单链表创建的LinkList L与LinkList *L区分的问题-程序员宅基地
在学习线性表的存储结构中,很多人在学习线性表的链式存储结构即单链表时,有人会注意函数传参LinkList L与LinkList *L的问题,如下
下面展示一些 内联代码片。
#include<stdio.h>
#include<stdlib.h>
typedef int Status;
typedef struct Node
{
ElemType data; //数据域
struct Node* Next; //指针域(指向节点的指针)
}Node;
typedef struct Node* LinkList;;
Status GetElem(LinkList L, int i, ElemType* e) //获取单链表L中的第i个元素,用e返回其值。
Status ListInsert(LinkList *L, int i, ElemType e)//向单链表第i个位置插入新元素e。
有人会发现为什么获取单链表的元素形参输入是LinkList L,而向单链表插入或者删除等操作要用到LinkList *L。
我从以下几个方面逐一递进解释:
1、对于LinkList L: L是指向定义的Node结构体的指针,因为我们前面用typedef struct Node* LinkList,就是LinkList相当于struct Node*,这里的*是跟Node的后面,LinkList是一个指向该结构体的的指针的别名,故此可以用->运算符来访问结构体成员,即L->data,而(*L)就是个Node型的结构体了,可以用点运算符访问该结构体成员,即(*L).elem;
而对于LinkList *L:L是指向定义的Node结构体指针的指针,也就是说L的内容是指向定义的Node结构体指针的地址,(*L)是指向Node结构体的指针,注意,这里的(*L)要理解好。
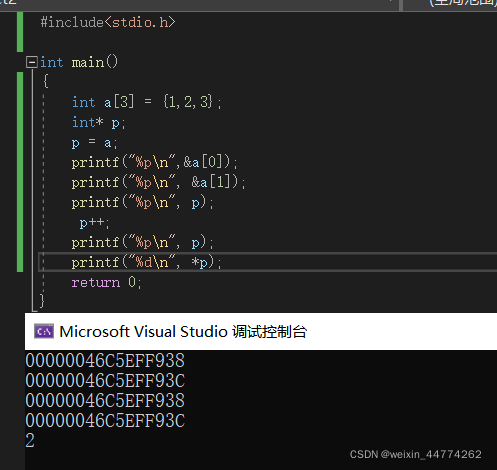
2、从上面的定义我们知道LinkList L的L是一级指针,而后面的LinkList *L是二级指针,对于一级指针我们都知道,可以通过改变的指针的值从而改变量,如
#include<stdio.h>
int main()
{
int a = 100;
int b = 200;
int* p;
p = &a;
printf("%d,",*p);
p = &b;
printf("%d\n",*p);
return 0;
}
执行结果打印出来是100,200,指针p第一次取的是整型变量a的地址,此时*p的值为100,第二次取的是整型变量b的地址,p的值为100,可以看出通过改变指针p指向的地址,对应p的值也就不同,这就是一级指针的用法。
而一级指针可以运用在线性表的顺序存储结构或者数组中,因为其逻辑上具有线性关系的数据按照前后的次序全部存储在一整块连续的内存空间中,之间不存在空隙。注意这段话:使用顺序存储结构存储的数据,第一个元素所在的地址就是这块存储空间的首地址。通过首地址,可以轻松访问到存储的所有的数据,只要首地址不丢(即我们能找到首地址)数据永远都能找着,这就是为什么我们可以使用一级指针而不用二级指针,以下代码1,2说明:
代码1
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#define MAXSIZE 20
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
typedef int Status;
typedef int ElemType;
typedef struct
{
ElemType data[MAXSIZE];
int length;
}SqList;
/******************向线性表第i个位置插入新元素e****************/
Status ListInsert(SqList* L, int i, ElemType e)
{
int k;
if (L->length == MAXSIZE)
{
return ERROR;
}
if (i<1 || i> L->length + 1)
{
return ERROR;
}
if (i <= L->length)
{
for (k = L->length - 1; k >= i - 1; k--)
{
L->data[k + 1] = L->data[k];
}
}
L->data[i - 1] = e;
L->length++;
return OK;
}
上面程序我们定义一个结构体指针*L,通过->运算符来访问结构体成员,而我们向线性表第i个位置插入的时候,后面的元素对应的地址会向后移,但是我们知道线性表的顺序存储结构或者数组中,其逻辑上具有线性关系的数据按照前后的次序全部存储在一整块连续的内存空间中,之间不存在空隙,故我们不需要指针内容发生改变,可以直接==L->data[k + 1] = L->data[k]==直接往后移。如果不理解可以看下图:
代码2
下面展示一些 内联代码片。
#include<stdio.h>
#include<stdlib.h>
#define ERROR 0
#define OK 1
typedef int ElemType;
