深度学习(9)之 easyOCR使用详解-程序员宅基地
技术标签: python 计算机视觉 深度学习 人工智能 # 深度学习 OCR
easyOCR使用详解
- 本文在 OCR-easyocr初识 基础上进行修改
- EasyOCR 是一个python版的文字识别工具。目前支持80中语言的识别。其对应的 github 地址:EasyOCR
- 可以在网站版测试 demo 测试效果:https://www.jaided.ai/easyocr/
- 其在字符识别上的效果如下:

一、介绍
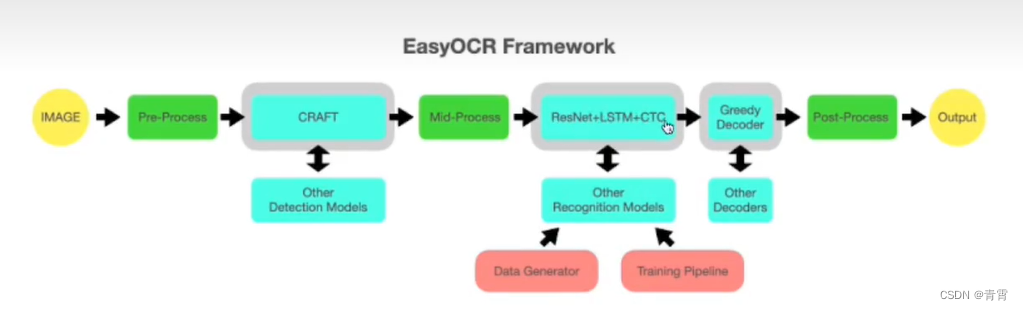
二、安装
- Install using pip
For the latest stable release:
pip install easyocr
For the latest development release:
pip install git+https://github.com/JaidedAI/EasyOCR.git
- 模型储存路径:
windows: C:\Users\username\.EasyOCR\linux:/root/.EasyOCR/
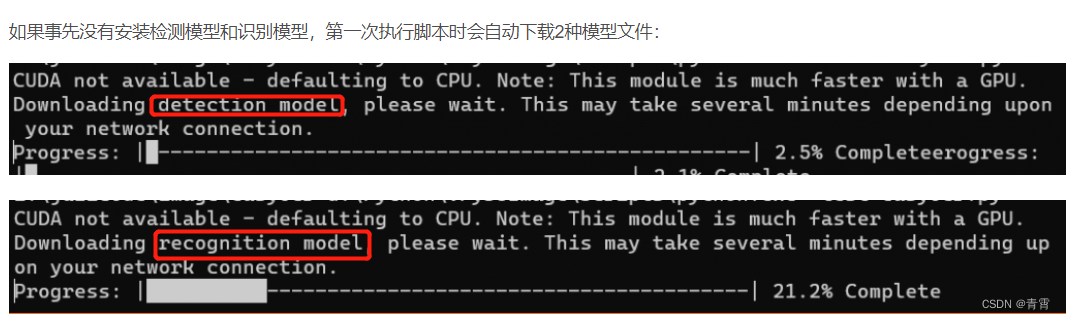

三、API文档
3.1、easyocr.Reader class:
-
lang_list (list) - 识别的语言代码列表,例如 ['ch_sim','en']
-
gpu (bool, string, default = True) - 启用 GPU
-
model_storage_directory (string, default = None) - 模型数据目录的路径。如果未指定,将从环境变量 EASYOCR_MODULE_PATH(首选)、MODULE_PATH(如果已定义)或 ~/.EasyOCR/ 定义的目录中读取模型。
-
download_enabled (bool, default = True) - 如果 EasyOCR 无法找到模型文件,则启用下载;
-
user_network_directory (bool, default = None) - 用户模型存储的路径。如果未指定,将从 MODULE_PATH + '/user_network' (~/.EasyOCR/user_network) 读取模型;
-
recog_network (string, default = 'standard') - 用户模型、模块和配置文件的名称;
-
detector (bool, default = True) - 将检测模型加载到内存中
-
recognizer (bool, default = True) - 将识别模型加载到内存中
-
lang_char - 显示当前模型中的所有可用字符
3.2、reader.readtext()
-
image (string, numpy array, byte) - 输入图像;
-
decoder (string, default = 'greedy')- 选项有 'greedy'、'beamsearch' 和 'wordbeamsearch';
-
beamWidth (int, default = 5) - 当解码器 = 'beamsearch' 或 'wordbeamsearch' 时要保留多少光束;
-
batch_size (int, default = 1) - batch_size>1 将使 EasyOCR 更快但使用更多内存;
-
worker (int, default = 0) - 数据加载器中使用的编号线程;
-
allowlist (string) - 强制 EasyOCR 只识别字符的子集。对特定问题有用(例如车牌等);
-
blocklist (string) - 字符的块子集。如果给定了允许列表,则此参数将被忽略。
-
detail (int, default = 1) - 将此设置为 0 以进行简单输出;
-
paragraph (bool, default = False) - 将结果合并到段落中;
-
min_size (int, default = 10) - 过滤文本框小于最小值(以像素为单位);
-
rotation_info (list, default = None) - 允许 EasyOCR 旋转每个文本框并返回具有最佳置信度分数的文本框。符合条件的值为 90、180 和 270。例如,对所有可能的文本方向尝试 [90, 180 ,270]。
