最全NLP语料资源集合及其构建现状-程序员宅基地

作者刘焕勇,语言学硕士,目前就职于中国科学院软件研究所,主要从事信息抽取,知识图谱,情感分析, 社会计算等自然语言处理研发工作,兴趣包括:语言资源构建、信息抽取与知识图谱、舆情监测与社会计算。
本项目包含中文自然语言处理的语料集合,包括语义词、领域共时、历时语料库、评测语料库等。本项目简单谈谈自己对语言资源的感想以及目前自己进行语言资源构建的现状。
介绍
语言资源,本身是一个宽泛的概念,即语言+资源,语言指的是资源的限定域,资源=资+源,是资料的来源或者汇总,加在一起,也就形成了这样一种界定:任何语言单位形成的集合,都可以称为语言资源。语言资源是自然语言处理任务中的一个必不可少的组成部分,一方面语言资源是相关语言处理任务的支撑,为语言处理任务提供先验知识进行辅助,另一方面,语言处理任务也为语言资源提出了需求,并能够对语言资源的搭建、扩充起到技术性的支持作用。因此,随着自然语言处理技术的不断发展,自然语言处理需求在各个领域的不断扩张、应用,相关语言资源的构建占据了越来越为重要的地位。作者在硕士期间所在的研究机构为国家语言资源监测与研究平面媒体中心,深受导师所传授的语言资源观影响,毕业后在实际的学习、工作过程中,动手实践,形成了自己的一些浅薄的语言资源认识,现在写出来,供大家一起讨论,主要介绍一些自己对语言资源的搜索,搭建过程中的一些心得以及自己目前在语言资源建设上的一些工作。
语言资源的分类
介绍中说到,任何语言单位的集合都可以称为语言资源,比如我有一个个人的口头禅集合,这个就可以称为一个语言资源库,在你实际生活中进行言语活动时,你其实就在使用这个语言资源库。再比如说,一个班级中的学生名单,其实也可以当作是一种语言资源,这个语言资源在进行班级学生点名、考核的时候也大有帮助。当然,此处所讨论的语言资源是从自然语言处理应用的角度上出发的。总的来说,我把它归为以下两种类型:
1、领域语料库
领域语料库,是从语料的这个角度来讲的,这里的语料,界定成文本级别(以自然语句为基础级别形成的文本集合,即可以是句子、段落、篇章等)。领域语料库,可以根据不同的划分规则而形成不同的语料类别:
1)根据所属领域,可以进一步细化成不同领域的语料库。包括金融领域语料、医药领域语料、教育领域语料、文学领域语料等等。
2)根据所属目的,可以进一步细化为:评测语料(为自然语言处理技术pk而人工构造的一些评测语料,如ACE,MUC等国际评测中所出现的如semeval2014,snli等);工具语料(指供自然语言处理技术提供资源支撑的语料)
3)根据语料加工程度的不同,可进一步分为:熟语料(指在自然语言单位上添加人工的标签标注,如经过分词、词性标注、命名实体识别、依存句法标注形成的语料),生语料(指直接收集而未经加工形成的语言资源集,如常见的微博语料,新闻语料等)
4)根据语料语种的不同,可进一步分为:单语语料和多语语料,多语语料指的是平行语料,常见于机器翻译任务中的双语对齐语料(汉-阿平行语料库,汉-英平行语料库)等。
5)根据语料规模的不同,可以进一步分为:小型语料库,中型语料库,大型语料库。至于小型、中型、大型的界定,可根据实际领域语料的规模而动态调整。
2、领域词库
领域词库,指以句级以下语言单位形成的语言资源库,这个层级的语言单位可以是笔画、偏旁部首、字、词、短语等。同样的,领域词库也可以进一步细分。
1)领域特征词库。这里所说的领域特征词库,指的是与领域强相关,具有领域区别能力形成的词语集合,如体育领域中常见的“篮球”、“足球”等词,文学领域常见的“令狐冲”、“鲁迅”等词,又如敏感词库等,这些词常常可作为分类特征而存在。
2)语法语义词库。语义词库的侧重点在与语言的语法层面和语义层面:
语法词库:北大的语法信息词典,北大的实体概念词典、Hownet语义词典这三类词典,这几个语法词库,在对词的语法功能上都做了不同的工作,对词的内部结构信息进行了详细的标注,如北大的语法信息词典,以词类为划分标准讲汉语的常用词进行了划分,并对词性、搭配(前接成分和后接成分)进行了详细的标注;Hownet语义词典从义项的角度对词的义元进行了分解和注释。
语义词库:这类语义词,侧重点不在词语的内部语法结构,而在词语的整体语义上。这类词库,常见的词库有哈工大发布的同义词词林扩展版,这个词库将同义词按照语义的相近程度进行了不同层次的聚类,可以作为同义词扩展提供帮助。另一个是情感分析任务中常用的情感词典,这类词典主要公开的词典包括大连理工大学信息检索实验室公开的情感本体词库、hownet、香港中文大学、台湾清华大学公开的情感词库(具体包括情感词库、否定词库、强度词库)等。另外,工业界,有boson公开的微博情感词库(词的规模比较大,但标注信息不是很精准)。还有的,则是中文的反义词库等,这个可以参考我的github项目,里面对这些词库也有一些涉及。
语言资源的问题