typedef int Status;
typedef struct Node
{
ElemType data; //数据域
struct Node* Next; //指针域(指向节点的指针)
}Node;
typedef struct Node* LinkList;
Status GetElem(LinkList L, int i, ElemType* e)
{
int j;
LinkList p;
j = 1;
p = L->Next;
while (p && j < i)
{
p = p->Next;
j++;
}
if( !p|| j>i)
{
return ERROR;
}
*e = p->data;
return OK;
}
代码2是单链表的取值操作,对于单链表,其链式存储结构中,除了要存储数据元素信息外,还要存储它的后继元素的存储地址(指针)。这就是表明它的内存地址不连续。但是对于取值操作,我们只需定义一个指向定义的Node结构体的指针L。因为是取值而没对链表的内容进行操作,所以我们可以通过一级指针指向结构体,结构体内部存有指向下个结点的指针域,进而帮助我们找到其值。到了这里我们就说明了LinkList L的意义了。
3、对于 LinkList *L,L是二级指针,前面我们说L的内容是指向定义的Node结构体指针的地址,故此(*L)是指向Node结构体的指针的地址。例如寻找或者修改数组的内容我们可以通过修改一级指针的值,因为内存地址是连续的,那么我们只要找到首地址就能把这个数组表达出来。而对于单链表内存地址不连续的,我们在对单链表进行增删等操作的时候,指针的内容会发生变化的,故此我们需要二级指针来改变一级指针的内容,如下代码3:
代码3
Status ListInsert(LinkList *L, int i, ElemType e)
{
int j;
LinkList p, s;
p = *L;
j = 1;
while (p && j < i)
{
p = p->Next;
j++;
}
if (!p || j > i)
{
return ERROR;
}
s = (LinkList)malloc(sizeof(Node));
s->data = e;
s->Next = p->Next;
p->Next = s;
return OK;
}
代码3定义一个二级指针LinkList *L,其中我们发现单链表插入的两条主要程序:s->Next = p->Next; p->Next = s;其中新结点s->Next是原来的p->Next,而原来的p->Next是新的结点s,此时原来p的内容已经发生了改变,即指向第i个位置的指针内容发生了变化,故此我们使用二级指针来改变p,第二次注意(*L)是指向Node结构体的指针,通过使用二级指针单链表在函数调用后就会有一个全新的内容,总的来说有点像递归,但是使用二级指针更是方便。在如下代码4也可以看出:
代码4
void InitList(LinkList *L)
{
*L = (LinkList)malloc(sizeof(Node));
(*L)->next = NULL; //由于->的优先级高于*,故此得加括号(*L)
}
代码4可看出,初始化空链表,函数调用完毕后,L会指向一个空的链表,即会改变指针的内容,故要用*L到了。到此我们就说明了LinkList *L的意义了。
*总结一句话:如果能理解的话,就记得但凡要修改L的值的操作都要使用 L,如果不修改L的值,用Linklist L 。
智能推荐
ajax跨域与cookie跨域_一级域名 的cookie ajax 请求二级域名时获取cookie-程序员宅基地
文章浏览阅读389次。ajax跨域ajax跨域取数据(利用可以跨域加载js的原理 functioncallback(){ }这是需要返回这样一个js函数)ajax数据类型使用jsonp :如 ajax{ url:..._一级域名 的cookie ajax 请求二级域名时获取cookie
Flutter从0到1实现高性能、多功能的富文本编辑器(基础实战篇)_flutter 富文本-程序员宅基地
文章浏览阅读1.3k次,点赞2次,收藏2次。在上一章中,我们分析了一个富文本编辑器需要有哪些模块组成。在本文中,让我们从零开始,去实现自定义的富文本编辑器。注:本文篇幅较长,从失败的方案开始分析再到成功实现自定义富文本编辑器,真正的从0到1。— 完整代码太多, 文章只分析核心代码,需要源码请到代码仓库作为基础的富文本编辑器实现,我们需要专注于简单且重要的部分,所以目前只需定义标题、文本对齐、文本粗体、文本斜体、下划线、文本删除线、文本缩进符等富文本基础功能。//定义默认颜色...///用户自定义颜色解析。_flutter 富文本
新一代异步IO框架——io_uring 架构-程序员宅基地
文章浏览阅读30次。近年来,Linux社区开发了一种新的异步IO框架,称为io_uring。io_uring通过提供高度可扩展和高性能的异步IO接口,有效地解决了传统异步IO框架中的一些性能瓶颈和限制。io_uring已经成为许多高性能应用程序的首选异步IO框架,为开发者提供了更好的IO处理能力。io_uring 架构是建立在Linux内核之上的,它使用了一组新的系统调用和内核机制,以提供高性能和低延迟的异步IO操作。io_uring的设计目标是提供一种简单而强大的接口,使得开发者可以轻松地利用异步IO的优势。
