1.Python网络爬虫—什么是网络爬虫(上篇)?-程序员宅基地
技术标签: 爬虫 python dubbo # Python网络爬虫基础入门
这里写目录标题
I. 引言
A. 对网络爬虫的简要介绍
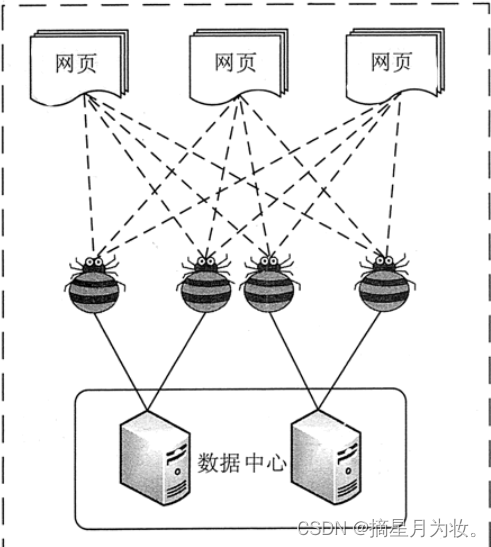
网络爬虫是一种自动化获取万维网信息的程序或脚本。
网络爬虫,也被称为网页蜘蛛或网络机器人,是设计用来自动浏览和收集网络信息的算法驱动的软件。这些程序遵循特定的规则来访问网站,并从中提取数据,这些数据随后可以被存储、分析或用于其他目的。
- 基本概念:网络爬虫通过模拟人类用户浏览网页的方式来工作,但它们以自动化的方式执行这一过程,能够快速地处理和分析大量网页。
- 工作原理:网络爬虫从一个或多个初始网页开始,通常由用户指定,然后按照设定好的算法对网页内容进行爬取,并将数据保存到数据库中。同时,它们会识别网页中的链接,并将其加入到待访问的URL队列中,以便后续的爬取工作。
- 技术应用:网络爬虫在多个领域都有广泛的应用,尤其是在搜索引擎的数据索引上。例如,百度搜索引擎使用的百度蜘蛛(Baiduspider)就是一个网络爬虫,它负责在互联网上爬取信息,以便当用户搜索时能够提供相关的网页结果。
- 分类:网络爬虫可以分为通用爬虫和聚焦爬虫。通用爬虫旨在尽可能多地下载互联网上的网页,而聚焦爬虫则针对特定的主题或网站进行数据抓取。
- 实现过程:网络爬虫的实现包括获取初始URL、爬取网页并发现新URL、将新URL加入队列、重复爬取过程等步骤。
- 技术挑战:网络爬虫在运行时可能会遇到各种挑战,包括如何处理动态网页、如何避免被反爬虫机制拦截、以及如何确保爬取效率和质量等。
- 开发工具:编程语言如Python常被用于编写网络爬虫程序,因为它拥有丰富的库和框架(如Scrapy、BeautifulSoup等),这些工具可以简化开发过程并提高效率。
B. 网络爬虫在现代互联网中的重要性
- 搜索引擎的数据来源:网络爬虫是搜索引擎能够提供搜索服务的基础。以百度为例,其使用的百度蜘蛛(Baiduspider)会不断地爬取互联网上的网页信息,并将这些信息收录到搜索引擎的数据库中。当用户进行搜索时,搜索引擎会从这些数据中找到与查询关键词相关的网页,按照一定的算法进行排序后展示给用户。
- 大数据分析的基石:随着大数据时代的到来,网络爬虫技术变得更加关键。它们能够帮助企业和研究机构自动高效地获取互联网上的信息,为市场分析、用户行为研究、趋势预测等提供数据支持。
- 内容聚合与推荐系统:网络爬虫也被用于内容聚合网站,这些网站通过爬取新闻、博客、社交媒体等平台的内容,为用户提供个性化的内容推荐。
- 维护网络安全:网络爬虫还可以用于监控和检测网络上的恶意活动,比如钓鱼网站、欺诈信息等,从而帮助维护网络安全。
- 促进知识共享:网络爬虫可以帮助学术机构和个人获取分散在不同网站上的学术资料和公开数据,促进知识的共享和传播。
II. 网络爬虫基础知识
A. 网络爬虫的定义和工作原理
网络爬虫,也被称为网络蜘蛛或网页抓取器,是一种按照一定规则自动抓取万维网信息的程序或脚本。
- 初始URL获取:网络爬虫从一组初始的网页链接(种子页面)开始工作。这些URL通常是手动选定的,它们作为爬虫的起点。
- 页面访问与解析:爬虫访问这些初始页面,并解析页面上的内容,包括文本、图片、视频等。同时,爬虫会识别和抓取页面中的链接,这些链接将作为下一步抓取的目标。
- 链接过滤:从新抓取的页面中提取的链接需要进行筛选,过滤掉与爬取目标无关的链接,以便更有效地聚焦于相关的内容。
- 内容分析:网络爬虫会对抓取到的页面内容进行分析和处理,提取有用的信息。这个过程可能包括数据清洗、格式转换等步骤,以确保数据的质量和使用价值。
- 存储数据:最后,网络爬虫将提取的信息存储到数据库或文件系统中,以便后续的使用和分析。
