在Wireshark的tcptrace图中看清TCP拥塞控制算法的细节(CUBIC/BBR算法为例)-程序员宅基地
技术标签: TCP Wireshark tcptrace TCP拥塞控制
另外,最近有人问我,为什么我总是喜欢在技术文章后面加一些与技术毫不相关的话,我说,咱们小时候学古文的时候,那些古代的作者不也是喜欢在文章最后写一段毫不相关的“呜呼...”“嗟夫...”之类的吗?人写文章总是有感而发,所以,点题总是必要的。也有同事问,我写一篇文章要多久,我说周末凌晨3点多起床,喝上一瓶真露酒,到7点多就应该可以完成,这也是跟古人学的,一定要醉里挑灯看剑,喝点清淡的酒是必要的,而且要在夜里,但这决不意味着可以喝白酒,我很讨厌白酒,那玩意气味刺鼻,而且只要喝一点,一天就啥也干不成了。
引述
近日工作中需要分析数据包,本着先从全局入手的原则,我一直都比较喜欢tcptrace图,这个图就像大航海时代的大西洋地图一样,可以让你像黑胡子一样在领域内得心应手!从对一幅幅的tcptrace图的分析中,你会对一个TCP连接的任何细节了如指掌。曾经,一个经理模样的人来做技术交流,他曾经说的话,我部分的揭露在这里。用Wireshark打开一个pcap文件,过滤出一个TCP流之后,点击“统计-TCP流图形-时间序列(tcptrace)”,你会看到一张图,眯着眼看你会看到大致3条线,我对这3条线大致解释一下,贴图如下:
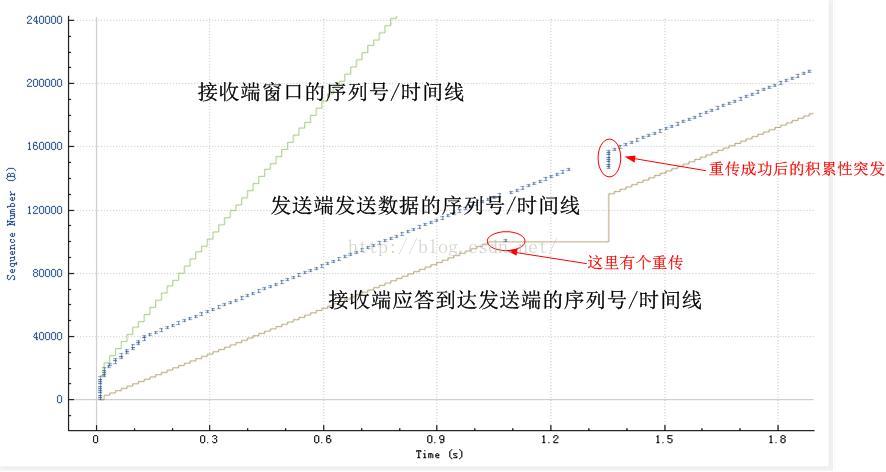
本文概要
接下来的篇幅中,大体上分为三块内容:1.首先把这个tcptrace图放大来看,加以更加详细的解释。
2.我首次(目前我没有见有人这么玩过)在这个tcptrace图上描述CUBIC算法以及BBR算法的行为
3.描述一下突发发送与Pacing发送
4.像往常一样,咒骂一个体系或者一个机制
-----------------------------------------
tcptrace图解详情
首先,我来展示一个解释比较详尽的图,配以不同的辅助线,你会发现,从这张图上,你看到的不止感官上Wireshark告诉你的那些:
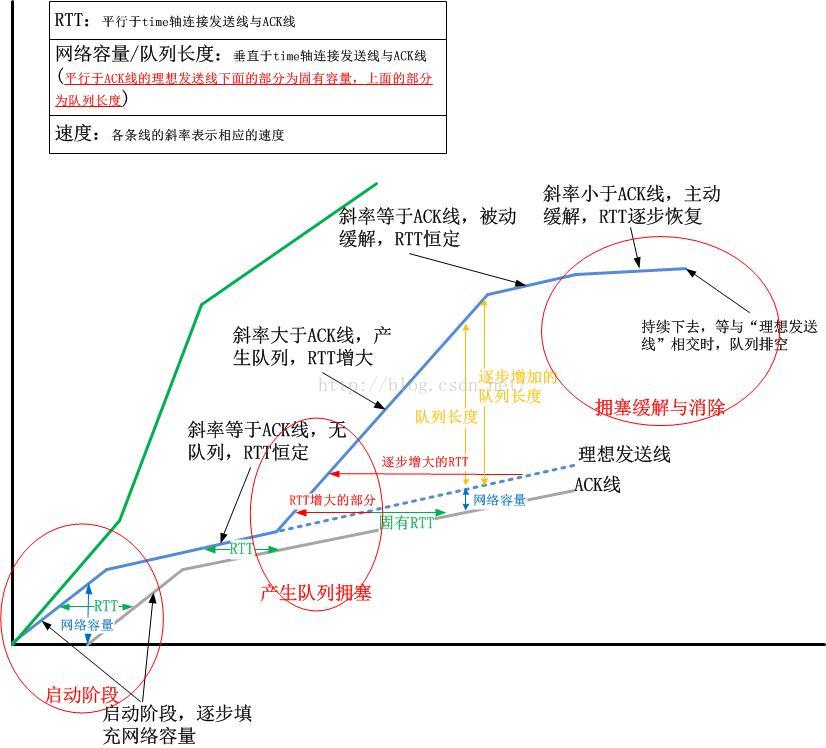
然而,这并不是全部!
由于TCP是一个端到端的傻逼瞎子协议,你就不能指望TCP可以获得哪怕是很粗糙的网络状况,为什么会产生队列,难道没有什么机制告诉TCP不要再发了,线路拥塞了吗?更可恶的是,如上图所示,这个例子中产生队列的那个红色圈圈,这完全是由TCP发送端自己造成的!它提高了自己的发送速度。是它自己的这种傻逼行为造成了排队,你仔细观察队列期间的ACK线,并不随着发送线斜率的陡高而陡高,这与启动阶段那个红圈圈的表现完全不同!因此可以说,TCP发送端本应该沿着那根“理想发送线”走上去,但它却走错了路!
