python爬虫知识:正则表达式_爬虫正则表达式实验原理-程序员宅基地
技术标签: 爬虫 python search match 正则表达式 findall
概念
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
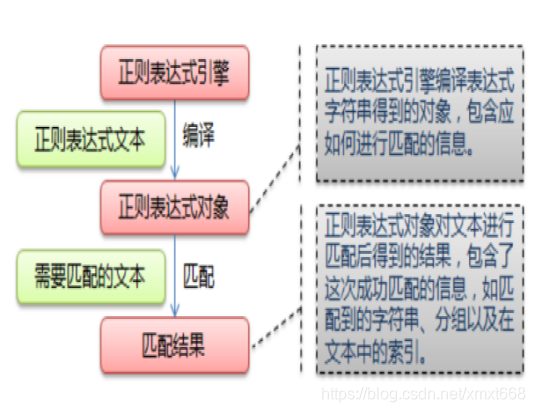
正则表达式的原理:
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。
正则表达式是由普通字符和特殊字符(元字符)组成的文字模式
在 Python 中,我们可以使用内置的 re 模块来使用正则表达式。
有一点需要特别注意的是,正则表达式使用 对特殊字符进行转义,所以如果我们要使用原始字符串,只需加一个 r 前缀,示例:
import re
#因为\a\b是元字符,所以没有打印出来
print("\a\b\c")#\c
#如果我们想打印出原始字符串,则需要在前面加r,防止转义
print(r"\a\b\c")
#对\进行转义,打印出\本身
print("\\")
#这样也可以将原始字符字符串答应出来
print("\\a\\b\c")
re 模块的一般使用步骤如下:
- 使用 compile() 函数将正则表达式的字符串形式编译为一个 Pattern 对象;
- 通过 Pattern 对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象;
- 最后使用 Match 对象提供的属性和方法获得信息,根据需要进行其他的操作。
compile 函数
compile 函数用于编译正则表达式,生成一个 Pattern 对象,它的一般使用形式如下:
在上面,我们已将一个正则表达式编译成 Pattern 对象,接下来,我们就可以利用 pattern 的一系列方法对文本进行匹配查找了。
Pattern 对象的一些常用方法主要有:
match方法:从起始位置开始查找,一次匹配search方法:从任何位置开始查找,一次匹配findall方法:全部匹配,返回列表finditer方法:全部匹配,返回迭代器split方法:分割字符串,返回列表sub方法:替换
下面对这几种发方法进行介绍:
- findall方法
我们需要搜索整个字符串,获得所有匹配的结果,使用的是findall()方法
findall 方法的使用形式如下:
findall(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
import re
#1.创建pattern对象,编译正则表达式
pattern=re.compile("we")
#2.使用findall匹配信息,匹配到所有的we,返回一个列表
result=pattern.findall("we are working how are you i am well thinks and you Welcome")
print(result)
#1.创建pattern对象,编译正则表达式
#\b是元字符,是匹配单词开始和结束
pattern=re.compile(r"\bwe\b")
#2.使用findall匹配信息,匹配到所有的we单词,返回一个列表
result1=pattern.findall("we are working how are you i am well thinks and you Welcome")
print(result1)
常见元字符:
前面提到的元字符\b表示匹配单词的开始和结束。引出其他元字符
| 元字符 | 含义 |
|---|---|
| . | 匹配除换行符以外的任意一个字符 |
| ^ | 匹配行首 |
| $ | 匹配行尾 |
| ? | 重复匹配0次或1次 |
| * | 重复匹配0次或更多次 |
| + | 重复匹配1次或更多次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n~m次 |
| [a-z] | 匹配[a-z]任意字符 |
| [abc] | a/b/c中的任意一个字符 |
| {n} | 重复n次 |
| \b | 匹配单词的开始和结束 |
| \d | 匹配数字 |
| \w | 匹配字母,数字,下划线 |
| \s | 匹配任意空白,包括空格,制表符(Tab),换行符 |
| \W | 匹配任意不是字母,数字,下划线的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开始和结束的位置 |
| [^a] | 匹配除了a以外的任意字符 |
| [^(123|abc)] | 匹配除了123或者abc这几个字符以外的任意字符 |
import re
#\d匹配数字一个数字
pattern1=re.compile("\d")
result1=pattern1.findall("hello 123 567")
print(result1)
#\d+匹配一个或者多个数字 如果是多个数字,则必须连续
pattern2=re.compile("\d+")
result2=pattern1.findall("hello 123 567 wor65k6")
print(result2)
#\d{3,}匹配3次或者多次,必须连续
pattern3=re.compile("\d{3,}")
result3=pattern1.findall("hello 123 567 wor65k6")
print(result3)
#\d{3}连续匹配三次
pattern4=re.compile("\d{3}")
result4=pattern1.findall("hello 123 567 wor65453k6434")
print(result4)
#\d{1,2} 可以匹配一次,也可以匹配两次,已更多的优先
