则还分配10*20个int空间。
可见若用后者表示前者,则会多分配一些空间;后者的优点在于每个元素不必指向相同长度的数组,这在用于存储多个字符串时很有用,如char * argv[10]
(6)函数指针与函数:(任何类型的指针都可以转化为void * 类型,并且在将它转换回原来的类型时不会丢失信息)
函数:char *cmp(char *,char *);cmp是一个函数,返回值类型为char 指针
函数指针:int (*cmp)(void *,void *):cmp是个指向函数的指针,该函数具有两个void*类型的参数,其返回值类型为int。使用函数指针的一个示例是作为排序算法里排序规则参数,示例如下(在传 函数指针 形参对应的函数实参时不用取址运算符&):
#include <stdio.h> #include <ctype.h> void swap(void *data[],int i,int j) { void *temp; temp=data[i]; data[i]=data[j]; data[j]=temp; } void myGeneralQsort(void *data[],int left,int right,int(*cmp)(void *,void *)) { //要修改排序规则如升序或降序只需要修改传不同cmp函数即可 int i,last; if (left>=right) { return; } last=left; for (i=left+1;i<=right;i++) { if ((*cmp)(data[i],data[left])<0) { swap(data,++last,i); } } swap(data,left,last); myGeneralQsort(data,left,last-1,cmp); myGeneralQsort(data,last+1,right,cmp); } int strCmp(char *a,char *b) { return strcmp(a,b); } int main() { char *strData[]={ "hello","world","what is","black"}; int i; myGeneralQsort(strData,0,3,strCmp); for (i=0;i<4;i++) { printf("%s ",strData[i]); } return 0; }
(7)其他
printf的格式化参数可以是表达式:printf(a[0][0]>0 ? "yes:%d\n" : "no\n",a[0][0]);
字符串常量可整体赋给字符指针: char *str; str="hello world"; 实际上是将指向字符串常量第一个元素的指针赋给str,而若str是字符数组str[]则不能整体赋值。此外,str没法改变指向的常量字符串的个别字符值,这点也与字符数组不同。
****第六章、结构****
结构初始化:
struct point { int x;int y; }p1[]={ 1,1,2,2}, center1={ 2,2}; point center2={ 2,3}; point p2[]={ 1,1,2,2,3,3}; point p3[]={ { 1,1},{ 2,2},{ 3,3}};
27、联合、位字段是以结构为基础的数据结构,可以节省存储空间
结构体定义及内存空间分配原则见1、2、3
(1)在所有运算符中,结构运算符 “.” 和 “->” 、函数调用的 “()” 、用于下标的 “[]” 优先级最高
(2)sizeof是C语言提供的一个编译时一元运算符 而不是函数,返回无符号整型。条件编译语句#if中不能使用sizeof,因预处理器不对类型名进行分析;#define中则可
确定 int数组 data[]元素个数:
1)、sizeof(data)/sizeof(int):适用于不确定是否至少有一个元素;需要知道类型
2)、sizeof(data)/sizeof(data[0]):适用于至少有一个元素;不需要知道类型
注意sizeof的陷阱,常用它来计算数组的元素个数,但在函数里使用时实际上得到的是数组变量(指针)的大小而不是元素个数,示例:
1 void testSizeOfInFunction(int a[]) 2 { 3 int n=sizeof(a)/sizeof(int); 4 printf("in function:%d\n",n);//2,64位系统上指针占8B,int为4B,所以为2 5 } 6 7 int main() 8 { 9 int a[]={ 1,2,3,4,5,6,7}; 10 printf("in main: %d\n",sizeof(a)/sizeof(int));//7 11 testSizeOfInFunction(a); 12 13 char str1[]="good"; 14 char *str2="good"; 15 printf("%d %d\n",sizeof(str1),sizeof(str2));// 5 8 16 return 0; 17 }
注意:
1.sizeof是个操作符而不是函数,其在编译时就完成了计算,而在编译时函数testSizeOfInFunction里的a只是个变量并没有实参,所以sizeof(a)得到的是该变量(指针)的大小。
2.对字符串使用sizeof包含'\0',而strlen遇到'\0'时停止并且长度不包含'\0'。
1 char a="good"; 2 sieof(a);//5 3 strlen(a);//4
5 char b="good\0now";
6 strlen(b);//4
3.sizeof的参数可以是表达式但不会计算表达式(编译器在编译阶段就根据表达式“最宽”变量的类型确定结果大小,编译后表达式就不存在了因此不会求值)、sizeof的参数亦可为函数调用但实际上函数不会被调用而是根据函数返回值类型确定sizeof的值。示例:
1 int foo1() {printf("foo1");} 2 void foo2(){printf("foo2");}; 3 double * foo3(){printf("foo3");return NULL;} 4 int main() 5 { 6 int n=2; 7 printf("%d\n",sizeof(1+1));//4 8 printf("%d\n",sizeof((short)1));//2 9 printf("%d\n",sizeof((short)1+1.2f));//4,最"宽"的类型 10 printf("\n"); 11 12 printf("%d\n",sizeof(n++));//4,不会对表达式进行操作,所以n还是2 13 printf("%d\n",n);//2 14 printf("\n"); 15 16 printf("%d\n",sizeof(foo1()));//4,结果是函数返回类型的大小,函数不会被调用即不会输出 "foo1" 17 printf("%d\n",sizeof(foo2()));//1 18 printf("%d\n",sizeof(foo3()));//8 19 20 return 0; 21 }
(3)自引用:包含有自身实例的结构是非法的,但是可以有指向自身结构类型的指针,也可以两个结构相互引用(指针)
