python爬虫知识:正则表达式_爬虫正则表达式实验原理-程序员宅基地
技术标签: 爬虫 python search match 正则表达式 findall
概念
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
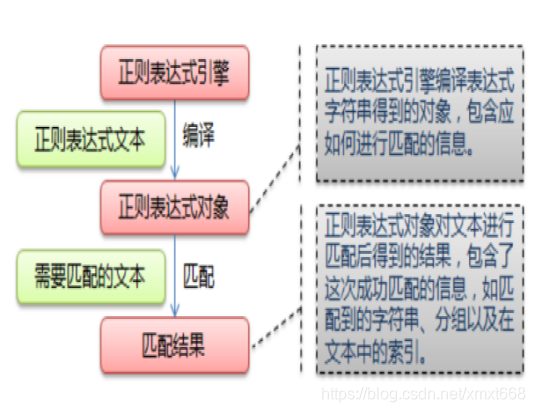
正则表达式的原理:
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。
正则表达式是由普通字符和特殊字符(元字符)组成的文字模式
在 Python 中,我们可以使用内置的 re 模块来使用正则表达式。
有一点需要特别注意的是,正则表达式使用 对特殊字符进行转义,所以如果我们要使用原始字符串,只需加一个 r 前缀,示例:
import re
#因为\a\b是元字符,所以没有打印出来
print("\a\b\c")#\c
#如果我们想打印出原始字符串,则需要在前面加r,防止转义
print(r"\a\b\c")
#对\进行转义,打印出\本身
print("\\")
#这样也可以将原始字符字符串答应出来
print("\\a\\b\c")
re 模块的一般使用步骤如下:
- 使用 compile() 函数将正则表达式的字符串形式编译为一个 Pattern 对象;
- 通过 Pattern 对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象;
- 最后使用 Match 对象提供的属性和方法获得信息,根据需要进行其他的操作。
compile 函数
compile 函数用于编译正则表达式,生成一个 Pattern 对象,它的一般使用形式如下:
在上面,我们已将一个正则表达式编译成 Pattern 对象,接下来,我们就可以利用 pattern 的一系列方法对文本进行匹配查找了。
Pattern 对象的一些常用方法主要有:
match方法:从起始位置开始查找,一次匹配search方法:从任何位置开始查找,一次匹配findall方法:全部匹配,返回列表finditer方法:全部匹配,返回迭代器split方法:分割字符串,返回列表sub方法:替换
下面对这几种发方法进行介绍:
- findall方法
我们需要搜索整个字符串,获得所有匹配的结果,使用的是findall()方法
findall 方法的使用形式如下:
findall(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
import re
#1.创建pattern对象,编译正则表达式
pattern=re.compile("we")
#2.使用findall匹配信息,匹配到所有的we,返回一个列表
result=pattern.findall("we are working how are you i am well thinks and you Welcome")
print(result)
#1.创建pattern对象,编译正则表达式
#\b是元字符,是匹配单词开始和结束
pattern=re.compile(r"\bwe\b")
#2.使用findall匹配信息,匹配到所有的we单词,返回一个列表
result1=pattern.findall("we are working how are you i am well thinks and you Welcome")
print(result1)
常见元字符:
前面提到的元字符\b表示匹配单词的开始和结束。引出其他元字符
| 元字符 | 含义 |
|---|---|
| . | 匹配除换行符以外的任意一个字符 |
| ^ | 匹配行首 |
| $ | 匹配行尾 |
| ? | 重复匹配0次或1次 |
| * | 重复匹配0次或更多次 |
| + | 重复匹配1次或更多次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n~m次 |
| [a-z] | 匹配[a-z]任意字符 |
| [abc] | a/b/c中的任意一个字符 |
| {n} | 重复n次 |
| \b | 匹配单词的开始和结束 |
| \d | 匹配数字 |
| \w | 匹配字母,数字,下划线 |
| \s | 匹配任意空白,包括空格,制表符(Tab),换行符 |
| \W | 匹配任意不是字母,数字,下划线的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开始和结束的位置 |
| [^a] | 匹配除了a以外的任意字符 |
| [^(123|abc)] | 匹配除了123或者abc这几个字符以外的任意字符 |
import re
#\d匹配数字一个数字
pattern1=re.compile("\d")
result1=pattern1.findall("hello 123 567")
print(result1)
#\d+匹配一个或者多个数字 如果是多个数字,则必须连续
pattern2=re.compile("\d+")
result2=pattern1.findall("hello 123 567 wor65k6")
print(result2)
#\d{3,}匹配3次或者多次,必须连续
pattern3=re.compile("\d{3,}")
result3=pattern1.findall("hello 123 567 wor65k6")
print(result3)
#\d{3}连续匹配三次
pattern4=re.compile("\d{3}")
result4=pattern1.findall("hello 123 567 wor65453k6434")
print(result4)
#\d{1,2} 可以匹配一次,也可以匹配两次,已更多的优先
