TensorFlow变量管理-tf.get_variable和tf.variable_scope_tf.global_variables csdn-程序员宅基地
技术标签: 变量管理 机器学习 深度学习 MNIST TensorFlow
本文代码可在https://github.com/TimeIvyace/MNIST-TensorFlow.git中下载,程序名为train_improved1.py。
当编写程序较长时,文件中定义的函数的输入参数可能会很多,例如神经网络的参数:
def inference(input_tensor, avg_class, weights1, biases1, weights2, biases2):
当神经网络的结构更加复杂、参数更多时,就需要一个更好的方式来传递和管理神经网络中的参数。
TensorFlow就提供了通过变量名来创建或获取变量的机制,可以使用***tf.get_variable***和***tf.variable_scope***函数来实现。
TensorFlow中除了通过***tf.Variable***来创建变量,还可以使用***tf.get_variable***来创建或者获取变量。当创建变量时,两个函数基本是等价的,例如:
#下面两行代码功能相同
v = tf.get_variable("v", shape[1], initializer=tf.constant_initializer(1.0))
v = tf.Variable(tf.constant(1.0, shape=[1]), name="v")
可看出***tf.get_variable***函数调用时的维度以及初始化和***tf.Variable***类似,就像常数初始化函数***tf.constant_initializer***和常数生成函数***tf.constant***功能上是一致的。TensorFlow提供了七种不同的参数初始化函数:
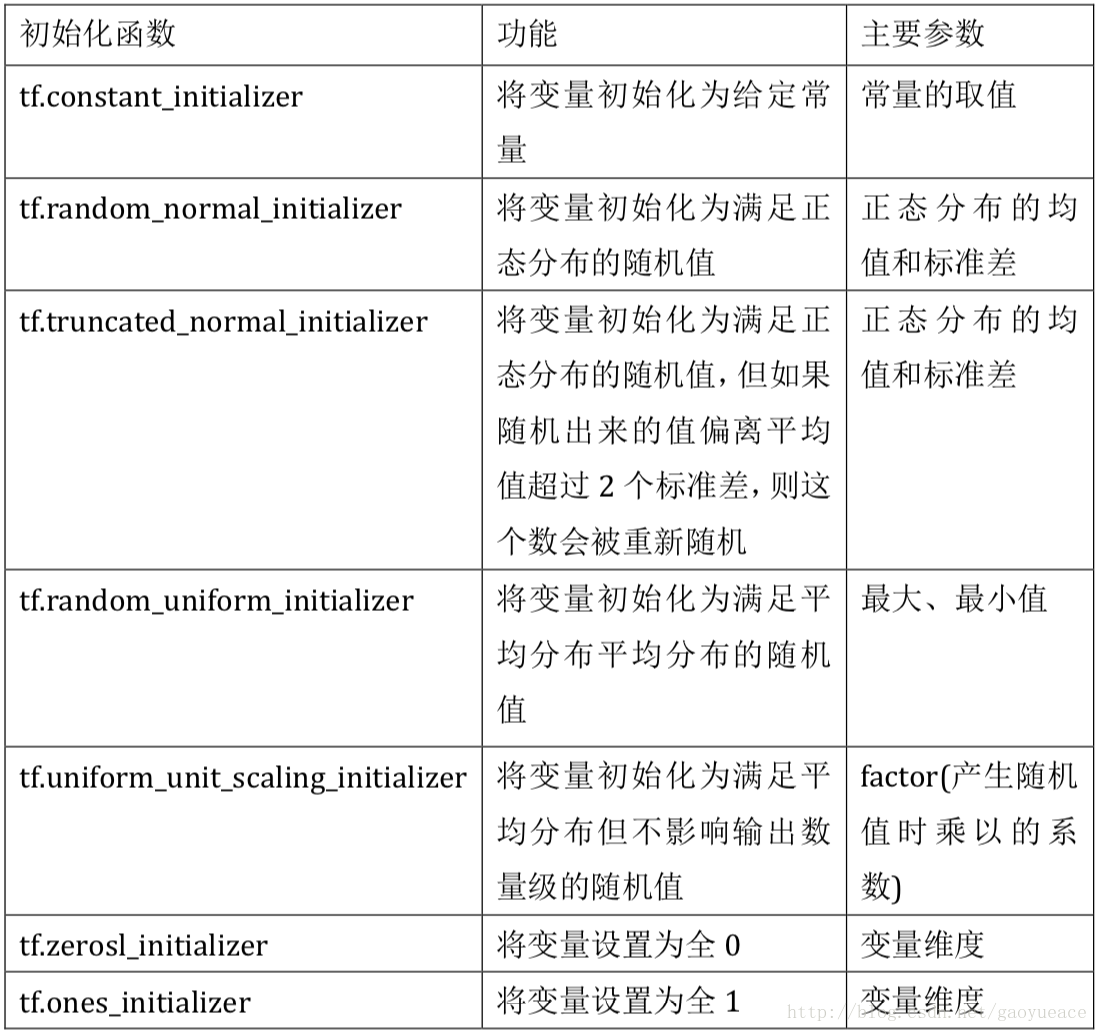
***tf.get_variable***和***tf.Variable***最大的不同在于变量名称,***tf.Variable***中的变量名称是一个可选的参数,通过name=""给出;而在***tf.get_variable***函数中,变量名称是必填的一个参数。当上述代码***tf.get_variable***创建名字为v的参数时,若已经有同名的参数,则会创建失败。但是,可以通过***tf.get_variable***来获取一个已经创建的变量,这是需要使用***tf.variable_scope***函数实现,***tf.variable_scope***会生成一个上下文管理器,并明确指定在这个上下文管理器中,***tf.get_variable***将直接获得已经生成的变量。例如:
import tensorflow as tf
#在名字为foo的命名空间内创建名字为v的变量
with tf.variable_scope("foo"):
v = tf.get_variable("v", [1], initializer=tf.constant_initializer(1.0))
#因为在命名空间foo中已经存在名字为v的变量,所以下面代码会报错
# with tf.variable_scope("foo"):
# v = tf.get_variable("v", [1])
#在生成上下文管理器时,将参数reuse设置为True
# 这样tf.get_variable函数将直接获取已经声明的变量
with tf.variable_scope("foo", reuse=True):
v1 = tf.get_variable("v", [1])
print(v==v1) #输出为True, 代表v,v1是相同的TensorFlow变量
>>True
可以看出,当***tf.variable_scope***使用参数reuse=True生成上下文管理器时,这个上下文管理器内所有的***tf.get_variable***会直接获取已经创建的变量。如果变量不存在,则会报错;但是若reuse=False或None时,***tf.get_variable***会创建新的变量,如果同名参数存在则会报错。
TensorFlow中***tf.variable_scope***函数是可以嵌套的,例如:
with tf.variable_scope("root"):
#可以通过tf.get_variable_scope().reuse来获取当前上下文管理器中reuse的取值
print(tf.get_variable_scope().reuse)
with tf.variable_scope("foo", reuse=True):
#新建嵌套的上下文管理器,指定reuse
print(tf.get_variable_scope().reuse)
with tf.variable_scope("bar"):
#再新建一个嵌套的上下文管理器,若不指定reuse,则和上一层一致
print(tf.get_variable_scope().reuse)
