DPDK 无锁ring_ring_f_mp_hts_enq-程序员宅基地
本文整理下之前的学习笔记,基于DPDK17.11版本源码,主要分析无锁队列ring的实现。
rte_ring_tailq保存rte_ring链表
创建ring后会将其插入共享内存链表rte_ring_tailq,以便主从进程都可以访问。
//定义队列头结构 struct rte_tailq_elem_head
TAILQ_HEAD(rte_tailq_elem_head, rte_tailq_elem);
//声明全局变量rte_tailq_elem_head,类型为struct rte_tailq_elem_head,
//相当于是链表头,用来保存本进程注册的队列
/* local tailq list */
static struct rte_tailq_elem_head rte_tailq_elem_head =
TAILQ_HEAD_INITIALIZER(rte_tailq_elem_head);
//调用EAL_REGISTER_TAILQ在main函数前注册rte_ring_tailq到全局变量rte_tailq_elem_head。
#define RTE_TAILQ_RING_NAME "RTE_RING"
static struct rte_tailq_elem rte_ring_tailq = {
.name = RTE_TAILQ_RING_NAME,
};
EAL_REGISTER_TAILQ(rte_ring_tailq)
调用rte_eal_tailq_update遍历链表rte_tailq_elem_head上的节点,将节点中的head指向 struct rte_mem_ring->tailq_head[]数组中的一个tailq_head,此head又作为另一个链表头。比如注册的rte_ring_tailq节点,其head专门用来保存创建的rte_ring(将rte_ring作为struct rte_tailq_entry的data,将struct rte_tailq_entry插入head)。前面说过struct rte_mem_ring->tailq_head存放在共享内存中,主从进程都可以访问,这样对于rte_ring来说,主从进程都可以创建/访问ring。
相关的数据结构如下图所示

image.png
创建ring
调用函数rte_ring_create创建ring,它会申请一块memzone的内存,大小为struct rte_ring结构加上count个void类型指针,内存结构如下
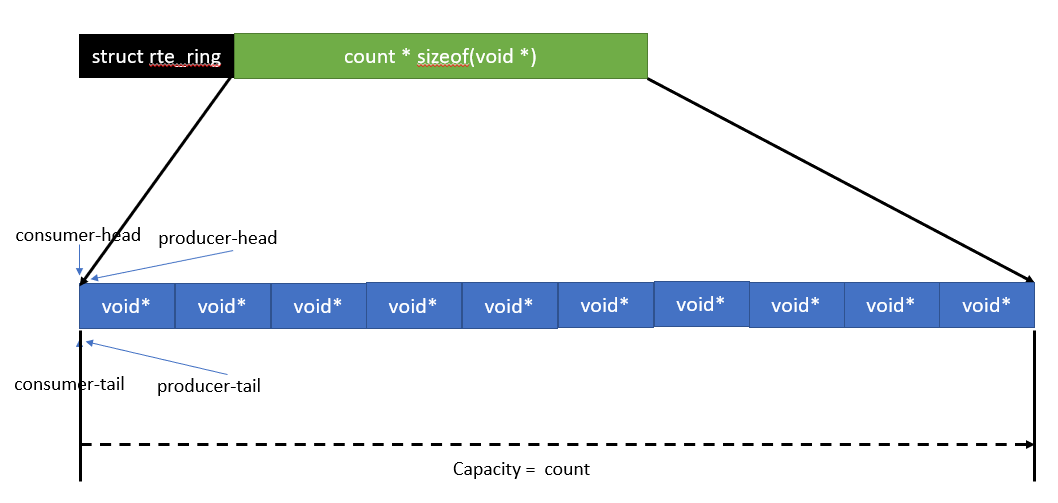
image.png
然后将ring中生产者和消费者的头尾指向0,最后将ring作为struct rte_tailq_entry的data插入共享内存链表,这样主从进程都可以访问此ring。
/**
* An RTE ring structure.