pattern5=re.compile("\d{1,2}")
result5=pattern1.findall("hello 123 567 wor65453k6434")
print(result5)
#re.I表示忽略大小写,"[a-z]{5}匹配a-z的字母五次
pattern6=re.compile("[a-z]{5}",re.I)
result6=pattern1.findall("hello 123 567 wor65453k6434")
print(result6)
#\w+匹配数字,字母, 下滑线 一次或者多次
pattern7=re.compile("\w+")
result7=pattern7.findall("hello 123 567 wor65_453k6434")
print(result7)
#\s+匹配空白字符一次或者多次
pattern8=re.compile("\s+")
result8=pattern8.findall("hello 123 567 wor65_453k6434")
print(result8)
# \W+ 匹配不是下滑线 字母 数字
pattern9=re.compile("\W+")
result9=pattern9.findall("hello 123 567 wor65_453k6434")
print(result9)
# [\w\W]+ 匹配所有字符, 一次或多次
pattern10=re.compile("[\w\W]+")
result10=pattern10.findall("hello 123 567 w¥or65_453k6434")
print(result10)
#[abc]+匹配a 或者b或c一次或多次
pattern10=re.compile("[abc]+")
result10=pattern10.findall("hello b123 c567 w¥ora65_453ka6434")
print(result10)
# [^abc|123]+ 获取不是abc或者123的字符
pattern10=re.compile("[^abc|123]+")
result10=pattern10.findall("hello b123 c567 w¥ora65_453ka6434")
print(result10)
# .* 匹配任意字符,除了换行符
pattern10=re.compile(".*")
result10=pattern10.findall("hello b123 c567 w¥ora65_453ka6434")
print(result10)
#re.I表示忽略大小写,"[a-z]{5}匹配a-z的字母五次
pattern10=re.compile("[a-z]{5}",re.I)
#只查找字符串在0-8之间范围的字符 ,要前不要后(左闭右开)-->只查找0,1,2,3,4,5,6,7
result10=pattern10.findall("hello b123 c567 w¥ora65_453ka6434",0,8)
print(result10)
- match 方法
match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。它的一般使用形式如下:
match(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。因此,当你不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
import re
pattern1=re.compile("\d+")
#match 匹配 匹配一次返回 从头开始匹配, 匹配不到返回none
result1=pattern1.match("gjkdsla3232342kjldf4332opopo")
print(result1)
pattern1=re.compile("\d+")
#match 匹配 匹配一次返回 从头开始匹配,返回的是match类型的数据
result1=pattern1.match("5458gjkdsla3232342kjldf4332opopo")
print( type(result1))#span=(0, 4), match='5458' span是查找的范围,要前不要后
print(result1)
#提取匹配数据,后面的哦和没有0 效果是一样的
print(result1.group())
print(result1.group(0))
print(result1.start())#获取在字符串开始的位置
print(result1.end())#结束的位置
print(result1.span())#开始和结束的位置 是一个元组
pattern1=re.compile("\d+")
#match 匹配 匹配一次返回 从头开始匹配,返回的是match类型的数据
#匹配不到 因为位置为6的是字符 不是数字
result1=pattern1.match("5458gjkdsla3232342kjldf4332opopo",6,10)
print(result1)
pattern1=re.compile("\d+")
#match 匹配 匹配一次返回 从头开始匹配,返回的是match类型的数据
pattern2=re.compile("\d+")
#match 匹配 匹配一次返回 从头开始匹配,返回的是match类型的数据
result2=pattern2.match("5458gjkdsla3232342kjldf4332opopo",1,10)
print(result2)
pattern2=re.compile("([a-z])+ ([a-z]+)")
#match 匹配 匹配一次返回 从头开始匹配,返回的是match类型的数据
