OpenAI的人工智能语音识别模型Whisper详解及使用_ai虚拟老师语音识别-程序员宅基地
技术标签: 音视频处理 深度学习 pytorch whisper AI数字人技术 语音识别
1 whisper介绍
拥有ChatGPT语言模型的OpenAI公司,开源了 Whisper 自动语音识别系统,OpenAI 强调 Whisper 的语音识别能力已达到人类水准。
Whisper是一个通用的语音识别模型,它使用了大量的多语言和多任务的监督数据来训练,能够在英语语音识别上达到接近人类水平的鲁棒性和准确性。Whisper还可以进行多语言语音识别、语音翻译和语言识别等任务。Whisper的架构是一个简单的端到端方法,采用了编码器-解码器的Transformer模型,将输入的音频转换为对应的文本序列,并根据特殊的标记来指定不同的任务。
Whisper 是一个自动语音识别(ASR,Automatic Speech Recognition)系统,OpenAI 通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask)监督数据对 Whisper 进行了训练。OpenAI 认为使用这样一个庞大而多样的数据集,可以提高对口音、背景噪音和技术术语的识别能力。除了可以用于语音识别,Whisper 还能实现多种语言的转录,以及将这些语言翻译成英语。OpenAI 开放模型和推理代码,希望开发者可以将 Whisper 作为建立有用的应用程序和进一步研究语音处理技术的基础。
代码地址:代码地址
2 whisper模型
2.1 使用数据集
Whisper模型是在68万小时标记音频数据的数据集上训练的,其中包括11.7万小时96种不同语言的演讲和12.5万小时从”任意语言“到英语的翻译数据。该模型利用了互联网生成的文本,这些文本是由其他自动语音识别系统(ASR)生成而不是人类创建的。该数据集还包括一个在VoxLingua107上训练的语言检测器,这是从YouTube视频中提取的短语音片段的集合,并根据视频标题和描述的语言进行标记,并带有额外的步骤来去除误报。
2.2 模型
主要采用的结构是编码器-解码器结构。
重采样:16000 Hz
特征提取方法:使用25毫秒的窗口和10毫秒的步幅计算80通道的log Mel谱图表示。
特征归一化:输入在全局内缩放到-1到1之间,并且在预训练数据集上具有近似为零的平均值。
编码器/解码器:该模型的编码器和解码器采用Transformers。
- 编码器的过程
编码器首先使用一个包含两个卷积层(滤波器宽度为3)的词干处理输入表示,使用GELU激活函数。
第二个卷积层的步幅为 2。
然后将正弦位置嵌入添加到词干的输出中,然后应用编码器 Transformer 块。
Transformers使用预激活残差块,编码器的输出使用归一化层进行归一化。
- 模型结构
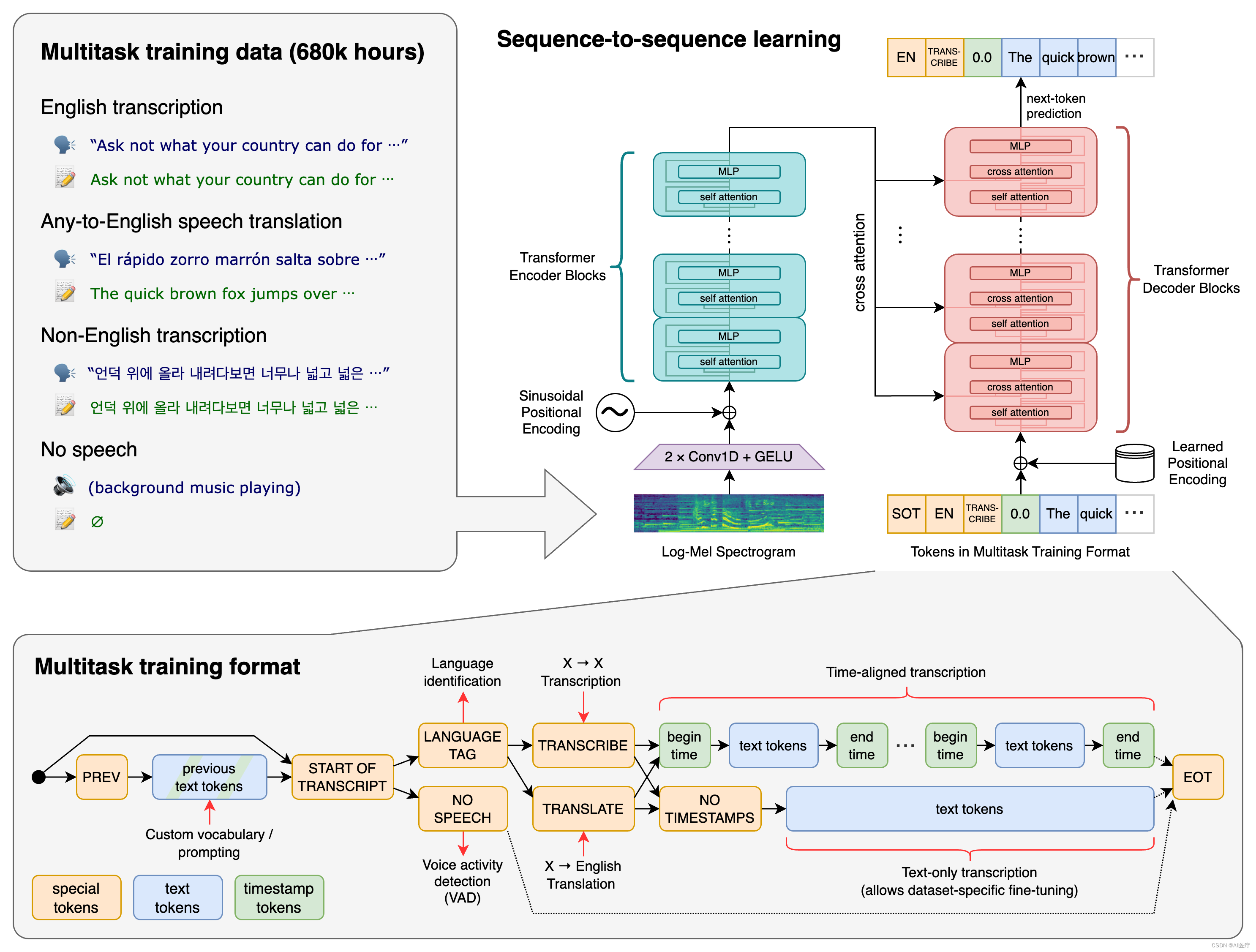
- 解码的过程
在解码器中,使用了学习位置嵌入和绑定输入输出标记表示。
编码器和解码器具有相同的宽度和数量的Transformers块。
2.3 训练
输入的音频被分割成 30 秒的小段、转换为 log-Mel 频谱图,然后传递到编码器。解码器经过训练以预测相应的文字说明,并与特殊的标记进行混合,这些标记指导单一模型执行诸如语言识别、短语级别的时间戳、多语言语音转录和语音翻译等任务。
相比目前市面上的其他现有方法,它们通常使用较小的、更紧密配对的「音频 - 文本」训练数据集,或使用广泛但无监督的音频预训练集。因为 Whisper 是在一个大型和多样化的数据集上训练的,而没有针对任何特定的数据集进行微调,虽然它没有击败专攻 LibriSpeech 性能的模型(著名的语音识别基准测试),然而在许多不同的数据集上测量 Whisper 的 Zero-shot(不需要对新数据集重新训练,就能得到很好的结果)性能时,研究人员发现它比那些模型要稳健得多,犯的错误要少 50%。
为了改进模型的缩放属性,它在不同的输入大小上进行了训练。
- 通过 FP16、动态损失缩放,并采用数据并行来训练模型。
- 使用AdamW和梯度范数裁剪,在对前 2048 次更新进行预热后,线性学习率衰减为零。
- 使用 256 个批大小,并训练模型进行 220次更新,这相当于对数据集进行两到三次前向传递。
由于模型只训练了几个轮次,过拟合不是一个重要问题,并且没有使用数据增强或正则化技术。这反而可以依靠大型数据集内的多样性来促进泛化和鲁棒性。
