面试题总结4-程序员宅基地
问题总结4
- 1、Java IO和NIO的区别
- 2、什么时候会触发FullGC
- 3、描述一下JVM加载class文件的原理机制?
- 4、Java对象的创建过程
- 5、Java的对象结构
- 6、调优命令
- 7、调优工具
- 8、你知道哪些JVM性能调优
- 9、你有没有遇到过OutOfMemory问题?你是怎么来处理这个问题的?处理 过程中有哪些收获?
- 10、通过什么⽅式来指定元空间⼤⼩
- 11、跟JVM内存相关的几个核心参数
- 12、如何停止一个正在运行的线程
- 13、notify()和notifyAll()有什么区别?
- 14、你一般在什么地方使用volatile
- 15、为什么wait和notify方法要在同步块中调用?
- 16、Java中interrupted 和 isInterruptedd方法的区别?
- 17、Java中synchronized 和 ReentrantLock 有什么不同?
- 18、有三个线程T1,T2,T3,如何保证顺序执行?
- 19、SynchronizedMap和ConcurrentHashMap有什么区别?
- 20、Thread类中的yield方法有什么作用?
- 21、说一说自己对于 synchronized 关键字的了解
- 22、为什么synchronized效率比较低
- 23、说说自己是怎么使用 synchronized 关键字,在项目中用到了吗?synchronized关键字最主要的三种使用方式
- 24、常用的线程池有哪些
- 25、简述一下你对线程池的理解(为什么要用线程池?)
- 26、单例模式
- 27、讲一下 synchronized 关键字的底层原理
- 28、依赖注入的方式有几种,各有什么优缺点?
- 29、Mybatis是如何进行分页的?分页插件的原理是什么?
- 30、mybatis如何实现一对一,一堆多
- 31、Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
- 32、什么是SpringBoot?为什么要用SpringBoot
- 33、Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
- 34、如何理解 Spring Boot 中的 Starters?
- 35、如何在Spring Boot启动的时候运行一些特定的代码
- 36、Spring Boot中的监视器是什么?
- 37、springboot常用的starter有哪些
- 38、如何理解 Spring Boot 配置加载顺序?
- 39、 Spring Boot 的核心配置文件有哪几个?它们的区别是什么?
- 40、InnoDB与MyISAM的区别
- 41、mysql索引分类
- 42、索引的优缺点
- 43、不可重复读和幻读区别
- 44、分布式事务中,innodb一般用的隔离级别
- 45、数据库分片的两种常见方案
- 46、uuid不适合作为主键的原因
- 47、缓存雪崩、缓存穿透、缓存击穿、缓存预热、缓存更新、缓存降级等问题
- 48、单线程的redis为什么这么快
- 49、redis的过期策略以及内存淘汰机制
- 50、同时有多个子系统去set一个key。这个时候要注意什么呢
- 51、Redis 常见性能问题和解决方案?
- 52、为什么Redis的操作是原子性的,怎么保证原子性的?
- 53、如何实现redis的事务
- 54、什么是微服务
- 55、服务熔断和服务降级
- 56、hystrix相关注解
- 57、Eureka和zookeeper区别
- 58、SpringBoot和SpringCloud的区别?
- 59、Nginx是如何处理一个HTTP请求的呢?(nginx为什么能够同时处理大量的并发请求)
- 60、反向代理和正向代理
- 61、Zookeeper 的典型应用场景
- 62、如何获取 topic 主题的列表
- 63、生产者和消费者的命令行是什么?
- 64、consumer 是推还是拉?为什么?
- 65、讲讲 kafka 维护消费状态跟踪的方法(维护消息是否被消费)
- 66、Zookeeper 对于 Kafka 的作用是什么?
- 67、Kafka 与传统 MQ 消息系统之间有三个关键区别
- 68、讲一讲 kafka 的 ack 的三种机制
- 69、消费者如何不自动提交偏移量,由应用提交?
- 70、消费者故障,出现活锁问题如何解决?
- 71、kafka如何控制消费的位置
- 72、分布式下的kafka如何保证消息的消费顺序?
- 73、kafka 如何减少数据丢失
- 74、kafka 如何不消费重复数据?比如扣款,我们不能重复的扣。
- 75、为什么使用MQ,MQ的优缺点
- 76、如何保证消息的可靠传输?如果消息丢了怎么办
- 77、消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
- 78、那如何解决消息队列的延时以及过期失效问题?
- 79、mq消息队列快满了,消息都积压在mq里,长时间都没有处理掉,这个时候该怎么办?
- 80、设计MQ的思路
- 81、elasticsearch 的倒排索引是什么
- 82、如何监控 Elasticsearch 集群状态?
- 83、介绍下你们电商搜索的整体技术架构。
- 84、Linux建立软连接以及硬连接的命令
- 85、用什么命令对一个文件的内容进行统计?(行号、单词数、字节数)
- 86、哪个命令专门用来查看后台任务?
- 87、搜索文件用什么命令? 格式是怎么样的?
- 88、使用什么命令查看磁盘使用空间? 空闲空间呢?
- 89、使用什么命令查看网络是否连通?
- 90、du 和 df 的定义,以及区别?
- 91、如果你的助手想要打印出当前的目录栈,你会建议他怎么做?
- 92、你的系统目前有许多正在运行的任务,在不重启机器的条件下,有什么方法可以把所有正在运行的进程移除呢?
- 93、怎样一页一页地查看一个大文件的内容呢?
- 94、你平时是怎么查看日志的?
- 95、常用的数据结构
- 96、Kafka、ActiveMQ、RabbitMQ、RocketMQ 都有什么区别,以及适合哪些场景?
- 97、ES 的分布式架构原理能说一下么(ES 是如何实现分布式的啊)?
- 98、es 写数据过程
- 99、es读数据过程
- 100、es搜索数据的过程
- 101、ES 在数据量很大的情况下(数十亿级别)如何提高查询效率啊?
- 102、假如,es 集群中每个机器写入的数据量还是超过了filesystem cache 一倍,比如说你写入一台机器 60G 数据,结果 filesystem cache 就 30G,还是有 30G 数据留在了磁盘上。
- 103、es分页性能优化
- 104、ES 生产集群的部署架构是什么?每个索引的数据量大概有多少?每个索引大概有多少个分片?
- 105、redis的内存淘汰策略
- 106、redis哨兵主备切换的数据丢失问题
- 107、主观宕机sdown和客观宕机odown
- 108、为什么要分库分表(设计高并发系统的时候,数据库层面该如何设计)?
- 109、用过哪些分库分表中间件?不同的分库分表中间件都有什 么优点和缺点?
- 110、你们具体是如何对数据库如何进行垂直拆分或水平拆分的?
- 111、现在有一个未分库分表的系统,未来要分库分表,如何设计才可以让系统从未分库分表动态切 换到分库分表上?
- 112、如何设计可以动态扩容缩容的分库分表方案?
- 113、MySQL 主从复制原理的是啥?
- 114、mysql主从同步延时问题
- 115、如何设计一个高并发系统?
- 116、InnoDB为什么采用B+树
- 117、dubbo 工作原理和工作流程
- 118、dubbo 支持哪些通信协议?支持哪些序列化协议?
- 119、dubbo 负载均衡策略都有哪些?
- 120、dubbo 集群容错策略
- 121、spi是啥?dubbo的spi是怎么实现的?
- 122、分布式服务接口的幂等性如何设计(比如不能重复扣款)?
- 123、分布式服务接口请求的顺序性如何保证?
- 124、什么是分区容错性?
- 125、分布式锁的实现
- 126、使用redis分布式锁,redis宕机或者失效了怎么办
- 127、分布式事务的实现方案
- 128、你们公司是如何处理分布式事务的
- 129、集群部署时的分布式 Session 如何实现?
- 130、限流的实现方式
1、Java IO和NIO的区别
1、数据处理上,NIO:块;IO:字节流
2、NIO的通道和缓存区
3、NIO是双向的
4、补充:NIO和BIO的核心区别就是NIO采用的是IO多路复用的IO模型,普通的IO用的是阻塞的IO模型
2、什么时候会触发FullGC
1、老年代满
2、老年代不够
3、方法区满
3、描述一下JVM加载class文件的原理机制?
1、JVM中类装载都是由类加载器完成的
2、加载、连接、初始化
3、类加载器都包含哪些:bootstrap、extension、system
4、Java对象的创建过程
1、检查常量池
2、分配内存
3、初始化0值
4、设置对象头
5、Java的对象结构
对象头、数据、填充
6、调优命令
1、显示系统内所有的hotspot虚拟机进程
jps
2、监控虚拟机运行时状态信息
VisualVM
3、生成dump
jmap
4、分析dump文件
mat
5、生成线程快照
jstack
6、实时查看虚拟机运行参数
VMware
7、调优工具
1、JDK中自带的java监控和管理控制台:
jconsole
2、jdk自带全能工具,可以分析内存快照、线程快照;监控内存变化、GC变化:
jvisualvm
3、基于Eclipse的内存分析工具,是一个快速、功能丰富的Javaheap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗:
MAT
4、一款专业分析gc日志的工具:
GChisto
8、你知道哪些JVM性能调优
设置堆内存大小 -Xms、-Xmx
设置新生代大小 -XX:NewSize
设置新生代和老年代比例 -XX:NewRatio
设置Eden区和幸存区比例 -XX:SurvivorRatio
设置垃圾回收器
老年代:-XX:+UseConcMarkSweepGC
新生代:-XX:+UseParNewGC
9、你有没有遇到过OutOfMemory问题?你是怎么来处理这个问题的?处理 过程中有哪些收获?
1、内存加载数据量过大,一次性从数据库查询太多数据
2、集合类中的对象饮用无法GC回收
3、循环创建对象
4、堆内存设置过小
10、通过什么⽅式来指定元空间⼤⼩
-XX:MetaSpaceSize
-XX:MaxMetaSpaceSize
11、跟JVM内存相关的几个核心参数
堆 -Xms、-Xmx
老年代
新生代 -Xmn
栈 -Xss
方法区 -XX:PermSize-XX:MaxPermSize
12、如何停止一个正在运行的线程
1、打退出标记
2、stop
3、interrupt+volatile
13、notify()和notifyAll()有什么区别?
1、notify使用不当可能导致死锁,notifyall不会
2、wait() 应配合while循环使用,不应使用if,务必在wait()调用前后都检查条件,如果不满足,必须调用notify()唤醒另外的线程来处理,自己继续wait()直至条件满足再往下执行。
14、你一般在什么地方使用volatile
状态标记量
单例双检锁
15、为什么wait和notify方法要在同步块中调用?
会抛出IllegalMonitorStateException异常
16、Java中interrupted 和 isInterruptedd方法的区别?
调用Thread.interrupt()来中断一个线程就会设置中断标识为true
调用静态方法Thread.interrupted()来检查中断状态时,中断状态会被清零
非静态方法isInterrupted()用来查询其它线程的中断状态且不会改变中断状态标识
17、Java中synchronized 和 ReentrantLock 有什么不同?
ReentrantLock:可中断、公平锁、多条件
18、有三个线程T1,T2,T3,如何保证顺序执行?
join()
19、SynchronizedMap和ConcurrentHashMap有什么区别?
SynchronizedMap和hashtable一样,对整个map加锁
20、Thread类中的yield方法有什么作用?
Yield方法可以暂停当前正在执行的线程对象,让其它有相同优先级的线程执行。它是一个静态方法而且只保证当前线程放弃CPU占用而不能保证使其它线程一定能占用CPU,执行yield()的线程有可能在进入到暂停状态后马上又被执行。
21、说一说自己对于 synchronized 关键字的了解
1、早期的版本中,作为重量级锁,效率较低
2、1.6之后引入了锁的升级
22、为什么synchronized效率比较低
synchronized它是依赖于监视器锁monitor实现的,monitor是依赖于底层的操作系统Mutex Lock来实现的,如果要挂起或者唤醒线程的话,都需要操作系统帮忙完成,而操作系统实现线程之间的切换需要从用户态转换到内核态,这个过程相对耗时,时间成本较高。
23、说说自己是怎么使用 synchronized 关键字,在项目中用到了吗?synchronized关键字最主要的三种使用方式
实例方法、静态方法、局部代码块
实例方法:实例锁
静态方法、局部代码块:类锁
24、常用的线程池有哪些
单个、固定大小、可缓存、无限大小
25、简述一下你对线程池的理解(为什么要用线程池?)
1、线程管理
2、降低损耗
3、提高速度
26、单例模式
27、讲一下 synchronized 关键字的底层原理
代码块:monitor
方法:ACC_
28、依赖注入的方式有几种,各有什么优缺点?
构造器
优点:对象初始化完成后便可获得可使用的对象。
缺点:不够灵活。若有多种注入方式,每种方式只需注入指定几个依赖,那么就需要提供多个重载的构造函数,麻烦。
setter
优点:灵活。可以选择性地注入需要的对象
缺点:依赖对象初始化完成后由于尚未注入被依赖对象,因此还不能使用。
接口
优点:接口注入中,接口的名字、函数的名字都不重要,只要保证函数的参数是要注入的对象类型即可。
缺点:侵入性强,不建议使用
29、Mybatis是如何进行分页的?分页插件的原理是什么?
30、mybatis如何实现一对一,一堆多
association,collection
31、Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
通过cglib动态代理生成代理类,在拦截器中,讲关联的SQL数据查上来,然后进行set赋值。
32、什么是SpringBoot?为什么要用SpringBoot
springboot用来简化spring的开发,约定大于配置,去繁从简
33、Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
@SpringbootApplication
@ComponentScan:spring组件扫描
@EnabAutoConfiguratuion:自动装配
@SpringBootConfigration: 组合了@Configration,实现了配置文件的功能
34、如何理解 Spring Boot 中的 Starters?
启动器,包含了一系列可以集成到应用里面的依赖包
35、如何在Spring Boot启动的时候运行一些特定的代码
可以实现接口ApplicationRunner
或者
CommandLineRunner
36、Spring Boot中的监视器是什么?
