新年第一天 | 恶补新一季《黑镜》的同时,营长又深入扒了扒它那擅长机器学习的新爸爸是如何赚钱的-程序员宅基地

关注『AI科技大本营』的各位小伙伴,新年好!营长祝愿大家天天都是18岁!
跟放假休息的各位一样,元旦假期的营长着实也不想干活……想起前两天刚刚更新的《黑镜》第四季还没有跟,营长便决定在新年的第一天恶补一下科技和AI的黑暗面。
第1集,《联邦星舰卡利斯特号》:“柯克船长”——咳,一直被老板和同事精神虐待的游戏公司老码农,却拥有一台能通过DNA来复制意识的机器,于是老码农变身猥琐男,把老板和同事的意识上传到他所掌控的游戏世界以供他泄愤……这一集糅合了《星际迷航》《TRON》《黑客帝国》等科幻大片的不少元素,尽管剧情设定上的漏洞在豆瓣上被批得体无完肤,但确是《黑镜》首播集在IMDB评分最高的一集。
第2集,《方舟天使》:因为孩子差点丢失的心理阴影,年轻的母亲在小女孩Sara头内植入“方舟天使”监护设备,从大脑内监控Sara看到、听到的一切,为她过滤所有“不良”信息。随着青春期的来临,Sara和男友谈情说爱的画面都被母亲通过她的眼睛录了下来,Sara知道后,一场无法避免的冲突爆发了……
第3集,《鳄鱼的眼泪》:假如记忆能用技术提取出来,世界会成为什么样子?假如保险公司借此获取到人们记忆深处最为黑暗的秘密,人们针对风险控制又将做出什么样的激烈反应?Mia Nolan选择了谋杀,两男一女,还有一个眼睛看不见的婴儿……