语言资源的搭建,指的是语言资源的整个搭建过程。其实是要解决四个问题,一个是语言资源的收集问题;二是语言资源的融合标准化问题;三是语言资源的动态更新问题;四是语言资源的共享与联盟问题。下面就这四点展开阐述:
1、语言资源收集的问题。语言资源搜索过程中有三步走策略,在这个步骤完成之后,会得到一系列的词库。这些词库可能初期不会特别完善,往往还需要人工使用启发式规则进行人工去噪的工作。
2、语言资源的融合标准化问题。通过不同方式收集起来的语言资源,往往会存在一个格式不对称的问题,这有点像知识图谱中的知识融合问题。因此,为了解决这个问题,我们通常需要制定一个标准化的语言资源格式,例如,在构建情感词表的过程当中,有的情感词表没有强度标记,有的强度值范围不一样,有的情感词表的标记不一,这个时候往往需要标准化,给定一个标准化的样式,再将不同来源的情感词按照这个标记做相应的调整。我在实际的工作过程中,常常把这种问题类别成知识图谱构建过程中的schema搭建问题,信息抽取过程中的slot-definition问题。先把规范和标准搭好,再去统一标准化。
3、语言资源的动态更新问题。知识和信息的价值,在很大程度上都在于它的一种实时性,语言资源作为一种常识性知识库,能够保证自身的一种与时俱进,将能够最大限度地发挥自身的价值。而从实践的角度上来说,语言资源的动态更新,可以靠人工去维持,去动态及时更新,也可以建立一种动态监测和更新机制,让机器自动地去更新。这类其实可以参考知识图谱更新的相关工作。
4、语言资源的共享与联盟问题。语言资源是否共享,其实是一个与业务敏感以及开源意识想结合的一种决策,有的资源因为某种业务敏感或者开源意识不够open而无法共享,当然还有其他因素成分在,不过,语言资源最好是需要共享的,这样能够最大力度的发挥语言资源在各个领域的应用。语言资源的联盟问题,更像是对开源语言资源的一种链接与互联。这类问题是对当前的资源零散、碎片化问题的一个思考,前面也说到,目前情感分析的词表有很多个,语法和语义词库也有很多个,但每个人在构建时的出发点不同,构建者也分布在不同的高校或机构当中,这些资源虽然在个数上会有增长,但随着时间的推移,这种零散化的现象将会越来越严重。
语言资源的实践
本项目以采集公开的人民日报与参考消息为例进行历时的新闻采集为例, 公开网站中公开了1946-2003年的人民日报语料,1957-2002年的参考消息语料, 采集这种具有长远历史信息的语料对于历史人文研究以及语言演变有重大意义,本项目放在newspaper目录下。
运行方式: scrapy crawl travel
主要函数包括:
class TravelSpider(scrapy.Spider):
name = 'travel'
'''资讯采集主控函数'''
def start_requests(self):
Data = BuildData()
date_list = Data.create_dates()
for date in date_list:
print(date)
date_url = 'http://www.laoziliao.net/ckxx/%s'%date
param = {
'url': date_url, 'date': date}
yield scrapy.Request(url=date_url, meta=param, callback=self.get_urllist, dont_filter=True)
'''获取页面新闻列表'''
def get_urllist(self, response):
selector = etree.HTML(response.text)
date_url = response.meta['url']
urls = [i.split('#')[0] for i in selector.xpath('//ul/li/a/@href') if date_url in i]
for url in set(urls):
param = {
'url':url , 'date': response.meta['date']}
yield scrapy.Request(url=url, meta=param, callback=self.page_parser, dont_filter=True)
'''新闻字段内容解析'''
def page_parser(self, response):
selector = etree.HTML(response.text)
articles = selector.xpath('//div[@class="article"]')
titles = selector.xpath('//h2/text()')
contents = []
for article in articles:
content = article.xpath('string(.)')