Spring boot actuator,可直接作为HTTP URL访问的REST端点来检查状态。
37、springboot常用的starter有哪些
spring-boot-starter-
web
data-jpa
data-redis
data-solr
mybatis-spring-boot-starter 第三方
38、如何理解 Spring Boot 配置加载顺序?
properties>ymal>系统环境变量>命令行参数
39、 Spring Boot 的核心配置文件有哪几个?它们的区别是什么?
application和bootstrap
bootstrap应用场景:
1、配置中心,在bootstrap中添加连接配置中心的属性
2、一些不能被覆盖的属性
3、加解密的场景
40、InnoDB与MyISAM的区别
1、事务
2、锁
3、外键
4、InnoDB:聚集索引;MyISAM非聚集索引
41、mysql索引分类
普通索引
主键索引
唯一索引
全文索引
42、索引的优缺点
首先索引是为了加快数据库的检索速度,但是在进行删除、修改、插入的时候需要维护索引,对速度有一定的影响;唯一索引可以保证行数据的唯一性,索引占物理和数据空间
43、不可重复读和幻读区别
44、分布式事务中,innodb一般用的隔离级别
SERIALIZABLE 可串行化
45、数据库分片的两种常见方案
客户端:分片逻辑在应用端,封装在jar包中,通过修改或封装jdbc层来实现。sharding-jdbc、阿里的tddl
中间件:mycat、360的atlas、网易的ddb
46、uuid不适合作为主键的原因
太长、无序、可读性较差、查询效率低。适合作为文件名称。
47、缓存雪崩、缓存穿透、缓存击穿、缓存预热、缓存更新、缓存降级等问题
48、单线程的redis为什么这么快
1、纯内存
2、单线程避免线程切换
3、IO多路复用
49、redis的过期策略以及内存淘汰机制
50、同时有多个子系统去set一个key。这个时候要注意什么呢
锁
锁+时间戳
51、Redis 常见性能问题和解决方案?
1、大key
2、master不做任何持久化工作
3、保证热点数据
4、减少IO次数
5、最多二级主从
52、为什么Redis的操作是原子性的,怎么保证原子性的?
redis是单线程的,操作不可再分
redis+lua
单命令操作incr
53、如何实现redis的事务
multi:开启事务
exec:执行事务中的命令
discard:清空事物队列
watch:提供cas行为
54、什么是微服务
微服务架构是一种架构模式或者说是一种架构风格,它提倡将单一应用程序划分为一组小的服务,每个
服务运行在其独立的自己的进程中,服务之间相互协调、互相配合,为用户提供最终价值。服务之间采
用轻量级的通信机制互相沟通(通常是基于HTTP的RESTful API),每个服务都围绕着具体的业务进行构
建,并且能够被独立的构建在生产环境、类生产环境等。另外,应避免统一的、集中式的服务管理机
制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构建,可以有一个非
常轻量级的集中式管理来协调这些服务,可以使用不同的语言来编写服务,也可以使用不同的数据存
储。
55、服务熔断和服务降级
56、hystrix相关注解
@EnableHystrix:开启熔断
@HystrixCommand(fallbackMethod=”XXX”):声明一个失败回滚处理函数XXX,当被注解的方法执行超时(默认是1000毫秒),就会执行fallback函数,返回错误提示
57、Eureka和zookeeper区别
1、zookeeper的master节点挂掉后,会重新选举leader,选举leader时间过长,30 ~ 120s,并且选举时间zk集群不可用,这样就会导致选举期间服务瘫痪。
2、eureka各个节点是平等的,只要有一个节点正常就可以提供服务,但是查到的信息有可能不是最新的。当eureka和客户端发生网络故障后,Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其他节点上(即保证当前节点仍然可用)
58、SpringBoot和SpringCloud的区别?
SpringBoot专注于快速、方便的开发单个微服务个体,SpringCloud关注全局的服务治理框架
59、Nginx是如何处理一个HTTP请求的呢?(nginx为什么能够同时处理大量的并发请求)
1、多进程机制:ng接收到客户端请求后,服务器主进程就会生成一个子进程和客户端建立连接并交互,直到连接断开。这样做的好处就是各个进程之间相互独立,不需要加锁。缺点就是在资源上会产生一定的开销,当有大量请求后,会导致系统性能下降。
2、异步非阻塞机制:接收到客户端请求后,无需等待响应,可以去处理其它事情,当IO返回后,会通知工作线程,然后去响应客户端请求。
60、反向代理和正向代理
61、Zookeeper 的典型应用场景
1、数据发布/订阅
2、负载均衡
zookeeper和nginx负载均衡区别
zk 的负载均衡是可以调控,nginx 只是能调权重,其他需要可控的都需要自己写插件;但是 nginx 的吞吐量比 zk 大很多,应该说按业务选择用哪种方式。
3、分布式锁
4、分布式队列
62、如何获取 topic 主题的列表
bin/kafka-topics.sh --list --zookeeper localhost:2181
63、生产者和消费者的命令行是什么?
生产者在主题上发布消息:
bin/kafka-console-producer.sh --broker-list 192.168.43.49:9092 --topicHello-Kafka
注意这里的 IP 是 server.properties 中的 listeners 的配置。接下来每个新行就是输入一条新消息。
消费者接受消息:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topicHello-Kafka --from-beginning
64、consumer 是推还是拉?为什么?
Kafka 遵循了一种大部分消息系统共同的传统的设计:producer 将消息推送到 broker,consumer 从broker 拉取消息。
push 模式下,当broker 推送的速率远大于 consumer 消费的速率时,consumer 恐怕就要崩溃了。
另一个好处就是,consumer 可以根据自己的消费能力去决定是单条消费还是批量消费消息。
但是pull也有一个缺点,pull是consumer主动进行拉取消费的,如果broker没有消息,将导致consumer不断的进行循环轮训,直到新消息到达。为了避免这点,Kafka 有个参数可以让 consumer阻塞直到新消息到达(当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发送)。
max.poll.interval.ms=300000
在上面的示例中,max.poll.interval.ms被设置为5分钟(300000毫秒),这意味着如果消费者在5分钟内没有收到新消息,就会被认为是不活跃的,并触发再平衡。
65、讲讲 kafka 维护消费状态跟踪的方法(维护消息是否被消费)
大部分的消息系统:在broker中维护消息被消费的记录,当消息发送到consumer中broker立马删除。
但是这种就会出现consumer消费失败后,数据的丢失问题。
所以很多消息系统又会提供另一个功能:consumer消费成功后的confirm机制。broker发送消息成功仅将消息标记为已发送,consumer消费成功后,broker才会将消息标记为已消费。
这种虽然解决了消息丢失的问题,但是假如consumer消费成功,但是通知broker的这个过程失败就会导致新的问题:
1、消息的重复消费
2、broker需要维护每条消息的状态
Kafka 采用了不同的策略。Topic 被分成了若干分区,每个分区在同一时间只被一个 consumer 消费。这意味着每个分区被消费的消息在日志中的位置仅仅是一个简单的整数:offset。这样就很容易标记每个分区消费状态就很容易了,仅仅需要一个整数而已。这样消费状态的跟踪就很简单了。这带来了另外一个好处:consumer 可以把 offset 调成一个较老的值,去重新消费老的消息。这对传统的消息系统来说看起来有些不可思议,但确实是非常有用的,谁规定了一条消息只能被消费一次呢?
66、Zookeeper 对于 Kafka 的作用是什么?
Zookeeper在Kafka中担当着重要的角色,主要用于管理和协调Kafka集群中的各个组件,以确保集群的可靠运行和高可用性。以下是Zookeeper在Kafka中的作用:
领导者选举: Kafka集群中的每个分区都有一个Leader副本和若干个Follower副本。Zookeeper用于协助进行领导者选举,当Leader副本不可用时,Zookeeper帮助选举一个新的Leader副本,确保数据的持续可用。
存储元数据: Kafka的元数据信息,如分区、副本、主题配置等,被存储在Zookeeper中。这些元数据的存储使得Kafka的各个组件可以在集群中相互发现和获取所需的信息。
偏移量管理: 消费者消费消息时,其偏移量(offset)会被记录下来,以便消费者下次继续从正确的位置消费。Zookeeper用于存储这些偏移量,确保消费者在重启后可以继续消费之前的位置。
集群管理: Zookeeper监控Kafka集群的状态,包括节点的上线、下线、变化等。它可以通知集群中的其他组件有关集群状态的变化情况。
配置管理: Kafka的一些配置信息被存储在Zookeeper中,例如主题的分区数量、副本数等。这些配置信息可以在集群内部的各个组件中进行同步。
锁和同步: 在分布式环境下,访问共享资源时需要进行协调和同步,以避免竞争条件。Zookeeper提供了分布式锁和同步机制,使得Kafka的各个组件可以安全地进行协作。
总之,Zookeeper在Kafka中充当了集群管理、元数据存储、选举、同步等关键角色,确保了Kafka集群的可靠性和稳定性。
67、Kafka 与传统 MQ 消息系统之间有三个关键区别
1、kafka持久化日志
2、kafka是一个分布式系统
3、支持实时的流式处理
68、讲一讲 kafka 的 ack 的三种机制
保证消息不丢失是一个消息队列中间件的基本保证,那producer在向kafka写入消息的时候,怎么保证消息不丢失呢?
通过ACK应答机制!在生产者向队列写入数据的时候可以设置参数来确定是否确认kafka接收到数据,这个参数可设置的值为0、1、all。
- 0代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效率最高。
- 1代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。
- all代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保leader发送成功和所有的副本都完成备份。安全性最高,但是效率最低。
注意:如果往不存在的topic写数据,能不能写入成功呢?kafka会自动创建topic,分区和副本的数量根据默认配置都是1。
69、消费者如何不自动提交偏移量,由应用提交?
将 auto.commit.offset 设为 false,然后在处理一批消息后 commitSync() 或者异步提交
commitAsync()
ConsumerRecords<> records = consumer.poll();
for (ConsumerRecord<> record : records){
。。。
try{
consumer.commitSync()
}
。。。
}
70、消费者故障,出现活锁问题如何解决?
活锁就是消费者持续发送心跳,但是不处理消息。
为了预防消费者在这种情况下一直持有分区,我们使用 max.poll.interval.ms 活跃检测机制。如果调用 Poll 的频率大于最大间隔,那么消费者将会主动离开消费组,以便其他消费者接管该分区
71、kafka如何控制消费的位置
使用 seek(TopicPartition, long)指定新的消费位置。
72、分布式下的kafka如何保证消息的消费顺序?
kafka分布式的单位是partition,同一个partition可以保证fifo的顺序。不同 partition 之间不能保证顺序。
Kafka 中发送 1 条消息的时候,可以指定(topic, partition, key) 3 个参数。partiton 和 key 是可选的。如果你指定了 partition,那就是所有消息发往同 1个 partition,就是有序的。并且在消费端,Kafka 保证,1 个 partition 只能被1 个 consumer 消费。或者你指定 key( 比如 order id),具有同 1 个 key的所有消息,会发往同 1 个 partition。
73、kafka 如何减少数据丢失
kafka通常不会丢数据,但有些情况下的确有可能会发生。
block.on.buffer.full = true
acks = all
retries = MAX_VALUE
max.in.flight.requests.per.connection = 1
使用KafkaProducer.send(record, callback)
callback逻辑中显式关闭producer:close(0)
unclean.leader.election.enable=false
replication.factor = 3
min.insync.replicas = 2
replication.factor > min.insync.replicas
enable.auto.commit=false
消息处理完成之后再提交位移
- 副本机制:kafka使用分区副本的方式存储数据。每一个分区都有一个leader和若干个follower副本,leader负责接收和写入数据,follower负责复制数据。这种机制保证就算某个副本不可用,数据仍然存在其它副本,从而降低数据丢失的风险。
- 持久化
- 数据复制:将数据复制到多个副本,如果一个副本不可用,还可以从其它副本获取数据
- 确认机制:生产者发送消息的ack机制
- 数据备份:定期备份kafka的数据
- 错误处理:在生产者和消费者端,采用适当的错误处理机制。例如重试,错误回调等。保证消息能重复写入和消费
- 监控和报警
74、kafka 如何不消费重复数据?比如扣款,我们不能重复的扣。
- 消息去重:生产者在生产消息的时候,可以对消息打一个唯一ID标识,消费者端可以根据消息的唯一ID来判断是否有消费过此消息
- 幂等性:在处理类似扣款等操作时,确保操作是幂等的,即重复操作不会产生不同的结果。即使消费者重复处理了消息,也不会对系统状态产生影响。
- 使用事务:Kafka提供了事务支持,消费者可以在处理消息时使用事务,确保消息的处理和提交是原子操作。如果处理失败,事务会被回滚,消息不会被提交。
- 使用消费者组: 每个消费者组在一个分区内只会有一个消费者消费消息。如果多个消费者组消费同一个主题,可以避免重复消费问题。
- 手动提交偏移量: 可以禁用消费者的自动偏移量提交功能,而是在消费者处理完消息后手动提交偏移量。这样,如果消息处理失败,偏移量不会被提交,避免了重复消费。
- 幂等性生产者: 如果生产者使用幂等性生产者,可以确保生产的消息不会重复。幂等性生产者会在重试时保证相同的消息只会写入一次。
75、为什么使用MQ,MQ的优缺点
异步、解耦、削峰
缺点:系统可用性降低、系统复杂度提高、一致性问题
76、如何保证消息的可靠传输?如果消息丢了怎么办
生产者丢失:confirm机制
mq丢失:持久化机制
消费者丢失:关闭rabbitmq自动ACK
77、消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
消息积压处理办法:临时紧急扩容。
1、首先修复consumer的问题,保证其消费速度,然后将现有的consumer都停掉。
2、新建一个topic,partition为原来的10倍,临时简历好原先10倍的queue数量。然后写一个数据分发的程序,将分发程序集群部署可以部署10台,将目前积压的数据均匀轮询写入临时建立好的10倍数量的queue。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。
3、恢复原来的架构,重新用修复好的consumer去消费消息。
78、那如何解决消息队列的延时以及过期失效问题?
rabbitmq是可以设置过期时间的,TTL,这样就会丢失大量的消息。
可以批量重导,就是大量数据堆积的时候,直接丢弃数据,然后等到高峰期以后,比如大家一起喝咖啡熬夜到晚上12点以后,用户都睡觉了。这个时候我们就开始写程序,将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新灌入 mq 里面去,把白天丢的数据给他补回来。也只能是这样了。假设 1 万个订单积压在 mq 里面,没有处理,其中 1000个订单都丢了,你只能手动写程序把那 1000 个订单给查出来,手动发到 mq 里去再补一次。
79、mq消息队列快满了,消息都积压在mq里,长时间都没有处理掉,这个时候该怎么办?