第4集,《绞死DJ》:如今,在社交网络上,算法已经控制了人们日常所读的一切信息,“喜欢”看什么,“不喜欢”看什么……完全由算法所决定。如果有一天,人们最重要的社交关系也完全交由算法控制,喜欢什么样的人,跟谁配对,交往多长时间,哪怕相处的状况是同床异梦……好在剧中的算法配对只是一个GAN式的模拟系统,好在跟其他人的配对都只是对抗网络所制造的噪音,然而新年第一天就用99.8%的匹配率来虐狗,这样真的好吗?
IMDB 9.2的高分已经平了第二季“白色圣诞”特辑所创的记录,本季最佳无可争议。《权力的游戏》导演Timothy Van Patten的功底确实不是盖的。
第5集,《金属头》:波士顿动力大狗化身杀手机器人,取代人类统治了世界,并守护着地面上所有的资源,女主角带人去偷电池和代号为"95-DY42"的物品。结果同伴被杀,女主角被“狗”一路追杀,剧情遂切换成机器人版的《异形》,特别是当“狗”前爪的武器变成尖刀的时候……好不容易杀掉追她的“狗”,女主角脸部、颈部却被“狗”濒死前打上追踪器,更多的“狗”闻讯而来。
最后的镜头,散落一地的"95-DY42"却只是一箱玩偶“猴”。
第6集,《黑色博物馆》:回归《黑镜》的“主旋律”,本季前五集的杀人道具作为彩蛋一一登场,还有第二季“白熊正义公园”的女主,第三季“全网公敌”的杀人蜜蜂。本集剧情的核心是关于意识转移,从生理感觉转移到意识的数字化抽取,再到完整的意识上传……当所有这些技术都被利欲熏心的商业行为扭曲时,一个被枉死的“杀人狂”的女儿便开始策划真正的谋杀……
正如《黑镜》之父查理·布鲁克说过的,“如果科技是一粒毒品——确实感觉像毒品——那么它的副作用是到底什么呢?”熄灭的屏幕之下,科技另一面的愉悦和不安,是出道于2011年的《黑镜》所要讨论的永恒话题。
2015年,Netflix的算法断定这里的“愉悦”和“不安”因素会使该剧大受欢迎的市场继续扩大,于是重金从英国第四频道手中抢来《黑镜》,利用人们对于科技黑暗面的恐惧大肆赚钱。
当然,如今的Netflix赚钱,更离不开它对技术因素的正面使用,特别是大数据和机器学习。比如,它如何通过视频的封面图像来打造符合用户兴趣的个性化内容?它如何用机器学习从成千上万的视频库中筛选出用户想看的四、五十部电影?当你按下播放按钮的时候,Netflix的后台具体都在做些什么?
针对这里的问题,营长专门扒来一篇原雅虎架构师Todd Hoff所写的科普文——“Netflix: What Happens When You Press Play?” 以从Netflix的完整技术结构上来了解机器学习的真正作用,这是营长今天在追剧上面的最大收获。
接下来,咱们来看Netflix的具体技术:
翻译 | shawn
编辑 | Donna,波波
在Netflix上看视频似乎很简单。很多人认为Netflix用亚马逊云服务(AWS)来提供视频。但事实是,Netflix采用的方法要复杂的多。
我们首先来看看Netflix 2017年的统计数据,非常惊人!
Netflix拥有1.1亿名用户。
Netflix为200多个国家提供服务。
Netflix每季度的营收可达近30亿美元。
Netflix每季度新注册的用户超过500万名。
Netflix每周播放超过10亿小时的视频。作为对比,YouTube每天播放10亿小时的视频,Facebook每天播放1.1亿小时的视频。
Netflix 2017年单日播放的视频长度达2.5亿小时。
在美国Netflix占据逾37%的网络流量高峰。
Netflix 2018年计划在新内容创造上投入70亿美元。
从这些数据中,我们可以看到什么?
非常肯定的是,Netflix家大业大,在全球拥有大量用户。它的视频播放量多,钱多。
值得注意的是,Netflix是一家基于用户订阅的视频网站。用户每月向Netflix支付一定的订阅费,并且随时可以取消订阅。当用户在Netflix上看视频时,Netflix必须让他们满意。不满意的用户可以取消订阅。
深入探究,我们发现Netflix将沟通作为最重要的企业文化,他们甚至愿意公开他们的架构。在过去几年间,Netflix就其内部运作方式作了很多演讲报告,写了数百篇文章,给整个行业带来了进步。
另一个原因是Netflix本身就很让人着迷。大部分人或多或少都使用过Netflix。有谁不想揭开帷幕,看看Netflix是怎么运作的呢?
Netflix 使用的两种云服务:AWS和Open Connect。
Netflix是如何做到让用户满意的?
靠的当然是云服务。
Netflix使用了两种不同的云服务:AWS和Open Connect。这两种云服务无缝协作,为用户提供无穷无尽的优质视频。
Netflix的三个组成部分:客户端、后端和内容分发网络(CDN)。
您可以将Netflix想为三个组成部分:客户端、后端和内容分发网络(CDN)。
客户端是指任何设备上用于浏览和播放Netflix视频的用户界面。它可以是iPhone的应用程序,用桌面电脑打开的网站,也可以是智能电视上的应用程序。Netflix可以控制每台设备上的每个客户端。
当按下“播放”按钮前发生的一切都在后端进行,例如:准备所有新上传的视频,处理来自于应用程序、网站、电视和其他设备的请求。
后端的运作则基于AWS。当按下“播放”按钮后发生的一切由Open Connect处理。Open Connect是Netflix定制的全球内容分发网络(CDN)。当你按下“播放”按钮时,Open Connect就会向您传送视频。
有趣的是,在Netflix,他们说的不是“点击视频上的播放按钮”,而是“点击视频标题上的开始按钮”。
通过控制这三部分——客户端、后端和CDN,Netflix实现了完全的垂直整合。
Netflix自始至终控制着用户的视频观看体验,这就是为什么你在世界上的任何地方点击“播放”按钮就可以观看Netflix视频。有了Netflix,您可以在任何时候观看您想看的内容。
接下来让我们看看Netflix是如何实现这一切的。
Netflix从2008年开始转向AWS
Netflix成立于1998年,起初他们通过美国联合包裹服务公司(UPS)租赁DVD。后来,Netflix看到了流媒体点播的未来。
2007年,Netflix推出了流媒体点播服务,用户可以通过个人电脑、各种平台上的Netflix软件在Netflix网站上观看电视剧和电影。
当时,流媒体点播服务未来如何,谁都不确定。但是,Netflix成功了。Netflix进入的时间并不早,一直等到2007年,因特网已经足够快速和便宜,可以为流媒体服务提供支持。同时,人们可以以更加容易、更加廉价的方式在任何时间任何地点传输视频。
Netflix一开始就运营自己的数据中心
2007年亚马逊的弹性计算云(EC2)才刚开始起步,与此同时,Netflix已经开始提供流媒体服务。就当时而言,使用EC2提供这项服务是不现实的。
于是,Netflix建造了两个相邻的数据中心。它们发现建造一个数据中心是一项很大的工程,订购设备需要花费很长一段时间,安装和调试所有设备也要花很长时间。等到一切工作都完成时,Netflix的能力也用完了,然后又得重新开始上述工作。
由于设备的交付时间过长,Netflix不得不采取所谓的垂直伸缩(vertical scaling)策略。他们开发出了可以在大型计算机上运行的大程序。这种方法叫作“开发超大程序”(building a monolith),一个程序可以完成所有任务。
这时,问题来了。Netflix的成长速度非常快,这便无法保证这个超大程序的可靠性。
一次服务中断导致Netflix转向AWS
2008年8月,由于数据库出现腐败问题,Netflix有三天无法递送DVD。
Netflix发现了自己的问题,他们不擅长建造数据中心。他们只能将视频递送给用户。对Netflix而言,它真正的竞争优势是递送视频,而不是建造数据中心。
于是,Netflix决定使用AWS。当时AWS才刚起步,选择AWS是一个大胆的决策。
Netflix之所以选择AWS,是因为它想使用一种更加可靠的基础架构。Netflix希望清除其系统中的所有故障点。AWS可以提供高度可靠的数据库、存储和多余的数据中心。Netflix需要云计算,这样它就不必再开发不可靠的超大程序。而且,Netflix还希望在不用自己建造数据中心的情况下向全世界的用户提供服务。
Netflix选择AWS的另一个原因是AWS可以为Netflix完成所有无差别的繁重工作。无差别的繁重工作是指那些必须完成的,但对提供优质视频观看体验的核心业务没有任何帮助的工作。有了AWS,Netflix就可以专注在提供商业价值上。
Netflix从使用自己的数据中心转为使用AWS共花了八年多。在这期间,Netflix的用户增加了八倍。现在,Netflix使用的EC2 instance 达数十万之多。
Netflix使用AWS更可靠
Netflix在使用AWS时也不是没遇到过故障,但是总体而言,Netflix的服务比之前要可靠的多。
你再也不会经常看到这样的牢骚:

我的Netflix用不了了,打电话叫警察!!!
或者:

Netflix出故障的时候我才意识到自己对它的依赖有多深。现在我正穿着无敌浩克的衣服在浴缸里发抖,引用《老友记》里面的台词。
Netflix现在已经变得非常可靠。为了让自己的服务更加可靠,Netflix采取了许多措施。比如:Netflix以三个AWS服务区为中心提供视频服务:一个在北弗吉尼亚州,一个在俄勒冈州波特兰市,一个在爱尔兰都柏林。在每个服务区内,Netflix会划分三个不同的可用区(availability zone)。
Netflix曾表示它不计划增加新的服务区。因为这样做不仅非常昂贵而且十分复杂。大多数公司只有一个AWS服务区,拥有两个或三个的非常少见。
拥有三个AWS服务区的好处是,如果其中一个服务区出现故障的话,其他服务区可以代替这个服务区处理该区域的用户请求。当某个服务区出现故障时,Netflix将这种情况称为“疏散服务区”。
举个例子,假设您在英国伦敦观看新一集的《纸牌屋》,您的Netflix设备很可能连接的是都柏林服务区,因为都柏林离伦敦最近。
如果整个都柏林服务区出现故障,会发生什么?Netflix会中断服务?当然不会!
Netflix在检测完故障后会将您的设备连接至弗吉尼亚服务区。您的设备会向弗吉尼亚发送请求,而不是都柏林。您可能甚至不会意识到有发生故障。
AWS服务区多久会发生一次故障?每月一次。事实上,并不是每个服务区每月都会发生故障。Netflix每月进行一次故障检测。它每月会故意让某一服务区发生故障,以确保系统能处理地区级别的故障。Netflix在6分钟之内就可以完成对一个故障服务区的疏散。
Netflix将这称为“全球服务模型”。任何服务区可以为任何用户提供服务,非常神奇。然而做到这一点并不简单。AWS无法处理服务区故障,也无法为多个服务区之外的用户提供服务。Netflix必须靠自己解决这些问题。在研究如何构建使用多个服务区的可靠系统上,Netflix是当之无愧的先驱。据我所知,还没有什么别的公司愿意像Netflix这样费劲心思提高服务的可靠性。
拥有这三个服务区还有一个好处,Netflix可以在全球范围内提供服务。Netflix曾做过一些测试,他们发现:在世界上任何地方使用Netflix应用程序,都可以从这三个服务区获得快速的服务。
Netflix使用AWS更省钱
很多人可能会感到意外,实际上Netflix使用AWS会更省钱。相比使用Netflix的旧数据中心,AWS云服务每点播一次的成本微乎其微。
为什么会这样?因为云服务的弹性。
Netflix可以在需要的时候增加服务器,也可以在不需要的时候归还服务器,不会多余很多只用于处理峰值负荷的计算机。因此,它只需要为有用到的服务器支付费用。
按下播放按钮前,AWS会完成哪些工作?
所有不涉及视频提供的工作都是由AWS负责处理的。它的工作包括:可扩展计算、可扩展存储、商业逻辑、可扩展分布式数据库、大数据处理和分析、建议、自动译码等数百种其他工作。
可扩展计算和可扩展存储
可扩展计算是EC2,可扩展存储是S3。这两种功能我们很熟悉。用户的Netflix设备,例如iPhone、智能电视、Xbox、安卓手机、平板电脑等,会向在EC2上运作的Netflix服务端发送请求。
为了查看可观看的视频列表,你的Netflix设备会向EC2上的计算机发送请求,以获取列表。
如果想要查找关于某一视频的更多信息,你的Netflix设备会向EC2上的计算机发送请求,以获取详细信息。
这种服务就像是书本上介绍的其他云服务一样。
可扩展分布式数据库
Netflix使用DynamoDB和Cassandra作为其分布式数据库。
数据库——数据库可以存储数据。用户的个人资料信息、账单信息、所有观看过的电影等信息都储存在数据库中。
分布式——分布式是指数据库在很多计算机上运行,而不是只在一台大计算机上运行。用户的数据被复制保存在多台计算机上,如果一台或两台存储数据的计算机发生故障,用户的数据仍是安全的。事实上,用户的数据被复制保存在三个服务区中。这样,如果一个服务区发生故障,新的服务区仍然可以使用用户的数据。
可扩展——可扩展意味着当你想输入多少数据,数据库就可以处理多少数据。这是分布式数据库的一大优势。如果需要处理更多的数据,Netflix可以按照需求增加更多的计算机。
大数据处理和分析
大数据就是指有很多数据。Netflix收集很多信息,例如:用户看了哪些内容,用户观看视频时所处的位置,哪些视频用户在观看后决定不再继续观看,每个视频的观看次数等。
将所有数据转化为标准格式的过程叫做 “数据处理”。
研究数据的意义的过程叫做“分析”。分析数据的目的是为了回答特定的问题。
Netflix为您提供个性化的视频
下面这个例子很好地说明了:Netflix如何通过数据分析引诱用户观看更多视频。
当你在Netflix上寻找要看的视频时,您是否注意到每个视频都匹配有一个图像?这个图像叫做“封面图像”(header image)。
封面图像的目的是激发用户观看某一视频的兴趣。封面图像越引人注意,用户观看某一视频的可能性就越大。用户观看的视频数越多,他们取消订阅Netflix的可能性就越小。
下面是《怪奇物语》(Stranger Things)的几张不同的封面图像:

有一件事可能会让您会感到惊奇:每个视频的封面图像都是专门为你定制的。每个人看到的封面图像都是不同的。
但是,用户过去看到的都是相同的封面图像。这背后的原理是什么?Netflix会向用户随机展示从一组图像(比如上文中《怪奇物语》的封面图像)中抽取的一张图像,然后记下视频观看的次数,同时记录用户选择观看视频时系统为该视频匹配的是哪一张图像。
拿《怪奇物语》作为例子,当系统向用户展示最中间的封面图像时,《怪奇物语》的观看次数为1000次。而展示其他图像时,《怪奇物语》的观看次数只有一次。
由于这张主角集体照最能吸引用户观看视频,Netflix会将这张照片一直作为《怪奇物语》的封面图像。
这叫做数据驱动。众所周知,Netflix是一家数据驱动型公司。它收集数据,在本例中为与每张图像有关的观看次数,然后通过分析数据做出最佳决策,在本例中为选择哪张封面图像。
所以,使用更多数据,通过学习数据来解决问题才是未来。
用户会被相同的封面图像吸引吗?可能不会。大家的品位不同,偏好也不同。
Netflix也知道这一点。这就是为什么Netflix现在向用户展示的所有图像都是经过个性化定制的。
Netflix试图挑选出能凸显出视频中用户最感兴趣的内容的封面图像。它是怎么做到的?
记住,Netflix会记录用户在其网站上的一切操作,了解最喜欢哪种类型的电影,最喜欢哪些演员……
假如Netflix向你推荐的电影是《心灵捕手》(Good Will Hunting),它必须选择一张向你展示的图像。目的是让你通过这张图像了解你可能会感兴趣的电影。
如果你喜欢喜剧,Netflix会向你展示一张凸显罗宾·威廉姆斯(Robin Williams)的图像。如果你喜欢看爱情片,Netflix会向你展示一张马特·达蒙(Matt Damon)和蜜妮·卓芙(Minnie Driver)亲吻的图像。

通过显示出罗宾•威廉姆斯,Netflix让你知道这个电影可能很幽默。因为Netflix知道你喜欢喜剧,并且这个视频符合你的口味。
马特•达蒙和蜜妮•卓芙的图像传递出截然不同的信息。如果你喜欢的是喜剧,您看到这张图像后可能略过这个视频。
封面图像可以给出明显的个性化信号,告诉浏览户这部电影讲的是什么。
下面是另一个例子:《低俗小说》(Pulp Fiction)