-
contrast_ths (float, default = 0.1) - 对比度低于此值的文本框将被传入模型 2 次。首先是原始图像,其次是对比度调整为“adjust_contrast”值。结果将返回具有更高置信度的那个;
-
adjust_contrast (float, default = 0.5) - 低对比度文本框的目标对比度级别。
-
text_threshold (float, default = 0.7) - 文本置信度阈值
-
low_text (float, default = 0.4) - 文本下限分数
-
link_threshold (float, default = 0.4) - 链接置信度阈值
-
canvas_size (int, default = 2560) - 最大图像尺寸。大于此值的图像将被缩小。
-
mag_ratio (float, default = 1) - 图像放大率
-
slope_ths (float, default = 0.1) - 考虑合并的最大斜率 (delta y/delta x)。低值意味着不会合并平铺框。
-
ycenter_ths (float, default = 0.5) - y 方向的最大偏移。不应该合并不同级别的框。
-
height_ths (float, default = 0.5) - 盒子高度的最大差异。不应合并文本大小非常不同的框。
-
width_ths (float, default = 0.5) - 合并框的最大水平距离。
-
add_margin (float, default = 0.1) - 将边界框向所有方向扩展某个值。这对于具有复杂脚本的语言(例如泰语)很重要。
-
x_ths (float, default = 1.0) - 当段落=True 时合并文本框的最大水平距离。
-
y_ths (float, default = 0.5) - 当段落 = True 时合并文本框的最大垂直距离。
四、识别模型
 https://github.com/JaidedAI/EasyOCR/blob/master/custom_model.md
https://github.com/JaidedAI/EasyOCR/blob/master/custom_model.md4.1、训练识别模型
4.2、使用自定义的识别模型
五、使用
5.1、基本使用1
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=True
5.2、基本使用2

代码实现如下:
import easyocr
reader = easyocr.Reader(
lang_list=['ch_sim', 'en'], # 需要导入的语言识别模型,可以传入多个语言模型,其中英语模型en可以与其他语言共同使用
gpu=False, # 默认为True
download_enabled=True # 默认为True,如果 EasyOCR 无法找到模型文件,则启用下载
)
result = reader.readtext('id_card.jpg', detail=1 ) # 图片可以传入图片路径、也可以传入图片链接。但推荐传入图片路径,会提高识别速度。包含中文会出错。设置detail=0可以简化输出结果,默认为1
print(result)
readtext 返回的列表中,每个元素都是一个元组,内含三个信息:位置、文字、置信度:
[
([[27, 37], [341, 37], [341, 79], [27, 79]], '姓 名 爱新觉罗 。玄烨', 0.6958897643232619),
([[29, 99], [157, 99], [157, 135], [29, 135]], '性 别 男', 0.914532774041559),
([[180, 95], [284, 95], [284, 131], [180, 131]], '民蔟满', 0.4622474180193509),
([[30, 152], [94, 152], [94, 182], [30, 182]], '出 生', 0.6015505790710449),
([[110, 152], [344, 152], [344, 184], [110, 184]], '1654 年54日', 0.42167866223467815),
([[29, 205], [421, 205], [421, 243], [29, 243]], '住 址 北京市东城区景山前街4号', 0.6362530289101117),