没有,谁让你第一个方案执行的太慢了,你临时写程序,接入数据来消费,消费一个丢弃一个,都不要了,快速消费掉所有的消息。然后走第二个方案,到了晚上再补数据吧。
80、设计MQ的思路
- 可伸缩性,就是快速扩容
- 持久化
- 高可用
- 数据0丢失
81、elasticsearch 的倒排索引是什么
传统的我们的检索是通过文章,逐个遍历找到对应关键词的位置。
而倒排索引,是通过分词策略,形成了词和文章的映射关系表,这种词典+映射表即为倒排索引。有了倒排索引,就能实现 o(1)时间复杂度的效率检索文章了,极大的提高了检索效率。
82、如何监控 Elasticsearch 集群状态?
Kibana
83、介绍下你们电商搜索的整体技术架构。
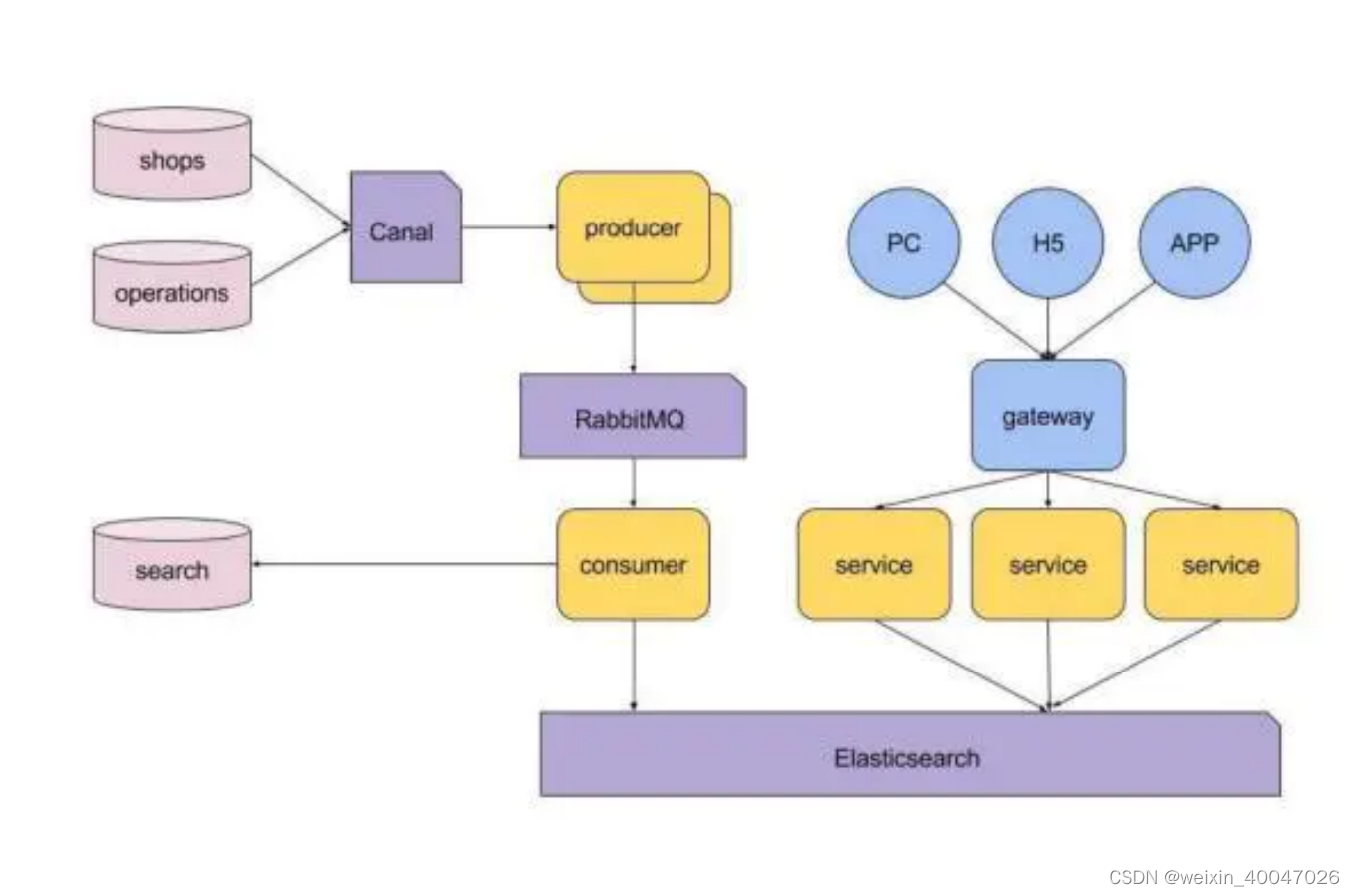
84、Linux建立软连接以及硬连接的命令
软连接:ln -s slink source
软链接文件有类似于 Windows 的快捷方式。
硬连接:ln link source
硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。其原因如上所述,因为对应该目录的索引节点有一个以上的连接。只删除一个连接并不影响索引节点本身和其它的连接,只有当最后一个连接被删除后,文件的数据块及目录的连接才会被释放。也就是说,文件真正删除的条件是与之相关的所有硬连接文件均被删除。
85、用什么命令对一个文件的内容进行统计?(行号、单词数、字节数)
wc 命令 - c 统计字节数 - l 统计行数 - w 统计字数
86、哪个命令专门用来查看后台任务?
job -l
87、搜索文件用什么命令? 格式是怎么样的?
find
locate 文件名
whereis 参数和文件名
88、使用什么命令查看磁盘使用空间? 空闲空间呢?
df
89、使用什么命令查看网络是否连通?
netstat
90、du 和 df 的定义,以及区别?
- du显示文件目录或文件的大小
- df显示每个文件的信息
- df 命令获得真正的文件系统数据,而 du 命令只查看文件系统的部分情况。
91、如果你的助手想要打印出当前的目录栈,你会建议他怎么做?
dirs
92、你的系统目前有许多正在运行的任务,在不重启机器的条件下,有什么方法可以把所有正在运行的进程移除呢?
disown -r
可以将所有正在运行的进程移除
93、怎样一页一页地查看一个大文件的内容呢?
通过管道将命令”cat file_name.txt” 和 ’more’ 连接在一起可以实现这个需要.
[root@localhost ~]# cat file_name.txt | more复制代码
94、你平时是怎么查看日志的?
- tail
tail -n 10 test.log 查询日志尾部最后10行的日志;
tail -n +10 test.log 查询10行之后的所有日志;
tail -fn 10 test.log 循环实时查看最后1000行记录(最常用的)
- grep
一般还会配合着grep搜索用,例如 :
tail -fn 1000 test.log | grep '关键字'
如果一次性查询的数据量太大,可以进行翻页查看,例如
tail -n 4700 aa.log |more -1000 可以进行多屏显示(ctrl + f 或者 空格键可以快捷键)
- head
跟tail是相反的head是看前多少行日志
head -n 10 test.log 查询日志文件中的头10行日志;
head -n -10 test.log 查询日志文件除了最后10行的其他所有日志;
- more
- sed:这个命令可以查找日志文件特定的一段 , 根据时间的一个范围查询,可以按照行号和时间范围查询按照行号
sed -n '5,10p' filename 这样你就可以只查看文件的第5行到第10行。
sed -n '/2014-12-17 16:17:20/,/2014-12-17 16:17:36/p' test.log
95、常用的数据结构
- 数组
- 链表
单向和双向 - 树
- 图
- 堆栈
- 队列
- 字典树
- 哈希表
96、Kafka、ActiveMQ、RabbitMQ、RocketMQ 都有什么区别,以及适合哪些场景?
中小型公司,技术实力较为一般,技术挑战不是特别高,用 RabbitMQ 是不错的选择;大 型公司,基础架构研发实力较强,用 RocketMQ (阿里)是很好的选择。
如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区
活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范。
97、ES 的分布式架构原理能说一下么(ES 是如何实现分布式的啊)?
98、es 写数据过程
每个node都是一个coordinating node
- 客户端选择一个 node 发送请求过去,这个 node 就是 coordinating node (协调节
点)。 - node 上的 primary shard 处理请求,然后将数据同步到 replica node 。
- coordinating node 如果发现 primary node 和所有 replica node 都搞定之后,就
返回响应结果给客户端。
99、es读数据过程
读数据根据doc_id,会根据doc_id进行hash,判断出来当时把 doc id 分配到了
哪个 shard 上面去,从那个 shard 去查询
- 客户端发送请求到任意一个 node,成为 coordinate node 。
- coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用
round-robin 随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,
让读请求负载均衡 - 接收请求的 node 返回 document 给 coordinate node 。
- coordinate node 返回 document 给客户端。
100、es搜索数据的过程
- 客户端发送请求到一个 coordinate node 。
- 协调节点将搜索请求转发到所有的 shard 对应的 primary shard 或 replica shard ,
都可以 - query phase:每个 shard 将自己的搜索结果(其实就是一些 doc id )返回给协调节点,
由协调节点进行数据的合并、排序、分页等操作,产出最终结果。 - fetch phase:接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,
最终返回给客户端。
101、ES 在数据量很大的情况下(数十亿级别)如何提高查询效率啊?
性能优化的杀手锏——filesystem cache
你往 es 里写的数据,实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里
的数据自动缓存到 filesystem cache 里面去。
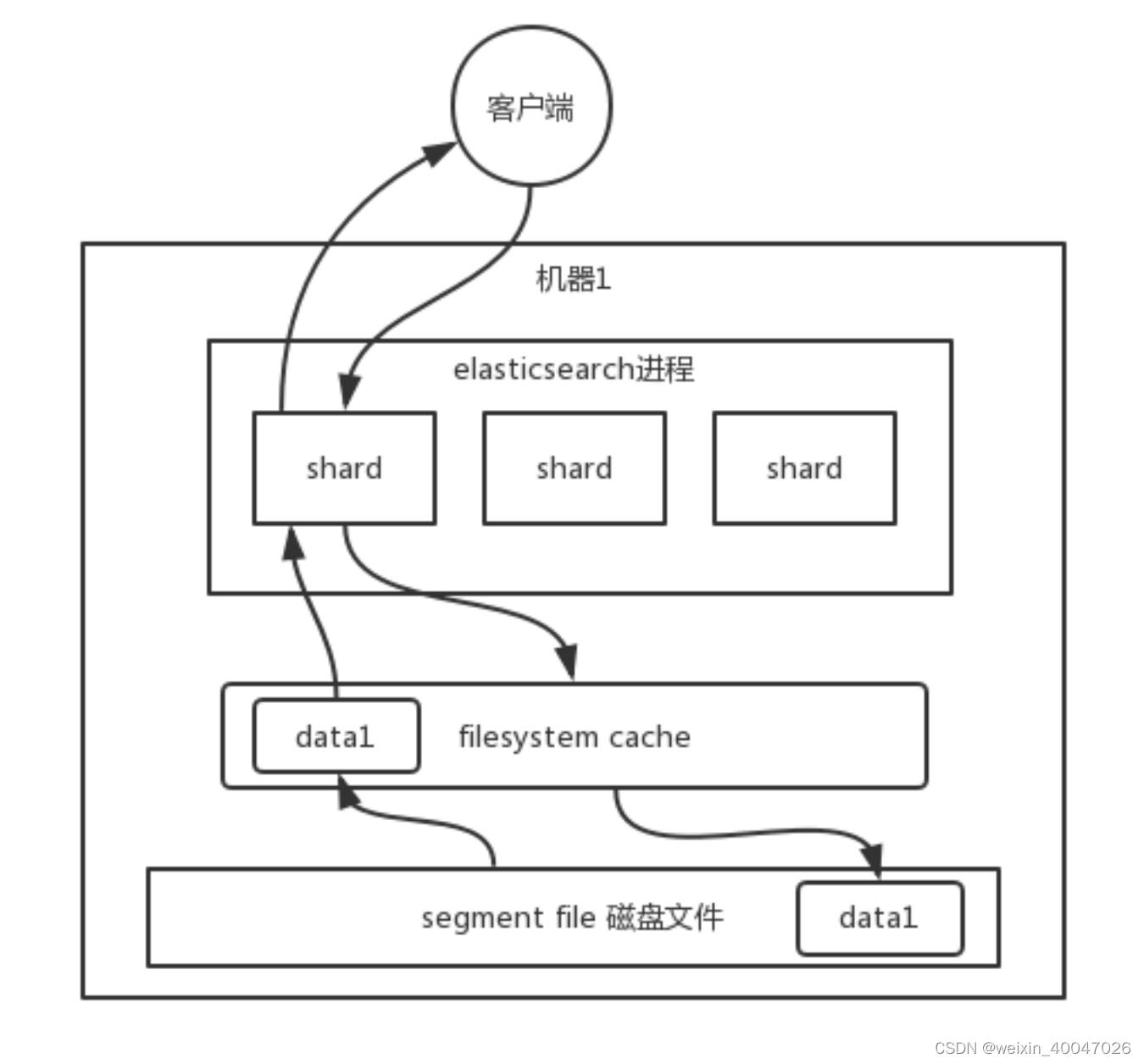
es 的搜索引擎严重依赖于底层的 filesystem cache ,你如果给 filesystem cache 更多
的内存,尽量让内存可以容纳所有的 idx segment file 索引数据文件,那么你搜索的时候
就基本都是走内存的,性能会非常高。
性能差距究竟可以有多大?我们之前很多的测试和压测,如果走磁盘一般肯定上秒,搜索性能
绝对是秒级别的,1秒、5秒、10秒。但如果是走 filesystem cache ,是走纯内存的,那么
一般来说性能比走磁盘要高一个数量级,基本上就是毫秒级的,从几毫秒到几百毫秒不等。
这里有个真实的案例。某个公司 es 节点有 3 台机器,每台机器看起来内存很多,64G,总内存
就是 64 * 3 = 192G 。每台机器给 es jvm heap 是 32G ,那么剩下来留给 filesystem cache 的就是每台机器才 32G ,总共集群里给 filesystem cache 的就是 32 * 3 = 96G
内存。而此时,整个磁盘上索引数据文件,在 3 台机器上一共占用了 1T 的磁盘容量,es 数
据量是 1T ,那么每台机器的数据量是 300G 。这样性能好吗? filesystem cache 的内
存才 100G,十分之一的数据可以放内存,其他的都在磁盘,然后你执行搜索操作,大部分操作都是走磁盘,性能肯定差。
归根结底,你要让 es 性能要好,最佳的情况下,就是你的机器的内存,至少可以容纳你的总数
据量的一半。
根据我们自己的生产环境实践经验,最佳的情况下,是仅仅在 es 中就存少量的数据,就是你要
用来搜索的那些索引,如果内存留给 filesystem cache 的是 100G,那么你就将索引数据
控制在 100G 以内,这样的话,你的数据几乎全部走内存来搜索,性能非常之高,一般可以在
1 秒以内。
比如说你现在有一行数据。 id,name,age … 30 个字段。但是你现在搜索,只需要根据 id,name,age 三个字段来搜索。如果你傻乎乎往 es 里写入一行数据所有的字段,就会导致说
90% 的数据是不用来搜索的,结果硬是占据了 es 机器上的 filesystem cache 的空间,单
条数据的数据量越大,就会导致 filesystem cahce 能缓存的数据就越少。其实,仅仅写入
es 中要用来检索的少数几个字段就可以了,比如说就写入 es id,name,age 三个字段,然后
你可以把其他的字段数据存在 mysql/hbase 里,我们一般是建议用 es + hbase 这么一个架
构
hbase 的特点是适用于海量数据的在线存储,就是对 hbase 可以写入海量数据,但是不要做
复杂的搜索,做很简单的一些根据 id 或者范围进行查询的这么一个操作就可以了。从 es 中根
据 name 和 age 去搜索,拿到的结果可能就 20 个 doc id ,然后根据 doc id 到 hbase 里去
查询每个 doc id 对应的完整的数据,给查出来,再返回给前端。
写入 es 的数据最好小于等于,或者是略微大于 es 的 filesystem cache 的内存容量。然后你从 es检索可能就花费 20ms,然后再根据 es 返回的 id 去 hbase 里查询,查 20 条数据,可能也就耗费个 30ms,可能你原来那么玩儿,1T 数据都放 es,会每次查询都是 5~10s,现在可能性能就会很高,每次查询就是 50ms。
102、假如,es 集群中每个机器写入的数据量还是超过了filesystem cache 一倍,比如说你写入一台机器 60G 数据,结果 filesystem cache 就 30G,还是有 30G 数据留在了磁盘上。