contents.append(content)
papers = zip(titles, contents)
for i in papers:
item = TravelspiderItem()
item['url'] = response.meta['url']
item['date'] = response.meta['date']
item['title'] = i[0]
item['content'] = i[1]
yield item
return
语言资源构建现状
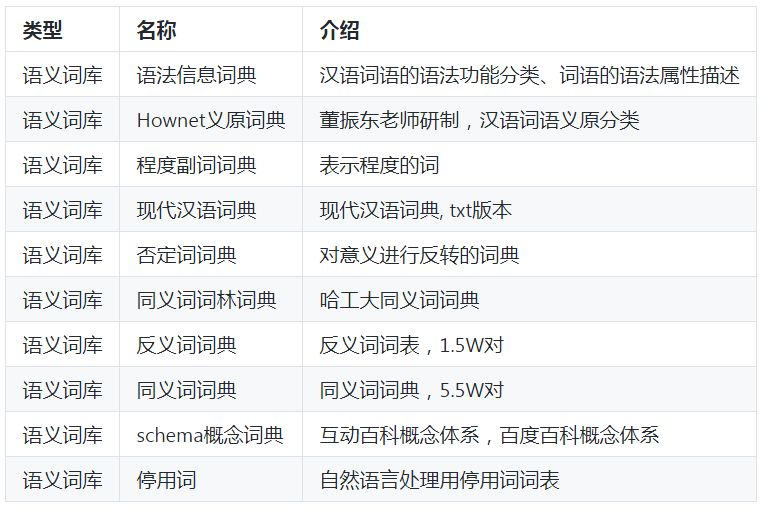
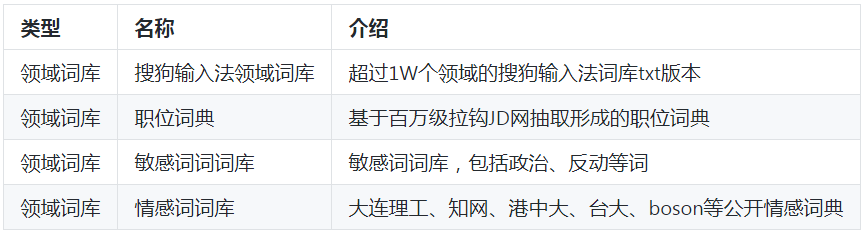
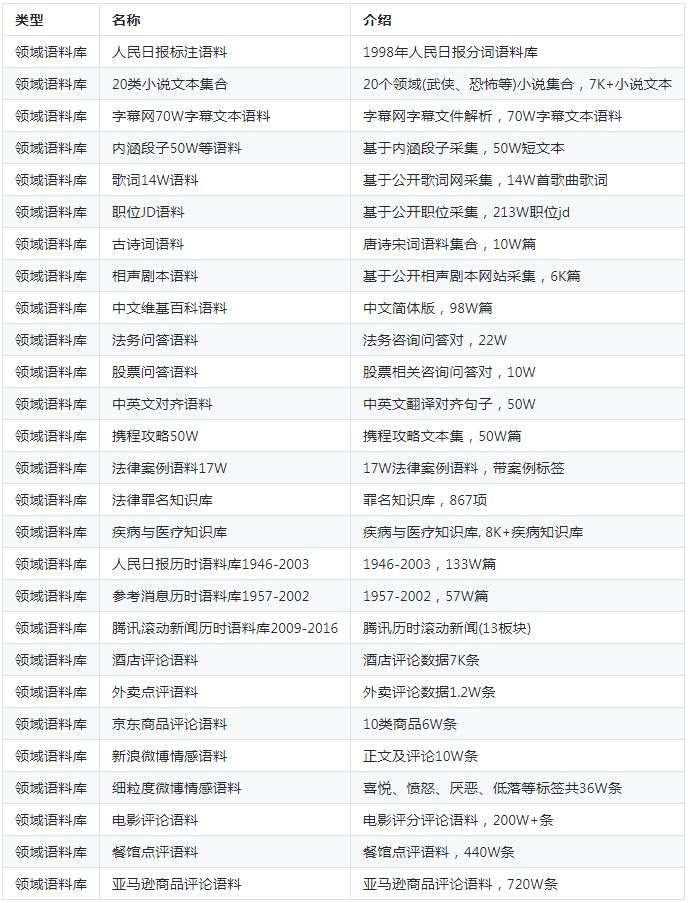
作者在学习和工作之余,根据语言资源搭建策略,构建起了语义词库、领域词库、领域语料库、评测语料库。种类约53种,具体如下:
语义知识库
领域词库
领域语料库
评测语料库

总结
1、本项目阐述了语言资源的相关感想,并给出了目前语言资源的构建现状,目前为止收集了四个大类共53小类的语言资源数据集。
2、本项目中所涉及到的报告内容均来源于网上公开资源,对此免责声明。
3、如果有需要用到以上作者收集到的这些语料库,可以联系作者获取。
4、自然语言处理,是人工智能皇冠上的一颗明珠,懂语言者得天下,语言资源在自然语言处理中扮演着举足轻重的作用,懂语言资源者,分得天下。目前开放的网络环境,对语言资源的大繁荣提供了很大的契机。语言资源构建是一门学问,也是一种手段,现在自然语言处理技术也对语言资源的构建提供了技术上的支持,如何把握语言资源搜索策略,搭建策略,重点解决语言资源的动态更新、共享与联盟问题,将是语言资源建设未来需要解决的问题。
如有自然语言处理、知识图谱、事理图谱、社会计算、语言资源建设等问题或合作,可联系我:
1、我的github项目介绍:https://liuhuanyong.github.io
2、我的csdn博客:https://blog.csdn.net/lhy2014
3、刘焕勇,中国科学院软件研究所,[email protected]
原文地址:
https://github.com/liuhuanyong/ChineseNLPCorpus
(*本文仅代表作者独立观点,转载请联系原作者)
公开课预告
◆
强化学习
◆
本期课程中,微软小冰全球首席架构师及研发总监周力博士将介绍微软小冰在全双工语音对话方面的最新成果,及其在智能硬件上的应用和未来将面临的更多技术产品挑战。

推荐阅读
智能推荐
使用nginx解决浏览器跨域问题_nginx不停的xhr-程序员宅基地
文章浏览阅读1k次。通过使用ajax方法跨域请求是浏览器所不允许的,浏览器出于安全考虑是禁止的。警告信息如下:不过jQuery对跨域问题也有解决方案,使用jsonp的方式解决,方法如下:$.ajax({ async:false, url: 'http://www.mysite.com/demo.do', // 跨域URL ty..._nginx不停的xhr
在 Oracle 中配置 extproc 以访问 ST_Geometry-程序员宅基地
