python 论坛自动发帖功能_python discuz发帖-程序员宅基地
技术标签: python网络爬虫
# -*- coding: utf-8 -*- """ @author: amtsing """ ''' Google翻译 ''' import execjs class Py4Js(): def __init__(self): self.ctx = execjs.compile(""" function TL(a) { var k = ""; var b = 406644; var b1 = 3293161072; var jd = "."; var $b = "+-a^+6"; var Zb = "+-3^+b+-f"; for (var e = [], f = 0, g = 0; g < a.length; g++) { var m = a.charCodeAt(g); 128 > m ? e[f++] = m : (2048 > m ? e[f++] = m >> 6 | 192 : (55296 == (m & 64512)
&& g + 1 < a.length && 56320 == (a.charCodeAt(g + 1) & 64512) ? (m = 65536 +
((m & 1023) << 10) + (a.charCodeAt(++g) & 1023), e[f++] = m >> 18 | 240, e[f++] = m >> 12 & 63 | 128) : e[f++] = m >> 12 | 224, e[f++] = m >> 6 & 63 | 128), e[f++] = m & 63 | 128) } a = b; for (f = 0; f < e.length; f++) a += e[f], a = RL(a, $b); a = RL(a, Zb); a ^= b1 || 0; 0 > a && (a = (a & 2147483647) + 2147483648); a %= 1E6; return a.toString() + jd + (a ^ b) }; function RL(a, b) { var t = "a"; var Yb = "+"; for (var c = 0; c < b.length - 2; c += 3) { var d = b.charAt(c + 2), d = d >= t ? d.charCodeAt(0) - 87 : Number(d), d = b.charAt(c + 1) == Yb ? a >>> d: a << d; a = b.charAt(c) == Yb ? a + d & 4294967295 : a ^ d } return a } """) def getTk(self, text): return self.ctx.call("TL", text) import urllib.request, urllib.parse def open_url(url): '''打开网页链接''' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64;rv:23.0)Gecko/20100101
Firefox/23.0'} req = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(req) data = response.read().decode('utf-8') return data def translate(content): '''定义翻译函数''' if len(content) > 4891: print("翻译的长度超过限制!!!") return # 获取tk值 if len(content) > 4891: print("翻译的长度超过限制!!!") return js = Py4Js() tk = js.getTk(content) # 对输入内容编码 content = urllib.parse.quote(content) url = "http://translate.google.cn/translate_a/single?client=t&sl=en&tl=zh-CN&hl=zh-CN&dt
=at&dt=bd&dt=ex&dt=ld&dt=md&dt=qca&dt=rw&dt=rm&dt=ss&dt=t&ie=UTF-8&oe=UTF-8&
source=bh&otf=1&ssel=0&tsel=0&kc=1&tk=%s&q=%s" % (tk, content)