- 数据预热
将热数据,刷到 filesystem cache 里去,后面用户实际上来看这个热数据的时候,他们就是直接从内存里搜索了,很快。 - 冷热分离
假设你有 6 台机器,2 个索引,一个放冷数据,一个放热数据,每个索引 3 个 shard。3
台机器放热数据 index,另外 3 台机器放冷数据 index。然后这样的话,你大量的时间是在访问
热数据 index,热数据可能就占总数据量的 10%,此时数据量很少,几乎全都保留在
filesystem cache 里面了,就可以确保热数据的访问性能是很高的。但是对于冷数据而言,
是在别的 index 里的,跟热数据 index 不在相同的机器上,大家互相之间都没什么联系了。如
果有人访问冷数据,可能大量数据是在磁盘上的,此时性能差点,就 10% 的人去访问冷数据,
90% 的人在访问热数据,也无所谓了。
103、es分页性能优化
es 的分页是较坑的,为啥呢?举个例子吧,假如你每页是 10 条数据,你现在要查询第 100
页,实际上是会把每个 shard 上存储的前 1000 条数据都查到一个协调节点上,如果你有个 5 个 shard,那么就有 5000 条数据,接着协调节点对这 5000 条数据进行一些合并、处理,再获取到最终第 100 页的 10 条数据。
分布式的,你要查第 100 页的 10 条数据,不可能说从 5 个 shard,每个 shard 就查 2 条数据,最后到协调节点合并成 10 条数据吧?你必须得从每个 shard 都查 1000 条数据过来,然后根据你的需求进行排序、筛选等等操作,最后再次分页,拿到里面第 100 页的数据。你翻页的时候,翻的越深,每个 shard 返回的数据就越多,而且协调节点处理的时间越长,非常坑爹。所以用 es 做分页的时候,你会发现越翻到后面,就越是慢。
- 不允许深度分页
- 类似于 app 里的推荐商品不断下拉出来一页一页的,可以用scroll api
104、ES 生产集群的部署架构是什么?每个索引的数据量大概有多少?每个索引大概有多少个分片?
- es 生产集群我们部署了 5 台机器,每台机器是 6 核 64G 的,集群总内存是 320G。
- 我们 es 集群的日增量数据大概是 2000 万条,每天日增量数据大概是 500MB,每月增量数据大概是 6 亿,15G。目前系统已经运行了几个月,现在 es 集群里数据总量大概是 100G 左右。
- 目前线上有 5 个索引(这个结合你们自己业务来,看看自己有哪些数据可以放 es 的),每个索引的数据量大概是 20G,所以这个数据量之内,我们每个索引分配的是 8 个 shard,比默认的 5 个 shard 多了 3 个 shard。
105、redis的内存淘汰策略
- noeviction: 当内存不足以容纳新写入数据时,新写入操作会报错,这个一般没人用吧,实在是太恶心了。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)。
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个 key,这个一般没人用吧,为啥要随机,肯定是把最近最少使用的 key 给干掉啊。
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 key(这个一般不太合适)。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机除某个 key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期间的 key 优先移除。
106、redis哨兵主备切换的数据丢失问题
- master->slave 的复制是异步的,所以可能有部分数据还没复制到 slave,master 就宕机了,此时这部分数据就丢失了。
min-slaves-max-lag 10
数据复制和同步的延迟不能超过 10 秒。一旦 slave 复制数据和 ack 延时太长,
就认为可能 master 宕机后损失的数据太多了,那么就拒绝写请求,这样可以把 master 宕机时
由于部分数据未同步到 slave 导致的数据丢失降低的可控范围内。
- 脑裂导致的数据丢失。某个 master 所在机器突然脱离了正常的网络,跟其他 slave 机器不能连接,但是实际上 master 还运行着。此时哨兵可能就会认为 master 宕机了,然后开启选举,将其他 slave 切换成了 master。这个时候,集群里就会有两个 master ,也就是所谓的脑裂。此时虽然某个 slave 被切换成了 master,但是可能 client 还没来得及切换到新的 master,还继续向旧 master 写数据。因此旧 master 再次恢复的时候,会被作为一个 slave 挂到新的 master上去,自己的数据会清空,重新从新的 master 复制数据。而新的 master 并没有后来 client 写入的数据,因此,这部分数据也就丢失了。
min-slaves-max-lag 10
如果一个 master 出现了脑裂,跟其他 slave 丢了连接,那么上面两个配置可以确保说,如果不
能继续给指定数量的 slave 发送数据,而且 slave 超过 10 秒没有给自己 ack 消息,那么就直接
拒绝客户端的写请求。因此在脑裂场景下,最多就丢失 10 秒的数据。
min-slaves-to-write 1
要求至少有 1 个 slave
107、主观宕机sdown和客观宕机odown
- sdown 是主观宕机,就一个哨兵如果自己觉得一个 master 宕机了,那么就是主观宕机
- odown 是客观宕机,如果 quorum 数量的哨兵都觉得一个 master 宕机了,那么就是客观宕机
sdown 达成的条件很简单,如果一个哨兵 ping 一个 master,超过了 is-master-down-after- milliseconds 指定的毫秒数之后,就主观认为 master 宕机了;如果一个哨兵在指定时间内,
收到了 quorum 数量的其它哨兵也认为那个 master 是 sdown 的,那么就认为是 odown 了。
108、为什么要分库分表(设计高并发系统的时候,数据库层面该如何设计)?
分库分表一定是为了支撑高并发、数据量大两个问题的。
说白了,分库分表是两回事儿,大家可别搞混了,可能是光分库不分表,也可能是光分表不分库,都有可能。
分表
比如你单表都几千万数据了,你确定你能扛住么?绝对不行,单表数据量太大,会极大影响你
的 sql 执行的性能,到了后面你的 sql 可能就跑的很慢了。一般来说,就以我的经验来看,单
表到几百万的时候,性能就会相对差一些了,你就得分表了。
分表是啥意思?就是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照
用户 id 来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个
表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在 200 万以内。
例如:日志表,如果按天分表,你可以创建像 “log_2023_08_10” 这样的表,将 2023 年 8 月 10 日的日志数据存储在其中。对于查询,如果你需要查询从 2023 年 8 月 1 日到 2023 年 8 月 10 日的数据,就需要在相关的分表中进行查询,然后将结果合并。
SELECT * FROM log_2023_08_01 WHERE timestamp BETWEEN '2023-08-01 00:00:00' AND '2023-08-01 23:59:59'
UNION ALL
SELECT * FROM log_2023_08_02 WHERE timestamp BETWEEN '2023-08-02 00:00:00' AND '2023-08-02 23:59:59'
-- ...
UNION ALL
SELECT * FROM log_2023_08_10 WHERE timestamp BETWEEN '2023-08-10 00:00:00' AND '2023-08-10 23:59:59';
分库
分库是啥意思?就是你一个库一般我们经验而言,最多支撑到并发 2000,一定要扩容了,而且
一个健康的单库并发值你最好保持在每秒 1000 左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
109、用过哪些分库分表中间件?不同的分库分表中间件都有什 么优点和缺点?
- mycat:proxy层
- sharding-jdbc:client层
- tddl:client层
- Atlas:proxy层
综上,现在其实建议考量的,就是 Sharding-jdbc 和 Mycat,这两个都可以去考虑使用。
Sharding-jdbc 这种 client 层方案的优点在于不用部署,运维成本低,不需要代理层的二次 转发请求,性能很高,但是如果遇到升级啥的需要各个系统都重新升级版本再发布,各个系
统都需要耦合 Sharding-jdbc 的依赖;
Mycat 这种 proxy 层方案的缺点在于需要部署,自己运维一套中间件,运维成本高,但是好处 在于对于各个项目是透明的,如果遇到升级之类的都是自己中间件那里搞就行了。
通常来说,这两个方案其实都可以选用,但是我个人建议中小型公司选用 Sharding-jdbc,client层方案轻便,而且维护成本低,不需要额外增派人手,而且中小型公司系统复杂度会低一些,项目也没那么多;但是中大型公司最好还是选用 Mycat 这类 proxy 层方案,因为可能大公司系统和项目非常多,团队很大,人员充足,那么最好是专门弄个人来研究和维护 Mycat,然后大量项目直接透明使用即可。
110、你们具体是如何对数据库如何进行垂直拆分或水平拆分的?
- 水平拆分:将数据均匀放更多的库里,然后用多个库来扛更高的并发,还有就是用多个库的存储容量来进行扩容。
- 垂直拆分:就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字 段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库
是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。 - 按照 range 来分,就是每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了。
- 或者是按照某个字段 hash 一下均匀分散,这个较为常用。
111、现在有一个未分库分表的系统,未来要分库分表,如何设计才可以让系统从未分库分表动态切 换到分库分表上?