([[105, 251], [267, 251], [267, 287], [105, 287]], '紫禁城乾清宫', 0.8425745057905053),
([[32, 346], [200, 346], [200, 378], [32, 378]], '公民身份证号码', 0.22538012770296922),
([[218, 348], [566, 348], [566, 376], [218, 376]], '000003165405049842', 0.902066405195785)
]
detail=0,从而只返回文字内容:
['姓 名 爱新觉罗 。玄烨', '性 别 男', '民蔟满', '出 生', '1654 年54日', '住 址 北京市东城区景山前街4号', '紫禁城 乾清宫', '公民身份证号码', '000003165405049842']
5.3、基本使用3


智能推荐
ctf 网络安全比赛简介_简单的ctf竞赛-程序员宅基地
文章浏览阅读1k次。MISC(安全杂项):全称Miscellaneous。题目涉及流量分析、电子取证、人肉搜索、数据分析、大数据统计等等,覆盖面比较广。我们平时看到的社工类题目;给你一个流量包让你分析的题目;取证分析题目,都属于这类题目。主要考查参赛选手的各种基础综合知识,考察范围比较广。PPC(编程类):全称Professionally Program Coder。题目涉及到程序编写、编程算法实现。算法的逆向编写,批量处理等,有时候用编程去处理问题,会方便的多。当然PPC相比ACM来说,还是较为容易的。_简单的ctf竞赛
数学建模预测方法之 微分方程模型_微分方程预测模型-程序员宅基地
文章浏览阅读6.7k次,点赞7次,收藏42次。微分方程模型适用于基于相关原理的因果预测模型,大多是物理或几何方面的典型问题,假设条件,用数学符号表示规律,列出方程,求解的结果就是问题的答案。短、中、长期的预测都适合。反应事物内部规律及其内在关系,但由于方程的建立是以局部规律的独立性假定为基础,当作为长期预测时,误差较大,且微分方程的解比较难以得到。传染病的预测模型、经济增长(或人口)的预测模型、Lanchester战争预测模型、药物在体内的分布与排除预测模型、烟雾的扩散与消失模型..._微分方程预测模型
C#调用Oracle数据库_c# oracle-程序员宅基地
文章浏览阅读3.8k次。目前为止所用过的c#访问orale数据库的方式有两种,一种是使用 Oracle.ManagedDataAccess.Client方式来调用,另一种是使用System.Data.OracleClient方式来调用,两者的区别是第一种方式是最新的方式,使用起来也比第二种方式要简单的多,但是缺点可能无法访问旧版的Oracle数据库例如 9i,尤其是当oracle数据库的各种权限、角色等各种参数由于各种原因不允许对其修改时可能会无法访问的情况,第二种方式是一种过时的方式,它的优点是可以弥补第一种方..._c# oracle
Network_Card/DR600VX-Qualcomm-Atheros-QCA9880-2T2R-MIMO-802.11ac-Mini-PCIe-Wi-Fi-Module-Dual-Ba_dr600vx网卡-程序员宅基地
文章浏览阅读328次。https://www.wallystech.com/Network_Card/DR600VX-Qualcomm-Atheros-QCA9880-2T2R-MIMO-802.11ac-Mini-PCIe-Wi-Fi-Module-Dual-Band-2.4GHz-5GHz.htmlcontact:[email protected] max 24dBm & 5GHz max 23dBm o..._dr600vx网卡
快速学会创建uni-app项目并了解pages.json文件_uni中的page-程序员宅基地
文章浏览阅读3.2k次,点赞103次,收藏96次。学习目标:1.学会创建uni-app项目 2.了解uni-app中pages.josn文件的作用_uni中的page
【js】JavaScript手动回收垃圾_js手动触发gc-程序员宅基地
文章浏览阅读1.5w次,点赞2次,收藏5次。如何手动触发 JavaScript 垃圾回收行为?垃圾回收,即 garbage collect,简称 “GC”。这里的 “手动” 指有效地、显式地、可控地触发浏览器 JavaScript 引擎的垃圾回收行为,比如通过点击页面中的按钮来调用 JS 方法,或使用浏览器提供的功能。IEIE 实际上提供了一个未公开的 JS 方法 CollectGarbage()。至少在 I_js手动触发gc
