spark2原理分析-RDD的shuffle简介_rdd shuffle-程序员宅基地
技术标签: 原理分析 spark 理解shuffle过程 源码分析-深入浅出Spark原理 shuffle
概述
本文介绍RDD的Shuffle原理,并分析shuffle过程的实现。
RDD Shuffle简介
spark的某些操作会触发被称为shuffle的事件。shuffle是Spark重新分配数据的机制,它可以对数据进行分组,该操作可以跨不同分区。该操作通常会在不同的执行器(executor)和主机之间复制数据,这使shuffle成为复杂且非常消耗资源的操作。
Shuffle背景
为了理解shuffle过程,我们可以拿reduceByKey操作进行举例。reduceByKey操作会产生一个新的RDD,其中单个键的所有值都组合成一个元组(tuple) - 对key和与该key关联的所有值执行reduce函数的结果。挑战在于,并非单个key的所有值都必须位于同一个分区,甚至是同一个机器上,但它们必须能够被定位到才能计算结果。
在Spark中,数据通常不跨分区分布,以便特定操作能够访问到必要位置。
在计算过程中,单个任务将在单个分区上运行 - 因此,要组织单个reduceByKey reduce任务执行的所有数据,Spark需要执行all-to-all的操作。Spark必须从所有分区读取以查找所有key的所有值,然后将各个值组合在一起以计算每个key的最终结果 - 这个过程称为shuffle。
虽然新shuffle数据的每个分区中的元素集是确定的,且分区本身的顺序也是确定的,但分区中的数据的顺序是不确定的。如果在shuffle后希望得到特定顺序的数据,则可以使用:
- 在mapPartitions使用例如.sorted对每个分区进行排序
- repartitionAndSortWithinPartitions在同时重新分区的同时有效地对分区进行排序
- sortBy来创建一个全局排序的RDD
可能导致shuffle的操作包括以下几种:
- 重新分区(repartition)操作,例如: repartition和 coalesce。
- ByKey操作(计数除外),例如:如groupByKey和reduceByKey
- 联合(join)操作,例如:cogroup和join。
shuffle对性能的影响
shuffle操作十分昂贵(消耗性能和资源),因为它包括:磁盘I/O,数据序列号,网络I/O等操作。为了对数进行shuffle,Spark创建了一个任务集,map任务负责组织数据,reduce任务负责对数据进行聚合。这两个术语来自MapReduce,但与Spark的map和reduce操作并没有直接关系。
在内部,各个map任务的结果会保留在内存中,直到它们不再合适(fit)。然后,这些结果基于目标分区进行排序并写入单个文件。reduce任务读取相关的排好序的数据块。
某些shuffle操作会消耗大量的堆内存,因为它们使用内存中的数据结构来在传输记录之前或之后组织记录。具体来说,reduceByKey和aggregateByKey在map端创建这些结构,并且’ByKey操作在reduce端生成这些结构。当数据不适合内存时,Spark会将这些写入到磁盘,从而导致磁盘I / O的额外开销和垃圾收集的增加。
Shuffle还会在磁盘上生成大量中间文件。从Spark 1.3开始,这些文件将被保留,直到对应的RDD不再被使用,且被垃圾回收。这样做是为了在重新计算谱系时不需要重新创建shuffle文件。如果应用程序保留对这些RDD的引用或GC不经常启动,则垃圾收集可能仅在很长一段时间后才会发生。这意味着长时间运行的Spark作业可能会占用大量磁盘空间。配置Spark上下文时,spark.local.dir配置参数指定临时存储目录。
可以通过调整各种配置参数来调整shuffle行为。具体的配置将会在实战部分讲到。
注:以上两端来自官方文档对shuffle过程的说明。
理解shuffle过程