- 比较low的方案:大家伙儿凌晨 12 点开始运维,网站或者 app 挂个公告,说 0 点到早上 6 点进行运维,无法访问。接着到 0 点停机,系统停掉,没有流量写入了,此时老的单库单表数据库静止了。然后你之前得写好一个导数的一次性工具,此时直接跑起来,然后将单库单表的数据哗哗哗读出来,写到分库分表里面去。导数完了之后,就 ok 了,修改系统的数据库连接配置啥的,包括可能代码和 SQL 也许有修改,那你就用最新的代码,然后直接启动连到新的分库分表上去。
- 双写迁移方案:简单来说,就是在线上系统里面,之前所有写库的地方,增删改操作,除了对老库增删改, 都加上对新库的增删改,这就是所谓的双写,同时写俩库,老库和新库。然后系统部署之后,新库数据差太远,用之前说的导数工具,跑起来读老库数据写新库,写的时候要根据 gmt_modified 这类字段判断这条数据最后修改的时间,除非是读出来的数据在新库里没有,或者是比新库的数据新才会写。简单来说,就是不允许用老数据覆盖新数据。导完一轮之后,有可能数据还是存在不一致,那么就程序自动做一轮校验,比对新老库每个表的每条数据,接着如果有不一样的,就针对那些不一样的,从老库读数据再次写。反复循环,直到两个库每个表的数据都完全一致为止。接着当数据完全一致了,就 ok 了,基于仅仅使用分库分表的最新代码,重新部署一次,不就仅仅基于分库分表在操作了么,还没有几个小时的停机时间,很稳。所以现在基本玩儿数据迁移之类的,都是这么干的。
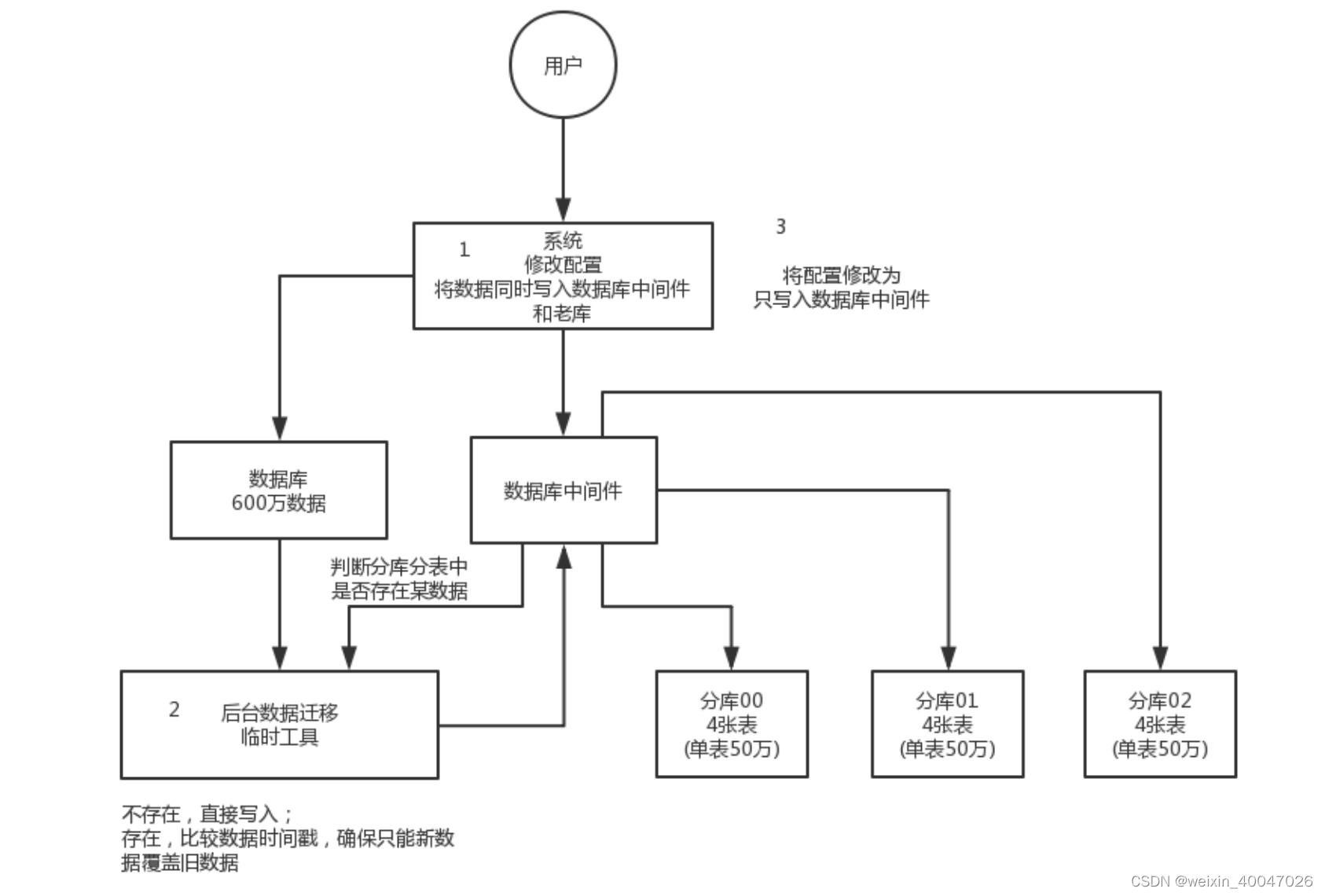
112、如何设计可以动态扩容缩容的分库分表方案?
- 停机扩容(不推荐)
- 第一次分库分表,就一次性给他分个够,32 个库,每个库32张表,1024 张表,可能对大部分的中小型互联网公司来说,已经可以支撑好几年了。
113、MySQL 主从复制原理的是啥?
1、主库将变更记录到binlog
2、从库中有一个IO线程,将主库的binlog日志拷贝到自己本地,并写入一个relay中继日志中
3、从库中还有一个SQL线程,会从中继日志读取sql并执行;
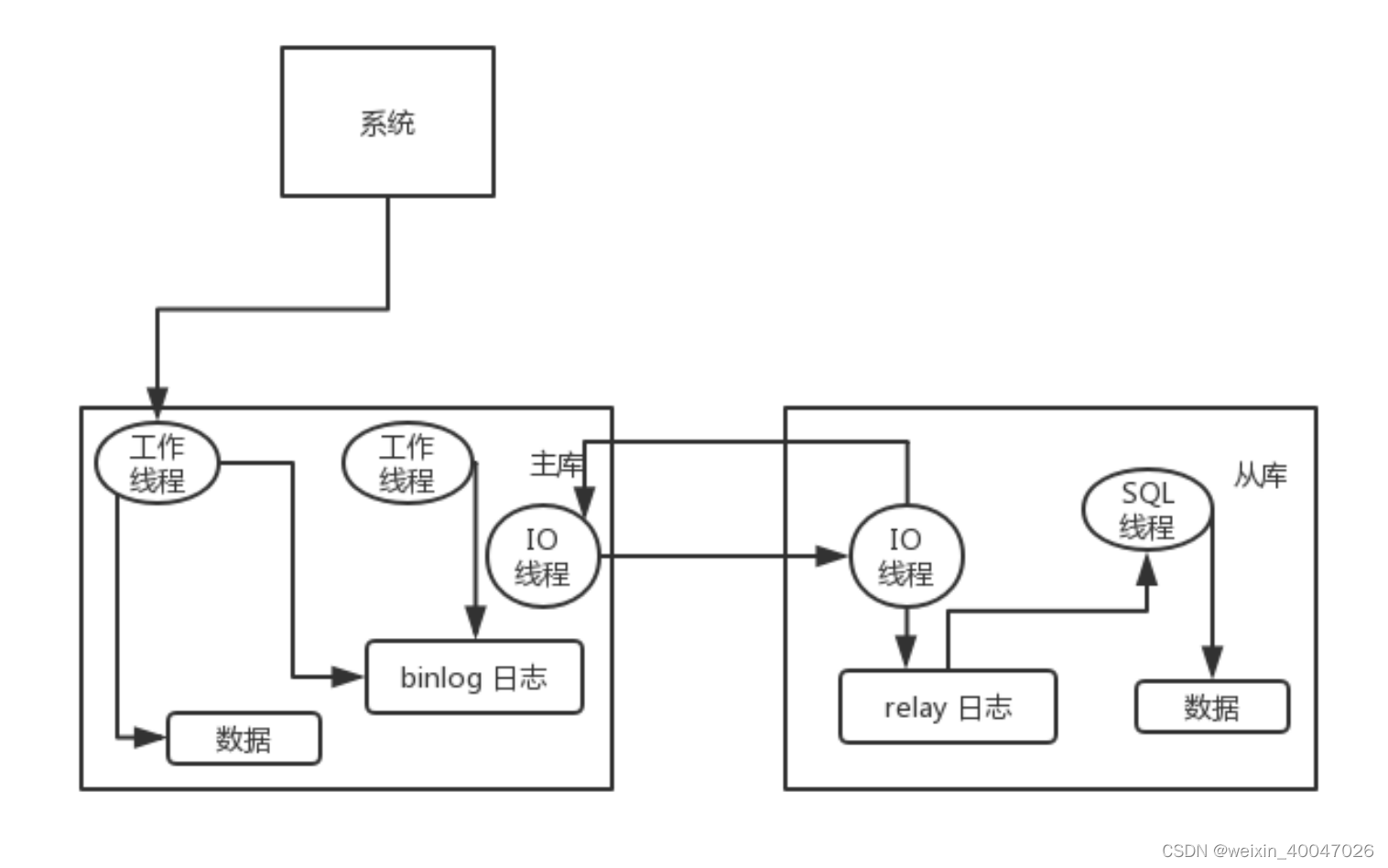
114、mysql主从同步延时问题
这里有一个非常重要的一点,就是从库同步主库数据的过程是串行化的,也就是说主库上并行
的操作,在从库上会串行执行。所以这就是一个非常重要的点了,由于从库从主库拷贝日志以
及串行执行 SQL 的特点,在高并发场景下,从库的数据一定会比主库慢一些,是有延时的。所
以经常出现,刚写入主库的数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
并行复制
指的是从库开启多个线程,并行读取 relay log 中不同库的日志,然后并行重 放不同库的日志,这是库级别的并行。
通过 MySQL 命令:
show status
查看 Seconds_Behind_Master ,可以看到从库复制主库的数据落后了几 ms。
一般来说,如果主从延迟较为严重,有以下解决方案:
- 分库,将一个主库拆分为多个主库,每个主库的写并发就减少了几倍,此时主从延迟可以忽略不计。
- 查主库,不推荐这种方法,你要是这么搞,读写分离的意义就丧失了。
- 重写代码,写代码的同学,要慎重,插入数据时立马查询可能查不到。
- 打开 MySQL 支持的并行复制,多个库并行复制。如果说某个库的写入并发就是特别高,单库写并发达到了 2000/s,并行复制还是没意义。
115、如何设计一个高并发系统?
1、对于高并发系统一般都会做系统的拆分,拆分成多个子系统,dubbo、springcloud,每个子系统对应一个数据库,这样也可以抗并发
2、当轻断发起请求后,先经过缓存。大部分的高并发场景,都是读多写少,那你完全可以在数据库和缓存里都写一份,然后读的时候大量走缓存不就得了。毕竟人家 redis 轻轻松松单机几万的并发。所以你可以考虑考虑你的项目里,那些承载主要请求的读场景,怎么用缓存来抗高并发。
3、MQ:异步、解藕、削峰
4、分库分表
5、读写分离,读流量太多的时候,还可以加更多的从库。
6、es,es 是分布式的,可以随便扩容,分布式天然就可以支撑高并发,因为动不动就可以扩容加机器来扛更高的并发。那么一些比较简单的查询、统计类的操作,可以考虑用 es 来承载,还有一些全文搜索类的操作,也可以考虑用 es 来承载。
116、InnoDB为什么采用B+树
- 数据库查询经常会出现非等值查询,哈希索引在这种情况下无法工作;
- 相比于B树,B+树索引非叶子节点不存放数据,从而磁盘一次IO可以读取更多的索引数据,有效减少磁盘IO次数;
- 数据库查询经常会出现范围查询,B+树底层的叶子节点之间按照顺序排列,可以更有效的实现范围查询;
InnoDB采用B+树作为其存储引擎的索引结构,有以下几个主要原因:
有序性: B+树是一种自平衡的树结构,可以保持数据的有序性。对于数据库中的索引,有序性非常重要,因为它可以减少磁盘I/O次数,提高查询效率。
范围查询: B+树支持范围查询非常高效,因为相邻的数据在B+树中也是相邻的,这样在范围查询时,可以快速定位范围的起点和终点,减少不必要的磁盘读取。
数据块访问: InnoDB使用了数据块(页)作为磁盘和内存之间的基本单位。B+树的叶子节点是双向链表,可以方便地进行数据块的顺序访问,提高I/O的效率。
适合高并发: B+树在插入和删除操作时,不需要频繁地调整树的平衡,这使得它适用于高并发的数据库操作,减少锁冲突和并发竞争。
磁盘空间利用: B+树对于磁盘空间的利用非常高效,因为每个节点中都存储了多个关键字,可以减少树的高度,从而减少了磁盘的访问次数。
总之,InnoDB选择采用B+树作为索引结构,是为了提供高效的数据访问、范围查询、适应高并发和节省磁盘空间等优势。这些特点使得B+树成为了关系型数据库中常用的索引结构之一。
117、dubbo 工作原理和工作流程
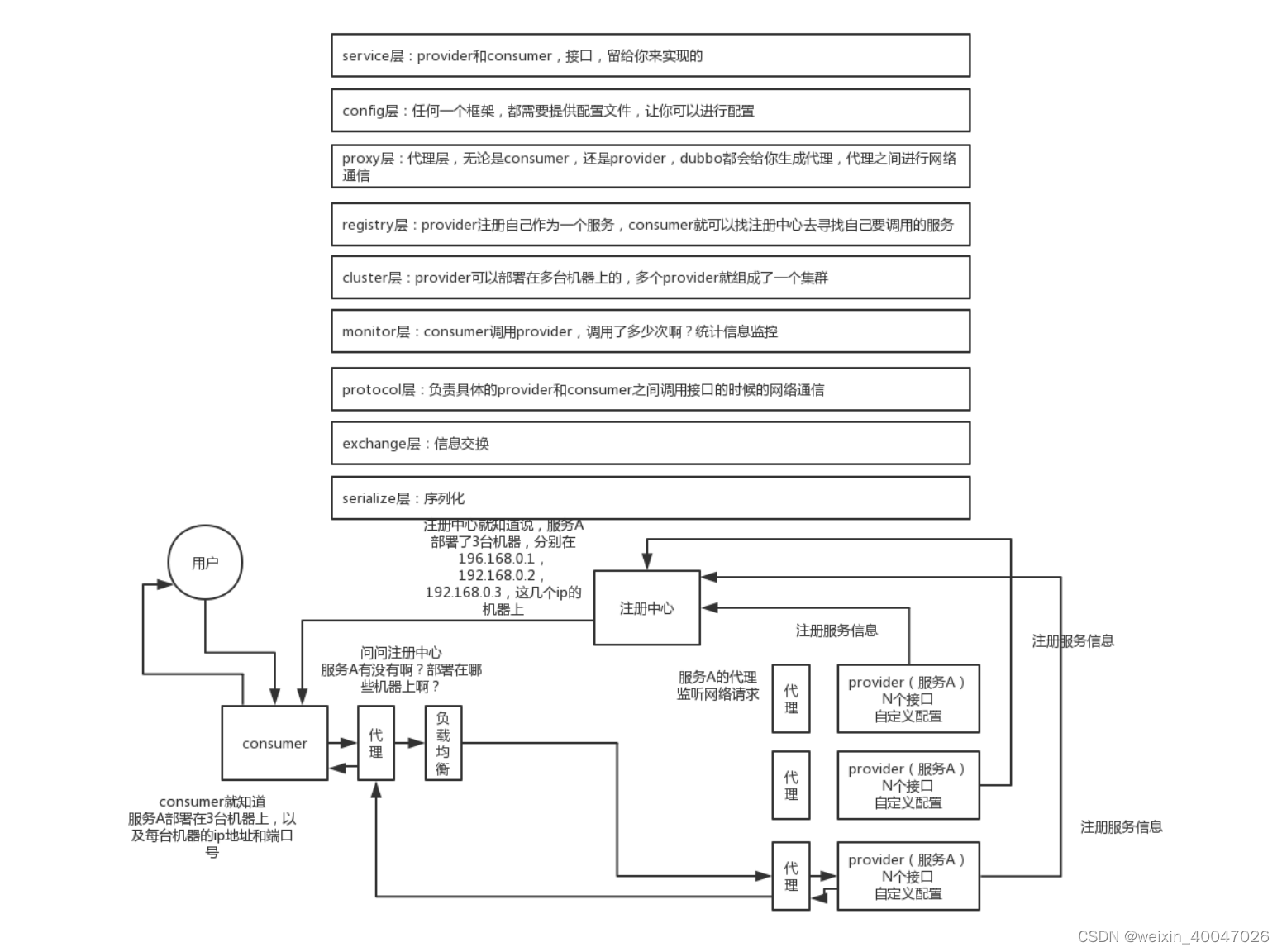
118、dubbo 支持哪些通信协议?支持哪些序列化协议?