Whisper 在之前使用过的数据集上展示了良好的准确性,并且已经针对其他最先进的模型进行了测试。
2.4 优点
-
Whisper 已经在真实数据以及其他模型上使用的数据以及弱监督下进行了训练。
-
模型的准确性针对人类听众进行了测试并评估其性能。
-
它能够检测清音区域并应用 NLP 技术在转录本中正确进行标点符号的输入。
-
模型是可扩展的,允许从音频信号中提取转录本,而无需将视频分成块或批次,从而降低了漏音的风险。
-
模型在各种数据集上取得了更高的准确率。
Whisper在不同数据集上的对比结果,相比wav2vec取得了目前最低的词错误率
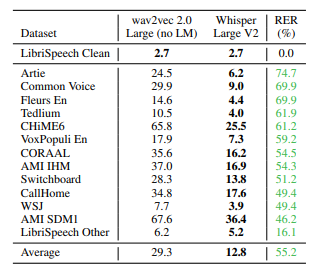
模型没有在timit数据集上进行测试,所以为了检查它的单词错误率,我们将在这里演示如何使用Whisper来自行验证timit数据集,也就是说使用Whisper来搭建我们自己的语音识别应用。
2.5 whisper的多种尺寸模型
whisper有五种模型尺寸,提供速度和准确性的平衡,其中English-only模型提供了四种选择。下面是可用模型的名称、大致内存需求和相对速度。

模型的官方下载地址:
"tiny.en": "https://openaipublic.azureedge.net/main/whisper/models/d3dd57d32accea0b295c96e26691aa14d8822fac7d9d27d5dc00b4ca2826dd03/tiny.en.pt",
"tiny": "https://openaipublic.azureedge.net/main/whisper/models/65147644a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9/tiny.pt",
"base.en": "https://openaipublic.azureedge.net/main/whisper/models/25a8566e1d0c1e2231d1c762132cd20e0f96a85d16145c3a00adf5d1ac670ead/base.en.pt",
"base": "https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt",
"small.en": "https://openaipublic.azureedge.net/main/whisper/models/f953ad0fd29cacd07d5a9eda5624af0f6bcf2258be67c92b79389873d91e0872/small.en.pt",
"small": "https://openaipublic.azureedge.net/main/whisper/models/9ecf779972d90ba49c06d968637d720dd632c55bbf19d441fb42bf17a411e794/small.pt",
"medium.en": "https://openaipublic.azureedge.net/main/whisper/models/d7440d1dc186f76616474e0ff0b3b6b879abc9d1a4926b7adfa41db2d497ab4f/medium.en.pt",
"medium": "https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt",
"large-v1": "https://openaipublic.azureedge.net/main/whisper/models/e4b87e7e0bf463eb8e6956e646f1e277e901512310def2c24bf0e11bd3c28e9a/large-v1.pt",
"large-v2": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",
"large": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",3 whisper环境构建及运行
3.1 conda环境安装
参见:annoconda安装
3.2 whisper环境构建
conda create -n whisper python==3.9
conda activate whisper
pip install openai-whisper