#退出reuse为True的上下文后,reuse恢复为False
print(tf.get_variable_scope().reuse)
>>False
True
True
False
***tf.variable_scope***函数生成的上下文管理器会创建一个命名空间,可以来管理变量,例如以下代码:
v1 = tf.get_variable("v", [1])
print(v1.name)
#输出v:0, "v"为变量的名称,":0"表示这个变量是生成变量这个运算的第一个结果
with tf.variable_scope("foo"):
v2 = tf.get_variable("v", [1])
print(v2.name)
#输出foo/v:0
#在tf.variable_scope中创建的变量,会加入命名空间的名称
#通过/来分隔命名空间的名称和变量的名称
with tf.variable_scope("foo"):
with tf.variable_scope("bar"):
v3 = tf.get_variable("v", 1)
print(v3.name) #命名空间可以嵌套
v4 = tf.get_variable("v1", [1])
print(v4.name) #当命名空间退出之后,变量名称就不会再加前缀
#创建一个名称为空的命名空间
with tf.variable_scope("", reuse=True):
v5 = tf.get_variable("foo/bar/v", [1])
#可以直接通过带命名空间名称的变量名来获取其他命名空间下的变量
print(v5 == v3)
v6 = tf.get_variable("foo/v1", [1])
print(v6 == v4)
>>v:0
foo/v:0
foo/bar/v:0
foo/v1:0
True
True
通过***tf.variable_scope***和***tf.get_variable***函数,可以对此链接里的神经网络中的计算前向传播结果的函数做一些改进,提高代码的可读性。如下:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
INPUT_NODE = 784 #输入层的节点数,图片为28*28,为图片的像素
OUTPUT_NODE = 10 #输出层的节点数,等于类别的数目,需要区分0-9,所以为10类
#配置神经网络的参数
LAYER1_NODE = 500 #隐藏层的节点数,此神经网络只有一层隐藏层
BATCH_SIZE = 100 #一个训练batch中的训练数据个数,数字越小,越接近随机梯度下降,越大越接近梯度下降
LEARNING_RATE_BASE = 0.8 #基础的学习率
LEARNING_RATE_DECAY = 0.99 #学习率的衰减率
REGULARIZATION_RATE = 0.0001 #描述网络复杂度的正则化向在损失函数中的系数
TRAINING_STEPS = 30000 #训练轮数
MOVING_AVERAGE_DECAY = 0.99 #滑动平均衰减率
#给定神经网络的输入和所有参数,计算神经网络的前向传播结果,定义了一个使用ReLU的三层全连接神经网络,通过加入隐藏层实现了多层网络结构
def inference(input_tensor, avg_class, reuse=False):
#定义第一层神经网络的变量和前向传播结果
with tf.variable_scope("layer1", reuse=reuse):
#根据传进来的reuse来判断是创建新变量还是使用已经创建好的
#在第一次构造网络时需要创建新的变量,以后每次调用这个函数都直接使用reuse=True就不需要每次传入变量了
weights = tf.get_variable("weights", [INPUT_NODE, LAYER1_NODE],
initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases", [LAYER1_NODE], initializer=tf.constant_initializer(0.1))
# 若没有提供滑动平均类,则直接使用参数当前的取值
if avg_class == None:
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights)+biases)
else:
layer1 = tf.nn.relu(tf.matmul(input_tensor, avg_class.average(weights)) + avg_class.average(biases))
#定义第二层神经网络的变量和前向传播过程
with tf.variable_scope("layer2", reuse=reuse):
weights = tf.get_variable("weights", [LAYER1_NODE, OUTPUT_NODE],
initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases", [OUTPUT_NODE], initializer=tf.constant_initializer(0.1))
if avg_class == None:
layer2 = tf.matmul(layer1, weights)+biases
else:
layer2 = tf.matmul(layer1, avg_class.average(weights))+avg_class.average(biases)
#返回最后的前向传播结果
return layer2
#训练网络的过程
def train(mnist):
x = tf.placeholder(tf.float32, [None, INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE], name='y-input')
#计算在当前参数下神经网络前向传播的结果,这里的用于计算滑动平均的类为None,所以没有使用滑动平均值
y = inference(x, None)
#在程序中需要使用训练好的神经网络进行推导时,可直接调用inference(new_x, variable_averages, True)
#定义存储训练轮数的变量,这个变量不需要被训练
global_step = tf.Variable(0, trainable=False)
#初始化滑动平均类
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
#在所有代表神经网络参数的变量上使用滑动平均,需要被训练的参数,variable_averages返回的就是GraphKeys.TRAINABLE_VARIABLES中的元素
variable_averages_op = variable_averages.apply(tf.trainable_variables())
#计算使用了滑动平均之后的前向传播结果,滑动平均不会改变变量本身取值,会用一个影子变量来记录
average_y = inference(x, variable_averages, True)
#计算交叉熵,使用了sparse_softmax_cross_entropy_with_logits,当问题只有一个正确答案时,可以使用这个函数来加速交叉熵的计算。
#这个函数的第一个参数是神经网络不包括softmax层的前向传播结果,第二个是训练数据的正确答案,argmax返回最大值的位置
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
#计算在当前batch中所有样例的交叉熵平均值
cross_entropy_mean = tf.reduce_mean(cross_entropy)
#计算L2正则化损失
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
with tf.variable_scope("", reuse=True):
weights1 = tf.get_variable("layer1/weights", [INPUT_NODE, LAYER1_NODE])
weights2 = tf.get_variable("layer2/weights", [LAYER1_NODE, OUTPUT_NODE])
#计算网络的正则化损失
regularization = regularizer(weights1) + regularizer(weights2)
#总损失为交叉熵损失和正则化损失之和
loss = cross_entropy_mean + regularization
#设置指数衰减的学习率
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step,
mnist.train.num_examples/BATCH_SIZE, LEARNING_RATE_DECAY)
#LEARNING_RATE_BASE为基础学习率,global_step为当前迭代的次数
#mnist.train.num_examples/BATCH_SIZE为完整的过完所有的训练数据需要的迭代次数
#LEARNING_RATE_DECAY为学习率衰减速度
#使用GradientDescentOptimizer优化算法优化损失函数
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
#在训练神经网络的时候,每过一遍数据都要通过反向传播来更新参数以及其滑动平均值
# 为了一次完成多个操作,可以通过tf.control_dependencies和tf.group两种机制来实现
# train_op = tf.group(train_step, variable_averages_op) #和下面代码功能一样
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name = 'train')