从以上分析我们可以看出,分区之间的物理数据的搬迁被称为shuffling。当需要构建新的RDD时,为了构建新的分区需要整合多个分区的数据,就会发生shuffling。例如:当通过key对成员进行分组时,Spark可能会扫描所有分区,来发现具有相同key的元素,然后在物理上对这些数据进行分组。
从以下图中可以看出具体shuffling过程:
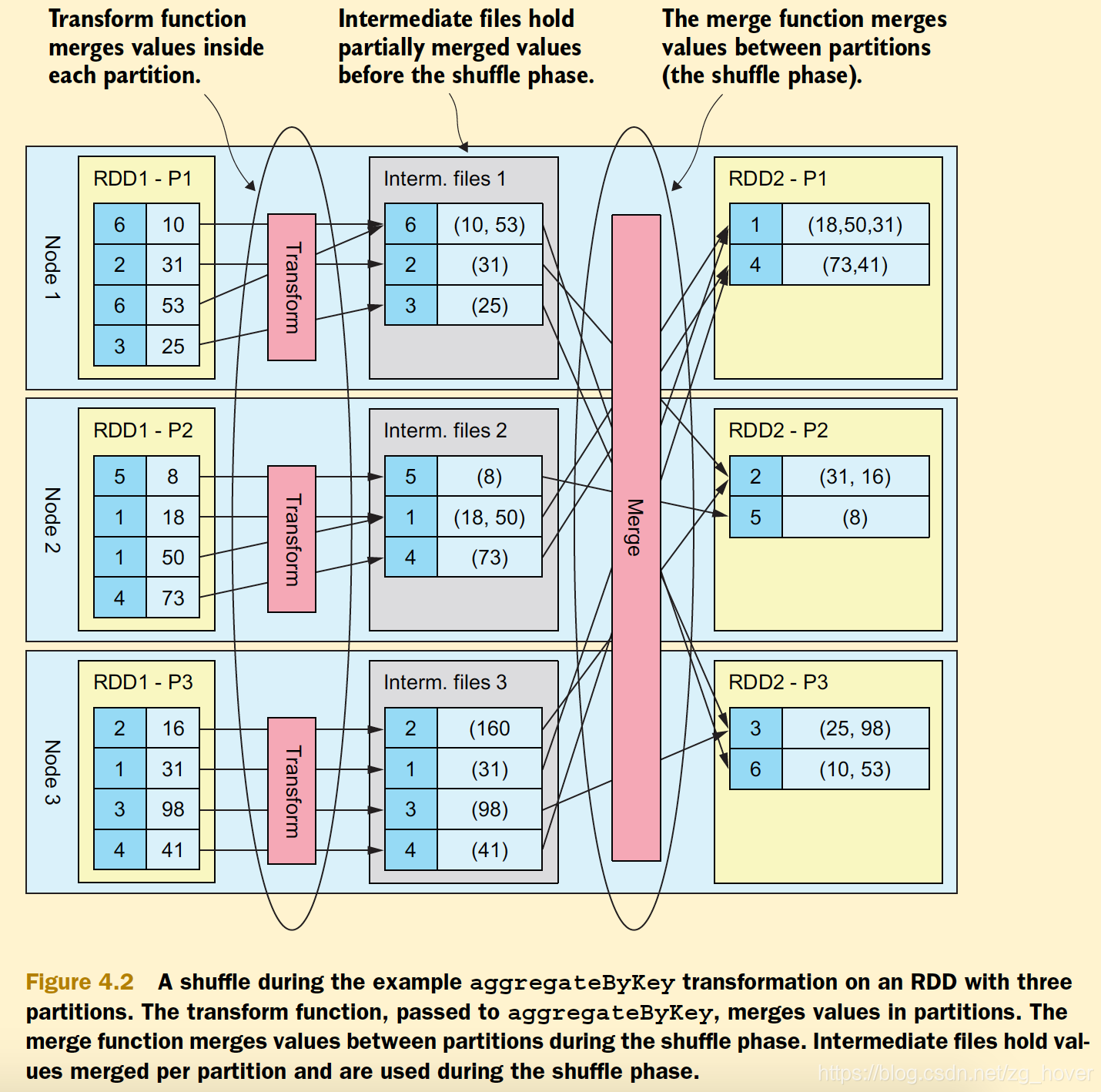
上图是《spark in action》中的例子图。
上图是一个通过key来聚合数据的例子,开始的时候各个key的数据分布在不同的Spark节点上。先进行transform过程,转换过程是在各个数据的分区上进行,聚合过程需要从不同节点的分区上获取数据,此时将会发生shuffling。
注意:关于shuffle的详细代码实现,还会有文章专门进行讲解。
参考资料
智能推荐
JavaScript Math.PI 属性-程序员宅基地
文章浏览阅读1.4w次,点赞3次,收藏16次。什么是PI?PI就是圆周率π,PI是弧度制的π,也就是180°所以,Math.PI = 3.14 = 180°ps,PI是一个浮小数Math.PI/5*4分别是什么意思?let dig = Math.PI/5*4Math.PI/5,表示角度平分为36° 每个顶点到与中心连线之间的夹角α=(2π)/n = Math.PI / n * 2 那么相间的两个顶点到与中心连线之间的夹..._math.pi
Windows下,使用免安装ZIP归档,安装MySQL(5.5)服务器-程序员宅基地
文章浏览阅读1.1k次。1. 解压 MySQL ZIP压缩包 到 安装路径 D:\xapp\apps\,并将解压出来的文件夹重命名为 mysql。2.将MySQL的可执行文件目录 D:\xapp\apps\mysql\bin 加入系统环境变量,然后重启计算机。6.启动Windows命令行 键入 mysql -u root -p ,然后两次回车,进入MySQL控制台。如果通过配置文件 将 数据库目录设置到了别处,则需要将 mysql程序根目录的 data目录中。的内容拷贝到新的目录中,否则MySQL无法启动。
Bootstrap4总结(1)_bootstrap4的好处-程序员宅基地
文章浏览阅读1k次。一.Bootstrap简介1.什么是BootstrapBootstrap 是全球最受欢迎的前端组件库,用于开发响应式布局、移动设备优先的 WEB 项目。Bootstrap4 目前是 Bootstrap 的最新版本,是一套用于 HTML、CSS 和 JS 开发的开源工具集。2.Bootstrap的来源Bootstrap是美国Twitter公司的设计师Mark Otto和Jacob Thornton合作基于HTML、CSS、JavaScript开发的简洁、直观、强悍的前端开发框架,使得 W._bootstrap4的好处
[C++]LeetCode208 . 实现 Trie (前缀树)-程序员宅基地
文章浏览阅读264次。208 . 实现 Trie (前缀树)题目:实现一个 Trie (前缀树),包含 insert, search, 和 startsWith 这三个操作。示例:Trie trie = new Trie();trie.insert(“apple”);trie.search(“apple”); // 返回 truetrie.search(“app”); // 返回 falsetrie.startsWith(“app”); // 返回 truetrie.insert(“app”);tr
阶乘和(高精度算法)_阶乘和高精度-程序员宅基地
文章浏览阅读6.6k次,点赞6次,收藏12次。(对于自然数N的阶乘,当N比较小时,可以32位整数int范围内准确表示 。例如12!=479001600<2147483647(231-1) 而20!=2432902008176640000<9223372036854775807(263-1)可以在64位整数long long int范围内准确表示 ,但是N取值更大时,N!只能使用浮点数计算,从而产生误差 )题目描述已知正整数N(N..._阶乘和高精度
emwin自定义字库-程序员宅基地
