词性标注学习笔记_joint chinese word segmentation and part-of-speech-程序员宅基地
1 词性标注概述
1.1 简介
词性(Par-Of-Speech,Pos)是词汇基本的语法属性,通常也称为词类。词性标注就是在给定句子中判定每个词的语法范畴,确定其词性并加以标注的过程。
1.2 难点
1)汉语是一种缺乏词形态变化的语言,词的类别不能像印欧语那样,直接从词的形态变化上来判别。
2)常用词兼类现象严重,具有多个词性的兼类词的占比高达22.5%。而且越是常用的词,多词性的现象越严重。
3)词性划分标准不统一。词类划分粒度和标记符号等,目前还没有一个广泛认可的统一的标准。比如LDC标注语料中,将汉语一级词性划分为33类,而北京大学语料库则将其划分为26类。
4)未登录词问题。和分词一样,未登录词的词性也是一个比较大的课题。
1.3 ICTCLAS汉语词性标注集
| 代码 | 名称 | 说明 | 举例 |
|---|---|---|---|
| a | 形容词 | 取英语形容词adjective的第1个字母。 | 最/d 大/a 的/u |
| ad | 副形词 | 直接作状语的形容词。形容词代码a和副词代码d并在一起。 | 一定/d 能够/v 顺利/ad 实现/v 。/w |
| ag | 形语素 | 形容词性语素。形容词代码为a,语素代码g前面置以A。 | 喜/v 煞/ag 人/n |
| an | 名形词 | 具有名词功能的形容词。形容词代码a和名词代码n并在一起。 | 人民/n 的/u 根本/a 利益/n 和/c 国家/n 的/u 安稳/an 。/w |
| b | 区别词 | 取汉字“别”的声母。 | 副/b 书记/n 王/nr 思齐/nr |
| c | 连词 | 取英语连词conjunction的第1个字母。 | 全军/n 和/c 武警/n 先进/a 典型/n 代表/n |
| d | 副词 | 取adverb的第2个字母,因其第1个字母已用于形容词。 | 两侧/f 台柱/n 上/ 分别/d 雄踞/v 着/u |
| dg | 副语素 | 副词性语素。副词代码为d,语素代码g前面置以D。 | 用/v 不/d 甚/dg 流利/a 的/u 中文/nz 主持/v 节目/n 。/w |
| e | 叹词 | 取英语叹词exclamation的第1个字母。 | 嗬/e !/w |
| f | 方位词 | 取汉字“方” 的声母。 | 从/p 一/m 大/a 堆/q 档案/n 中/f 发现/v 了/u |
| g | 语素 | 绝大多数语素都能作为合成词的“词根”,取汉字“根”的声母。 | 例如dg 或ag |
| h | 前接成分 | 取英语head的第1个字母。 | 目前/t 各种/r 非/h 合作制/n 的/u 农产品/n |
| i | 成语 | 取英语成语idiom的第1个字母。 | 提高/v 农民/n 讨价还价/i 的/u 能力/n 。/w |
| j | 简称略语 | 取汉字“简”的声母。 | 民主/ad 选举/v 村委会/j 的/u 工作/vn |
| k | 后接成分 | 权责/n 明确/a 的/u 逐级/d 授权/v 制/k | |
| l | 习用语 | 习用语尚未成为成语,有点“临时性”,取“临”的声母。 | 是/v 建立/v 社会主义/n 市场经济/n 体制/n 的/u 重要/a 组成部分/l 。/w |
| m | 数词 | 取英语numeral的第3个字母,n,u已有他用。 | 科学技术/n 是/v 第一/m 生产力/n |
| n | 名词 | 取英语名词noun的第1个字母。 | 希望/v 双方/n 在/p 市政/n 规划/vn |
| ng | 名语素 | 名词性语素。名词代码为n,语素代码g前面置以N。 | 就此/d 分析/v 时/Ng 认为/v |
| nr | 人名 | 名词代码n和“人(ren)”的声母并在一起。 | 建设部/nt 部长/n 侯/nr 捷/nr |
| ns | 地名 | 名词代码n和处所词代码s并在一起。 | 北京/ns 经济/n 运行/vn 态势/n 喜人/a |
| nt | 机构团体 | “团”的声母为t,名词代码n和t并在一起。 | [冶金/n 工业部/n 洛阳/ns 耐火材料/l 研究院/n]nt |
| nx | 字母专名 | ATM/nx 交换机/n | |
| nz | 其他专名 | “专”的声母的第1个字母为z,名词代码n和z并在一起。 | 德士古/nz 公司/n |