result2=pattern2.match("gjkdsla kjld opopo")
print(result2)
print(result2.group())
print(result2.group(0))#获取所有匹配的内容
print(result2.group(1))#获取第一个()中的内容
print(result2.group(2))#获取第2个()中的内容
print(result2.groups())#获取全部返回一个元组
在上面,当匹配成功时返回一个 Match 对象,其中:
- group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
- start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
- end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
- span([group]) 方法返回 (start(group), end(group))。
- search 方法
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果,它的一般使用形式如下:
search(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
让我们看看例子:
import re
pattern=re.compile("\d+")
#search 是一次匹配 从任意位置开始,返回的是match对象,
#和match最大的不同,就是开始的位置不一样 ,没有查找到 返回none
result=pattern.search("nnd123tyy4566tre189")
#match类型,后面的操作和match方法是一样的
print(result)
print(type(result))
print(result.group())
- finditer 方法
finditer 方法的行为跟 findall 的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match 对象)的迭代器。
看看例子:
import re
pattern=re.compile("\d+")
#finditer 是全局查找,返回一个迭代器
result=pattern.finditer("nnd123tyy4566tre189")
print(result)
#遍历迭代器,一个个拿出我们想要的数据
for i in result:
#返回到是match对象
print(i)
#获取match对象中的内容
print(i.group())
列表和迭代器的区别
- 迭代器不占用内存,等你想要的时候,遍历获取出来即可
- 列表是占用大量内存,不使用也占用内存
- split 方法
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
split(string[, maxsplit])
其中,maxsplit 用于指定最大分割次数,不指定将全部分割。
看看例子:
import re
#把所有的字母分开
pattern=re.compile("[\s;\,\:]+")
#split 是分隔符[\s;\,\:]+
result=pattern.split("i; want: eat;;; dinner, do, you,; want it yes")
print(result)
- sub 方法
sub 方法用于替换。它的使用形式如下:
sub(repl, string[, count])
其中,repl 可以是字符串也可以是一个函数:
- 如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl 还可以使用 id 的形式来引用分组,但不能使用编号 0;
- 如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
- count 用于指定最多替换次数,不指定时全部替换。
import re
#\w 匹配数字 字母 下划线
pattern=re.compile("(\w+)(\w+)")
str1="hello 123 hello 456"
#相当于把str1中被paterna ((\w+)(\w+)) 匹配到的内容 使用wew替换
result=pattern.sub("wew,tr",str1)
print(result)
在某些情况下,我们想匹配文本中的汉字,有一点需要注意的是,中文的 unicode 编码范围 主要在[u4e00-u9fa5]+,这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。
假设现在想把字符串 title = ‘你好,hello,世界’ 中的中文提取出来,可以这么做:
import re
#声明要匹配的内容
str="这世界真美好 fdjska dfa"
# [u4e00-u9fa5]这个范围可以匹配绝大多数汉字
# \u是匹配中文
pattern=re.compile("[\u4e00-\u9fa5]+")
result=pattern.findall(str)
print(result)
智能推荐
c# 调用c++ lib静态库_c#调用lib-程序员宅基地
文章浏览阅读2w次,点赞7次,收藏51次。四个步骤1.创建C++ Win32项目动态库dll 2.在Win32项目动态库中添加 外部依赖项 lib头文件和lib库3.导出C接口4.c#调用c++动态库开始你的表演...①创建一个空白的解决方案,在解决方案中添加 Visual C++ , Win32 项目空白解决方案的创建:添加Visual C++ , Win32 项目这......_c#调用lib
