25 Redis的缓存中的数据和数据库中的不一致问题_redis缓存和数据库不一致解决-程序员宅基地
25 Redis的缓存中的数据和数据库中的不一致问题
前言
Redis 缓存经常会遇到有 4 个方面:
- 缓存中的数据和数据库中的不一致;
- 缓存雪崩;
- 缓存击穿;
- 缓存穿透。
只要我们使用 Redis 缓存,就会面对缓存和数据库间的一致性保证问题。如果数据不一致,业务应用从缓存中读取的数据就不是最新数据。比如,把电商商品的库存信息缓存在 Redis 中,如果库存信息不对,那么业务层下单操作就可能出错。
一、缓存和数据库的数据不一致是如何发生的?
数据一致性包含两种情况:
- 缓存中有数据,缓存的数据值需要和数据库中的值相同;
- 缓存中本身没有数据,数据库中的值必须是最新值。
不符合这两种情况的就属于缓存和数据库的数据不一致问题了。当缓存的读写模式不同时,缓存数据不一致的发生情况不一样,应对方法也会有所不同,根据是否接收写请求,把缓存分成读写缓存和只读缓存。
读写缓存:
如果要对数据进行增删改,就需要在缓存中进行,根据采取的写回策略,决定是否同步写回到数据库中:
- 同步直写策略:写缓存时也同步写数据库,缓存和数据库中的数据一致;要想保证缓存和数据库中的数据一致,就要采用同步直写策略。需要同时更新缓存和数据库。所以要在业务应用中使用事务机制,来保证缓存和数据库的更新具有原子性,两者要不一起更新,要不都不更新返回错误信息,进行重试。否则就无法实现同步直写。
- 异步写回策略:写缓存时不同步写数据库,等到数据从缓存中淘汰时再写回数据库。 如果数据还没有写回数据库,缓存就发生了故障,数据库就没有最新的数据了。 对数据一致性的要求可能不是那么高,比如,缓存的是电商商品的非关键属性或者短视频的创建或修改时间等,可以使用异步写回策略。
只读缓存:
如果有数据新增,会直接写入数据库; 而有数据删改时,把只读缓存中的数据标记为无效。应用后续再访问这些增删改的数据时,因为缓存中没有相应的数据,就会发生缓存缺失。应用再从数据库中把数据读入缓存,这样后续再访问数据时,就能够直接从缓存中读取了。
Tomcat 向 MySQL 中写入和删改数据,如下图:
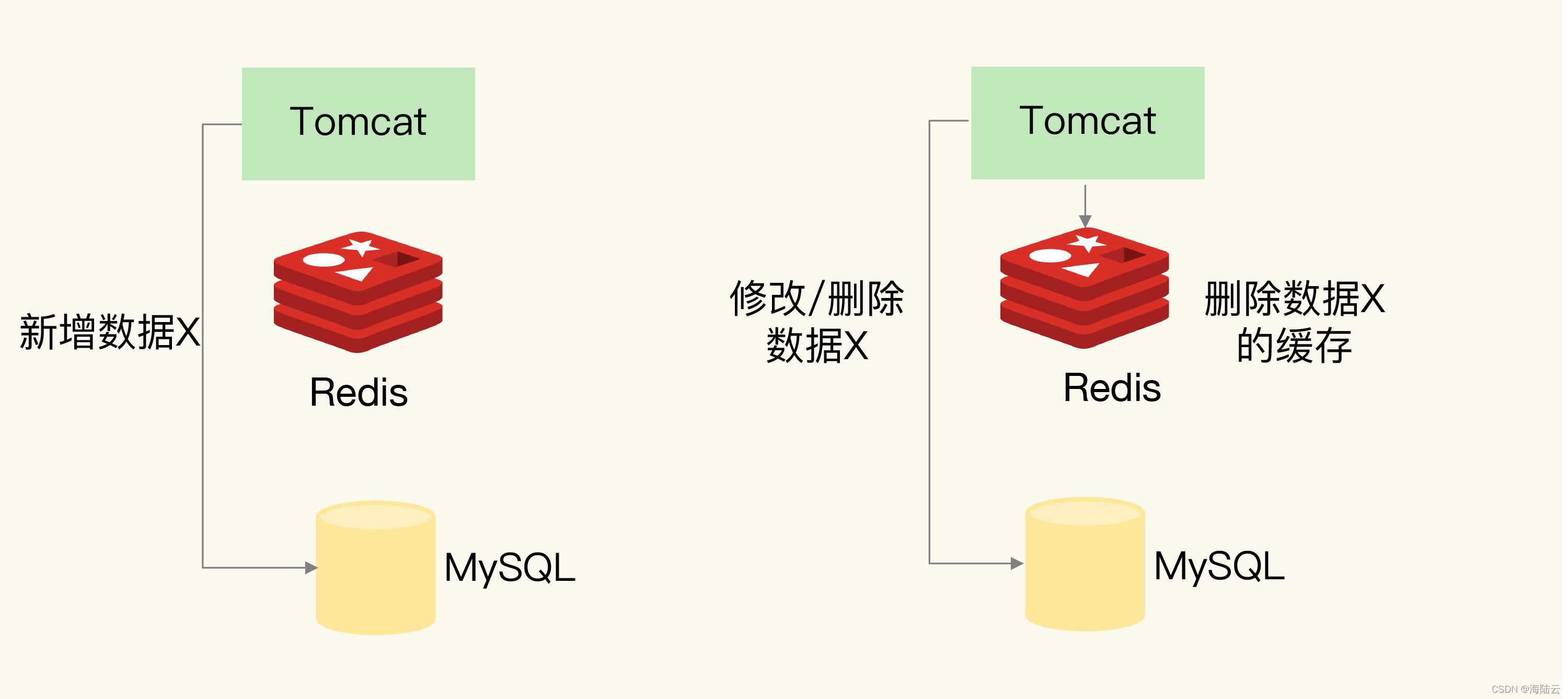
Tomcat 上运行的应用,无论是新增(Insert 操作)、修改(Update 操 作)、还是删除(Delete 操作)数据 X,都会直接在数据库中增改删。如果应用执行的是修改或删除操作,还会删除缓存的数据 X。
新增数据和删改数据的数据不一致的情况:
- 新增数据 :数据会直接写到数据库中,不用对缓存做任何操作,缓存中本身就没有新增数据,而数据库中是最新值,符合一致性的第 2 种情况,缓存和数据库的数据是一致的。
- 删改数据 :应用既要更新数据库,也要在缓存中删除数据。这两个操作如果无法保证原子性,就会出现数据不一致问题了。
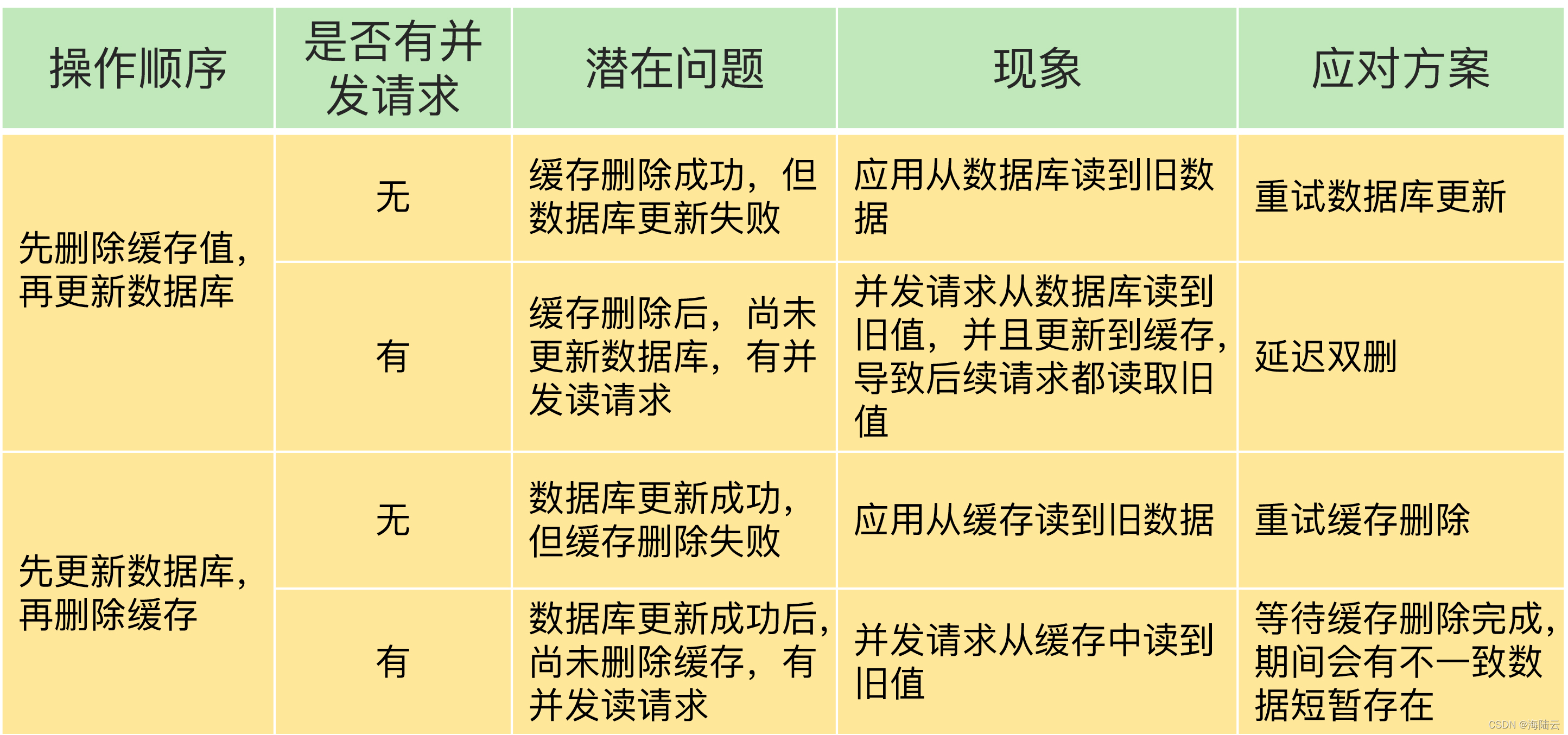
应用先删除缓存,再更新数据库: 如果缓存删除成功,但是数据库更新失败,应用再访问数据时,缓存中没有数据,就会发生缓存缺失。应用再访问数据库,但是数据库中的值为旧值,应用就访问到旧值了。
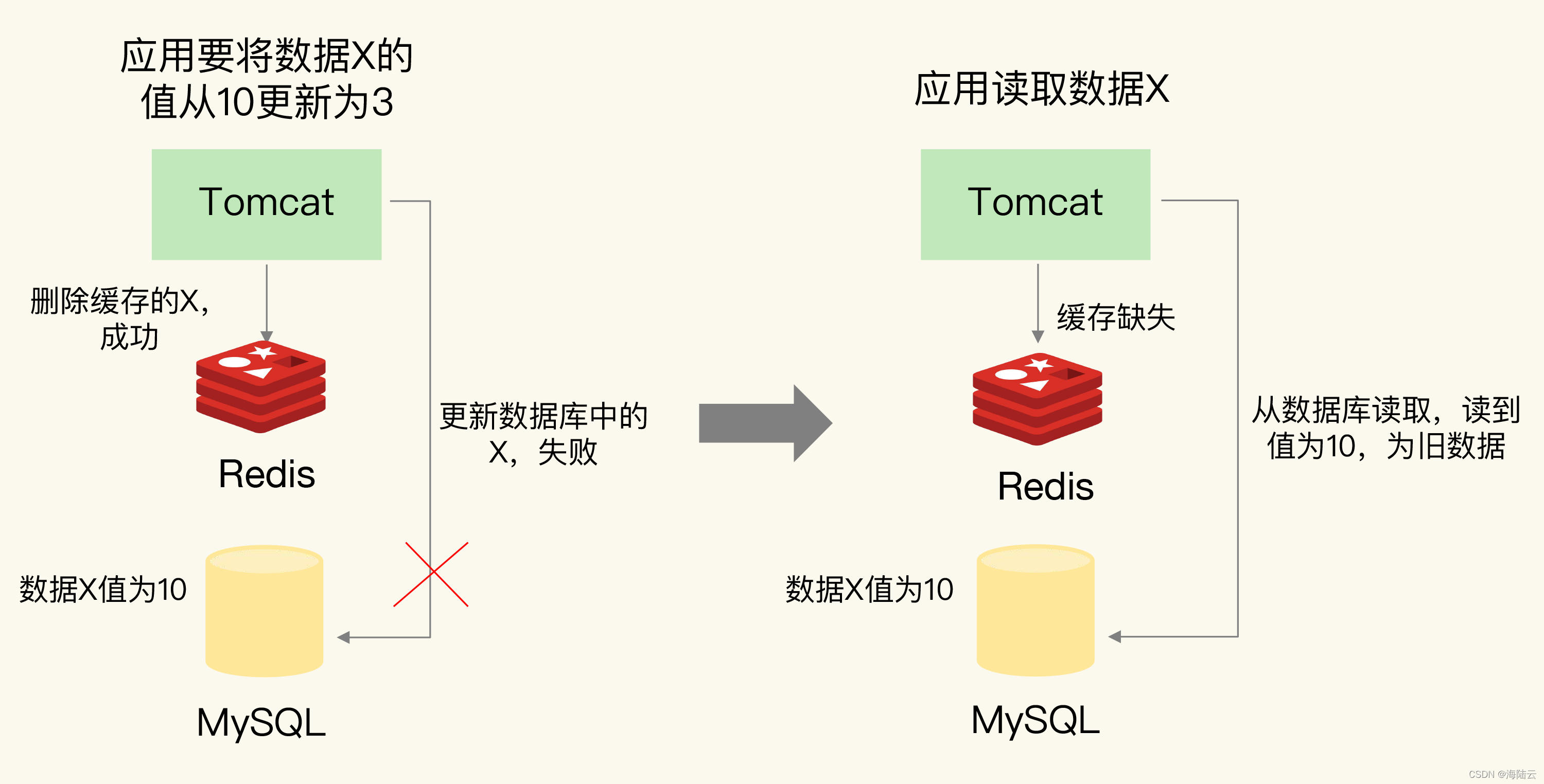
应用把数据 X 的值从 10 更新为 3,先在 Redis 缓存中删除了 X 的缓存值,但是更新数据库却失败了。如果有其他并发的请求访问 X,会发现 Redis 中缓存缺失, 请求就会访问数据库,读到的却是旧值 10。
如果先更新数据库,再删除缓存中的值: 如果应用先完成了数据库的更新,但是在删除缓存时失败了,数据库中的值是新值,而缓存中的是旧值。如果有其他的并发请求来访问数据,按照正常的缓存访问流程,就会先在缓存中查询读到旧值了。