*
* The producer and the consumer have a head and a tail index. The particularity
* of these index is that they are not between 0 and size(ring). These indexes
* are between 0 and 2^32, and we mask their value when we access the ring[]
* field. Thanks to this assumption, we can do subtractions between 2 index
* values in a modulo-32bit base: that's why the overflow of the indexes is not
* a problem.
*/
struct rte_ring {
/*
* Note: this field kept the RTE_MEMZONE_NAMESIZE size due to ABI
* compatibility requirements, it could be changed to RTE_RING_NAMESIZE
* next time the ABI changes
*/
char name[RTE_MEMZONE_NAMESIZE] __rte_cache_aligned; /**< Name of the ring. */
//flags有如下三个值:
//RING_F_SP_ENQ创建单生产者,
//RING_F_SC_DEQ创建单消费者,
//RING_F_EXACT_SZ
int flags; /**< Flags supplied at creation. */
//memzone内存管理的底层结构,用来分配内存
const struct rte_memzone *memzone;
/**< Memzone, if any, containing the rte_ring */
//size为ring大小,值和RING_F_EXACT_SZ有关,如果指定了flag
//RING_F_EXACT_SZ,则size为rte_ring_create的参数count的
//向上取2次方,比如count为15,则size就为16。如果没有指定
//flag,则count必须是2的次方,此时size等于count
uint32_t size; /**< Size of ring. */
//mask值为size-1
uint32_t mask; /**< Mask (size-1) of ring. */
//capacity的值也和RING_F_EXACT_SZ有关,如果指定了,
//则capacity为rte_ring_create的参数count,如果没指定,
//则capacity为size-1
uint32_t capacity; /**< Usable size of ring */
//生产者位置,包含head和tail,head代表着下一次生产时的起
//始位置。tail代表消费者可以消费的位置界限,到达tail后就无
//法继续消费,通常情况下生产完成后tail = head,意味着刚生
//产的元素皆可以被消费
/** Ring producer status. */
struct rte_ring_headtail prod __rte_aligned(PROD_ALIGN);
// 消费者位置,也包含head和tail,head代表着下一次消费时的
//起始位置。tail代表生产者可以生产的位置界限,到达tail后就
//无法继续生产,通常情况下消费完成后,tail =head,意味着
//刚消费的位置皆可以被生产
/** Ring consumer status. */
struct rte_ring_headtail cons __rte_aligned(CONS_ALIGN);
};
下面看一下在函数rte_ring_create中ring是如何被创建的。
/* create the ring */
struct rte_ring *
rte_ring_create(const char *name, unsigned count, int socket_id, unsigned flags)
{
char mz_name[RTE_MEMZONE_NAMESIZE];
struct rte_ring *r;
struct rte_tailq_entry *te;
const struct rte_memzone *mz;
ssize_t ring_size;
int mz_flags = 0;
struct rte_ring_list* ring_list = NULL;
const unsigned int requested_count = count;
int ret;
//(tailq_entry)->tailq_head 的类型应该是 struct rte_tailq_entry_head,
//但是返回的却是 struct rte_ring_list,因为 rte_tailq_entry_head 和 rte_ring_list 定义都是一样的,
//可以认为是等同的。
#define RTE_TAILQ_CAST(tailq_entry, struct_name) \
(struct struct_name *)&(tailq_entry)->tailq_head
ring_list = RTE_TAILQ_CAST(rte_ring_tailq.head, rte_ring_list);
/* for an exact size ring, round up from count to a power of two */
if (flags & RING_F_EXACT_SZ)
count = rte_align32pow2(count + 1);
//获取需要的内存大小,包括结构体 struct rte_ring 和 count 个指针
ring_size = rte_ring_get_memsize(count);