deepin/ubuntu安装苹方字体-程序员宅基地
文章浏览阅读4.6k次。苹方字体是苹果系统上的黑体,挺好看的。注重颜值的网站都会使用,例如知乎:font-family: -apple-system, BlinkMacSystemFont, Helvetica Neue, PingFang SC, Microsoft YaHei, Source Han Sans SC, Noto Sans CJK SC, W..._ubuntu pingfang
html表单常见操作汇总_html表单的处理程序有那些-程序员宅基地
文章浏览阅读159次。表单表单概述表单标签表单域按钮控件demo表单标签表单标签基本语法结构<form action="处理数据程序的url地址“ method=”get|post“ name="表单名称”></form><!--action,当提交表单时,向何处发送表单中的数据,地址可以是相对地址也可以是绝对地址--><!--method将表单中的数据传送给服务器处理,get方式直接显示在url地址中,数据可以被缓存,且长度有限制;而post方式数据隐藏传输,_html表单的处理程序有那些
PHP设置谷歌验证器(Google Authenticator)实现操作二步验证_php otp 验证器-程序员宅基地
文章浏览阅读1.2k次。使用说明:开启Google的登陆二步验证(即Google Authenticator服务)后用户登陆时需要输入额外由手机客户端生成的一次性密码。实现Google Authenticator功能需要服务器端和客户端的支持。服务器端负责密钥的生成、验证一次性密码是否正确。客户端记录密钥后生成一次性密码。下载谷歌验证类库文件放到项目合适位置(我这边放在项目Vender下面)https://github.com/PHPGangsta/GoogleAuthenticatorPHP代码示例://引入谷_php otp 验证器
【Python】matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距-程序员宅基地
文章浏览阅读4.3k次,点赞5次,收藏11次。matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距
docker — 容器存储_docker 保存容器-程序员宅基地
文章浏览阅读2.2k次。①Storage driver 处理各镜像层及容器层的处理细节,实现了多层数据的堆叠,为用户 提供了多层数据合并后的统一视图②所有 Storage driver 都使用可堆叠图像层和写时复制(CoW)策略③docker info 命令可查看当系统上的 storage driver主要用于测试目的,不建议用于生成环境。_docker 保存容器
随便推点
网络拓扑结构_网络拓扑csdn-程序员宅基地
文章浏览阅读834次,点赞27次,收藏13次。网络拓扑结构是指计算机网络中各组件(如计算机、服务器、打印机、路由器、交换机等设备)及其连接线路在物理布局或逻辑构型上的排列形式。这种布局不仅描述了设备间的实际物理连接方式,也决定了数据在网络中流动的路径和方式。不同的网络拓扑结构影响着网络的性能、可靠性、可扩展性及管理维护的难易程度。_网络拓扑csdn
JS重写Date函数,兼容IOS系统_date.prototype 将所有 ios-程序员宅基地
文章浏览阅读1.8k次,点赞5次,收藏8次。IOS系统Date的坑要创建一个指定时间的new Date对象时,通常的做法是:new Date("2020-09-21 11:11:00")这行代码在 PC 端和安卓端都是正常的,而在 iOS 端则会提示 Invalid Date 无效日期。在IOS年月日中间的横岗许换成斜杠,也就是new Date("2020/09/21 11:11:00")通常为了兼容IOS的这个坑,需要做一些额外的特殊处理,笔者在开发的时候经常会忘了兼容IOS系统。所以就想试着重写Date函数,一劳永逸,避免每次ne_date.prototype 将所有 ios
如何将EXCEL表导入plsql数据库中-程序员宅基地
文章浏览阅读5.3k次。方法一:用PLSQL Developer工具。 1 在PLSQL Developer的sql window里输入select * from test for update; 2 按F8执行 3 打开锁, 再按一下加号. 鼠标点到第一列的列头,使全列成选中状态,然后粘贴,最后commit提交即可。(前提..._excel导入pl/sql
Git常用命令速查手册-程序员宅基地
文章浏览阅读83次。Git常用命令速查手册1、初始化仓库git init2、将文件添加到仓库git add 文件名 # 将工作区的某个文件添加到暂存区 git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件...
分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120-程序员宅基地
文章浏览阅读202次。分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120
【C++缺省函数】 空类默认产生的6个类成员函数_空类默认产生哪些类成员函数-程序员宅基地
文章浏览阅读1.8k次。版权声明:转载请注明出处 http://blog.csdn.net/irean_lau。目录(?)[+]1、缺省构造函数。2、缺省拷贝构造函数。3、 缺省析构函数。4、缺省赋值运算符。5、缺省取址运算符。6、 缺省取址运算符 const。[cpp] view plain copy_空类默认产生哪些类成员函数