- 通讯协议
-
dubbo协议
默认就是走 dubbo 协议,单一长连接,进行的是 NIO 异步通信,基于 hessian 作为序列化协议。使用的场景是:传输数据量小(每次请求在 100kb 以内),但是并发量很高。为了要支持高并发场景,一般是服务提供者就几台机器,但是服务消费者有上百台,可能每天调用量达到上亿次!此时用长连接是最合适的,就是跟每个服务消费者维持一个长连接就可以,可能总共就 100 个连接。然后后面直接基于长连接 NIO 异步通信,可以支撑高并发请求。
-
rmi 协议
走 Java 二进制序列化,多个短连接,适合消费者和提供者数量差不多的情况,适用于文件的传输,一般较少用。 -
hessian 协议
走 hessian 序列化协议,多个短连接,适用于提供者数量比消费者数量还多的情况,适用于文件的传输,一般较少用。 -
http 协议
走表单序列化 -
webservice
走 SOAP 文本序列化。
-
长连接,通俗点说,就是建立连接过后可以持续发送请求,无须再建立连接。
短连接,每次要发送请求之前,需要先重新建立一次连接
- 序列化协议
- hession(默认)
- Java二进制序列化
- json
- soap
119、dubbo 负载均衡策略都有哪些?
- RandomLoadBalance:随机
默认情况下,dubbo 是 RandomLoadBalance ,即随机调用实现负载均衡,可以对 provider 不同实例设置不同的权重,会按照权重来负载均衡,权重越大分配流量越高,一般就用这个默认的就可以了。 - RoundRobinLoadBalance:均匀
均匀地将流量打到各个机器上去,但是如果各个机器的性能不一样,容易导致性能差的机器负载过高。所以此时需要调整权重,让性能差的机器承载权重小一些,流量少一些。 - LeastActiveLoadBalance:自动感知
这个就是自动感知一下,如果某个机器性能越差,那么接收的请求越少,越不活跃,此时就会给不活跃的性能差的机器更少的请求。 - ConsistentHashLoadBalance:一致性 Hash 算法
相同参数的请求一定分发到一个 provider 上去,provider 挂掉的时候,会基于虚拟节点均匀分配剩余的流量,抖动不会太大。如果你需要的不是随机负载均衡,是要一类请求都到一个节点,那就走这个一致性 Hash 策略。
120、dubbo 集群容错策略
- Failover Cluster: 失败自动切换,自动重试其他机器(默认)
- Failfast Cluster : 调用失败就立即失败
常见于非幂等性的写操作,比如新增一条记录(调用失败就立即失
败) - Failsafe Cluster :出现异常时忽略掉
常用于不重要的接口调用,比如记录日志 - Failback Cluster :失败了后台自动记录请求,然后定时重发,比较适合于写消息队列这种。
- Forking Cluster :并行调用多个 provider,只要一个成功就立即返回。
常用于实时性要求比较高的读操作,但是会浪费更多的服务资源,可通过 forks=“2” 来设置最大并行数。 - Broadcast Cluster :逐个调用所有的 provider。
任何一个 provider 出错则报错(从 2.1.0 版本开始支持)。通常用于通知所有提供者更新缓存或日志等本地资源信息。
121、spi是啥?dubbo的spi是怎么实现的?
@SPI("dubbo")
public interface Protocol {
int getDefaultPort();
@Adaptive
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
@Adaptive
<T> Invoker<T> refer(Class<T> type, URL url) throws RpcException;
void destroy();
}
在 dubbo 自己的 jar 里,在 /META_INF/dubbo/internal/com.alibaba.dubbo.rpc.Protocol文件中:
dubbo=com.alibaba.dubbo.rpc.protocol.dubbo.DubboProtocol
http=com.alibaba.dubbo.rpc.protocol.http.HttpProtocol
hessian=com.alibaba.dubbo.rpc.protocol.hessian.HessianProtocol
@SPI(“dubbo”) 说的是,通过 SPI 机制来提供实现类,实现类是通过 dubbo 作为默认 key 去配置文件里找到的,配置文件名称与接口全限定名一样的,通过 dubbo 作为 key 可以找到默认的实现类就是 com.alibaba.dubbo.rpc.protocol.dubbo.DubboProtocol 。
122、分布式服务接口的幂等性如何设计(比如不能重复扣款)?
其实保证幂等性主要是三点:
- 对于每个请求有唯一标识
- 每次请求处理完,必须要标记为已完成。比如支付之前记录一条这个订单的支付流水。
- 每次接收请求前根据唯一标识和标记判断之前是否有处理过。
123、分布式服务接口请求的顺序性如何保证?
队列
用 Dubbo 的一致性 hash 负载均衡策略,将比如某一个订单 id 对应的请求都给分发到某个机器上去,接着就是在那个机器上,因为可能
还是多线程并发执行的,你可能得立即将某个订单 id 对应的请求扔一个内存队列里去,强制排队,这样来确保他们的顺序性
124、什么是分区容错性?
分区容错性是指分布式系统中,特别是消息队列系统中,通过将数据分为多个分区partitions,每个分区存储在不同的节点上,以增强系统的可靠性和稳定性。
在消息队列系统中,分区容错性的好处包括
1、故障隔离:每个分区存储在不同的节点上,如果一个节点发生故障,只会影响到该节点上的分区,而不会影响到其它分区的正常运行。
2、提高可用性:分区分布在多个节点上,即使某个节点不可用,其它节点上的分区仍可用
3、水平扩展:分区容错性支持系统的水平扩展,可以随着数据量的增加添加更多的节点和分区,而不必牺牲可靠性。
4、负载均衡:通过将数据分布在多个分区上,可以均匀分散负载,防止某些节点成为热点,从而提高系统的吞吐量和性能。
5、数据冗余:在分区容错性的系统中,通常会讲每个分区的数据进行复制,以增加数据的荣誉性,从而在某个分区发生故障时保证数据不会丢失。
125、分布式锁的实现
- redis分布式锁
- zk分布式锁
区别:
1、redis分布式锁,需要自己不断去尝试获取锁,比较消耗性能
2、zk分布式锁,获取不到锁,注册个监听器即可,不需要不断主动尝试获取锁,性能开销较小
另外一点就是,如果是redis获取锁的那个客户端出现bug挂了,那么只能等待超时时间之后才能释放锁;而zk的话,因为创建的是临时znode,只要客户端挂了,znode就没了,此时就自动释放锁。
126、使用redis分布式锁,redis宕机或者失效了怎么办
1、设置锁的过期时间,确保锁子冻释放,避免长时间的锁定
2、使用带有子冻续期功能的锁,防止在某些情况下因为网络原因导致的锁过早失效
3、使用Redloc算法,提高锁的可用性和安全性
4、redis哨兵集群保证高可用
5、zk分布式锁
127、分布式事务的实现方案
分布式事务的实现主要有6种方案
- 两阶段提交/XA方案
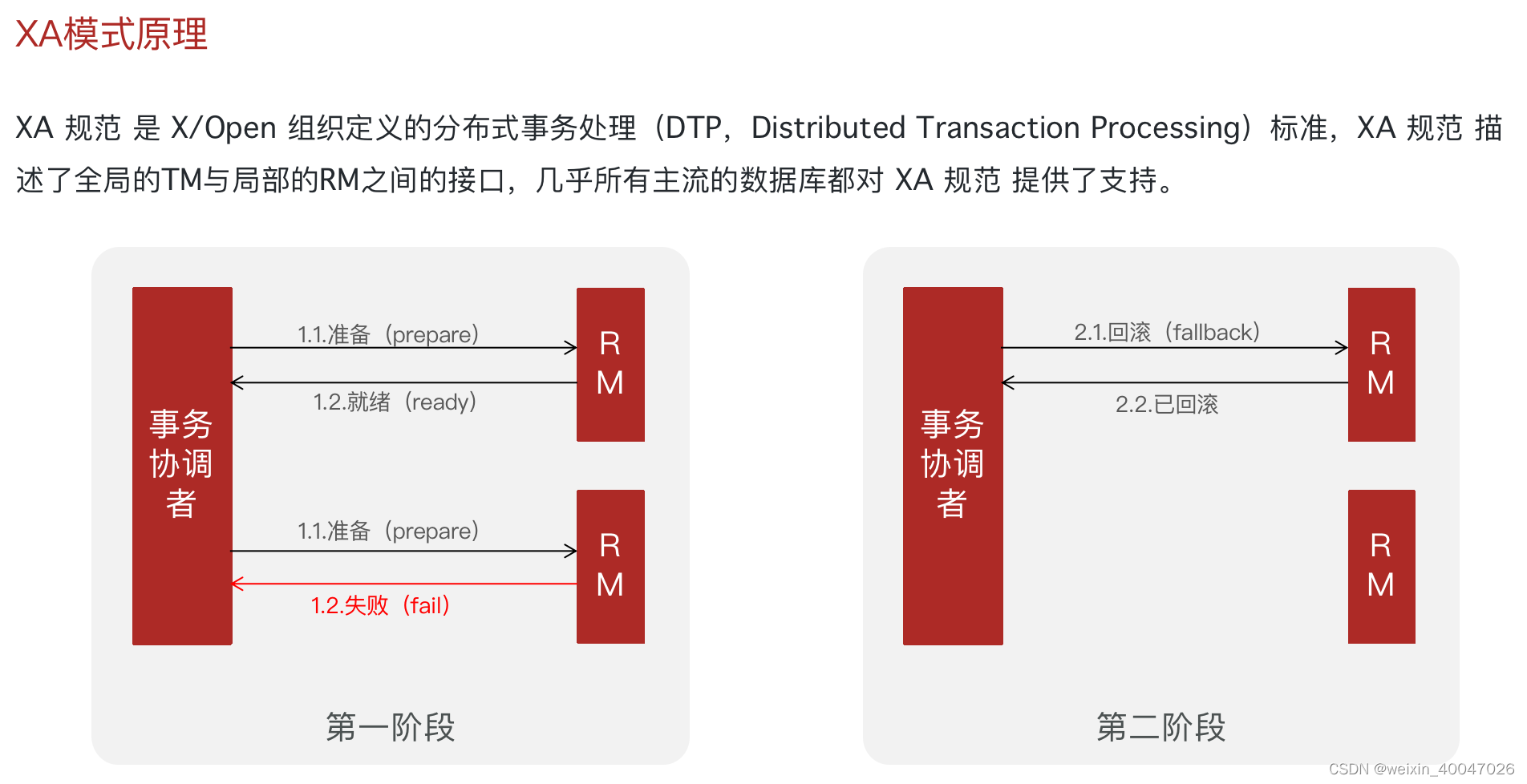