# 返回值是一个多层嵌套列表的字符串形式,解析起来还相当费劲,写了几个正则,发现也很不理想, # 后来感觉,使用正则简直就是把简单的事情复杂化,这里直接切片就Ok了 result = open_url(url) end = result.find("\",") if end > 4: print(' '+ result[4:end]) output = (' '+ result[4:end]) return str(output) ''' 识别验证码 ''' import os import requests from PIL import Image,ImageGrab import pytesseract from collections import Counter,OrderedDict # def downimg(url): # '''下载图片''' # with open ('verifycodepage.jpg','wb') as f: # s = requests.Session() # response = s.get(url) # f.write(response.content) def acumulate_colors(image): '''对色彩像素进行统计''' img = Image.open(image) pixdata = img.load() # c = Counter() # print(pixdata) colors = {} for y in range(img.size[1]): for x in range(img.size[0]): #print(pixdata[x, y]) # c.update(pixdata[x, y]) if pixdata[x, y] in colors: colors[pixdata[x, y]] += 1 else: colors[pixdata[x, y]] = 1 colors = sorted(colors.items(),key=lambda d:d[1],reverse=True) # c = OrderedDict(c) # print (c.values()) print(colors[2][0]) return colors # def gray(): # '''灰度化''' # img = Image.open('verifycodepage.jpg') # img.convert('L').save('灰色图.jpg') ''' convert() 是图像实例对象的一个方法,接受一个 mode 参数,用以指定一种色彩模式,mode 的取值可以是如下几种: · 1 (1-bit pixels, black and white, stored with one pixel per byte) · L (8-bit pixels, black and white) · P (8-bit pixels, mapped to any other mode using a colour palette) · RGB (3x8-bit pixels, true colour) · RGBA (4x8-bit pixels, true colour with transparency mask) · CMYK (4x8-bit pixels, colour separation) · YCbCr (3x8-bit pixels, colour video format) · I (32-bit signed integer pixels) · F (32-bit floating point pixels) 怎么样,够丰富吧?其实如此之处,PIL 还有限制地支持以下几种比较少见的色彩模式: LA (L with alpha), RGBX (true colour with padding) and RGBa。 ''' def binary(image): '''二值化''' img = Image.open(image) pixdata = img.load() for y in range(img.size[1]): for x in range(img.size[0]): # if pixdata[x, y] != colors[0][0]: # pixdata[x, y] = (255,255,255) # else: # pixdata[x, y] = (0,0,0) if pixdata[x, y][0] < 115: pixdata[x, y] = (0, 0, 0)# 黑色 for y in range(img.size[1]): for x in range(img.size[0]): if pixdata[x, y][1] < 90: pixdata[x, y] = (0, 0, 0) for y in range(img.size[1]): for x in range(img.size[0]): if pixdata[x, y][2] > 120: pixdata[x, y] = (255, 255, 255)# 白色 img.save('2值.jpg') ''' red 必要参数;Integer类型。数值范围从 0 到 255,表示颜色的红色成份。 green 必要参数;Integer类型。数值范围从 0 到 255,表示颜色的绿色成份。 blue 必要参数;Integer类型。数值范围从 0 到 255,表示颜色的蓝色成份。 ''' def denoisepoint(n,opt_point=0): '''去噪点''' direction = [ [1, 1], [1, 0], [1, -1], [0, -1], [-1, -1], [-1, 0], [-1, 1], [0, 1] ] num = 0 # 操作数量 point = 0 # 噪点数 img = Image.open('2值.jpg') pix = img.load() # 像素值 size = img.size #图片大小 # print(size) for y in range(size[1]): for x in range(size[0]): num += 1 if pix[x, y][0] < n: nearpoint = 0 for (a, b) in direction: if (x+a>= 0 and x+a <= size[0]-1) and (y+b>= 0 and y+b <= size[1]-1): # 如果遇到边界外的点不处理 if pix[x + a, y + b][0] < n: nearpoint += 1 if nearpoint <= opt_point: pix[x, y] = (255, 255, 255, 255) point += 1 # 噪点数 img.save('无噪点.jpg') return (num, point) def img2string(): '''图像转验证码''' img = Image.open('无噪点.jpg') pytesseract.pytesseract.tesseract_cmd= 'C:\\Program Files(x86)\\Tesseract-OCR\\tesseract' captcha = pytesseract.image_to_string(img,lang='eng') print(captcha) return captcha ''' 自动发帖 ''' import requests import re from lxml import etree from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.action_chains import ActionChains from selenium.common.exceptions import NoSuchElementException import random import time import newspaper from PIL import Image def get_content(url,language): '''获取正文''' content = newspaper.Article(url, language) content.download() content.parse() return content login_url = "http://www.****.so/member.php?mod=logging&action=login" def login(login_url): '''模拟登陆''' headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/58.0.3026.3 Safari/537.36" } for key,value in headers.items(): webdriver.DesiredCapabilities.PHANTOMJS['phantomjs.page.customHeaders{}'.format
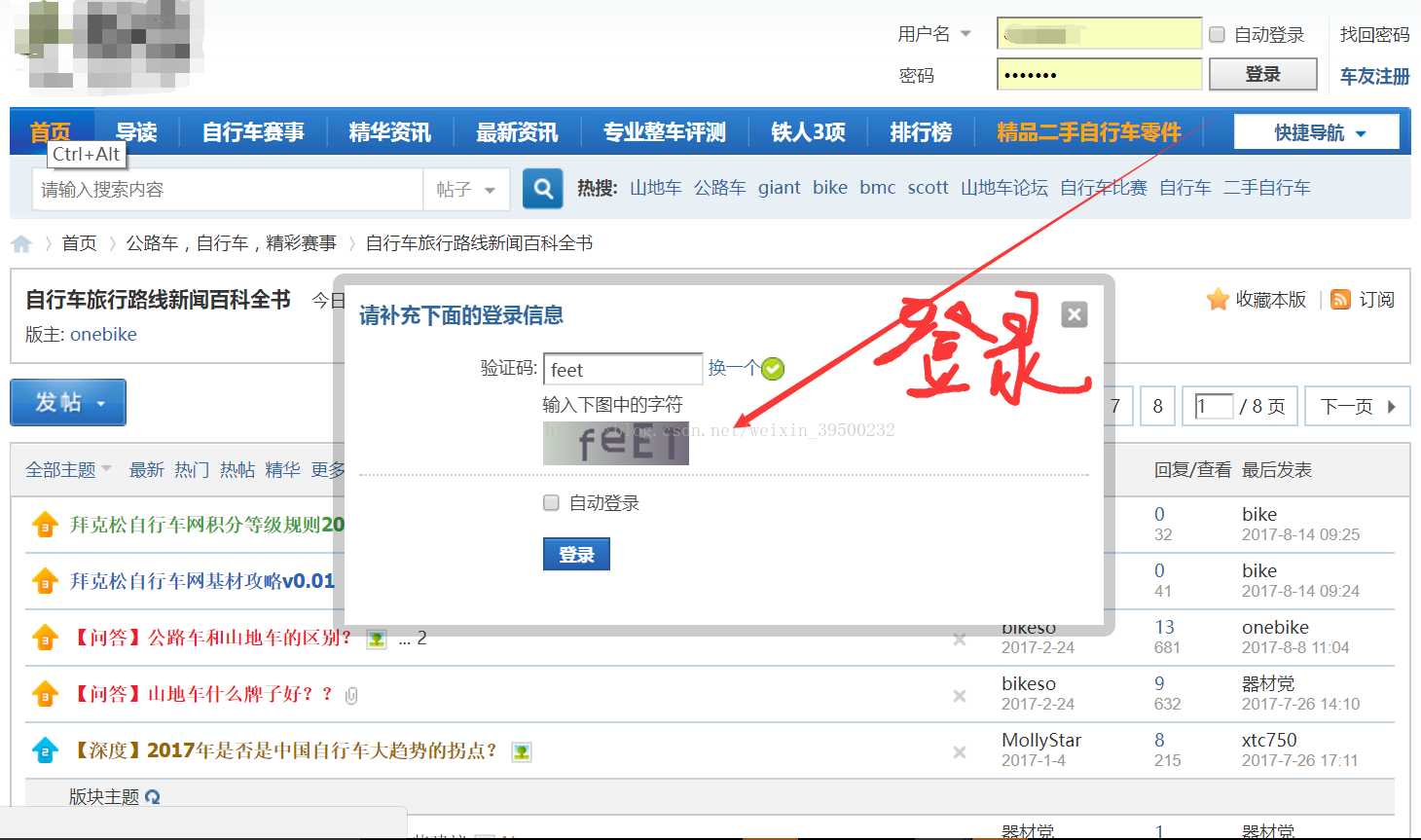