struct node { int value; struct node a;//包含自身实例,非法 struct node *b;//指向结构类型的指针,合法 struct edge *e; } struct edge { int value; struct node *n;//n和e相互引用 }
(4)联合:联合与结构类似,不同的是其各成员共享内存,相对于基地址的偏移量都为0;其所占大小要大到足够容纳最“宽”的成员;且对齐方式要适合于联合中的所有类型的成员(即不是单纯地取最大字节的变量就完事)。
可以通过联合判断处理器的大端或小端:[ 大端小端取决于CPU架构,power pc,aix等是大端,arm,Intel(x86系列等),amd是小端 ]
(在windows上测试如下)
#include <stdio.h> union u_tag { int a; char b; }u; int main() { //method 1 int a=0x12345678; printf("%x\n",*(short *)&a);//5678,小端 //method 2 u.a=1; printf("%x\n",u.b);//1,小端 //method 3 int b=1; printf("%d\n",((char *)&b)[0]);//1,小端 return 0; }
(5)位字段:与结构一样,不同的是在定义时需要指定成员所占的位数,与基本数据类型类似,可以把位字段看成特殊的一种数据类型,只不过其占落干位。(实际上,位字段所提供的功能也可以通过位操作自己实现)
主要用于一些使用空间很宝贵的程序中,如嵌入式程序。对于位字段中的成员不能用位操作符进行运算也不能使用&取址,因为它们没有地址。考虑到字节存放的大端小端的问题,使用位字段定义的数据不能在不同字节顺序的机器之间移动。因此,从理论上来说,使用位字段的程序是不可移植的。
1 struct Bit { 2 int b8: 1; 3 int b7: 1; 4 int b6: 1; 5 int b5: 1; 6 int b4: 1; 7 int b3: 1; 8 int b2: 1; 9 int b1: 1; 10 char aa; 11 float bbb; 12 } B; 13 int main() 14 { 15 unsigned char *p = NULL; 16 printf("size:%d\n",sizeof(struct Bit));//8:int 8位小于4字节、char 1字节对齐后4字节、float 4字节 17 B.b1 = 1; B.b2 = 1; B.b3 = 1; B.b4 = 1; B.b5 = 1; B.b6 = 1; B.b7 = 1; B.b8 = 1; 18 p = (unsigned char *)&B; 19 printf("%d\n", *p); /* 255 */ 20 21 B.b1 = 0; B.b2 = 0; B.b3 = 0; B.b4 = 0; B.b5 = 0; B.b6 = 0; B.b7 = 0; B.b8 = 1; 22 p = (unsigned char *)&B; 23 printf("%d\n", *p); /* 1 */ 24 25 B.b1 = 0; B.b2 = 0; B.b3 = 0; B.b4 = 0; B.b5 = 1; B.b6 = 1; B.b7 = 1; B.b8 = 1; 26 p = (unsigned char *)&B; 27 printf("%d\n", *p); /* 15 */ 28 29 B.b1 = 0; B.b2 = 1; B.b3 = 1; B.b4 = 1; B.b5 = 1; B.b6 = 1; B.b7 = 1; B.b8 = 1; 30 p = (unsigned char *)&B; 31 printf("%d\n", *p); /* 127 */ 32 return 0; 33 }
****第七章、输入与输出****
28、
(1)printf、fprintf 格式输出:%[flags][width][.perc][ d|i|u|o|x|c|s|f ]。 (int printf(char *format, arg1, arg2, ...),返回值为打印的字符数,包括'\0',数有多位算多个字符)
总:flags:负左对齐正右对齐;width:至少占width位;perc:精度要perc位,小数为位数,整数为位数不够补前0,字符串为字符个数。
i与d无异,是旧式写法;输出时不管是float还是double都用f,输入则分别为f、lf;可以用"%%"打印"%"自身。
printf的格式%a.b_(a表示至少占a位,负左对齐正右对齐;b对于_的不同有不同意义。_处可为d、i、u、o、x,c、s、f 等)
%a.bc、%a.bf已熟知,前者b参数没用,后者表示小数精确到b位
%a.bs:b表示最多打印b个字符
%a.bd(或i、u、o、x):b表示至少打印b个字符,不够补前导0
a、b也可以用*代替,然后动态确定:printf("%*.*d",a,b,num);位数不够自动补前导0的方法:printf("%.5d %05d\n",12,4);//00012 00004
示例:
#include <stdio.h> #include <stdlib.h> int main(int argc,char *argv[]) { char s[]="hello"; //%a.bc:a可正可负,b非负;a为负左对齐,否则右对齐,b摆设 printf("%3.1c\n",'a'); //%a.bs:a可正可负,b非负;最少占a位,最多打b个字符,a为负左对齐,否则右对齐 printf("%.3s",s);printf("aaa\n"); printf("%-8.7s",s);printf("bbb\n"); printf("%8.3s",s);printf("ccc\n"); //%a.bd、%a.bu、%a.bo;%a.bx:a可正可负,b非负;最少占a位,至少打b位,不够补前导0,a为负左对齐,否则右对齐 printf("%5.3o\n",34); //%a.bf:a可正可负,b非负;最少占a位,小数b位 printf("%6.3f\n",2.2457); printf("%*.*d\n",5,5,34);//位数a、b可以动态决定:printf("%*.*d",a,b,num) return 0; }
结果:
a helaaa hello bbb helccc 042 2.246 00034
(2)scanf、fscanf、sscanf 格式输入:% [*] [2] [l] [ d|i|u|o|x|c|s|f|集合 ]。 (int scanf(char *format, ...),返回正确读入的个数,若到达文件末尾,返回EOF;format后的参数都必须是指针)
与格式输出printf等的交集在于d、f...几个字符,此外无。有各自的特别之处,printf如上述,scanf 如下(注意,printf、fprintf并没有如下这些特性):
1)%nd 表示读入不超过n位。如scanf("%2d",&a),输入为1234时a为12
2)读入字符串支持集合操作:
%[a-z]:从首字符起的连续字符串,仅包含字母 a 到 z
%[az]:从首字符起的连续字符串,仅包含字母 a 和 z
%[^a-z]:从首字符起的连续字符串,遇到字母 a 到 z 之一停止。这里a-z也可以为若干个字符,如 a 或 abcd