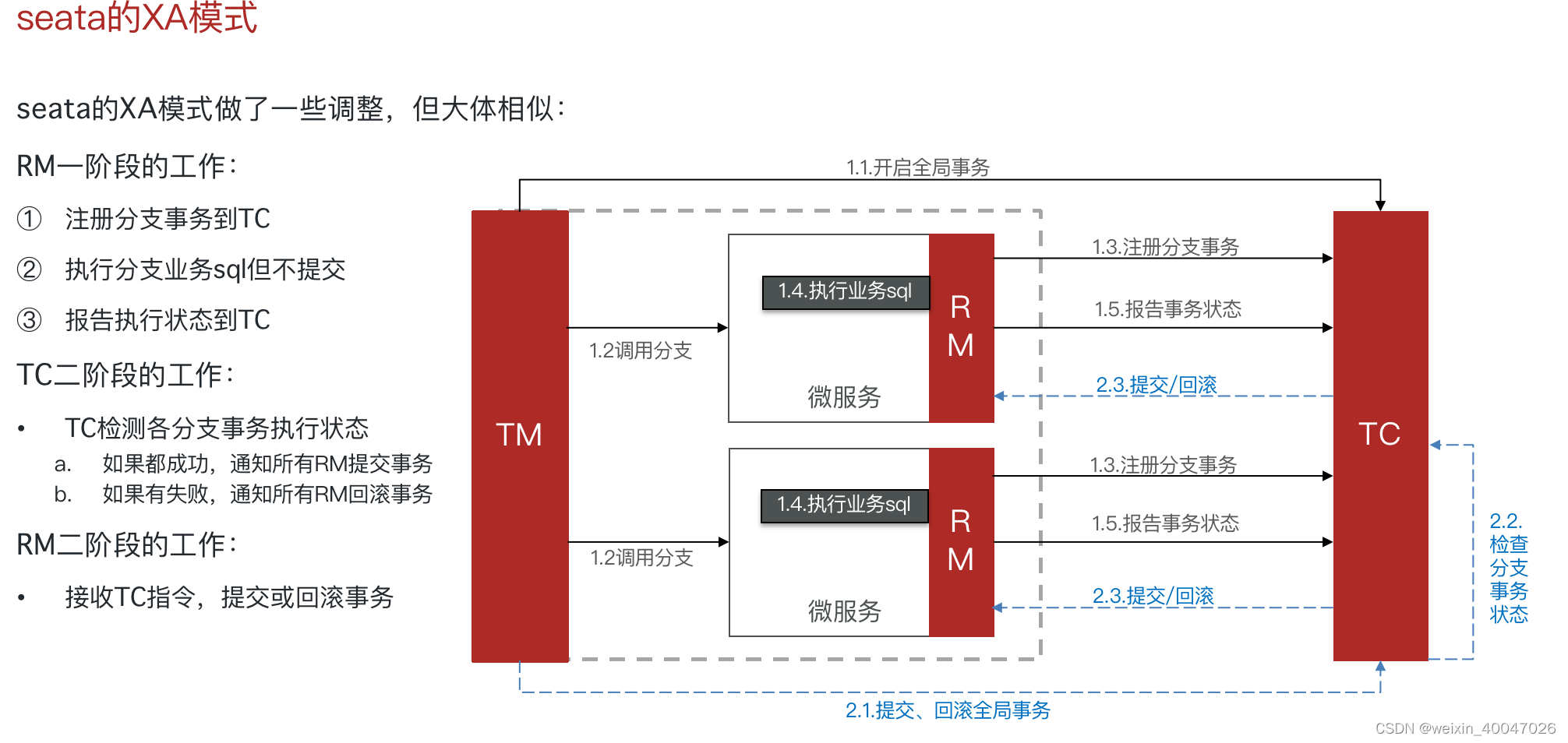
两阶段提交,有一个事务管理器的概念,负责协调多个数据库(资源管理器)的事务,事务管理器先问问各个数据库你准备好了吗?如果每个数据库都回复 ok,那么就正式提交事务,在各个数据库上执行操作;如果任何其中一个数据库回答不 ok,那么就回滚事务。
这种方案,比较适合单块应用,跨多个库的分布式事务,而且因为严重依赖于数据库层面来搞定复杂的事务,效率很低,绝对不适合高并发的场景。
很少用,在微服务中,一般来说,某个系统内部如果出现跨多个库的操作,是很不合规的。
- AT方案
- TCC方案
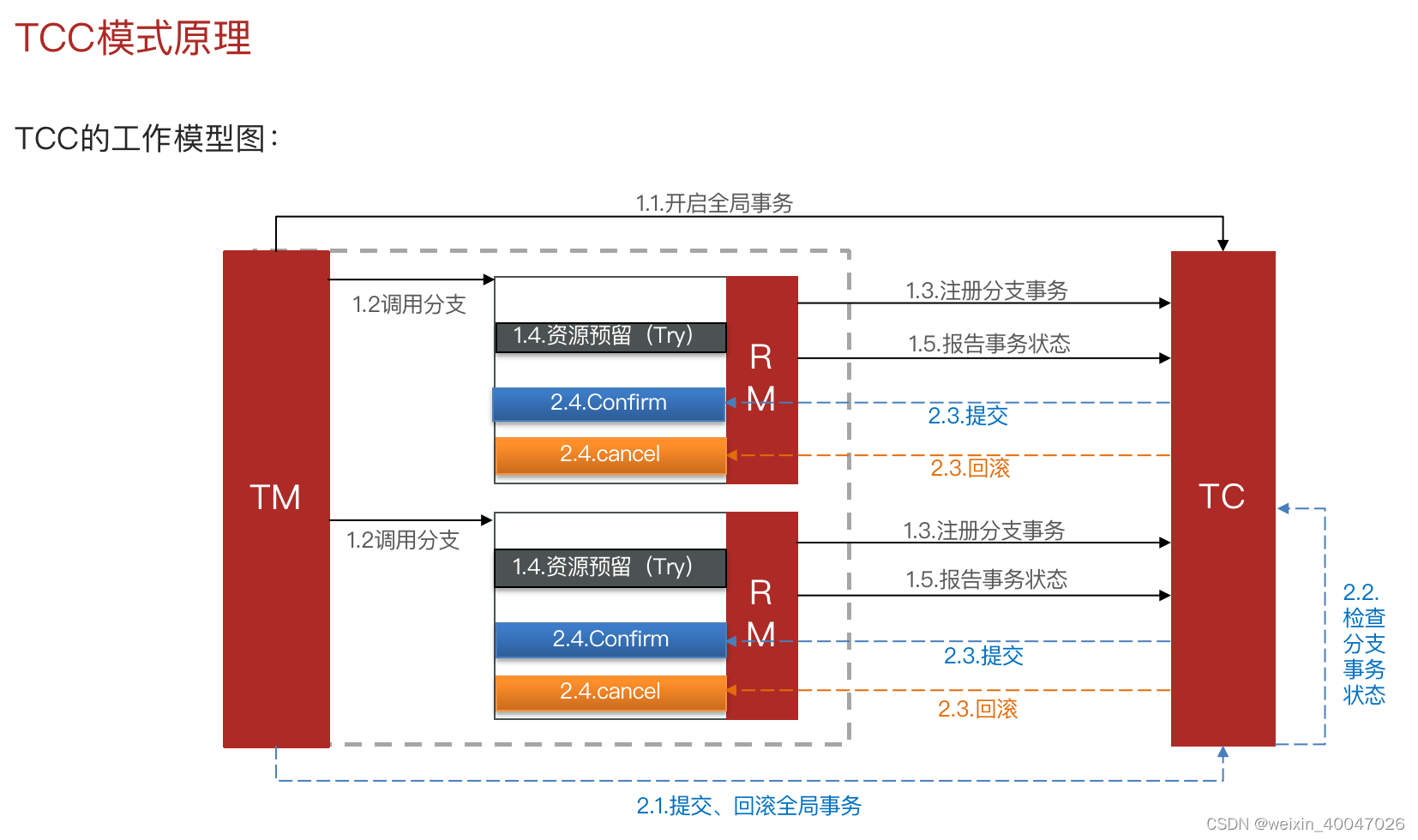
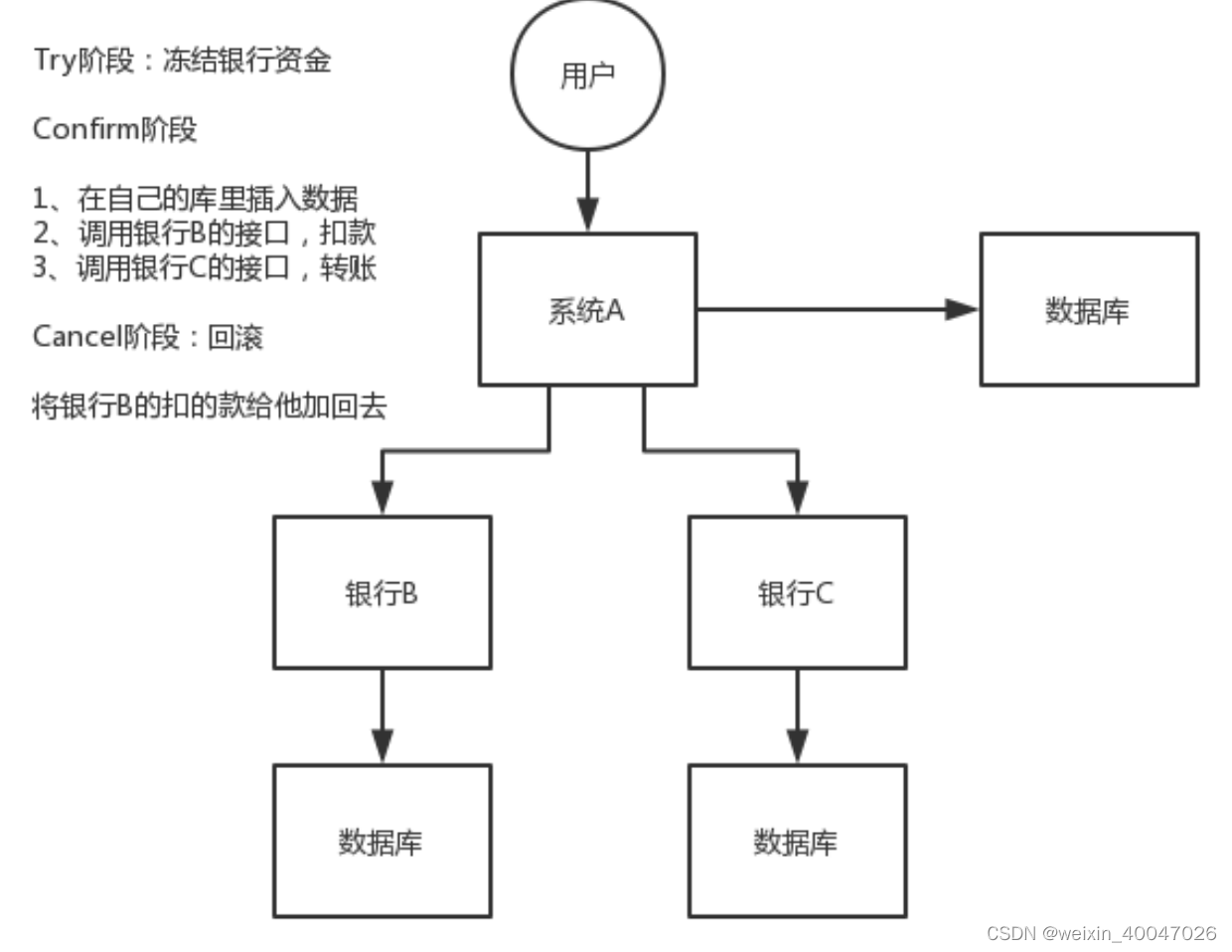
TCC 的全称是: Try 、 Confirm 、 Cancel 。
Try 阶段:这个阶段说的是对各个服务的资源做检测以及对资源进行锁定或者预留。
Confirm 阶段:这个阶段说的是在各个服务中执行实际的操作。
Cancel 阶段:如果任何一个服务的业务方法执行出错,那么这里就需要进行补偿,就是执行已经执行成功的业务逻辑的回滚操作。(把那些执行成功的回滚)
这种方案说实话几乎很少人使用。因为事务的回滚实际上严重依赖于你自己写代码来回滚和补偿了,会造成补偿代码巨大,非常恶心。
比如说我们,一般来说跟钱相关的,跟钱打交道的,支付、交易相关的场景,我们会用 TCC,严格保证分布式事务要么全部成功,要么全部自动回滚,严格保证资金的正确性,保证在资金上不会出现问题。
而且最好是你的各个业务执行的时间都比较短。
但是说实话,一般尽量别这么搞,自己手写回滚逻辑,或者是补偿逻辑,实在太恶心了,那个业务代码是很难维护的。
- SAGA补偿事务方案
金融核心等业务可能会选择 TCC 方案,以追求强一致性和更高的并发量,而对于更多的金融核心以上的业务系统 往往会选择补偿事务,补偿事务处理在 30 多年前就提出了 Saga 理论,随着微服务的发展,近些年才逐步受到大家的关注。目前业界比较公认的是采用 Saga 作为长事务的解决方案。
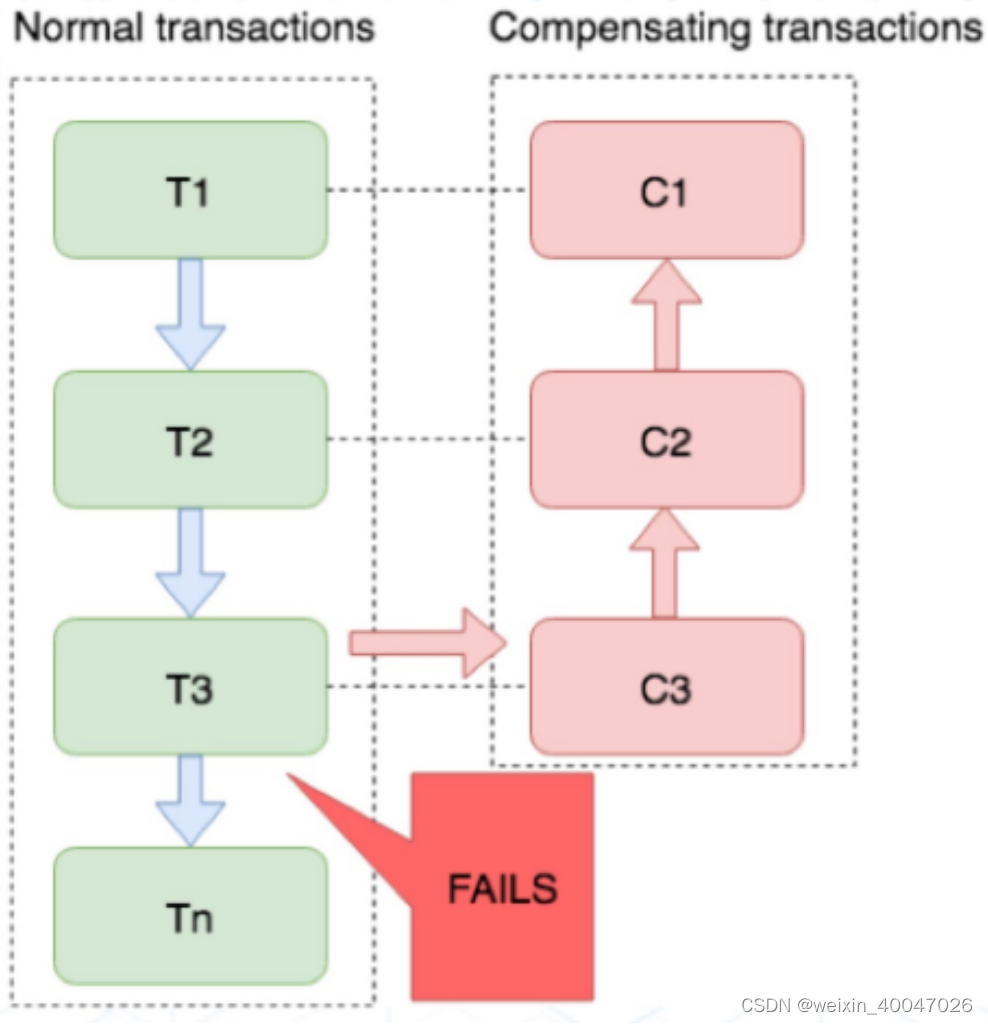
对于一致性要求高、短流程、并发高 的场景,如:金融核心系统,会优先考虑 TCC 方案。而在另外一些场景下,我们并不需要这么强的一致性,只需要保证最终一致性即可。
比如 很多金融核心以上的业务(渠道层、产品层、系统集成层),这些系统的特点是最终一致即可、流程多、流程长、还可能要调用其它公司的服务。这种情况如果选择 TCC 方案开发的话,一来成本高,二来无法要求其它公司的服务也遵循 TCC 模式。同时流程长,事务边界太长,加锁时间长,也会影响并发性能。
所以 Saga 模式的适用场景是:
1、业务流程长、业务流程多
2、参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口。
优点
一阶段提交本地事务,无锁,高性能;
参与者可异步执行,高吞吐;
补偿服务易于实现,因为一个更新操作的反向操作是比较容易理解的。
缺点
不保证事务的隔离性。
- 本地消息表
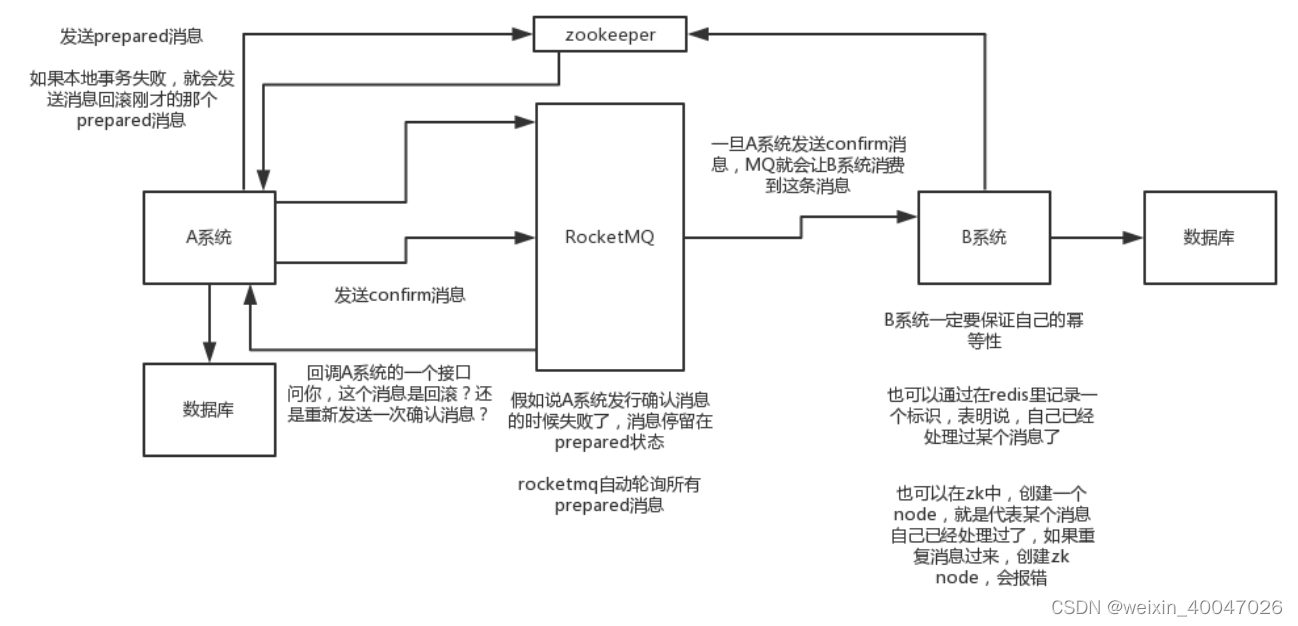
- 可靠性最终一致方案:基于 MQ 来实现事务
比如阿里的RocketMQ 就支持消息事务
- A 系统先发送一个 prepared 消息到 mq,如果这个 prepared 消息发送失败那么就直接取消操作别执行了;
- 如果这个消息发送成功过了,那么接着执行本地事务,如果成功就告诉 mq 发送确认消息,如果失败就告诉 mq 回滚消息;
- 如果发送了确认消息,那么此时 B 系统会接收到确认消息,然后执行本地的事务;
- mq 会自动定时轮询所有 prepared 消息回调你的接口,问你,这个消息是不是本地事务处理失败了,所有没发送确认的消息,是继续重试还是回滚?一般来说这里你就可以查下数据库看之前本地事务是否执行,如果回滚了,那么这里也回滚吧。这个就是避免可能本地事务执行成功了,而确认消息却发送失败了。
- 这个方案里,要是系统 B 的事务失败了咋办?重试咯,自动不断重试直到成功,如果实在是不行,要么就是针对重要的资金类业务进行回滚,比如 B 系统本地回滚后,想办法通知系统 A 也回滚;或者是发送报警由人工来手工回滚和补偿。
- 这个还是比较合适的,目前国内互联网公司大都是这么玩儿的,要不你就用 RocketMQ 支持的,要不你就自己基于类似 ActiveMQ?RabbitMQ?自己封装一套类似的逻辑出来,总之思路就是这样子的
- 最大努力通知方案
128、你们公司是如何处理分布式事务的
可以这么说,我们某某特别严格的场景,用的是 TCC 来保证强一致性;然后其他的一些场景基于阿里的 RocketMQ 来实现分布式事务。
如果是一般的分布式事务场景,比如说订单插入之后要调用库存服务更新库存,库存数据没有资金那么的敏感,可以用可靠消息最终一致性方案。
129、集群部署时的分布式 Session 如何实现?
- 单体的session是怎么玩的?
浏览器有个 Cookie,在一段时间内这个 Cookie 都存在,然后每次发请求过来都带上一个特殊的 jsessionid cookie ,就根据这个东西,在服务端可以维护一个对应的Session 域,里面可以放点数据。
一般的话只要你没关掉浏览器,Cookie 还在,那么对应的那个 Session 就在,但是如果 Cookie没了,Session 也就没了。常见于什么购物车之类的东西,还有登录状态保存之类的。
-
JWT
-
Tomcat+Redis
这个其实还挺方便的,就是使用 Session 的代码,跟以前一样,还是基于 Tomcat 原生的Session 支持即可,然后就是用一个叫做 Tomcat RedisSessionManager 的东西,让所有我们部署的tomcat都将session数据存储到redis即可。 -
Spring Session+Redis
上面所说的第二种方式会与 Tomcat 容器重耦合,如果我要将 Web 容器迁移成 Jetty,难道还要重新把 Jetty 都配置一遍?上面那种 Tomcat + Redis 的方式好用,但是会严重依赖于 Web 容器,不好将代码移植到其他 Web 容器上去,尤其是你要是换了技术栈咋整?比如换成了 Spring Cloud 或者是 Spring Boot 之类的呢?
所以现在比较好的还是基于 Java 一站式解决方案,也就是 Spring。
给 Spring Session 配置基于 Redis 来存储 Session 数据,然后配置了一个 Spring Session 的过滤器,这样的话,Session 相关操作都会交给 Spring Session 来管了。接着在代码中,就用原生的 Session 操作,就是直接基于 Spring Session 从 Redis 中获取数据了。
130、限流的实现方式
- 计数器
- 滑动窗口
- 漏桶
- 令牌桶
工作中的使用
1、gateway
spring cloud gateway 默认使用redis进行限流, 一般只是修改修改参数属于拿来即用. 并没有去从头实现上述那些算法.
2、sentinel
通过配置来控制每个url的流量
智能推荐
从零开始搭建Hadoop_创建一个hadoop项目-程序员宅基地