(key)] = value acountdictionary = { '*****':'*****', '******':'*****', '*******':'*****', } acount = random.choice(list(acountdictionary.items())) name = acount[0] password = acount[1] print(name,password) browser.get(login_url) time.sleep(3) browser.find_element_by_xpath('//input[@name="username"]').send_keys(name) browser.find_element_by_xpath('//input[@name="password"]').send_keys(password) # browser.get_screenshot_as_file('bks.png') # 截取当前网页,该网页有我们需要的验证码 # imgelement = browser.find_element_by_xpath('//*[@id="vseccode_cS"]/img') # 定位验证码 # location = imgelement.location # 获取验证码x,y轴坐标 # size = imgelement.size # 获取验证码的长宽 # rangle = (location['x']+ size['width'], # location['y']+ ize['height'], # location['x'] + size['width'], # location['y'] + size['height']) # 写成我们需要截取的位置坐标 # img = Image.open("bks.png") # 打开截图 # frame = img.crop(rangle) # 使用Image的crop函数,从截图中再次截取我们需要的区域 # frame.save('验证码.png') # img = Image.open('验证码.png') # img.show() # colors = acumulate_colors('验证码.png') # denoisepoint(10) # binary('验证码.png') # denoisepoint(100) # # devide(4) # captcha = img2string() browser.find_element_by_xpath('//input[@name="seccodeverify"]').send_keys(captcha) browser.find_element_by_xpath('//button[@name="loginsubmit"]').click() for i in range(1,20): try: # browser.execute_script('window.scrollTo(0, 5)') time.sleep(1) a = browser.find_element_by_xpath('//*[@id="ntcwin"]/table/tbody/tr/td[2]/div/i') a = a.text while a == '抱歉,验证码填写错误': time.sleep(4) if browser.current_url == 'http://www.bike.so/': # print(browser.current_url) # print('验证码正确!!') break else: print('你还有{0}尝试机会'.format(20 - i)) i += 1 if 20-i == 0: print('对不起验证码错误次数过多!!!') time.sleep(4) browser.close() break else: print('验证码错误!!!!请重新输入……') browser.find_element_by_xpath('// *[ @ id = "seccode_cS"] / div
/ table / tbody / tr / td / a').click() # browser.get_screenshot_as_file('bks.png') # 截取当前网页,该网页有我们
