
”PPO“ 的搜索结果

根据OpenAI 提供的伪代码,PPO算法中的第一步。 受的简单实现启发,通过使用Actor和Critic网络创建轨迹
PPO(Proximal Policy Optimization,近端策略优化)是一种强化学习算法,由John Schulman等人在2017年提出。PPO属于策略梯度方法,这类方法直接对策略(即模型的行为)进行优化,试图找到使得期望回报最大化的策略...
接着上面的讲,PG方法一个很大的缺点就是参数更新慢,因为我们每更新一次参数都需要进行重新的采样,这其实是中on-policy的策略,即我们想要训练的agent和与环境进行交互的agent是同一个agent;...
Proximal Policy Optimization (PPO) 是一种强化学习算法,用于训练能够执行连续动作的智能体,以最大化累积奖励。PPO是一种改进的策略梯度方法,旨在解决一些传统策略梯度方法的稳定性和样本效率问题。在本章的内容...
总结来说,PPO和DPO在算法框架和目标函数上有共同之处,但在实现方式、并行化程度以及适用的计算环境上存在差异,DPO特别适用于需要大规模并行处理的场景。总结来说,PPO专注于通过剪切概率比率来稳定策略更新,而...
强化学习PPO算法详解
标签: 算法
也就是上图所描述的方法。接着上面的讲,PG方法一个很大的缺点就是参数更新慢,因为我们每更新一次参数都需要进行重新的采样,这其实是中on-policy的策略,即我们想要训练的agent和与环境进行交互的agent是同一个...
PPO算法是一种强化学习中的策略梯度方法,它的全称是Proximal Policy Optimization,即近端策略优化1。PPO算法的目标是在与环境交互采样数据后,使用随机梯度上升优化一个“替代”目标函数,从而改进策略。PPO算法的...

PPO算法之所以被提出,根本原因在于在处理连续动作空间时取值抉择困难。取值过小,就会导致深度强化学习收敛性较差,陷入完不成训练的局面,取值过大则导致新旧策略迭代时数据不一致,造成学习波动较大或局部震荡。...
PPO初学者 介绍 你好! 我叫Eric Yu,我写了这个资料库来帮助初学者开始使用PyTorch从头开始编写近端策略优化(PPO)。 我的目标是为PPO提供一个基本的代码(很少/没有花哨的技巧),并提供充分的文档记录/样式和...
盆式PPO关于沉思-PPO 这是Pensieve [1]的一个简单的TensorFlow实现。 详细地说,我们通过PPO而非A3C培训了Pensieve。 这是一个稳定的版本,已经准备好训练集和测试集,并且您可以轻松运行仓库:只需键入python train...
[PYTORCH]玩超级马里奥兄弟的近战策略优化(PPO) 介绍 这是我的python源代码,用于训练特工玩超级马里奥兄弟。 通过使用纸张近端策略优化算法推出近端政策优化(PPO)算法。 说到性能,我经过PPO培训的代理可以...
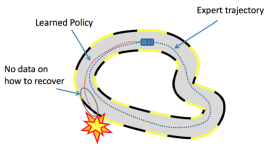
PPO算法是由OpenAI提出的一种新的策略梯度算法,其实现复杂度远低于TRPO算法。PPO算法主要包括两种实现方法,第一种通过CPU仿真实现的,第二种通过GPU仿真实现的,其仿真速度是第一种PPO算法的三倍以上。此外,与...
基于pytorch深度强化学习的PPO,DQN,SAC,DDPG等算法实现python源码.zip基于pytorch深度强化学习的PPO,DQN,SAC,DDPG等算法实现python源码.zip基于pytorch深度强化学习的PPO,DQN,SAC,DDPG等算法实现python源码.zip基于...
基于李宏毅课程总结
[PYTORCH]针对矛盾的最近策略优化(PPO) 介绍 这是我的python源代码,用于训练代理播放相反的声音。 通过使用纸张近端策略优化算法推出近端政策优化(PPO)算法。 供您参考,PPO是OpenAI提出的算法,用于训练Open...
(1)在中国A股市场15只股票上的应用 (2)构建投资组合 (3)每日调仓 (4)绘制收益率曲线 (5)PPO算法
基于turtlebot3+pytorch的深度强化学习DQN,DDPG,PPO,SAC算法源码.zip 基于turtlebot3+pytorch的深度强化学习DQN,DDPG,PPO,SAC算法源码.zip 基于turtlebot3+pytorch的深度强化学习DQN,DDPG,PPO,SAC算法源码.zip 基于...
PPO [] A2C [] GAE [] NAE [] 整体架构 该存储库旨在表示一个漂亮的Tensorboard图,这对于调试非常有用。 典型的图形如下所示: 笔记 分布式算法是使用Ray (灵活,高性能的分布式执行框架)实现的。 由于...
_python_代码_下载 ...在mujoco环境下实现PPO算法,如Ant-v2、Humanoid-v2、Hopper-v2、Halfcheeth-v2。 用法 $ python main.py --env_name Hopper-v2 更多详情、使用方法,请下载后阅读README.md文件
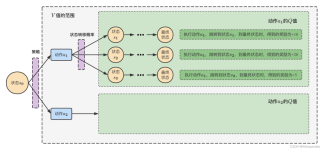
适用于Unity环境的Multi Agent PPO实施 [此项目正在进行中] 基本信息 PPO实现是为具有连续操作空间的多代理程序环境编写的。 该项目已作为Udacity深度强化学习纳米学位的一部分完成。 它适用于Unity ML-Agents环境...
李宏毅强化学习ppo算法ppt
标签: ppo
李宏毅强化学习ppo算法ppt
分布式近端策略优化(DPPO) 这是的pytorch版本实现。 该项目基于。 但是,它已经被重写并包含一些修改,这些修改在某些环境下可能会改善学习。 在这段代码中,我修改了运行均值过滤器,从而提高了性能(例如,在...
算法包括软参与者关键(SAC),深度确定性策略梯度(DDPG),双延迟DDPG(TD3),参与者关键(AC / A2C),近端策略优化(PPO),QT-Opt(包括交叉熵( CE)方法) , PointNet ,运输商,循环策略梯度,软决策树等...
PPO-Keras Keras实施PPO解决OpenAI体育馆环境
通过使用近端策略优化算法论文中介绍的近端策略优化(PPO)算法。 [PYTORCH]用于玩超级马里奥兄弟的近战策略优化(PPO)简介这是我的python源代码,用于训练特工玩超级马里奥兄弟。 通过使用近端策略优化算法论文中...
推荐文章
- YOLO V8车辆行人识别_yolov8 无法识别路边行人-程序员宅基地
- jpa mysql分页_Spring Boot之JPA分页-程序员宅基地
- win10打印图片中间空白以及选择打印机预览重启_win10更新后打印图片中间空白-程序员宅基地
- 【加密】SHA256加盐加密_sha256随机盐加密-程序员宅基地
- cordys 启动流程_cordys服务重启-程序员宅基地
- net中 DLL、GAC-程序员宅基地
- (一看就会)Visual Studio设置字体大小_visual studio怎么调整字体大小-程序员宅基地
- Linux中如何读写硬盘(或Virtual Disk)上指定物理扇区_dd写入确定扇区-程序员宅基地
- python【力扣LeetCode算法题库】面试题 17.16- 按摩师(DP)_一个有名的讲师,预约一小时为单位,每次预约服务之间要有休息时间,给定一个预约请-程序员宅基地
- 进制的转换技巧_10111100b转换为十进制-程序员宅基地