ssize_t sz;
sz = sizeof(struct rte_ring) + count * sizeof(void *);
sz = RTE_ALIGN(sz, RTE_CACHE_LINE_SIZE);
#define RTE_RING_MZ_PREFIX "RG_"
snprintf(mz_name, sizeof(mz_name), "%s%s", RTE_RING_MZ_PREFIX, name);
//分配 struct rte_tailq_entry,用来将申请的ring挂到共享链表ring_list中
te = rte_zmalloc("RING_TAILQ_ENTRY", sizeof(*te), 0);
rte_rwlock_write_lock(RTE_EAL_TAILQ_RWLOCK);
//申请memzone,
/* reserve a memory zone for this ring. If we can't get rte_config or
* we are secondary process, the memzone_reserve function will set
* rte_errno for us appropriately - hence no check in this this function */
mz = rte_memzone_reserve_aligned(mz_name, ring_size, socket_id, mz_flags, __alignof__(*r));
if (mz != NULL) {
//memzone的的addr指向分配的内存,ring也从此内存开始
r = mz->addr;
/* no need to check return value here, we already checked the
* arguments above */
rte_ring_init(r, name, requested_count, flags);
//将ring保存到链表entry中
te->data = (void *) r;
r->memzone = mz;
//将链表entry插入链表ring_list
TAILQ_INSERT_TAIL(ring_list, te, next);
} else {
r = NULL;
RTE_LOG(ERR, RING, "Cannot reserve memory\n");
rte_free(te);
}
rte_rwlock_write_unlock(RTE_EAL_TAILQ_RWLOCK);
return r;
}
int
rte_ring_init(struct rte_ring *r, const char *name, unsigned count,
unsigned flags)
{
int ret;
/* compilation-time checks */
RTE_BUILD_BUG_ON((sizeof(struct rte_ring) &
RTE_CACHE_LINE_MASK) != 0);
RTE_BUILD_BUG_ON((offsetof(struct rte_ring, cons) &
RTE_CACHE_LINE_MASK) != 0);
RTE_BUILD_BUG_ON((offsetof(struct rte_ring, prod) &
RTE_CACHE_LINE_MASK) != 0);
/* init the ring structure */
memset(r, 0, sizeof(*r));
ret = snprintf(r->name, sizeof(r->name), "%s", name);
if (ret < 0 || ret >= (int)sizeof(r->name))
return -ENAMETOOLONG;
r->flags = flags;
r->prod.single = (flags & RING_F_SP_ENQ) ? __IS_SP : __IS_MP;
r->cons.single = (flags & RING_F_SC_DEQ) ? __IS_SC : __IS_MC;
if (flags & RING_F_EXACT_SZ) {
r->size = rte_align32pow2(count + 1);
r->mask = r->size - 1;
r->capacity = count;
} else {
if ((!POWEROF2(count)) || (count > RTE_RING_SZ_MASK)) {
RTE_LOG(ERR, RING,
"Requested size is invalid, must be power of 2, and not exceed the size limit %u\n",
RTE_RING_SZ_MASK);
return -EINVAL;
}
r->size = count;
r->mask = count - 1;
r->capacity = r->mask;
}
//初始时,生产者和消费者的首尾都为0
r->prod.head = r->cons.head = 0;
r->prod.tail = r->cons.tail = 0;
return 0;
}
入队操作
DPDK提供了如下几个api用来执行入队操作,它们最终都会调用__rte_ring_do_enqueue来实现,所以重点分析函数__rte_ring_do_enqueue。
//多生产者批量入队。入队个数n必须全部成功,否则入队失败。调用者明确知道是多生产者
rte_ring_mp_enqueue_bulk
//单生产者批量入队。入队个数n必须全部成功,否则入队失败。调用者明确知道是单生产者
rte_ring_sp_enqueue_bulk
//批量入队。入队个数n必须全部成功,否则入队失败。调用者不用关心是不是单生产者
rte_ring_enqueue_bulk
//多生产者批量入队。入队个数n不一定全部成功。调用者明确知道是多生产者
rte_ring_mp_enqueue_burst
//单生产者批量入队。入队个数n不一定全部成功。调用者明确知道是单生产者