conda install ffmpeg
pip install setuptools-rust3.3 whisper命令行使用
whisper /opt/000001.wav --model base输出内容如下:
[00:00.000 --> 00:02.560] 人工智能识别系统。执行命令时,会自动进行模型下载,自动下载模型存储的路径如下:
~/.cache/whisper也可以通过命令行制定本地模型运行:
Whisper /opt/000001.wav --model base --model_dir /opt/models --language Chinese支持的文件格式:m4a、mp3、mp4、mpeg、mpga、wav、webm
3.4 whisper在代码中使用
import whisper
model = whisper.load_model("base")
result = model.transcribe("/opt/000001.wav")
print(result["text"])智能推荐
PCS7 入门指南 v9.0 SP3 v9.1 中文版 学习资料 (官方公开可用资料)_pcs7v9.1-程序员宅基地
文章浏览阅读1.8w次,点赞13次,收藏82次。链接:https://pan.baidu.com/s/1-p4h_QDL8BN04tnn3vSkOA提取码:nou3PCS7入门指南v9.0含APL(包含PDF和项目文件)官方地址:SIMATIC 过程控制系统 PCS 7 入门指南第1部分 (V9.0,含APL)https://support.industry.siemens.com/cs/document/109756196/simatic-%E8%BF%87%E7%A8%8B%E6%8E%A7%E5%88%B6%E7%B3%BB..._pcs7v9.1
c# 调用非托管代码_c# 声明kernel32 函数-程序员宅基地
文章浏览阅读956次,点赞3次,收藏5次。编程过程中,一般c#调用非托管的代码有两种方式:1.直接调用从DLL中导出的函数。2.调用COM对象上的接口方法。首先说明第1种方式,基本步骤如下:1.使用关键字static,extern声明需要导出的函数。2.把DllImport 属性附加到函数上。3.掌握常用的数据类型传递的对应关系。4.如果需要,为函数的参数和返回值指定自定义数据封送处理信息,这将重写.net framework默认的封送处理。简单举例如下:托管函数原型:DWORD GetShortPathName(LPCTST_c# 声明kernel32 函数
高频交易及化资策与区_hudson river trading-程序员宅基地
文章浏览阅读406次。转 高频交易及量化投资的策略与误区一、高频交易公司和量化投资公司的区别一般来说,高频交易公司和量化投资公司既有联系,又有区别。在美国,人们常说的高频交易公司一般都是自营交易公司,这些公司主要有Getco、Tower Research、Hudson River Trading、SIG、Virtu Financial、Jump Trading、RGM Advisor、Chopper Tradi..._hudson river trading
C语言文件操作相关的函数_c语言与文件处理有关的函数-程序员宅基地
文章浏览阅读865次。文件的打开和关闭文件在读写之前应该先打开文件,在使用结束之后应该关闭文件。在编写程序的时候,在打开文件的同时,都会返回一个FILE*的指针变量指向该文件,也相当于建立了指针和文件 的关系。ANSIC 规定使用fopen函数来打开文件,fclose来关闭文件。FILE * fopen ( const char * filename, const char * mode ); int fcl..._c语言与文件处理有关的函数
java 无法读取文件_java 读取文件,无法显示文件内容,如何解决? 谢谢。-程序员宅基地
文章浏览阅读1.1k次。从来没见过进行文件读取写入时,在写入中需要随机数的,你读取文件就是从一个地方获取输入流,然后将这个输入流写到别的地方,根本不要随机数。给你一个示例://copyafiletoanotherfilebyusingFileReader/FileWriterimportjava.io.*;publicclassTFileRead{publicstaticvoidmain(S..._java复制文件文件没有内容显示