- 循环抓取:网络爬虫会继续沿着提取的链接进行下一步的抓取,这个过程是循环进行的,直到满足预设的停止条件,如达到预定的抓取深度或时间限制等。
示例:
import requests
from bs4 import BeautifulSoup
# 初始URL
start_url = 'https://www.example.com'
# 发送请求并获取网页内容
response = requests.get(start_url)
html_content = response.text
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(html_content, 'html.parser')
# 提取信息(这里以提取所有段落文本为例)
paragraphs = soup.find_all('p')
for paragraph in paragraphs:
print(paragraph.text)
# 提取链接(这里以提取所有超链接为例)
links = soup.find_all('a')
for link in links:
print(link['href'])
在实现一个网络爬虫时,通常需要考虑以下几个方面:
- 确定爬取目标:明确网络爬虫需要爬取的内容类型和目标网站。
- 设计爬取策略:选择合适的搜索策略和分析算法,如广度优先搜索、最佳优先搜索或深度优先搜索等。
- 遵守规则:遵循网站的robots.txt文件规定,以及考虑反爬虫机制和用户隐私保护。
- 技术实现:利用编程语言(如Python)和相关库(如Scrapy、BeautifulSoup)来编写网络爬虫程序。
B. 不同类型网络爬虫
通用网络爬虫:
- 定义:也称为全网爬虫,它们的目标是尽可能广泛地爬取互联网上的信息。
- 特点:通常用于搜索引擎的数据收集,如百度、谷歌等,以便为用户提供全面的搜索结果。
- 策略:通用网络爬虫在实施时可能会采用广度优先策略或深度优先策略,以确保能够覆盖尽可能多的网页。
聚焦网络爬虫:
- 定义:聚焦网络爬虫是针对特定主题或需求设计的爬虫程序,它们只抓取与特定主题相关的信息。
- 特点:适用于特定领域的数据收集,如特定行业的市场分析、特定主题的学术研究等。
- 优势:与通用网络爬虫相比,聚焦网络爬虫可以更高效地获取目标数据,减少无关信息的干扰,提高数据处理的效率和质量。
C. 网络爬虫的法律和道德问题
在使用网络爬虫进行数据采集时,需要考虑法律和道德问题,以避免侵犯版权或隐私权
从法律角度来看,国内外都有关于网络数据保护的法律法规,这些法规旨在保护个人隐私、知识产权和网络安全。例如,欧盟的通用数据保护条例(GDPR)对个人数据的处理提出了严格的要求。在中国,相关的法律如《中华人民共和国网络安全法》也对网络数据的采集和使用做出了规定。网络爬虫在采集数据时必须遵守这些法律法规,否则可能面临法律责任。
从道德层面来说,网络爬虫应当尊重网站的隐私政策和用户协议,不应采集未公开或未经授权的数据。此外,过度的爬取行为可能会对网站服务器造成负担,影响正常用户的访问体验,这在道德上也是不被推崇的。
III. 网络爬虫的核心技术和组件
A. 请求发送和接收技术(HTTP协议等)
网络爬虫在发送请求和接收响应时,主要依赖于HTTP协议。
HTTP(HyperText Transfer Protocol)是一种用于分布式、协作式和超媒体信息系统的应用层协议。它是网络爬虫获取网页信息的基础,因为它定义了客户端和服务器之间交换信息的格式和方式。
- 请求方法:网络爬虫通常使用HTTP的GET方法来请求资源,但也可能需要使用POST、PUT或DELETE等其他HTTP方法来执行不同的操作。
- 请求头:在发送请求时,爬虫可能需要设置请求头信息,如User-Agent、Accept等,以模拟浏览器行为或请求特定类型的数据。
- Cookie和Session:为了维持登录状态或访问需要认证的页面,网络爬虫可能需要在请求中带上Cookie信息。