# 需要的验证码 # imgelement = browser.find_element_by_xpath('//*[@id="vseccode_cS"]
/img') # 定位验证码 # location = imgelement.location # 获取验证码x,y轴坐标 # size = imgelement.size # 获取验证码的长宽 # rangle = (location['x'] + size['width'], # location['y'] + size['height'], # location['x'] + size['width'], # location['y'] + size['height']) # 写成我们需要截取的位置坐标 # img = Image.open("bks.png") # 打开截图 # frame = img.crop(rangle) # 使用Image的crop函数,从截图中再次截取
# 我们需要的区域 # frame.save('验证码.png') # img = Image.open('验证码.png') # img.show() # colors = acumulate_colors('验证码.png') # denoisepoint(10) # binary('验证码.png') # denoisepoint(100) # # devide(4) # captcha = img2string() browser.find_element_by_xpath('//input[@name="seccodeverify"]').clear() browser.find_element_by_xpath('//input[@name="seccodeverify"]')
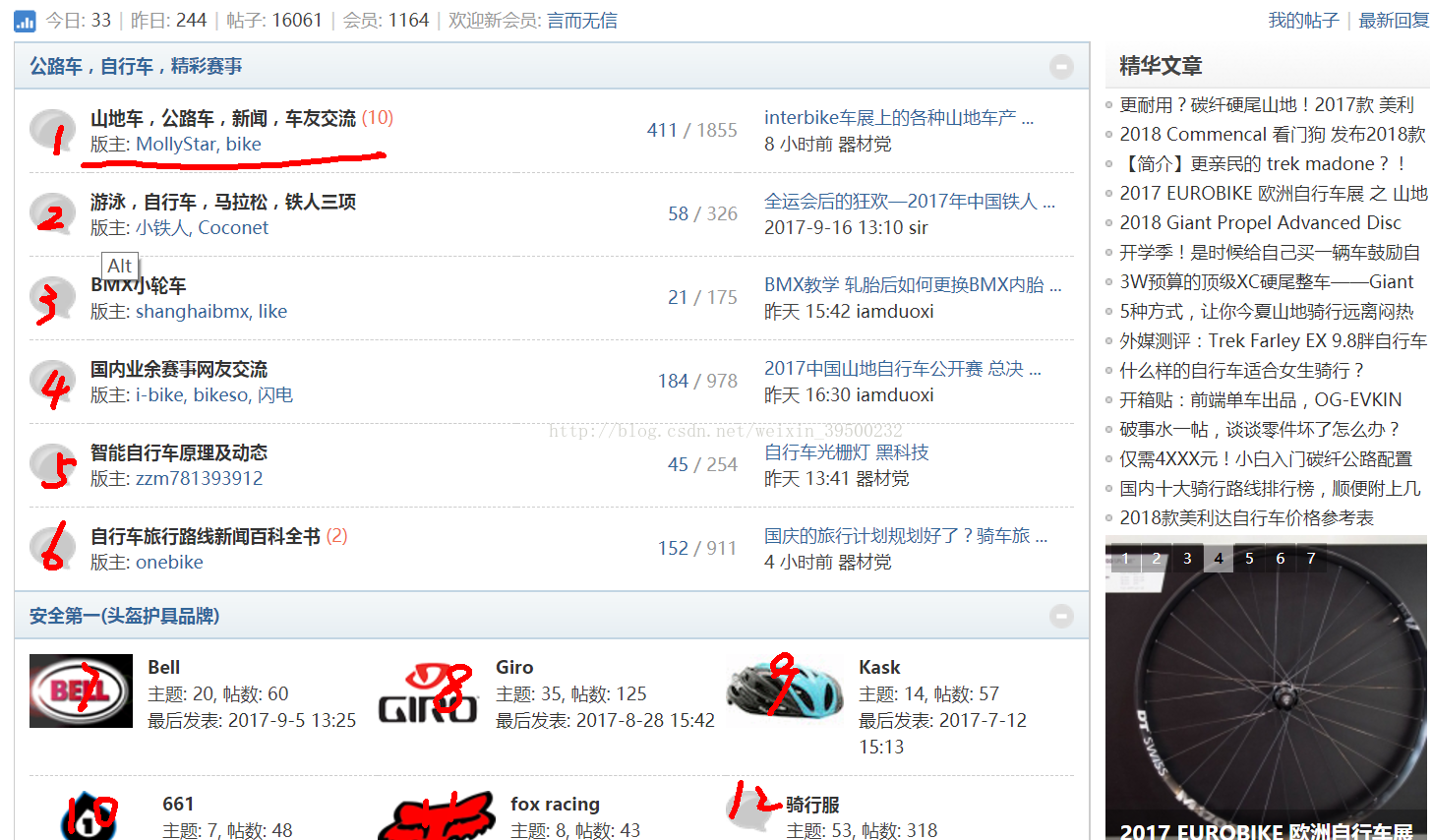
.send_keys(captcha) browser.find_element_by_xpath('//button[@name="loginsubmit"]').click() except NoSuchElementException: print("验证码正确!!") break def locat_plate(): '''定位发帖板块''' browser.execute_script('window.scrollTo(0, 100)') time.sleep(2) # 所有版块 plates = { 'plate1':"山地车,公路车,新闻,车友交流", 'plate2':"游泳,自行车,马拉松,铁人三项", 'plate3': "BMX小轮车", 'plate4': "国内业余赛事网友交流", 'plate5': "智能自行车原理及动态", 'plate6': "自行车旅行路线新闻百科全书", 'plate7': "骑行眼镜", 'plate8': "骑行书籍", 'plate9': "骑行饮料", 'plate10': "国产著名品牌/native", 'plate11': "Giant/捷安特", 'plate12': "Merida/美利达", 'plate13': "Lapierre/法国拉皮尔", 'plate14': "Trek/崔克", 'plate15': "Shimano/禧玛诺" } print(""" "请选择你要发表的版块:", 'plate1':"山地车,公路车,新闻,车友交流", 'plate2':"游泳,自行车,马拉松,铁人三项", 'plate3': "BMX小轮车", 'plate4': "国内业余赛事网友交流", 'plate5': "智能自行车原理及动态", 'plate6': "自行车旅行路线新闻百科全书", 'plate7': "骑行眼镜", 'plate8': "骑行书籍", 'plate9': "骑行饮料", 'plate10': "国产著名品牌/native", 'plate11': "Giant/捷安特", 'plate12': "Merida/美利达", 'plate13': "Lapierre/法国拉皮尔", 'plate14': "Trek/崔克", 'plate15': "Shimano/禧玛诺" """ ) browser.execute_script('window.scrollTo(100, 0.5*document.body.scrollHeight)') time.sleep(1) ratio = input('要重新定位到哪里?范围是0~0.5:') browser.execute_script('window.scrollTo(0.5*document.body.scrollHeight, {}*document.body.