事实上,这不能怪TCP,除了那些所谓搞加速的人会故意有所为之之外,任何正常的TCP都会时不时的探测一下是不是有更多的带宽可用,如果有,就提高发送线的斜率,因为它知道,此时发送速率的提高,在RTT过后,会带来ACK率的提高,但是如果不巧,这个“有空闲带宽”是个误判,那么当它发现在RTT后,ACK速率并没有提高后,就会马上把速率降下来,以避免进一步的排队。说实话,这对于TCP而言非常累!
在以上这个图示中,其实还隐藏着一条线,那条线就是“可用带宽线”!如下图所示:
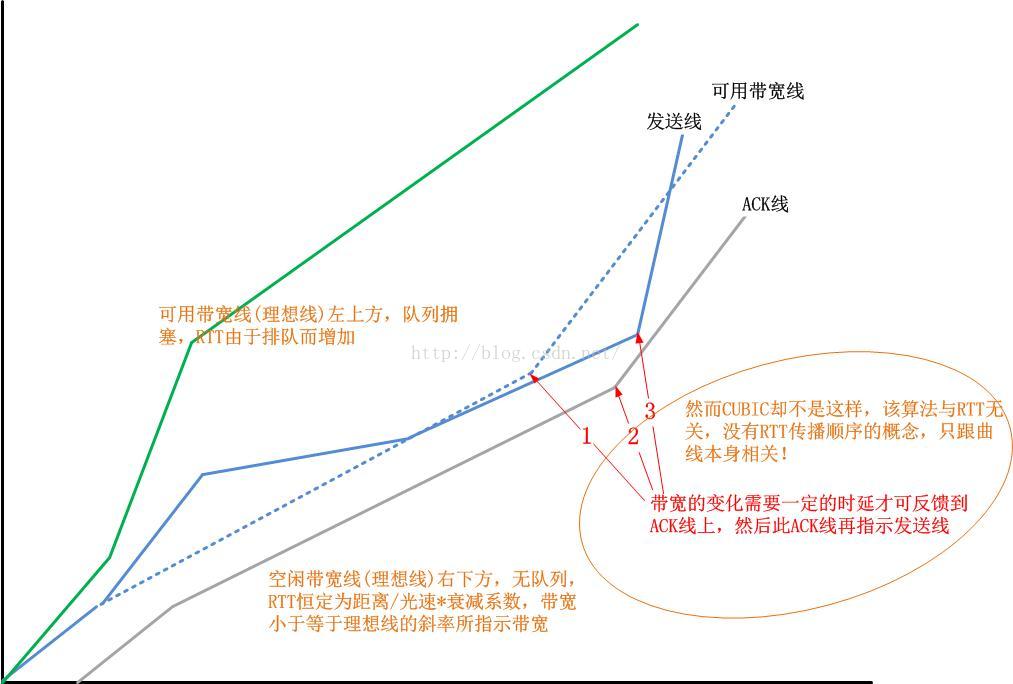
TCP发送端看不到这条终极指示路线,结果是什么?
结果就是,TCP无法知道什么时候网络中有了新的连接,需要出让自己的带宽,也不知道什么时候网络中有别的连接出让了带宽,自己可以去分享它。所以说,TCP拥塞控制算法需要做的就是完成以上两件事:
1.当网络拥塞的时候,降低发送速率;
2.当有新的可用带宽的时候,和其它所有的连接一起分享它。
评价一个拥塞控制算法好坏的指标就是一个TCP连接画出的“发送线”和那条不被TCP所见的“可用带宽”终极指示线的拟合程度。
CUBIC算法和BBR算法
假设你已经完全看懂并彻底理解了上面的图,接下来我来用这个图来阐释一个经典的CUBIC拥塞控制算法以及Google最新的BBR拥塞控制算法。首先我们看下CUBIC算法,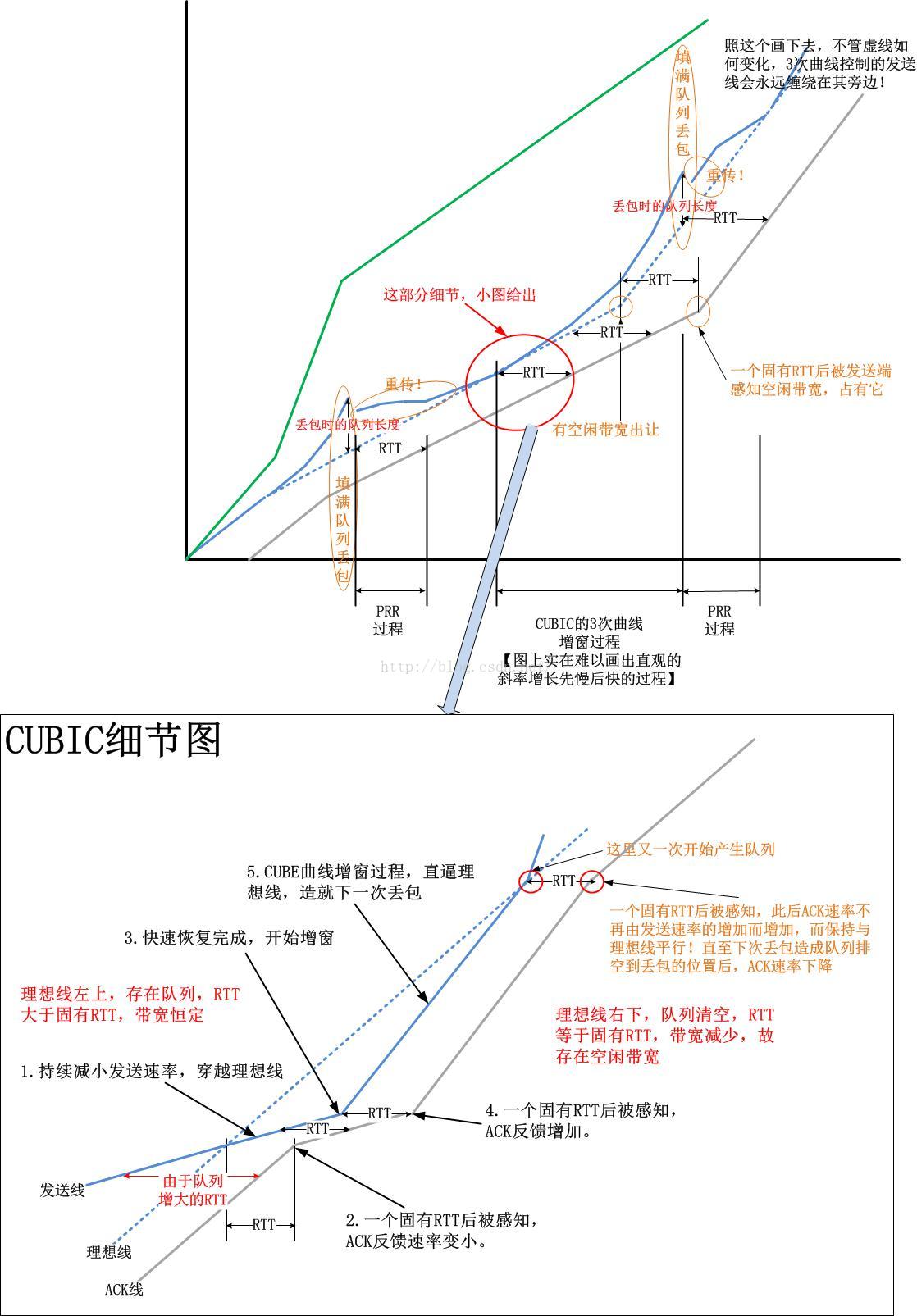
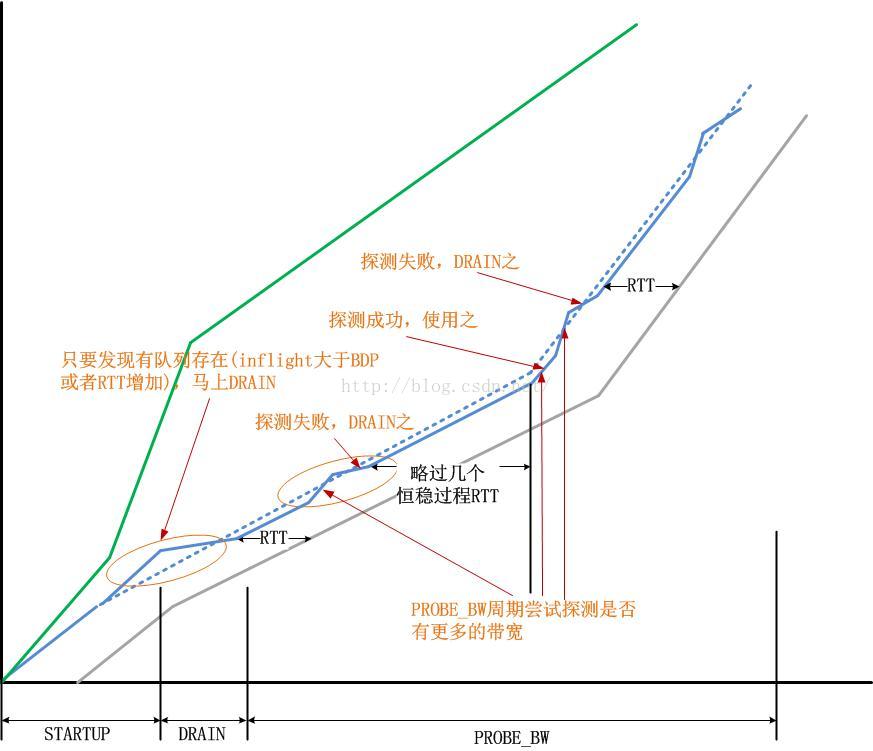
最终,我们可以得到一个明确的比较结论:
BBR算法计算依赖的是内置伺服器,保持发送曲线紧贴着“空闲带宽”线前行,而CUBIC算法则依赖于一条3次曲线,该3次曲线时刻左右TCP的发送速率,导致基于CUBIC算法的TCP发送曲线是缠绕“空闲带宽”线前行而不是紧贴它前行的,由于曲线参数在标准CUBIC中是恒定的,因此对每次的网络拥塞反应都一样。