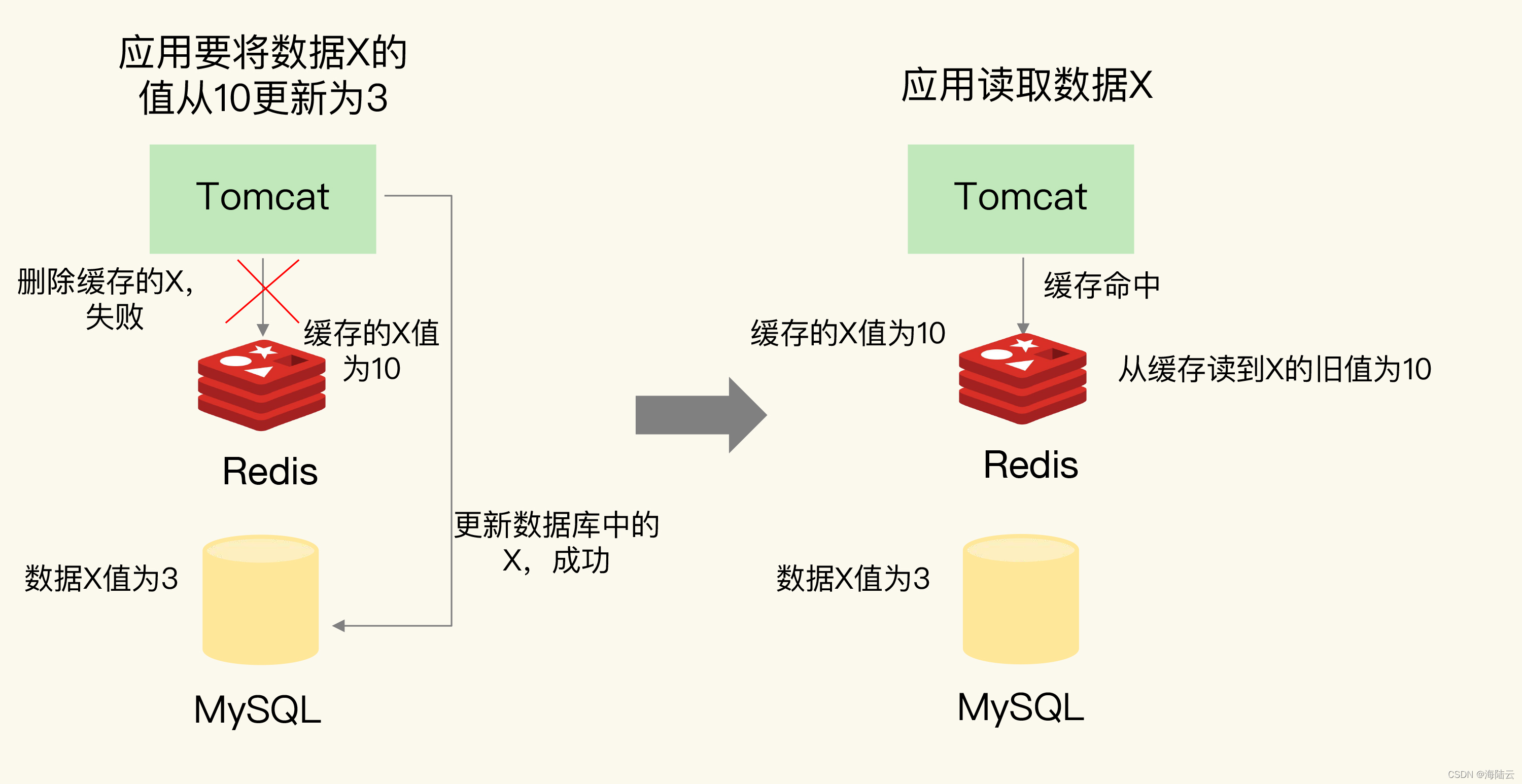
应用要把数据 X 的值从 10 更新为 3,先成功更新了数据库,然后在 Redis 缓存中删除 X 的缓存,但是这个操作却失败了,数据库中 X 的新值为 3,Redis 中的 X 的缓存值为 10。如果有其他客户端也发送请求访问 X,会先在 Redis 中查询,发现缓存读到的却是旧值 10。
在更新数据库和删除缓存值的过程中,无论这两个操作的执行顺序谁先谁后,只要有一个操作失败了,导致客户端读取到旧值。

二、解决Redis 和数据库数据不一致的方法
重试机制:
把要删除的缓存值或者是要更新的数据库值暂存到消息队列中。
- 如果没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。
- 如果能够成功地删除或更新,要把这些值从消息队列中去除,以免重复操作,保证数据库和缓存的数据一致了。否则的话还需要再次进行重试。 如果重试超过的一定次数,还是没有成功,就需要向业务层发送报错信息了。先更新数据库,再删除缓存值时,如果缓存删除失败,再次重试后删除成功的情况:
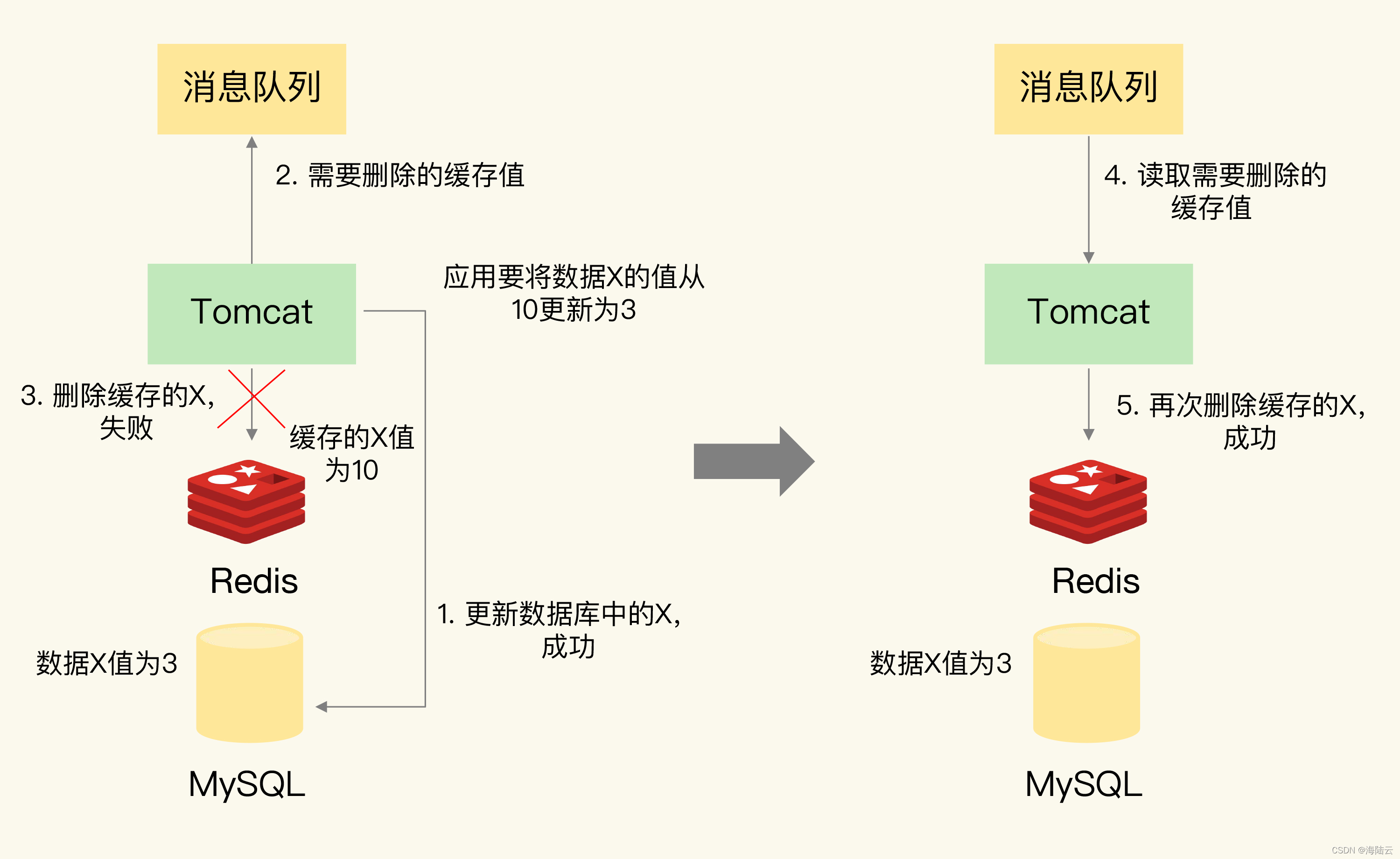
刚刚说的是在更新数据库和删除缓存值的过程中,其中一个操作失败的情况,实际上即使这两个操作第一次执行时都没有失败,当有大量并发请求时,应用还是有可能读到不一致的数据。
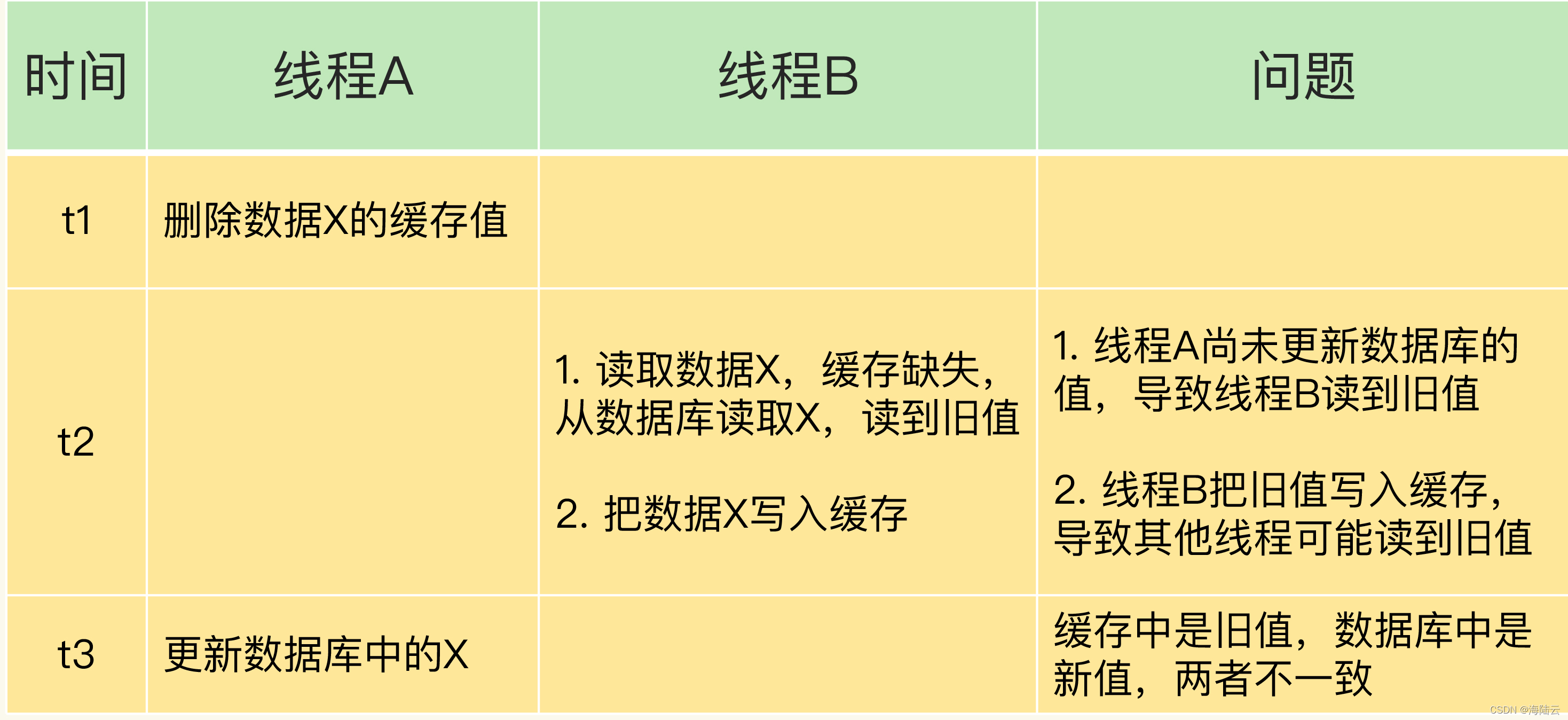
情况一:先删除缓存,再更新数据库。
假设线程 A 删除缓存值后,还没有来得及更新数据库(比如说有网络延迟),线程 B 就开始读取数据了,线程 B 会发现缓存缺失,去数据库读取。这会带来两个问题:
- 线程 B 读取到了旧值;
- 线程 B 是在缓存缺失的情况下读取的数据库,还会把旧值写入缓存,会导致其他线程从缓存中读到旧值。