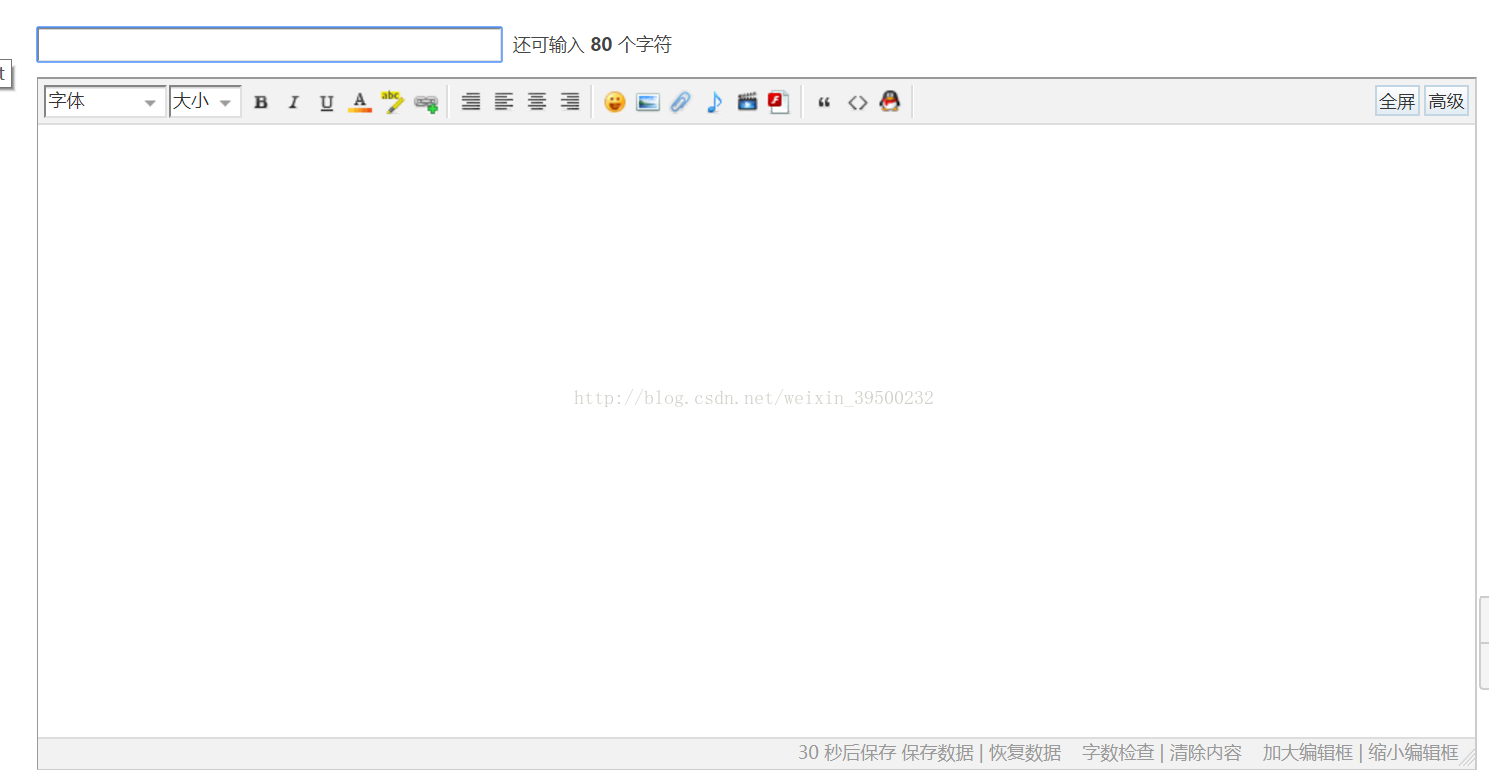
scrollHeight)'.format(ratio)) plate = input('请输入你要发帖的版块:') browser.find_element_by_link_text(plates[plate]).click() time.sleep(2) def random_pick(some_list, probabilities): '''定义不等概率抽样''' x = random.uniform(0, 1) cumulative_probability = 0.0 for item, item_probability in zip(some_list, probabilities): cumulative_probability += item_probability if x < cumulative_probability: break return item def post_content(content): '''自动发帖''' browser.find_element_by_id('newspecial').click() browser.switch_to.frame("e_iframe") browser.find_element_by_xpath('/html/body').send_keys(Keys.TAB) a = content.text.split('\n') postcontent = [] for i in a: if i != '': output = translate(i) + '\n' postcontent.append(output) else: beautystyle = [i, '……………………………………………………………………………………………………………………………………………', '=====================================================', '-----------------------------------------------------', '—————————————————————————————————————————————————————' ] probabilities = [0.8, 0.05, 0.05, 0.05, 0.05] line = random_pick(beautystyle, probabilities) postcontent.append(line + '\n') browser.find_element_by_xpath('/html/body').send_keys(postcontent) time.sleep(4) browser.switch_to.default_content() # 或者driver.switch_to.parent_frame() if content.title != '': # if flag == 0: title = translate(content.title) browser.find_element_by_xpath('//*[@id="subject"]').send_keys(title) else: browser.find_element_by_xpath('//*[@id="subject"]').send_keys(input('请输入标题:')) browser.execute_script('window.scrollTo(0, 300)') time.sleep(2) # browser.find_element_by_xpath('//button[@id="为了不给网站带来麻烦,