| o | 拟声词 | 取英语拟声词onomatopoeia的第1个字母。 | 汩汩/o 地/u 流/v 出来/v |
| p | 介词 | 取英语介词prepositional的第1个字母。 | 往/p 基层/n 跑/v 。/w |
| q | 量词 | 取英语quantity的第1个字母。 | 不止/v 一/m 次/q 地/u 听到/v ,/w |
| r | 代词 | 取英语代词pronoun的第2个字母,因p已用于介词。 | 有些/r 部门/n |
| s | 处所词 | 取英语space的第1个字母。 | 移居/v 海外/s 。/w |
| t | 时间词 | 取英语time的第1个字母。 | 当前/t 经济/n 社会/n 情况/n |
| tg | 时语素 | 时间词性语素。时间词代码为t,在语素的代码g前面置以T。 | 秋/Tg 冬/tg 连/d 旱/a |
| u | 助词 | 取英语助词auxiliary 的第2个字母,因a已用于形容词。 | 工作/vn 的/u 政策/n |
| ud | 结构助词 | 有/v 心/n 栽/v 得/ud 梧桐树/n | |
| ug | 时态助词 | 你/r 想/v 过/ug 没有/v | |
| uj | 结构助词的 | 迈向/v 充满/v 希望/n 的/uj 新/a 世纪/n | |
| ul | 时态助词了 | 完成/v 了/ ul | |
| uv | 结构助词地 | 满怀信心/l 地/uv 开创/v 新/a 的/u 业绩/n | |
| uz | 时态助词着 | 眼看/v 着/uz | |
| v | 动词 | 取英语动词verb的第一个字母。 | 举行/v 老/a 干部/n 迎春/vn 团拜会/n |
| vd | 副动词 | 直接作状语的动词。动词和副词的代码并在一起。 | 强调/vd 指出/v |
| vg | 动语素 | 动词性语素。动词代码为v。在语素的代码g前面置以V。 | 做好/v 尊/vg 干/j 爱/v 兵/n 工作/vn |
| vn | 名动词 | 指具有名词功能的动词。动词和名词的代码并在一起。 | 股份制/n 这种/r 企业/n 组织/vn 形式/n ,/w |
| w | 标点符号 | 生产/v 的/u 5G/nx 、/w 8G/nx 型/k 燃气/n 热水器/n | |
| x | 非语素字 | 非语素字只是一个符号,字母x通常用于代表未知数、符号。 | |
| y | 语气词 | 取汉字“语”的声母。 | 已经/d 30/m 多/m 年/q 了/y 。/w |
| z | 状态词 | 取汉字“状”的声母的前一个字母。 | 势头/n 依然/z 强劲/a ;/w |
2 常见方法
2.1 基于字符串匹配的字典查找
从字典中查找每个词语的词性,对其进行标注。这种方法比较简单,但是不能解决一词多词性的问题,因此存在一定的误差。
2.2 基于统计的算法
通过机器学习模型,从数据中学习规律,进行词性标注。此类方法可以根据词的上下文进行词性标注,解决一词多词性的问题。常见模型如HMM、CRF、神经网络等。
根据输入的粒度,可以分为基于词的方法,和基于字的方法。基于词的方法需要首先对句子进行分词,然后对分词的结果进行词性标注。基于字的方法把分词和词性标注两个任务联合训练。
3 数据集、评价指标
3.1 常用数据集
- 宾州中文树库CTB 5~9
- PFR人民日报标注语料库
- UD-Chinese-GSD数据集
3.2 评价指标
一般采用精确率(precision)、召回率 (recall)和F1值进行测评。
基于词的方法, 可以直接计算以上三个指标。基于字的方法,只有当分词和词性标注同时正确时,才算标注正确。
3 论文笔记
================================================================================================
ACL 2017:Character-based Joint Segmentation and POS Tagging for Chinese using Bidirectional RNN-CRF
================================================================================================