- 重定向和跳转:HTTP响应中的重定向状态码(如301、302)指示爬虫到新的位置获取资源,爬虫需要正确处理这些重定向以避免无限循环。
- 错误处理:网络爬虫在接收到错误状态码(如404、503)时,需要进行适当的错误处理,比如记录错误、跳过或重试请求。
- 响应解析:接收到的HTTP响应通常包含HTML、JSON或其他类型的数据,网络爬虫需要解析这些数据以提取有用信息。
- 遵循robots协议:网络爬虫应遵守目标网站的robots.txt文件中的规则,以确保合法合规地爬取数据。
- 反爬虫机制:许多网站会采取反爬虫措施,如检查请求频率、请求头信息等,网络爬虫需要相应地进行规避或调整策略。
- 性能优化:为了提高爬取效率,网络爬虫可能会采用多线程、异步IO或分布式爬取等技术。
- 数据存储:爬取到的数据需要存储到数据库或文件系统中,以便于后续的分析和处理。
B. 解析技术
HTML和XML是两种常用的标记语言,它们在网络爬虫中扮演着重要的角色。HTML 是用于描述网页的一种标记语言,而XML 是一种可扩展标记语言,通常用于存储和传输数据。两者的主要区别在于HTML主要用于网页的显示,而XML则更侧重于数据的结构化表示。
在Python中,有多种库可以用来解析HTML和XML文档,其中Beautiful Soup 是一个广泛使用的库,它提供了简单而直观的方式来遍历文档树、搜索特定标签和提取数据。此外,还有如lxml、etree 等库也是进行HTML和XML解析的常用工具。
使用这些解析技术,网络爬虫可以从网页中提取所需的信息,如文本内容、链接、图片等。这些信息可以用于多种目的,包括数据分析、市场研究、内容聚合等。
除了解析技术,构建一个网络爬虫还需要考虑其他组件,如爬虫调度器(负责各个模块之间的通信,可以理解为爬虫的入口与核心),URL管理器(负责URL的管理),以及如何处理爬取到的数据等。
C. 数据存储
- 文件系统:
- 数据可以保存为各种格式的文件,如txt、csv、excel、json等。这种方式适合数据量不大的情况,优点是简单易用,可以直接用文本编辑器或表格处理软件打开和查看。
- 可以使用Python的文件操作函数,如
open()、write()等,将获取到的数据写入到TXT文本文件中。
- 关系型数据库:
- 对于大量的数据,可以使用如MySQL、Oracle等关系型数据库进行存储。这些数据库能够提供结构化的查询和高效的数据管理能力。
- 非关系型数据库:
- 非关系型数据库,如MongoDB、Redis等,通常以键值对的形式存储数据,适合存储结构灵活或需要高速读写的场景。
D. 反爬虫机制和应对策略
常见的反爬虫机制和应对策略:
-
User-Agent检测:网站会检测访问者的User-Agent,如果发现是爬虫,就会拒绝访问。应对策略是设置合适的User-Agent,模拟正常用户访问。 -
IP限制:网站会对访问频率过高的IP进行限制或封禁。应对策略是使用代理IP,降低访问频率。 -
验证码:网站会设置验证码,要求用户输入正确的验证码才能继续访问。应对策略是使用OCR技术识别验证码,或者手动输入。 -
JavaScript检测:网站会通过JavaScript检测访问者的行为,如果发现是爬虫,就会拒绝访问。应对策略是使用支持JavaScript的爬虫框架,如Selenium。 -
Cookie检测:网站会检测访问者的Cookie,如果没有正确的Cookie,就会拒绝访问。应对策略是设置合适的Cookie。 -
登录检测:网站会要求访问者登录后才能访问某些页面。应对策略是模拟登录过程,获取登录后的Cookie或者其他凭证。 -
动态页面:网站会使用Ajax等技术动态加载数据,使得爬虫难以直接抓取数据。应对策略是分析网站的请求过程,找到数据接口,直接抓取数据。 -