pattern5=re.compile("\d{1,2}")
result5=pattern1.findall("hello 123 567 wor65453k6434")
print(result5)
#re.I表示忽略大小写,"[a-z]{5}匹配a-z的字母五次
pattern6=re.compile("[a-z]{5}",re.I)
result6=pattern1.findall("hello 123 567 wor65453k6434")
print(result6)
#\w+匹配数字,字母, 下滑线 一次或者多次
pattern7=re.compile("\w+")
result7=pattern7.findall("hello 123 567 wor65_453k6434")
print(result7)
#\s+匹配空白字符一次或者多次
pattern8=re.compile("\s+")
result8=pattern8.findall("hello 123 567 wor65_453k6434")
print(result8)
# \W+ 匹配不是下滑线 字母 数字
pattern9=re.compile("\W+")
result9=pattern9.findall("hello 123 567 wor65_453k6434")
print(result9)
# [\w\W]+ 匹配所有字符, 一次或多次
pattern10=re.compile("[\w\W]+")
result10=pattern10.findall("hello 123 567 w¥or65_453k6434")
print(result10)
#[abc]+匹配a 或者b或c一次或多次
pattern10=re.compile("[abc]+")
result10=pattern10.findall("hello b123 c567 w¥ora65_453ka6434")
print(result10)
# [^abc|123]+ 获取不是abc或者123的字符
pattern10=re.compile("[^abc|123]+")
result10=pattern10.findall("hello b123 c567 w¥ora65_453ka6434")
print(result10)
# .* 匹配任意字符,除了换行符
pattern10=re.compile(".*")
result10=pattern10.findall("hello b123 c567 w¥ora65_453ka6434")
print(result10)
#re.I表示忽略大小写,"[a-z]{5}匹配a-z的字母五次
pattern10=re.compile("[a-z]{5}",re.I)
#只查找字符串在0-8之间范围的字符 ,要前不要后(左闭右开)-->只查找0,1,2,3,4,5,6,7
result10=pattern10.findall("hello b123 c567 w¥ora65_453ka6434",0,8)
print(result10)
- match 方法
match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。它的一般使用形式如下:
match(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。因此,当你不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
import re
pattern1=re.compile("\d+")
#match 匹配 匹配一次返回 从头开始匹配, 匹配不到返回none
result1=pattern1.match("gjkdsla3232342kjldf4332opopo")
print(result1)
pattern1=re.compile("\d+")
#match 匹配 匹配一次返回 从头开始匹配,返回的是match类型的数据
result1=pattern1.match("5458gjkdsla3232342kjldf4332opopo")
print( type(result1))#span=(0, 4), match='5458' span是查找的范围,要前不要后
print(result1)
#提取匹配数据,后面的哦和没有0 效果是一样的
print(result1.group())
print(result1.group(0))
print(result1.start())#获取在字符串开始的位置
print(result1.end())#结束的位置
print(result1.span())#开始和结束的位置 是一个元组
pattern1=re.compile("\d+")
#match 匹配 匹配一次返回 从头开始匹配,返回的是match类型的数据
#匹配不到 因为位置为6的是字符 不是数字
result1=pattern1.match("5458gjkdsla3232342kjldf4332opopo",6,10)
print(result1)
pattern1=re.compile("\d+")
#match 匹配 匹配一次返回 从头开始匹配,返回的是match类型的数据
pattern2=re.compile("\d+")
#match 匹配 匹配一次返回 从头开始匹配,返回的是match类型的数据
result2=pattern2.match("5458gjkdsla3232342kjldf4332opopo",1,10)
print(result2)
pattern2=re.compile("([a-z])+ ([a-z]+)")