概述
文本提出一个基于BiRNN-CRF的中文分词和词性标注联合标注模型,模型在字符的表示上进行改进,可以提供更加丰富的信息。
模型架构

模型的核心是传统的双向RNN加CRF架构,RNN选用GRU。标签体系使用BIES和词性标签的组合,可以在一个标签中同时包含两种信息(如B-DEG、I-DEG、E-DEG )。
本文的关键创新是在字符的表示上。
1)Concatenated N-gram
首先对于每个字符,提取以该字符为中心的n-gram信息![]() ,其中m为开始位置,n为结束位置。
,其中m为开始位置,n为结束位置。![]() 为对应n-gram字符串的embedding。然后把多个n-gram的
为对应n-gram字符串的embedding。然后把多个n-gram的![]() 进行拼接,得到该字符的表示。
进行拼接,得到该字符的表示。
2)Radicals and Orthographical Features(偏旁和字形特征)
对于汉字,偏旁包含了丰富的信息,每个偏旁使用一个embedding表示,然后拼接到该字符的表示当中。
汉字的字形也提供了重要的信息,使用两层的CNN+Max pooling卷积网络提取字形信息,拼接到该字符的表示当中。
3)Pre-trained Character Embeddings
本文测试了使用预训练的embedding和随机embedding的区别。
4)Ensemble Decoding
本文测试了使用多个模型进行联合解码的效果。
实验结果



特征分析



================================================================================================
IEEE 2018:A Simple and Effective Neural Model for Joint Word Segmentation and POS Tagging
================================================================================================

概述
由于中文分词和词性标注具有高度的关联性,传统的首先进行分词再进行词性标注的二阶段模式会造成错误的累积。文本提出一个简单高效的,基于Seq2Seq架构的神经网络模型,对中文分词和词性标注进行联合标注。
模型架构
1) Transition System
由于本模型的解码方式参考传统的Transition System,所以首先对其进行简单介绍。Transition System主要包含两部分:状态(State)和动作(Action)。开始时,有一个空的开始状态,然后通过一系列的动作逐渐改变状态的值,直到得到一个表示最终结果的结束状态。
通过设计一个针对分词和词性标注联合解码的Transition System,可以把解码过程表示为一系列动作组成的序列,并使用Seq2Seq模型预测得出。系统包含两类动作:1)SEP(t):将当前字作为词性(t)开始的第一个字放入状态当中;2)APP:将当前字添加到状态当中,作为当前状态顶端的词性所表示的字当中。具体可以参考下图例子。

2)Seq2Seq模型
本模型包含Encoder和Decoder两部分。
2.1)Encoder
2.1.1)Embedding Layer
本层包含字(![]() )的unigram和bigram的Embedding,其中bigram包含正向(
)的unigram和bigram的Embedding,其中bigram包含正向(![]() )和反向(
)和反向(![]() )两种。
)两种。
每种Embedding又分别包含两种类型:1)随机初始化并随着网络训练调整;2)使用外部数据预训练得到并固定权重。最终的Embedding由两种类型拼接而成。
其中使用外部数据预训练Embedding时,考虑两种方式:1)只使用字信息训练的Basic Embeddings;2)结合分词、词性标签训练的Word-Context Embeddings。实验结果表明,Word-Context Embeddings效果更好。
2.1.2)LSTM Input
Encoder由正向和反向两个LSTM组成,所以需要分别为两个LSTM提供输入。输入由unigram和对应的bigram的Embedding拼接后,通过一个简单的线性变换得到:
 或
或
2.1.3)Bi-Directional LSTM
经过输入层,分别得到正向和反向两部分输入:![]() 和
和![]() 。然后分别输入到两个LSTM当中,Encoder的最终输出由两个LSTM的输出拼接得到:
。然后分别输入到两个LSTM当中,Encoder的最终输出由两个LSTM的输出拼接得到:![]() 。
。
2.2)Decoder
Decoder由一个基于动态解码的词为输入的单向LSTM构成。和传统的Seq2Seq模型对比,本模型具有两方面的区别。第一,由于基于Transition System的解码系统自带了注意力的属性,所以本模型不需要显式的注意力结构。第二,本模型的Decoder基于动态解码的word-level特征作为输入,而不是原始输入的character-level特征。
2.2.1)Word Representation
Decoder的输入为词列表![]() ,其中每个词由两部分组成:1)组成词的每个字的Encoder输出的组合;2)预测的词性标签的Embedding。
,其中每个词由两部分组成:1)组成词的每个字的Encoder输出的组合;2)预测的词性标签的Embedding。
Decoder的输入的词可以表示为:

其中![]() 有几种可选的计算方式:
有几种可选的计算方式:

由于Encoder的输出由两个方向分别组成,所以词的表示也分别由两个方向的组合拼接得到:
![]()
然后把词表示和词性标签的Embedding拼接,通过一个简单的线性变换得到![]() :
:
![]()
2.2.2)LSTM
把![]() 输入到单向LSTM当中,得到每一步的隐藏状态
输入到单向LSTM当中,得到每一步的隐藏状态![]() ,然后经过两次线性变换,得到每一步的输出:
,然后经过两次线性变换,得到每一步的输出:

2.3)Training
使用交叉熵作为损失函数:

实验结果

特征分析
1)Word Representation
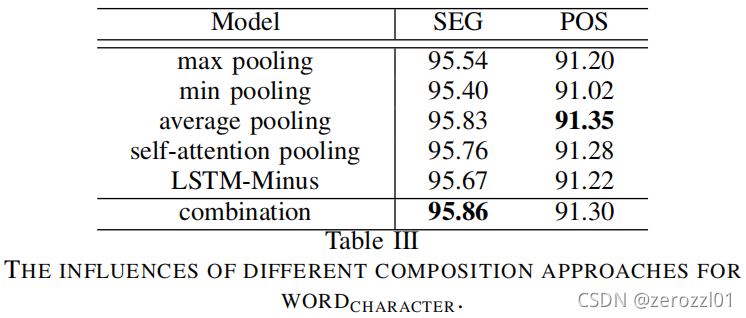
2)Feature

3)Pretrain Embedding


================================================================================================
ACL 2020:Joint Chinese Word Segmentation and Part-of-speech Tagging via Two-way Attentions of Auto-analyzed Knowledge
================================================================================================

概述
当前的词性标注模型只关注n-gram等上下文信息,忽略了其他语法知识。然而,句法结构、依存关系等知识可以提供单词之间的距离依赖信息。使用现成的工具自动生成的语法知识,可以对词性标注模型起到辅助作用。本文提出一个中文分词和词性标注联合标注模型,使用双向注意机制整合每个输入字符的上下文特征及其相应的语法知识。
模型架构
设输入为![]()
![]() ,输出为
,输出为![]() ,
,![]() 的上下文特征为
的上下文特征为![]() ,语法知识为
,语法知识为![]() 。每个字符
。每个字符![]() 对应的特征表示为
对应的特征表示为![]() 和
和![]() 。
。
1)Auto-analyzed Knowledge

