flume+kafka+hive收集用户行为数据_flume kafka hive-程序员宅基地
技术标签: hive Hive Hadoop kafka flume Flume big data
目录
需求背景
项目中需要将用户的行为数据或者其他数据放入大数据仓库,已有kafka服务。
解决方案
我们可以通过flume获取kafka实时数据并转存储到hdfs。
转存到hdfs后,再通过load data命令加载到Hive表中,hive再处理用户行为数据,最终输出到mysql呈现到用户端。
具体步骤
一. 安装部署Hadoop并启动Hadoop
具体步骤见:
Windows10 安装Hadoop3.3.0_xieedeni的博客-程序员宅基地
Windows10安装Hive3.1.2_xieedeni的博客-程序员宅基地
说明:这里的版本本人安装的是Hadoop3.3.0,Hive3.1.2,kafka是腾讯云,Flume这里建议安装flume1.9
二. Windows下安装Flume
1.下载flume1.9
flume官方下载地址是http://www.apache.org/dyn/closer.lua/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
这个地址下载速度慢的话,可以使用镜像资源地址:https://download.csdn.net/download/xieedeni/24882711
2.解压apache-flume-1.9.0-bin
3.配置flume环境变量


三. flume配置文件
1.创建flume连接kafka到hive配置文件%FLUME%/conf/kafka2hive.conf
# in this case called 'agent'
agent.sources = kafka_source
agent.channels = mem_channel
agent.sinks = hive_sink
# 以下配置 source
agent.sources.kafka_source.type = org.apache.flume.source.kafka.KafkaSource
agent.sources.kafka_source.channels = mem_channel
agent.sources.kafka_source.batchSize = 5000
agent.sources.kafka_source.kafka.bootstrap.servers = ckafka-1:6003
agent.sources.kafka_source.kafka.topics = flume-collect
#agent.sources.kafka_source.kafka.topics = bi-collect
agent.sources.kafka_source.kafka.consumer.group.id = group-1
# kafka访问协议
agent.sources.kafka_source.kafka.consumer.security.protocol = SASL_PLAINTEXT
agent.sources.kafka_source.kafka.consumer.sasl.mechanism = PLAIN
agent.sources.kafka_source.kafka.consumer.sasl.kerberos.service.name = kafka
# Hive Sink
agent.sinks.hive_sink.type = hive
agent.sinks.hive_sink.channel = mem_channel
agent.sinks.hive_sink.hive.metastore = thrift://localhost:9083
agent.sinks.hive_sink.hive.database = dd_database_bigdata