等到线程 B 从数据库读取完数据、更新了缓存后,线程 A 才开始更新数据库,此时缓存中的数据是旧值,而数据库中的是最新值,两者就不一致了。
延迟双删: 在线程 A 更新完数据库值以后,让它先 sleep 一小段时间,再进行一次缓存删除操作。为了让线程 B 能够先从数据库读取数据,再把缺失的数据写入缓存,然后线程 A 再进行删除。所以线程 A sleep 的时间,就需要大于线程 B 读取数据再写入缓存的时间。在业务程序运行的时候, 统计下线程读数据和写缓存的操作时间,以此为基础来进行估算sleep时间。 其它线程读取数据时,会发现缓存缺失,会从数据库中读取最新值。
延迟双删方案的伪代码示例:
redis.delKey(X)
db.update(X)
Thread.sleep(N)
redis.delKey(X)
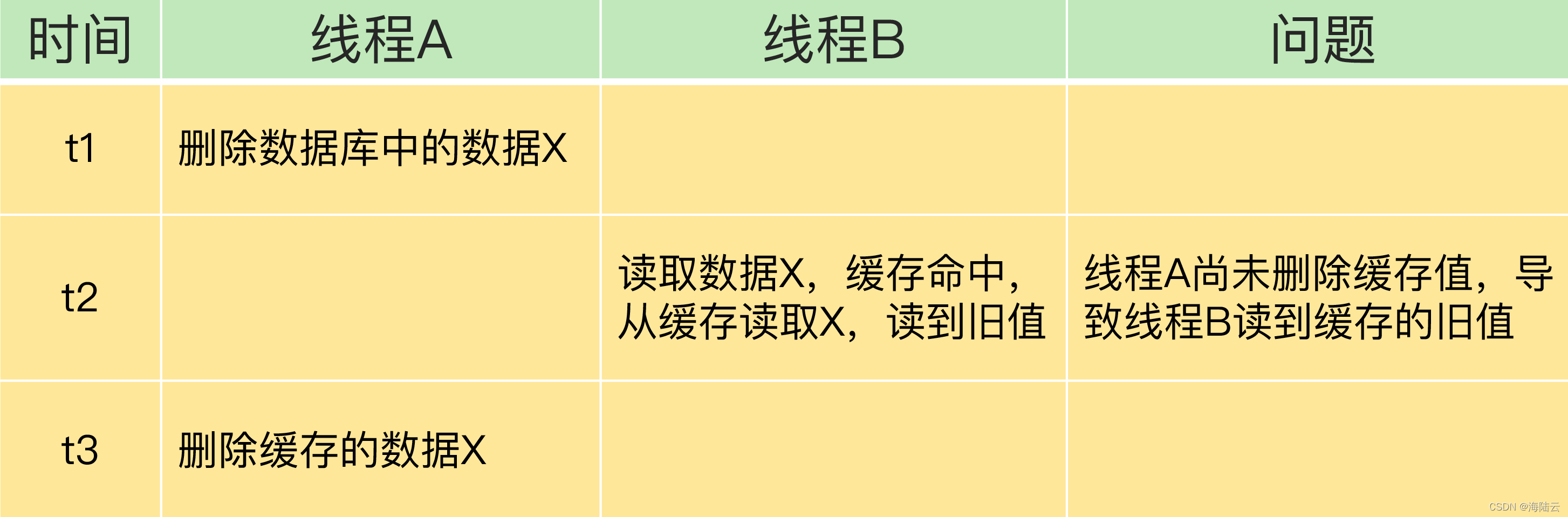
情况二:先更新数据库值,再删除缓存值。
如果线程 A 删除了数据库中的值,但还没来得及删除缓存值,线程 B 就开始读取数据了,线程 B 查询缓存时,发现缓存命中,会直接从缓存中读取旧值。如果其他线程并发读缓存的请求不多,就不会有很多请求读取到旧值。而且线程 A 一般也会很快删除缓存值,其他线程再次读取时,会发生缓存缺失,进而从数据库中读取最新值。所以这种情况对业务的影响较小。
缓存和数据库的数据不一致一般是由两个原因导致:
- 删除缓存值或更新数据库失败而导致数据不一致,可以使用重试机制确保删除或更新操作成功。
- 在删除缓存值、更新数据库的这两步操作中,有其他线程的并发读操作,导致其他线程读取到旧值,应对方案是延迟双删。
总结
Redis 缓存和数据库 不一致的问题,可以分成读写缓存和只读缓存两种情况进行分析:
- 读写缓存:如果我们采用同步写回策略,可以保证缓存和数据库中的数据一 致。
- 只读缓存:
在大多数业务场景下,会把 Redis 作为只读缓存使用。既可以先删除缓存值再更新数据库,也可以先更新数据库再删除缓存。
建议优先使用先更新数据库再删除缓存的方法,原因有两个:
- 先删除缓存值再更新数据库,有可能导致请求因缓存缺失而访问数据库,给数据库带来压力;
- 如果业务应用中读取数据库和写缓存的时间不好估算,那么延迟双删中的等待时间就不好设置。
先更新数据库再删除缓存需要注意:如果业务层要求必须读取一致的数据,就需要在更新数据库时,先在 Redis 缓存客户端暂存并发读请 求,等数据库更新完、缓存值删除后,再读取数据从而保证数据一致性。
智能推荐
IPv6地址_ipv6保留地址-程序员宅基地
文章浏览阅读1.6k次。IPv6,Internet Protocol version 6(网际协议第六版),IPv4的升版本。和IPv4类似,IPv6是一种逻辑编址方案,用于网络层主机到主机的通信。_ipv6保留地址
HTTP请求头的具体含意-程序员宅基地
文章浏览阅读252次。Request headersAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 浏览器支持的 MIME 类型分别是 text/html、application/xhtml+xml、application/xml 和 */*,优先顺序是它..._text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,
解决LineChart 标签被屏幕遮盖问题_mpandroidchart 被遮挡-程序员宅基地
文章浏览阅读3.1k次。最近项目中有一个趋势展示功能,就用到了MPAndroidchart中了Linechart(折线图来实现)绘制好图后,发现x轴最后一个标签被屏幕遮挡一点(有一部分跑出屏幕外边)经查找问题后发现,原来是y轴右边设置不显示后,图会自动向屏幕右边扩展。虽然x轴有个一个函数 xAxis.setAvoidFirstLastClipping(false);//图表将避免第一个和最后一个标签条目被减掉_mpandroidchart 被遮挡