对于CUBIC算法而言,优化的目标是,让这条发送曲线缠绕“空闲带宽”线更加紧一些,而这个,完全由3次曲线的形状决定,而后者则完全由曲线参数控制。反观BBR算法,优化的目标则是让发送曲线贴的“空闲带宽”线更加紧一些,这取决于BBR算法对实时带宽测量的精确性。
在结束本部分之前,我给出CUBIC算法以及BBR算法的“带有实际带宽的时间/序列图”:


接下来的篇幅留给突发和咒骂!
-----------------------------------------
什么是突发?
所谓的突发就是一次性把所有可以发送的数据全部发出去,当前大多数TCP的实现都是突发的,比如Linux的TCP实现就是突发,你可以看一下核心发送函数tcp_write_xmit,它里面有一个while循环,只要允许发送,就会立马发送!突发有什么危害呢?
我举一个例子,携带着对现代文明的一点诅咒!你知道贵族都是少食多餐吗?你知道只有屌丝才会暴饮暴食吗?你知道是奴隶主确定的一日三餐吗?是的,暴饮暴食和一日三餐都属于突发!在古代那个机械简陋的时代,不管是种地还是土木工程,都需要巨大的人力在同一段时间同时发力,因此必须固定这些人的饮食和休息时间,以统一步调,既可以补充他们的体力,又可以让他们吃饭的时间不至于影响工作。可想而知,干了连续几个小时的重体力活,肯定是只要还饿并且还有食物就会继续吃(当然,食物多并不代表精致),但是看看那些贵族,什么时候想吃就吃,每次只吃固定的且少量的,比如固定时间吃甜点,固定时间喝茶,然后有宴会什么的。
事实上,直到现在,我们大多数人依然过着这样突发饮食的生活。这是现代文明的需要!如果程序员可以任意时间离开座位去吃饭,团队怎么合作?这与古代搬砖造金字塔如出一辙。
突发饮食对工作进度有利,对你的健康非常有害!
-----------------------------------------
对于TCP而言,突发意味着什么?