3)* 表示跳过此数据不读入,也就是不把此数据读入参数中
合理使用这三者,可以当“正则”使用,甚至可以通过scanf、sscanf、printf等实现复杂的功能,如后缀表达式计算等。一些例子如下:
char s[20]; sscanf("123456abcd","%[1-4a-z]",s); printf("%s\n",s);//1234 s[0]='\0'; sscanf("123456abcd","%[14az]",s); printf("%s\n",s);//1 s[0]='\0'; sscanf("123456abcd","%[^3-4]",s); printf("%s\n",s);//12 s[0]='\0'; sscanf("a123456abcd","%[3-4]",s); printf("%s\n",s);//空,虽然串中有34但不是从首字符起的 s[0]='\0'; sscanf("123456abcd","%3[0-9a-z]",s); printf("%s\n",s);//123,限定最多读取3个字符 s[0]='\0'; sscanf("a123456,abcd","%*c%s",s); printf("%s\n",s);//123456,abcd,* 表示跳过此数据不读入. (也就是不把此数据读入参数中) s[0]='\0'; sscanf("iios/12DDWDFF@122","%*[^/]/%[^@]",s); printf("%s\n",s);//12DDWDFF,综合使用,某种程度上可以充当正则使用 s[0]='\0';
(3)其他
char *ss="st%dr2\n"; printf(ss);//ss中若包含格式符%,如%d,则可能由于后面没有对应的参数而出错,所以不要这样写,而是用格式串 printf("%s",ss);
//printf可以自动把多个字符串连在一起输出 printf("a " " program");//"a program"
| stdin/stdout | stream | |
| 读入一字符 | getchar | getc/fgetc |
| 读入一字符 | putchar | putc/fputc |
| 读入一行 | gets | fgets |
| 读入一行 | puts | fputs |
读入一行时,gets会删掉结尾的'\n'、puts会在写入字符串时在结尾添加一个'\n';fget、fputs则原样读入、原样输出。对比如下:
1 #include <stdio.h> 2 #include <string.h> 3 int main() 4 { 5 char s[10]; 6 gets(s); 7 puts(s); 8 printf("%d\n",strlen(s)); 9 10 fgets(s,100,stdin); 11 fputs(s,stdout); 12 printf("%d\n",strlen(s)); 13 return 0; 14 } 15 16 两次都输入"a bcd"的运行结果: 17 a bcd 18 a bcd 19 5//说明'\n'不算在内 20 a bcd 21 a bcd 22 6//说明'\n'算在内
(4)变长参数表:参数格式和类型可变。stdarg.h中包含一组宏定义,对如何遍历参数表进行定义。C的变长参数表应至少有一个有名参数,省略号只能出现在尾部
以下在不同的编译器有不同的实现,但接口一致:
- va_list类型:用于定义一个变量ap,将依次引用各参数(包括有名、无名参数),相当于参数指针。处理三步骤:
- va_start(ap,namedPara):将ap初始化为指向一个有名参数。在处理格式串前,必须将ap指向最后一个有名参数
- va_arg(ap,type):将ap指向下一个参数(有名或无名),并返回其值
- va_end(ap):完成一些必要的清理工作
以vc6.0编译器为例:
#include <stdio.h> #include <stdarg.h> void printIntArgs(int arg1, ...) /* 输出所有int类型的参数,直到-1结束 */ { //变长参数表处理 va_list ap; int i; va_start(ap, arg1); for (i = arg1; i != -1; i = va_arg(ap, int)) printf("%d ", i); va_end(ap); putchar('\n'); } void myPrintf(int a,char *format,...) { //变长参数表处理 char *p; va_list ap;//参数指针 va_start(ap,a);//初始化ap,指向某个有名参数 printf("%s\n",va_arg(ap,int));//再次调用后,ap指向最后一个有名参数。 //在处理格式串前,必须将ap指向最后一个有名参数 for (p=format;*p;p++) { if (*p!='%') { putchar(*p); continue; } switch(*++p) { case 'd': printf("%d",va_arg(ap,int)); break; case 'f': printf("%f",va_arg(ap,double)); break; case 's': printf("%s",va_arg(ap,char *)); break; case 'c': printf("%c",va_arg(ap,char)); break; } } va_end(ap); } void myScanf(char *format,...) { //变长参数表处理 char *p; va_list ap;//参数指针 //在处理格式串前,必须将ap指向最后一个有名参数 va_start(ap,format); for (p=format;*p;p++) { if (*p!='%') { continue; } ++p; switch(*p) { //myScanf实参如&a传的是地址,所以里面参数值就是地址值,因此调用scanf时只要能按指针4字节得到其值即可 case 'd': scanf("%d",va_arg(ap,void *)); break; case 'f': scanf("%f",va_arg(ap, void *)); break; case 's': scanf("%s",va_arg(ap,void *)); break; case 'c': scanf("%c",va_arg(ap,void *)); break; } } va_end(ap); } int main() { printargs(2,1,3,4,-1); myprintf(3," char:%c\n int:%d\n double%f\n string:%s\n",'ab',12,12.2,"hello"); return 0; } //结果 1 3 4 char:%c int:%d double%f string:%s char:b int:12 double12.200000 string:hello Press any key to continue
29、ungetc(int c,FILE *fp):将读出的数据放回到缓冲区去,下一次读数据时,再次读出来。可压入到缓冲区的字符数与缓冲区中已输出字符数有关?