数据结构——图论基础篇_图论中有同权-程序员宅基地
文章浏览阅读525次。基本概念:图论〔Graph Theory〕是数学的一个分支。它以图为研究对象。图论中的图是由若干给定的点及连接两点的线所构成的图形,这种图形通常用来描述某些事物之间的某种特定关系,用点代表事物,用连接两点的线表示相应两个事物间具有这种关系。图论是一种表示 "多对多" 的关系图是由顶点和边组成的:(可以无边,但至少包含一个顶点)一组顶点:通常用 V(vertex) 表示顶点集合..._图论中有同权
Vue中 Vue.extend() 详解及使用-程序员宅基地
文章浏览阅读3w次,点赞13次,收藏45次。Vue中 Vue.extend() 详解及使用_vue.extend
解决springboot,单元测试启动ApplicationRunner问题_applicationrunner解决-程序员宅基地
文章浏览阅读1.6k次。在执行单元测试时,ApplicationRunner被意外启动,导致了Netty服务器被初始化,单元测试无法执行的问题。解决方案:通过设置ApplicationRunner对应Bean的Profile解决对应组件添加注解:@Profile("!test")单元测试添加注解:@ActiveProfiles("test")..._applicationrunner解决
随便推点
node vue 实时推送_如何使用Node,Vue和ElasticSearch构建实时搜索引擎-程序员宅基地