文章浏览阅读331次。第一部分:准备工作1 安装虚拟机2 安装centos73 安装JDK以上三步是准备工作,至此已经完成一台已安装JDK的主机第二部分:准备3台虚拟机以下所有工作最好都在root权限下操作1 克隆上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;1.1 进行克隆21.2 下一步1.3 下一步1.4 下一步1.5 根据子机需要,命名和安装路径1.6 ..._创建一个hadoop项目
心脏滴血漏洞HeartBleed CVE-2014-0160深入代码层面的分析_heartbleed代码分析-程序员宅基地
文章浏览阅读1.7k次。心脏滴血漏洞HeartBleed CVE-2014-0160 是由heartbeat功能引入的,本文从深入码层面的分析该漏洞产生的原因_heartbleed代码分析
java读取ofd文档内容_ofd电子文档内容分析工具(分析文档、签章和证书)-程序员宅基地
文章浏览阅读1.4k次。前言ofd是国家文档标准,其对标的文档格式是pdf。ofd文档是容器格式文件,ofd其实就是压缩包。将ofd文件后缀改为.zip,解压后可看到文件包含的内容。ofd文件分析工具下载:点我下载。ofd文件解压后,可以看到如下内容: 对于xml文件,可以用文本工具查看。但是对于印章文件(Seal.esl)、签名文件(SignedValue.dat)就无法查看其内容了。本人开发一款ofd内容查看器,..._signedvalue.dat
基于FPGA的数据采集系统(一)_基于fpga的信息采集-程序员宅基地
文章浏览阅读1.8w次,点赞29次,收藏313次。整体系统设计本设计主要是对ADC和DAC的使用,主要实现功能流程为:首先通过串口向FPGA发送控制信号,控制DAC芯片tlv5618进行DA装换,转换的数据存在ROM中,转换开始时读取ROM中数据进行读取转换。其次用按键控制adc128s052进行模数转换100次,模数转换数据存储到FIFO中,再从FIFO中读取数据通过串口输出显示在pc上。其整体系统框图如下:图1:FPGA数据采集系统框图从图中可以看出,该系统主要包括9个模块:串口接收模块、按键消抖模块、按键控制模块、ROM模块、D.._基于fpga的信息采集
微服务 spring cloud zuul com.netflix.zuul.exception.ZuulException GENERAL-程序员宅基地
文章浏览阅读2.5w次。1.背景错误信息:-- [http-nio-9904-exec-5] o.s.c.n.z.filters.post.SendErrorFilter : Error during filteringcom.netflix.zuul.exception.ZuulException: Forwarding error at org.springframework.cloud..._com.netflix.zuul.exception.zuulexception
邻接矩阵-建立图-程序员宅基地
文章浏览阅读358次。1.介绍图的相关概念 图是由顶点的有穷非空集和一个描述顶点之间关系-边(或者弧)的集合组成。通常,图中的数据元素被称为顶点,顶点间的关系用边表示,图通常用字母G表示,图的顶点通常用字母V表示,所以图可以定义为: G=(V,E)其中,V(G)是图中顶点的有穷非空集合,E(G)是V(G)中顶点的边的有穷集合1.1 无向图:图中任意两个顶点构成的边是没有方向的1.2 有向图:图中..._给定一个邻接矩阵未必能够造出一个图
随便推点
MDT2012部署系列之11 WDS安装与配置-程序员宅基地
文章浏览阅读321次。(十二)、WDS服务器安装通过前面的测试我们会发现,每次安装的时候需要加域光盘映像,这是一个比较麻烦的事情,试想一个上万个的公司,你天天带着一个光盘与光驱去给别人装系统,这将是一个多么痛苦的事情啊,有什么方法可以解决这个问题了?答案是肯定的,下面我们就来简单说一下。WDS服务器,它是Windows自带的一个免费的基于系统本身角色的一个功能,它主要提供一种简单、安全的通过网络快速、远程将Window..._doc server2012上通过wds+mdt无人值守部署win11系统.doc
python--xlrd/xlwt/xlutils_xlutils模块可以读xlsx吗-程序员宅基地
文章浏览阅读219次。python–xlrd/xlwt/xlutilsxlrd只能读取,不能改,支持 xlsx和xls 格式xlwt只能改,不能读xlwt只能保存为.xls格式xlutils能将xlrd.Book转为xlwt.Workbook,从而得以在现有xls的基础上修改数据,并创建一个新的xls,实现修改xlrd打开文件import xlrdexcel=xlrd.open_workbook('E:/test.xlsx') 返回值为xlrd.book.Book对象,不能修改获取sheett_xlutils模块可以读xlsx吗
关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题_unresolved attribute reference 'find_element_by_id-程序员宅基地
文章浏览阅读8.2w次,点赞267次,收藏656次。运行Selenium出现'WebDriver' object has no attribute 'find_element_by_id'或AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'等定位元素代码错误,是因为selenium更新到了新的版本,以前的一些语法经过改动。..............._unresolved attribute reference 'find_element_by_id' for class 'webdriver
DOM对象转换成jQuery对象转换与子页面获取父页面DOM对象-程序员宅基地
文章浏览阅读198次。一:模态窗口//父页面JSwindow.showModalDialog(ifrmehref, window, 'dialogWidth:550px;dialogHeight:150px;help:no;resizable:no;status:no');//子页面获取父页面DOM对象//window.showModalDialog的DOM对象var v=parentWin..._jquery获取父window下的dom对象
什么是算法?-程序员宅基地
文章浏览阅读1.7w次,点赞15次,收藏129次。算法(algorithm)是解决一系列问题的清晰指令,也就是,能对一定规范的输入,在有限的时间内获得所要求的输出。 简单来说,算法就是解决一个问题的具体方法和步骤。算法是程序的灵 魂。二、算法的特征1.可行性 算法中执行的任何计算步骤都可以分解为基本可执行的操作步,即每个计算步都可以在有限时间里完成(也称之为有效性) 算法的每一步都要有确切的意义,不能有二义性。例如“增加x的值”,并没有说增加多少,计算机就无法执行明确的运算。 _算法
【网络安全】网络安全的标准和规范_网络安全标准规范-程序员宅基地
文章浏览阅读1.5k次,点赞18次,收藏26次。网络安全的标准和规范是网络安全领域的重要组成部分。它们为网络安全提供了技术依据,规定了网络安全的技术要求和操作方式,帮助我们构建安全的网络环境。下面,我们将详细介绍一些主要的网络安全标准和规范,以及它们在实际操作中的应用。_网络安全标准规范