agent.sinks.hive_sink.hive.table = dwd_base_event_log_b
#采集的数据放在哪个分区下
agent.sinks.hive_sink.hive.partition = %Y-%m-%d
agent.sinks.hive_sink.hive.txnsPerBatchAsk = 2
#分批入库
agent.sinks.hive_sink.batchSize = 10
#序列化
#agent.sinks.hive_sink.serializer = DELIMITED
agent.sinks.hive_sink.serializer = JSON
#分隔符默认是 ,
agent.sinks.hive_sink.serializer.delimiter = "\t"
agent.sinks.hive_sink.serializer.serdeSeparator = '\t'
agent.sinks.hive_sink.serializer.fieldnames = biz_id,biz_type,behavior_type,behavior_value,user_id,longitude,latitude,ip,request_ip,app_version,app_id,device_id,device_type,network,mobile_type,os,session_id,trace_id,parent_trace_id,page_id,current_time_millis,sign,timestamp,token
# 以下配置 channel
agent.channels.mem_channel.type = memory
agent.channels.mem_channel.capacity = 100000
agent.channels.mem_channel.transactionCapacity = 10000
参数说明:
a.好好研究下官方文档,不然过程中真的会遇到很多坑Flume 1.9.0 User Guide — Apache Flume
b.kafka协议,真是坑,网上一堆资料唯独这个介绍的不够全
# kafka访问协议
agent.sources.kafka_source.kafka.consumer.security.protocol = SASL_PLAINTEXT
agent.sources.kafka_source.kafka.consumer.sasl.mechanism = PLAIN
agent.sources.kafka_source.kafka.consumer.sasl.kerberos.service.name = kafka大家看到这里的kafka协议使用的是SASL_PLAINTEXT,如果需要其他方式请参看官方文档啊。
2.既然使用了protocol协议为SASL_PLAINTEXT,则需要如下设置
a.复制%FLUME%/conf/flume-env.sh.template命名为flume-env.sh还放到这个文件夹,内容为:
export JAVA_HOME=D:\work\jdk1.8.0_291b.复制%FLUME%/conf/flume-env.ps1.template命名为flume-env.ps1还放到这个文件夹,内容为:
$JAVA_OPTS="-Djava.security.auth.login.config=D:\work\soft\apache-flume-1.9.0-bin\conf\kafka_client_jaas.conf"
$FLUME_CLASSPATH="D:\work\soft\apache-flume-1.9.0-bin\lib"这里涉及到一个关键的文件kafka_client_jaas.conf,是用于kafka公网接入方式的protocol协议为SASL_PLAINTEXT