文章浏览阅读337次。node vue 实时推送 介绍 (Introduction)Elasticsearch is a distributed, RESTful search and analytics engine capable of solving a growing number of use cases. Elasticsearch is built on top of Apache Lucene, wh..._vue elasticsearch
CCS中的IER和IFR寄存器:Symbol ‘IER‘ could not be resolved_symbol 'ier' could not be resolved-程序员宅基地
文章浏览阅读9.1k次,点赞16次,收藏53次。问题现象main函数初始化时,关闭CPU的中断使能,清除不断标志,一般都是这么写的: IER = 0x0000; IFR = 0x0000;但是,CCS却提示:Symbol 'IER' could not be resolved可是呢,编译整个工程时,也不会报错。<Linking>Finished building target: "DCDC.out""D:/ti/ccs1040/ccs/utils/tiobj2bin/tiobj..._symbol 'ier' could not be resolved
Apk 分析与Hook技术_hook apk-程序员宅基地
文章浏览阅读4.4k次。Android技术防范与揭秘总结APK静态分析静态分析指,在不允许代码的情况下,通过词法分析,语法分析,控制流,数据流分析等技术对程序代码进行扫描,验证代码是否满足规范性,安全性可靠性,可维护行等指标的一种代码分析技术。常用的分析利器查看源码工具dex2jar jd-gui dex2jar 将apk中的class.dex 转化为jar文件,而jd-gui是一个反编译工具,可以直接查看jar包中的源_hook apk
DM368开发 -- 文件烧写_dm368 不能下载 yaffs 程序-程序员宅基地