人工标注的语法知识比较难以获取,但是自动分析得到的语法知识可以通过工具生成,虽然自动生成的知识有一定噪声,但是如果可以让模型学习如何利用这些知识,可以有效提升模型效果。本模型通过注意力机制,从自动生成的语法知识中提取特征。
本文使用三种语法知识:1)自动生成的词性标注标签;2)句法结构;3)依存关系。
1.1)自动生成的词性标注标签
对于每个字符![]() ,取包含该字符的词,以及其相邻2个词范围内的所有词,的上下文和词性标注标签特征。
,取包含该字符的词,以及其相邻2个词范围内的所有词,的上下文和词性标注标签特征。
1.2)句法结构
首先定义一组需要关注的句法标签。对于每个字符![]() ,从包含该字符的词开始往根节点回溯,直到遇到第一个在预定义的句法标签的词为止,取该词下的所有叶子节点的词的上下文和句法标签特征。
,从包含该字符的词开始往根节点回溯,直到遇到第一个在预定义的句法标签的词为止,取该词下的所有叶子节点的词的上下文和句法标签特征。
1.3)依存关系
对于每个字符![]() ,取包含该字符的词以及与其存在依存关系的所有词的上下文和依存关系标签特征。
,取包含该字符的词以及与其存在依存关系的所有词的上下文和依存关系标签特征。
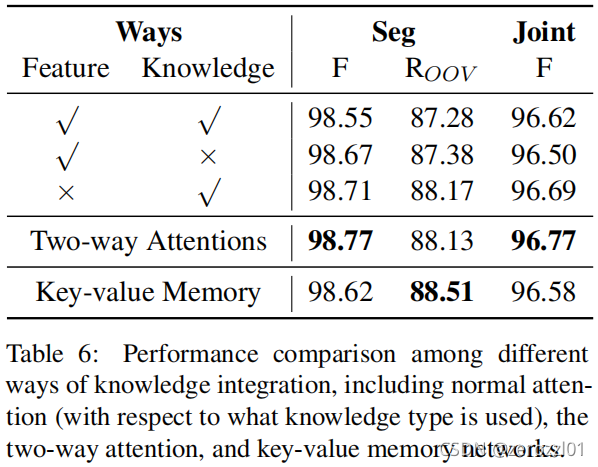
2)Two-Way Attentions
之前的研究直接把上下文特征和语法知识进行拼接,容易受噪声干扰,本模型分别使用两个attention提取上下文和语法知识特征。以上下文特征为例,计算方式为:


其中![]() 是编码器提取的
是编码器提取的![]() 特征,
特征,![]() 是
是![]() 的上下文特征中的第j项,
的上下文特征中的第j项,![]() 是
是![]() 的embedding。
的embedding。
使用同样的方式提取语法知识特征![]() ,最后把上下文和语法知识特征拼接,得到本层输出
,最后把上下文和语法知识特征拼接,得到本层输出![]() 。
。
3)Joint Tagging with Two-way Attentions
把编码器和双向注意机制提取的特征拼接后输入到一个线性变换层,然后输入到CRF层得到最终输出:
![]()

实验结果
本文测试使用Stanford CoreNLP Toolkit(SCT)和Berkeley Neural Parser(BNP)两个工具本身进行词性标注的结果,和基于它们提取的语法特征在本模型下的结果。
同时也对比使用Bi-LSTM、BERT、ZEN三种编码器的结果。