随便推点
回炉夜话 - 序-程序员宅基地
文章浏览阅读159次。有志足风流,惜诺自可亲 这是我大学时代信奉的格言。转眼年至不惑,回想人生倒也是感慨万千。 在这里,作为一个老码农,我想梳理下自己的技术栈。为继续做一个码农而努力。 一、首先,对于各种技术的掌握程度作出如下定义: 了解: 阅读过相关资料或书籍,有可能..._回炉夜话全集
Android问题解决--“signal 11 (SIGSEGV), code 2 (SEGV_ACCERR), fault addr 0xxxxxxx” 又出现了_to unreadable libraries. for unwinds of apps, only-程序员宅基地
文章浏览阅读1.2w次。今天,调试一个app,又出现“signal 11 (SIGSEGV), code 2 (SEGV_ACCERR), fault addr 0xxxxxx”问题了。而且只在Android10以上版本才会有,导致的现象是app崩溃,这怎么怎?问题log:signal 11 (SIGSEGV), code 2 (SEGV_ACCERR), fault addr 0x739ae8d004全部log如下:05-08 10:21:31.065 D/a.module(1890.._to unreadable libraries. for unwinds of apps, only shared libraries
工件SSMwar exploded 部署工件时出错。请参阅服务器日志了解详细信息_正在构建工件 'ssm0950my8t:war exploded': 正在复制文件…-程序员宅基地
文章浏览阅读1.9k次。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。由于监听器过早的生效时间导致我们自动注入的bean的引用名称还没有生效(实际上bean已经注入了,但是监听器此时识别不到,小写类名首字母也没有用),这时候就要用到自定义bean名称了!仔细想一下,查看我监听器的代码,监听器实现了ServletContextListener接口,是一个全局监听器,也就是项目刚启动是就会生效,于是我添加了一条输出信息,就是“进入监听器”..._正在构建工件 'ssm0950my8t:war exploded': 正在复制文件…
字符串(python)_首先创建一个字符串str为“a little girl”,提取第3到13个字符,并组成新的字符串b-程序员宅基地
文章浏览阅读217次,点赞2次,收藏2次。(2)请统计字符串出现的每个字母的出现次数(忽略大小写,a 与 A 是同一个字母),并输出成一个字典。‘aAsmr3idd4bgs7Dlsf9eAF’,经过去除后,输出 ‘asmr3id4bg7lf9e’(4)按字符串中字符出现频率从高到低输出到列表,如果次数相同则按字母顺序排列。(3)请去除字符串多次出现的字母,仅留最先出现的一个,大小写不敏感。(1)请将字符串的数字取出,并输出成一个新的字符串。_首先创建一个字符串str为“a little girl”,提取第3到13个字符,并组成新的字符串b
JVisualVM 手动生成 Java Core Dump_手动生成coredump-程序员宅基地
文章浏览阅读2k次。最近在研究 Java Core Dump 查看及使用问题,这里我采了JDK自带工具jvisualvm ,这个工具可协助生成 Java Core Dump 文件1, Java Core Dump 文件是什么Java Core Dump 文件呢,是针对 JVM 虚拟机发生致命问题或者 JVM 中运行的程序造成致命问题时,所产生的记录文件,通常会存在2个文件1.1,Java Cor..._手动生成coredump
谈谈开源技术选型_开源技术 选型-程序员宅基地
文章浏览阅读4.7k次。有时感觉技术选型就像个伪命题,胜出的技术占据绝对的主流,就像 java 领域中 ejb 被 ssh/ssi 框架取代。 大部分项目使用近似的模式搭建,选型在工程中变得似乎可有可无。 时间上胜出的开源技术帮助开发者在客观上做出了选择,我们先了解下影响选型的客观因素。客观因素客观因素包括如下:1. 广泛性我们都倾向于选择更广泛应用的开源技术以规避未知性风险。2. 质量质量我们会_开源技术 选型