c.创建%FLUME%/conf/kafka_client_jaas.conf文件,还是放在conf下,内容为:
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="ckafka-123#kafka"
password="123";
};这里的username为“实例id#用户名”
四. Hive配置文件及启动
1.修改%HIVE_HOME%/conf/hive-site.xml文件,注意是开启事务等
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://xxx:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://127.0.0.1:3306/hive?serverTimezone=UTC&useSSL=false&allowPublicKeyRetrieval=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/xxx/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.exec.parallel</name>
<value>true</value>
<description>Whether to execute jobs in parallel</description>
</property>
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
</property>2.使用hive创建表
USE dd_database_bigdata;
DROP TABLE IF EXISTS dwd_base_event_log_b;
CREATE TABLE dwd_base_event_log_b
(
`biz_id` STRING COMMENT '业务id',
`biz_type` STRING COMMENT '内容类型',
`behavior_type` STRING COMMENT '行为类型',
`behavior_value` STRING COMMENT '行为结果,扩展字段',
`user_id` STRING COMMENT '用户id,不登录为0',
`longitude` STRING COMMENT '位置经度',
`latitude` STRING COMMENT '用户纬度',
`ip` STRING COMMENT 'ip地址',
`request_ip` STRING,
`app_version` STRING COMMENT 'app版本',
`app_id` STRING COMMENT '上报来源,appid',
`device_id` STRING COMMENT '设备id',
`device_type` STRING COMMENT '设备类型,安卓,ios,小程序,pc,未知',
`network` STRING COMMENT '网络类型,wifi,数据网络',
`mobile_type` STRING COMMENT '手机型号,iphoneX,小米11.....',
`os` STRING COMMENT '终端操作系统,操作系统,版本信息',
`session_id` STRING COMMENT '用户一次访问的标识ID',
`trace_id` STRING COMMENT '行为唯一标识',
`parent_trace_id` STRING COMMENT '父行为标识',
`page_id` STRING COMMENT '页面标识',
`current_time_millis` STRING COMMENT '时间',
`sign` STRING COMMENT '签名',
`timestamp` STRING COMMENT '日期',
`token` STRING COMMENT '请求token'