FILE *fp=fopen("file2.txt","r+");//文件file2.txt的内容:jklmn putc(getc(fp),stdout);//j putc(getc(fp),stdout);//k ungetc ('e', fp); ungetc ('f', fp); ungetc ('g', fp); putc(getc(fp),stdout);//f putc(getc(fp),stdout);//e putc(getc(fp),stdout);//l ungetc ('a', fp); ungetc ('b', fp); ungetc ('c', fp); printf ("%c", getc(fp));//c printf ("%c", getc(fp));//b printf ("%c", getc(fp));//a printf ("%c", getc(fp));//m printf ("%c", getc(fp));//n
30、存储函数管理:malloc、realloc、calloc、free、memset
1)void *malloc(size_t n)
从堆中动态分配n字节大小的空间,成功返回首地址,失败返回NULL;
由于malloc函数值的类型为void型指针,因此,可以将其值类型转换后赋给任意类型指针,这样就可以通过操作该类型指针来操作从堆上获得的内存空间;
分配得到的内存空间未初始化,可以用 C++中的memset(见后面)来初始化,或用会自动初始化的calloc
2)void * realloc(void * p,int n)
将p指向的对象空间的大小调节为n字节,成功返回首地址,失败返回NULL;
p应为指向堆空间的指针(即指向动态分配空间对象),若p为空,则重新分配一块新的区域;
分配得到的空间也是未初始化的
int * p; p=(int *)malloc(sizeof(int)); *p=3; printf("p=%p\n",p);//p=004D2EC8 printf("*p=%d\n\n",*p);//*p=3 p=(int *)realloc(p,sizeof(int)); printf("p=%p\n",p);//p=004D2EC8 printf("*p=%d\n\n",*p);//*p=3 p=(int *)realloc(p,3*sizeof(int)); printf("p=%p\n",p);//p=004D2EC8 printf("*p=%d\n\n",*p);//*p=3 p=(int *)realloc(NULL,3*sizeof(int)); printf("p=%p\n",p);//p=004D06D0 printf("*p=%d\n",*p);//*p=-842150451 //释放p指向的空间 realloc(p,0); p=NULL;
3)void *calloc(int n,int size)
分配n个大小为size字节的空间,相当于malloc(n*size),成功返回首地址,失败返回NULL;p=(int *)calloc(SIZE,sizeof(int));
自动初始化为0
4)memset(void *p,int ch,size_t n):将指针p指向的对象的前面n个字节的每个字节以ch代替
int * p=NULL; p=(int *)malloc(3*sizeof(int));//malloc不能自动初始化 if(NULL==p){ printf("Can't get memory!\n"); return -1; } printf("%d\n\n",*p);//未初始化的不定乱值-842150451 memset(p,1,2*sizeof(int)); //用c++的函数memset初始化前两个数 printf("%d\n",*p);//初始化值16843009 printf("%d\n",p[1]==0x01010101);//1,说明每个字节被0x01代替 printf("%d\n",p[2]);//未初始化乱值-842150451 *(p+2)=2; printf("%d\n\n",p[2]);//2 free(p);//动态分配者在程序结束前必须释放,否则内存泄露 printf("%d\n",*p);;//乱值-572662307。free后指针仍指向原来指向的地方,为野指针
5)free(*p)释放指针p指向的动态申请的空间,free后p仍指向原来指向的地方,但不能再访问p指向的对象,否则系统会报错,指向的对象空间(堆中)被OS回收,值有没有被改看系统的实现。这时p为野指针,一般还要置空:p=NULL
31、几个有用的整数位运算:
1)x&(x-1) 可以用来去掉整数x的二进制形式的最后一个1。
以之为基础,有个妙用:判断一个正数x(x>0)是不是2的n次方:return (x&(x-1)==0);
2)取反操作:-x=~x+1=~(x-1)
3)除数是2的整数倍时的求余操作:a%b 等于 a &(b-1),注意只有当b为2的整数倍时才成立。
4)将整数x除最后一个1外其他位都置为0: x & (-x),如当x为6时候该式结果为2
5)无分支取绝对值:
int intAbs(int x)//x为最小负数时得到的结果仍未该负数,只能将之赋给更大的类型来避免 { //无分支取绝对值 int y=x>>(8*sizeof(x)-1); return (x^y)-y;//(x+y)^y; //或 return x<0? (~x+1):x; }
6)两整数取均值,一般是(x+y)/2,但可能溢出。可用位运算代之,但注意,其和不能为负,否则结果有误:
int intAverage(int x,int y) { //x,y和为负时会出错,如-4、3结果会得到-1,正确为0 return ( (x & y) + ( (x^y) >>1 )); }
32、void qsort(void *base, size_t n,size_t size, int (*cmp)(const void *,const void *))
对base[n]进行排序,每个元素的大小siezeof(base[0])为size