文章浏览阅读5.6k次,点赞2次,收藏5次。参看:DM36x的UBL分析以及串口启动UBL 是 RBL 引导启动的一段小程序,主要负责初始化时钟,串口,NAND,DDR2 等,然后把 uboot, kernel, rootfs 复制到 DDR2 上并引导 uboot。为什么 UBL 跟串口启动一起讲,那是因为这两个关系很密切,很多代码是共用的,而且代码都放在同一个目录下,所以就合起来一起讲了。一、UBLubl 的代码放在 dvsdk 目录下_dm368 不能下载 yaffs 程序
什么是分库分表?为什么需要分表?什么时候分库分表-程序员宅基地
文章浏览阅读1.4k次,点赞4次,收藏14次。分库分表是在海量数据下,由于单库、表数据量过大,导致数据库性能持续下降的问题,演变出的技术方案。分库分表是由分库和分表这两个独立概念组成的,只不过通常分库与分表的操作会同时进行,以至于我们习惯性的将它们合在一起叫做分库分表。通过一定的规则,将原本数据量大的数据库拆分成多个单独的数据库,将原本数据量大的表拆分成若干个数据表,使得单一的库、表性能达到最优的效果(响应速度快),以此提升整体数据库性能。预定义算法是事先已经明确知道分库和分表的数量,可以直接将某类数据路由到指定库或表中,查询的时候亦是如此。_分库分表
多行业万能预约门店小程序源码系统 带完整的搭建教程以及安装代码包-程序员宅基地
文章浏览阅读472次。小编给大家分享一款多行业万能预约门店小程序源码系统。该系统不仅具备高度的可定制性,还提供了丰富的功能模块,能够轻松应对不同行业的预约需求。:该系统支持多行业预约需求,无论是美容美发、餐饮娱乐还是医疗健身等行业,都能找到适合的预约模板和功能模块。:该系统提供了完整的搭建教程和安装代码包,用户只需按照教程操作,即可轻松完成小程序的搭建和部署。:系统提供了丰富的数据分析和统计功能,可以帮助商家了解预约情况、客户分布等信息,为门店运营提供有力支持。同时,还支持预约提醒功能,确保客户能够按时到店,提高预约的准确率。