#检验使用了滑动平均模型的神经网络前向传播结果是否正确
#f.argmax(average_y, 1)计算了每一个样例的预测答案,得到的结果是一个长度为batch的一维数组
#一维数组中的值就表示了每一个样例对应的数字识别结果
#tf.equal判断两个张量的每一维是否相等。如果相等返回True,反之返回False
correct_prediction = tf.equal(tf.argmax(average_y, 1), tf.argmax(y_, 1))
#首先将一个布尔型的数组转换为实数,然后计算平均值
#平均值就是网络在这一组数据上的正确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#初始会话并开始训练过程
with tf.Session() as sess:
tf.global_variables_initializer().run() #参数初始化
#准备验证数据,在神经网络的训练过程中,会通过验证数据来大致判断停止的条件和评判训练的效果
validate_data = {x: mnist.validation.images, y_:mnist.validation.labels}
#准备测试数据
test_data = {x:mnist.test.images, y_:mnist.test.labels}
#迭代的训练神经网络
for i in range(TRAINING_STEPS):
#每1000轮输出一次在验证数据集上的测试结果
if i%1000==0:
#计算滑动平均模型在验证数据上的结果,因为MNIST数据集较小,所以可以一次处理所有的验证数据
validate_acc = sess.run(accuracy, feed_dict=validate_data)
print("After %d training steps, validation accuracy using average model is %g"
%(i, validate_acc))
# 产生训练数据batch,开始训练
xs, ys = mnist.train.next_batch(BATCH_SIZE) # xs为数据,ys为标签
sess.run(train_op, feed_dict={x:xs, y_:ys})
test_acc = sess.run(accuracy, feed_dict=test_data)
print("After %d training steps, validation accuracy using average model is %g"
%(TRAINING_STEPS, test_acc))
#程序主入口
def main(argv=None):
# 声明处理MNIST数据集的类,one_hot=True将标签表示为向量形式
mnist = input_data.read_data_sets("/Users/gaoyue/文档/Program/tensorflow_google/chapter5", one_hot=True)
train(mnist)
#TensorFlow提供程序主入口,tf.app.run会调用上面定义的main函数
if __name__ =='__main__':
tf.app.run()
智能推荐
计算机丢失concrt140,小编教你解决concrt140 dll 【解决教程】 的技巧_-程序员宅基地
文章浏览阅读4.5w次。近日有小伙伴发现电脑出现问题了,在突然遇到concrt140 dll时不知所措了,对于concrt140 dll带来的问题,其实很好解决concrt140 dll带来的问题,下面小编跟大家介绍concrt140 dll解决方法:丢失CONCRT140.dll,怎么办?答:分析及解决:网上下载这个DLL文件,将其放置到system32目录下面。 重启系统,或者在CMD下面运行regsvr32*.dl..._concrt140.dll下载教程
微信小程序源码案例大全_微信小程序switch页面demo-程序员宅基地
文章浏览阅读4.3k次,点赞4次,收藏62次。微信小程序demo:足球,赛事分析 小程序简易导航 小程序demo:办公审批 小程序Demo:电魔方 小程序demo:借阅伴侣 微信小程序demo:投票 微信小程序demo:健康生活 小程序demo:文章列表demo 微商城(含微信小程序)完整源码+配置指南 微信小程序Demo:一个简单的工作系统 微信小程序Demo:用于聚会的小程序 微信小程序Demo:Growth 是一款..._微信小程序switch页面demo
SLAM学习笔记(Code2)----刚体运动、Eigen库_eigen.determinant-程序员宅基地
文章浏览阅读2.2k次。2.1除了#include<iostream>之外的头文件#include <Eigen/Core>//Core:核心#include <Eigen/Dense>//求矩阵的逆、特征值、行列式等#include <Eigen/Geometry>//Eigen的几何模块,可以利用矩阵完成如旋转、平移/***其他***/#include <ctime>//可用于计时,比较哪个程序更快#include <cmath>//包含a_eigen.determinant