#match 匹配 匹配一次返回 从头开始匹配,返回的是match类型的数据
result2=pattern2.match("gjkdsla kjld opopo")
print(result2)
print(result2.group())
print(result2.group(0))#获取所有匹配的内容
print(result2.group(1))#获取第一个()中的内容
print(result2.group(2))#获取第2个()中的内容
print(result2.groups())#获取全部返回一个元组
在上面,当匹配成功时返回一个 Match 对象,其中:
- group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
- start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
- end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
- span([group]) 方法返回 (start(group), end(group))。
- search 方法
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果,它的一般使用形式如下:
search(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
让我们看看例子:
import re
pattern=re.compile("\d+")
#search 是一次匹配 从任意位置开始,返回的是match对象,
#和match最大的不同,就是开始的位置不一样 ,没有查找到 返回none
result=pattern.search("nnd123tyy4566tre189")
#match类型,后面的操作和match方法是一样的
print(result)
print(type(result))
print(result.group())
- finditer 方法
finditer 方法的行为跟 findall 的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match 对象)的迭代器。
看看例子:
import re
pattern=re.compile("\d+")
#finditer 是全局查找,返回一个迭代器
result=pattern.finditer("nnd123tyy4566tre189")
print(result)
#遍历迭代器,一个个拿出我们想要的数据
for i in result:
#返回到是match对象
print(i)
#获取match对象中的内容
print(i.group())
列表和迭代器的区别
- 迭代器不占用内存,等你想要的时候,遍历获取出来即可
- 列表是占用大量内存,不使用也占用内存
- split 方法
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
split(string[, maxsplit])
其中,maxsplit 用于指定最大分割次数,不指定将全部分割。
看看例子:
import re
#把所有的字母分开
pattern=re.compile("[\s;\,\:]+")
#split 是分隔符[\s;\,\:]+
result=pattern.split("i; want: eat;;; dinner, do, you,; want it yes")
print(result)
- sub 方法
sub 方法用于替换。它的使用形式如下:
sub(repl, string[, count])
其中,repl 可以是字符串也可以是一个函数:
- 如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl 还可以使用 id 的形式来引用分组,但不能使用编号 0;
- 如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
- count 用于指定最多替换次数,不指定时全部替换。
import re
#\w 匹配数字 字母 下划线
pattern=re.compile("(\w+)(\w+)")
str1="hello 123 hello 456"
#相当于把str1中被paterna ((\w+)(\w+)) 匹配到的内容 使用wew替换
result=pattern.sub("wew,tr",str1)
print(result)
在某些情况下,我们想匹配文本中的汉字,有一点需要注意的是,中文的 unicode 编码范围 主要在[u4e00-u9fa5]+,这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。
假设现在想把字符串 title = ‘你好,hello,世界’ 中的中文提取出来,可以这么做:
import re
#声明要匹配的内容
str="这世界真美好 fdjska dfa"
# [u4e00-u9fa5]这个范围可以匹配绝大多数汉字
# \u是匹配中文
pattern=re.compile("[\u4e00-\u9fa5]+")
result=pattern.findall(str)
print(result)
智能推荐
vue3背景下,el-input嵌套在弹出框中,自动聚焦“失效”?如何实现自动聚焦_vue3 el-input 自动聚焦autofocus无效-程序员宅基地
文章浏览阅读436次,点赞15次,收藏2次。原因或许是,使用autofocus时,确实聚焦了!但是当我们又点击 显示弹出框的按钮时,input又失焦了,所以当我们看到input框时,没有自动聚焦。_vue3 el-input 自动聚焦autofocus无效