网页结构变化:网站会不定期改变网页结构,使得爬虫难以适应。应对策略是定期更新爬虫代码,适应网页结构的变化。 -
Robots协议:网站会通过Robots协议告诉爬虫哪些页面可以抓取,哪些页面不可以抓取。应对策略是遵守Robots协议,只抓取允许抓取的页面。 -
人机交互检测:网站会检测访问者的行为,如鼠标移动、滚动等,判断是否为人类访问。应对策略是模拟人类行为,如随机间隔时间访问、模拟鼠标操作等。
智能推荐
海康威视网络摄像头开发流程(五)------- 直播页面测试_ezuikit 测试的url-程序员宅基地
文章浏览阅读3.8k次。1、将下载好的萤石js插件,添加到SoringBoot项目中。位置可参考下图所示。(容易出错的地方,在将js插件在html页面引入时,发生路径错误的问题)所以如果对页面中引入js的路径不清楚,可参考下图所示存放路径。2、将ezuikit.js引入到demo-live.html中。(可直接将如下代码复制到你创建的html页面中)<!DOCTYPE html><html lan..._ezuikit 测试的url
如何确定组态王与多动能RTU的通信方式_组态王ua-程序员宅基地
文章浏览阅读322次。第二步,在弹出的对话框选择,设备驱动—>PLC—>莫迪康—>ModbusRTU—>COM,根据配置软件选择的协议选期期,这里以此为例,然后点击“下一步”。第四步,把使用虚拟串口打勾(GPRS设备),根据需要选择要生成虚拟口,这里以选择KVCOM1为例,然后点击“下一步”设备ID即Modbus地址(1-255) 使用DTU时,为下485接口上的设备地址。第六步,Modbus的从机地址,与配置软件相同,这里以1为例,点击“下一步“第五步,Modbus的从机地址,与配置软件相同,这里以1为例,点击“下一步“_组态王ua
npm超详细安装(包括配置环境变量)!!!npm安装教程(node.js安装教程)_npm安装配置-程序员宅基地
文章浏览阅读9.4k次,点赞22次,收藏19次。安装npm相当于安装node.js,Node.js已自带npm,安装Node.js时会一起安装,npm的作用就是对Node.js依赖的包进行管理,也可以理解为用来安装/卸载Node.js需要装的东西_npm安装配置
火车头采集器AI伪原创【php源码】-程序员宅基地
文章浏览阅读748次,点赞21次,收藏26次。大家好,小编来为大家解答以下问题,python基础训练100题,python入门100例题,现在让我们一起来看看吧!宝子们还在新手村练级的时候,不单要吸入基础知识,夯实自己的理论基础,还要去实际操作练练手啊!由于文章篇幅限制,不可能将100道题全部呈现在此除了这些,下面还有我整理好的基础入门学习资料,视频和讲解文案都很齐全,用来入门绝对靠谱,需要的自提。保证100%免费这不,贴心的我爆肝给大家整理了这份今天给大家分享100道Python练习题。大家一定要给我三连啊~
Linux Ubuntu 安装 Sublime Text (无法使用 wget 命令,使用安装包下载)_ubuntu 安装sumlime text打不开-程序员宅基地
文章浏览阅读1k次。 为了在 Linux ( Ubuntu) 上安装sublime,一般大家都会选择常见的教程或是 sublime 官网教程,然而在国内这种方法可能失效。为此,需要用安装包安装。以下就是使用官网安装包安装的教程。打开 sublime 官网后,点击右上角 download, 或是直接访问点击打开链接,即可看到各个平台上的安装包。选择 Linux 64 位版并下载。下载后,打开终端,进入安装..._ubuntu 安装sumlime text打不开
CrossOver for Mac 2024无需安装 Windows 即可以在 Mac 上运行游戏 Mac运行exe程序和游戏 CrossOver虚拟机 crossover运行免安装游戏包-程序员宅基地