rte_ring_sp_enqueue_burst
//批量入队。入队个数n不一定全部成功。调用者不用关心是不是单生产者
rte_ring_enqueue_burst
__rte_ring_do_enqueue主要做了三个事情:
a. 移动生产者head,此处在多生产者下可能会有冲突,需要使用cas操作循环检测,只有自己能移动head时才行。
b. 执行入队操作,将obj插入ring,从老的head开始,直到新head结束。
c. 更新生产者tail,只有这样消费者才能看到最新的消费对象。
其参数r指定了目标ring。
参数obj_table指定了入队对象。
参数n指定了入队对象个数。
参数behavior指定了入队行为,有两个值RTE_RING_QUEUE_FIXED和RTE_RING_QUEUE_VARIABLE,前者表示入队对象必须一次性全部成功,后者表示尽可能多的入队。
参数is_sp指定了是否为单生产者模式,默认为多生产者模式。
static __rte_always_inline unsigned int
__rte_ring_do_enqueue(struct rte_ring *r, void * const *obj_table,
unsigned int n, enum rte_ring_queue_behavior behavior,
int is_sp, unsigned int *free_space)
{
uint32_t prod_head, prod_next;
uint32_t free_entries;
//先移动生产者的头指针,prod_head保存移动前的head,prod_next保存移动后的head
n = __rte_ring_move_prod_head(r, is_sp, n, behavior,
&prod_head, &prod_next, &free_entries);
if (n == 0)
goto end;
//&r[1]指向存放对象的内存。
//从prod_head开始,将n个对象obj_table插入ring的prod_head位置
ENQUEUE_PTRS(r, &r[1], prod_head, obj_table, n, void *);
rte_smp_wmb();
//更新生产者tail
update_tail(&r->prod, prod_head, prod_next, is_sp);
end:
if (free_space != NULL)
*free_space = free_entries - n;
return n;
}
__rte_ring_move_prod_head用来使用cas操作更新生产者head。
static __rte_always_inline unsigned int
__rte_ring_move_prod_head(struct rte_ring *r, int is_sp,
unsigned int n, enum rte_ring_queue_behavior behavior,
uint32_t *old_head, uint32_t *new_head,
uint32_t *free_entries)
{
const uint32_t capacity = r->capacity;
unsigned int max = n;
int success;
do {
/* Reset n to the initial burst count */
n = max;
//获取生产者当前的head位置
*old_head = r->prod.head;
/* add rmb barrier to avoid load/load reorder in weak
* memory model. It is noop on x86
*/
rte_smp_rmb();
const uint32_t cons_tail = r->cons.tail;
/*
* The subtraction is done between two unsigned 32bits value
* (the result is always modulo 32 bits even if we have
* *old_head > cons_tail). So 'free_entries' is always between 0
* and capacity (which is < size).
*/
//获取空闲 entry 个数
*free_entries = (capacity + cons_tail - *old_head);
//如果入队的对象个数大于空闲entry个数,则如果入队要求固定大小,则入队失败,返回0,否则
//只入队空闲entry个数的对象
/* check that we have enough room in ring */
if (unlikely(n > *free_entries))
n = (behavior == RTE_RING_QUEUE_FIXED) ?
0 : *free_entries;
if (n == 0)
return 0;
//当前head位置加上入队对象个数获取新的生产者head
*new_head = *old_head + n;
//如果是单生产者,直接更新生产者head,并返回1
if (is_sp)
r->prod.head = *new_head, success = 1;
else //如果是多生产者,需要借助函数rte_atomic32_cmpset,比较old_head和r->prod.head是否相同,
//如果相同,则将r->prod.head更新为new_head,并返回1,退出循环,
//如果不相同说明有其他生产者更新head了,返回0,继续循环。
success = rte_atomic32_cmpset(&r->prod.head,
*old_head, *new_head);
} while (unlikely(success == 0));
return n;
}
ENQUEUE_PTRS定义了入队操作。
/* the actual enqueue of pointers on the ring.
