python中数据分析的流程为-用Python进行数据分析-1-程序员宅基地
第一章 准备工作
1.3 重要的python数据库
Numpy:是python科学计算的基础包,本书大部分内容都基于numpy以及构建于其上的库功能如下:
-快速高效的多维数组对象ndarray。
-用于对数组执行元素级计算以及直接对数组执行数学运算的函数
-用于读写硬盘上基于数组的数据集的工具
-线性代数运算、傅立叶变换、以及随机数的生成
-成熟的c API,用于python插件和原生的c c++ fortran代码访问numpy的数据结构和计算工具
pandas:提供了快速便捷处理结构化数据的大量数据结构和函数。本书使用最多的pandas对象时dataframe,它是一个面向列(column-oriented)的一个二维表结构,另一个是series,一个一维的标签化数组对象,pandas兼具numpy高性能的数组计算功能以及电子表格和关系型数据库(如sql)灵活的数据处理功能。它提供了复杂精细的索引功能,以便于更为便捷的的完成重塑、切片和切换,聚合以及选取数据子集的操作,因为数据操作、准备、清洗是数据分析最重要的技能。pandas是本书的重点。
-功能:为一款适用于金融和商业分析的工具
-有标签化的数据结构,支持自动或清晰的数据对齐,这可以防止由于数据不对齐和处理来源不同的索引,不同的数据造成的错误。
-集成时间序列功能
-相同的数据结构用于处理时间序列数据和非时间序列数据
-保存元数据的算数运算和压缩
-灵活处理缺失的数据
-合并和其他流行的数据库(例如基于sql的数据库)的关系操作
matplotlib:是最流行的用于绘制图表和其他二维数据的可视化python库。非常适合用于创建出版物上用的图表。
-Scipy:是一组专门解决科学计算中各种标准问题域的包的集合,包括下列包:
-Scipy.integrate:数值积分例程和微分方程求解器。
-Scipy.linalg:扩展了由numpy.linalg提供的线性代数例程和矩阵分解功能。
-Scipy.optimize:函数优化器(最小化器)以及根查找算法
-Scipy.signal:信号处理工具
-Scipy.sparse:稀疏矩阵和稀疏线性系统求解器。
-Scipy.stats:标准连续和离散概率分布(如密度分布、采样器、连续分布函数等)、各种统计检验方法以及更好的描述性统计法
-numpy和scipy结合使用,便形成了一盒相当完备和成熟的计算平台,可以处理所中传统的科学计算的问题
scikit-learn:是python通用的机器学习工具包。子模块包括:
-分类:svm,近邻,随机森林,逻辑回归等等
-回归:lasso,岭回归等等
-聚类:k-均值,谱聚类等等
-降维:pca、特征选择,矩阵分解等等
-选型:网格搜索,交叉验证、度量。
-预处理:特征提取,标准化。
stats models:是一个统计分析包,包含经典统计学和计量经济学的算法,有以下子模块:
-回归模型:线性回归,广义线性模型,健壮线性模型,线性混合效应模型等等。
-方差分析anova
-时间序列分析:ar arma arima var 和其他模型
-非参数方法:核密度估计,核回归。
-统计模型结果可视化。
第二章 python语法基础,ipython,jupyter
自省:在变量的前后使用?,可显示对象的信息:
b = [1,2,3]
b?