linux网络服务配置说课,《说课稿LINUX》PPT课件.ppt-程序员宅基地
文章浏览阅读222次。《《说课稿LINUX》PPT课件.ppt》由会员分享,可在线阅读,更多相关《《说课稿LINUX》PPT课件.ppt(16页珍藏版)》请在装配图网上搜索。1、LINUX 基础应用与配置管理 桂林山水职业学院计算机系 朱笑雷 主要内容 课程定位 1 课程内容设置 2 教学方法与手段 3 教材建设 4 教学团度 5 主要内容 实践条件 6 课程考核 7 教学效果 8 课程特色 9 建设思路 10 一、课..._linux说课课件
在SpringBoot中启动时关于连接数据库失败的问题_springboot启动时数据库连接失败 不关闭-程序员宅基地
文章浏览阅读2.2k次。#在SpringBoot中启动时关于连接数据库失败的问题对照了application.yml,发现配置文件貌似没什么问题,但是在查找信息之后,发现问题正是出现在application.yml中问题出于datasource下的data-username和data-password只要将data-username和data-password改为username和password即可..._springboot启动时数据库连接失败 不关闭
antd-pro(V5)动态菜单_antdpro的菜单-程序员宅基地
文章浏览阅读4.6k次。一般情况下登录系统后菜单是由后端返回的,不是前端写死的。antd-pro也支持,修改的路径在app.tsx在 layout 里加一个menuDataRender字段先给一个() =>[]可以看到左侧菜单没了,说明配置生效了,接下来就可以围绕这个配置做文章了,我们先定义一个 menuDataRender方法。根据登录缓存到本地的数据做下处理,判断菜单里要展示哪些内容(比如替换字段,隐藏不显示的菜单,隐藏按钮等),处理好了后返回一个数组结构即可。示例代码如下export const layout: _antdpro的菜单
Linux安装使用jprofiler6分析服务器应用状态-程序员宅基地
文章浏览阅读77次。为什么80%的码农都做不了架构师?>>> ..._jprofiler6 key
苏小红C语言第四版课后习题练习7.7最大公约数三种计算方式_c语言程序设计第四版课后题答案苏小红第七章-程序员宅基地
文章浏览阅读170次。(可以看出递归算法更加侧重于计算的技巧,并且计算机计算的次数也相对更少);_c语言程序设计第四版课后题答案苏小红第七章
随便推点
Fiddler抓包,并修改请求数据_filder改数据包-程序员宅基地
文章浏览阅读4.4w次,点赞8次,收藏51次。浏览器抓包(工具:fiddler)并 修改请求内容 工具下载:https://pan.baidu.com/s/1pyKdAwgTdNNvoWA2bGlk9A 1、正常打开网页,输入要提交的内容 2、打开工具,f11暂停了页面的所有提交动作 3、这时再点击提交按钮,请求的数据就会被工具拦截 4、双击截取的数据,右侧会看到请求的具体内容,任意修改数据 5、点击绿色按钮 run ..._filder改数据包
视频格式转换器榜单:10 款最值得拥有的高清视频转换器_奇客视频转换-程序员宅基地
文章浏览阅读560次。如果您想在计算机或任何其他设备上播放高质量的视频,高清视频转换器可以帮助确保您的视频与您的操作系统和硬件兼容。您还可以使用高清转换器更改视频的分辨率,无论您是想提高质量还是降低分辨率以生成更小的文件。在下表中,我们描述了用于转换高清视频的最流行和可用的桌面程序和在线服务。它们各有优缺点,因此请根据您的需要进行选择。_奇客视频转换
Unity血条效果,图片动画_游戏血条动图-程序员宅基地
文章浏览阅读1.9k次。欢迎来到unity学习、unity培训、unity企业培训教育专区,这里有很多U3D资源、U3D培训视频,我们致力于打造业内unity3d培训、学习第一品牌。今天开始做我们的游戏了,组长给分配了任务,我负责做剧情动画,人物血条和种植植物。 一、剧情动画 动画是以多个图片的形式展现的,图片是自己制作的。 private GUITextu_游戏血条动图
环境变量的加载顺序、环境变量集合_环境变量的顺序-程序员宅基地
文章浏览阅读1k次。*******字符编码ASCII,GB2312,GBK,Unicode,UTF-8比较参考:https://blog.csdn.net/softwarenb/article/details/51994943**环境变量的加载顺序:Mac系统的环境变量,加载顺序为:a. /etc/profileb. /etc/pathsc. ~/.bash_profiled. ~/..._环境变量的顺序
科学家发现让人类幸福感飙升的密码!给大脑植入这个算法 | 精选-程序员宅基地
文章浏览阅读316次。▼大型年度AI人物评选——2017中国AI英雄风云榜已于12月4日在乌镇张榜,12月18日在北京国贸三期举行颁奖典礼。榜单评选出年度技术创新人物TOP 10;商业创新人物TOP 10,获取完整榜单请关注网易智能公众号(ID:smartman163),回复关键词“评奖”。本文系网易智能工作室出品聚焦AI,读懂下一个大时代【网易智能讯12月10日消息】不只有你会_人类大脑植入代码
正则表达式匹配中括号内的内容_正则<>里内容-程序员宅基地
文章浏览阅读3.6k次。几经研究, 终于实现了。time[2020-06-04 11:43:36](?<=\[)(.*)(?=])(pattern) 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 '\(' 或 '\)'。 (?:pattern) 匹配 pattern 但不获取匹配结..._正则<>里内容