深度学习笔记——pytorch实现双向GRU(BiGRU)-程序员宅基地
技术标签: 笔记 机器学习 深度学习 pytorch 人工智能 gru 深度学习入门—pytorch深度学习实践
系列文章目录
机器学习笔记——梯度下降、反向传播
机器学习笔记——用pytorch实现线性回归
机器学习笔记——pytorch实现逻辑斯蒂回归Logistic regression
机器学习笔记——多层线性(回归)模型 Multilevel (Linear Regression) Model
深度学习笔记——pytorch构造数据集 Dataset and Dataloader
深度学习笔记——pytorch解决多分类问题 Multi-Class Classification
深度学习笔记——pytorch实现卷积神经网络CNN
深度学习笔记——卷积神经网络CNN进阶
深度学习笔记——循环神经网络 RNN
深度学习笔记——pytorch实现双向GRU
前言
参考视频——B站刘二大人《pytorch深度学习实践》
一、压缩填充张量 Pack_padded_sequence
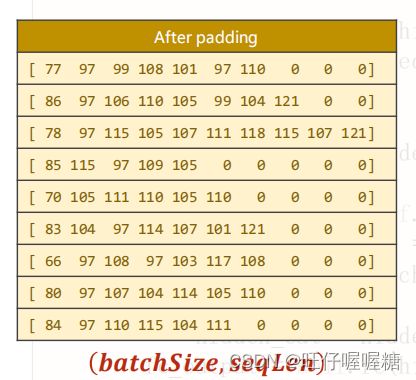
在交给模型处理数据之前,我们需要将数据做成矩阵。
由于每条序列的长短不一,我们将一个batch_size的序列做成矩阵时,需要选取最长的序列作为矩阵的宽,在其他序列填充0,形成矩阵。
但我们在计算时这些0就是无用的数据,浪费计算资源
因此提出了压缩填充张量 Pack_padded_sequence
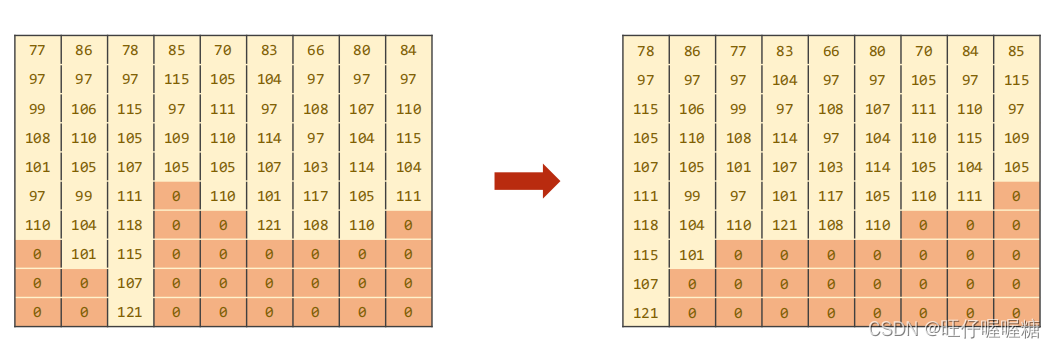
将矩阵转置后,并按序列长度排序
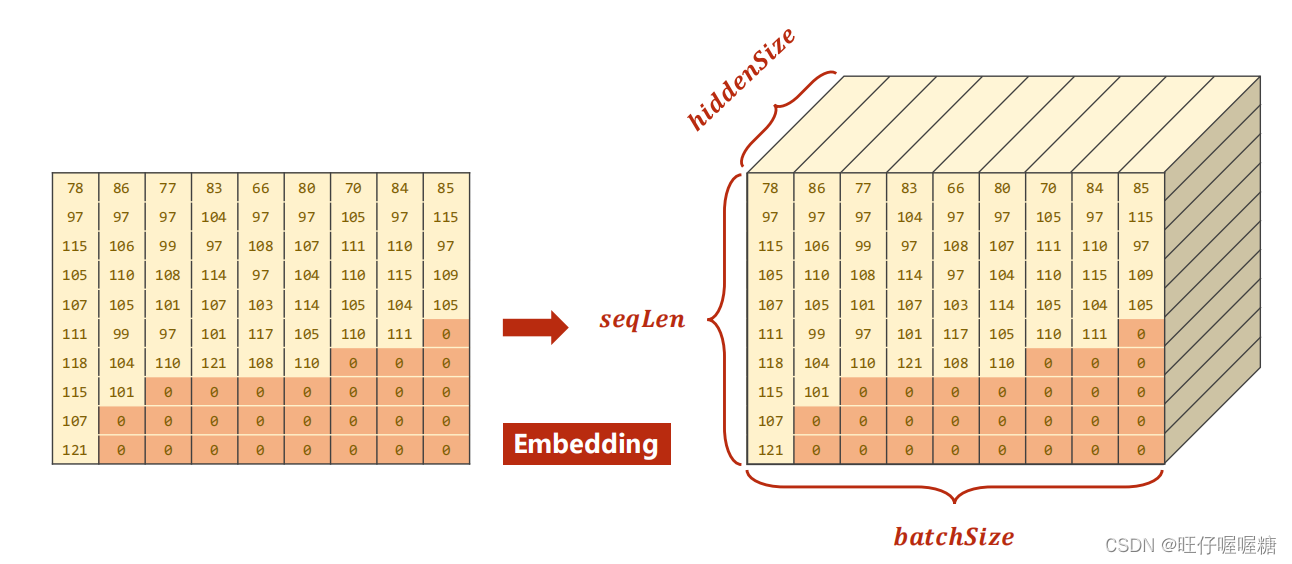
经过embedding层处理
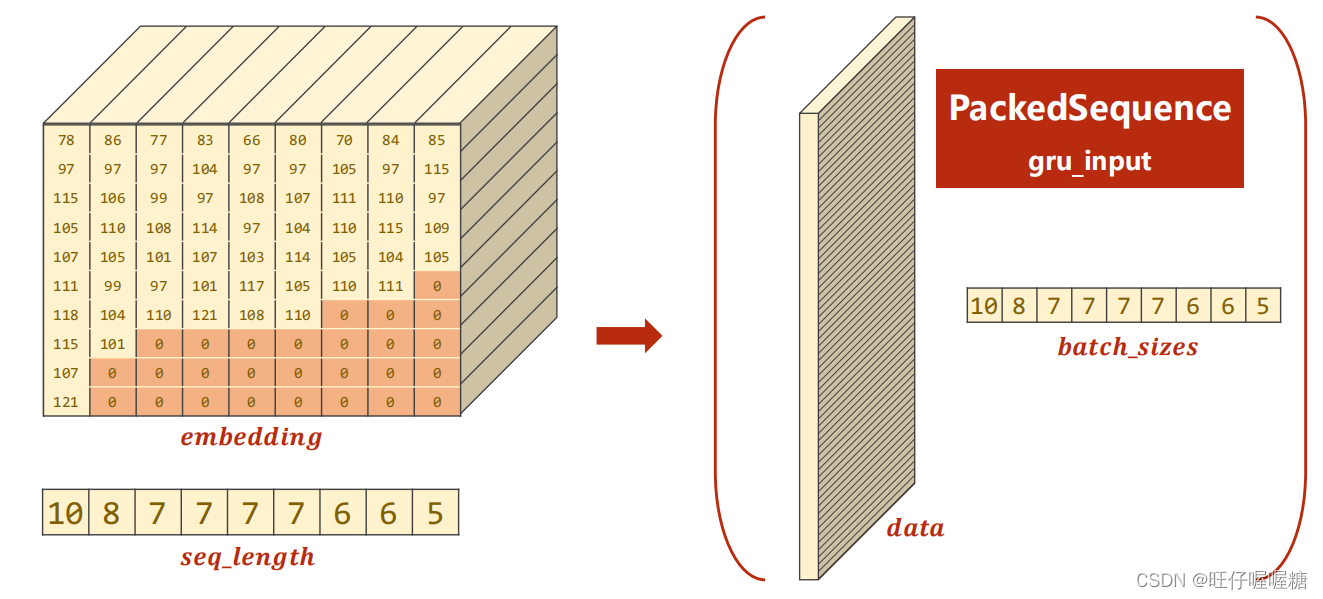
记录有效数据,在计算时只计算有效数据
二、代码
代码如下(示例):
#!/user/bin/env python3
# -*- coding: utf-8 -*-
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import pandas as pd
import time
import matplotlib.pyplot as plt
import math
BATCH_SIZE = 256 # batch size
HIDDEN_SIZE = 100 # 隐层维度
N_LAYER = 2 # RNN层数
N_EPOCHS = 100 # 训练轮数
N_CHARS = 128 # 字符
USE_GPU = True # 是否使用gpu
# prepare data
class NameDataset(Dataset):
def __init__(self, is_train_set=True):
filename = 'data/names_train.csv' if is_train_set else 'data/names_test.csv'
data = pd.read_csv(filename, delimiter=',', names=['names', 'country'])
self.names = data['names']
self.len = len(self.names)
self.countries = data['country']
self.countries_list = list(sorted(set(self.countries)))
self.countries_dict = self.getCountryDict()
self.countries_num = len(self.countries_list)
def __getitem__(self, item):
return self.names[item], self.countries_dict[self.countries[item]]