vue引入原生高德地图_前端引入原生地图-程序员宅基地
文章浏览阅读556次,点赞2次,收藏3次。由于工作上的需要,今天捣鼓了半天高德地图。如果定制化开发需求不太高的话,可以用vue-amap,这个我就不多说了,详细就看官网 https://elemefe.github.io/vue-amap/#/zh-cn/introduction/install然而我们公司需要英文版的高德,我看vue-amap中好像没有这方面的配置,而且还有一些其他的定制化开发需求,然后就只用原生的高德。其实原生的引入也不复杂,但是有几个坑要填一下。1. index.html注意,引入的高德js一定要放在头部而_前端引入原生地图
随便推点
优化算法——拟牛顿法之BFGS算法-程序员宅基地
文章浏览阅读6.2w次,点赞25次,收藏188次。一、BFGS算法简介 BFGS算法是使用较多的一种拟牛顿方法,是由Broyden,Fletcher,Goldfarb,Shanno四个人分别提出的,故称为BFGS校正。 同DFP校正的推导公式一样,DFP校正见博文“优化算法——拟牛顿法之DFP算法”。对于拟牛顿方程:可以化简为:令,则可得:在B_bfgs算法
联想RD430服务器的Raid 5阵列+Esxi6.7部署_esxi6 raid m5015-程序员宅基地
文章浏览阅读3.9k次。一、主要解决的问题:(一)硬盘存储总容量提高+读写速率快1、原RD430服务器主板自带阵列卡仅支持Raid 0、Raid 1、Raid 10,主要特点:Raid 0速率快但是某一块硬盘物理故障后,所有数据都将丢失;Raid 1需要一半的硬盘做冗余,容量牺牲较多,速率比Raid 0降一倍。Raid 10容量牺牲一半,速率比Raid1稍快。2、独立阵列卡的Raid 5特点:Raid 5改进的特点:比如8个硬盘做成的阵列,总容量少1块硬盘的空间,某数据分布于不同的7个硬盘上,另1块硬盘进行数据校验,校验_esxi6 raid m5015
Linux安全应用2-程序员宅基地
文章浏览阅读59次。[root@localhost 桌面]# service NetworkManager stop[root@localhost 桌面]# chkconfig NetworkManager off[root@localhost 桌面]# setup[root@localhost 桌面]# vim /etc/udev/rules.d/70-persistent-net.rules..._linux本地安全2
深度篇——人脸识别(一) ArcFace 论文 翻译_arcface论文-程序员宅基地
文章浏览阅读6.6k次,点赞23次,收藏120次。返回主目录返回 目标检测史 目录上一章:深度篇——目标检测史(八)CPTN 论文 翻译论文地址:《ArcFace: Additive Angular Margin Loss for Deep Face Recognition》源码地址:InsightFace: 2D and 3D Face Analysis Project本小节,ArcFace 论文 翻译,下一小节细说 ArcFace文本检测 代码一.ArcFace 论文 翻译1.概述..._arcface论文
台式计算机有没有无线连接模块,台式机能不能连接wifi_台式机怎么连接wifi-程序员宅基地
文章浏览阅读1.2k次。2016-12-30 09:54:26你好!很高兴为你解答,先将无线路由器接通电源,然后插上网线,将另一端插到你电脑上,等网络通了之后,你在IE浏览器上输入:192.168.1.1(这是一般无线路由器的IP,如果有特殊...2016-12-16 11:44:30手机系统问题,可能系统出现了问题,导致连接上了WiFi却无法上网。重启一下路由器试试,或者将路由器恢复一下出厂设置,然后重新拨号上网,并根..._计算机无线模块怎么看
OpenGLES编程思想-程序员宅基地
文章浏览阅读4.8k次。最近在看gles的reference,想多了解一下gles的底层,gles是opengl在khronos在嵌入式设备上的图形硬件的软件访问接口,很多东西和opengl似曾相似,但是和opengl又有很大的不同,最新的标准是gles3.2,标准文档非常长,如果不是写引擎没必要对每个接口烂熟于心,但是为了能够了解他,我对他的编程思想做个总结,最重要的是理解gles的设计思路,然后在使用的时候也必将容易找到相关接口。所以本文基本不会列出gles的每个接口,不会记录讲解每个接口,而是希望能够通过总结gles的设计思_gles