图像梯度-sobel算子-程序员宅基地
文章浏览阅读1w次,点赞12次,收藏61次。(1)理论部分x 水平方向的梯度, 其实也就是右边 - 左边,有的权重为1,有的为2 。若是计算出来的值很大 说明是一个边界 。y 竖直方向的梯度,其实也就是下面减上面,权重1,或2 。若是计算出来的值很大 说明是一个边界 。图像的梯度为:有时简化为:即:(2)程序部分函数:Sobelddepth 通常取 -1,但是会导致结果溢出,检测不出边缘,故使..._sobel算子
cuda10.1和cudnn7.6.5百度网盘下载链接(Linux版)_cudnn7.6网盘下载-程序员宅基地
文章浏览阅读3.6k次,点赞17次,收藏8次。cuda10.1和cudnn7.6.5百度网盘下载链接(Linux版)在官网下载不仅慢,,,主要是还总失败。。终于下载成功了,这里给出百度网盘下载链接,希望可以帮到别人百度网盘下载链接提取码: vyg5_cudnn7.6网盘下载
Python正则表达式大全-程序员宅基地
文章浏览阅读9.3w次,点赞69次,收藏427次。定义:正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。上面都是官方的说明,我自己的理解是(仅供参考):通过事先规定好一些特殊字符的匹配规则,然后利用这些字符进行组合来匹配各种复杂的字符串场景。比如现在的爬虫和数据分析,字符串校验等等都需要用_python正则表达式
随便推点
NILM(非侵入式电力负荷监测)学习笔记 —— 准备工作(一)配置环境NILMTK Toolkit_nilmtk学习-程序员宅基地
文章浏览阅读1.9w次,点赞27次,收藏122次。安装Anaconda,Python,pycharm我另一篇文章里面有介绍https://blog.csdn.net/wwb1990/article/details/103883775安装NILMTK有了上面的环境,接下来进入正题。NILMTK官网:http://nilmtk.github.io/因为官方安装流程是基于linux的(官方安装流程),我这里提供windows..._nilmtk学习
k8s-pod 控制器-程序员宅基地
文章浏览阅读826次,点赞20次,收藏28次。如果实际 Pod 数量比指定的多那就结束掉多余的,如果实际数量比指定的少就新启动一些Pod,当 Pod 失败、被删除或者挂掉后,RC 都会去自动创建新的 Pod 来保证副本数量,所以即使只有一个 Pod,我们也应该使用 RC 来管理我们的 Pod。label 与 selector 配合,可以实现对象的“关联”,“Pod 控制器” 与 Pod 是相关联的 —— “Pod 控制器”依赖于 Pod,可以给 Pod 设置 label,然后给“控制器”设置对应的 selector,这就实现了对象的关联。
相关工具设置-程序员宅基地
文章浏览阅读57次。1. ultraEdit设置禁止自动更新: 菜单栏:高级->配置->应用程序布局->其他 取消勾选“自动检查更新”2.xshell 传输文件中设置编码,防止乱码: 文件 -- 属性 -- 选项 -- 连接 -- 使用UTF-8编码3.乱码修改:修改tomcat下配置中,修改: <Connector connectionTimeou..._高级-配置-应用程序布局
ico引入方法_arco的ico怎么导入-程序员宅基地
文章浏览阅读1.2k次。打开下面的网站后,挑选要使用的,https://icomoon.io/app/#/select/image下载后 解压 ,先把fonts里面的文件复制到项目fonts文件夹中去,然后打开其中的style.css文件找到类似下面的代码@font-face {font-family: ‘icomoon’;src: url(’…/fonts/icomoon.eot?r069d6’);s..._arco的ico怎么导入
Microsoft Visual Studio 2010(VS2010)正式版 CDKEY_visual_studio_2010_professional key-程序员宅基地
文章浏览阅读1.9k次。Microsoft Visual Studio 2010(VS2010)正式版 CDKEY / SN:YCFHQ-9DWCY-DKV88-T2TMH-G7BHP企业版、旗舰版都适用推荐直接下载电驴资源的vs旗舰版然后安装,好用方便且省时!) MSDN VS2010 Ultimate 简体中文正式旗舰版破解版下载(附序列号) visual studio 2010正_visual_studio_2010_professional key
互联网医疗的定义及架构-程序员宅基地
文章浏览阅读3.2k次,点赞2次,收藏17次。导读:互联网医疗是指综合利用大数据、云计算等信息技术使得传统医疗产业与互联网、物联网、人工智能等技术应用紧密集合,形成诊前咨询、诊中诊疗、诊后康复保健、慢性病管理、健康预防等大健康生态深度..._线上医疗的定义