def __len__(self):
return self.len
def getCountryDict(self):
country_dict = {
}
for idx, country in enumerate(self.countries_list, 0):
country_dict[country] = idx
return country_dict
def id2country(self, idx):
return self.countries[idx]
def getCountryNum(self):
return self.countries_num
# 训练集
train_data = NameDataset(is_train_set=True)
trainloader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)
# 测试集
test_data = NameDataset(is_train_set=False)
testloader = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=False)
N_COUNTRY = train_data.getCountryNum() # 国家的数量
# 模型
class RNNClassifier(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layer=1, bidirectional=True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layer = n_layer
self.n_directions = 2 if bidirectional else 1
self.emb = torch.nn.Embedding(input_size, hidden_size)
self.gru = torch.nn.GRU(hidden_size, hidden_size, num_layers=n_layer,
bidirectional=bidirectional)
self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size)
def forward(self, inputs, seq_lengths):
inputs = create_tensor(inputs.t())
batch_size = inputs.size(1)
hidden = self._init_hidden(batch_size)
embedding = self.emb(inputs)
gru_input = torch.nn.utils.rnn.pack_padded_sequence(embedding, seq_lengths) # 用于提速
output, hidden = self.gru(gru_input, hidden)
if self.n_directions == 2:
# 如果是双向神经网络,则有两个hidden,需要将它们拼接起来
hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1)
else:
hidden_cat = hidden[-1]
fc_output = self.fc(hidden_cat)
return fc_output
def _init_hidden(self, batch_size):
hidden = torch.zeros(self.n_layer * self.n_directions, batch_size, self.hidden_size)
return create_tensor(hidden)
def create_tensor(tensor):
if USE_GPU:
device = torch.device('cuda')
tensor = tensor.to(device)
return tensor
def make_tensors(names, countries):
sequences_and_lengths = [name2list(name) for name in names] # 得到name所有字符的ASCII码值和name的长度
name_sequences = [sl[0] for sl in sequences_and_lengths] # 获取name中所有字符的ASCII码值
seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths]) # 获取所有name的长度
# 获得所有name的tensor,形状 batch_size*max(seq_len) 即name的个数*最长的name的长度
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long() # 形状[name的个数*最长的name的长度]
for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq) # 将所有name逐行填充到seq_tensor中
# sort by length to use pack_padded_sequence
seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True) # 将seq_lengths按降序排列,perm_idx是排序后的序号
seq_tensor = seq_tensor[perm_idx] # seq_tensor中的顺序也随之改变
countries = countries[perm_idx] # countries中的顺序也随之改变
# 返回所有names转为ASCII码的tensor,所有names的长度的tensor,所有country的tensor
return create_tensor(seq_tensor), \
create_tensor(seq_lengths), \
create_tensor(countries)
def name2list(name):
arr = [ord(c) for c in name] # 将string转为list且所有字符转为ASCII码值
return arr, len(arr) # 返回的是tuple([arr],len(arr))
def modelTrain():
total_loss = 0.0
for i, (names, countries) in enumerate(trainloader, 1):
inputs, seq_lengths, targets = make_tensors(names, countries)
output = Net(inputs, seq_lengths.to('cpu'))
loss = criterion(output, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if i % 10 == 0: # 每十个批次输出一次
print(f'[{
time_since(start_time)}] Epoch {
epoch}', end='')
print(f'[{
i * len(inputs)}/{
len(train_data)}]', end='')
print(f'loss={
total_loss / i * len(inputs)}')
return total_loss # 返回一轮训练的所有loss之和
def modelTest():
correct = 0
total = len(test_data)
print('evaluating trained model...')