文章浏览阅读2k次。关于在 Oracle 中配置 extproc 以访问 ST_Geometry,也就是我们所说的 使用空间SQL 的方法,官方文档链接如下。http://desktop.arcgis.com/zh-cn/arcmap/latest/manage-data/gdbs-in-oracle/configure-oracle-extproc.htm其实简单总结一下,主要就分为以下几个步骤。..._extproc
Linux C++ gbk转为utf-8_linux c++ gbk->utf8-程序员宅基地
文章浏览阅读1.5w次。linux下没有上面的两个函数,需要使用函数 mbstowcs和wcstombsmbstowcs将多字节编码转换为宽字节编码wcstombs将宽字节编码转换为多字节编码这两个函数,转换过程中受到系统编码类型的影响,需要通过设置来设定转换前和转换后的编码类型。通过函数setlocale进行系统编码的设置。linux下输入命名locale -a查看系统支持的编码_linux c++ gbk->utf8
IMP-00009: 导出文件异常结束-程序员宅基地
文章浏览阅读750次。今天准备从生产库向测试库进行数据导入,结果在imp导入的时候遇到“ IMP-00009:导出文件异常结束” 错误,google一下,发现可能有如下原因导致imp的数据太大,没有写buffer和commit两个数据库字符集不同从低版本exp的dmp文件,向高版本imp导出的dmp文件出错传输dmp文件时,文件损坏解决办法:imp时指定..._imp-00009导出文件异常结束
python程序员需要深入掌握的技能_Python用数据说明程序员需要掌握的技能-程序员宅基地
文章浏览阅读143次。当下是一个大数据的时代,各个行业都离不开数据的支持。因此,网络爬虫就应运而生。网络爬虫当下最为火热的是Python,Python开发爬虫相对简单,而且功能库相当完善,力压众多开发语言。本次教程我们爬取前程无忧的招聘信息来分析Python程序员需要掌握那些编程技术。首先在谷歌浏览器打开前程无忧的首页,按F12打开浏览器的开发者工具。浏览器开发者工具是用于捕捉网站的请求信息,通过分析请求信息可以了解请..._初级python程序员能力要求
Spring @Service生成bean名称的规则(当类的名字是以两个或以上的大写字母开头的话,bean的名字会与类名保持一致)_@service beanname-程序员宅基地
文章浏览阅读7.6k次,点赞2次,收藏6次。@Service标注的bean,类名:ABDemoService查看源码后发现,原来是经过一个特殊处理:当类的名字是以两个或以上的大写字母开头的话,bean的名字会与类名保持一致public class AnnotationBeanNameGenerator implements BeanNameGenerator { private static final String C..._@service beanname
随便推点
二叉树的各种创建方法_二叉树的建立-程序员宅基地
文章浏览阅读6.9w次,点赞73次,收藏463次。1.前序创建#include<stdio.h>#include<string.h>#include<stdlib.h>#include<malloc.h>#include<iostream>#include<stack>#include<queue>using namespace std;typed_二叉树的建立