-使用??会显示函数的源码
-?还有一个用途,就是搜索Ipython的命名空间。字符和通配符结合,可以匹配所有的名字。
%run命令:可以用来运行所有的python程序,假设有一个python文件:shili.py,可以如下运行:
%run shili.py
-这段脚本运行在空的命名空间,因此结果和普通的运行方式python script.py相同,文件中所有定义的变量(import,函数和全局变量,除非报错了)都可以在ipython命令中随后访问。
*笔记:如果向让一个脚本访问ipython中已经定义过的变量,可以使用%run -i,在jupyter中,你也可以使用%load,它将脚本倒入到一个代码格子中:
-中断运行中代码:按ctrl-c
从剪切板执行程序:
%paste#%paste可以直接运行剪切板中的代码
%cpaste#%cpaste有类似的功能,但是会给出一条提示
键盘快捷键

魔术命令:ipython中特殊的命令,被称作魔术命令,这些命令可以使普通的任务更快捷,更容易控制ipython系统,魔术命令难过是在指令之前添加%的前缀。例如,可以用%timeit会测量任何python语句的执行时间,魔术命令可以看作是ipython中运行的命令行,许多魔术命令有命令行选项,可以通过?查看。魔术函数默认可以不使用%前缀,但是不能有变量和函数名称相同,这个特点被称为自动魔术,可以使用%automatic打开和关闭。一些魔术函数和python函数很像,他的结果可以直接赋值给一个变量。
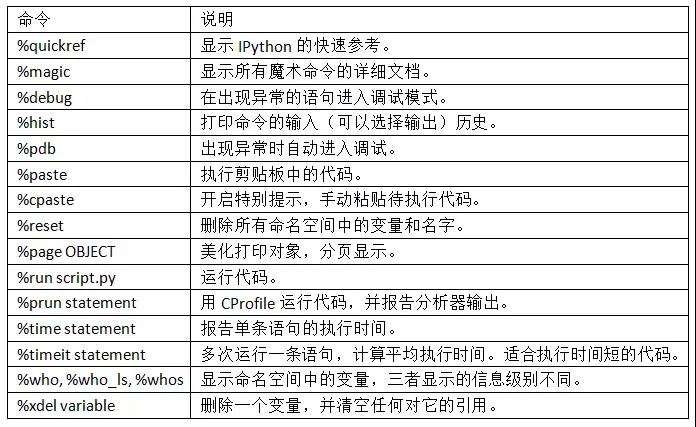
一些常用的ipython魔术命令:
集成matplotlib:ipython在分析极端领域能够流行的原因之一是它非常好的集成了数据可视化和其他用户界面,比如matplotlib
-在IPython shell中,运行%matplotlib可以进行设置,可以创建多个绘图窗口,而不会干扰控制台session:
%matplotlib
Using matplotlib backend: Qt4Agg
-在jupyter中命令有所不同:
%matplotlib inline
import matplotlib,pyplot as plt
plt.plot(np.random.randn(50).cumsum())
可变对象与不可变对象:python中的大多数对象都是可变的,比如列表,字典,numpy数组,和用户定义的类型(类)都是可变的,其他的,例如字符串和元组,是不可变的。
字节和unicode:假定知道字符编码,可以将其转换为unicode,例如:
val = “dhfhfff”
val
-可以用encode将这个unicode字符串编码为utf-8:
val_utf8 = val.encode("utf8’)
-如果你知道一个字节对象的unicode编码,用decode方法可以解码:
val_utf8.decode("utf8’)
-工作中碰到的文件很多都是字节对象,盲目的将所有数据编码为unicode是不可取的。虽然用的不多,但是你可以在字节文本的前面加上一个b:
a = b"this is shuju’
b"this is shuju’
decoded = a.decode(’utf8’)
"this is shuju’
日期和时间:python内建函数的datetime模块提供了datetime,date和time类型。datetime类型结合了date和time,是最常用的:
from date time import date time, date,time
dt = datetime(20,11,10,29,20,30,21)
print(day)
print(minute)
-根据datetime实例,你可以用date和time提取各自的对象:
print(dt.data)#输出dt.date()为(20,11,10,29)
print(dt.time)#输出dt.time为(20,30,21)
#strftime方法可以将detetime格式化为字符串
#strptime可以将字符串转换为datetime对象
-当你聚类活着对时间序列进行分组,替换datetime的time字段有时候会很有用,例如,用0替换分和秒:
dt.replace(minute=0,second=0)
print(datatime.datatime)#输出datetime.datetime为(2011,10,29,20,0)