* Placed here since identical code needed in both
* single and multi producer enqueue functions */
#define ENQUEUE_PTRS(r, ring_start, prod_head, obj_table, n, obj_type) do { \
unsigned int i; \
const uint32_t size = (r)->size; \
uint32_t idx = prod_head & (r)->mask; \
obj_type *ring = (obj_type *)ring_start; \
//idx+n 大于 size,说明入队n个对象后,ring还没满,还没翻转
if (likely(idx + n < size)) { \
//一次循环入队四个对象
for (i = 0; i < (n & ((~(unsigned)0x3))); i+=4, idx+=4) { \
ring[idx] = obj_table[i]; \
ring[idx+1] = obj_table[i+1]; \
ring[idx+2] = obj_table[i+2]; \
ring[idx+3] = obj_table[i+3]; \
} \
//还有剩余不满四个对象,则在switch里入队
switch (n & 0x3) { \
case 3: \
ring[idx++] = obj_table[i++]; /* fallthrough */ \
case 2: \
ring[idx++] = obj_table[i++]; /* fallthrough */ \
case 1: \
ring[idx++] = obj_table[i++]; \
} \
} else { \
//入队n个对象,会导致ring满,发生翻转,
//则先入队idx到size的位置,
for (i = 0; idx < size; i++, idx++)\
ring[idx] = obj_table[i]; \
//再翻转回到ring起始位置,入队剩余的对象
for (idx = 0; i < n; i++, idx++) \
ring[idx] = obj_table[i]; \
} \
} while (0)
最后更新生产者tail。
static __rte_always_inline void
update_tail(struct rte_ring_headtail *ht, uint32_t old_val, uint32_t new_val,
uint32_t single)
{
/*
* If there are other enqueues/dequeues in progress that preceded us,
* we need to wait for them to complete
*/
if (!single)
//多生产者时,必须等到其他生产者入队成功,再更新自己的tail
while (unlikely(ht->tail != old_val))
rte_pause();
ht->tail = new_val;
}
出队操作
DPDK提供了如下几个api用来执行出队操作,它们最终都会调用__rte_ring_do_dequeue来实现,所以重点分析函数__rte_ring_do_dequeue。
//多消费者批量出队。出队个数n必须全部成功,否则出队失败。调用者明确知道是多消费者
rte_ring_mc_dequeue_bulk
//单消费者批量出队。出队个数n必须全部成功,否则出队失败。调用者明确知道是单消费者
rte_ring_sc_dequeue_bulk
//批量出队。出队个数n必须全部成功,否则出队失败。调用者不用关心是不是单消费者
rte_ring_dequeue_bulk
//多消费者批量出队。出队个数n不一定全部成功。调用者明确知道是多消费者
rte_ring_mc_dequeue_burst
//单消费者批量出队。出队个数n不一定全部成功。调用者明确知道是单消费者
rte_ring_sc_dequeue_burst
//批量出队。出队个数n不一定全部成功。调用者不用关心是不是单消费者
rte_ring_dequeue_burst
__rte_ring_do_dequeue主要做了三个事情:
a. 移动消费者head,此处在多消费者下可能会有冲突,需要使用cas操作循环检测,只有自己能移动head时才行。
b. 执行出队操作,将ring中的obj插入obj_table,从老的head开始,直到新head结束。
c. 更新消费者tail,只有这样生成者才能进行生产。
其参数r指定了目标ring。
参数obj_table指定了出队对象出队后存放位置。
参数n指定了入队对象个数。
参数behavior指定了出队行为,有两个值RTE_RING_QUEUE_FIXED和RTE_RING_QUEUE_VARIABLE,前者表示出队对象必须一次性全部成功,后者表示尽可能多的出队。
参数is_sp指定了是否为单消费者模式,默认为多消费者模式。
static __rte_always_inline unsigned int
__rte_ring_do_dequeue(struct rte_ring *r, void **obj_table,
unsigned int n, enum rte_ring_queue_behavior behavior,
int is_sc, unsigned int *available)
{
uint32_t cons_head, cons_next;
uint32_t entries;
//先移动消费者head,成功后,cons_head为老的head,cons_next为新的head,
//两者之间的部分为此次可消费的对象
n = __rte_ring_move_cons_head(r, is_sc, n, behavior,