现如今大多数TCP的实现都是“ACK-窗口”驱动的,意思就是ACK到达后会驱动发送数据包,至于发多少,由窗口大小决定,这个发送是一次性的,也就是突发发送的。我依然以TCP的时间/序列图来解释一个实例:
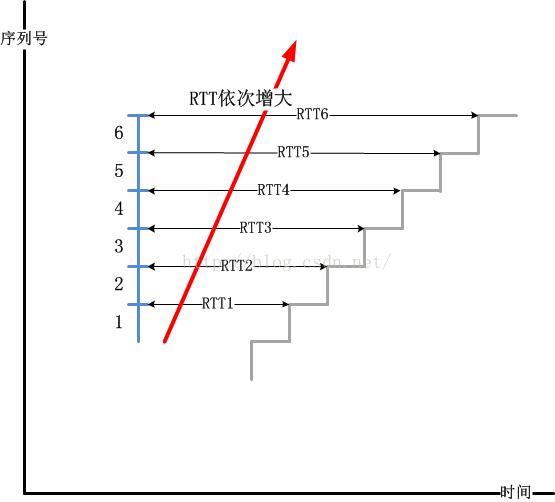
当Buffer满了后一定会丢包,而这个丢包被TCP发送端发现要经过一个RTO的时间,然而RTO是RTT计算出来的,RTT的变大意味着RTO会变大,这就导致丢包不能即时被发现得意即时重传!这是一连串的连锁反应!很显然,下面这个图是合理的:
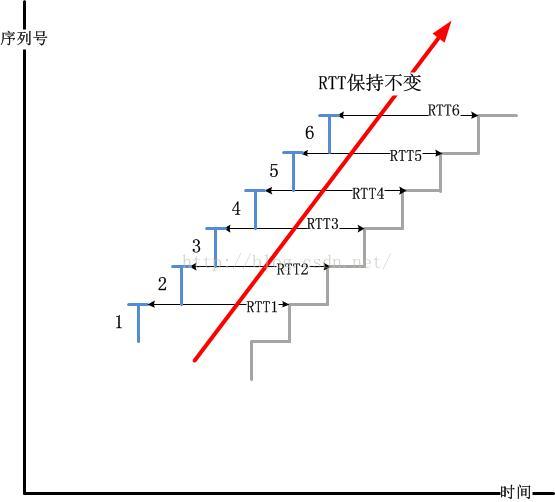
简单点说,我们知道了突发的危害,然而,然而Linux并没有实现非突发的Pacing模型!
也许你已经知道了Linux内核自3.12版本开始内置了一个FQ scheduler,然而Linux FQ机制解决不了根本问题,它根本上就是错误的!
Linux FQ实现Pacing Rate发送是错误的
我大胆的妄下此言,因为它本来就是错误的!1.仔细观察FQ的位置,它的位置摆错了
一句话概述,FQ并没有做到队列的消除,它只是把网络中的队列搬到了本机而已!本质上,FQ就是个队列!数据包从TCP层进入FQ依然是突发式进入的,依然要排队。只是说网络中的队列对于我们的TCP流而言可能并不可控,这种并不属于我们控制范围的队列会被其它具有侵略性的数据流侵占,然而本机的FQ队列可以做到公平调度。
FQ所处的位置并没有为TCP消除排队现象,要真正做到Pacing,必须从源头上抑制数据包的突发式发送,这个我后面会谈到。
2.仔细观察FQ的逻辑,它显然对TCP的RTT计算没有实施任何措施
一个TCP连接的RTT表示的是两个端节点之间的来回时延,其起始时间应该是数据包离开本机的时间,而终止时间则是ACK到达本机的时间,终止时间与起始时间的差值就是RTT!然而使用了FQ后,我们看下一个数据包的起始时间,它是数据包离开TCP层的时间,即tcp_transmit_skb中打上的时间,然而由于FQ实现的Pacing,这个数据包必定在FQ的队列中排队等待spread式发送,真正等到这个数据包被发出的时候,当前时间可能已经相距TCP打上的时间很久了!这种效应会造成TCP算出来的RTT还是会变大,这次的RTT变大并不是数据包网络中排队导致的,而是在本地FQ队列中排队导致的,唯一值得欣慰的是,本地的排队时延是可控的,而这个可控正是FQ scheduler中Fair的含义!FQ实现的公平调度不会使得某个连接的数据包饿死,不会导致TCP流的数据包被UDP流的数据包无情侵占。
-----------------------------------------
那么怎样做才是正确的
FQ应该放在TCP的上面而不是下面,FQ正确的位置处在socket和TCP之间。TCP计算的Pacing Rate应该向上告诉FQ,然后FQ抑制用户数据向TCP发送队列的下发,TCP则完全不需要任何修改。依然保持现有的“ACK-窗口”驱动模型发送数据。下面是一个简单的示意图: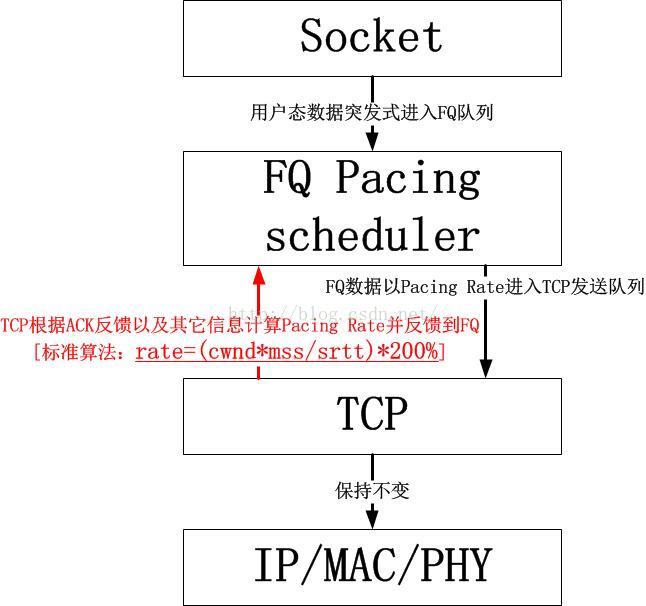
diff -urN linux-2.6.32.7/include/linux/sysctl.h linux-2.6.32.7_pacing/include/linux/sysctl.h
--- linux-2.6.32.7/include/linux/sysctl.h 2010-01-28 15:06:20.000000000 -0800
+++ linux-2.6.32.7_pacing/include/linux/sysctl.h 2016-11-19 00:04:20.108999867 -0800
@@ -426,14 +426,15 @@
NET_IPV4_TCP_WORKAROUND_SIGNED_WINDOWS=115,
NET_TCP_DMA_COPYBREAK=116,
NET_TCP_SLOW_START_AFTER_IDLE=117,
- NET_CIPSOV4_CACHE_ENABLE=118,
- NET_CIPSOV4_CACHE_BUCKET_SIZE=119,
- NET_CIPSOV4_RBM_OPTFMT=120,
- NET_CIPSOV4_RBM_STRICTVALID=121,
- NET_TCP_AVAIL_CONG_CONTROL=122,
- NET_TCP_ALLOWED_CONG_CONTROL=123,
- NET_TCP_MAX_SSTHRESH=124,
- NET_TCP_FRTO_RESPONSE=125,
+ NET_TCP_PACING=118,
+ NET_CIPSOV4_CACHE_ENABLE=119,
+ NET_CIPSOV4_CACHE_BUCKET_SIZE=120,
+ NET_CIPSOV4_RBM_OPTFMT=121,
+ NET_CIPSOV4_RBM_STRICTVALID=122,
+ NET_TCP_AVAIL_CONG_CONTROL=123,
+ NET_TCP_ALLOWED_CONG_CONTROL=124,
+ NET_TCP_MAX_SSTHRESH=125,
+ NET_TCP_FRTO_RESPONSE=126,
};
enum {
diff -urN linux-2.6.32.7/include/linux/tcp.h linux-2.6.32.7_pacing/include/linux/tcp.h