请大家不要使用此命令"]').click() # 编辑帖子 # browser.find_element_by_link_text('编辑').click() # browser.page_source if __name__ == '__main__': # 获取正文并翻译 urls = [ 'http://www.360doc.com/content/11/1021/10/7796166_157906146.shtml', ] for url in urls: # 登录论坛 browser = webdriver.Chrome() browser.maximize_window() login(login_url) content = get_content(url,'en') # 定位发帖版块 locat_plate() # 发帖 post_content(content) # browser.close()
智能推荐
Dubbo 服务本地缓存_dubbo本地缓存什么时候失效-程序员宅基地
文章浏览阅读4.4k次。开篇 根据官方图,dubbo调用者需要通过注册中心(例如:ZK)注册信息,获取提供者,但是如果频繁往ZK获取信息,肯定会存在单点故障问题,所以dubbo提供了将提供者信息缓存在本地的方法。 Dubbo在订阅注册中心的回调处理逻辑当中会保存服务提供者信息到本地缓存文件当中(同步/异步两种方式),以url纬度进行全量保存。 Dubbo在服务引用过程中会创建registry对象并加载本地缓存文件,会优先订阅注册中心,订阅注册中心失败后会访问本地缓存文件内容获取服务提供信息。 核心_dubbo本地缓存什么时候失效
generator逆向工程_java 逆向工程 generatorconfiguration-程序员宅基地
文章浏览阅读157次。pom.xml:<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.or_java 逆向工程 generatorconfiguration
快速使用 Javassist_ctmethod-程序员宅基地
文章浏览阅读523次。目录前置知识JVM指令码指令码编辑Javassist使用场景基本使用常见插入方法添加异常代码块总结方法拷贝特殊语法特殊语法表$0, $1, $2$args$$$cflow$r$w$_$sig$class创建类实例访问类实例变量参考链接:https://www.cnblogs.com/sunfie/p/5154246.html前置知识JVM指令码Java源代码不能直接运行,需要编译成class文件,然后被JVM加载后运行。Class文件是由JVM指令码所组成的,JVM加载Class文件,就是在加载Cl_ctmethod
Java语法进阶及常用技术(三)--Maven项目管理-程序员宅基地
文章浏览阅读559次。Maven介绍Maven是项目管理工具,对软件项目提供构建与依赖管理。Maven是Apache下的Java开源项目。Maven为Java项目提供了统一的管理方式,已成为业界标准。Maven核心特性项目设置遵循统一的规则,保证不同开发环境的兼容性。强大的依赖管理,项目依赖组件自动下载、自动更新。可扩展的插件机制,使用简单,功能丰富。Maven的安装与配置安装Maven之前需要安装jdk1.8。从官网下载MavenMaven官网:https://maven.apache.org/bin
C#排序 访问指定下标_c# 获取list 下表-程序员宅基地
文章浏览阅读1.9k次。一、C #中Sort()函数的使用与C++中类似,C#中也有自己的Sort()函数,其使用方式:(列表List的排序使用方式)第一步:声明一个myComparer类,它继承自IComparer:class myComparer : IComparer<MyPoint>/*实现 IComparer<T> 接口中的 Compare 方法, ..._c# 获取list 下表
Python不可变序列类型--字符串-程序员宅基地
文章浏览阅读1.7w次,点赞16次,收藏17次。Python从入门到精通零基础入门篇