如果你看过很多乌玛·瑟曼(Uma Thurman)主演的电影,你就很可能会看到凸显乌玛•瑟曼的封面图像。如果你看过很多约翰·特拉沃尔塔(John Travolta)主演的电影,你就很可能会看到凸显约翰•特拉沃尔塔的图像。
虽然Netflix在选择封面图像时会参考您的兴趣,但是它不会向你展示一张噱头性图像。
因为,Netflix并不是按照用户观看的视频数收费的。Netflix尽可能避免让用户感到后悔,它希望用户观看视频后感到快乐,因此会挑选最适合用户的封面图像。
这只是Netflix如何利用数据分析的一个小例子。事实上,Netflix将这种策略应用到了方方面面。
使用机器学习推荐视频
Netflix拥有成千上万个视频,但是它通常只会向用户推荐40至50个视频。
它是如何决定的呢?使用机器学习。
这就是我们所说的大数据处理和分析程序。Netflix通过研究数据来预测用户会喜欢的视频。事实上,你在Netflix上看到的一切内容都是Netflix使用机器学习为你精心挑选的。
下面我们将探讨Netflix是如何处理视频的。
从源媒体转码为您看到的视频
在你观看视频前,Netflix必须将视频转换为最适合你使用的设备播放的格式。这个过程叫做“转码或译码”。
转码是将视频文件从一种格式转换为另一种格式,让视频可以在不同平台和设备上正常播放。
Netflix在拥有30万个CPU的AWS上一次性转码了它的所有视频。这个AWS比大多数超级电脑还要大。
源媒体的来源
Netflix将影视制作公司和工作室制作的视频称为“源视频”。Netflix会把新视频会交给内容运营团队进行处理。
高分辨率格式的视频通常可达兆兆字节(TB)级别。1 TB 相当于60座埃菲尔铁塔那么高的纸堆。
在用户观看视频前,Netflix会使用一个严格的程序分多个步骤处理视频。

验证视频
Netflix首先要做的是花很多时间验证视频。它会寻找由于先前转码操作或数据传输问题造成的数字失真(digital artifacts)、颜色变化或帧丢失。如果发现任何问题,Netflix就会拒绝接受该视频。
导入媒体管道
视频经过验证后会被导入到一个处理管道中,Netflix将其称为 “媒体管道”。媒体管道就是处理视频的一系列步骤,其作用是确保视频可以使用,就像是工厂里的装配线在生成每个视频的过程中,视频会经过70多个不同的软件的处理。
一次性处理一个TB级别的视频文件并不可行,因此管道的第一个步骤是将视频分解为很多小段。然后管道会对小段视频进行平行译码。平行就是指同时处理所有小段视频。
下面让我们通过一个例子说明这个平行译码过程。
假设您要给100只脏兮兮的狗洗澡。是一只一只地洗快呢?还是雇100名清洗工同时洗100只狗快?
当时是后者。这就是平行操作。
这就是为什么Netflix在EC2上使用这么多服务器的原因。Netflix需要用大量的处理器同时处理这些巨大的视频文件。Netflix表示,对一个源媒体文件进行译码再将其推送到CDN中只需要30分钟。
这些小段视频经过译码后会接受验证,以确保操作中没有引入新的问题。然后将这些小段视频重新组合为一个文件,最后再进行验证。
最终得出的一堆文件。
因为Netflix的最终目标是支持所有联网设备,所以译码过程会生成很多文件。
2007年,Netflix开始在微软的Windows平台上传输视频。后来出现了更多设备——Roku、 LG、三星蓝光(Samsung Blu-ray)、 Apple Mac、Xbox 360、 LG DTV、 Sony PS3、任天堂 Wii、Apple iPad、 Apple iPhone、 Apple TV、 安卓、Kindle Fire和 Comcast X1。
Netflix现在共支持2200种不同的设备。它为每种设备都配置了播放效果最好的视频格式。如果你在iPhone上观看Netflix视频,你看到的视频采用的是在IPhone上播放效果最好的格式。
Netflix将视频的各种格式称为“译码文件”。
Netflix还提供根据不同网络速度优化得出的文件。如果你用高速网络观看视频,你将看到比低速网络下更高清的视频。Netflix还提供不同音频格式的文件。音频被译码为不同质量和不同语言的文件。有些文件还包含字幕。一个视频文件可能匹配有多种语言的字幕。
每段视频都有很多不同的观看选项。用户看的是什么样的视频取决于用户的设备、网络质量、Netflix计划和选择的语言。
那么,Netflix拥有多少文件?
拿《王冠》(The Crown)来说,Netflix就保存了大约1200个文件。《怪奇物语》第二季的文件甚至更多。这一季共有9集,每一集都是8K分辨率的视频。源媒体文件是TB大小的数据。译码一季的视频就需要190000 个CPU花费数小时的时间。最终得到了 9570个视频、音频和文本文件!
接下来让我们看看Netflix是如何播放所有视频的。
三种不同的视频传输策略
Netflix尝试使用过三种不同的视频传输策略:自家的小型CDN;第三方CDN;Open Connect。
CDN是内容分发网络的简称。Netflix的内容就是上文讨论的视频文件。分发是指从数据中心复制视频文件,通过网络将文件传输到世界各地的计算机中。
对于Netflix而言,储存视频文件的数据中心就是S3。
为什么要构建CDN?
CDN的原理很简单:通过在世界各地分布计算机,将视频储存在尽可能离用户近的地方。当用户想观看某一视频时,CDN会找到离用户最近的计算机,这台计算机就会将储存的视频传输给该用户。
CDN最大的优势是速度和可靠性。
假设您在伦敦观看某一视频,您接收的视频传输自俄勒冈州波特兰市。这个视频流必须穿过很多网络,包括海底电缆,因此视频连接不仅慢而且不可靠。
通过将视频存储在离用户尽可能近的位置,用户就会获得非常快速且可靠的视频观看体验。
储存视频内容的计算机所在的位置叫做PoP(接入点)。PoP是一个提供网络接入服务的实际位置。它配置有服务器、路由器和其他电信设备。
第一代CDN太小
2007年,Netflix推出了新的流媒体服务,它在50个国家拥有3600名用户。这些用户每月共观看超过10亿小时的视频,Netflix每秒可传输数TB的内容。
为了支持流媒体服务,Netflix在美国的5个地方建立了简单的CDN。只是当时Netflix的视频量还比较小,每个CDN都存储有所有内容。
而第二代CDN又太大
所以,2009年,Netflix决定使用第三方CDN。当时,第三方CDN的价格正在下降。
对Netflix而言,使用第三方CDN合情合理。当使用现有的CDN服务就可以即刻覆盖全球时,为什么要耗时耗力地自己建造CDN呢?
Netflix和Akamai、 Limelight和Level 3等公司签订合同,接受这些公司提供的CDN服务。使用第三方CDN并没有什么问题,事实上,几乎所有公司使用的都是第三方CDN。例如,美国国家橄榄球联盟(NFL)使用Akamai的CDN直播橄榄球比赛。
由于不用自己建立CDN,Netflix可以将更多时间花在其他更重要的项目上。
在开发更加智能的客户端上,Netflix投入大量的时间和精力。为了适应不断变化的网络条件,Netflix开发了许多算法。在出现网络错误、网络超载和服务器超载等情形时,Netflix仍希望为用户提供尽可能好的观看体验。Netflix开发的其中一种算法可以让用户转接到一个不同的视频源,例如另一个CDN或服务器,以获得更好的体验。
与此同时,Netflix还花费了大量精力改进所有的AWS服务。Netflix将AWS服务称为“控制面”。控制面是一个电信术语,它定义的是系统中控制一切活动的部分。在人体中,大脑就是控制面,它控制体内的一切活动。
后来,Netflix认为建造自己的CDN可以更好地改进服务。
Open Connect是正解
2011年,Netflix意识到自己需要建造一个专用的CDN解决方案来获得最大化的网络效率。对Netflix而言,视频分发是自己的核心竞争力,并且可能成为巨大的竞争优势。
因此,Netflix开始开发Open Connect,这是Netflix按照自己的目的建造的CDN。2012年Open Connect 正式发布。
Open Connect为Netflix带来了很多优势:
更加廉价。第三方CDN非常昂贵。自己建造CDN可以省下很大一笔钱。
质量更好。通过控制整个视频分发渠道——转码、CDN和客户端,Netflix证明了它可以为用户提供更好的视频观看体验。
可扩展性更好。Netflix的目标是在全世界范围内提供服务。为了实现这一目标,并提供优质的视频观看体验,Netflix必须构建自己的系统。
第三方CDN必须确保用户可以在世界上的任何地方访问任何内容。Netflix的工作要轻松的多。
Netflix非常了解用户,因为用户必须订阅才能享受服务。它知道用户喜欢看什么,以及喜欢在什么时间观看视频。Netflix非常清楚自己需要提供哪些视频,它只需提供大的视频流,这使得它可以做出很多明智的优化决策,其他CDN是无法做出这样的决策的。
在这些知识的帮助下,Netflix建造了一个高性能的CDN。接下来我们会深入探讨Open Connect的工作原理。
Open Connect设备
还记得我们在上文中说过CDN在全世界分布有很多计算机吗?
Netflix自己开发了用于存储视频的计算机系统。Netflix将其称为Open Connect设备(OCA)。
下图是早期安装的OCA:

从上图中可以看到很多OCA。这些OCA被分成了多个服务器群。
每个OCA都是一个快速服务器,配置有大量用于存储视频的硬盘或闪存,并且针对传输大型文件专门进行了优化。
下图是其中一个OCA服务器:

Netflix根据不同的用途制造了几种不同的OCA。其中大型的OCA可以储存Netflix的全部视频,小型OCA只可以储存一小部分视频。在每天的高峰时刻,小型的OCA会利用一个程序存满视频,Netflix将这个程序称为主动缓存(Proactive Caching)。
从硬件的角度看,OCA并没有什么特别之处。它们基于商用的PC组件,装配在由不同供应商生产的定制外壳中。
为什么Netflix所有的计算机都是红色的?为的是匹配Netflix 标志的颜色。
从软件的角度看,OCA使用的是FreeBSD操作系统和NGINX网页服务器。每个OCA都配有一个网页服务器。视频传输使用的就是NGINX。网站OCA的数量取决于Netflix希望网站可以实现多大程度的可靠性,Netflix网站传输的流量(带宽)大小以及网站允许传输的流量大小。
当用户按下播放按钮时,用户所观看的视频传输自您附近的某一台OCA,如上图所示。
为了向用户提供最好的视频观看体验,Netflix真正想做的是在你的房子里存储视频。但是现在来说这并不实际。下一种最佳途径是在离您房子尽可能近的位置安装一个小型Netflix设备。
Netflix在哪里安装Open Connect设备(OCA)?
Netflix利用全世界1000多个地方的数千台服务器传输海量的视频数据。下图是Netflix服务器的分布位置:

YouTube和亚马逊等其他视频服务商利用自己的基础网络向用户提供视频。为了做到这一点,这些公司建造了属于自己的全球网络。这样做非常昂贵且复杂。
Netflix用截然不同的方法来建造自己的CDN。它不运营网络,也不再运营自己的数据中心。网络服务提供商(ISP)同意在他们的数据中心安装OCA。Netflix免费向ISP提供OCA,以接入后者的网络。另外,Netflix还将OCA安装在互联网交换中心(IXP)或靠近IXP的位置。
通过实施这个策略,Netflix不必运营自己的数据中心,但是却可以获得数据中心带来的所有好处。
借助ISP建造CDN。
ISP是指网络提供商。也就是向您提供网络的人。可能是Verizon、Comcast等其他网络运营商。
重点是ISP在世界各地提供服务,他们离用户更近。通过将OCA安装在ISP的数据中心,Netflix也可以在全球范围内提供服务,离自己的用户更近。
利用IXP建造CDN
互联网交换中心是指让ISP和CDN的网络交换数据的数据中心。它就像是在派对上与朋友交换圣诞节礼物。如果所有人都在同一个地点,交换起礼物来就更加容易。如果所有相关设备都在同一位置,交换起数据来就更容易。
IXP分布在全球各地:

TeleGeography的互联网交换中心地图
下图为伦敦互联网交换中心:

伦敦互联网交换中心 (LINX)
沿着这些黄色的光纤,您会在荷兰阿姆斯特丹的AMS-IX 互联网交换中心看到下图装置:

上图中的每条线将一个网络与另一个网络连接在一起。不同的网络就是这样互相交换数据的。
IXP就像是一个高速公路交汇点,连接不同网络的是光缆:

对于Netflix而言,这又是一大优势。IXP分布在全世界各地。通过将自己的OCA安装在IXP,Netflix就不必运营自己的数据中心了。
每天视频都被主动缓存在OCA中
Netflix将所有的视频储存在S3中。Netflix将所有这些提供视频的计算机分布在全世界各地,但是缺少一样东西:视频!
Netflix使用一个程序将视频复制到OCA中,它将这个程序称为“主动缓存”。
贮存处是什么?
贮存处就是一个储存东西的地方,尤其是指用于储存弹药、食物和财宝的底下洞穴。
你知道松鼠是如何埋藏冬季吃的坚果的吧?

它们埋藏坚果的地方就是贮存处。到了冬季,松鼠就会找到埋有坚果的贮存处。北极探险者会派遣小队伍走在前面,沿路贮存食物、燃料和其他供给品。跟在后面的大队伍会在每个贮存处停下来补充补给。松鼠和北极探险者都是主动的;他们都会为日后提前做好准备。
OCA就是一个视频缓存设备,它存储的是用户最可能观看的视频。
Netflix通过预测用户想看哪些视频,再用OCA存储这些视频。Netflix知道世界各地的用户喜欢看什么视频,以及喜欢在什么时候看,它在这方面的准确度很高。
还记得上文说过Netflix是一家数据驱动型公司吗?
Netflix使用流行度数据预测各个位置的用户明天可能会想看哪些视频。在这里,位置是指安装在ISP或IXP中的OCA群。
Netflix会将预测的视频复制到每个位置上的一个或多个OCA中。这个过程叫做“预置”(prepositioning)。在用户发出请求前,视频就已经缓存在OCA中。这样做可以为用户提供优质的服务。他们想看的视频储存在离他们很近的位置,可以很快地传输给他们。
Netflix运营着一种称为“分级缓存系统”的系统。

我们前文提到的小型OCA放在ISP和IXP中。这些OCA因为太小无法储存Netflix的所有视频。一些地点的OCA储存有Netflix的大部分视频。有些地点的OCA储存有Netflix的全部视频。这些OCA从S3获取视频。
每天晚上,每个OCA都会向AWS的服务器询问它应该储存哪些视频。AWS上的服务器会根据我们之前讨论的预测,向OCA发送一份视频清单,列明每个OCA应该储存的视频。
各OCA负责确保其缓存有清单上列出的所有视频。如果相同位置的OCA未储存它本应该有的一个视频,它就会从当地的OCA中复制这个视频。否则它就会找出附近缓存有该视频的OCA,并复制该视频。
由于Netflix预测的是明天会流行的视频,因此OCA有一天的时间来获取服务器要求其缓存的视频。这意味着OCA可以在安静的非高峰时刻复制视频,这样做可以在很大程度上减少ISP带宽的使用。
在Open Connect中永远不会出现缓存缺失(cache miss)的情况。缓存缺失是指请求从OCA获取某一视频,OCA中却没有这个视频。
缓存缺失在其他CDN中常常发生,因为到处复制视频的成本太高。由于Netflix知道它必须缓存的所有视频,因此它总是知道每个视频的存放位置。如果某个小型OCA没有某一视频,那么某个大型OCA肯定缓存有这个视频。
为什么Netflix不将所有的视频都复制到世界上的每个OCA中?它的视频量太过庞大,不可能储存在所有位置。2013年,Netflix的视频达到了3×10^15字节。我不知道netflix现在所有的视频有多大,我认为变大了非常多。
这就是为什么Netflix要利用数据来预测用户想看什么视频,选择在各OCA上缓存哪些视频。
举个例子,《纸牌屋》是一部非常火的剧。哪些OCA应该复制该剧呢?可能是每个位置的OCA,因为全世界的用户都想看《纸牌屋》。
如果某个视频不像《纸牌屋》那么广受欢迎呢?Netflix决定哪个位置的OCA应该复制这个视频。
在一个位置,像《纸牌屋》这样的大热剧会被复制到很多不同的OCA中。视频越受欢迎,复制它的服务器就越多。为什么?如果只有一个OCA复制有某一热门视频,将这个视频传送给众多用户会使服务器崩溃。正所谓众人拾柴火焰高。
当一个视频只被复制到一个OCA中时,Netflix不认为这个视频存在。Netflix希望能在世界上的任何地方同时播放相同的内容,只有当足够多的OCA复制有某一视频时,Netflix才认为这个视频存在并且可以提供给用户观看。
例如:2016年播出《超胆侠》第二季的时候,Netflix首次在所有国家在所有设备上同时一次性放出所有剧集。
连接OCA:ISP能从中得到什么好处?
为什么ISP会同意在他们的网络内安装OCA群?乍一看,ISP似乎很慷慨,但是实际上他们是为了自身的利益着想。
为了理解个中缘由,我们需要讨论一下网络的运作方式。我们之前说过通过因特网可以获取云服务。但是对Netflix来说却不是这样,至少在观看视频时不是这样。当使用Netflix应用程序时,应用程序会通过因特网向AWS发送请求。
因特网是网络的互联。ISP为其用户提供因特网服务。我从Comcast获得因特网服务。这意味着我的房子通过一条光缆连接Comcast的网络。Comcast的网络是他们的网络,不是因特网,因特网是别的东西。
举例来说,假如我想使用谷歌搜索,我在浏览器中输入一个问题然后点击回车。
我向谷歌发送的请求首先在Comcast的网络上传递,谷歌没有连接Comcast的网络。在某一点上,我的请求必须传递到谷歌的网络上。这就是因特网的作用。
因特网将Comcast的网络连接至谷歌的网络。路由协议(routing protocols)的作用像交通警察一样,指挥网络数据的传输方向。当我的问题被传递到因特网上时,就没Comcast的网络什么事了。不过问题也没在谷歌的网络中,它在所谓的因特网主干网(internet backbone)上。
很多选择互通的私有网络交织在一起就形成了因特网。我们之前讨论的IXP就是网络相互连接的一种方式。
下图为美国长距离光纤网络的分布地图:

Netflix的Open Connect将它的OCA群放在了ISP的网络中。这意味着当我观看Netflix视频时,我的设备会通过Comcast的网络向OCA 发送请求。视频的传输完全是在Comcast的网络中进行,没因特网什么事。
缩减视频传输的过程的关键在于尽可能靠近用户。如果实现了这一点,就不会用到因特网主干网。使用当地的一部分网络就可以满足用户的请求。
为什么这是一件好事呢?前文说过,Netflix占据美国因特网逾37%的流量。如果ISP不合作的话,Netflix会占用更多的流量。因特网无法处理所有视频数据。ISP不得不增加更多的网络容量,这样做的话成本非常昂贵。
现在超过100%的Netflix内容都是从ISP网络中获取的。这降低了ISP缓解因特网拥塞的成本。同时,Netflix的用户可以体验到高质量的视频观看体验。每个人的网络表现都会得到改善。
对Netflix和ISP而言,这么做是双赢的。
Open Connect既可靠又灵活
之前我们讨论过Netflix通过以三个AWS服务区为中心提供服务可以提供其系统的可靠性。Open Connect的架构也可以实现相同的目标。
OCA是独立运作的,这一点也许并不显而易见。OCA相当于是自给自足的视频服务机群。当其他OCA出现故障时,向用户传输视频的OCA并不会受到影响。
当一个OCA出现故障时会发生什么?用户正在使用的Netflix客户端会立即转换到另一个OCA,重新开始传输视频。
如果某一位置有太多人使用同一OCA会发生什么?Netflix的客户端会寻找一个负载程度较轻的OCA使用。
如果用户用于传输视频的网络出现过载会发生什么?同样,Netflix的客户端会在负载程度较轻的网络上寻找另一个OCA。
所以,Open Connect是一个既可靠又灵活的系统。
Netflix如何控制客户端
Netflix可以从容地处理故障,因为它可以控制每台运行Netflix服务的设备上的客户端。
Netflix的安卓和iOS应用程序是自己开发的,它能控制这两大平台上的客户端不足为奇。但是在智能电视这样的平台上,Netflix并没有开发自己的客户端,它仍然可以实现控制,因为它可以控制软件开发工具包(SDK)。
SDK是一系列用于开发应用程序的软件开发工具。每个Netflix应用程序都会向AWS发送请求,使用SDK播放视频。通过控制SDK,Netflix可以同时适应低速网络、故障OCA及其他可能出现的问题。
总结:当你按下播放按钮后Netflix都在背后做了啥
一路下来,我们学到了很多东西,下面是对上述内容的一个总结
Netflix可以被划分为三部分:后端、客户端和CDN。
Netflix客户端发送的所有请求都是由AWS处理的。
所有视频都是传输自附近的Open Connect设备(OCA)。
Netflix以三个AWS服务器为中心提供服务,通常它可以在用户未发现的情况下处理故障。
Netflix将新视频内容转换为多种格式,这样系统就可以根据设备类型、网络质量、地理位置、用户的订阅计划选择观看效果最佳的格式。
每天Netflix都会预测各地点的成员会想看什么视频,然后根据这些预测在全世界通过Open Connect分发视频。
下图是Netflix描述其视频播放过程的说明图:
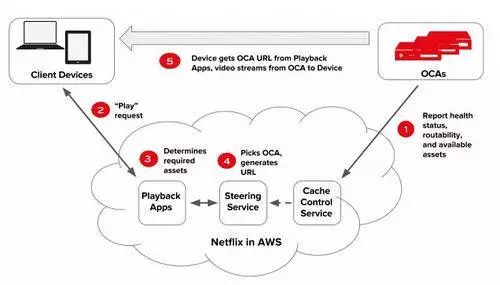
现在,让我们完成这幅图:
您用某种设备上的客户端选择观看某一视频,客户端向AWS上的Playback(回放)应用程序服务器发送播放请求,表明您想播放哪个视频。
我们之前曾讨论过这个问题,但是当你点击播放按钮后系统完成的大部分工作一定与授权有关。并不是世界上的所有地方都有观看的每个视频的许可。Netflix必须确定你是否拥有观看某一视频的有效许可。我们不会讨论其中的工作原理(这很无聊),但是要记住一个会有这个程序。Netflix之所以开始开发属于自己的内容,其中一个原因是为了避免授权问题。
考虑所有相关信息后,回放应用程序服务器会返回最多10个不同OCA服务器的URL。这些URL和你在网页浏览器上使用的URL属于同一类。Netflix利用从ISP获得的IP地址和信息,确定哪些OCA群最适合您使用。
通过测试连接每个OCA的网络的质量,客户端智能地选择使用哪个OCA。它会最先选择传输速度最快、最可靠的OCA。客户端在整个视频传输过程中都会持续运行这些测试操作。
客户端通过测试找出从OCA接收内容的最佳方式。
客户端连接OCA,开始向你的设备传输视频。
当观看视频时,你是否注意到画面的质量会发生变化?有时候画面看起来分辨率很低,有时候又会突然恢复到高清状态。这是因为客户端在适应网络的质量。如果网络质量下降,客户端会降低视频的质量。当视频的质量下降的太严重时,客户端会连接另一个OCA。
当您按下Netflix上的播放按钮后,Netflix会完成上述所有工作。谁会想到观看视频这么简单的事实际上这么复杂?
原文链接: http://highscalability.com/blog/2017/12/11/netflix-what-happens-when-you-press-play.html
原作者 | Todd Hoff
热文精选
不用数学也能讲清贝叶斯理论的马尔可夫链蒙特卡洛方法?这篇文章做到了
盘点深度学习一年来在文本、语音和视觉等方向的进展,看强化学习如何无往而不利
干货 | AI 工程师必读,从实践的角度解析一名合格的AI工程师是怎样炼成的
AI校招程序员最高薪酬曝光!腾讯80万年薪领跑,还送北京户口
算法还是算力?周志华微博引爆深度学习的“鸡生蛋,蛋生鸡”问题
智能推荐
什么是内部类?成员内部类、静态内部类、局部内部类和匿名内部类的区别及作用?_成员内部类和局部内部类的区别-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏42次。一、什么是内部类?or 内部类的概念内部类是定义在另一个类中的类;下面类TestB是类TestA的内部类。即内部类对象引用了实例化该内部对象的外围类对象。public class TestA{ class TestB {}}二、 为什么需要内部类?or 内部类有什么作用?1、 内部类方法可以访问该类定义所在的作用域中的数据,包括私有数据。2、内部类可以对同一个包中的其他类隐藏起来。3、 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。三、 内部类的分类成员内部_成员内部类和局部内部类的区别