)
COMMENT '行为事件日志基础明细表buckets'
PARTITIONED BY (`dt` STRING)
stored as orc
LOCATION '/warehouse/dd/bigdata/dwd/dwd_base_event_log_b/'
tblproperties('transactional'='true');3.启动hive
cd %HIVE_HOME%/bin
hive --service metastore &五. Kafka数据消息的格式
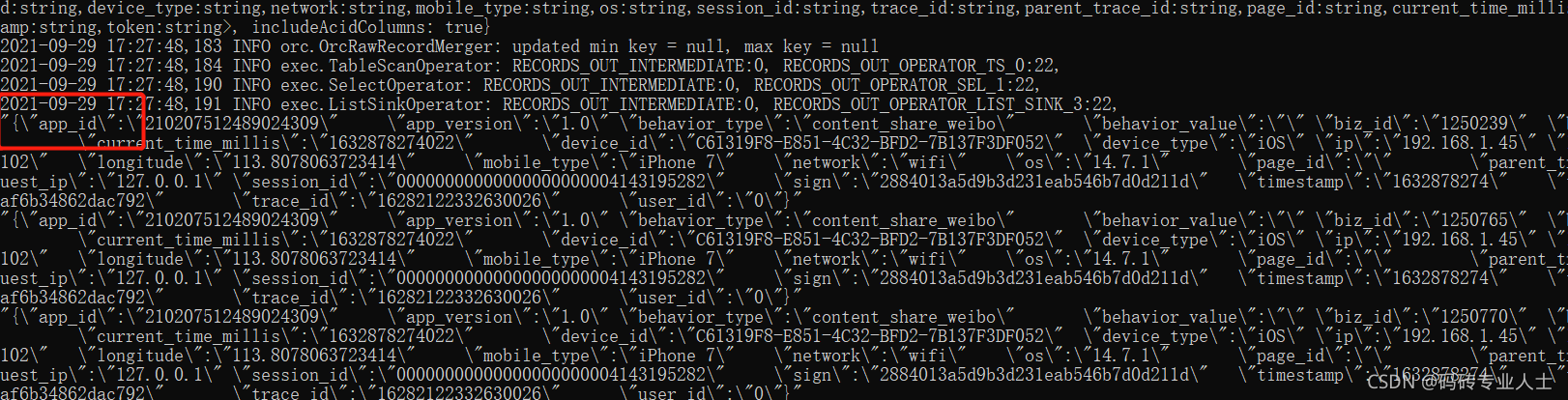
注意不用发一个json转成String后的数据,不然,存储到hive后是错误的数据结构
{"id":"16","biz_id":"9","biz_type":"article","behavior_type":"content_share_weixin","behavior_value":"","user_id":"0","longitude":"113.8078063723414","latitude":"34.79383784587102","ip":"192.168.1.45","request_ip":"","app_version":"1.0","app_id":"210207512489024309","device_id":"C61319F8-E851-4C32-BFD2-7B137F3DF052","device_type":"iOS","network":"wifi","mobile_type":"iPhone 7","os":"14.7.1","session_id":"00000000000000000000004143195282","trace_id":"16282122332630026","parent_trace_id":"","page_id":"","create_time":"6/8/2021 09:10:35"}
{"id":"17","biz_id":"9","biz_type":"article","behavior_type":"content_share_weixin","behavior_value":"","user_id":"0","longitude":"113.8078063723414","latitude":"34.79383784587102","ip":"172.20.10.2","request_ip":"","app_version":"1.0","app_id":"210207512489024309","device_id":"C61319F8-E851-4C32-BFD2-7B137F3DF052","device_type":"iOS","network":"wifi","mobile_type":"iPhone 7","os":"14.7.1","session_id":"00000000000000000000003311508828","trace_id":"16282123402150022","parent_trace_id":"","page_id":"","create_time":"6/8/2021 09:12:21"}错误示例,数据在引号内”“,是不对的
六. 启动flume
启动的前提是:kafka服务已启动,topic已创建;hadoop服务已启动并创建了database,hadoop文件需要开发权限。
启动命令:
cd %FLUME_HOME%/bin
flume-ng agent -c %FLUME_HOME%/conf -n agent -f %FLUME_HOME%/conf/kafka2hive.conf &参数 作用 举例
–conf 或 -c 指定配置文件夹,包含flume-env.sh和log4j的配置文件 –conf conf
–conf-file 或 -f 配置文件地址 –conf-file conf/flume.conf