文章浏览阅读563次,点赞13次,收藏6次。CrossOver24是一款类虚拟机软件,专为macOS和Linux用户设计。它的核心技术是Wine,这是一种在Linux和macOS等非Windows操作系统上运行Windows应用程序的开源软件。通过CrossOver24,用户可以在不购买Windows授权或使用传统虚拟机的情况下,直接在Mac或Linux系统上运行Windows软件和游戏。该软件还提供了丰富的功能,如自动配置、无缝集成和实时传输等,以实现高效的跨平台操作体验。
随便推点
一个用聊天的方式让ChatGPT写的线程安全的环形List_为什么gpt一写list就卡-程序员宅基地
文章浏览阅读1.7k次。一个用聊天的方式让ChatGPT帮我写的线程安全的环形List_为什么gpt一写list就卡
Tomcat自带的设置编码Filter-程序员宅基地
文章浏览阅读336次。我们在前面的文章里曾写过Web应用中乱码产生的原因和处理方式,旧文回顾:深度揭秘乱码问题背后的原因及解决方式其中我们提到可以通过Filter的方式来设置请求和响应的encoding,来解..._filterconfig selectencoding
javascript中encodeURI和decodeURI方法使用介绍_js encodeur decodeurl-程序员宅基地
文章浏览阅读651次。转自:http://www.jb51.net/article/36480.htmencodeURI和decodeURI是成对来使用的,因为浏览器的地址栏有中文字符的话,可以会出现不可预期的错误,所以可以encodeURI把非英文字符转化为英文编码,decodeURI可以用来把字符还原回来_js encodeur decodeurl
Android开发——打包apk遇到The destination folder does not exist or is not writeable-程序员宅基地
文章浏览阅读1.9w次,点赞6次,收藏3次。前言在日常的Android开发当中,我们肯定要打包apk。但是今天我打包的时候遇到一个很奇怪的问题Android The destination folder does not exist or is not writeable,大意是目标文件夹不存在或不可写。出现问题的原因以及解决办法上面有说报错的中文大意是:目标文件夹不存在或不可写。其实问题就在我们的打包界面当中图中标红的Desti..._the destination folder does not exist or is not writeable
Eclipse配置高大上环境-程序员宅基地
文章浏览阅读94次。一、配置代码编辑区的样式 <1>打开Eclipse,Help —> Install NewSoftware,界面如下: <2>点击add...,按下图所示操作: name:随意填写,Location:http://eclipse-color-th..._ecplise高大上设置
Linux安装MySQL-5.6.24-1.linux_glibc2.5.x86_64.rpm-bundle.tar_linux mysql 安装 mysql-5.6.24-1.linux_glibc2.5.x86_6-程序员宅基地
文章浏览阅读2.8k次。一,下载mysql:http://dev.mysql.com/downloads/mysql/; 打开页面之后,在Select Platform:下选择linux Generic,如果没有出现Linux的选项,请换一个浏览器试试。我用的谷歌版本不可以,换一个别的浏览器就行了,如果还是不行,需要换一个翻墙的浏览器。 二,下载完后解压缩并放到安装文件夹下: 1、MySQL-client-5.6.2_linux mysql 安装 mysql-5.6.24-1.linux_glibc2.5.x86_64.rpm-bundle