with torch.no_grad():
for i, (names, countries) in enumerate(testloader, 1):
inputs, seq_lengths, targets = make_tensors(names, countries)
output = Net(inputs, seq_lengths.to('cpu'))
pred = output.max(dim=1, keepdim=True)[1]
correct += pred.eq(targets.view_as(pred)).sum().item()
percent = '%.2f' % (100 * correct / total)
print(f'Test set:Accuracy{
correct}/{
total} {
percent}%')
return correct / total
def time_since(since):
s = time.time() - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
if __name__ == '__main__':
Net = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER, bidirectional=True)
if USE_GPU:
device = torch.device('cuda:0')
Net.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(Net.parameters(), lr=0.001)
start_time = time.time()
print('Training for %d epochs...' % N_EPOCHS)
acc_list = []
epoch_list=[]
for epoch in range(1, N_EPOCHS + 1):
modelTrain()
acc = modelTest()
acc_list.append(acc)
epoch_list.append(epoch)
plt.plot(epoch_list, acc_list)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.grid()
plt.show()
运行结果
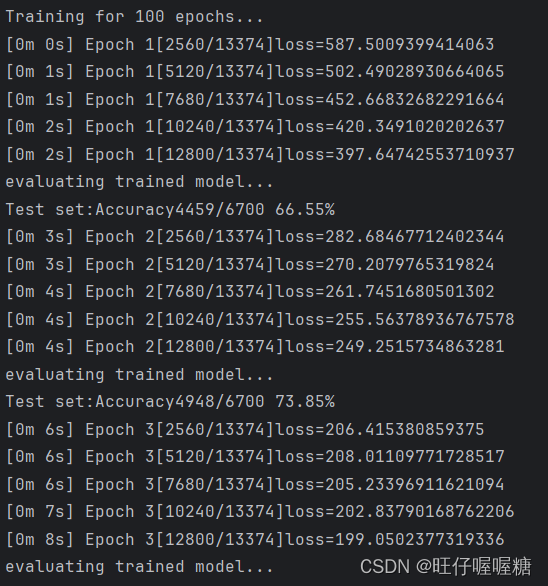
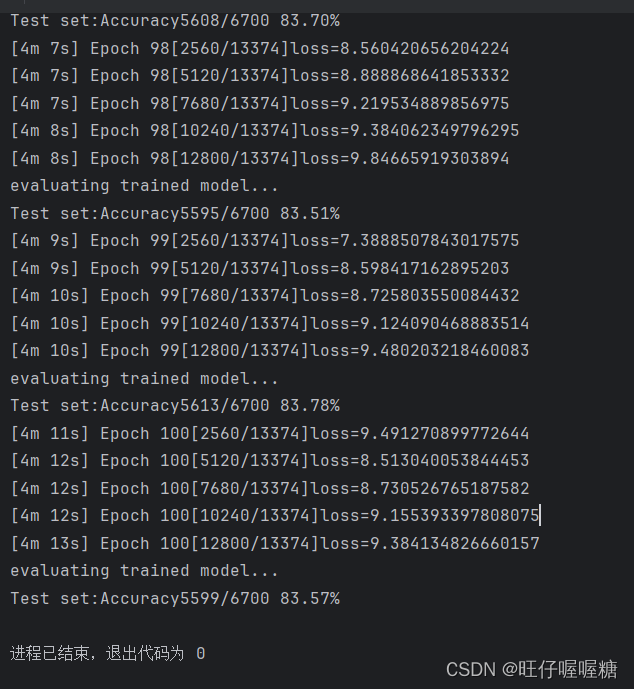
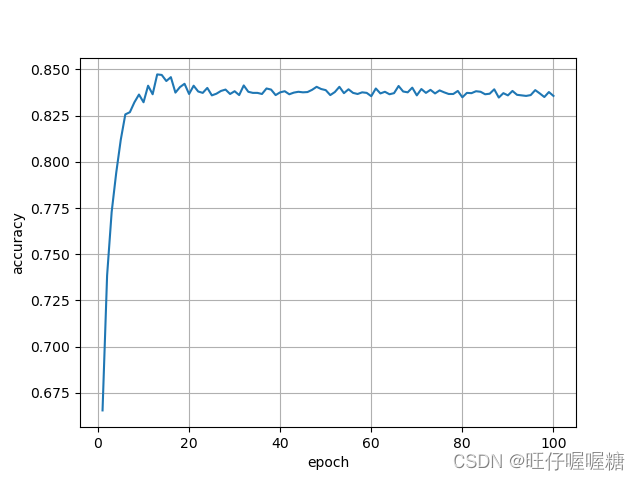
智能推荐
第一章-第七题( 有人认为,“中文编程”, 是解决中国程序员编程效率一个秘密武器,请问它是一个 “银弹” 么? )--By 侯伟婷...-程序员宅基地
文章浏览阅读208次。 首先,“银弹”在百度百科中的解释是银色的子弹,我们更熟知的“银弹”一词,应该是在《人月神话》中提到的。银弹原本应该是指某种策略、技术或者技巧可以极大地提高程序员的生产力【1】。此题目中关于中文编程是否是一个“银弹”的讨论,我所持的是否定的态度,我不认为中文编程会是一项提高中国程序员编程效率的一个秘密武器,相反,我还认为他会比现在的英文编程来说降低工作效率,造成很大的工作上的困难。..._存在一种策略,技术技巧可以极大的提高程序员的生产力。
模拟用户操作 京东抢购 华为mate40 Pro、支付的js脚本_京东抢华为脚本-程序员宅基地