–name 或 -n agent名称 –name a1
启动成功:
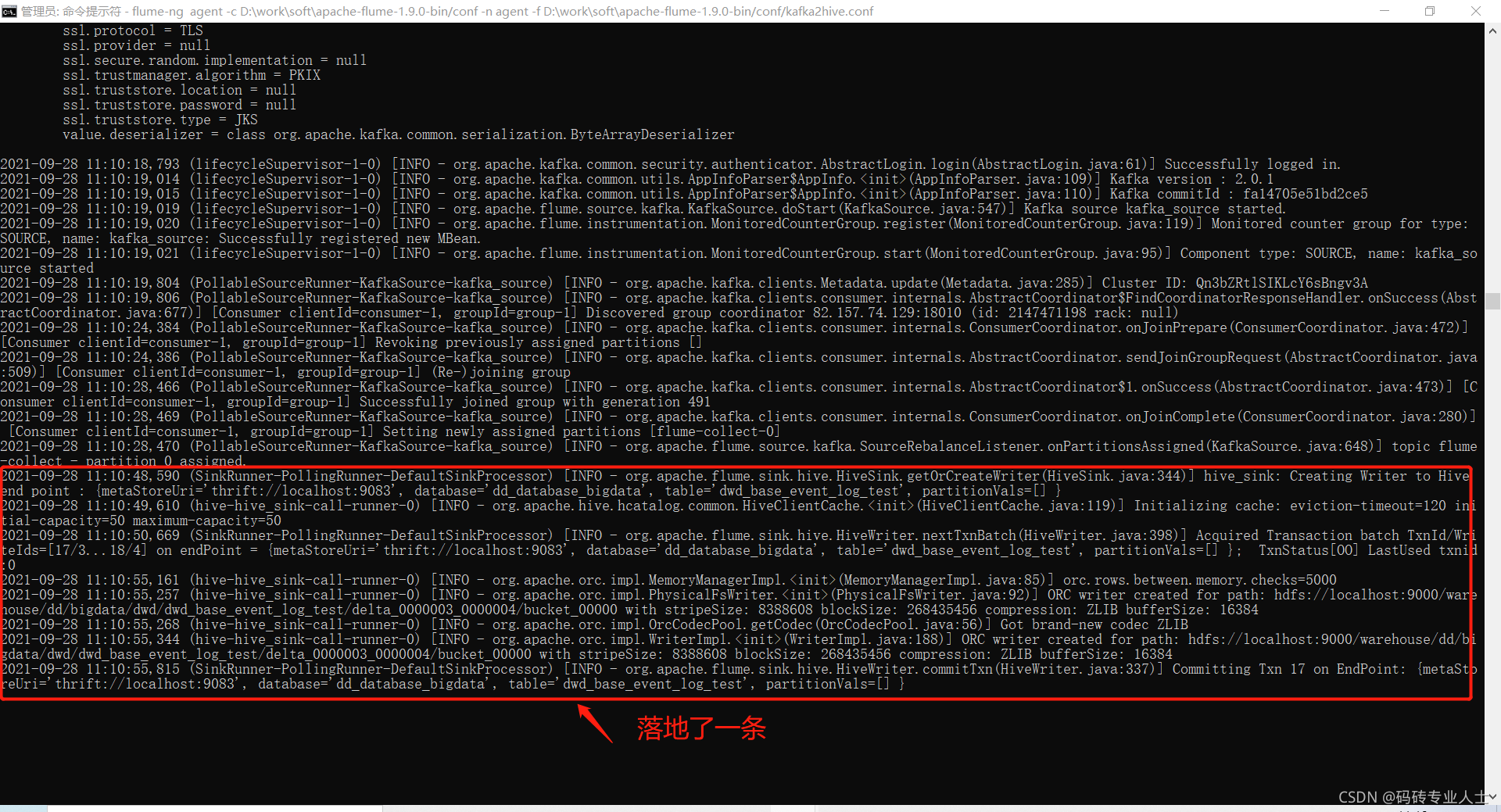
如果没有具体的日志信息,请修改%FLUME%/conf/log4j.properties

七. 测试
kafka生成一条消息,flume消费落地到hive
select * from dwd_base_event_log_test;
小结
本人新手,比较笨,为了实现这个功能,研究花费近3天时间,中间遇到了很多坑。通过查阅资料,网上的资料都不够完整,这种东西就是难者不会会者不难。真的达到了目的,反而觉得出现的问题真是不难,但过程中却是处处碰壁。所以记录下遇到的问题,以供以后查阅,也分享给需要的小伙伴们。别放弃,阳光总在风雨后。
踩到的坑
1.启动flume后,就运行到(lifecycleSupervisor-1-0) [INFO - org.apache.kafka.common.utils.AppInfoParser$AppInfo.<init>(AppInfoParser.java:110)] Kafka commitId : xxxxxx
后面没有再输出内容,也没有提示是否连接到了kafka的topic。如下图:
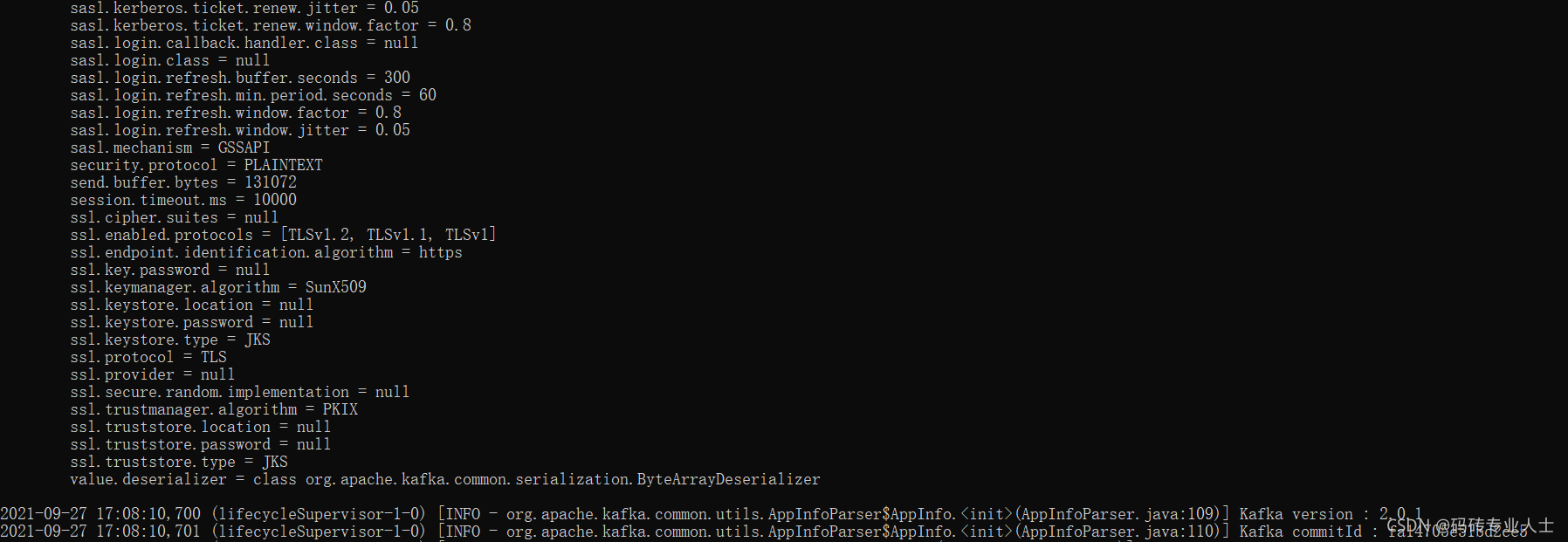
图中没有任何报错信息,kafka生产消息后flume也接收不到,没有任何响应。
原因:检查kafka是否开启了安全策略,如果开启,需要设置protocol
# kafka访问协议
agent.sources.kafka_source.kafka.consumer.security.protocol = SASL_PLAINTEXT
agent.sources.kafka_source.kafka.consumer.sasl.mechanism = PLAIN
agent.sources.kafka_source.kafka.consumer.sasl.kerberos.service.name = kafka方法见步骤三。
这里是个新手坑,如果遗漏设置的话,flume就连接不到kafka。
2.配置文件无误且连接到了kafka,flume接收消息后落地到hive报错
org.apache.hive.hcatalog.streaming.InvalidTable:
Invalid table db:dd_database_bigdata, table:dwd_base_event_log_test: is not an Acid table原因:hive表创建的有问题,创建时需要添加属性:tblproperties('transactional'='true')

3.接收到kafka消息后,转存到hive报错,如下图:

可以看到明显的错误原因:org.apache.flume.EventDeliveryException: java.lang.ArrayIndexOutOfBoundsException: 6
原因:这是数据格式不完成
{"id":"16","biz_id":"9","biz_type":"article","behavior_type":"content_share_weixin","behavior_value":"","user_id":"0","longitude":"113.8078063723414","latitude":"34.79383784587102","ip":"192.168.1.45","request_ip":"","app_version":"1.0","app_id":"210207512489024309","device_id":"C61319F8-E851-4C32-BFD2-7B137F3DF052","device_type":"iOS","network":"wifi","mobile_type":"iPhone 7","os":"14.7.1","session_id":"00000000000000000000004143195282","trace_id":"16282122332630026","parent_trace_id":"","page_id":"","create_time":"6/8/2021 09:10:35"}