耗时一个月!期末熬夜复习整理 | 计算机网络(谢希仁第七版)大合集【知识点+大量习题讲解】_计算机网络期末复习题-程序员宅基地
文章浏览阅读2.5w次,点赞204次,收藏1.8k次。期末计网满绩计划教材:计算机网络(第七版)谢希仁版目录1. 概述2. 物理层3. 数据链路层(次重点)4. 网络层(重点)5. 运输层(重点)6. 应用层7. 网络安全最后1. 概述第一章概述2. 物理层第二章物理层3. 数据链路层(次重点)第三章数据链路层4. 网络层(重点)第四章网络层5. 运输层(重点)第五章运输层6. 应用层第六章应用层7. 网络安全稍后发布最后小生凡一,期待你的关注。..._计算机网络期末复习题
DNS解析中的A记录、AAAA记录、CNAME记录、MX记录、NS记录、TXT记录、SRV记录、URL转发等-程序员宅基地
文章浏览阅读6k次,点赞2次,收藏18次。AA记录: 将域名指向一个IPv4地址(例如:100.100.100.100),需要增加A记录NSNS记录: 域名解析服务器记录,如果要将子域名指定某个域名服务器来解析,需要设置NS记录SOASOA记录: SOA叫做起始授权机构记录,NS用于标识多台域名解析服务器,SOA记录用于在众多NS记录中标记哪一台是主服务器MXMX记录: 建立电子邮箱服务,将指向邮件服务器地址,需要设置MX记录。建立邮箱时,一般会根据邮箱服务商提供的MX记录填写此记录TXTTXT记录: 可任意填写,可为空。一_a记录
SpringBoot项目引入外部jar包_springboot引入外部jar包-程序员宅基地
文章浏览阅读695次。SpringBoot项目引入外部jar包_springboot引入外部jar包
随便推点
Hadoop 序列化机制_hadoop final-程序员宅基地
文章浏览阅读493次。序列化是指将结构化对象转化为字节流以便在网络上传输或者写到磁盘上进行永久存储的过程,反序列化是指将字节流转回结构化对象的逆过程序列化用于分布式处理的两大领域,进程间通信和永久存储。在Hadoop中,系统中多个节点上进程间的通信是通过“远程过程调用”(remote procedure call, RPC)实现的。RPC将消息序列化成二进制流后发送到远程节点,远程节点接着将二进制流饭序列化为原始..._hadoop final
tinymce富文本编辑器实现本地图片上传_tinymce images_upload_handler-程序员宅基地
文章浏览阅读5.7k次,点赞3次,收藏6次。在开发过程中使用tinymce富文本编辑器,发现他的图片上传默认是上传网络图片那么如何实现上传本地图片呢,上官网逛一圈,发现其实很简单在官网中找到下面这张图片,并且有相关的例子这里,我使用了自定义函数images_upload_handler (blobInfo, success, failure) { const url = 'uploadImg' ..._tinymce images_upload_handler
SpringCloud-拜托!面试请不要再问我Spring Cloud底层原理实战_spring cloud +sql springcloud底层组件-程序员宅基地
文章浏览阅读2.6k次,点赞5次,收藏14次。上一篇我们说到《拜托!面试请不要再问我Spring Cloud底层原理》,我们大概了解了Spring Cloud中各个组件的作用以及其背后实现的原理。但是俗话说得好,实践是检验真理的唯一标准。这一篇我们动手实践一下,即搭建一个包含订单服务、库存服务、仓库服务、积分服务的微服务架构项目。一、项目的工程结构工程名 服务名 端口号 shop-parent 父工程 ..._spring cloud +sql springcloud底层组件
安装及配置py-faster-rcnn(亲测且详细)-程序员宅基地
文章浏览阅读819次。Ubuntu16.04下编译py-faster-rcnn全过程,在本机上试验成功,亲测有效,清晰总结踩过的坑,常见问题及解决方案一并给出_py-fast
Hausaufgabe--Python 08-程序员宅基地
文章浏览阅读89次。0-- print A/B/C/D rather than detail score:score = float(input('please input your score: '))if score>=90: print('A')elif 80<=score<90: print('B')elif 60<=score<80: print('C'...
linux下mkdir头文件_Linux下的创建目录函数——mkdir()-程序员宅基地
文章浏览阅读2.2k次。原型:int mkdir (const char *filename, mode_t mode)返回0表示成功,返回-1表述出错。使用该函数需要包含头文件sys/stat.hmode 表示新目录的权限,可以取以下值:S_IRUSRS_IREADRead permission bit for the owner of the file. On many systems this bit is 040..._linux mkdir 头文件