--- linux-2.6.32.7/include/linux/tcp.h 2010-01-28 15:06:20.000000000 -0800
+++ linux-2.6.32.7_pacing/include/linux/tcp.h 2016-11-19 00:05:25.876998887 -0800
@@ -398,6 +398,17 @@
u32 probe_seq_start;
u32 probe_seq_end;
} mtu_probe;
+
+#ifdef CONFIG_TCP_PACING
+/* TCP Pacing structure */
+ struct {
+ struct timer_list timer;
+ __u16 count;
+ __u16 burst;
+ __u8 lock;
+ __u8 delta;
+ } pacing;
+#endif
#ifdef CONFIG_TCP_MD5SIG
/* TCP AF-Specific parts; only used by MD5 Signature support so far */
diff -urN linux-2.6.32.7/include/net/tcp.h linux-2.6.32.7_pacing/include/net/tcp.h
--- linux-2.6.32.7/include/net/tcp.h 2010-01-28 15:06:20.000000000 -0800
+++ linux-2.6.32.7_pacing/include/net/tcp.h 2016-11-19 00:06:53.853999772 -0800
@@ -236,6 +236,9 @@
extern int sysctl_tcp_base_mss;
extern int sysctl_tcp_workaround_signed_windows;
extern int sysctl_tcp_slow_start_after_idle;
+#ifdef CONFIG_TCP_PACING
+extern int sysctl_tcp_pacing;
+#endif
extern int sysctl_tcp_max_ssthresh;
extern atomic_t tcp_memory_allocated;
@@ -498,6 +501,11 @@
extern unsigned int tcp_sync_mss(struct sock *sk, u32 pmtu);
extern unsigned int tcp_current_mss(struct sock *sk);
+#ifdef CONFIG_TCP_PACING
+extern void tcp_pacing_recalc_delta(struct sock *sk);
+extern void tcp_pacing_reset_timer(struct sock *sk);
+#endif
+
/* Bound MSS / TSO packet size with the half of the window */
static inline int tcp_bound_to_half_wnd(struct tcp_sock *tp, int pktsize)
{
diff -urN linux-2.6.32.7/net/ipv4/Kconfig linux-2.6.32.7_pacing/net/ipv4/Kconfig
--- linux-2.6.32.7/net/ipv4/Kconfig 2010-01-28 15:06:20.000000000 -0800
+++ linux-2.6.32.7_pacing/net/ipv4/Kconfig 2016-11-19 00:07:48.466000097 -0800
@@ -543,6 +543,21 @@
loss packets.
See http://www.ntu.edu.sg/home5/ZHOU0022/papers/CPFu03a.pdf
+config TCP_PACING
+ bool "TCP Pacing"
+ depends on EXPERIMENTAL
+ select HZ_1000
+ default n
+ ---help---
+ Many researchers have observed that TCP's congestion control mechanisms
+ can lead to bursty traffic flows on modern high-speed networks, with a
+ negative impact on overall network efficiency. A proposed solution to this
+ problem is to evenly space, or "pace", data sent into the network over an
+ entire round-trip time, so that data is not sent in a burst.
+ To enable this feature, please refer to Documentation/networking/ip-sysctl.txt.
+ If unsure, say N.