** 关于快排函数的一些说明 ** qsort,包含在stdlib.h头文件里,函数一共四个参数,没返回值.一个典型的qsort的写法如下 qsort(s,n,sizeof(s[0]),cmp); 其中第一个参数是参与排序的数组名(或者也可以理解成开始排序的地址,因为可以写&s[i] 这样的表达式,这个问题下面有说明); 第二个参数是参与排序的元素个数; 第三个三数是 单个元素的大小,推荐使用sizeof(s[0])这样的表达式,下面也有说明 :) ;第四个参数就是 很多人觉得非常困惑的比较函数啦,关于这个函数,还要说的比较麻烦... 我们来讨论cmp这个比较函数(写成cmp是我的个人喜好,你可以随便写成什么,比如qcmp什么 的).典型的cmp的定义是 int cmp(const void *a,const void *b); 返回值必须是int,两个参数的类型必须都是const void *,那个a,b是我随便写的,个人喜好. 假设是对int排序的话,如果是升序,那么就是如果a比b大返回一个正值,小则负值,相等返回 0,其他的依次类推,后面有例子来说明对不同的类型如何进行排序. 在函数体内要对a,b进行强制类型转换后才能得到正确的返回值,不同的类型有不同的处理 方法.具体情况请参考后面的例子. ** 关于快排的一些小问题 ** 1.快排是不稳定的,这个不稳定一个表现在其使用的时间是不确定的,最好情况(O(n))和最 坏情况(O(n^2))差距太大,我们一般说的O(nlog(n))都是指的是其平均时间. 2.快排是不稳定的,这个不稳定表现在如果相同的比较元素,可能顺序不一样,假设我们有 这样一个序列,3,3,3,但是这三个3是有区别的,我们标记为3a,3b,3c,快排后的结果不一定 就是3a,3b,3c这样的排列,所以在某些特定场合我们要用结构体来使其稳定(No.6的例子就 是说明这个问题的) 3.快排的比较函数的两个参数必须都是const void *的,这个要特别注意,写a和b只是我的 个人喜好,写成cmp也只是我的个人喜好.推荐在cmp里面重新定义两个指针来强制类型转换, 特别是在对结构体进行排序的时候 4.快排qsort的第三个参数,那个sizeof,推荐是使用sizeof(s[0])这样,特别是对结构体, 往往自己定义2*sizeof(int)这样的会出问题,用sizeof(s[0)既方便又保险 5.如果要对数组进行部分排序,比如对一个s[n]的数组排列其从s[i]开始的m个元素,只需要 在第一个和第二个参数上进行一些修改:qsort(&s[i],m,sizeof(s[i]),cmp); ** 标程,举例说明 ** No.1.手工实现QuickSort #include <stdio.h> int a[100],n,temp; void QuickSort(int h,int t) { if(h>=t) return; int mid=(h+t)/2,i=h,j=t,x; x=a[mid]; while(1) { while(a[i]<x) i++; while(a[j]>x) j--; if(i>=j) break; temp=a[i]; a[i]=a[j]; a[j]=temp; } a[mid]=a[j]; a[j]=x; QuickSort(h,j-1); QuickSort(j+1,t); return; } int main() { int i; scanf("%d",&n); for(i=0;i<n;i++) scanf("%d",&a[i]); QuickSort(0,n-1); for(i=0;i<n;i++) printf("%d ",a[i]); return(0); } No.2.最常见的,对int数组排序 #include <stdio.h> #include <string.h> #include <stdlib.h> int s[10000],n,i; int cmp(const void *a, const void *b) { return(*(int *)a-*(int *)b); } int main() { scanf("%d",&n); for(i=0;i<n;i++) scanf("%d",&s[i]); qsort(s,n,sizeof(s[0]),cmp); for(i=0;i<n;i++) printf("%d ",s[i]); return(0); } No.3.对double型数组排序,原理同int 这里做个注释,本来是因为要判断如果a==b返回0的,但是严格来说,两个double数是不可能相等的,只能说fabs(a-b)<1e-20之类的这样来判断,所以这里只返回了1和-1 #include <stdio.h> #include <stdlib.h> double s[1000]; int i,n; int cmp(const void * a, const void * b) { return((*(double*)a-*(double*)b>0)?1:-1); } int main() { scanf("%d",&n); for(i=0;i<n;i++) scanf("%lf",&s[i]); qsort(s,n,sizeof(s[0]),cmp); for(i=0;i<n;i++) printf("%lf ",s[i]); return(0); } No.4.对一个字符数组排序.原理同int #include <stdio.h> #include <string.h> #include <stdlib.h> char s[10000],i,n; int cmp(const void *a,const void *b) { 0 return(*(char *)a-*(char *)b); } int main() { scanf("%s",s); n=strlen(s); qsort(s,n,sizeof(s[0]),cmp); printf("%s",s); return(0); } No.5.对结构体排序 注释一下.很多时候我们都会对结构体排序,比如校赛预选赛的那个樱花,一般这个时候都在 cmp函数里面先强制转换了类型,不要在return里面转,我也说不清为什么,但是这样程序会 更清晰,并且绝对是没错的. 这里同样请注意double返回0的问题 #include <stdio.h> #include <stdlib.h> struct node { double date1; int no; } s[100]; int i,n; int cmp(const void *a,const void *b) { struct node *aa=(node *)a; struct node *bb=(node *)b; return(((aa->date1)>(bb->date1))?1:-1); } int main() { scanf("%d",&n); for(i=0;i<n;i++) { s[i].no=i+1; scanf("%lf",&s[i].date1); } qsort(s,n,sizeof(s[0]),cmp); for(i=0;i<n;i++) printf("%d %lf\n",s[i].no,s[i].date1); return(0); } No.6.对结构体排序.加入no来使其稳定(即data值相等的情况下按原来的顺序排) #include <stdio.h> #include <stdlib.h> struct node { double date1; int no; } s[100]; int i,n; int cmp(const void *a,const void *b) { struct node *aa=(node *)a; struct node *bb=(node *)b; if(aa->date1!