文章浏览阅读5.4k次,点赞2次,收藏29次。1 登录 https://item.jd.com/10024680695127.html2 打开开发者模式,插入如下代码,count=1nIntervId=0 stop=0 var goDate function start(){ if (stop==1){ clearInterval(nIntervId);//停止监控 return } if (Date.now() < goDate){ return _京东抢华为脚本
php eayswoole node axios crypto-js 实现大文件分片上传复盘_cryptojs 处理文件过大-程序员宅基地
文章浏览阅读740次。1)前端侧 :前端上传文件,根据分片大小,自动计算出整个文件的分片数量,以及分片二进制文件,以及整个文件的md5值,以及分片文件md5值,传与后端,后端处理完后,根据上传分片的进度以及后端返回状态,判断整个文件是否传输完毕,完毕后,前端展示完成进度。2)后端PHP侧:后端接收前端传过来的数据,包括文件名,文件md5,分片信息,然后将分片文件信息存储到redis 有序集合中,其中key为整个文件的md5 ,待所有分片文件都上传完后,根据顺序,然后将文件整合存储,然后完成整个文件分片上传逻辑。_cryptojs 处理文件过大
VScode 编译器配置IDE环境(C/C++/Go)_vscode 配置 在ide上编译运行-程序员宅基地
文章浏览阅读4.5k次,点赞4次,收藏29次。VScode 编译器配置IDE环境(C/C++/Go)摘要VS Code 下载安装下载安装简单使用WindowsLinuxIDE 环境配置C/C++C/C++ 编译器安装及配置简单使用 VS Code 终端进行编译和运行方式使用code runner插件:Go总结摘要对于 VS Code 的使用,我本人感觉这个编译器还是很好用的,而且目前能够支持在 Windows、Linux、MacOs 上流畅运行,并且官方已经提供了 X86、ARM等主流架构版本,还很容易通过安装插件就能过实现基于 SSH 的远程代_vscode 配置 在ide上编译运行
oracle use_ntl详细解释_oracle中use_nl提示-程序员宅基地
文章浏览阅读1k次。1./*+ use_nl(t2,t) */提示走nest Loop,但是没有提示t2还是t为驱动表2./*+ ordered user_nl(t2,t) */提示走 Nest Loop,order提示的是from 后面的第一个表为驱动表.3./*+ leading(t2) use_nl(t) */直接提示t2为驱动表。结论:use_NL不能让优化器确定谁是驱动表谁是被驱动表。use_nl(t,t2)也没有指出哪个是驱动表,这时候我们就需要使用Ordered ,_oracle中use_nl提示
windows下python2.7 media模块的安装_python下载media模块-程序员宅基地
文章浏览阅读1.2k次。总共就是需要以上这些安装包(这里面python-2.7.4.msi是python的安装包)关于pygraphics的模块可以到http://code.google.com/p/pygraphics/downloads/list下载,下载时要看好针对的操作系统和python的版本号。找不到的就百度吧,最好是到官网上下载。安装步骤:下载:Python Ima_python下载media模块
随便推点
5、Nacos 、Sentinel、Seata下载与安装_sentinel下载安装-程序员宅基地