+
+
config TCP_CONG_YEAH
tristate "YeAH TCP"
depends on EXPERIMENTAL
diff -urN linux-2.6.32.7/net/ipv4/sysctl_net_ipv4.c linux-2.6.32.7_pacing/net/ipv4/sysctl_net_ipv4.c
--- linux-2.6.32.7/net/ipv4/sysctl_net_ipv4.c 2010-01-28 15:06:20.000000000 -0800
+++ linux-2.6.32.7_pacing/net/ipv4/sysctl_net_ipv4.c 2016-11-19 00:09:19.760999390 -0800
@@ -742,6 +742,16 @@
.strategy = sysctl_intvec,
.extra1 = &zero
},
+#ifdef CONFIG_TCP_PACING
+ {
+ .ctl_name = NET_TCP_PACING,
+ .procname = "tcp_pacing",
+ .data = &sysctl_tcp_pacing,
+ .maxlen = sizeof(int),
+ .mode = 0644,
+ .proc_handler = &proc_dointvec
+ },
+#endif
{ .ctl_name = 0 }
};
diff -urN linux-2.6.32.7/net/ipv4/tcp_input.c linux-2.6.32.7_pacing/net/ipv4/tcp_input.c
--- linux-2.6.32.7/net/ipv4/tcp_input.c 2010-01-28 15:06:20.000000000 -0800
+++ linux-2.6.32.7_pacing/net/ipv4/tcp_input.c 2016-11-19 00:09:55.244999661 -0800
@@ -3663,6 +3663,10 @@
if ((flag & FLAG_DATA_ACKED) && !frto_cwnd)
tcp_cong_avoid(sk, ack, prior_in_flight);
}
+#ifdef CONFIG_TCP_PACING
+ if(sysctl_tcp_pacing)
+ tcp_pacing_recalc_delta(sk);
+#endif
if ((flag & FLAG_FORWARD_PROGRESS) || !(flag & FLAG_NOT_DUP))
dst_confirm(sk->sk_dst_cache);
diff -urN linux-2.6.32.7/net/ipv4/tcp_output.c linux-2.6.32.7_pacing/net/ipv4/tcp_output.c
--- linux-2.6.32.7/net/ipv4/tcp_output.c 2010-01-28 15:06:20.000000000 -0800
+++ linux-2.6.32.7_pacing/net/ipv4/tcp_output.c 2016-11-19 00:26:03.760999278 -0800
@@ -59,6 +59,10 @@
/* By default, RFC2861 behavior. */
int sysctl_tcp_slow_start_after_idle __read_mostly = 1;
+#ifdef CONFIG_TCP_PACING
+int sysctl_tcp_pacing=0;
+#endif
+
/* Account for new data that has been sent to the network. */
static void tcp_event_new_data_sent(struct sock *sk, struct sk_buff *skb)
{
@@ -654,6 +658,12 @@
if (tcp_packets_in_flight(tp) == 0)
tcp_ca_event(sk, CA_EVENT_TX_START);
+#ifdef CONFIG_TCP_PACING
+ if(sysctl_tcp_pacing) {
+ tcp_pacing_reset_timer(sk);
+ tp->pacing.lock = 1;
+ }
+#endif
skb_push(skb, tcp_header_size);
skb_reset_transport_header(skb);
@@ -1342,6 +1352,14 @@
const struct inet_connection_sock *icsk = inet_csk(sk);
u32 send_win, cong_win, limit, in_flight;
+#ifdef CONFIG_TCP_PACING
+ /* TCP Pacing conflicts with this algorithm.
+ * When Pacing is enabled, don't try to defer.
+ */
+ if(sysctl_tcp_pacing)
+ goto send_now;
+#endif
+
if (TCP_SKB_CB(skb)->flags & TCPCB_FLAG_FIN)
goto send_now;
@@ -1577,6 +1595,11 @@
if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now)))
break;
+#ifdef CONFIG_TCP_PACING
+ if (sysctl_tcp_pacing && tp->pacing.lock)
+ return 0;
+#endif
+
if (tso_segs == 1) {
if (unlikely(!tcp_nagle_test(tp, skb, mss_now,
(tcp_skb_is_last(sk, skb) ?
@@ -1588,9 +1611,14 @@
}
limit = mss_now;
- if (tso_segs > 1 && !tcp_urg_mode(tp))
+ if (tso_segs > 1 && !tcp_urg_mode(tp))
limit = tcp_mss_split_point(sk, skb, mss_now,
cwnd_quota);
+#ifdef CONFIG_TCP_PACING
+ if (sysctl_tcp_pacing && sent_pkts >= tp->pacing.burst)
+ tp->pacing.lock=1;
+#endif
+
if (skb->len > limit &&
unlikely(tso_fragment(sk, skb, limit, mss_now)))
@@ -1951,6 +1979,11 @@
}
}
+#ifdef CONFIG_TCP_PACING
+ if (sysctl_tcp_pacing && tp->pacing.lock)
+ return -EAGAIN;
+#endif
+
/* Make a copy, if the first transmission SKB clone we made
* is still in somebody's hands, else make a clone.
*/
diff -urN linux-2.6.32.7/net/ipv4/tcp_timer.c linux-2.6.32.7_pacing/net/ipv4/tcp_timer.c
--- linux-2.6.32.7/net/ipv4/tcp_timer.c 2010-01-28 15:06:20.000000000 -0800
+++ linux-2.6.32.7_pacing/net/ipv4/tcp_timer.c 2016-11-19 00:39:38.195998392 -0800
@@ -34,10 +34,19 @@
static void tcp_delack_timer(unsigned long);
static void tcp_keepalive_timer (unsigned long data);
+#ifdef CONFIG_TCP_PACING
+static void tcp_pacing_timer(unsigned long data);
+#endif
+
void tcp_init_xmit_timers(struct sock *sk)
{
inet_csk_init_xmit_timers(sk, &tcp_write_timer, &tcp_delack_timer,
&tcp_keepalive_timer);
+#ifdef CONFIG_TCP_PACING
+ init_timer(&(tcp_sk(sk)->pacing.timer));
+ tcp_sk(sk)->pacing.timer.function=&tcp_pacing_timer;
+ tcp_sk(sk)->pacing.timer.data = (unsigned long) sk;
+#endif
}
EXPORT_SYMBOL(tcp_init_xmit_timers);
@@ -535,3 +544,112 @@
bh_unlock_sock(sk);
sock_put(sk);
}
+
+#ifdef CONFIG_TCP_PACING
+/*
+ * This is the timer used to spread packets.
+ * a delta value is computed on rtt/cwnd,
+ * and will be our expire interval.
+ * The timer has to be restarted when a segment is sent out.
+ */
+static void tcp_pacing_timer(unsigned long data)
+{
+ struct sock *sk = (struct sock*)data;
+ struct tcp_sock *tp = tcp_sk(sk);
+
+ if(!sysctl_tcp_pacing)
+ return;
+
+ bh_lock_sock(sk);
+ if (sock_owned_by_user(sk)) {
+ /* Try again later */
+ if (!mod_timer(&tp->pacing.timer, jiffies + 1))
+ sock_hold(sk);
+ goto out_unlock;
+ }
+
+ if (sk->sk_state == TCP_CLOSE)
+ goto out;
+
+ /* Unlock sending, so when next ack is received it will pass.
+ *If there are no packets scheduled, do nothing.