分布式系统_分布式系统运维工具-程序员宅基地
文章浏览阅读118次。分布式系统要求拆分分布式思想的实质搭配要求分布式系统要求按照某些特定的规则将项目进行拆分。如果将一个项目的所有模板功能都写到一起,当某个模块出现问题时将直接导致整个服务器出现问题。拆分按照业务拆分为不同的服务器,有效的降低系统架构的耦合性在业务拆分的基础上可按照代码层级进行拆分(view、controller、service、pojo)分布式思想的实质分布式思想的实质是为了系统的..._分布式系统运维工具
用Exce分析l数据极简入门_exce l趋势分析数据量-程序员宅基地
文章浏览阅读174次。1.数据源准备2.数据处理step1:数据表处理应用函数:①VLOOKUP函数; ② CONCATENATE函数终表:step2:数据透视表统计分析(1) 透视表汇总不同渠道用户数, 金额(2)透视表汇总不同日期购买用户数,金额(3)透视表汇总不同用户购买订单数,金额step3:讲第二步结果可视化, 比如, 柱形图(1)不同渠道用户数, 金额(2)不同日期..._exce l趋势分析数据量
宁盾堡垒机双因素认证方案_horizon宁盾双因素配置-程序员宅基地
文章浏览阅读3.3k次。堡垒机可以为企业实现服务器、网络设备、数据库、安全设备等的集中管控和安全可靠运行,帮助IT运维人员提高工作效率。通俗来说,就是用来控制哪些人可以登录哪些资产(事先防范和事中控制),以及录像记录登录资产后做了什么事情(事后溯源)。由于堡垒机内部保存着企业所有的设备资产和权限关系,是企业内部信息安全的重要一环。但目前出现的以下问题产生了很大安全隐患:密码设置过于简单,容易被暴力破解;为方便记忆,设置统一的密码,一旦单点被破,极易引发全面危机。在单一的静态密码验证机制下,登录密码是堡垒机安全的唯一_horizon宁盾双因素配置
谷歌浏览器安装(Win、Linux、离线安装)_chrome linux debian离线安装依赖-程序员宅基地
文章浏览阅读7.7k次,点赞4次,收藏16次。Chrome作为一款挺不错的浏览器,其有着诸多的优良特性,并且支持跨平台。其支持(Windows、Linux、Mac OS X、BSD、Android),在绝大多数情况下,其的安装都很简单,但有时会由于网络原因,无法安装,所以在这里总结下Chrome的安装。Windows下的安装:在线安装:离线安装:Linux下的安装:在线安装:离线安装:..._chrome linux debian离线安装依赖
烤仔TVの尚书房 | 逃离北上广?不如押宝越南“北上广”-程序员宅基地
文章浏览阅读153次。中国发达城市榜单每天都在刷新,但无非是北上广轮流坐庄。北京拥有最顶尖的文化资源,上海是“摩登”的国际化大都市,广州是活力四射的千年商都。GDP和发展潜力是衡量城市的数字指...
随便推点
java spark的使用和配置_使用java调用spark注册进去的程序-程序员宅基地
文章浏览阅读3.3k次。前言spark在java使用比较少,多是scala的用法,我这里介绍一下我在项目中使用的代码配置详细算法的使用请点击我主页列表查看版本jar版本说明spark3.0.1scala2.12这个版本注意和spark版本对应,只是为了引jar包springboot版本2.3.2.RELEASEmaven<!-- spark --> <dependency> <gro_使用java调用spark注册进去的程序
汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用_uds协议栈 源代码-程序员宅基地
文章浏览阅读4.8k次。汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用,代码精简高效,大厂出品有量产保证。:139800617636213023darcy169_uds协议栈 源代码
AUTOSAR基础篇之OS(下)_autosar 定义了 5 种多核支持类型-程序员宅基地
文章浏览阅读4.6k次,点赞20次,收藏148次。AUTOSAR基础篇之OS(下)前言首先,请问大家几个小小的问题,你清楚:你知道多核OS在什么场景下使用吗?多核系统OS又是如何协同启动或者关闭的呢?AUTOSAR OS存在哪些功能安全等方面的要求呢?多核OS之间的启动关闭与单核相比又存在哪些异同呢?。。。。。。今天,我们来一起探索并回答这些问题。为了便于大家理解,以下是本文的主题大纲:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JCXrdI0k-1636287756923)(https://gite_autosar 定义了 5 种多核支持类型
VS报错无法打开自己写的头文件_vs2013打不开自己定义的头文件-程序员宅基地
文章浏览阅读2.2k次,点赞6次,收藏14次。原因:自己写的头文件没有被加入到方案的包含目录中去,无法被检索到,也就无法打开。将自己写的头文件都放入header files。然后在VS界面上,右键方案名,点击属性。将自己头文件夹的目录添加进去。_vs2013打不开自己定义的头文件
【Redis】Redis基础命令集详解_redis命令-程序员宅基地
文章浏览阅读3.3w次,点赞80次,收藏342次。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。当数据量很大时,count 的数量的指定可能会不起作用,Redis 会自动调整每次的遍历数目。_redis命令
URP渲染管线简介-程序员宅基地
文章浏览阅读449次,点赞3次,收藏3次。URP的设计目标是在保持高性能的同时,提供更多的渲染功能和自定义选项。与普通项目相比,会多出Presets文件夹,里面包含着一些设置,包括本色,声音,法线,贴图等设置。全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,主光源和附加光源在一次Pass中可以一起着色。URP:全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,一次Pass可以计算多个光源。可编程渲染管线:渲染策略是可以供程序员定制的,可以定制的有:光照计算和光源,深度测试,摄像机光照烘焙,后期处理策略等等。_urp渲染管线