&cons_head, &cons_next, &entries);
if (n == 0)
goto end;
//执行出队操作,从老的cons_head开始出队n个对象
DEQUEUE_PTRS(r, &r[1], cons_head, obj_table, n, void *);
rte_smp_rmb();
//更新消费者tail,和前面更新生产者head代码相同
update_tail(&r->cons, cons_head, cons_next, is_sc);
end:
if (available != NULL)
*available = entries - n;
return n;
}
__rte_ring_move_cons_head用来使用cas操作更新消费者head。
static __rte_always_inline unsigned int
__rte_ring_move_cons_head(struct rte_ring *r, int is_sc,
unsigned int n, enum rte_ring_queue_behavior behavior,
uint32_t *old_head, uint32_t *new_head,
uint32_t *entries)
{
unsigned int max = n;
int success;
/* move cons.head atomically */
do {
/* Restore n as it may change every loop */
n = max;
//取出当前head位置
*old_head = r->cons.head;
/* add rmb barrier to avoid load/load reorder in weak
* memory model. It is noop on x86
*/
rte_smp_rmb();
//生产者tail减去消费者head为可消费的对象个数。
//因为head和tail都是无符号32位类型,即使生产者tail比消费者head
//小,也能正确得出结果,不用担心溢出。
const uint32_t prod_tail = r->prod.tail;
/* The subtraction is done between two unsigned 32bits value
* (the result is always modulo 32 bits even if we have
* cons_head > prod_tail). So 'entries' is always between 0
* and size(ring)-1. */
*entries = (prod_tail - *old_head);
//要求出队对象个数大于实际可消费对象个数
/* Set the actual entries for dequeue */
if (n > *entries)
//此时如果behavior为RTE_RING_QUEUE_FIXED,表示必须满足n,满足不了就一个都不出队,返回0,
//如果不为RTE_RING_QUEUE_FIXED,则尽可能多的出队
n = (behavior == RTE_RING_QUEUE_FIXED) ? 0 : *entries;
if (unlikely(n == 0))
return 0;
//当前head加上n即为新的消费者head
*new_head = *old_head + n;
if (is_sc)
//如果单消费者,直接更新head即可,返回1
r->cons.head = *new_head, success = 1;
else
//多消费者,需要借用rte_atomic32_cmpset更新head
success = rte_atomic32_cmpset(&r->cons.head, *old_head,
*new_head);
} while (unlikely(success == 0));
return n;
}
ring是否满或者是否为空
函数rte_ring_full用来判断ring是否满
static inline int
rte_ring_full(const struct rte_ring *r)
{
return rte_ring_free_count(r) == 0;
}
static inline unsigned
rte_ring_free_count(const struct rte_ring *r)
{
return r->capacity - rte_ring_count(r);
}
函数rte_ring_empty用来判断ring是否为空
static inline int
rte_ring_empty(const struct rte_ring *r)
{
return rte_ring_count(r) == 0;
}
判断ring是否为空或者是否满都需要调用rte_ring_count获取当前ring中已使用的个数。
static inline unsigned
rte_ring_count(const struct rte_ring *r)
{
uint32_t prod_tail = r->prod.tail;
uint32_t cons_tail = r->cons.tail;
uint32_t count = (prod_tail - cons_tail) & r->mask;
return (count > r->capacity) ? r->capacity : count;
}
参考
http://doc.dpdk.org/guides/prog_guide/ring_lib.html
https://www.cnblogs.com/jungle1996/p/12194243.html
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法