+ */
+ tp->pacing.lock=0;
+
+ if(!sk->sk_send_head){
+ /* Sending queue empty */
+ goto out;
+ }
+
+ /* Handler */
+ tcp_push_pending_frames(sk);
+
+ out:
+ if (tcp_memory_pressure)
+ sk_mem_reclaim(sk);
+
+ out_unlock:
+ bh_unlock_sock(sk);
+ sock_put(sk);
+}
+
+void tcp_pacing_reset_timer(struct sock *sk)
+{
+ struct tcp_sock *tp = tcp_sk(sk);
+ __u32 timeout = jiffies+tp->pacing.delta;
+
+ if(!sysctl_tcp_pacing)
+ return;
+ if (!mod_timer(&tp->pacing.timer, timeout))
+ sock_hold(sk);
+}
+EXPORT_SYMBOL(tcp_pacing_reset_timer);
+
+/*
+ * This routine computes tcp_pacing delay, using
+ * a simplified uniform pacing policy.
+ */
+void tcp_pacing_recalc_delta(struct sock *sk)
+{
+ struct tcp_sock *tp=tcp_sk(sk);
+ __u32 window=(tp->snd_cwnd)<<3;
+ __u32 srtt = tp->srtt;
+ __u32 round=0;
+ __u32 curmss=tp->mss_cache;
+ int state=inet_csk(sk)->icsk_ca_state;
+
+ if( (state==TCP_CA_Recovery) &&(tp->snd_cwnd < tp->snd_ssthresh))
+ window=(tp->snd_ssthresh)<<3;
+
+ if( (tp->snd_wnd/curmss) < tp->snd_cwnd )
+ window = (tp->snd_wnd/curmss)<<3;
+
+ if (window>1 && srtt){
+ if (window <= srtt){
+ tp->pacing.delta=(srtt/window);
+ if(srtt%window)
+ round=( (srtt/(srtt%window)) / tp->pacing.delta);
+ if (tp->pacing.count >= (round-1) &&(round>1)){
+ tp->pacing.delta++;
+ tp->pacing.count=0;
+ }
+ tp->pacing.burst=1;
+ } else {
+ tp->pacing.delta=1;
+ tp->pacing.burst=(window/srtt);
+ if(window%srtt)
+ round=( (window/(window%srtt)) * tp->pacing.burst);
+ if (tp->pacing.count >= (round-1) && (round>1)){
+ tp->pacing.burst++;
+ tp->pacing.count=0;
+ }
+ }
+ } else {
+ tp->pacing.delta=0;
+ tp->pacing.burst=1;
+ }
+}
+
+EXPORT_SYMBOL(tcp_pacing_recalc_delta);
+
+#endif关于Pacing,我还想最终解释一下,因为也许看了这个解释,你才会觉得“权威”!不然你总觉得我在瞎bibi,大多数时候,想阐明一个简单的道理并说服别人,那时相当的费劲,毕竟因为它太简单了,大家都会,凭什么我说了算呢?嗯,是的,那么权威解释的唯一方式便是引用一段英文了:
Perhaps most importantly, ack-clocking will only spread data
at the bottleneck rate. For high-bandwidth links shared by a
large number of connections, this can result in each connec-
tion transmitting in a burst and remaining idle for the rest of the
round trip time. As a connection starts up, its data packets are
spaced apart at the bottleneck by one time unit (the rate the bot-
tleneck services packets). Each round trip increases the number
of packets, but all of the packets remain clustered together. Un-
less two connections happen to send their cluster of packets so
that they overlap at the bottleneck, the packets for each connec-
tion will tend to stay clustered. When two clusters do overlap at
the bottleneck (for example, because of slow start increases or
if the connections have different round trip times), the result is a
larger burst than either would have generated on its own.
但是问题又来了,又有很多人不喜欢看英文,觉得看英文也费劲,那怎么办呢?有办法,我还有图解呢。
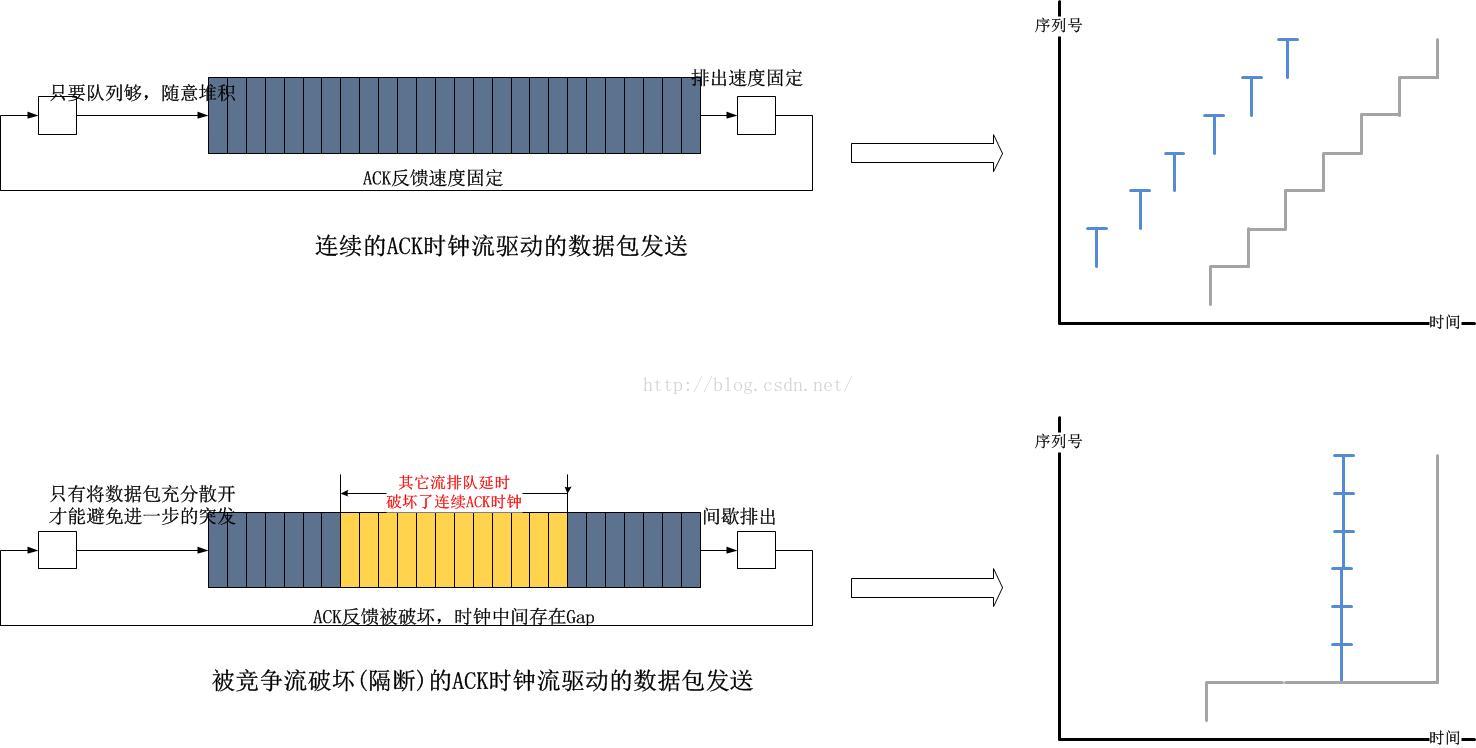
我们知道,对于TCP而言,ACK时钟始终扮演了一个重要的角色,是它驱动了TCP发送端的行为,包括但不限于数据的发送,拥塞窗口的调整等,但是要想维持ACK时钟,就必须保证有源源不断的ACK回到TCP发送端,这个要求在单流场景下是必然被满足的,因为即便网络中存在队列,也是唯一的TCP流独占队列,该队列的处理速度决定了ACK时钟的频率。然而一旦有其它的流竞争队列,单一的TCP流在队列中就会被隔开,这个被隔开的间隔就是ACK时钟被中断的断层,这个断层造成了数据的突发:
The goal of pacing is to evenly spread the transmission of a
window of packets across the entire duration of the round trip
time.