文章浏览阅读1.8k次,点赞2次,收藏10次。1、官网:https://nacos.io/zh-cn/index.html2、 下载3、解压安装双击startup.cmdjava.io.IOException: java.lang.IllegalArgumentException: db.num is null如果出现以上错误,需要指令启动:单机模式启动 window版本 startup.cmd -m standalone4、访问登录http://localhost:8848/nacos/index.html#/._sentinel下载安装
linux ssh远程登录退出,ssh登陆小技巧-用SSH 退出符切换 SSH 会话-程序员宅基地
文章浏览阅读1.7k次。用SSH 退出符切换 SSH 会话这个技巧非常实用。尤其是远程登陆到一台主机A,然后从A 登陆到B,如果希望在A 上做一些操作,还得再开一个终端,很是麻烦。当你使用ssh从本机登录到远程主机时,你可能希望切换到本地做一些操作,然后再重新回到远程主机。这个时候,你不需要中断 ssh连接,只需要按照如下步骤操作即可:当你已经登录到了远程主机时,你可能想要回到本地主机进行一些操作,然后又继续回到远程主机..._linux中ssh远程登录后如何回到原来主机
[渝粤教育] 四川农业大学 计算机网络 参考 资料_调制的信号是单一频率的载波信号吗-程序员宅基地
文章浏览阅读796次。教育-计算机网络-章节资料考试资料-四川农业大学【】随堂测验1、【单选题】以下哪一项不属于物联网的实现基础A、可穿戴设备B、RFIDC、APPD、蓝牙参考资料【 】2、【单选题】以下哪一项不是解决网络安全问题的因素A、 安全技术B、法律法规C、道德自律D、多种应用参考资料【 】电路交换随堂测验1、【单选题】以下哪一项不是电路交换的特征A、按需建立点对点信道B、数据无需携带地址信息C、点对点信道独占经过的物理链路带宽D、两两终端之间可以同时通信参考资料_调制的信号是单一频率的载波信号吗
吃透这几道MQ消息队列面试题,秒杀面试官..._mq面试题吊打面试官-程序员宅基地
文章浏览阅读450次。几种常见的MQ面试题相关视频参考(来自动力节点):https://www.bilibili.com/video/BV1Ap4y1D7tU相关资料下载:http://www.bjpowernode.com/?csdn为什么使用消息队列?其实就是问问你消息队列都有哪些使用场景,然后你项目里具体是什么场景,说说你在这个场景里用消息队列是什么?面试官问你这个问题,期望的一个回答是说,你们公司有个什么业务场景,这个业务场景有个什么技术挑战,如果不用 MQ 可能会很麻烦,但是你现在用了 MQ 之后带_mq面试题吊打面试官
《UnityAPI.Screen屏幕》(Yanlz+Unity+SteamVR+云技术+5G+AI+VR云游戏+Unity+Screen+dpi+SetResolution+立钻哥哥++OK++)_unity刷新屏幕的api-程序员宅基地
文章浏览阅读1.5k次。《UnityAPI.Screen屏幕》 Screen屏幕 版本 作者 参与者 完成日期 备注 UnityAPI_Screen_V01_1.0 严立钻 2020.09.16 ..._unity刷新屏幕的api
流媒体服务器SRS的搭建及QT下RTMP推流客户端的编写_开源srs流媒体服务器-程序员宅基地
文章浏览阅读2.4k次。本客户端基于我的博客:https://blog.csdn.net/linyibin_123/article/details/132107948 开发的播放器下新增RTMP推流。播放器可以支持软硬解码,截图、录像等功能,详细功能看该博客。本客户端支持读取文件解码后推流,也支持拉取网络流解码后进行推流。推流地址为前面搭建的RTMP流媒体服务器,推流成功后,通过VLC播放器从RTMP服务器上拉流下来播放。_开源srs流媒体服务器