解决asp.net导出excel时中文文件名乱码_asp.net utf8 导出中文字符乱码-程序员宅基地
文章浏览阅读7.1k次。在Asp.net上使用Excel导出功能,如果文件名出现中文,便会以乱码视之。 解决方法: fileName = HttpUtility.UrlEncode(fileName, System.Text.Encoding.UTF8);_asp.net utf8 导出中文字符乱码
笔记-编译原理-实验一-词法分析器设计_对pl/0作以下修改扩充。增加单词-程序员宅基地
文章浏览阅读2.1k次,点赞4次,收藏23次。第一次实验 词法分析实验报告设计思想词法分析的主要任务是根据文法的词汇表以及对应约定的编码进行一定的识别,找出文件中所有的合法的单词,并给出一定的信息作为最后的结果,用于后续语法分析程序的使用;本实验针对 PL/0 语言 的文法、词汇表编写一个词法分析程序,对于每个单词根据词汇表输出: (单词种类, 单词的值) 二元对。词汇表:种别编码单词符号助记符0beginb..._对pl/0作以下修改扩充。增加单词
android adb shell 权限,android adb shell权限被拒绝-程序员宅基地
文章浏览阅读773次。我在使用adb.exe时遇到了麻烦.我想使用与bash相同的adb.exe shell提示符,所以我决定更改默认的bash二进制文件(当然二进制文件是交叉编译的,一切都很完美)更改bash二进制文件遵循以下顺序> adb remount> adb push bash / system / bin /> adb shell> cd / system / bin> chm..._adb shell mv 权限
投影仪-相机标定_相机-投影仪标定-程序员宅基地
文章浏览阅读6.8k次,点赞12次,收藏125次。1. 单目相机标定引言相机标定已经研究多年,标定的算法可以分为基于摄影测量的标定和自标定。其中,应用最为广泛的还是张正友标定法。这是一种简单灵活、高鲁棒性、低成本的相机标定算法。仅需要一台相机和一块平面标定板构建相机标定系统,在标定过程中,相机拍摄多个角度下(至少两个角度,推荐10~20个角度)的标定板图像(相机和标定板都可以移动),即可对相机的内外参数进行标定。下面介绍张氏标定法(以下也这么称呼)的原理。原理相机模型和单应矩阵相机标定,就是对相机的内外参数进行计算的过程,从而得到物体到图像的投影_相机-投影仪标定
Wayland架构、渲染、硬件支持-程序员宅基地
文章浏览阅读2.2k次。文章目录Wayland 架构Wayland 渲染Wayland的 硬件支持简 述: 翻译一篇关于和 wayland 有关的技术文章, 其英文标题为Wayland Architecture .Wayland 架构若是想要更好的理解 Wayland 架构及其与 X (X11 or X Window System) 结构;一种很好的方法是将事件从输入设备就开始跟踪, 查看期间所有的屏幕上出现的变化。这就是我们现在对 X 的理解。 内核是从一个输入设备中获取一个事件,并通过 evdev 输入_wayland