特征分析
智能推荐
Docker 快速上手学习入门教程_docker菜鸟教程-程序员宅基地
文章浏览阅读2.5w次,点赞6次,收藏50次。官方解释是,docker 容器是机器上的沙盒进程,它与主机上的所有其他进程隔离。所以容器只是操作系统中被隔离开来的一个进程,所谓的容器化,其实也只是对操作系统进行欺骗的一种语法糖。_docker菜鸟教程
电脑技巧:Windows系统原版纯净软件必备的两个网站_msdn我告诉你-程序员宅基地
文章浏览阅读5.7k次,点赞3次,收藏14次。该如何避免的,今天小编给大家推荐两个下载Windows系统官方软件的资源网站,可以杜绝软件捆绑等行为。该站提供了丰富的Windows官方技术资源,比较重要的有MSDN技术资源文档库、官方工具和资源、应用程序、开发人员工具(Visual Studio 、SQLServer等等)、系统镜像、设计人员工具等。总的来说,这两个都是非常优秀的Windows系统镜像资源站,提供了丰富的Windows系统镜像资源,并且保证了资源的纯净和安全性,有需要的朋友可以去了解一下。这个非常实用的资源网站的创建者是国内的一个网友。_msdn我告诉你
vue2封装对话框el-dialog组件_<el-dialog 封装成组件 vue2-程序员宅基地
文章浏览阅读1.2k次。vue2封装对话框el-dialog组件_
MFC 文本框换行_c++ mfc同一框内输入二行怎么换行-程序员宅基地
文章浏览阅读4.7k次,点赞5次,收藏6次。MFC 文本框换行 标签: it mfc 文本框1.将Multiline属性设置为True2.换行是使用"\r\n" (宽字符串为L"\r\n")3.如果需要编辑并且按Enter键换行,还要将 Want Return 设置为 True4.如果需要垂直滚动条的话将Vertical Scroll属性设置为True,需要水平滚动条的话将Horizontal Scroll属性设_c++ mfc同一框内输入二行怎么换行
redis-desktop-manager无法连接redis-server的解决方法_redis-server doesn't support auth command or ismis-程序员宅基地
文章浏览阅读832次。检查Linux是否是否开启所需端口,默认为6379,若未打开,将其开启:以root用户执行iptables -I INPUT -p tcp --dport 6379 -j ACCEPT如果还是未能解决,修改redis.conf,修改主机地址:bind 192.168.85.**;然后使用该配置文件,重新启动Redis服务./redis-server redis.conf..._redis-server doesn't support auth command or ismisconfigured. try
实验四 数据选择器及其应用-程序员宅基地
文章浏览阅读4.9k次。济大数电实验报告_数据选择器及其应用
随便推点
灰色预测模型matlab_MATLAB实战|基于灰色预测河南省社会消费品零售总额预测-程序员宅基地
文章浏览阅读236次。1研究内容消费在生产中占据十分重要的地位,是生产的最终目的和动力,是保持省内经济稳定快速发展的核心要素。预测河南省社会消费品零售总额,是进行宏观经济调控和消费体制改变创新的基础,是河南省内人民对美好的全面和谐社会的追求的要求,保持河南省经济稳定和可持续发展具有重要意义。本文建立灰色预测模型,利用MATLAB软件,预测出2019年~2023年河南省社会消费品零售总额预测值分别为21881...._灰色预测模型用什么软件
log4qt-程序员宅基地
文章浏览阅读1.2k次。12.4-在Qt中使用Log4Qt输出Log文件,看这一篇就足够了一、为啥要使用第三方Log库,而不用平台自带的Log库二、Log4j系列库的功能介绍与基本概念三、Log4Qt库的基本介绍四、将Log4qt组装成为一个单独模块五、使用配置文件的方式配置Log4Qt六、使用代码的方式配置Log4Qt七、在Qt工程中引入Log4Qt库模块的方法八、获取示例中的源代码一、为啥要使用第三方Log库,而不用平台自带的Log库首先要说明的是,在平时开发和调试中开发平台自带的“打印输出”已经足够了。但_log4qt
100种思维模型之全局观思维模型-67_计算机中对于全局观的-程序员宅基地
文章浏览阅读786次。全局观思维模型,一个教我们由点到线,由线到面,再由面到体,不断的放大格局去思考问题的思维模型。_计算机中对于全局观的
线程间控制之CountDownLatch和CyclicBarrier使用介绍_countdownluach于cyclicbarrier的用法-程序员宅基地
文章浏览阅读330次。一、CountDownLatch介绍CountDownLatch采用减法计算;是一个同步辅助工具类和CyclicBarrier类功能类似,允许一个或多个线程等待,直到在其他线程中执行的一组操作完成。二、CountDownLatch俩种应用场景: 场景一:所有线程在等待开始信号(startSignal.await()),主流程发出开始信号通知,既执行startSignal.countDown()方法后;所有线程才开始执行;每个线程执行完发出做完信号,既执行do..._countdownluach于cyclicbarrier的用法
自动化监控系统Prometheus&Grafana_-自动化监控系统prometheus&grafana实战-程序员宅基地
文章浏览阅读508次。Prometheus 算是一个全能型选手,原生支持容器监控,当然监控传统应用也不是吃干饭的,所以就是容器和非容器他都支持,所有的监控系统都具备这个流程,_-自动化监控系统prometheus&grafana实战
React 组件封装之 Search 搜索_react search-程序员宅基地
文章浏览阅读4.7k次。输入关键字,可以通过键盘的搜索按钮完成搜索功能。_react search