{"id":"17","biz_id":"9","biz_type":"article","behavior_type":"content_share_weixin","behavior_value":"","user_id":"0","longitude":"113.8078063723414","latitude":"34.79383784587102","ip":"172.20.10.2","request_ip":"","app_version":"1.0","app_id":"210207512489024309","device_id":"C61319F8-E851-4C32-BFD2-7B137F3DF052","device_type":"iOS","network":"wifi","mobile_type":"iPhone 7","os":"14.7.1","session_id":"00000000000000000000003311508828","trace_id":"16282123402150022","parent_trace_id":"","page_id":"","create_time":"6/8/2021 09:12:21"}表字段必须都传入,消息体不能缺少这些字段,比如{"id":"16","biz_id":"9"},会报这个错误
4. hive和flume如果不在同一服务器上获取读取不到%HIVE_HOME%时,可能需要这样
将%HIVE_HOME%/hcatalog/share/hcatalog下的包复制到%FLUME_HOME%/lib下。
5.要注意的是,hive表结构是不区分大小写的,统一显示为小写。
比如建表语句
CREATE TABLE dwd_base_event_log_ddbi
(
`id` STRING COMMENT '行为类型id',
`bizId` STRING COMMENT '业务id',
`bizType` STRING COMMENT '内容类型'
)
COMMENT '行为事件日志基础明细表test'
clustered by(id) into 2 buckets stored as orc
LOCATION '/warehouse/dd/bigdata/dwd/dwd_base_event_log_ddbi/'
tblproperties('transactional'='true');实际表结构等同于
CREATE TABLE dwd_base_event_log_ddbi
(
`id` STRING COMMENT '行为类型id',
`bizid` STRING COMMENT '业务id',
`biztype` STRING COMMENT '内容类型'
)
COMMENT '行为事件日志基础明细表test'
clustered by(id) into 2 buckets stored as orc
LOCATION '/warehouse/dd/bigdata/dwd/dwd_base_event_log_ddbi/'
tblproperties('transactional'='true');如果kafka消息的数据结构为
{"id":"16","bizId":"9","bizType":"article"}则flume获取kafka消息落地到hive时会报错,报错内容为表dwd_base_event_log_ddbi中没有字段bizId。
flume+kafka+hdfs
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象