OK!我要结束本文了,但是此时依然觉得意犹未尽,依然拿温州皮鞋厂老板开刀吧。温州老板不会用二胡拉《卡农》。
后记与吐槽
和往常一样,如果不是因为我有槽点,我根本就不会花这么大工夫来写这么一篇可能根本没人看的文章。我听着《卡农》以及《垃圾场》写下下面的话。大多数的人,可能也包括我,都喜欢别人按照自己的思路行事却从来都抵触服从别人,至少要尽可能坚持不能让别人把自己否了,特别是在国内这种环境下。因此,本着一种收敛的内在机制,每当有人提出一点想法或者思路的时候,其它人总是喜欢在全面审视之前先去找漏洞或者污点,其论据无非就是他一直坚持的那些,人们总是喜欢质疑别人,不是为了让事情变得更好,而只是为了挑毛病,让人说一句,看,嗨,你也不行的,咱都一样!也许我的理解不对或者至少过于偏激,但事实总是让人觉得决定从此尽量哑口不言是最明智的选择。
我们的环境不是自由表达自由辩论的环境,这是一个诡辩的环境,你必须时刻应对一种作风,鸡蛋里挑骨头的作风。即便你已经同意一种观点,为了维护住所谓的“面子”,你只能默默地去实践,表面上却依然不依不饶,抑扬顿挫地绝不能让自己的帽子歪掉。
我个人关注这个tcptrace线已经很久了,大概已经将近3年了,每当我分析数据包的时候,我总能从这里看出点端倪,然而当我描述详情的时候,却总有那类不耐烦的气焰萦绕在我耳边以及眼前,总是那么多的质疑,总是那么多的“我的疑问”,“我想知道的是”,“我觉得不是这样”...如果这是一个值得讨论的话题,比如是那种高科技生化实验,人工智能之类的话题,我会花一个通宵去讨论,此时Talk is not cheap,然而,对于关于tcptrace的话题,这是一个显而易见的事实,我纳闷这么一个简单的事实,解释起来怎么就比造原子弹还费劲!事实就明显摆在那里,睁大眼就能看得见,针对这种问题的质疑,表现的并不是开放活泼的学术作风,而是在浪费生命!问题出在,确实有人在默默实践你的方案,并且尽可能把这一切作为自己的独践,如果这只是一场误会,我承认我是傻逼,但如果这是人的私心在作怪,我将闭口不言。
也许,可能是我表达的不够清晰,让人有很多的疑问,是事实更可能是因为我个人并非什么权威,如果是洋洋洒洒的一篇来自美国的英文文章,即使写的再蹩脚,人们也总是能从中揣摩出一点作者的所谓“本意”,嗯,是这样子的,然而面对一个大活人,却截然相反。
这就是中国式教育培养出的新的人性弱点,在别人证明自己不充分不完善的时候,自己努力要做的并不是充实和完善,而是反咬对方,证明对方也不充分不完善,从而完全误解了对方的好意。对方的目标只是想让事情变得更美好,并没有想营造一个硝烟弥漫的战场,而更加不幸的并不是硝烟本身,而是这根本不是一个真正的战场,这只是在诡辩!不知不觉中,中国人学会了西方的一切形式,却学不会思想。人们学会了质疑别人,但是从来很少有人敢质疑自己的老师,质疑自己的老板,质疑自己的经理,质疑自己的父母,人们从西方学会的是质疑跟自己一样的,因为这样做的成本很低!这种质疑并不是真正的质疑,而只是为了维护面子和身份。
老师,老板,经理,父母的地位是安全的,因为他跟你不是竞争关系,所以任人尽情地去献媚,你已经压在他们之下了,为了在跟自己平等的圈子里维护自己的尊严,只能想尽一切办法不让自己倒下,但与此同时尽力要让别人倒下,于是乎从西方学会了质疑和辩论,并默默将其进化为诡辩。真正要做的是什么?真正要做的是联合跟自己一样的人去质疑你的老板,质疑你的老师,质疑你的父母,甚至...
-----------------------------------------
这回该温州皮鞋厂老板躺枪了!
如果你已经读了CUBIC的Paper,干嘛为代码中的cube_factor以及cube_rtt_scale而纠结,我告诉温州老板这只是控制曲线形状的参数,就是方程式中的C,K之类的,老板就开始纠结代码中的计算问题了。...其实Linux内核的代码只是一种写法而已,给你一个数学公式,相信你也可以正确实现它,然后别人会纠结你为什么这么实现,这其实只是你的一种方法而已,没有为什么。这不是一种正确的学习方法,这会让人抓不到重点。
-----------------------------------------
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法