文章浏览阅读638次。一.用到软件 1.FontCvtST.exe 2.U2C.exe 下载地址:https://i.cnblogs.com/Files.aspx二.转换1.新建文本文档,在文本文档中写入所需要用的字或词语,注意:根据用到的字或者词语,每个换行,方便后面使用,如下图2.将文本文档另存为UNICODE格式的新文本文档,备用;并将原文档再另存为UTF-8格式的新文..._st emwin修改字库
随便推点
java file数组 初始化_Java数组的定义,声明,初始化和遍历-程序员宅基地
文章浏览阅读633次。数组的定义数组是相同类型数据的有序集合。数组描述的是相同类型的若干个数据,按照一定的先后次序排列组合而成。其中,每一个数据称作一个元素,每个元素可以通过一个索引(下标)来访问它们。数组的三个基本特点:1. 长度是确定的。数组一旦被创建,它的大小就是不可以改变的。2. 其元素必须是相同类型,不允许出现混合类型。3. 数组类型可以是任何数据类型,包括基本类型和引用类型。数组变量属引用类型,数组也可以看..._java file 数组
十四章上机1_北大青鸟java第十四章上机练习4-程序员宅基地
文章浏览阅读449次。实现客户姓名录入 package kj;public class kehu { String []names=new String[10]; public void addName(String name){ for(int i=0;i
React路由 报错 ‘Switch‘ is not exported from ‘react-router‘.-程序员宅基地
文章浏览阅读722次。配置 路由 报错 'Switch' is not exported from 'react-router'.npm uninstall react-router-domnpm install [email protected]
利用tushare实现选股_tushare 选股-程序员宅基地
文章浏览阅读1.1k次,点赞2次,收藏7次。ID:399899量化交易中,首先要弄好的就是选股。然后在才是买卖策略的制定。不同类型的策略,选股思路也不相同。俗话说得好,不管黑猫白猫,抓到老鼠的就是好猫。一个好的选股策略,往往在量化中是起较为关键的作用的。要实现程序化选股的话,数据又是一个前提。要有数据才能去实现编写程序。数据来源有很多,可以去爬取,也可以去股票交易网站下载。当然也有一些接口可以提供数据。常见的接口有tushare、baostock、akshare在这里我以一个简单的选股案例,为大家介绍一下使用tushare接口使用tush_tushare 选股
Gin框架使用Casbin进行用户权限校验_gin 的权限校验-程序员宅基地
文章浏览阅读3.7k次,点赞2次,收藏10次。以下是测试项目目录一、配置modelconf/casbin_rbac_model.conf# 请求[request_definition]r = sub,obj,act# sub ——> 想要访问资源的用户角色(Subject)——请求实体# obj ——> 访问的资源(Object)# act ——> 访问的方法(Action: get、post...)# 策略(.csv文件p的格式,定义的每一行为policy rule;p,p2为policy rule的名字。)_gin 的权限校验
OKR制定与实施:团队OKR众筹策略_运营okr的制定与实施-程序员宅基地
文章浏览阅读319次。例如,一个团队有20个人,其中有2个员工在共同做A业务,3个员工在共同做B业务,5个员工在共同做C业务,剩下10个员工在共同做D业务,那么可以基于业务相关性将这20个员工分成A业务研讨组、B业务研讨组、C业务研讨组和D业务研讨组,这样,在步骤2目标众筹时,就以A、B、C、D 4个研讨小组为单位,邀请其输出3~5个团队OKR,然后团队主管再基于所有小组贡献的团队OKR进行投票表决,形成团队的OKR。通过这种方式,大大增强了团队成员对团队目标的共识程度,团队目标真正变成了大家共同的目标,而不再只是主管的目标。_运营okr的制定与实施