随便推点
Failed to start usr-lib-systemd-system-xxx.service.mount: Unit not found的一种可能情况_failed to start usr-lib-systemd-system-mode_export-程序员宅基地
文章浏览阅读290次。systemctl enable\start /usr/lib/systemd/system/xxx.service`则会报标题所示的错误。去掉路径,直接systemctl enable\start xxx.service则不会报错。xxx.service放入到/usr/lib/systemd/system下之后,如果以。_failed to start usr-lib-systemd-system-mode_exporter.service.mount: unit not
无人直播系统源码开发:功能、优势与开发方法探析-程序员宅基地
文章浏览阅读617次,点赞8次,收藏8次。本文介绍了无人直播系统的功能和优势,以及如何进行开发。无人直播系统能够实时采集、编码和传输视频流,支持弹幕互动,并具备实时性、互动性、灵活性和可扩展性等优势。开发无人直播系统的方法包括确定需求、设计系统架构、实现功能、部署上线和维护优化。通过定制开发无人直播系统,可以满足不同业务场景下的实时视频传输和互动需求,提供高质量的直播体验。_无人直播系统源码
windows10环境VS2017 编译Opencv和TensorFlow程序(cmake)-程序员宅基地
文章浏览阅读539次。嘿嘿,我刚上研一,体育方面的研究生,想做计算机视觉方面的课题,这几天都在配置opencv和tensorflow的环境,走了不少歪路,总结了一下。一、关于opencv源码的查看和编译:http://blog.csdn.net/poem_qianmo/article/details/21974023 这个网址介绍的很全。其中要注意的是:如果安装的是vs2017,那么current generato...
Android 设��默认浏览器后安装另外浏览器后默认浏览器功能修复-程序员宅基地
文章浏览阅读84次。在“设置”应用中,找到“应用程序”或“应用管理器”选项,然后找到默认浏览器应用。点击该应用,然后找到“存储”或“存储空间”选项,点击进入。在存储页面中,找到“清除数据”或“清除缓存”选项,并点击确认。在Android设备上,打开“设置”应用,并找到“应用程序”或“应用管理器”选项。点击该应用,然后找到“清除默认值”或“清除默认设置”的选项,并点击确认。在“设置”应用中,找到“应用程序”或“应用管理器”选项,然后找到另外一个浏览器应用。点击该应用,然后找到“清除数据”或“清除缓存”选项,并点击确认。
Ant Design vue自定义文件上传_ant design vue 上传-程序员宅基地
文章浏览阅读4.4k次。实际项目中,上传文件时实际可能需要传输一个token。方法一:1、查看vue antdesign文档https://vue.ant.design/components/upload-cn/2、使用customRequestcustomRequest 通过覆盖默认的上传行为,可以自定义自己的上传实现 Function3、定义customRequest,之前定义action行为会被覆盖,可以注释掉4、customRequest代码如下customRequest ._ant design vue 上传
C++ 学习路线:快速入门到进阶_c++学习路线-程序员宅基地
文章浏览阅读4.9k次,点赞12次,收藏92次。C/C++ 是一门底层、细粒度、功能强大、学习曲线陡峭的语言,掌握这门语言的程序员通常有着更长的生命周期以及更深的护城河。但入门门槛高也是不争的事实,这篇文章把C++学习划分为入门、进阶、深入三个阶段,每步提供相应的学习方法和资源,帮助大家更好地掌握这门语言。_c++学习路线