=bb->date1) return(((aa->date1)>(bb->date1))?1:-1); else return((aa->no)-(bb->no)); } int main() { scanf("%d",&n); for(i=0;i<n;i++) { s[i].no=i+1; scanf("%lf",&s[i].date1); } qsort(s,n,sizeof(s[0]),cmp); for(i=0;i<n;i++) printf("%d %lf\n",s[i].no,s[i].date1); return(0); } No.7.对字符串数组的排序(char s[][]型) #include <stdio.h> #include <string.h> #include <stdlib.h> char s[100][100]; int i,n; int cmp(const void *a,const void *b) { return(strcmp((char*)a,(char*)b)); } int main() { scanf("%d",&n); for(i=0;i<n;i++) scanf("%s",s[i]); qsort(s,n,sizeof(s[0]),cmp); for(i=0;i<n;i++) printf("%s\n",s[i]); return(0); } No.8.对字符串数组排序(char *s[]型) #include <stdio.h> #include <string.h> #include <stdlib.h> char *s[100]; int i,n; int cmp(const void *a,const void *b) { return(strcmp(*(char**)a,*(char**)b)); } int main() { scanf("%d",&n); for(i=0;i<n;i++) { s[i]=(char*)malloc(sizeof(char)); scanf("%s",s[i]); } qsort(s,n,sizeof(s[0]),cmp); for(i=0;i<n;i++) printf("%s\n",s[i]); return(0); }
33、(&a得到a类型的指针,指向a。如对于int a; &a得到 int *类型的指针)
把浮点数在计算机内部的表示当成整数对应的值
#include <stdio.h> int getInt(float num) { return *(int *) # } float getFloat(int num) { return *(float *) # } int main(void) { float num=1.5f; printf("%d\n",getInt(num)); printf("%f\n",getFloat(getInt(num))); return 0; }
打印各种数据对象的字节表示:(long和指针占的字节数为机器字长,long long为8B)
1 #include<stdio.h> 2 typedef unsigned char * byte_pointer; 3 4 void show_bytes(byte_pointer start,int len) 5 { 6 int i; 7 for(i=0;i<len;i++) 8 { 9 //printf("%.2x ",start[i]); 10 printf("%.2x ",*(start+i)); 11 } 12 printf("\n"); 13 } 14 15 void show_short(short x){ 16 show_bytes((byte_pointer)&x,sizeof(short)); 17 } 18 19 void show_int(int x){ 20 show_bytes((byte_pointer)&x,sizeof(int)); 21 } 22 23 void show_long(long x){ 24 show_bytes((byte_pointer)&x,sizeof(long)); 25 } 26 27 void show_longlong(long long x){ 28 show_bytes((byte_pointer)&x,sizeof(long long)); 29 } 30 31 void show_float(float x){ 32 show_bytes((byte_pointer)&x,sizeof(float)); 33 } 34 35 void show_double(double x){ 36 show_bytes((byte_pointer)&x,sizeof(double)); 37 } 38 39 void show_pointer(void *x){ 40 show_bytes((byte_pointer)&x,sizeof(void *)); 41 } 42 43 int main(){ 44 int val=128; 45 46 show_short((short)val); 47 show_int(val); 48 show_long(val);//long所占字节数为机器字长,32位机4B,64位机8B 49 show_longlong(val);//long long占8B 50 show_float((float)val); 51 show_double((double)val); 52 show_pointer(&val);//指针所占字节数为机器字长,32位机4B,64位机8B 53 }
34、以O(lgn)复杂的计算a^n
1 //1.直接n-1次乘法,O(n) 2 //2.a^n=(a^(n/2))*(a^(n/2)) (n为偶数) 或 a*(a^(n/2))*(a^(n/2)) (n为奇数),O(n) 3 //3.a^n=(a^(n/2))^2 (n为偶数) 或 a*(a^(n/2))^2 (n为奇数),与直接乘n-1次比可以以最多两次乘法的代价减半问题规模,O(lgn) 4 int pow1(int a,int n) 5 { 6 if(n==0) return 1; 7 int p=pow1(a,n/2); 8 if(n%2==0) return p*p; 9 else return p*p*a; 10 } 11 12 //4.a^n=(a^2)^(n/2) (n为偶数) 或 a*(a^2)^(n/2) (n为奇数),与直接乘n-1次比可以以最多两次乘法的代价减半问题规模,O(lgn) 13 int pow2(int a,int n) 14 { 15 if (n==0) return 1; 16 if(n%2==0) return pow2(a*a,n/2); 17 else return a*pow2(a*a,n/2); 18 }
35、位运算求模:对于b%a ,当a为2^k的倍数时,b/a=b>>k、b%a=b&(a-1)
36、进程同步与互斥(详见:那些烦人的同步与互斥问题)
进程临界区互斥的实现:
//此函数中的三条指令须是“原子”执行的,也就是说不会被打断
bool TestAndSet(bool *lock){ bool rv = *lock; *lock = true; return tv; }
使用:
bool lock = false; while(TestAndSet(&lock)){ ;//什么也不做 } 临界区; lock = false; 剩余区;
进程同步(同步是一种更特殊的互斥,也就是生产者消费者问题)的实现:信号量
37、C/C++中没有逻辑右移符号“>>>”(Java有),对于右移只有符号“>>”,其既可表示算术右移又可表示逻辑右移。C标准没有明确定义应该使用哪种右移,但一般来说编译器/机器都对有符号数使用算术右移,对无符号数使用逻辑右移。如:
unsigned char a=128; printf("%u\n",a>>2);//32 printf("%d\n",((char)a)>>2);//-32
38、递归版整数转字符串(可以处理最大负数)
1 void itoa(int n) 2 { 3 static int isNegative=1; 4 if(isNegative && n<0) 5 { 6 putchar('-'); 7 isNegative=0; 8 } 9 if(n/10) 10 { 11 itoa(n/10); 12 } 13 putchar(fabs(n%10)+'0'); 14 }
39、关于传值、传址
所谓传值、传址,是指调用函数时传入的实参是 变量的内容(或称变量的值) 还是 变量的位置(或称变量的地址)。对于前者,在被调用函数里是没法改变实参变量的值的,而后者则可以。
对Java来说,只有传值这一方式,因此无论如何都没有办法在被调用的函数里改变实参变量的值。
根据参数类型的不同,传的“值”的含义也不同,具体来说:
1、若参数是基本数据类型,则传的为变量的值。如int、long等
2、若参数是对象类型,则传的为引用(即对象的地址)。此时在被调用函数里虽然没法改变实参变量的值(即让该实参变量指向其他对象),但却可通过该引用改变实参变量指向的对象的内容。
对于String、基本数据类型包装类如Integer 等immutable类型,虽然也为对象类型,但因为其没有提供自身修改的函数,每次操作都是新生成一个对象,所以要特殊对待。可以认为是传值,因此没办法在函数里改变引用对象的内容。
示例:
1 class Person { 2 public String name = "LiMing"; 3 } 4 class TestCase { 5 public static void test(Person p, Integer count, String address) { 6 p.name = "XiaoLi"; 7 p = null; 8 count = 2; 9 address = "Beijing"; 10 } 11 public static void main(String[] args) { 12 Person person = new Person(); 13 Integer count = 1; 14 String address = "Shanghai"; 15 System.out.println(person.name + " " + (person == null) + " " + count + " " + address);// LiMing false 1 Shanghai 16 test(person, count, address); 17 System.out.println(person.name + " " + (person == null) + " " + count + " " + address);// XiaoLi false 1 Shanghai 18 } 19 }
Java对变量值的解析方式:
若变量是基本数据类型,则直接使用该值进行加减等操作;
若变量是对象类型,则把该值当做地址,需要一次据之进行一次寻址才能拿到要进行加减等操作的值。
对C来说,除了传值外,还有传址方式,因此能在被调用函数里改变实参变量的值。
1、若参数是基本数据类型,则为传值,如int、long等
2、若参数是指针类型,且实参是一个指针变量,则在被调用函数里无法改变实参即该变量的内容但可以改变该变量指向的对象的内容。这相当于上述Java里的引用情形。
特别地,若实参是形如 &a 这样取值运算符加变量的形式,则实参的值会被改变,此即传址。实际上,对变量取址就隐含得到了指向该变量的指针,所以函数里能够改变该指针指向的对象的内容即变量的值。
示例:如下所示,传指针变量a时调用前后指针变量a的内容不变但其指向的对象的内容变了;传&d2前后d2的内容变了。
1 void test(int * p,int *q) 2 { 3 *p=10; 4 *q=20; 5 } 6 int main() 7 { 8 int d1=1,d2=2; 9 int *a=&d1; 10 11 printf("%p\n",a);//000000000062FE1C 12 test(a,&d2); 13 printf("%p\n",a);//000000000062FE1C 14 printf("%d %d %d\n",*a,d1,d2);//10 10 20 15 16 return 0; 17 }
40、C99标准允许数组动态定义,即动态确定数组大小,如 int foo(int n) { int a[n]; return 1; } ,注意需要编译器支持。
41、关于C/C++中的内存分配:(全局变量、静态变量、局部变量等)
1、静态存储区:静态变量、常量、全局变量分配在静态存储区,这块内存在程序编译时就已经分配好,且在程序的整个运行期间都存在。(对于一个具体程序而言,包括data段和bss段)
2、栈区:函数(包括main函数)内部的变量及其存储单元分配在栈上(任何局部变量都处于栈区,如int a[]={1,2};,变量a及1、2都处于栈区),这块内存在运行时随着函数调用和调用结束而自动分配和释放。栈内存分配运算置于处理器的指令集中,效率很高,但可分配容量有限。
3、堆区:程序在运行时用malloc或new申请的内存(即动态内存分配)在堆区。这块内存由程序员负责申请并在适当时用free或delete释放,生存期完全由程序员决定,若没释放则在程序结束时自动释放。
(上述分配位置与Java中的方法区、栈、堆类比:Java中全局变量、静态变量、局部变量等都在栈区,变量指向的对象在堆区、动态分配的对象在堆区)
由此引申出char *a与char a[]的区别:(分配位置、读写能力、存取效率)
char *a="abc"; 中"abc"是常量,存放在静态存储区,因此内存大小在编译时就分配好,且通过指针a只能读而不能改变每个字符;
char a[]="abc"; 中"abc"存放在栈中,在运行时分配,可以通过指针a来读取和修改每个字符;由于存于栈上,效率比上者快。
42、Linux中C/C++程序的内存布局:(5段)