-因为datetime是不可变类型上面的方法会产生一个新的对象。两个datetime对象的差会产生一个datetime类型,结果(17,7179)指明了将17天7179秒的编码方式。
第三章 python的数据结构、函数和文件
排序:sort()
-可以用sort将一个列表进行原地排序(不创建新的对象)
-sort有一些可选参数,例如sort(key=len)可以按照字符串的长度对字符串进行排序
-sorted函数———稍后学习
二分搜索和维护已排序的列表:bisect()
-bisect模块支持二分查询,和向已经排序的列表中插入值。bisect.bisect可以找到插入值后先不插入,而是返回可以插入的位置下标。保持排序的位置。bisect.insort是向可以插入的这个位置插入值:
*注意:bisect模块不会检查列表是否已经排了序,因此,对没有排序的列表进行操作,不会报错,但是结果不一定正确
切片:列表名称(开始位置下标:结束位置下标)例如:list(1:5)
-切片还可以被序列赋值:
list = 【1,2,3,4,5,6】
list[3:4]= [6,3]#会将列表list中位置下标为3的元素换成列表[6,3]也就是说,序列赋值之后的list比原来的列表多了一个元素。
-开始位置的下标和结束位置的下表都可以省略,此时,默认开头和结尾———负数表明从后向前切片
-还可以设置切片的步长:list【1:2:2】的意思是,切下来list列表中下标为1到2的内容,切片方法为隔一个取一个。当第三个参数为-1的话,可以将原来的列表颠倒过来。
智能推荐
从零开始搭建Hadoop_创建一个hadoop项目-程序员宅基地
文章浏览阅读331次。第一部分:准备工作1 安装虚拟机2 安装centos73 安装JDK以上三步是准备工作,至此已经完成一台已安装JDK的主机第二部分:准备3台虚拟机以下所有工作最好都在root权限下操作1 克隆上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;1.1 进行克隆21.2 下一步1.3 下一步1.4 下一步1.5 根据子机需要,命名和安装路径1.6 ..._创建一个hadoop项目
心脏滴血漏洞HeartBleed CVE-2014-0160深入代码层面的分析_heartbleed代码分析-程序员宅基地
文章浏览阅读1.7k次。心脏滴血漏洞HeartBleed CVE-2014-0160 是由heartbeat功能引入的,本文从深入码层面的分析该漏洞产生的原因_heartbleed代码分析
java读取ofd文档内容_ofd电子文档内容分析工具(分析文档、签章和证书)-程序员宅基地
文章浏览阅读1.4k次。前言ofd是国家文档标准,其对标的文档格式是pdf。ofd文档是容器格式文件,ofd其实就是压缩包。将ofd文件后缀改为.zip,解压后可看到文件包含的内容。ofd文件分析工具下载:点我下载。ofd文件解压后,可以看到如下内容: 对于xml文件,可以用文本工具查看。但是对于印章文件(Seal.esl)、签名文件(SignedValue.dat)就无法查看其内容了。本人开发一款ofd内容查看器,..._signedvalue.dat
基于FPGA的数据采集系统(一)_基于fpga的信息采集-程序员宅基地
文章浏览阅读1.8w次,点赞29次,收藏313次。整体系统设计本设计主要是对ADC和DAC的使用,主要实现功能流程为:首先通过串口向FPGA发送控制信号,控制DAC芯片tlv5618进行DA装换,转换的数据存在ROM中,转换开始时读取ROM中数据进行读取转换。其次用按键控制adc128s052进行模数转换100次,模数转换数据存储到FIFO中,再从FIFO中读取数据通过串口输出显示在pc上。其整体系统框图如下:图1:FPGA数据采集系统框图从图中可以看出,该系统主要包括9个模块:串口接收模块、按键消抖模块、按键控制模块、ROM模块、D.._基于fpga的信息采集
微服务 spring cloud zuul com.netflix.zuul.exception.ZuulException GENERAL-程序员宅基地
文章浏览阅读2.5w次。1.背景错误信息:-- [http-nio-9904-exec-5] o.s.c.n.z.filters.post.SendErrorFilter : Error during filteringcom.netflix.zuul.exception.ZuulException: Forwarding error at org.springframework.cloud..._com.netflix.zuul.exception.zuulexception