1、text段(代码段/正文段):存放程序的二进制执行代码,只读,在程序运行前即已确定,是共享的(如在父子进程中共享代码段)。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
2、data段(初始化数据段):存放已初始化的静态变量和已初始化全局变量,在程序运行前即已确定。
3、bss段(未初始化数据段):存放未初始化的静态变量和未初始化的全局变量,在程序运行前即已确定。
4、stack段(栈段)
5、heap段(堆段)
在Linux下可以用size命令看一个c/c++程序中前三段的大小,示例:
1 ivic@test39:~/imtg/testhehe$ size a.out 2 text data bss dec hex filename 3 1837 612 4 2453 995 a.out
43、enum类型占用的内存空间大小由枚举值列表里的最大值确定。
1 //enum为枚举常量,枚举值是常量整型值的列表,分别用一个枚举名表示,若没有显示指定每个枚举名对应的值,则默认为0起。 2 enum e1{e1a,e1b};//枚举名对应的值分别为0,1,用int够表示 3 enum e2{e2a,e2b=0x800000000};//枚举名对应的值分别为0,0x800000000,后者超过四字节由int表示不了,需要用long long(32位机下)或long(64位机下) 表示 4 5 printf("%d\n",sizeof(e1));//4 6 printf("%d\n",sizeof(e2));//8
1 struct A 2 { 3 char a; 4 double b; 5 enum color{red=111111,yellow};//定义了enum类型,没定义变量,不占内存 6 }; 7 struct B 8 { 9 char a; 10 double b; 11 enum color{red=111111,yellow} c;//定义了enum类型和变量 12 }; 13 struct C 14 { 15 char a; 16 enum color{red=111111,yellow=0x1234567890} c;//定义了enum类型和变量 17 }; 18 19 printf("%d\n",sizeof(A));//16=8+8 20 printf("%d\n",sizeof(B));//24=8+8+8 21 printf("%d\n",sizeof(C));//16=8+8
44、浮点数(IEEE 754标准规定了浮点数在计算机内部的表示。参考:IEEE754浮点数表示方法)
1、浮点数的表示(三部分):
a)符号位S:1位负,0位正;
b)阶码E(非负,[0,255] 或 [0,2047]):指数x的移码-1,也即x+2n-1=x+127或x+1023。(移码即补码符号位取反,引入的目的是便于浮点数运算时的对阶操作)
c)尾数M:规格化为1.xyz的形式,只保存xyz。如(1.75)10=(1.11)2×21,从而尾数部分只保存最后的两个1。
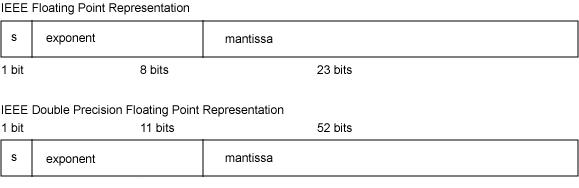
因此,一个规格化的32位浮点数的机器码对应的真值为:x=(-1)S× 2(E-127)× (1.M),一个规格化的64位浮点数的机器码对应的真值为:x=(-1)S× 2(E-1023)× (1.M)。
如对于单精度(0.5)10=(0.1)2,符号位为0、指数为-1、规格化后的尾数为1.0。故阶码为-1+127=126=[0111 1110]2、尾数为[000...00]2,所以0.5=[0 01111110 000...00]2;
对于单精度的(2.25)10=(10.01)2,符号位为0、指数为1、规格化后尾数为1.001。故阶码为1+127=128=[1000 0000]2、尾数为[0010...00]2,所以2.25=[0 10000000 0010...00]2;
对于单精度的(-12.5)10=(-1100.1)2,符号位为1、指数为3、规格化后的尾数为1.1001。故阶码为3+127=130=[1000 0010]2、尾数为[10010...00]2,所以-12.5=[1 10000010 10010...00]2。验证: float a= -12.5f; int * pa=( int *)&a; printf("%x\n",*pa);//c1480000
2、浮点数的范围(下面以32位单精度浮点数为例,由于x=(-1)S× 2(E-127)× (1.M),且阶码E范围为[0,28-1]、尾数M范围为[0,223-1]/223):
a)特殊数的表示:从上述机器码对应的真值可以看出,IEEE754标准无法精确表示0。因此,IEEE754标准规定阶码为0或255的特殊情况来表示这些数:
若阶码E=0且尾数M=0,则规定此数表示±0(正负号和数符位有关),即+0的机器码为0 00...00,-0的机器码为1 00...00。故计算机内部无法表示精确的浮点数0,其实际值分别为1.0*2-127、-1.0*2-127。
若阶码E=255且尾数M=0,则规定次数表示±无穷。即正无穷的机器码为0 11111111 00...00,负无穷的机器码为1 11111111 00...00。故正负无穷的实际值分别为1.0*2128、-1.0*2128。
若阶码E=255且尾数M!=0,则这不是一个数(NaN)。
b)范围(除去E为0和255这两种特殊情况):
最大正数:符号位S=0,阶码E=254,尾数M=11..11,即机器码为0 11111110 11...11,故浮点数最大正数为(1.11...11)2*2127≈3.402832e+38;
最小正数:符号位S=0,阶码E=1,尾数M=00..00,即机器码为0 00000001 00...00,故浮点数最大正数为(1.0)2*2-126≈1.175494e-38;
最小负数、最大负数于最大正数、最小正数对应,只是符号位S=1。即最小负数、最大负数分别为-3.402832e+38、-1.175494e-38;
2、浮点数的精度
浮点数的精度是指浮点数的小数位所能表达的位数。
以32位浮点数为例,尾数域有23位。那么浮点数以二进制表示的话精度是23位,23位所能表示的最大数是223−1=8388607,所以十进制的尾数部分最大数值是8388607,也就是说尾数数值超过这个值,float将无法精确表示,所以float最多能表示小数点后7位,但绝对能保证的为6位,也即float的十进制的精度为为6~7位。
64位双精度浮点数的尾数域52位,因252−1=4,503,599,627,370,495,所以双精度浮点数的十进制的精度最高为16位,绝对保证的为15位,所以double的十进制的精度为15~16位。。
浮点数的表示范围由阶码(用整数形式表示,阶码指明小数点在数据中的位置,决定了浮点数的表示范围)确定、精度由尾数(用定点小数形式表示,尾数部分给出有效数字的位数,决定了浮点数的表示精度)确定。