邻接矩阵-建立图-程序员宅基地
文章浏览阅读358次。1.介绍图的相关概念 图是由顶点的有穷非空集和一个描述顶点之间关系-边(或者弧)的集合组成。通常,图中的数据元素被称为顶点,顶点间的关系用边表示,图通常用字母G表示,图的顶点通常用字母V表示,所以图可以定义为: G=(V,E)其中,V(G)是图中顶点的有穷非空集合,E(G)是V(G)中顶点的边的有穷集合1.1 无向图:图中任意两个顶点构成的边是没有方向的1.2 有向图:图中..._给定一个邻接矩阵未必能够造出一个图
随便推点
MDT2012部署系列之11 WDS安装与配置-程序员宅基地
文章浏览阅读321次。(十二)、WDS服务器安装通过前面的测试我们会发现,每次安装的时候需要加域光盘映像,这是一个比较麻烦的事情,试想一个上万个的公司,你天天带着一个光盘与光驱去给别人装系统,这将是一个多么痛苦的事情啊,有什么方法可以解决这个问题了?答案是肯定的,下面我们就来简单说一下。WDS服务器,它是Windows自带的一个免费的基于系统本身角色的一个功能,它主要提供一种简单、安全的通过网络快速、远程将Window..._doc server2012上通过wds+mdt无人值守部署win11系统.doc
python--xlrd/xlwt/xlutils_xlutils模块可以读xlsx吗-程序员宅基地
文章浏览阅读219次。python–xlrd/xlwt/xlutilsxlrd只能读取,不能改,支持 xlsx和xls 格式xlwt只能改,不能读xlwt只能保存为.xls格式xlutils能将xlrd.Book转为xlwt.Workbook,从而得以在现有xls的基础上修改数据,并创建一个新的xls,实现修改xlrd打开文件import xlrdexcel=xlrd.open_workbook('E:/test.xlsx') 返回值为xlrd.book.Book对象,不能修改获取sheett_xlutils模块可以读xlsx吗
关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题_unresolved attribute reference 'find_element_by_id-程序员宅基地
文章浏览阅读8.2w次,点赞267次,收藏656次。运行Selenium出现'WebDriver' object has no attribute 'find_element_by_id'或AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'等定位元素代码错误,是因为selenium更新到了新的版本,以前的一些语法经过改动。..............._unresolved attribute reference 'find_element_by_id' for class 'webdriver
DOM对象转换成jQuery对象转换与子页面获取父页面DOM对象-程序员宅基地
文章浏览阅读198次。一:模态窗口//父页面JSwindow.showModalDialog(ifrmehref, window, 'dialogWidth:550px;dialogHeight:150px;help:no;resizable:no;status:no');//子页面获取父页面DOM对象//window.showModalDialog的DOM对象var v=parentWin..._jquery获取父window下的dom对象
什么是算法?-程序员宅基地
文章浏览阅读1.7w次,点赞15次,收藏129次。算法(algorithm)是解决一系列问题的清晰指令,也就是,能对一定规范的输入,在有限的时间内获得所要求的输出。 简单来说,算法就是解决一个问题的具体方法和步骤。算法是程序的灵 魂。二、算法的特征1.可行性 算法中执行的任何计算步骤都可以分解为基本可执行的操作步,即每个计算步都可以在有限时间里完成(也称之为有效性) 算法的每一步都要有确切的意义,不能有二义性。例如“增加x的值”,并没有说增加多少,计算机就无法执行明确的运算。 _算法
【网络安全】网络安全的标准和规范_网络安全标准规范-程序员宅基地
文章浏览阅读1.5k次,点赞18次,收藏26次。网络安全的标准和规范是网络安全领域的重要组成部分。它们为网络安全提供了技术依据,规定了网络安全的技术要求和操作方式,帮助我们构建安全的网络环境。下面,我们将详细介绍一些主要的网络安全标准和规范,以及它们在实际操作中的应用。_网络安全标准规范